
Ingenieria de Trafico en Redes MPLS - iie.fing.edu.uy · integrantes del grupo de trabajo son...
118
Ingeniería de Tráfico en Redes MPLS Proyecto Final de Carrera Integrantes: Adrián Delfino, Sebastián Rivero, Marcelo San Martín Tutor: Ing. Pablo Belzarena Instituto de Ingeniería Eléctrica Facultad de Ingeniería de la República
Transcript of Ingenieria de Trafico en Redes MPLS - iie.fing.edu.uy · integrantes del grupo de trabajo son...

Ingeniería de Tráfico en Redes MPLS
Proyecto Final de Carrera
Integrantes: Adrián Delfino, Sebastián Rivero, Marcelo San Martín Tutor: Ing. Pablo Belzarena
Instituto de Ingeniería Eléctrica Facultad de Ingeniería de la República

2
Prefacio
El presente documento constituye la documentación final del Proyecto de Fin de Carrera titulado “Ingeniería de Tráfico en Redes MPLS”, realizado para el Instituto de Ingeniería Eléctrica de la Facultad de Ingeniería, Universidad de la República. Los integrantes del grupo de trabajo son Sebastián Rivero, Adrián Delfino y Marcelo San Martín. Todos ellos, estudiantes de Ingeniería, opción Telecomunicaciones.
El proyecto en cuestión se llevo a cabo en el período comprendido entre Marzo de 2004 y Agosto de 2005, bajo la tutoría del Ing. Pablo Belzarena.
El objetivo del proyecto fue desarrollar una herramienta de software que permite al usuario realizar lo siguiente: diseñar la topología de la red a su gusto por medio de una interfaz gráfica, tanto de manera manual o cargándola de manera automática a la misma, disponer de diversos algoritmos para el establecimiento de LSPs (Label Switched Paths) (objetivo principal de éste proyecto) así como de herramientas de visualización del estado actual de la red. En cuanto a los métodos de búsqueda de caminos, se utilizó el establecimiento explícito del LSP por parte del usuario, CSPF (Constraint Shortest Path First), una versión modificada del algoritmo MIRA (Minumum Interference Routing Algorithm) y algoritmos usados en las llamadas Fair Networks que se explicarán más adelante.
El trabajo se divide en 4 partes. Primero se presenta el Objetivo del proyecto, la Motivación que llevo a su creación y una breve descripción de cómo está organizado el mismo. Luego se presentan los conceptos principales sobre TE (Traffic Engineering) de manera que el lector este familiarizado con los conceptos básicos en los que se basa éste proyecto. A continuación pasamos a una segunda parte donde exponemos las principales herramientas teóricas que tuvieron que ser estudiadas durante todo el desarrollo del proyecto para poder alcanzar los objetivos marcados. En la tercer parte se comenta de manera profunda los diferentes packages que conforman el software NET-TE (Networking Traffic Engineering), explicando con detenimiento como fueron implementados. Finalmente, en una última y cuarta parte se realizan las conclusiones del proyecto y plantean los posibles casos a futuro.
Con la presente documentación se adjunta un disco compacto conteniendo:
• El archivo instalador del software NET-TE.
• Un Manual del Usuario.
• Documentación completa del Proyecto.
• Documentación del código de software (JavaDoc).
Agradecimientos:
• A nuestro tutor, Pablo Belzarena

3
• A Paola Bermolen, por su amable ayuda en la compresión de los algoritmos de Fair Networks.
• Al grupo de proyecto del EasySim (Mauricio García, Gastón Madruga y Víctor Paladino) por brindarnos su proyecto como base para la interfaz gráfica del nuestro.

4
Índice General I Presentación del Problema 1. Introducción y objetivos ……………………………………… 8
1.1. Objetivos del proyecto ……………………………………… 8 1.2. Motivación ……………………………………… 9 1.3. Especificación funcional del proyecto ……………………… 12 1.4. Esquema organizacional del proyecto ……………………… 14
2. Casos de Uso ……………………………………………………… 16 Caso de Uso#1: Construcción de la topología ……………………… 16 Caso de Uso#2: Establecimiento de los LSPs ……………………… 18 Caso de Uso#3: Visualización del estado actual de la red ……… 25 3. Ingeniería de Tráfico ……………………………………………… 27
3.1. Introducción ……………………………………………… 27 3.2. Componentes de la Ingeniería de Tráfico ……………………… 28
II Principios y Bases teóricas 4. Constraint Shortest Path First (CSPF) ……………………… 32
4.1. Principios básicos de CBR ........………………………… 32 4.2. CSPF ……………………………………………………… 33 4.3. Ruteo basado en QoS. WSP y SWP ……………………… 34
5. Minimum Interference Routing Algorithm (MIRA) ……… 37
5.1. Presentación del algoritmo ……………………………… 37 5.2. Modelado del sistema ……………………………………… 38 5.3. Algoritmo propuesto ……………………………………… 38
6. Redes Justas (“Fair Networks”) ……………………………… 40
6.1. Introducción ……………………………………………… 40 6.1.1. Nociones de Justicia ……………………………………… 41
6.2. Algoritmo 1: Max-Min Fairness básico para caminos fijos ……… 41 6.2.1. Formulación completa del Algoritmo 1 ……………… 42 6.2.2. Pasos para resolver el Algoritmo 1 ……………………… 43 6.3. Algoritmo 2: Max-Min Fairness para caminos fijos con cotas …… 44 6.3.1. Formulación del Algoritmo 2 ……………………… 44
6.3.2. Pasos para resolver el Algoritmo 2 ……………………… 45 6.4. Algoritmo 3: Max-Min Fairness para múltiples caminos ……… 46
6.4.1. Pasos para resolver el Algoritmo 3 (usando NBT1) ……… 48 6.5. Algoritmo 4: Max-Min Fairness para múltiples caminos acotado ... 49

5
III Arquitectura de Software 7. Representación de la red e interacción con ARCA ……………… 52
7.1. El package topología ……………………………………… 52 7.2. La clase Elemento ……………………………………… 54 7.3. Las clases LER y LSR ……………………………………… 54 7.4. La clase Link ……………………………………………… 54 7.5. La clase LSP ……………………………………………… 54 7.6. El Package Arca.InterfazGráfica ……………………………… 54 7.6.1. Compatibilidad con ARCA – Analizador de Redes de Caminos
Virtuales ……………………………………………… 55 8. Interfaz Gráfica ……………………………………………… 57
8.1. El package Programa ……………………………………… 57 8.2. Clase Principal y VentanaConf ……………………………… 58 8.3. Clase Intérprete ……………………………………………… 59 8.4. Clases TxtFileFilter y ArcFileFilter ……………………… 60 8.5. Clase ConfLink ……………………………………………… 61 8.6. Clase Cargar topología ……………………………………… 62 8.7. Clases Estadísticas y Propiedades ……………………… 62 8.8. Clase Utilización ……………………………………………… 64
9. Carga automática de la topología …………………………………… 65 9.1. El package CargarRed – Implementación ……………………… 65 10. Computación de caminos ……………………………………… 70
10.1. El package CrearLSPs ……………………………………… 70 10.2. La clase Ruteo Explícito ……………………………………… 71 10.3. La clase CSPF ……………………………………………… 72 10.4. La clase Algoritmo ……………………………………… 75 10.5. La clase CarConf ……………………………………… 76 10.6. La clase MIRA ……………………………………………… 77
11. Algoritmos de justicia y el MIRA ……………………………… 78
11.1. El package MT ……………………………………………… 78 11.2. La clase Caminos ……………………………………… 79 11.3. La clase InterpreteMT ……………………………………… 79 11.4. La clase GeneroMT ……………………………………… 80 11.5. La clase FairnessNetwork ……………………………… 81 11.6. La clase LasDemandas ……………………………………… 83 11.7. La clase OfflineMira ……………………………………… 84

6
IV Conclusiones 12. Conclusiones y tareas a futuro ……………………………… 87 12.1. Supuestos y objetivos ……………………………………… 87 12.2. Conclusiones ……………………………………………… 88 12.3. Tareas a futuro ……………………………………………… 89 APÉNDICES
A. Multi Protocol Label Switching (MPLS) ……………… 91 A.1. Descripción funcional de MPLS ……………………… 91 A.2. Componentes y funcionamiento de una red ……………… 92 A.3. Método de distribución de etiquetas ……………… 94 B. Simple Network Management Protocol (SNMP) & Management Information Base (MIB) ……………………………………… 97 B.1. SNMP y Management Information Base ……………… 97 B.2. ASN.1 ……………………………………………… 98 B.3. SNMP v1 ……………………………………………… 100 B.3.1. Operaciones básicas ……………………………… 101 B.4. SNMP v2 ……………………………………………… 101 C. Ejemplo de Fairness con múltiples caminos ……………… 102 C.1. Ejemplo ……………………………………………… 102 D. Software ……………………………………………………… 107 D.1. Menú Archivo y Barra de Herramientas ……………………… 108 D.2. Crear Matriz de Tráfico ……………………………………… 110 D.3. Barra Vertical ……………………………………………… 110
Bibliografía ……………………………………………………… 116 Glosario de términos ……………………………………………… 117

7
Parte I
Presentación del Problema

8
Capítulo 1
Introducción y Objetivos
En este capítulo expondremos los objetivos, motivaciones y los distintos casos de uso de manera que se pueda entender en forma clara lo que hace el software y cuál es su utilidad. 1.1 Objetivos del proyecto El objetivo general de este proyecto es desarrollar una herramienta que permita analizar las distintas prestaciones que se pueden obtener al aplicar algoritmos de Ingeniería de Tráfico sobre una red de computadoras basadas en Multi Protocol Label Switching (MPLS). En general se pueden identificar cuatro diferentes objetivos a lo largo de todo este proyecto. El primer objetivo específico fue el formar una sólida base teórica sobre MPLS y TE (Traffic Engineering), entendiendo la razón de su existencia y su funcionamiento. El enfoque brindado se basará en el estudio de algoritmos de TE “offline” y “online”, orientados a brindar garantías de Calidad de Servicio (QoS), las cuales permitan asegurarle al cliente que obtendrá el grado de servicio esperado en términos del ancho de banda solicitado. Asimismo se estudiaron también métodos de optimización asociados al reparto “justo” de carga de las demandas de los clientes, lo que constituye las llamadas “fair networks”. Y por último, y también a destacar, se estudiaron los principales conceptos que abarcan las MIBs (Management Information Bases), con el objetivo en particular de determinar cómo descubrir los routers presentes en cierta red, que estén intercambiando información de ruteo mediante el protocolo OSPF. Un segundo objetivo, fue el desarrollo de la herramienta de software, llamada NET-TE (Networking Traffic Engineering), la cual en primera instancia le permitiera al usuario el poder ingresar manualmente la topología de la red en estudio, devolviéndole el programa por medio de una interfaz gráfica, el estado actual de la red. Se buscó también implementar un algoritmo para la computación de caminos (LSPs en nuestro caso), comúnmente usado en algoritmos de ruteo estilo Constraint Base Routing (CBR), el cual le ofrecerá también al usuario diferentes criterios de priorización al momento de elegir un camino. El algoritmo elegido fue el Constraint Shortest Path First (CSPF). Posteriormente, se puede señalar como tercer objetivo el agregar una funcionalidad al software que le permitiera al usuario el cargar la topología de la red en estudio en forma automática. Finalmente, como cuarto objetivo, se busco el darle la posibilidad al usuario de poder determinar, teniendo como dato de entrada la matriz de tráfico conteniendo todos los pares origen-destino con sus respectivos anchos de banda, cuál es la mejor manera de distribuir la carga de forma tal que la mayoría de las demandas se vean cubiertas de manera satisfactoria siguiendo diferentes pautas de “justicia” en el reparto de la carga.

