
NETVU CONNECTED, SINGLE CHANNEL, SELECTABLE ENCODER/DECODER€¦ ·

INTELLIGENT ENCODER AND DECODER MODEL
FOR ROBUST AND SECURE AUDIO
WATERMARKING
A synopsis for the research submitted to
Shivaji University, Kolhapur
For the Degree of Doctor
Of Philosophy
In
Electronics Engineering
By
Mrs. Meenakshi Ravindra Patil Dr. J. J. Magdum College of Engineering, Jaysingpur
Email: [email protected]
Under the Guidance of
Dr. Mrs. S. D. Apte Rajarshi Shahu College of Engineering, Pune.
Email: [email protected]
2009

2
Topic of Research :Intelligent encoder and decoder model for
robust and secure audio watermarking
Name of Research Student : Mrs. Meenakshi Ravindra Patil
Address : ‘Vidyasagar’, Plot No. 7, Majale Housing Society
Near Parvati Housing Society, Agarbhag
Jaysingpur-416101.
Phone: 9422727612
Name of the Research Guide : Dr. Mrs. S.D. Apte.
A7, Whispering Wind, Pashan Baner Link
Road, Baner, Pune-
Phone: 9975185707
Signature of Research Guide Signature of Research Student
Dr. Mrs. S. D. Apte Mrs. Meenakshi Ravindra Patil
.

3
1. INTRODUCTION: Presently there is increased usage of Internet and multimedia information.
The availability of different multimedia editing software and the ease with which
multimedia signal are manipulated have opened many challenges and opportunities
for the researchers. A possibility for unlimited copying without a loss of fidelity
causes a considerable financial loss for copyright holders. The ease of content
modification and a perfect reproduction in digital domain have promoted the
protection of intellectual ownership and the prevention of the unauthorized
tampering of multimedia data to become an important technological and research
issue
Encryption of digital multimedia prevents access of the multimedia content
to an individual without a proper decryption key. Therefore, content providers get
paid for the delivery of perceivable multimedia, and each client that has paid the
royalties must be able to decrypt a received file properly. Once the multimedia has
been decrypted, it can be repeatedly copied and distributed without any obstacles.
Modern software and broadband Internet provides the tools to perform it quickly and
without much effort and deep technical knowledge. It is clear that existing security
protocols for electronic commerce serve to secure only the communication channel
between the content provider and the user and are useless if commodity in
transactions is digitally represented.
With the fast growth of the Internet technology unauthorized copying and
distribution of digital media is become difficult. As a result the music industry
claims a multibillion-dollar annual loss due to piracy, which is likely to increase. A
promising solution to this problem is marking the media signal with a secret, robust
and imperceptible watermark. The invention of digital watermarks not only triggered
worldwide research on digital watermarking technology but also ways of attacking,
counterfeiting and falsifying digital watermarks, with the goal of making illegal
profit or bypassing laws. The research on watermark attacks made it significant to
develop the new methods of digital watermarking which are resilient to attacks.
Digital watermarking has been proposed as a new, alternative method to
enforce the intellectual property rights and protect digital media from tampering. It
involves a process of embedding the digital signature into a host signal in order to

4
"mark" the ownership. The digital signature is called the digital watermark. The
digital watermark contains data that can be used in various applications, including
digital rights management, broadcast monitoring and tamper proofing. The existence
of the watermark is indicated when watermarked media is passed through an
appropriate watermark detector. Watermark Secret Key
Host Watermarked Detected Audio Audio Watermark
Secret Key
Fig1.1 Block diagram of watermarking system
Figure 1.1 gives an overview of the general watermarking system. A
watermark, which usually consists of a binary data sequence, is inserted into the host
signal in the watermark embedder. Thus, a watermark embedder has two inputs; one
is the watermark message accompanied by a secret key and the other is the host
signal (e.g. image, video clip, audio sequence etc.).
Applications for digital watermarking include copyright protection,
authentication copy control, tamper detection and data hiding applications. For the
robust watermarking which include copyright protection where each copy gets a
unique watermark to identify the end user so that tracing is possible for cases of
illegal use and authentication where the watermark can represent a signature and
copy control for digital recording devices.
Perceptibility
Perceptibility can be assessed to different levels of assurance. The problem
here is very similar to the evaluation of compression algorithms. The watermark
could be just slightly perceptible but not perceptible under domestic/ consumer
viewing/listening conditions. Another level is nonperceptibility in comparison with
the original under studio conditions.
The robustness can be assessed by measuring the detection probability of the
mark and the bit error rate for a set of criteria that are relevant for the application
Watermark
Embedder Watermark
Detecter

5
that is considered. The levels of robustness range from no robustness to provable
robustness.
The first levels of robustness can be assessed automatically by applying a
simple benchmark algorithm:
For each medium in a determined set:
1. Embed a random payload with the greatest strength that does not introduce
annoying effects. In other words, embed the mark such that the quality of the output
for a given quality metric is greater than a given minima.
2. Apply a set of given transformations to the marked medium.
For each distorted medium try to extract the watermark and measure the certainty of
extraction. Simple methods may just use a success/failure approach, that is, to
consider the extraction successful if and only if the payload is fully recovered
without error. The measure for the robustness is the certainty of detection or the bit
error rate after extraction.
Capacity
In most applications the capacity will be a fixed constraint of the system so
robustness testing will be done with a random payload of a given size. While
developing a watermarking scheme, however, knowing the tradeoff between the
basic requirements is very useful and graphing with two varying requirements—the
others being fixed—is a simple way to achieve this. This is useful from a user’s
point of view: the performance is fixed (we want only 5% of the bits to be corrupted
so we can use error correction codes to recover all the information we wanted to
hide) and so it helps to define what kind of attacks the scheme will survive if the
user accepts such or such quality degradation.
Speed
Speed is dependent on the type of implementation: software or hardware.
The complexity is an important criteria and some applications impose a limitation on
the maximum number of gates that can be used, the amount of required memory, etc.

6
Statistical Undetectability All methods of steganography and watermarking substitute part of the cover
signal, which has some particular statistical properties, with another signal with
different statistical properties; in fact, embedding processes usually do not pay
attention to the difference in statistical properties between the original cover signal
and the stegosignal. This leads to possible detection attacks.
2. LITERATURE SURVEY Several digital watermarking techniques are proposed which include
watermarking for images, audio and video. The watermarking is primarily
developed for the images [1-11], the research in audio is started later. During the last
decade audio watermarking schemes [12-50] have been applied widely. These
schemes are sophisticated very much in terms of robustness and imperceptibility.
Robustness and imperceptibility are important requirements of watermarking, while
they conflict each other.
2.1 Spread spectrum audio watermarking: Spread spectrum (SS) technique is most popular technique and is used by many
researchers in their implementations [12-18]. Amplitude scaled Spread Spectrum
Sequence is embedded in the host audio signal which can be detected via a
correlation technique. Boney et al [12] proposed a non blind audio watermarking
which generates different watermark for different audio signal and spread in to the
host audio. J. Seok et al [13] and Kirovski et al [14] developed the audio
watermarking schemes that embed the information by modulating it by a direct
sequence spread spectrum method. Malvar et al [15] proposes a new embedding
approach based on traditional SS embedding by slightly modifying it. In this scheme
they introduced two parameters to control the distortion level and control the
removal of carrier distortion on the detection statistics. The content based audio
watermarking technique was implemented by S. Esmaili et al [16] to satisfy and
maximize both imperceptibility and robustness of the watermark. They used short-
time Fourier transform of the original audio signal to estimate a weighted
instantaneous mean frequency of the signal. D. Kirovski et al [17] devised a scheme