9
La realización de este proyecto esta contenida en un marco más amplio de trabajo, que cuenta con el financiamiento del BID y del PDT, y que tiene por objeto la implementación de una red multi-servicio, utilizando infraestructura similar a la que soporta los servicios de datos ofrecidos por ANTEL (ANTELDATA), con el objetivo de probar aplicaciones/servicios que pueda ser implantados en el futuro con garantías de calidad de servicio. 1.2 Motivación El crecimiento actual de la Internet le da una oportunidad a los Internet Service Providers (ISPs) de ofrecer nuevos servicios como VoIP, Videoconferencia, etc., además de los ya tradicionales servicios de datos como email, ftp y web browsing. Todos estos nuevos servicios tienen grandes requerimientos en lo que a throughput, tasa de pérdida, delay y jitter se refiere. La Internet no fue diseñada para trabajar con este tipo de requerimientos, trabajando desde sus comienzos, bajo el paradigma “Best Effort” de IP. Esto significa que el usuario manda paquetes a la red y la red va a tratar de hacerlos llegar a destino sin garantía alguna. A pesar que protocolos como TCP han agregado mecanismos de reenvío que tratan de solucionar el problema de la pérdida de paquetes generado por el congestionamiento en la red, estos no solucionan las pérdidas en aplicaciones interactivas de tiempo real, donde no es posible esperar a que un paquete sea reenviado. Es por ello que la comunidad de Internet ha hecho grandes esfuerzos en los pasados años para poder ofrecer garantías de calidad de servicio (QoS) a Internet, con el objetivo de transformarla en una red convergente para todos los servicios de telecomunicaciones. Entre los primeros modelos podemos destacar el de Servicios Integrados (IntServ) y el de Servicios Diferenciados (DiffServ). Debido principalmente a problemas de escalabilidad en el primer caso y al no poder ofrecer las suficientes garantías de QoS en el segundo (el actual paradigma de ruteo IP de la Internet provoca la hiper-agregación de flujos en ciertas partes de la red y sub-utilización de recursos en otras), es que se necesita de la Ingeniería de Tráfico en las redes IP para asegurar QoS. Los ISPs necesitan así de sofisticadas herramientas de gestión de redes que apunten a un uso óptimo de los recursos de la red que son compartidos entre clases de servicios con diferentes requerimientos de QoS. La tecnología de Multi Protocol Label Switching (MPLS) es un buen ejemplo que ayuda a realizar TE en sistemas autónomos (AS) (ver Apéndice A por más información). Se basa en la idea de enviar paquetes a través de Label Switched Paths (LSPs) haciendo uso de etiquetas que son adjuntadas a los paquetes en los routers de ingreso de al red (puntos de interconexión entre la red MPLS y la red de acceso). Esas etiquetas son a su vez asignadas a los paquetes de acuerdo a su Forwarding Equivalence Class (FEC) (representación de un conjunto de paquetes que comparten los mismos requerimientos para su transporte) que son entonces mandados a través de uno de los LSPs asociado con esa FEC en particular. La práctica de TE hoy en día abarca el establecimiento y uso de esos LSPs como tuberías de determinado ancho de banda entre dos puntos. Dichos LSPs pueden ser seteados a través de varios routers, ya sea de forma manual por parte del usuario

10
eligiendo las rutas deseadas o por medio de una herramienta que los compute. Las rutas pueden ser computadas tanto offline usando alguna herramienta de software, o a través del uso de algún algoritmo de computación online basado en restricciones (CSPF). Como podemos ir viendo, la Ingeniería de Tráfico (TE) intenta optimizar la performance de las redes, a través de tres actividades integradas: medición del tráfico, modelado de la red, y selección de mecanismos para el control del tráfico. Desafortunadamente, grandes Proveedores de Servicios de Internet (ISPs) tienen pocos sistemas de software y herramientas que soporten la medición del tráfico y el modelado de la red, pilares básicos de una ingeniería de tráfico efectiva. De manera similar, preguntas sencillas sobre la topología, tráfico y ruteo son sorprendentemente difíciles de contestar en las redes IP de hoy en día. Una gran cantidad de trabajo ha sido dedicado al desarrollo de mecanismos y protocolos para el control del tráfico. Como ejemplo de ello, la mayor parte del trabajo de la Internet Engineering Task Force (IETF) está relacionado al control del tráfico en lo que a la ingeniería de tráfico concierne. Existen determinados factores que indican la necesidad de más y mejores herramientas de ingeniería de tráfico para las redes. Entre ellos se destacan la calidad del servicio, los parámetros ajustables interdependientes, el crecimiento de las redes y la variabilidad del tráfico (Referirse a [1] por más información). En cuanto a la Calidad del Servicio, los clientes son cada vez más exigentes en el cumplimiento de la performance, confiabilidad y seguridad, que se manifiestan en forma de Service Level Agreements (SLAs). Los clientes desarrollan más procedimientos de certificación y testeos continuos, para asegurar el cumplimiento de dichos SLAs. Aplicaciones como Voz sobre IP, las cuales por su naturaleza, requieren del transporte de datos de alta calidad, medido por el retardo, tasa de pérdida de paquetes y jitter, están emergiendo hoy en día. Por eso es muy importante para los operadores de redes el coordinar cuidadosamente por dónde fluye el tráfico de cada demanda y ver si pueden o no tolerar la llegada de futuras nuevas demandas sin afectar las ya existentes y por ende, viendo comprometido el cumplimiento de los SLAs pertinentes. En lo que a los Parámetros ajustables Interdependientes se refiere, hoy en día, los proveedores de equipos de red, proveen a los ISPs con poco o ningún control sobre los mecanismos básicos responsables de la coordinación de paquetes, gestión de buffers y selección de caminos. En su lugar, los proveedores de backbones son forzados a entender una larga cantidad de parámetros interrelacionados que de una manera u otra afectan la configuración y operación. Hasta el día de hoy, un ISP debe gestionar su red de backbone, y sus complicadas relaciones de frontera con proveedores vecinos, ajustando los asuntos mencionados anteriormente a través de una combinación de intuición, testeo y pruebas de intento y error. El Crecimiento de las Redes se ve reflejado en que por un lado, redes de backbones individuales están creciendo rápidamente en tamaño, velocidad y espectro abarcado; mientras que por otro lado, la industria intenta unir redes discordes entre sí, en redes integradas más grandes. Como resultado, las funciones de gestión de red que una vez pudieron ser manejadas por un grupo reducido de personas, basándose en la intuición y experimentación, deben ser ahora soportadas por herramientas efectivas de ingeniería de tráfico que unen información de configuración y de uso de una variedad de fuentes. Por último, la Variabilidad del Tráfico. El tráfico de Internet es complejo. La carga ofrecida entre pares origen-destino es típicamente desconocida. Asimismo, la

11
distribución del tráfico IP usualmente fluctúa ampliamente a través del tiempo. Esto introduce una gran complejidad a la ingeniería de tráfico sin alivianar las demandas de los clientes por una performance de comunicación predecible. Herramientas efectivas de TE deben soportar la identificación rápida de potenciales problemas de performance y un ambiente flexible para experimentar posibles soluciones. Es por los motivos expuestos anteriormente que se decidió la creación del software NET-TE, como un aporte más en cuanto a las herramientas que puede encontrar un usuario para poder realizar tests de ingeniería de tráfico en un ambiente simulado. La idea clave detrás de este software es la de ofrecer al usuario de una plataforma donde pueda visualizar la topología de su red de estudio conjuntamente con datos sobre el uso de los enlaces, qué enlaces se encuentran saturados, establecer afinidades que distingan el tráfico que pasa por cierto grupo de enlaces del resto. Una vez enfrente a la topología, el poder inferir sobre ella y visualizar las implicaciones de cambios locales en el tráfico y determinar por dónde se rutean las distintas demandas a medida que van llegando, de acuerdo al estado actual de la red. También el poder realizar una mirada general sobre todo el grupo de demandas que se tienen hasta el momento y determinar cuál es la mejor manera de ubicar los LSPs en la red de manera que todas vean sus requerimientos satisfechos. En el caso de no ser posible satisfacerlas a todas, es deseable el poder determinar cómo lograr cubrirlas de la manera “más justa” posible a todas ellas. Entendiendo por “justicia”, la elección por parte del usuario de determinado criterio en cuanto a la manera en que se debe tratar de repartir la carga entre las diferentes demandas (clientes). Usando esta herramienta, un proveedor de red pude claramente experimentar con cambios en la configuración de la red en un ambiente simulado, en vez en una red operacional, basándose en una plataforma para investigaciones del tipo “what-if” de ingeniería de tráfico.

12
Cálculo de Caminos Candidatos (Dijkstra)
Selección de Camino
Objetivos de Performance (restricciones)
Estado Actual de la Red
Cargar Matriz de Tráfico
Algoritmos MIRA o FairNetworks
Descripción de la Red
Visualización
usuario de la Red
Router más próximo
MIBs
LSP establecido
LSPs establecidos
1.3 Especificación Funcional del proyecto La herramienta de software desarrollada, se puede describir en rasgos generales por medio del diagrama de bloques mostrado en la Figura 1.1.
Figura 1.1: Diagrama de bloques del Proyecto A continuación pasamos a comentar brevemente cada uno de los bloques funcionales. Descripción de la Red: La función de este bloque es la de generar “un objeto Red”, el cual representará a la red sobre la cual el usuario trabajará. Se construirá manualmente por parte del usuario de la Red, ingresando datos como ser la lista de nodos y links con sus respectivos atributos, los LSPs ya existentes, etc. También se tendrá la opción de cargarla automáticamente extrayendo la información necesaria de las MIBs del router más próximo al cual esta conectada la estación de trabajo donde se encuentra instalado el software NET-TE.

13
Cálculo de caminos candidatos (Dijkstra): En este bloque el usuario podrá establecer restricciones que los futuros LSPs deberán cumplir, como ser el ancho de banda (BW) que deberán soportar y el pertenecer a una determinada Afinidad previamente establecida (P2P, UDP, etc.). Objetivos de Performance (restricciones): Acá el usuario podrá ingresar restricciones como el asegurarse que los caminos encontrados pasen por un determinado enlace y/o no lo hagan por otro, o el elegir el tipo y valor de los pesos que desea tengan los mismos, determinando así el criterio de optimización que establecerá la elección de caminos. Selección de camino: A partir del estado actual de la red y de los “candidatos”, se podrán establecer nuevos LSPs mediante la utilización de un algoritmo del tipo Shortest Path First (SPF) que tome además en consideración un conjunto de restricciones que deben ser cumplidas, teniendo como objetivo encontrar caminos de origen a destino que satisfagan esas restricciones impuestas por el usuario previamente, y de ser posible, optimizar la elección. El usuario también dispondrá de más de un criterio de TE para aplicar antes de mostrar cuál es/son las soluciones posibles encontradas, a manera de elegir la opción que más óptima le resulte. Cargar Matriz de Tráfico: Aquí se ingresara la matriz de tráfico conteniendo toda la lista de las demandas que hay sobre la red para los distintos clientes. Se especificarán todos los pares origen-destino así como el valor del ancho de banda requerido para cada una de esas demandas. Algoritmos MIRA o FairNetworks: Una vez ingresada la matriz de tráfico o cargada una ya creada previamente, se podrán aplicar diversos algoritmos de ruteo offline que mostrarán la manera de alojar a todas esas demandas en la red en forma conjunta e indicando cuánto se puede satisfacer a cada una de ellas. Estado Actual de la Red: Simplemente se refiere al estado en el que se encuentra la red en un determinado instante, con los LSPs ya establecidos en caso que los haya, qué enlaces están saturados,

14
y cuáles tienen sus recursos sobre o sub-utilizados. Se podrá apreciar el porcentaje de utilización de cada enlace también. Visualización: En este bloque se visualizan los nuevos LSPs establecidos, así como el estado actual de la red. 1.4 Esquema organizacional del proyecto El objetivo de esta sección es el mostrarle al lector las áreas teóricas analizadas y principales tareas que se realizaron durante todo el transcurso de este proyecto así como la manera en que está distribuida la información en el presente documento. En primer lugar, la tarea de este grupo de trabajo fue la de ponerse en contacto con los principales conceptos que encierra MPLS y la Ingeniería de Tráfico en Internet (TE). Para ello nos informamos sobre lo que motivo la aparición de MPLS, sus ventajas, cómo es el mecanismo de intercambio de etiquetas, entre otras cosas. Asimismo se estudió TE, su relación con MPLS, los objetivos que busca la ingeniería de tráfico así como también los pasos que debe seguir un Administrador para poder hacer una aprovechamiento eficiente de los recursos que ofrece la red en la que opera. Se estudiaron diversos algoritmos de ruteo que hacen ingeniería de tráfico tanto offline como online. También se vieron algoritmos de búsqueda de caminos, haciendo principal hincapié en el Constraint Shortest Path First (CSPF), analizando su uso junto con diferentes tipos de restricciones. Una vez conseguida la base teórica deseada, se empezó a desarrollar la herramienta de software. En una primera instancia, se buscó ofrecerle al usuario la posibilidad de que creara la topología de la red a su gusto, pudiendo agregar o quitar nodos y enlaces a su deseo y especificando el ancho de banda, peso y afinidad de los mismos; todo por medio de una interfaz gráfica. También se crearon herramientas mediante las cuales el usuario puede visualizar el estado actual de la red en todo momento. Algunos de los ejemplos de lo anterior son el observar el porcentaje de ocupación de los enlaces o la lista de los LSPs creados hasta el momento con sus respectivos anchos de banda. En cuanto a los mecanismos para el establecimiento de los LSPs, el primero en implementar fue el Ruteo Explícito, mediante el cual el usuario puede crear un LSP de manera manual, eligiendo los enlaces hasta llegar a formar el camino de origen a detino. El paso siguiente fue implementar un algoritmo de computación de caminos (usado en protocolos tipo CBR en su primera etapa de búsqueda de caminos). El elegido fue el Constaint Shortest Path First (CSPF). Si bien en un principio se implementó para que sólo desplegara la primera ruta que encontraba de origen a destino y que cumpliera además con las restricciones ingresadas por el usuario, luego esto se extendió para que mostrara todas las soluciones posibles (se despliegan todos los caminos con la distancia más corta del origen a fin, refiriéndonos por distancia al peso de los enlaces, los cuales representan diversas cosas de acuerdo a lo que el usuario desee) brindando así al usuario una mayor gama de posibilidades sobre la cual trabajar y una mayor flexibilidad en la búsqueda de las rutas posibles.

15
Posteriormente se agregaron más funciones, siempre con el objetivo de darle al usuario una mayor participación en la elección de los caminos y dándole al programa una mayor o menor participación en esa búsqueda. De ésta manera, cuantas más opciones tenga el usuario, podrá crear una mayor variedad de escenarios “what-if”. Claros ejemplos de la flexibilidad que se le intenta dar al usuario son los distintos tipos de pesos que le puede asignar a los enlaces al momento de usar el CSPF, dándole prioridad a la distancia o al ancho de banda disponible en los enlaces o a cierto peso administrativo que es fijado por el usuario. También se ofrecen distintos criterios de TE, que hacen una especie de filtrado sobre los resultados brindados por el algoritmo CSPF, ayudando también a incrementar las combinaciones de escenarios que se pueden crear. El siguiente paso fue el empezar a idear la manera de agregarle al programa la funcionalidad de poder cargar la topología de la red a la que está conectada la PC vía Simple Network Management (SNMP) de manera automática. Vale destacar que con cargar la topología de red se entiende como descubrir todos los routers presentes en cierta red que estén intercambiando información de ruteo mediante el protocolo OSPF. En nuestro caso la componente de gestión SNMP fue implementada en el software usando el API de Adventnet. Se tuvo que hacer nuevamente una fuerte investigación teórica, enfocándose esta vez en la estructura en forma de árbol usada por SNMP para organizar la gestión de datos; con esto nos estamos refiriendo a las llamadas Bases de gestión de Información (MIBs) (ver Apéndice B por más información). En la próxima etapa surgió la idea de agregar un nuevo algoritmo para el ruteo dinámico de los LSPs con ancho de banda garantido, en donde las demandas de ruteo van llegando una por una y no hay conocimiento previo acerca de futuras demandas. Este problema es motivado por la necesidad de los ISPs de desarrollar rápidamente servicios de ancho de banda garantidos y la consecuente necesidad en los backbones de redes de un aprovisionamiento rápido de caminos con ancho de banda garantido. El algoritmo elegido fue una pequeña variante del conocido algoritmo Minimun Interference Routing Algorithm (MIRA), el cual se basa en el principio de que cada nuevo túnel ruteado (LSP) debe seguir una ruta que no “interfiera demasiado” con una ruta que pueda ser posiblemente crítica para satisfacer una futura demanda. Previo a su elección se analizaron otros posibles algoritmos y luego de compararlos se decidió usar éste. Finalmente, en una última etapa, asumimos que el volumen de carga (BW) para cada demanda deja de ser una cantidad fija y pasa a ser una especie de demanda elástica. Así nos planteamos la siguiente pregunta: ¿cuál debería ser el principio que gobierne la distribución de los volumenes de esas demandas entre ciertos recursos de red (capacidad de los links) que llevan a asignaciones que cumplen con determinado criterio de justicia? Nos encontramos así con un nuevo tema abarcado por las llamadas “redes justas” (Fair Networks), del cual estudiamos sus aspectos más generales e incorporamos cuatro diferentes algoritmos, con el objetivo de determinar si el usuario podrá alojar en la red todas las demandas que fueron solicitadas, o en caso de no ser posible, cuál es la manera “más justa” de distribuirlas entre los recursos de la misma. Demos paso entonces, en los próximos capítulos, a introducir los conceptos principales que deberá poseer el lector sobre MPLS y TE.

16
Capítulo 2
Casos de Uso Veamos ahora cuáles son los usos y las distintas funcionalidades que el software NET-TE tiene para ofrecer. Se distinguen tres principales utilidades o casos de uso dentro de NET-TE: construcción de la topología de la red de trabajo, establecimiento de los LSPs por los cuáles pasará el tráfico de cada demanda y visualización del estado actual de la red. A su vez, han de destacarse los cuatro mecanismos usados por NET-TE para el establecimiento de los LSPs: ruteo explícito, CSPF, MIRA y FairNetworks. Explicaremos más adelante qué ventaja ofrece cada uno de ellos y los compararemos.
CCCaso de Uso# 111: Construcción de la topología Para empezar a trabajar, lo primero que necesita hacer el usuario es construirse la topología de la red sobre la cual va a trabajar. NET-TE ofrece dos maneras de realizar esto: una manual y otra automática. La interfaz gráfica donde se apoya NET-TE está formada por dos barras de herramientas, desde las cuales el usuario puede acceder a las distintas funciones del software y una pantalla que es el marco de trabajo donde se crea o carga la topología de la red. Empecemos por el método manual de construcción. En este caso, el usuario dispone de dos posibles objetos para crear su topología: routers y links. Como la red donde se trabaja es basada en MPLS, los routers que se ofrecen son de dos tipos: LERs y LSRs. NET-TE permite manipular los objetos dentro de la pantalla con total libertad, pudiéndolos colocar y desplazándolos de un lugar a otro a gusto del usuario, de manera que éste pueda diseñar la red con la forma que desee y pudiéndola guardar luego en un archivo en su computadora, en caso de querer reutilizarla luego, si así lo desease.
Esto resulta muy cómodo ya que el usuario puede cargar una vieja topología que tenia guardada, y cambiarla a su gusto, para reflejar el estado más reciente de la misma, agregando o quitando enlaces o routers de la red. Los campos que ofrece NET-TE para configurar los enlaces son los siguientes: ancho de banda, peso administrativo y afinidad. Como se puede apreciar en la Figura 2.1, el usuario puede describir con bastantes detalles las características de los elementos de la red. La opción del uso de pesos administrativos es especialmente útil en los casos en los que el usuario desea darle más prioridad a ciertos enlaces sobre otros. Son varios los motivos que pueden llevar a un usuario el querer priorizar cierto grupo de enlaces sobre otros. Como ejemplo, podemos mencionar razones de política interna por parte del cliente que regulen el uso de los recursos sobre cierto enlace o grupo de enlaces. También pueden existir tráficos que satisfacen demandas que son críticas o de mayor importancia,

17
con lo cual resultaría particularmente útil el evitar que futuros LSPs a ser establecidos pasen por los enlaces que las conforman, a menos que sea necesario. Otra característica de suma utilidad es poder
Figura 2.1: Pantalla principal de NET-TE y ventana de configuración de enlace.
seleccionar una Afinidad determinada para ciertos grupos de enlaces. NET-TE le da al usuario la posibilidad de crear como grupos de enlaces que se diferencien unos a otros de acuerdo al tipo de tráfico que pasa a través de ellos. Es muy común en una red el tener distintos tipos de tráfico circulando por la misma (P2P, TCP, UDP, Low Delay, etc.) y es deseable quizás para un usuario el establecer LSPs sólo sobre los enlaces que dejan pasar determinado tráfico por ellos. El concepto de Afinidad brindado por NET-TE permite éste tipo de cosas. Basta con hacer un simple click en el enlace deseado y el usuario será capaz de visualizar las propiedades de cada enlace y router, así como apreciar cuáles LSPs pasan por ellos. De la misma manera y con la misma facilidad, el usuario será capaz de modificar los parámetros de los enlaces nombrados anteriormente, para poder reflejar así cualquier cambio que haya ocurrido en la topología. En todo momento, si el usuario realizó algún cambio el cual quisiera deshacer, o viceversa, NET-TE le ofrece esa posibilidad por medio del uso de dos flechas de poder ir hacia adelante como hacia atrás en cambios ocurridos en la topología. Ver Figura 2.2.
Figura 2.2: Botones para deshacer o rehacer cambios.

18
Pero supongamos que el usuario no tiene conocimiento sobre cómo es la topología de la red a la cual esta conectado, y sin embargo quiere poder obtenerla para poder así crear distintos escenarios sobre la misma. Obviamente la solución manual no es la adecuada. Es por ello que NET-TE ofrece también un mecanismo automático, mediante el cual, tras ingresar determinados parámetros obligatorios tal como la Figura 2.3 nos muestra, comienza a iterar hasta descubrir completamente la red. Vale destacar que para NET-TE, el cargar la topología se entiende como descubrir todos los routers presentes en la red, que estén intercambiando información de ruteo mediante el protocolo OSPF.
Dentro de los parámetros obligatorios se encuentra la dirección IP de algún router de la red (en general es la del router a la que la computadora está directamente conectada), la versión SNMP que se desea ejecutar (NET-TE ofrece las versiones 1 y 2) y el “community” o password usado por SNMP para permitir sólo el acceso al router a personas con permiso. También se ofrecen parámetros opcionales, que el usuario es libre de modificar, como el puerto (NET-TE usa el 161 por defecto), número de reintentos y timeout. Además se tiene la posibilidad de seleccionar la opción de “Continuar carga de red”, útil cuando llegamos a un área de la red la cual tiene un community distinto, el cual poseemos y queremos ingresar al programa para que continúe su descubrimiento de la red.
Figura 2.3: Ventana Cargar Red. Obviamente, esto es sumamente útil si la red es una red de gran tamaño, ya que consumiría mucho tiempo el crearla manualmente. De esta manera se obtiene el mismo resultado, pero de una manera mucho más rápida. Una vez cargada la topología en forma automática, el usuario vuelve a ser libre de poder modificarla a su gusto, tal como lo hace si la cargara manualmente.
CCCaso de Uso# 222: Establecimiento de los LSPs En MPLS, como todos ya sabemos, el tráfico para determinada demanda sigue determinados LSPs desde que entra a la red MPLS hasta que sale. Es de esa manera que se puede clasificar los servicios según la QoS que desee cada usuario. Por eso, es tan importante el establecimiento de los LSPs, cómo elegirlos y dónde ubicarlos de manera de cubrir de la mejor manera posible las demandas. NET-TE tiene por ende cuatro distintos mecanismos para ofrecer al usuario, al momento de elegir cómo y por dónde ubicar a los LSPs.