7
for robust covert communication over a public audio channel using spread spectrum
by imposing particular structures of watermark patterns and applying nonlinear filter
to reduce carrier noise. Hafiz Malik et al [18] proposed an audio watermarking
method based on frequency selective direct sequence spread spectrum. The method
improves the detection capability, watermarking capacity and robustness to
desynchronization attacks.
2.2 Methods using patchwork algorithm:
The patchwork technique was first presented in 1996 by Bender et al [19] for
embedding watermarks in images. It is a statistical method based on hypothesis
testing and relying on large data sets. The watermark embedding process uses a
pseudorandom process to insert a certain statistic into a host audio data set, which is
extracted with the help of numerical indexes (like the mean value), describing the
specific distribution. The method is usually applied in a transform domain (Fourier,
wavelet, etc.) in order to spread the watermark in time domain and to increase
robustness against signal processing modifications [19].
Multiplicative patchwork scheme developed by Yeo et al [20] provides a
new way of patchwork embedding. Cvejic et al [21] presented a robust audio
watermarking method implemented in wavelet domain which uses the frequency
hopping and patchwork method. R. Wang et al [22] proposed an audio
watermarking scheme which embedded robust and fragile watermark at the same
time in lifting wavelet domain.
2.3 Methods in time domain: There are few algorithms implemented in time domain [23-26]. W. Lie et al
[23] proposed a method of embedding digital watermarks which exploits differential
average-of-absolute-amplitude relations within each group of audio samples to
represent one-bit information. In a method suggested by Bassia et al [24] watermark
embedding depends on the audio signals amplitude and frequency in a way that
minimizes the audibility of the watermark signal. A. N. Lemma et al [25]
investigated an audio watermarking system is referred to as modified audio signal

8
keying (MASK). In MASK, the short-time envelope of the audio signal is modified
in such a way that the change is imperceptible to the human listener.
2.4 Methods implemented in Transform domain:
A blind digital audio watermarking scheme against synchronization attack
using adaptive quantization is proposed by X.Y. Wang et al [26]. Barker code has
better self-relativity, so Huang et al. [27] chooses it as synchronization mark and
embeds it into temporal domain and embeds the watermark information into DCT
domain. S. Wu, J. Hang. et al [28] proposed a self-synchronization algorithm for
audio watermarking to facilitate assured audio data transmission. The
synchronization codes are embedded into audio with the informative data, thus the
embedded data have the self-synchronization ability. To achieve robustness, they
embed the synchronization codes and the hidden informative data into the low
frequency coefficients in DWT (discrete wavelet transform) domain. Li et al [29]
developed the watermarking technique in wavelet domain based on SNR to
determine the scaling parameter required to scale the watermark. The intensity of
embedded watermark can be modified by adaptively adjusting the scaling parameter.
A new watermarking technique capable of embedding multiple watermarks based on
phase modulation is devised by A. Takahashi et al [30]. H. H. Tsai et al [31]
proposed a new intelligent audio watermarking method based on the characteristics
of the HAS and the techniques of neural networks in the DCT domain. C. Xu et al
[32] implemented a method to embed and extract the digital compressed audio. The
watermark is embedded in partially uncompressed domain and the embedding
scheme is high related to audio content. X. Li et al [33] developed a data hiding
scheme for audio signals in cepstrum domain. Cepstrum representation of audio can
be shown to be very robust to a wide range of attacks. S. K. Lee et al [34] insert a
digital watermark into the cepstral components of the audio signal using a technique
analogous to spread spectrum communications, hiding a narrow band signal in a
wideband channel. There are various techniques implemented in wavelet domain
[35-41]. In these papers it is proved that the wavelet domain is the more suitable
domain compare to the other transform domains.

9
2.5 Other recently developed algorithms:
Audio watermarking is usually used as a multimedia copyright protection
tool or as a system that embed metadata in audio signals. In the method suggested by
S. D. Larbi et al [42] watermarking is viewed as a preprocessing step for further
audio processing systems: the watermark signal conveys no information; rather it is
used to modify the nonstationarity. T. Furon et al [43] investigated an asymmetric
watermarking method as an alternative to direct sequence spread spectrum technique
(DSSS) of watermarking.
Conventional watermarking techniques based on echo hiding provide many
benefits, but also have several disadvantages, for example, lenient decoding process,
weakness against multiple encoding attacks etc. B.S. Ko et al [44] improve the weak
points of conventional echo hiding by time-spread echo method. Spreading an echo
in the time domain is achieved by using pseudo-noise (PN) sequences. S. Eerüçük et
al [45] introduced a novel watermark representation for audio watermarking, where
they embed linear chirps as watermark signals. A new adaptive blind digital audio
watermarking algorithm is proposed by X. Wang et al [46] on the basis of support
vector regression (SVR). This algorithm embeds the template information and
watermark signal into the original audio by adaptive quantization according to the
local audio correlation and human auditory masking.
2.6 Audio watermarking techniques against time scale
modification: Mansour and Twefik [47] proposed to embed watermark by changing the
relative length of the middle segment between two successive maximum and
minimum of the smoothed waveform, the performance highly depends on the
selection of the threshold and it is a delicate work to find an appropriate threshold.
Mansour and Twefik [48] proposed another algorithm for embedding data into audio
signals by changing the interval lengths between salient points in the signal. The
extreme point of the wavelet coefficients from the selected envelop is adopted as
salient points. W. Li et al [49] have suggested a novel content – dependent localized
scheme to combat synchronization attacks like random cropping and time-scale
modification. The basic idea is to first select steady high-energy local regions that

10
represent music edges like note attacks, transitions or drum sounds by using
different methods, then embed the watermark in these regions. S. Xiang et al [50]
presented a multibit robust audio watermarking solution by using the insensitivity of
the audio histogram shape and the modified mean to TSM and cropping operations.
A blind digital audio watermarking scheme against synchronization attack using
adaptive mean quantization is developed by X-Y. Wang et al [51].
2.7 Papers studied on performance analysis and evaluation of
watermarking systems: J. D. Gordy et al [52] have presented an algorithm independent set of criteria
for quantitatively comparing the performance of digital watermarking algorithms.
The criteria are simple to test, and may be applied to any type of watermarking
system (audio, image, or video). 1) Bit rate refers to the amount of watermark data
that may be reliably embedded within a host signal per unit of time or space, such as
bits per second or bits per pixel. 2)Perceptual quality refers to the
imperceptibility of embedded watermark data within the host signal. 3)
Computational complexity refers to the processing required to embed watermark
data into a host signal, and / or to extract the data from the signal. 4) Watermarked
digital signals may undergo common signal processing operations such as linear
filtering, sample requantization, D/A and A/D conversion, and lossy
compression. Although these operations may not affect the perceived quality of
the host signal, they may corrupt the watermark data embedded within the
signal. It is important to know, for a given level of host signal distortion,
which watermarking algorithm will produce a more reliable embedding.
The performance of spread-transform dither modulation watermarking in the
presence of two important classes of non additive attacks, such as the gain attack
plus noise addition and the quantization attack are evaluated by F. Bartolini et al
[53]. Many systems have been proposed by different authors but it was difficult to
have idea of their performance and hence to compare them. Then F.A.P. Petitcolas et
al [54] propose a benchmark based on a set of attacks that any system ought to
survive. G.C. Rodriguez et al [55] presented a survey report on audio watermarking
in which watermarking techniques are briefly summarized and analyzed. M. Wu et

11
al [56] points out weaknesses in the watermark techniques and suggest directions for
further improvement. Authors have provided the general framework for analyzing
the robustness and security of audio watermark systems.
2.8 Watermark attacks: Frank Hartung et al [57] have shown that the spread spectrum watermarks
and watermark detectors are vulnerable to a variety of attacks. However with
appropriate modifications to the embedding and extraction methods, methods can be
made much more resistant to variety of such attacks. Martin Kutter et al [58]
suggested the watermark copy attack, which is based on an estimation of the
embedded watermark in the spatial domain through a filtering process. Alexander et
al [59] suggested the watermark template attack. This attack estimates the
corresponding template points in the FFT domain and then removes them using local
interpolation. J. K. Su et al [60] suggested a Channel Model for a Watermark
Attack. Authors have analyzed this attach for images and stated that the attack can
be applied to audio/video watermarking schemes. D. Kirovski et al [61] analyzed the
security of multimedia copyright protection systems that use watermarks by
proposing a new breed of attacks on generic watermarking systems.
My research concentrates on developing an audio watermarking technique to
detection convergence and robustness, improving watermark imperceptiveness. An
attempt is also made to embed the audio data in audio signal during this research.
3. RESEARCH PROBLEM:
The fundamental process in each watermarking system can be modeled as a
form of communication where a message is transmitted from watermark embedder
to the watermark receiver [2]. The process of watermarking is viewed as a
transmission channel through which the watermark message is being sent, with the
host signal being a part of that channel. In Figure 3.1, a general mapping of a
watermarking system into a communications model is given.