19
RRuutteeoo EExxppllíícciittoo:: El primer mecanismo es el más sencillo de los propuestos (en lo que a cálculos se refiere): el ruteo explícito. Se le ofrece al usuario una ventana (ver Figura 2.4) en la cual, a partir de la elección del nodo de origen, se le van desplegando los posibles enlaces para que pueda ir creando salto a salto, el LSP de manera explícita de origen a fin. En NET-TE, la demanda se expresa en términos del ancho de banda. Es decir, cada demanda se representa por medio del nodo origen, destino y un determinado ancho de banda que satisfacer. El usuario debe por ello ingresar también en primer lugar el ancho de banda que desea tenga el LSP a crear. NET-TE entonces va chequeando el ancho de banda disponible de los enlaces que contienen el nodo en el que esta parado el usuario y despliega sólo aquellos que cumplan con la condición de tener un BW mayor o igual al requerido por el LSP.
Esta es una manera que como vemos no utiliza algoritmo alguno, sino que sólo se basa en la decisión que tome el usuario y depende exclusivamente del camino que éste desee. Un ejemplo de una situación de este tipo es cuando el usuario, ya sea o porque la red tiene suficiente ancho de banda como para no restringir ningún posible LSP o porque posee un conocimiento muy
Figura 2.4: Ventana para el Ruteo Explícito. grande de la red, cree saber ya de entrada por que camino es mejor que vaya el LSP. Quizás haya un acuerdo con el cliente, el cual obligue al LSP a seguir cierto camino explícito de manera obligatoria, con lo cual ésta sería la manera más sencilla de establecerlo. CCSSPPFF:: El segundo mecanismo ofrecido es el CSPF. Supongamos el caso donde el usuario tiene una red sobre la cual ya existen determinadas demandas siendo ruteadas por ciertos LSPs. Supongamos también que hay más de un tipo de tráfico circulando por la red y que eso está siendo reflejado por las afinidades creadas por el usuario. Aparece entonces un nuevo cliente queriendo conseguir un LSP por el cual rutear su tráfico y

20
requiere que le aseguren determinado BW. Entonces, salvo que sea una red de tamaño pequeño y sea muy evidente el camino a usar, el usuario necesitará de algún algoritmo que le halle ese LSP que está buscando, teniendo en cuenta el estado actual de la red. NET-TE le muestra al usuario cuales son todos los posibles caminos por los cuales puede rutear su tráfico, asegurándose que cumplan con el BW solicitado por el cliente, además de un conjunto pre-definido de restricciones que puede él mismo ingresar y comentaremos más adelante. Finalmente, será decisión del usuario el elegir el camino que más le convenga, dentro de toda la gama de soluciones. Dentro de los parámetros obligatorios a ingresar (ver Figura 2.5) por parte del usuario, se encuentran obviamente, el nodo de origen, el nodo destino y el BW requerido por el cliente. En caso que se desee buscar soluciones sólo por aquellos enlaces que soportan cierto tipo de tráfico se incorporó al NET-TE la posibilidad de elegir la Afinidad, como parámetro opcional. Puede suceder que por razones político-administrativas de parte del cliente, o por determinado SLA que debe cumplirse, el usuario necesite que los caminos posibles pasen por un determinado enlace en particular y no lo hagan por otro, por ejemplo. A manera de tener en cuenta este tipo de solicitudes, se incorporaron también otros dos parámetros opcionales a elegir, que son: Enlace Presente y Enlace Ausente. NET-TE se encarga de esta manera de asegurar al cliente que las soluciones a mostrar (en el caso que existan) cumplirán con estas restricciones. Ahora bien, ya que el CSPF se basa en el algoritmo Dijkstra, se debe determinar cuál es la métrica a usar para elegir el camino “más corto” (con más corto, nos referimos no al camino de menos saltos, sino al camino cuya suma de pesos es la menor). Acá, NET-TE ofrece 4 diferentes tipos de pesos a asignar a los enlaces: Ruteo Mínimo por Pesos Administrativos, Ruteo por Mínima Cantidad de Saltos, 1/(BWreservado) y 1/(BWlibre). El primero de todos es básicamente basarse en los pesos que fueron pre-definidos por el usuario para cada enlace. El usuario, al tener la posibilidad de asignar pesos a los enlaces, puede influir en la toma de decisión de cuál es el mejor camino por donde establecer el LSP. El segundo, es simplemente establecer la cantidad de saltos, como la métrica elegida. NET-TE se fijará solamente en la cantidad de saltos del origen al destino y buscará los caminos que tengan la menor cantidad de saltos de principio a fin. La tercera, tal como lo indica su nombre, usa pesos que equivalen al inverso del BWreservado en cada enlace. Supongamos que el cliente, tiene ya varios LSPs establecidos sobre la red, los cuales consumen determinado BW de los enlaces por los que pasan. Esto hace que hayan enlaces más ocupados y otros más libres en la red. Llega un nuevo LSP que necesita ser ubicado en la red y el usuario quiere que éste tienda a usar los enlaces más ocupados en la red, de manera tal de dejar a los que están más libres, disponibles para futuras demandas. Es una manera de procurar seguir usando los enlaces que ya están siendo más utilizados por otros LSPs, y no tocar los que están más libres. NET-TE brinda esta posibilidad, con tan sólo seleccionar este tipo de peso. Finalmente, supongamos que el usuario quiere exactamente lo opuesto a lo anterior. Es decir, quiere que el nuevo LSP a crearse tienda a pasar por aquellos enlaces que están más libres en la red, no tocando aquellos que ya tienen recursos consumidos o LSPs pasando por ellos. O sea, dicho con otras palabras, que se tienda a ubicar al LSP por

21
aquellas zonas de la red que no han sido usadas aún, de manera de no sobrecargar aquellas que sí lo están siendo. Esto es lo que NET-TE permite si el usuario elige la cuarta opción de peso. Se puede ver que NET-TE ofrece una amplia gama de criterios de pesos, de manera que el usuario pueda elegir cuál desea sea usado por el algoritmo para el cálculo de la nueva ruta, pudiendo jugar así con las distintas combinaciones y viendo cómo afecta una u otra elección. Vale decir que estos son parámetros obligatorios que debe ingresar el usuario. Por último, NET-TE le ofrece al usuario, como última opción, la posibilidad de usar o no determinado criterio de TE, sobre los caminos encontrados: Elegir manualmente, No saturación enlaces críticos y Minhop. Supongamos que luego de que el usuario haya ingresado todos los parámetros anteriores, NET-TE encuentra más de un camino que satisfaga los requerimientos de BW, Afinidad y demás. Y supongamos ahora que el usuario no quiere ver uno a uno cada uno de ésos caminos, analizando sus diferencias, sino que por otro lado, desea aplicarle una especie de “filtro” y que sólo se desplieguen aquellas soluciones que no contienen a los enlaces más críticos, o por aquellas que, dentro del grupo de soluciones posibles, tengan la menor cantidad de saltos. Es por lo anterior que se incorporaron tres criterios de TE al software. El primer criterio, simplemente le indica a NET-TE que despliegue todas las soluciones posibles que encontró Dijkstra, tomando en cuenta las restricciones y pesos seleccionados. De esta manera el usuario ve todas las soluciones y él es quien determina con cuál quedarse.
Figura 2.5: Ventanas de CSPF y de información sobre resultados hallados.

22
Con el segundo criterio, NET-TE lo que hace es comparar las soluciones encontradas y se queda sólo con aquella cuyos enlaces que la componen, tiene el mayor ancho de banda disponible. De esta manera, no sólo se muestra el camino que cumple con las restricciones y que según la métrica elegida es el más “corto”, sino que se muestra aquel que “molesta” menos a los enlaces más saturados. Finalmente, el último criterio de TE es el de Minhop, el cual, tal como su nombre lo indica, de todas las soluciones encontradas, se queda sólo con aquellas que tienen la menor cantidad de saltos de origen a destino. Esto es especialmente útil si se combina con ciertos tipos de pesos, pudiendo encontrar por ejemplo, no sólo las posibles soluciones que van por la parte más o menos ocupada de la red, sino también, por la más corta. Vale destacar que otra práctica funcionalidad que el NET-TE ofrece al elegir el segundo o tercer criterio de TE, es una ventana que despliega, en caso de existir múltiples soluciones, valores como la Capacidad, BW usado y Porcentaje de Utilización de los enlaces que las conforman. Se distinguen las soluciones ofrecidas de aquellas que fueron descartadas. Esto es muy útil para poder visualizar numéricamente la razón de la decisión tomada por NET-TE. MMIIRRAA:: Ya habiendo visto los criterios de Ruteo Explícito y CSPF, pasemos ahora al mecanismo conocido como MIRA (Minimum Interefence Routing Algorithm), para el establecimiento de los LSPs. El usuario por ejemplo se puede encontrar en la situación de querer establecer varios caminos de acceso a Internet para clientes a los que no se les garantiza ningún tipo de calidad de servicio (tráfico Best Effort). Pero a la vez querer establecer caminos con altos requerimientos de calidad de servicio para ofrecer por ejemplo servicios corporativos de voz y video. Con los algoritmos clásicos como el SPF, los caminos se mapearán indistintamente por el camino más corto degradando el servicio de los clientes corporativos ya establecidos e interfiriendo con futuras demandas (nuevos clientes). La solución ideal en este caso sería correr un algoritmo que tenga como entrada los puntos (localidades, nodos, etc.) que el usuario considera críticos y mapear los caminos de Internet por enlaces que no sean críticos para las demandas que se les quiere dar prioridad. Con NET-TE, el usuario podrá cargar todas las demandas que corresponden a caminos de acceso a Internet y mapearlas en la red corriendo el algoritmo MIRA. Así, se

23
mapearán todos los caminos de acceso a Internet por los caminos más largos, o hasta que no exista otra posibilidad (sature por ejemplo algún enlace). Luego el usuario podrá por ejemplo correr CSPF para establecer los caminos de
servicios corporativos.
Figura 2.6: Ventana del algoritmo MIRA. La idea básica de este tipo de algoritmos es la de minimizar la interferencia que provoca el establecimiento de un nuevo LSP a potenciales nuevos LSPs que son desconocidos de modo de reservar recursos para demandas a las que considero más importantes. Se puede apreciar la ventana de dicho algoritmo en la Figura 2.6. FFaaiirrnneessss:: Así llegamos al último mecanismo ofrecido por NET-TE, Fairness. Supongamos ahora que el usuario ya no tiene que preocuparse por ver cómo colocar determinado LSP para cada demanda nueva entrante. Ahora, lo que desea es, teniendo una matriz de tráfico que contiene a todas las demandas que desean establecerse sobre la red (la cual ya puede contener viejos LSPs establecidos), ver cómo satisfacerlas a todas ellas de una manera lo más “justa” posible. El usuario posee la lista de todas las demandas correspondientes a cada uno de sus clientes, especificadas por sus pares origen-destino y BW mínimo requerido por cada una de ellas. La pregunta que le podría resultar interesante de hacerse sería: ¿Cuántos recursos me puede ofrecer la red en su estado actual, para cada uno de los caminos que satisfacen las demandas de los clientes? Esos caminos solución son los hayados por el algoritmo CSPF. El usuario dispone de dos tipos de pesos a elección: minhop o pesos administrativos. Una vez hayados todos los caminos posibles que cumplen con la restricción del ancho de banda para todas las demandas, el objetivo es ver cómo se asignan los recursos de la red, a cada una de ellas, de manera que se obtenga el máximo aprovechamiento posible de la red. Una aplicación puede ser cuando se tiene determinada red utilizada para brindar servicios exclusivamente a un determinado número de clientes. Se quiere entonces

24
“arrojar” sobre ella los LSPs que van a cubrir cada una de esas demandas y darles a ellos la máxima cantidad de recursos que la red me puede brindar, de manera que se haga un uso de ellos “justo” entre las demandas. NET-TE brinda la información anterior al usuario, y le da a elegir cuatro algoritmos a usar distintos: fairness básico, acotado, con múltiples caminos y con múltiples caminos acotado. Observar la Figura 2.7.
El primero y el tercero brindan información sobre cuál es la cantidad máxima de BW que puedo tomar de la red para cada una de las demandas. La única diferencia es que el primer algoritmo sólo me considera un camino solución fijo para cada demanda, mientras que el tercero toma todos los caminos solución posibles. Para el caso en que hayan múltiples caminos posibles en el primero, se le brinda la posibilidad al usuario de elegir el que guste de entre una lista de posibles opciones, de manera tal que se quede con uno solamente, tal como debe ser. El segundo considera también sólo un camino solución fijo por demanda (tal
Figura 2.7: Ventana de algoritmos Fairness como en el primero, el usuario puede elegir el que desee en caso de haber más de una opción disponible), pero le brinda al usuario la opción de ingresar prioridades a las demandas y le permite elegir una cota inferior de BW para cada demanda. Si bien el concepto de incorporar prioridades parece oponerse al de ofrecer un reparto de ancho de banda justo entre las demandas, es útil para aquellos casos en donde deseamos poder diferenciar a los clientes desde un punto de vista económico, priorizando a aquellos que por ejemplo pagan más de los que pagan menos. También es útil cuando el usuario debe asegurarse que las demandas lleguen a obtener al menos un BW mínimo obligatorio en el reparto. Como ejemplo, supongamos que tiene una demanda que requiere 10MB. Como sabe que quizás el LSP que se cree para esa demanda, tenga que compartir recursos con otros LSPs de otras demandas, puede suceder que no llegue a obtener esos 10MB. Lo que puede hacer es poner un mínimo de 5MB por ejemplo y de esa manera se asegura que de haber solución, el BW que va a obtener va a estar entre esos dos valores con seguridad. El cuarto algoritmo es similar al tercero. La diferencia es que en vez de detenerse el cálculo cuando ya no quedan más recursos que la red pueda ofrecer, se detiene cuando se llegó a cumplir con el ancho de banda requerido para cada demanda. Obviamente que en caso de saturar primero la red antes que se llegue al ancho de banda requerido, también se detendrá el cálculo.

25
Éste es particularmente útil para un usuario cuando no desea ver cuál es la cantidad máxima de recursos que le puede ofrecer la red para satisfacer sus demandas, sino saber si puede llegar a cumplirlas, deteniéndose una vez que fueron satisfechas. Para la mejor visualización del usuario, aquellas demandas que no lograron satisfacer el BWrequerido, se pintarán de color rojo, a diferencia de aquellas que si lo lograron satisfacer o superar. Asimismo, para el tercer y cuarto algoritmo, se tiene la posibilidad de apreciar cada una de las sub-demandas o caminos que conforman las demandas principales en forma separada, pudiendo ver cuánto ancho de banda rutean cada una de ellas, así como apreciarlas en forma gráfica. Asimismo, se dispondrá también de una ventana que despliega los resultados obtenidos en forma numérica para todas las demandas, teniendo el usuario de ésta manera, otra forma sencilla de visualizar cuántas demandas satisfacen y cuántas no, el ancho de banda requerido. CCCaso de Uso# 3: Visualización del estado actual de la red El último caso de uso consiste en los métodos que tiene el usuario con el software NET-TE de poder ver el estado de la red. Básicamente lo puede hacer de dos formas posibles: por medio del uso del botón Estadísticas o bien del botón Utilización. Con tan sólo apretar el botón Estadísticas (ver Figura 2.8), en cualquier momento, al usuario se le desplegará una pantalla donde figurarán todos los nodos que conforman la red, los enlaces, así como los LSPs establecidos hasta ahora. Podrá ver las características de cada uno de ellos, así como también por cuál o tal nodo o enlace pasa cierto LSP, entre otros valores. Si así lo desea, se le brinda la posibilidad de visualizar al mismo tiempo todos los enlaces de la red, y ver el porcentaje de utilización de cada uno de ellos. Debido a la manera en que esta desplegada la información, resulta muy práctico a la vista el comparar unos con otros.
Al usuario también le podría interesar el poder clasificar a los enlaces de la red, de acuerdo al porcentaje de utilización que tienen y visualizar esa clasificación de una manera rápida y sencilla en pantalla. NET-TE permite realizar eso por medio de la herramienta Utilización (ver Figura 2.9).
Figura 2.8: Ventana Estadísticas.

26
Basta tan sólo ingresar dos valores de porcentajes, una cota inferior y otra superior, y NET-TE pintará de colores distintos cada uno de los tres niveles de utilización para cada enlace. Esta es una manera sencilla de visualizar en pantalla qué zonas de la red están más saturadas que otras. Es en especial práctico para redes de gran tamaño, donde ver valores numéricos no sea tan intuitivo como esto.
Figura 2.9: Ventana Utilización.
En caso de no ingresarse ningún número, se asignan dos valores por defecto.

27
Capítulo 3
Ingeniería de Tráfico (TE) 3.1 Introducción La Ingeniería de Tráfico (TE) es una disciplina que procura la optimización de la performance de las redes operativas. La Ingeniería de Tráfico abarca la aplicación de la tecnología y los principios científicos a la medición, caracterización, modelado, y control del tráfico que circula por la red. Las mejoras del rendimiento de una red operacional, en cuanto a tráfico y modo de utilización de recursos, son los principales objetivos de la Ingeniería de Tráfico. Esto se consigue enfocándose a los requerimientos del rendimiento orientado al tráfico, mientras se utilizan los recursos de la red de una manera fiable y económica. Una ventaja práctica de la aplicación sistemática de los conceptos de Ingeniería de Tráfico a las redes operacionales es que ayuda a identificar y estructurar las metas y prioridades en términos de mejora de la calidad de servicio dado a los usuarios finales de los servicios de la red. También la aplicación de los conceptos de Ingeniería de Tráfico ayuda en la medición y análisis del cumplimiento de éstas metas. La ingeniería de tráfico se subdivide en dos ramas principalmente diferenciadas por sus objetivos: Orientada a tráfico: ésta rama tiene como prioridad la mejora de los indicadores relativos al transporte de datos, como por ejemplo: minimizar la pérdida de paquetes, minimizar el retardo, maximizar el throughput, obtener distintos niveles de acuerdo para brindar calidad de servicio, etc. Orientada a recursos: ésta rama se plantea como objetivo, la optimización de la utilización de los recursos de la red, de manera que, no se saturen partes de la red mientras otras permanecen subutilizadas, tomando principalmente el ancho de banda como recurso a optimizar. Ambas ramas convergen en un objetivo global, que es minimizar la congestión. Un reto fundamental en la operación de una red, especialmente en redes IP públicas a gran escala, es incrementar la eficiencia de la utilización del recurso mientras se minimiza la posibilidad de congestión. Los paquetes luchan por el uso de los recursos de la red cuando se transportan a través de la red. Un recurso de red se considera que está congestionado si la velocidad de entrada de paquetes excede la capacidad de salida del recurso en un intervalo de tiempo. La congestión puede hacer que algunos de los paquetes de entrada sean retardados e incluso descartados. La congestión aumenta los retardos de tránsito, las variaciones del retardo, la pérdida de paquetes, y reduce la previsión de los servicios de red. Claramente, la congestión es un fenómeno nada deseable y es causada por ejemplo por la insuficiencia

28
de recursos en la red. En casos de congestión de algunos enlaces, el problema se resolvía a base de añadir más capacidad a los enlaces. La otra causa de congestión es la utilización ineficiente de los recursos debido al mapeado del tráfico. El objetivo básico de la Ingeniería de Tráfico es adaptar los flujos de tráfico a los recursos físicos de la red. La idea es equilibrar de forma óptima la utilización de esos recursos, de manera que no haya algunos que estén sobre-utilizados, creando cuellos de botella, mientras otros puedan estar subutilizados. En general, los flujos de tráfico siguen el camino más corto calculado por el algoritmo IGP correspondiente. La Ingeniería de Tráfico consiste en trasladar determinados flujos seleccionados por el algoritmo IGP sobre enlaces más congestionados, a otros enlaces más descargados, aunque estén fuera de la ruta más corta (con menos saltos). En resúmen la Ingeniería de Tráfico provee por ende, de capacidades para realizar lo siguiente:
• Mapear caminos primarios alrededor de conocidos cuellos de botella o puntos de congestionamiento en la red.
• Lograr un uso más eficiente del ancho de banda agregado disponible, asegurando
que subgrupos de la red no se vuelvan sobre-utilizados, mientras otros subgrupos de la red son inutilizados a lo largo de caminos potenciales alternativos.
• Maximizar la eficiencia operacional. • Mejorar las características de la performance del tráfico orientado de la red,
minimizando la pérdida de paquetes, minimizando períodos prolongados de congestión y maximizando el throughput.
• Mejorar las características estadísticas de los límites de la performance de la red
(como ser tasa de pérdidas, variación del delay y delay de transferencia).
• Proveer de un control preciso sobre cómo el tráfico es re-enrutado cuando el camino primario se enfrenta con una sola o múltiples fallas.
3.2 Componentes de la Ingeniería de Tráfico Hay cuatro componentes que se pueden destacar dentro de la Ingeniería de Tráfico: la componente del packet fowarding, la componente de distribución de información, la componente de selección de camino y la componente de señalización (Por más información ver [2], RFC 3272). Dentro de la primera componente tenemos a MPLS, responsable de dirigir un flujo de paquetes IP a lo largo de un camino predeterminado a través de la red. Esa es una de las principales diferencias entre MPLS e IP, ya que en IP, en vez de seguir los paquetes un camino ya preestablecido, lo hacen salto a salto. Antes de continuar con la segunda componente veamos una breve descripción sobre MPLS.

29
La clave detrás de MPLS es el mecanismo de asignación e intercambio de etiquetas en que se basa. Esas etiquetas son las que permiten que se establezcan las rutas que siguen los paquetes entre dos nodos de la red. Esa ruta a seguir se la conoce como ruta conmutada de etiquetas (LSP). Se crea concatenando uno o más saltos (hops) en los que se produce el intercambio de etiquetas, de modo que cada paquete se envía de un “conmutador de etiquetas” (Label-Switching Router, LSR) a otro, a través de la red MPLS. Los routers en este tipo de redes pueden ser de dos tipos, routers de frontera de etiquetas (LERs) y routers de conmutación de etiquetas (LSRs). Los LERs operan en los extremos de la red MPLS y se encarga de interconectar a ésta con la red de acceso. Al llegar un paquete a un LER, éste examina la información entrante y chequeando una base de datos, le asigna una etiqueta. A la salida de la red MPLS, éstos mismos dispositivos se encargan de remover la etiqueta para entregar así el paquete tal como fue recibido. Los paquetes, una vez etiquetados por el LER, viajan por la red MPLS a través de los routers de conmutación de etiquetas (LSRs). Estos se encargan básicamente de dirigir el tráfico en el interior de la red, según sea la etiqueta que contenga el paquete. Al llegar un paquete a un LSR, éste examina su etiqueta y usándola como índice en una tabla, determina el siguiente “salto” y una nueva etiqueta para el paquete. Cambia una por otra y lo envía hacia el siguiente router, formando así el LSP. Un conjunto de paquetes que comparten los mismos requerimientos para su transporte, pertenecen a la misma FEC (Forwarding Equivalence Class). Las FECs son una manera de distinguir un tipo de tráfico de otro. Todos los paquetes que pertenezcan a la misma FEC seguirán el mismo LSP para llegar a destino. A diferencia del enrutamiento IP convencional, la asignación de un paquete a determinado FEC se hace sólo una vez. Otra diferencia con IP, es que las etiquetas en MPLS no contienen una dirección IP, sino un valor numérico acordado entre dos nodos consecutivos para brindar una conexión a través de un LSP. Este valor se asocia a una determinada FEC. Finalmente, luego que cada router tiene sus tablas de etiquetas puede comenzar el direccionamiento de paquetes a través de los LSPs preestablecidos por un determinado FEC. Habiendo señalado las principales características de MPLS, proseguimos con la segunda componente de TE. Ésta consiste en requerir de un conocimiento detallado de la topología de la red así como también información dinámica de la carga en la red. La componente de distribución de información es implementada definiendo extensiones relativamente simples a los IGPs, tal que los atributos de los enlaces son incluídos como parte de cada aviso del estado de enlace en cada router. Cada router mantiene atributos de los enlaces de la red e información de la topología de la red en una base de datos de TE especializada (TED). La TED es usada exclusivamente para el cálculo de rutas explícitas, para la ubicación de LSPs a lo largo de la topología física. En forma aparte, una base de datos es mantenida, de manera que el cálculo subsiguiente de la ingeniería de tráfico sea independiente del IGP y de la base de datos del estado de enlace del IGP. Mientras tanto, el IGP continúa su operación sin ninguna modificación, realizando el cálculo tradicional del camino más corto, basado en información contenida en la base de datos del estado de enlace en el router.