12
Fig. 3.1. A watermarking system and an equivalent communications model.
After the watermark is embedded, the watermarked signal is usually distorted
after watermark attacks. The distortions of the watermarked signal are, similarly to
the data communications model, modeled as additive noise.
Thus, the research problem can be divided into three specific sub problems.
They are:
SP1: What is the highest watermark bit rate obtainable, under perceptual
transparency constraint, and how to approach the limit?
SP2: How can the detection performance of a watermarking system be improved
using algorithms based on communications models for that system?
SP3: How can overall robustness to attacks of a watermark system be increased
using an attack characterization at the embedding side?
The division of the research problem into the three sub problems above
defines the following three research hypotheses:
RH1: To obtain a distinctively high watermark data rate, embedding algorithm can
be implemented in a transform domain.
RH2: To improve detection performance, a spread spectrum method can be used. To
make the system intelligent encode the watermark, add synchronization pattern,
remove the isolated pixels at the end of decoder.
RH3:To achieve the robustness of watermarking algorithms, an attack
characterization can be introduced at the embedder. The perceptual transparency
(inaudibility) of a proposed audio watermarking scheme can be confirmed through
Input
Message
wk
n
Noise
cwn
Output
Message
Host
signal Watermark
key
Watermark
key
cw
com Wa
Watermark detector
Watermark
Decoder
Watermark embedder
Watermark
encoder

13
subjective listening tests in a predefined laboratory environment with participation
of a predefined number of people with a different music education and background.
4. HIGH CAPACITY COVERT COMMUNICATION FOR AUDIO Usually embedding is performed in high amplitude portions of the signal
either in time or frequency domain. The technique proposed in this section uses the
audio information as the watermark. The objective of the method implemented here
is to provide an audio watermarking technique that can be used for covert
communication of audio signals. In the proposed technique the input audio is
decomposed using discrete wavelet transform (DWT). The covert message (audio
watermark) is embedded to the detailed coefficient of three level decomposed
original audio signals. The watermark embedding and watermark extraction process
is shown in fig 2 and fig 3 respectively.
The algorithm is applied to a set of audio signals. The signals are mono with
sampling rates 44.1 KHz. In a 45 sec audio file we are able to embed 5 sec of cover
audio signal. To evaluate the watermarked audio quality the listening test [13] is
performed. The subjective listening test results are summarized under Diffgrade.
The Diffgrade is equal to the subjective rating given to the watermarked test item
minus the rating given to the hidden reference: a Diffgrade near 0.00 indicates a high
level of quality.
Audio watermark
Original Signal Watermarked Signal
Watermark extraction
3-level Wavelet
Decomposition
3-level Wavelet
Decomposition
Fig 3 Watermark extraction
Secret key
Audio Watermark
Original Signal
3-level wavelet
decomposition
Watermark
Embedding
Inverse
DWT
Watermarked signal
Fig.2 Watermark embedding

14
Table 1 Subjective listening test for mp3 song
Sr.No Type of attack Diffgrade 1 MPEG-1 Layer-3 128 kbps/mono 0.00 2 MPEG-1 Layer3 64 kbps/mono 0.00 3 Band pass filtering 0.00 4 Echo addition 0.00 5 Equalization 0.00 6 Cropping 0.00 7 Requantization 0.00 8 Down sampling 0.00 9 Up sampling -1 10 Time warping -2 11 Low pass filtering -3
The Diffgrade scale is partitioned into five ranges: imperceptible (> 0.00),
not annoying (0.00 to –1.00), slightly annoying (–1.00 to –2.00), annoying (–2.00 to
–3.00), and very annoying (–3.00 to –4.00).” The number of transparent items
represents the number of incorrectly identified items. Fifteen listeners participated in
the listening test.
To evaluate the performance of the proposed watermarking technique its
robustness is tested. To test the robustness of the scheme the watermarked signal is
passed through different signal processing attacks and then watermark is recovered.
The BER tells the similarity between the original watermark and the
extracted watermark. Experimental results obtained indicate that the present
watermarking technique is robust to common signal processing attacks such as
compression, echo addition and equalization. While performing the robustness test it
is also observed that the watermark will not withstand if the watermarked signal is
passed through low pass filtering of 6 KHz, 10 KHz.

15
Table 2 Robustness test for mp3 song
Sr.No Type of attack BER in % for this scheme
1 MPEG-1 Layer-3 128 kbps/mono
0.0017493
2 MPEG-1 Layer3 64 kbps/mono 0.0017877 3 Band pass filtering 0.0017578 4 Echo addition 0.0017591 5 Equalization 0.0017493 6 Cropping 0.003564 7 Requantization 0.001728 8 Down sampling 0.003564 9 Up sampling 0.042567
10 Time warping 0.037863 11 Low pass filtering 2.1
5. SPREAD SPECTRUM AUDIO WATERMARKING
ALGORITHM The spread spectrum techniques can be divided in to two categories blind
and non blind techniques. Blind watermarking techniques detect the watermark
without using the original host signal whereas the non blind techniques use the
original host signal to detect the watermark. Non blind techniques recover the
watermark whereas it requires the original signal to recover the watermark.
The non blind technique suggested by Li et al [29] is implemented in the
initial stage of the research to test the watermarking scheme for our database and
then compare the results with our proposed schemes. We propose the adaptive blind
watermarking technique based on SNR using DWT and lifting wavelet transform. In
this method we compute the scaling parameter (α(k)) for every segment of host
audio signal and then embed according to the rules for bit one or bit zero of
watermark signal. One bit of binary watermark is then added in to one segment of
host audio signal.
( )
⎪⎩
⎪⎨
⎧ ⋅α+=
otherwise)i(k3A
)i(Amaxis)i(k3Aif)k(w)k()i(k
3A)i(k
3B3k
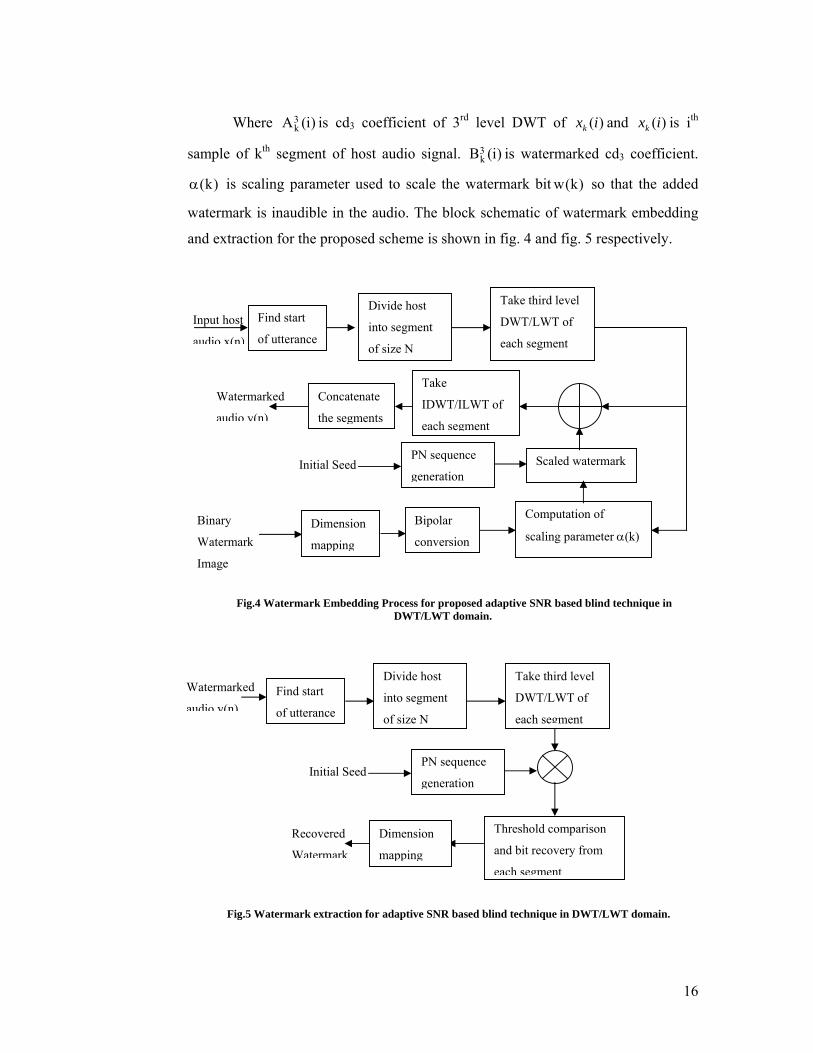
16
Where )i(A3k is cd3 coefficient of 3rd level DWT of )(ixk and )(ixk is ith
sample of kth segment of host audio signal. )i(B3k is watermarked cd3 coefficient.
)k(α is scaling parameter used to scale the watermark bit )k(w so that the added
watermark is inaudible in the audio. The block schematic of watermark embedding
and extraction for the proposed scheme is shown in fig. 4 and fig. 5 respectively.
Fig.4 Watermark Embedding Process for proposed adaptive SNR based blind technique in DWT/LWT domain.
Fig.5 Watermark extraction for adaptive SNR based blind technique in DWT/LWT domain.
Initial Seed
Watermarked
audio y(n)
Input host
audio x(n)
Binary
Watermark
Image
Find start
of utterance
Divide host
into segment
of size N
Dimension
mapping
Bipolar
conversion
Computation of
scaling parameter α(k)
Scaled watermark
Concatenate
the segments
PN sequence
generation
Take third level
DWT/LWT of
each segment
Take
IDWT/ILWT of
each segment
Recovered
Watermark
Watermarked
audio y(n)Find start
of utterance
Divide host
into segment
of size N
Take third level
DWT/LWT of
each segment
Initial Seed PN sequence
generation
Threshold comparison
and bit recovery from
each segment
Dimension
mapping