30
En cuanto a la componente de selección de caminos, luego que los atributos de los enlaces y la información de la topología han sido inundados por IGP y localizados en la TED, cada router de ingreso utiliza la TED para calcular los caminos de su propio conjunto de LSPs a lo largo del dominio de ruteo. El camino para cada LSP puede ser representado tanto por lo que se denomina, una ruta explícita estricta o sin trabas(“strict or loose explicit route”). El router de ingreso determina el camino físico para cada LSP aplicando por ejemplo, un algoritmo de restricciones de camino más corto (CSPF, Constrained Shortest Path First) a la información en la TED. A pesar de que se reduce el esfuerzo de administración (resultado del cálculo online del camino) una herramienta de planeamiento y análisis offline es necesaria si se quiere optimizar la TE globalmente. En el cálculo online se toma en consideración las restricciones de los recursos y se va calculando un LSP a la vez, a medida que van llegando las demandas. Esto implica que el orden en que los LSPs son calculados es muy importante, ya que depende de los LSPs ya establecidos, por dónde se dirigirá cada nuevo LSP que llega. Si se cambiara el orden de llegada de los LSPs, es muy probable que los caminos elegidos para establecerlos cambien también. De esta manera, los LSPs que se calculan primero tienen más recursos disponibles para utilizar que los que llegan más tarde, ya que todo LSP calculado previamente consume recursos. Por otro lado, una herramienta de planeamiento y análisis offline, examina en forma simultánea las restricciones de recursos de cada enlace y los requerimientos de cada LSP. Si bien el acercamiento offline puede tardar varias horas en completarse, realiza cálculos globales comparando los resultados de cada cálculo y selecciona entonces la mejor solución de la red tomada como un conjunto. La salida del cálculo es un conjunto de LSPs que optimizan la utilización de los recursos de la red. Una vez finalizado el cálculo offline, el LSP puede ser establecido en cualquier orden ya que cada uno ha sido instalado siguiendo las reglas para una solución óptima global. Por último, la componente de señalización es la responsable de que el LSP sea establecido para que sea funcional mediante el intercambio de etiquetas entre los nodos de la red. La arquitectura MPLS no asume un único protocolo de distribución de etiquetas; de hecho se están estandarizando algunos existentes con las correspondientes extensiones como son RSPV y LDP.

31
Parte II
Principios y Bases Teóricas

32
Capítulo 4
Constraint Shortest Path First (CSPF) 4.1 Principios básicos de CBR Para poder entender el concepto de Constraint Based Routing (CBR), debemos mirar primero al sistema de ruteo convencional usado en redes IP, como la Internet. Una red es modelada como una colección de Sistemas Autónomos (AS), donde las rutas dentro de un AS son determinadas por ruteo intradominio y las rutas que atraviesan múltiples ASs son determinadas por ruteo interdominio. Ejemplos de protocolos intradominio son RIP, OSPF y IS-IS. El protocolo de ruteo interdominio usado hoy en día en redes IP es BGP. Nos enfocaremos de ahora en más al ruteo intradominio ya que utiliza para el cálculo de los caminos algoritmos que buscan minimizar cierta métrica en particular, como es el caso de CSPF usado en NET-TE. La computación de caminos para cualquiera de los protocolos de ruteo intradominio que mencionamos anteriormente, se basa como ya indicamos, en un algoritmo que optimiza (minimiza) una métrica escalar en particular. En el caso de RIP, dicha métrica es el número de saltos. En el caso de OSPF o IS-IS la métrica es la métrica administrativa de un camino. Esto es, con OSPF (o IS-IS), un administrador de red asigna a cada enlace en la red una métrica administrativa. Dada la opción de múltiples caminos a un destino dado, OSPF (o IS-IS) usa el algoritmo de Dijkstra del camino más corto (SPF) para computar el camino que minimiza la métrica administrativa del camino, donde la métrica administrativa del camino se define como la suma de las métricas administrativas en todos los enlaces a lo largo del camino. La diferencia principal entre el ruteo IP convencional y el ruteo basado en restricciones (CBR) es la siguiente. Algoritmos de ruteo plano IP intentan encontrar un camino que optimiza una determinada métrica escalar, mientras que los algoritmos basados en CBR intentar encontrar un camino que optimice cierta métrica escalar y al mismo tiempo que no viole un conjunto de restricciones. Es precisamente la habilidad de encontrar un camino que no viole un conjunto de restricciones lo que distingue al ruteo basado en restricciones del ruteo plano IP. Los mecanismos claves necesarios para soportar ruteo basado en restricciones son a grandes rasgos los enumerados a continuación. El primer mecanismo que necesitamos es la habilidad de computar un camino, y de hacerlo de manera tal que no tome sólo en cuenta determinada métrica escalar usada como criterio de optimización, sino también un conjunto de restricciones que no deben ser violadas. Esto requiere que la fuente tenga toda la información necesaria para computar dicho camino. El segundo mecanismo es la habilidad de distribuir la información sobre la topología de la red y atributos asociados a los enlaces a través de la red. Esto porque ya que cualquier nodo en la red es potencialmente capaz de generar tráfico que tenga que ser ruteado vía ruteo basado en restricciones, la información que usa la fuente para computar el camino debe estar disponible a cualquier nodo de la red.

33
Una vez computado el camino, también necesitaremos el soportar el envío a través de dicho camino. Por lo que el tercer mecanismo es aquel que sea capaz de soportar el ruteo explícito. Por último, el establecer una ruta para un conjunto particular de tráfico, puede requerir la reserva de recursos a lo largo de esa ruta, alterando quizás el valor de los atributos asociados a enlaces individuales de la red. Por lo que el último mecanismo es uno a través del cual se puedan reservar recursos de la red y sean modificados los atributos de los enlaces como resultado de cierto tráfico tomando ciertas rutas. De ahora en más nos basaremos en comentar el algoritmo Constraint Shortest Path First (CSPF), el cual, como mencionamos anteriormente, es usado por CBR para computar un camino.
Figura 4.1: Modelo del servicio CBR 4.2 CSPF Como se dijo anteriormente, CBR requiere la habilidad de computar un camino de manera tal que
• Sea óptimo respecto a alguna métrica escalar (por ejemplo el minimizar la cantidad de saltos o un métrica administrativa)
• No viole un conjunto de restricciones Una manera de lograr esos objetivos es usar el algoritmo de shortest path first (SPF). El algoritmo SPF plano, computa un camino que es óptimo con respecto a cierta métrica escalar. Entonces, para computar un camino que no viole restricciones, todo lo que necesitamos es el modificar el algoritmo de manera tal que pueda tomar en cuenta

34
esas restricciones. Nos referiremos a tal algoritmo como constraint shortest path first (CSPF) (Ver [3] por más información). Para entender como SPF debe ser modificado para tomar restricciones en cuenta, miremos primero como es la operación del SPF plano. El algoritmo SPF plano trabaja empezando de un nodo llamado raíz, y creando luego a partir del mismo, una estructura en forma de árbol que contiene el camino más corto. En cada iteración del algoritmo, hay una lista de posibles nodos “candidatos” (inicialmente esta lista contiene sólo a la raíz). En general, los caminos de la raíz a los nodos candidatos no son los más cortos. Sin embargo, para el nodo candidato que esta más cerca de la raíz (con respecto a la distancia usada por SPF), el camino a ese nodo es el más corto garantizadamente. Entonces, en cada iteración, el algoritmo toma de la lista de candidatos, al nodo con la distancia más corta a la raíz. Este nodo es entonces agregado al árbol del camino más corto y removido de la lista de nodos candidatos. Una vez que el nodo ha sido agregado al árbol del camino más corto, los nodos que no están en el árbol, pero son adyacentes a ese nodo, son examinados para una posible adición o modificación de la lista de candidatos. El algoritmo entonces itera nuevamente. Para el caso en donde se desee encontrar el camino más corto de la raíz a todo el resto de los nodos, el algoritmo termina cuando la lista de candidatos esta vacía. Para el caso en que se desee simplemente encontrar el camino más corto de la raíz a algún otro nodo especifico, el algoritmo termina cuando este otro nodo es agregado al árbol del camino más corto.
Figura 4.2: Proceso de computación del CSPF
En la Figura 4.2 se puede apreciar el proceso total de computación del algoritmo CSPF. Vale destacar que la TED es la Base de Datos de Ingeniería de Tráfico, la cual provee a CSPF con información actual sobre la topología de la red. Dadas las operaciones del SPF plano, es bastante sencillo el observar la modificación que debemos hacerle al mismo de manera de convertirlo a CSPF. Todo lo que tenemos que hacer es modificar el paso que maneja la adición o modificación de la lista de candidatos. Específicamente, cuando agregamos un nodo al árbol del camino más corto y nos fijamos en los enlaces adyacentes a ese nodo, nos fijamos primeramente si

35
esos enlaces satisfacen todas las restricciones planteadas. Sólo si el enlace satisface todas las restricciones, recién ahí examinamos el nodo que esta ubicado en el otro extremo del enlace. En general, el procedimiento por el cual chequeamos si un enlace satisface una restricción en particular, es específico de la naturaleza de la restricción. Por ejemplo, cuando la restricción que queremos satisfacer es al ancho de banda disponible, entonces el chequeo es si el ancho de banda disponible en el enlace es mayor o igual al ancho de banda especificado por la restricción; sólo si lo es, es que examinamos el nodo ubicado en el otro extremo del enlace. También observar que el chequear si un enlace satisface una restricción en particular, asume que hay una información de restricción relacionada, asociada con el enlace. La naturaleza de esta información relacionada a la restricción. Por ejemplo, cuando la restricción que queremos satisfacer es el ancho de banda disponible, la información que necesitamos es tener al ancho de banda disponible en un enlace. Notar que el algoritmo CSPF requiere que el router que realiza la computación del camino, tenga información sobre todos los enlaces en la red. Esto impone una restricción en el tipo de protocolo de ruteo que podemos usar para soportar el ruteo basado en restricciones (CBR). Tenemos que usar protocolos de estado de enlace como IS-IS u OSPF, ya que protocolos de ruteo de vector distancia como RIP no son capaces de encontrar estos requerimientos. Como comentario sobre uno del resto de los mecanismos restantes necesarios para soportar CBR, la capacidad de ruteo explícito necesaria es provista por MPLS. En el caso del software NET-TE en este proyecto, se utilizó CSPF para computar los caminos para los LSPs obligando a que cumplan ciertos requerimientos. El requerimiento usado en este proyecto fue el ancho de banda disponible en cada enlace de la red. Además se le agregó la posibilidad de que el usuario pueda obligar al LSP hayado que pase por cierto enlace de la red así como que no pase por otro en particular. La razón por la cual se puede desear querer obligar que un LSP pase por cierto enlace y no lo haga por otro depende totalmente del usuario y de la forma en que él gestione su red. Además es importante destacar que con respecto a los pesos asignados a los enlaces al momento de correr el SPF, se le ofrece al usuario la oportunidad de usar distintos pesos, dependiendo de cual sea la métrica en la que él este interesado de usar (por ejemplo la cantidad mínima de saltos, minimizar los pesos administrativos asignados por el mismo a los enlaces o hacer la métrica en función del ancho de banda disponible en los enlaces, entre otros). 4.3 Ruteo basado en QoS. WSP y SWP.
El ruteo basado en QoS ha sido un área de investigación muy activa por muchos años. Selecciona rutas en la red que satisfagan la QoS requerida para una conexión o grupo de conexiones. Además, el ruteo basado en QoS logra una eficiencia global en la utilización eficiente de los recursos. Un ejemplo de esto es al algoritmo Shortest-Widest-Path (WSP), el cual usa al ancho de banda como una métrica y selecciona los caminos que tienen un cuello de botella de ancho de banda mayor. El cuello de botella de