17
This variation of α(k) for every segment takes in to account the feature of the
host audio in that segment and then computes the value of α(k), which is similar to
finding the scaling parameter taking into consideration the perceptual transparency
of the host audio. In order to proceed to detect the watermark the knowledge of
scaling parameter α is very important. Without the knowledge of α(k) it is not
possible to detect the watermark. Scaling parameter α(k) is computed during the
watermark embedding process using the formula
( )( )( )
)k(w
10.iA)k( i
10SNR23k∑
=α
−
Where )i(A3k is cd3 coefficient of 3rd level DWT of )(ixk and )(ixk is ith
sample of kth segment of host audio signal.
The original signal x(n) is required for computation of the value of α(k) in
order to recover the watermark properly. The formula required to detect the
watermark is exactly the reverse of watermark embedding. To detect the watermark
the x(n) and y(n) are divided into subsections of size N where N =2i. Where the
value of i is same as that used during the watermark embedding process. Each
subsection is decomposed using 3-level wavelet transform. Experimental results for
this method are summarized in table 3. Table 3 Experimental Results against Signal Processing Attacks for non blind technique (MP3
song)
Sr.
No
Attack SNR Correlation
Coefficient
BER
Without attack 43.77 1 0
1 Down Sampling 28.56 0.9889 0.0039
2 Up Sampling 34.26 0.9917 0.0027
3 LP-filtering 19.73 0.9917 0.0027
4 Requantization 39 0.9917 0.0027
5 Cropping 37.29 0.9889 0.0039
6 Mp3 compression 41.25 0.9917 0.0027
7 Noise addition 34.26 0.9889 0.0039
9 Echo addition 37.4420 0.9889 0.0039
10 Equalization 38.518 0.9889 0.0039
18
To improve the imperceptibility between the original audio signal and the
watermarked audio signal the adaptive SNR based scheme using DWT-DCT is
implemented. To make the system intelligent we propose to embed the watermark
using cyclic coding. The scheme which encodes the watermark using cyclic codes
and embeds the watermark is also proposed.
It can be observed that blind techniques are robust against various signal
processing attacks. The scaling parameter used to embed the watermark is varied
adaptively for each segment in order to achieve the imperceptibility and to take the
advantage of insensitivity of HAS to smaller variations in transform domain. To
provide the security to the system the secret key is used which is a PNR sequence
generated by any cryptographic method. Without the knowledge of this secret key it
is not possible to recover the watermark.
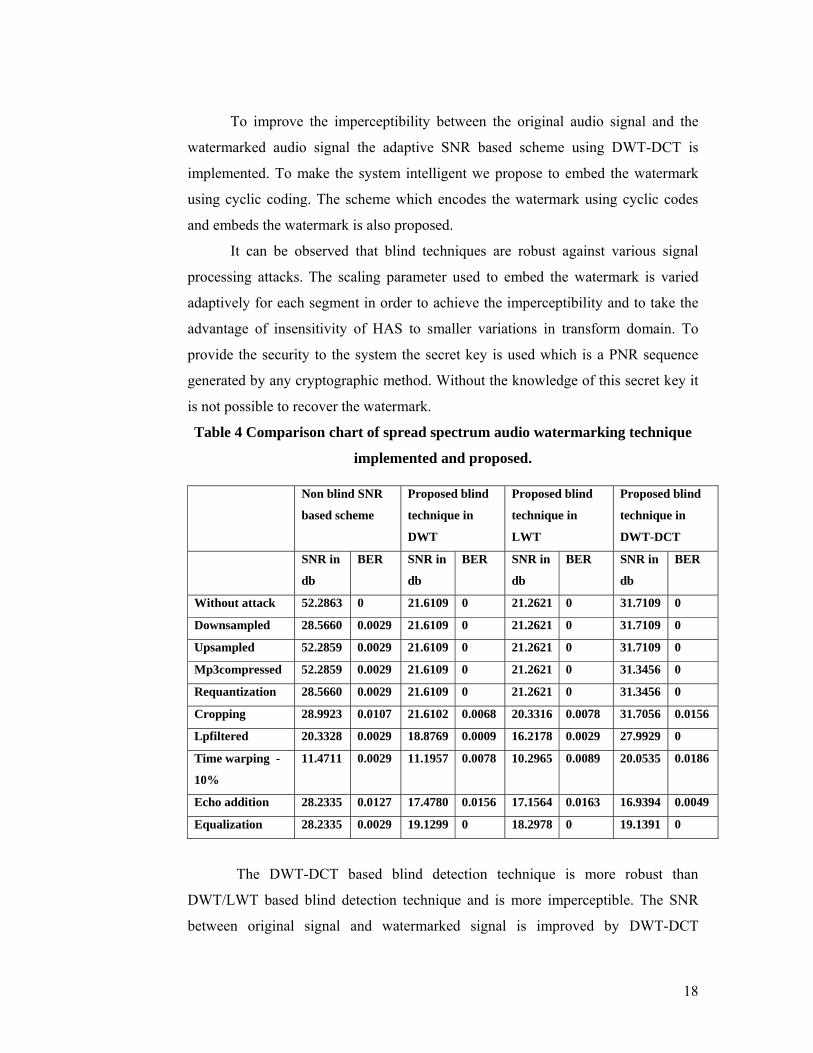
Table 4 Comparison chart of spread spectrum audio watermarking technique
implemented and proposed.
The DWT-DCT based blind detection technique is more robust than
DWT/LWT based blind detection technique and is more imperceptible. The SNR
between original signal and watermarked signal is improved by DWT-DCT
Non blind SNR
based scheme
Proposed blind
technique in
DWT
Proposed blind
technique in
LWT
Proposed blind
technique in
DWT-DCT
SNR in
db
BER SNR in
db
BER SNR in
db
BER SNR in
db
BER
Without attack 52.2863 0 21.6109 0 21.2621 0 31.7109 0
Downsampled 28.5660 0.0029 21.6109 0 21.2621 0 31.7109 0
Upsampled 52.2859 0.0029 21.6109 0 21.2621 0 31.7109 0
Mp3compressed 52.2859 0.0029 21.6109 0 21.2621 0 31.3456 0
Requantization 28.5660 0.0029 21.6109 0 21.2621 0 31.3456 0
Cropping 28.9923 0.0107 21.6102 0.0068 20.3316 0.0078 31.7056 0.0156
Lpfiltered 20.3328 0.0029 18.8769 0.0009 16.2178 0.0029 27.9929 0
Time warping -
10%
11.4711 0.0029 11.1957 0.0078 10.2965 0.0089 20.0535 0.0186
Echo addition 28.2335 0.0127 17.4780 0.0156 17.1564 0.0163 16.9394 0.0049
Equalization 28.2335 0.0029 19.1299 0 18.2978 0 19.1391 0

19
technique. The multiresolution characteristics of discrete wavelet transform (DWT)
and the energy-compression characteristics of discrete cosine transform (DCT) are
combined to improve the transparency of digital watermark [26]. By computing the
DCT of 3-level DWT coefficients we take advantage of low-middle frequency
components to embed the information.
To further improve the detection convergence and to make the system more
secure the idea of encoding the watermark using cyclic coding is proposed due to
this the attacker will not be able to understand the statistical behavior of the
embedded watermark and will also be able to correct the one bit error. The results
obtained for watermark robustness using cyclic encoder are better than the methods
not using any such encoder.
Fig 4 Improved encoder and decoder for blind watermarking using cyclic coding.
Table 5 results obtained for (6,4) cyclic codes
SNR BER Without attack 32.2044 0 Downsampled 32.2044 0 Upsampled 32.2044 0 Mp3compressed 32.2044 0 Requantization 32.2044 0 Cropping 30.2458 0.0110 Lpfiltered fc=22050 29.1862 0 Time scaling -10% 21.2377 0.0029 Echo addition 16.9391 0.0039 Equalization 21.0204 0
Recovered
Watermark
Host
Audio
Watermark encoder
Watermark
Encoding using
cyclic codes
Dimension
mapping Dimension
mapping
Watermark Decoder
Encoding using
cyclic codes

20
Table 6 results obtained for (7, 4) cyclic codes
It is clear from the table 5 and 6 that the encoder and decoder model proposed using
cyclic coding is more robust as compared to all other techniques proposed.
6. ADAPTIVE WATERMARKING BY GOS MODIFICATION Unlike conventional algorithms, which add modulated and scaled PN-
sequences or other disturbing patterns, no basic form of the watermark signal is set
in advance. Instead, segments of host audio signals are modified into the “1” or “0”
state based on the principle of differential amplitudes. Patchwork algorithms work in
a similar manner. The watermark disturbance is actually strongly related, or similar
to, the host signal itself. It is just like an echo signal with a zero time delay, thus
yielding a high degree of watermark transparency. Besides, the proposed embedding
process is performed subject to the frequency-masking test of watermark signals so
that disturbances of the host audio signal are beyond the ability of human ears to
perceive.
The proposed adaptive audio watermarking technique which modifies the
GOS in DWT domain and embeds and extracts the watermark is shown in fig.6 and
fig 7 respectively. First the complete audio signal is partitioned into consecutive
GOS each containing two non overlapping sections of equal/ unequal length. To
SNR BER Without attack 28.5381 0 downsampled 28.3982 0 upsampled 28.3982 0 Mp3compressed 28.3982 0 requantization 28.3982 0 cropping 22.3475 0.0094 Lpfiltered fc=22050 26.9378 0 Time scaling -10% 23.5560 0 Time scaling +10% 21.2156 0.0018 Echo addition 16.0376 0.0021 Equalization 20.8502 0

21
implement cryptographic method the length of sections can be kept unequal of size
L1, L2 selected randomly for each GOS based on cryptographic key. Hence a GOS
contains L = L1 + L2 samples. One watermark message represents one binary bit of
value 0 or 1, embedded in one GOS. To embed one watermark message the mean of
two sections of each GOS is considered as a feature space and is modified. To
embed the watermark bit 1 if A≤B then no operation is performed and if A>B then
decrease A and increase B by the amount δ so that the condition A≤B satisfies.
To embed the watermark bit 0 if A>B then no operation is performed and if
A<B then increase A and decrease B by the amount δ so that the condition A>B
satisfies.
Fig 6 Block schematic of GOS based watermark embedding in DWT domain.
Fig 7 Block schematic of GOS based watermark extraction in DWT domain.
The results are obtained by implementing the proposed scheme in
DWT/DWTDCT/DCT domains and are verified for the various Indian musical
Watermarked
signal
Input x DWT
transformation
Computation
of mean A &
B
Selection of
length L1 & L2Segmentation
Scaling
parameter K
WDimension
mapping
IDWT
transformation
Concatenation
of Segments
Watermark
insertion
Watermarked
signal DWT
transformation
Computation
of mean A′
Selection of
length L1 & L2Segmentation
Watermark bit
recovery
Recovered
watermark
w
Concatenation
and Dimension
22
signals like Tabla, Harmonium and Indian classical song. The watermarking scheme
that encodes the watermark using cyclic codes and embeds the watermark is also
proposed. It is observed that the SNR between the original watermark and the
recovered watermark is increased compare to the schemes implemented in previous
sections. The scaling parameter used to scale the host signal during the watermark
embedding is adaptive meaning that the parameter is different for each GOS
depending on the audible requirements of each GOS. It is observed that the DWT-
DCT domain is more suitable domain to embed the watermark as it gives us an
advantage of embedding in low-middle frequency regions. The watermark
embedded in low-middle frequency sustains all kind of signal processing attacks.
The comparison of proposed methods with various well known algorithms is
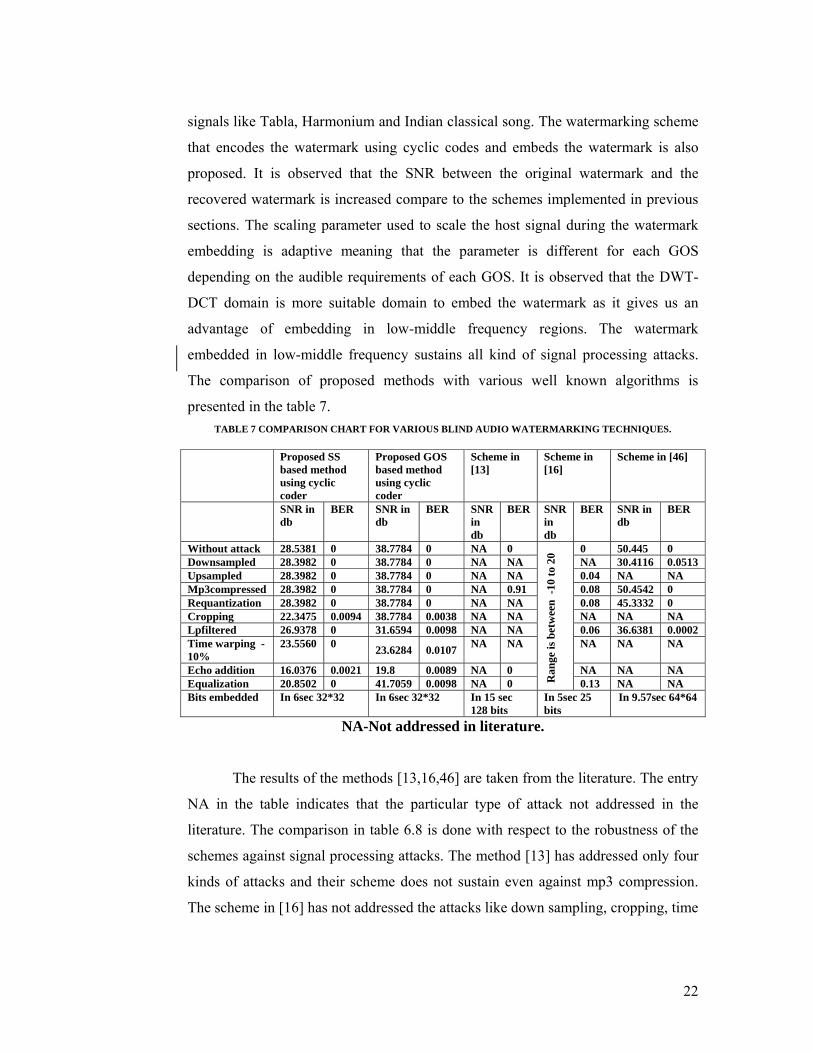
presented in the table 7. TABLE 7 COMPARISON CHART FOR VARIOUS BLIND AUDIO WATERMARKING TECHNIQUES.
NA-Not addressed in literature.
The results of the methods [13,16,46] are taken from the literature. The entry
NA in the table indicates that the particular type of attack not addressed in the
literature. The comparison in table 6.8 is done with respect to the robustness of the
schemes against signal processing attacks. The method [13] has addressed only four
kinds of attacks and their scheme does not sustain even against mp3 compression.
The scheme in [16] has not addressed the attacks like down sampling, cropping, time
Proposed SS based method using cyclic coder
Proposed GOS based method using cyclic coder
Scheme in [13]
Scheme in [16]
Scheme in [46]
SNR in db
BER SNR in db
BER SNR in db
BER SNR in db
BER SNR in db
BER
Without attack 28.5381 0 38.7784 0 NA 0 R
ange
is b
etw
een
-10
to 2
0 0 50.445 0
Downsampled 28.3982 0 38.7784 0 NA NA NA 30.4116 0.0513 Upsampled 28.3982 0 38.7784 0 NA NA 0.04 NA NA Mp3compressed 28.3982 0 38.7784 0 NA 0.91 0.08 50.4542 0 Requantization 28.3982 0 38.7784 0 NA NA 0.08 45.3332 0 Cropping 22.3475 0.0094 38.7784 0.0038 NA NA NA NA NA Lpfiltered 26.9378 0 31.6594 0.0098 NA NA 0.06 36.6381 0.0002 Time warping -10%
23.5560 0 23.6284 0.0107 NA NA NA NA NA
Echo addition 16.0376 0.0021 19.8 0.0089 NA 0 NA NA NA Equalization 20.8502 0 41.7059 0.0098 NA 0 0.13 NA NA Bits embedded In 6sec 32*32 In 6sec 32*32 In 15 sec
128 bits In 5sec 25 bits
In 9.57sec 64*64