36
ancho de banda representa la capacidad mínima no usada de todos los enlaces en el camino. En el caso de dos caminos con el mismo cuello de botella de ancho de banda, el camino con la mínima cantidad de saltos es seleccionado (Ver [4] por más información). Los algoritmos de ruteo usados en CBR y la complejidad de los mismos, depende del tipo y del número de métricas que son incluídas en el cálculo de la ruta. Algunas de las restricciones pueden ser contradictorias (por ejemplo costo vs. ancho de banda, delay vs. throughput). Resulta que el ancho de banda y la cuenta de saltos son en general restricciones más útiles en comparación con el delay y jitter, ya que muy pocas aplicaciones no pueden tolerar una ocasional violación de dichas restricciones, y como el delay y jitter se pueden determinar por medio del ancho de banda alojado y número de saltos del camino donde va el flujo, éstas restricciones pueden ser mapeadas en restricciones de ancho de banda y número de saltos, en caso de ser necesario. Otro factor es que muchas aplicaciones en tiempo real requieren un determinado ancho de banda. El número de saltos de una ruta también es una métrica importante, ya que cuantos más saltos atraviese un flujo, más recursos consumirá. Con las implementaciones básicas del esquema de CBR, hay una especie de balance y equilibrio entre la conservación de recursos y el balance de carga. Un esquema de CBR puede seleccionar de las siguientes opciones para un camino viable para un flujo:
• Shortest-Distance Path (SDP): éste acercamiento es básicamente el mismo
que el ruteo dinámico. Hace énfasis en preservar los recursos de la red por medio de la selección de los caminos más cortos.
• Widest-Shortest Path (WSP): éste acercamiento hace énfasis en balancear la carga por medio de la elección de caminos más “anchos” en cuanto al ancho de banda. Encuentra caminos con el mínimo número de saltos y, si encuentra múltiples caminos, se queda con el que tiene ancho de banda mayor.
• Shortest-Widest Path (SWP): éste acercamiento hace una especie de intercambio entre los dos extremos. Favorece a los caminos más cortos cuando la carga de la red es pesada y a los caminos más “anchos” cuando la carga de la red es moderada. Encuentra un camino con el ancho de banda más grande y, en caso de haber múltiples caminos, se queda con el que tiene la mínima cantidad de saltos.
En los últimos dos casos se consumen más recursos, lo cual no es eficiente cuando la utilización de la red es alta. Se debe hacer un balance o equilibrio entre la conservación de recursos y el balance de carga (Ver [5] por más información). Vale hacer notar en este momento, que cualquiera de las 3 opciones superiores se pueden implementar en el software NET-TE, combinando correctamente la elección del tipo de pesos para los enlaces con la elección del criterio de TE.

37
Capítulo 5
Minimum Interference Routing Algorithm (MIRA) 5.1 Presentación del algoritmo
La idea de éste tipo de algoritmos es la de minimizar la “interferencia” que provoca el establecimiento de un nuevo LSP a potenciales nuevos LSPs que son desconocidos. Mapear un LSP en la red puede reducir el máximo ancho de banda disponible entre algunos pares de nodos ingreso-egreso críticos en la red, dependiendo de por dónde se dirija el mismo. Este fenómeno es conocido como “interferencia”. Esto nos lleva a pensar que si los caminos que reducen la cantidad de ancho de banda disponible entre otros nodos ingreso-egreso son evitados, entonces la creación de los cuellos de botella puede ser evitada también. Para llevar a cabo esto, se asocia a cada enlace de la red un peso y luego se aplica SPF a la red. Este peso es proporcional a cuán crítico es el enlace para el establecimiento de LSPs entre pares de nodos ingreso-egreso. De esta manera futuras demandas entre estos nodos tendrán baja probabilidad de ser rechazadas. En este tipo de algoritmos es necesario conocer la topología actual y las capacidades disponibles. Se asume que la topología es conocida administrativamente o que un protocolo de ruteo de estado de enlace está operacional (OSPF, IS-IS, etc.) y que la base de datos de los estados de los enlaces es accesible. Además, desde cierto nodo ingreso, pueden ser permitidos LSPs a ciertos egresos solamente Esto se debe por ejemplo a restricciones de política o de servicio. Toda información de este tipo es conocida, y se asume que no varía frecuentemente. Existen varios trabajos respecto a algoritmos que disminuyen la interferencia, pero el algoritmo que implementamos en nuestro software esta basado en el algoritmo MIRA (por más información ver Referencias [6] y [7]). En la Figura 5.1 se muestra en que casos éste tipo de algoritmo soluciona los problemas causados por los algoritmos clásicos como el min-hop algorithm.

38
Figura 5.1: Ejemplo de uso del MIRA
Consideramos que los nodos ingreso-egreso son (A, G), (B, G), (C, G). Se puede dar la situación en que se necesiten varios LSPs entre (A,G) y se utiliza el enfoque de min-hop los LSPs serán mapeados en el camino con menor cantidad de saltos, saturando los enlaces A-D y D-G y bloqueando futuras demandas entre (B,G) y (C,G), siendo lo ideal un algoritmo que tenga en consideración lo crítico que son estos enlaces en éstas futuras demandas, de modo de mapear la demanda entre (A,G) por A-E-F-G aunque éste camino sea más largo (en lo que a número de saltos se refiere). 5.2 Modelado del sistema Se considera una red de n nodos representados por un grafo G = (V, E), donde V es el conjunto de nodos en la red y E el conjunto de m enlaces de la red. Un subconjunto de estos nodos es considerado como nodos ingreso-egreso de futuras demandas y se denota a este subconjunto como L. Sin embargo, no es necesario conocer este subconjunto para que el algoritmo funcione, ya que se puede considerar que L=V de modo que cada par de nodos pueden ser los nodos ingreso-egreso para futuras demandas. La capacidad disponible R (l) de cada enlace l se asume conocida (mediante alguna extensión del protocolo de enlace de estado operacional). 5.3 Algoritmo propuesto El pseudo código del algoritmo para el establecimiento de un LSP entre (s, d) se presenta a continuación:
1- Calcular el MNF (Maximum Network Flow) entre todos los pares ingreso-egreso ( ) Lds ∈',' .
2- Calcular el peso w(l) para todos los enlaces l E∈ .

39
3- Eliminar todos los enlaces que tienen ancho de banda disponible menor al requerido por el LSP y formar una nueva topología con los nodos y enlaces restantes.
4- Correr SPF con la topología reducida. 5- Establecer el LSP entre ( )ds, y actualizar los anchos de banda disponible en cada
enlace. Específicamente, dada una nueva demanda entre ( )ds, , se considera el impacto de mapear esta demanda en futuras demandas entre nodos ingreso-egreso. Este impacto es caracterizado al asignarle pesos a los enlaces que pueden ser usados por estas futuras demandas. Cuando consideramos un par de nodos ingreso-egreso ( ) Lds ∈',' , primero calculamos el MNF (maximum network flow) ''dsθ [3] entre s’ y d’. El MNF representa el máximo ancho de banda que puede traficar la red entre el par de nodos (s, d), ya sea por varios caminos o por uno sólo. Luego para cada enlace El ∈ se calcula la
contribución del enlace a este MNF entre s’ y d’ que es representado como ''
''
ds
dslf
θ, donde
''dslf es la cantidad de tráfico de MNF que pasa por l. También se necesita caracterizar el
ancho de nada disponible en el enlace l de modo de incorporar la capacidad de mapear futuras demandas por el enlace. Hacemos esto calculando la contribución normalizada de ancho de banda del enlace l como sigue,
( )lRfds
dsl''
''
θ (5.1a)
Ésta es la diferencia principal de este algoritmo con respecto a otros, como versiones anteriores del MIRA, en las cuales sólo se considera si los enlaces son críticos o no en futuras demandas ( ''ds
lf =1 ó 0). De ésta manera se considera la importancia del enlace pero también el cuantificar esta importancia con la contribución normalizada de ancho de banda. Luego se asigna a cada enlace el peso total debido a todas las contribuciones de todos los pares ingreso-egreso ( ) Lds ∈',' que pueden originar LSPs en el futuro:
( )∑∈
∈=Lds
ds
dsl El
lRflw
)','(''
''
,)(θ
(5.2a)
Una vez que los pesos son calculados y asignados, se eliminan los enlaces en E que tienen el ancho de banda disponible menos al requerido por la demanda obteniéndose una topología reducida con los pesos asignados incambiados. Luego se corre el SPF basado en Dijkstra para obtener el LSP entre s y d y se actualiza el ancho de banda disponible en los enlaces que pertenecen al nuevo LSP.

40
Capítulo 6
Redes Justas (“Fair Networks”) 6.1 Introducción Debido a que la distribución del tráfico en las redes de datos cambia rápidamente, es complicado para los operadores de una red, el determinar cuándo y dónde incrementar la capacidad de la misma, lo cual puede llevar a problemas de sobrecarga. La toma de decisión sobre cuántos usuarios pueden ser atendidos y cuánto tráfico puede generar cada uno de ellos, es un tema del que se encarga el proceso de admisión de tráfico. El mismo, es responsable de garantizar que los usuarios tengan un acceso justo a los servicios de la red, al mismo tiempo de minimizar la probabilidad de negar un servicio a un cliente. El determinar cuánto tráfico de cada flujo debe ser admitido por la red y por dónde rutear al mismo una vez que ingresa, satisfaciendo los requerimientos de alta utilización de la red y garantizando justicia a los usuarios, es uno de los retos más grandes en el diseño de las redes de telecomunicaciones de hoy en día. Así nos encontramos frente a la pregunta de cómo distribuir económicamente cierto volúmen de demanda sobre una red, bajo cierto conjunto de restricciones de ruteo y flujo. La primera hipótesis es que las demandas entre pares de nodos origen-destino, pueden utilizar cualquier ancho de banda asignado a ellas en términos de sus flujos de caminos, quizás bajo ciertos límites. La pregunta es: ¿qué principio debemos seguir al alojar las demandas entre los recursos que la red tiene pare ofrecer, de manera de cumplir con algún criterio de justicia? Una primera solución que se nos podría ocurrir es asignar la mayor cantidad de recursos a cada demanda, al mismo tiempo que se intenta mantener los recursos asignados lo más similares posible. Esto nos lleva al principio de asignación llamado Max-Min Fairness (MMF), usado para formular el esquema de asignación de recursos (Ver [10] por más información). La noción de justicia se presenta en el contexto de redes basadas en el intercambio de paquetes, transportando demandas elásticas entre pares de nodos. Con elasticidad nos referimos a que cada demanda puede consumir cualquier ancho de banda agregado asignado a sus caminos individuales, quizás dentro de determinados límites predefinidos. En las próximas secciones de éste capítulo mostraremos los enunciados principales de los problemas MMF, analizando cómo usar sus nociones para expresar la justicia en el proceso de admisión de tráfico. Se presentarán los cuatro diferentes métodos que fueron implementados en el software NET-TE.