23
scaling and echo addition attacks. The BER for this scheme in[16] for other attacks
is always greater than 0.04 and their scheme is not able to recover the watermark
with 0 BER for any of the attacks. The scheme in [46] has reported better SNR and
good BER but their scheme produces poor BER for the down sampling attack. They
have not addressed the major sensitive attacks like upsampling, cropping, time
scaling, echo addition and equalization. Though our proposed methods give less
SNR compare to scheme in [46], it is successful to sustain all kinds of attacks. Our
schemes are more robust compared to the other schemes; also we have taken care to
add the security to the implemented schemes.
7. INTELLIGENT ENCODER DECODER MODELING This section proposes the intelligent encoder decoder model of audio
watermarking based on the implementations of section 5 and section 6. The main
aim of the present work is to make the system robust to all kinds of attacks. In this
chapter we propose the intelligent model of encoding and decoding based on spread
spectrum method (method-1)/GOS modification method (Method-2). To make the
system intelligent we propose to add the following features.
1. Add synchronization patterns to indicate the start of the file from where the
watermark is embedded in the host signal
2. To improve the robustness of the system through diversity, add multiple
watermarks at different locations in a file using time diversity.
3. Encode the watermark to reduce the bit error rate and to improve the
robustness further.
4. Make the system secure by using SS technique/ by selection of unequal
length in GOS modification method.
24
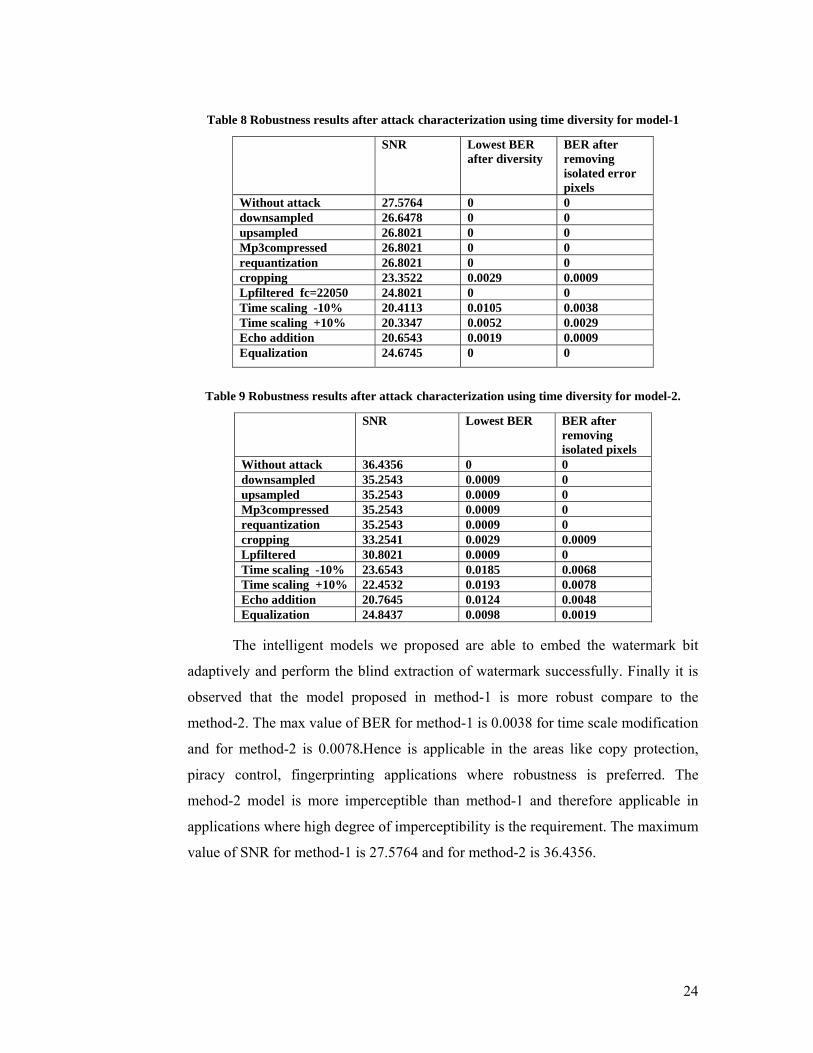
Table 8 Robustness results after attack characterization using time diversity for model-1
Table 9 Robustness results after attack characterization using time diversity for model-2.
The intelligent models we proposed are able to embed the watermark bit
adaptively and perform the blind extraction of watermark successfully. Finally it is
observed that the model proposed in method-1 is more robust compare to the
method-2. The max value of BER for method-1 is 0.0038 for time scale modification
and for method-2 is 0.0078.Hence is applicable in the areas like copy protection,
piracy control, fingerprinting applications where robustness is preferred. The
mehod-2 model is more imperceptible than method-1 and therefore applicable in
applications where high degree of imperceptibility is the requirement. The maximum
value of SNR for method-1 is 27.5764 and for method-2 is 36.4356.
SNR Lowest BER after diversity
BER after removing isolated error pixels
Without attack 27.5764 0 0 downsampled 26.6478 0 0 upsampled 26.8021 0 0 Mp3compressed 26.8021 0 0 requantization 26.8021 0 0 cropping 23.3522 0.0029 0.0009 Lpfiltered fc=22050 24.8021 0 0 Time scaling -10% 20.4113 0.0105 0.0038 Time scaling +10% 20.3347 0.0052 0.0029 Echo addition 20.6543 0.0019 0.0009 Equalization 24.6745 0 0
SNR Lowest BER BER after removing isolated pixels
Without attack 36.4356 0 0 downsampled 35.2543 0.0009 0upsampled 35.2543 0.0009 0 Mp3compressed 35.2543 0.0009 0 requantization 35.2543 0.0009 0 cropping 33.2541 0.0029 0.0009 Lpfiltered 30.8021 0.0009 0 Time scaling -10% 23.6543 0.0185 0.0068 Time scaling +10% 22.4532 0.0193 0.0078 Echo addition 20.7645 0.0124 0.0048 Equalization 24.8437 0.0098 0.0019

25
8. DISCUSSION AND CONCLUSION The main aim of the present work is the development of audio watermarking
algorithms, with the state-of-the-art performance. The algorithms performance is
validated in the presence of the standard watermarking attacks. The models we
propose are able to embed 1024 bits in 6.5 sec duration signal preserving the
imperceptibility of the signal. The results provided in chapter 5 and chapter 6
indicates that DWT-DCT domain is the more suitable domain to embed the
information. The SS based method is more robust than the method based on patch
work algorithm whereas the patchwork algorithm provides better imperceptibility.
The SS based algorithm obtained high detection robustness and increasing the
perceptual transparency of the watermarked signal. Time required to embed and
recover the watermark from SS based scheme is 21.131 sec. Time required to embed
and recover the watermark from GOS based scheme is 24.401 sec.
8.1. Main contribution of the present research
1. Audio watermarking scheme is proposed to embed an audio watermark in the
audio signal.
2. Adaptive blind watermarking algorithms based on SNR are developed using
Spread spectrum technique.
3. Spread spectrum based techniques are implemented in different transform
domains.
4. Cyclic coder and attack characterization by diversity is used to increase the
robustness of the scheme.
5. Synchronization pattern is added to track the watermark.
6. New intelligent encoder and decoder model is proposed for an audio
watermarking system using Spread Spectrum method.
7. Blind watermarking algorithms based on GOS modification are developed in
different transform domain.
8. Cyclic coder and attack characterization by diversity is employed to increases the
robustness.
9. Synchronization pattern is added to track the watermark.

26
10. New intelligent encoder and decoder model is proposed for an audio
watermarking system using GOS method.
Our contributions:
I) “DWT based Image Watermarking” at international conference ICWCN
2003 organized by S.S.N.C.O.E., Kalavakkam, Chennai during 27-28 June
2003.
II) “DWT based Audio Watermarking” at international conference ICWCN
2003 organized by S.S.N.C.O.E., Kalavakkam, Chennai during 27-28 June
2003.
III) “Audio Watermarking for covert communication” in 12th annual Symposium
on mobile computing and applications organized by IEEE Bangalore section
November 2004.
IV) “Insight on Audio Watermarking” at national conference NC2006 organized
by Padre Conceicao College of Engineering Verna – Goa during 14-15
September 2006
V) “Performance analysis of Audio Watermarking in Wavelet Domain” at
international conference RACE organized by Engineering College Bikaner
during 24-25 March 2007
VI) “SNR based audio watermarking in Wavelet domain” International
conference ICCR-08 April 2008 Mysore.
VII) “SNR based audio watermarking Scheme for blind detection” International
conference ICETET -08, July 2008 Nagpur, published by IEEE Computer
Digital Library.
VIII) “SNR based Spread Spectrum Watermarking using DWT and Lifting
Wavelet Transform” in International Journal IJCRYPT October 2008.
IX) “Adaptive Spread Spectrum Audio Watermarking for Indian Musical
Signals by Low Frequency Modification” in proc. IEEE international
conference ASID 2009 held in 22-25 August 2009 at Hongkong.
X) “Adaptive Spread spectrum audio watermarking” in ICFAI Journal on
Information technology, September 2009.

27
XI) “Adaptive Audio Watermarking for Indian Musical Signals by GOS
Modification” selected in IEEE International conference TECNCON 2009
held on 23-26 November 2009 at Singapore.
Selected Bibliography:
[1]. I. J. Cox and Matt L Miller, “ The first 50 years of electronic watermarking”,
Journal of applied signal processing, 2002, pp. 126-132.
[2]. I. J. Cox, J. Kilian, F. Thomson Leighton and T. Shamoon, “Secure Spread
Spectrum Watermarking for Multimedia”, IEEE Transactions on Image Processing,
Vol. 6, No. 12, December 1997, p.p. 1673-1686.
[3]. J. A. Bloom, I. J. Cox, T. Kalker, J. M. G. Linnartz and M. L. Miller, C. B. S.
Traw , “Copy protection for DVD Video” ,Proc. of the IEEE, Vol. 87, No. 7, July
1999.
[4]. C.T. Hsu, J.L. Wu., “Hidden Digital Watermarks in Images”, IEEE
Transactions on Image Processing, Vol. 8,No. 1, January 1999, p.p.58-68.
[5]. D. Kundur and D. Hazinakos, “Digital watermarking for telltale tamper
proofing and authentication”, Proc. IEEE No.7, July 1999, pp. 1167-1180.
[6]. D. Kundur and D. Hazinakos, “Diversity and Attack Characterization for
Improved Robust Watermarking”, IEEE Transactions on Signal Processing, Vol. 49,
No. 10, October 2001, p.p.2383-2396.
[7]. Ming Shing Hsish and Din Chang, “Hidding the digital watermarks using
Multiresolution wavelet transform”, IEEE Transactions on industrial electronics.
Vol. 48 No. 5. October 2001, pp. 875-891.
[8]. L. M. Marvel, C.G. Boncelet and C.T. Retter, “Spread Spectrum Image
steganography”, IEEE Transactions on Image Processing, Vol. 8. August 1999. p.p.
1075-1083.
[9]. C. S. Lu, S.K. Huang, C. J. Sze and H. Y. M. Liao, “Cocktail Watermarking for
Digital Image Protection”, IEEE Transaction on Multimedia, Vol. 2., No.4,
December 2000, p.p. 209-224.
[10]. D.Kundur, “Watermarking with Diversity: insights and Implications”, IEEE
Multimedia magazine , October-Decemer 2001, p.p 46-52.

28
[11]. A.P.Fabien and Petitcols, “Watermarking Schemes evaluation”, IEEE Signal
Processing Magazine, September 2000, p.p.58-64.
[12]. L.B. Boney ,A. Twefik and K. Hamdy, “Digital Watermarks for Audio
Signals”, IEEE Int. Conf. on Multimedia computing and Systems, June 1996, p.p.
473-480.
[13]. J. Seok, J. Hong and J. Kim, “A Novel Audio Watermarking Algorithm for
Copyright Protection of Digital Audio,” ETRI Journal, Volume 24, No. 3, June
2002, p.p. 181-189.
[14]. D.Kirovski and H.S.Malvar, “Spread spectrum watermarking of audio signals”
, IEEE Transactions on Signal Processing, Vol. 51, No. 4, April 2003 p.p. 1020-
1033.
[15]. H.S.Malvar and D.A.F. Florencio, “Improved Spread Spectrum: A New
Modulation Technique for Robust Watermarking”, IEEE Transactions on signal
Processing, Vol. 51, No. 4, April 2003, p.p. 898-905.
[16]. S. Esmaili, S. Krishnan and K. Raahemifar, “A Novel Spread Spectrum Audio
Watermarking Scheme Based on Time-Frequency Characteristics”, Proc. of CCECE
2003, p.p. 1963-1966.
[17]. D. Kirovaki and H. Malver, “Robust covert communication over a public audio
channel using spread spectrum”, available at site www.cs.ucla.edu/~darko/papers.
[18]. Hafiz Malik, Ashfaq Khokhar and Rashid Ansari, “Robust audio watermarking
using frequency selective spread spectrum theory” Proceeding of ICASSP 2004,
IEEE, p.p. V385- V388.
[19]. W. Bender, D. Gruhl, N. Morimoto and A. Lu, “Techniques for data hiding”,
IBM system Journal, 1996,Vol. 35, p.p. 313-336.
[20]. I.K. Yeo and H.J. Kim, “Modified patchwork algorithm: a novel audio
watermarking scheme”, Proc. ICITCC 2001, p.p. 237-242.
[21]. N. Cvejic and T. Seppanen, “Robust Audio watermarking in Wavelet Domain
Using Frequency Hopping and Patchwork method”, Proc. of 3rd International
Symposium on Image and Signal processing and Analysis 2003, p.p. 251-255.
[22]. R.Wang and Dawen Xu,Q. Li, “Multiple audio watermarks based on lifting
wavelet transform”, Proc. of 4th international conference on m/c learning and
cybernetics IEEE, August 2005,p.p. 1959-1964.

29
[23]. W. N. Lie and L. C. Chang, “Robust and High Quality Time-Domain Audio
Watermarking Based on Low Frequency Amplitude Modulation”, IEEE Transactions
on Multimedia, Vol.8., No.1., February 2006, p.p. 46-59.
[24]. P. Bassia and I. Pitas, “Robust audio watermarking in the time domain”, IEEE
Transactions on Multimedia,Vol. 3, No.2, June 2001 p.p.232-241.
[25]. A. N. Lemma, J. Aprea, W. Oomen and L. V. D. Kerkhof, “A Temporal
Domain Audio Watermarking Technique”, IEEE Transaction on Signal Processing,
Vol. 51, No. , April 2003, p.p. 1088-1097.
[26]. S. Wu., J. Huang, D. Huang and Y. Q. Shi, “Self-Synchronized Audio
Watermark in DWT Domain”, Proc. of ISCAS 2004, p se.p. V.712-V.715.
[27]. J. Huang, Y. Wang and Y. Q. Shi, “A blind audio watermarking algorithm with
self synchronization,” Proc. IEEE Int. Symp. On circuits and systems, vol. 3, 2002,
p.p.627-630
[28]. S. Wu., J. Huang, D. Huang and Y. Q. Shi, “Efficiently self synchronized Audio
watermarking for Assured Audio Data Transmission”, IEEE Transaction on
Broadcasting, Vol. 51, No1, March 2005, p.p. 69-76.
[29]. X. Li, M. Zhang and S.Sun, “Adaptive audio watermarking algorithm based on
SNR in wavelet domain”, Proc. of IEEE conference 2003 p.p.287-292.
[30]. A. Takahashi, R. Nishimura and Y. Suzuki, “Multiple Watermarks for Stereo
Audio Signals Using Phase-Modulation Techniques”, IEEE Transactions on Signal
Processing, Vol. 53, No. 2, February 2005, p.p. 806-815.
[31]. H. H. Tsai, J. S. Cheng and P. T. Yu, “Audio Watermarking Based on HAS and
Neural Networks in DCT Domain”, EURASIP Journal on Applied signal processing
2003, p.p. 252-263.
[32]. C.Xu, J. Wu, D.D. Feng, “Content based Digital Watermarking for
Compressed Audio”, Available on line at site
http://133.23.229.11/~ysuzuki/Proceedingsall/ .
[33]. X. Li and H.H. Yu., “Transparent and Robust Audio Data Hiding in Cepstrum
Domain”, Proc. IEEE International conference on Multimedia and Expo. New
York(I), 2000, P.P.397-400.

30
[34]. S. K. Lee and Y. S. Ho, “Digital Audio Watermarking in the Cepstrum
Domain”, IEEE Transaction on Consumer Electronics. Vol.46, No.3 August 2000,
p.p.744 -750.
[35]. N. Sriyingyong and K. Attakimongeol, “Wavelet based Audio watermarking
using adaptive Tabu search”, Proc. of IEEE Int. Symp. Wireless Pervacive
computing 2006 pp 1-5 available at
http://sutir.sut.ac.th:8080/sutir/bitstream/123456789/1821/1/BIB990_F.pdf.
[36]. Wang, Xu Dawen, Chen Jiner and Duchengtou, “Digital Audio Watermarking
algorithm based on Linear Predictive Coding in wavelet domain”, ICSP-04 Proc. of
IEEE, 2004, p.p. 2393-2396.
[37]. Chin-Su Ko, K.Kim, R.Hwang, Y. Kim and S.Rhee, “Robust Audio
Watermarking in wavelet domain using PN sequences”, Proc. of ICIS-2005
published by IEEE.
[38]. R.Vieru, R. Tahboub,C. Constantinescu and V. Lazarescu, “New results using
the audio watermarking based on wavelet transform”, International Symposium on
Signals, Circuits, and Systems, Kobe, Japan 2 (2005) published by IEEE 2005, p.p.
441-444.
[39]. R.Wang, Dawen Xu and L Qian, “Audio Watermarking based on wavelet
packet and Psychoacoustic model”, IEEE Proc. of PDCAT-2005.
[40]. Wang, Xu, Z. Hang and C. Youngrui, “2-D digital Audio Watermarking based
on Integer Wavelet Transform”, IEEE Proc. of ISCIT 2005, p.p. 877-880.
[41]. S.Ratansanya, S.Poomdaeng, S. Tachaphetpiboon and T. Amornraksa, “New
Psychoacoustic models for wavelet based Audio watermarking”, IEEE Proc. of
ISCIT 2005, p.p. 582-585.
[42]. S. D. Larbi, M. J. Saidane , “Audio Watermarking A Way to Stationnarize
Audio Signals”, IEEE Transactions on Signal Processing, Vol. 53, No. 2, February
2005 p.p. 816-823.
[43]. T. Furon and P. Duhamel, “An Asymmetric Audio Watermarking Method”,
IEEE Transactions on Signal Processing, Vol. 51, No. 4, April 2003 p.p. 981-995.
[44]. B. S. Ko, R. Nishimura and Y. Suzuki, “Time-spread Echo method for digital
audio watermarking”, IEEE Transaction on multimedia, Vol. 7, No.2, April 2005,
pp 212-221.

31
[45]. S. Eerüçük, S. Krishnan and M. Zeytinoğlu, “A Robust audio watermark
representation based on linear chirps”, IEEE Transaction on multimedia, Vol. 8,
No.5, October 2005, pp 925-936.
[46]. X. Wang, W. Qi and P. Niu, “A new Adaptive Digital Audio watermarking
based on support vector regression”, IEEE Transaction on audio , speech and
language processing, Vol. 15, No.8, November 2007, pp 2270-2277.
[47]. M.Mansour and A. Twefik, “Audio watermarking by time scale modification”,
in Proc. Int. conf. on Acoustics, speech and signal processing, May 2001, Vol. 3, pp
1353-1356.
[48]. M.Mansour and A. Twefik, “Data embedding in audio using time-scale
modification”, IEEE Transaction on speech audio Processing, Vol. 13 No.3 pp432-
440, 2005.e
[49]. Wei Li, X Xue and P. Lu , “Localized Audio watermarking technique Robust
against Time scale modification”, IEEE Transaction on multimedia, Vol. 8, No.1,
February 2006, pp 60-69.
[50]. S. Xiang and J. Huang, “Histogram-based audio watermarking against time-
scale modification and cropping attacks”, IEEE Transaction on multimedia, Vol. 9,
No.7, November 2007, pp1357-1372.
[51]. X. Y. Wang and H. Zhao, “A Novel Synchronization Invariant Audio
Watermarking Scheme based on DWT and DCT”, IEEE Transaction on signal
processing, Vol.54, No.12, December 2006, pp 4835-4839.
[52]. J. D. Gordy and L. T. Bruton, “Performance Evaluation of Digital Audio
Watermarking Algorithms”, Proc. of Midwest symposium on Circuits and Systems,
Vol. 1, August 2000, p.p. 456-459.
[53]. F. Bartolini, M. Barni and A Piva, “Performance Analysis of ST-DM
Watermarking in Presence of Non Additive Attacks”, IEEE Transactions on Signal
Processing, Vol. 52, No. 10, October 2004 p.p. 2965-2974.
[54]. F.A.P. Petitcolas and R. J. Anderson, “Evaluation of copyright marking
systems”, Proc. of IEEE Multimedia systems’ 99, Vol. 1, pp 574-579.
[55]. G.C. Roddriguez, M. N. Miyatake and H. M. P. Meana, “Analysis of Audio
Watermarking Schemes”, Proc. of ICEEE 2005, p.p. 17-20.

32
[56]. M. Wu, S. A. Craver, E. W. Felten and B. Liu, “Analysis of Attacks on SDMI
Audio Watermarks”, IEEE Int. Conf. on acoustics, speech and Signal Processing,
Vol. No.3, p.p. 1369-1372.
[57]. F. Hartung, J. K. Su and B. Girod, “Spread Spectrum Watermarking: Malicious
Attacks and Counterattacks”, Proc. SPIE, Vol. 3657 January 1999.
[58]. M. Kuttur, S. Voloshynovskiy and A. Herrigel, “ The Watermark Copy
Attack”, Proc. SPIE, Vol. 3971, security and watermarking of multimedia. 2000,
p.p.371-380.
[59]. Alexander Herrigel, Sviatoslav Voloshynovskiy and Yuriy Rystar, “The
watermark template attack.” Proc. SPIE, Vol 4314, 2001, p.p. 394-400.
[60]. J. K. Su., F. Hartung and B. Girod, “A Channel Model for a Watermark
Attack”, Proc. SPIE, Vol. 3657, January 1999, p.p. 159-170.
Signature of Research Guide Signature of Research Student
Dr. Mrs. S. D. Apte Mrs. Meenakshi Ravindra Patil
![Encoder-DecoderwithAtrous Separable Convolution for ...openaccess.thecvf.com/...Chieh_Chen_Encoder-Decoder... · encoder-decoder models [21,22] lend themselves to faster computation](https://static.fdocuments.in/doc/165x107/5e7440b302bb226df76bfe1c/encoder-decoderwithatrous-separable-convolution-for-encoder-decoder-models-2122.jpg)

