41
*La información, así como los enunciados y métodos presentados en éste capítulo, fueron extraídos del libro "Routing, Flow and Capacity Design in Communication and Computer Networks", de Michal Pioro y Deepankar Medhi [10].
6.1.1 Nociones de Justicia Consideremos una red con demandas elásticas. Un problema general con este tipo de redes es cómo asignar flujos (BW) a los caminos de las demandas, de manera que las capacidades de los links no son excedidas y que los actuales volumenes de ancho de banda agregado asignados a las demandas sean distribuídos de una manera justa.
6.2 Algoritmo 1: Max-Min Fairness básico para caminos fijos
Consideremos una red con enlaces de capacidades fijas y con caminos prefijados únicos asignados para transportar los flujos de las demandas (o sea que en caso de existir varios caminos posibles entre determinado par de nodos, nos quedamos solamente con uno sólo de ellos, pudiendo éste ser elegido por el usuario a su gusto). Antes de seguir con el planteo del primer método utilizado de asignación justa de recursos, debemos introducir una definición: Definición 6.1: Un vector de n componentes x = (x1, x2,…, xn) ordenado en orden ascendente (x1 ≤ x2 ≤… ≤ xn) es lexicográficamente mayor que otro vector de n componentes y = (y1, y2,…, yn) ordenado ascendentemente (y1 ≤ y2 ≤… ≤ yn) si existe un índice k, 0 ≤ k ≤ n, tal que xi = yi para i=1, 2,…, k y xk > yk. Ahora presentemos la formulación del primer algoritmo. Índices d = 1, 2,…, D demandas e = 1, 2,…, E enlaces Constantes edδ = 1 si el enlace e pertenece al camino fijo de la demanda d; 0 en otro caso ec Capacidad del enlace e Variables dx Flujo asignado a la demanda d, x = (x1, x2,…, xD) Objetivo Hayar el vector de asignación x, el cual, cuando ordenado en orden ascendente, es lexicográficamente máximo entre todos los vectores de asignación ordenados en orden ascendente.

42
Restricciones
ed d ed
x c eδ ≤ =1,2,..., Ε∑ (6.2.1a)
0x ≥ (6.2.1b) Obviamente, como es simple de ver, la ecuacion (6.2.1a) quiere decir que, para cada enlace, la suma de los anchos de banda de cada demanda que pase por ese enlace, no puede ser mayor que la capacidad de dicho enlace, lo cual es razonable. De acuerdo a la Definición 6.1, la solución x* de éste problema tiene la propiedad de que para cualquier otro posible vector x = (x1, x2,…, xD), cuando ambos vectores están ordenados * * *
(1) (2) ( ) (1) (2) ( )( ... ... )i i i D j j j Dx x x y x x x≤ ≤ ≤ ≤ ≤ ≤ entonces existe un índice
d, 0 ≤ d ≤ D, tal que *( ) ( )i l j lx x= para l = 1, 2,…, d y *
( 1) ( 1)i d j dx x+ +> . Para establecer la equivalencia de la caracterización lexicográfica de la solución óptima al problema MMF/FIXSP (Max-Min Fairness for Fixs Paths; problema que estamos actualmente analizando) con una caracterización justa max-min más conocida, para el caso considerado de camino fijo único, debemos introducir a continuación una nueva definición y proposición. Definición 6.2 Un posible vector de asignación de flujo x que satisfaga (6.2.1a y 6.2.1b) es max-min
justo si para cada demanda d existe un enlace saturado e ( ed d ed
x cδ =∑ ) perteneciente al
camino que satisface la demanda d ( 1edδ = ) de manera tal que el flujo xd es máximo en e
{ }' '( max : ' 1, 2,..., ; 1 )d d edx x d D δ= = = . Proposición 6.1 Un vector de asignación x* resuelve el problema anterior si y sólo si es max-min justo en el sentido señalado por la Definición 6.2. La solución x* de este problema es única. Finalmente, la formulación completa del problema de MMF con caminos fijos únicos es la siguiente: 6.2.1 Formulación completa del Algoritmo 1: Variables xd flujo asignado a la demanda d ued variable auxiliar binaria, ued = 0 si el enlace e pertenece al camino de la demanda d, e esta saturado y xd es máximo en e; ued = 1 en cualquier otro caso ze variable auxiliar del flujo para el enlace e

43
Restricciones (6.2.2a)
(6.2.2b)
(6.2.2c)
(6.2.2d) (6.2.2e)
con todas las xd y ze continuas no negativas y todas las ued binarias (6.2.2f) Como comentarios que podemos hacer al respecto de la formulación de las ecuaciones anteriores, si observamos la ecuación (6.2.2b) podemos ver que lo que básicamente quiere decir es que para cada demanda, si consideramos sólo los enlaces que la conforman, existe alguno para el cual ued es igual a 0, lo cual implica que ése enlace e está saturado y xd es máximo en el mismo (dicho de otra manera, que llegué a obtener al mayor ancho de banda posible para ésa demanda y me doy cuenta de ello, ya que alguno de los enlaces que conforman la demanda saturó ya). Luego, la ecuación (6.2.2c), básicamente nos hace ver que si ued es igual a cero para un determinado enlace, entonces la parte de la derecha de ésa ecuación es cero también, indicando que ya ha saturado el enlace, debido a que la suma de todos los anchos de banda de todas las demandas que pasan por el mismo ha igualado a su capacidad. Finalmente, de las ecuaciones (6.2.2d) y (6.2.2e) sacamos que si ued es igual a cero, entonces xd = max{xd’: d’=1,2,…D, y
' 1edδ = } (dicho en otras palabras, si ued=0 entonces xd es el máximo flujo en el enlace e. Por ende, usando la Preposición 6.1, el problema (6.2.2) tiene una solución única
* * * *1 2( , ,..., )Dx x x x= , idéntica a la solución inicial del problema (6.2.1)).
Finalmente, el único vector justo max-min (máximo vector de asignación lexicográfico) * * * *
1 2( , ,..., )Dx x x x= , puede ser hayado usando el siguiente algoritmo 1. 6.2.2 Pasos para resolver el Algoritmo 1 Paso 0: Poner * 0x =
Paso 1: : min / : 1,2,...,e edd
t c e Eδ = =
∑
Paso 2: * *: 1,2,..., ; : 1,2,...,e e ed d dd
c c t para e E x x t para d Dδ = − = = + =
∑
' ''
(1 ) 1 1,2,...,
' 1, 2,...,
1, 2,..., 11,2,..., 1
ed d ed
ed ede
ed e e ed dd
ed e e d ed
d e ed
x c e
d D
c c x e d D
c z x e d D yx z e d D y
δ
δ
δ
δδ
≤ =1,2,..., Ε
− υ ≥ =
υ ≥ − =1,2,..., Ε =
υ ≥ − =1,2,..., Ε = =
≥ =1,2,..., Ε = =
∑
∑
∑

44
Remover todos los enlaces saturados (todos los enlaces e con ce=0). Para cada enlace removido e, remover todos los caminos y correspondientes demandas que usan ese enlace removido (todas las d con 1edδ = ). Paso 3: Si no queda ninguna demanda más, entonces detenerse. En caso contrario ir al paso 1. Observar que la cantidad t calculada en el paso 1, es la solución del siguiente problema de programación lineal (LP): maximizar t (6.2.3a)
sujeto a 1, 2,...,ed ed
t c e Eδ ≤ =
∑ (6.2.3b)
Esa observación nos permitirá a nosotros extender la noción y solución de algoritmos para problemas más generales MMF como el que veremos más adelante.
6.3 Algoritmo 2: Max-Min Fairness para caminos fijos con cotas
Ahora seguiremos considerando el caso del MMF para caminos fijos, pero agregándole ahora pesos a las demandas y cotas superior e inferior a los flujos asignados a esas demandas.
6.3.1 Formulación del Algoritmo 2:
Índices d = 1, 2,…, D demandas e = 1, 2,…, E enlaces Constantes edδ = 1 si el enlace e pertenece al camino fijo de la demanda d; 0 en caso contrario ce capacidad del enlace e wd peso de la demanda d hd límite inferior para el flujo de la demanda d Hd límite superior para el flujo de la demanda d Variables xd flujo asignado a la demanda d, x = (x1, x2,…, xD) Objetivo Encontrar el vector de asignación x, el cual, cuando está ordenado en orden ascendente, es lexicográficamente máximo entre todos los vectores de asignación ordenados ascendentemente.

45
1,2,...,1, 2,...,
0
d d d
ed d d ed
h x H d Dw x c e E
x
δ
≤ ≤ =
≤ =
≥
∑
Restricciones (6.3.1a) (6.3.1b) (6.3.1c) En la restricción (6.3.1b) la carga del enlace e inducida por el flujo xd es igual a
ed d dw xδ , lo cual implica que el flujo actual asignado a la demanda d es igual a wdxd. Debido a la presencia de límites inferiores, el problema se puede tornar irresoluble. La solución al problema del Algoritmo 2 (MMF/EFIXSP), * * * *
1 2( , ,..., )Dx x x x= , puede ser encontrada usando el algoritmo 6.3.2 que enunciaremos a continuación. Este algoritmo es similar al algoritmo 6.2.2 visto anteriormente. Hace uso también del siguiente problema LP: maximizar t (6.3.2a)
sujeto a 1, 2,...,d ed ed
t w c e Eδ ≤ =
∑ (6.3.2b)
6.3.2 Pasos para resolver el Algoritmo 2: Paso 0: Poner *
d dx h= para d = 1, 2,…, D y : 1,2,..., ;e e ed d d
dc c w h para e Eδ= − =∑
Remover todos los enlaces saturados (todos los e con ce = 0). Para cada enlace removido e remover todos los caminos y correspondientes demandas que usan el enlace removido (todas las d con 1edδ = ). Paso 1: Resolver el problema LP (6.3.2) para obtener t. Paso 2: Remover todos los enlaces saturados (todos los e con ce=0). Para cada enlace removido e remover todos los caminos y correspondientes demandas que usen el enlace removido (todas las d con 1edδ = ). Paso 3: Si no quedan más demandas entonces detenerse. En caso contrario ir al paso 1.
* *: 1,2,..., ; : 1, 2,...,e e ed d d dd
c c t w para e E x x t para d Dδ = − = = + =
∑

46
Observación La implementación de este algoritmo consiste básicamente en agregar un enlace y nodo ficticio para cada demanda, de manera de asegurarse que por dicho enlace pase solamente ésa demanda en particular. O sea que cada demanda tendrá un enlace y nodo ficiticio propio de ella. La capacidad de dicho enlace ficticio será igual al ancho de banda requerido para la demanda en cuestión. De esta manera, nos aseguramos que el ancho de banda no se aumente más que el ancho de banda requerido por el usuario. Es una manera de poner un tope superior al ancho de banda. En las próximas secciones consideraremos un problema más general para MMF, que involucrará optimización simultánea de caminos y flujos. Nos referimos a este tipo de problemas como problemas de caminos flexibles, en contraste con los problemas de caminos fijos vistos hasta ahora. En particular, el problema analizado a continuación es con capacidades para caminos flexibles. Se considerará ahora el caso donde múltiples caminos son posibles candidatos en la lista de ruteo asignada a cada demanda. Esto implica por ende que, los flujos que satisfacen el volumen de cada demanda son divididos entre los posibles caminos, lo cual resultará, en general, en un vector de asignación lexicográficamente mayor que el que resuelve el caso de los caminos fijos.
6.4 Algoritmo 3: Max Min Fairness para múltiples caminos
El siguiente problema es para múltiples caminos flexibles (MMF/FLMP, Max-Min Fairness for Flexible Multiple Paths). Índices d = 1, 2,…, D demandas (pares de nodos) p = 1, 2,…, Pd caminos candidatos para la demanda d e = 1, 2,…, E enlaces Constantes edpδ = 1 si el enlace e pertenece al camino p de la demanda d; 0 en caso contrario ce capacidad del enlace e Variables xdp flujo (ancho de banda) asignado al camino p de la demanda d Xd flujo total (ancho de banda) asignado a la demanda d, X = (X1, X2,…, XD)

47
1, 2,...,
0 1, 2,...,1, 2,...,
d dpp
d
edp dp ed p
X x d D
t X d Dx c e Eδ
= =
− ≤ =
= =
∑
∑∑
Objetivo Encontrar el vector de asignación de flujo total X, el cual, cuando ordenado en orden ascendente, es lexicográficamente máximo entre todos los vectores de asignación ordenados en orden ascendente. Restricciones 1, 2,...,dp d
p
x X d D= =∑ (6.4.1a)
1, 2,...,edp dp ed p
x c e Eδ = =∑∑ (6.4.1b)
todos los xdp ≥ 0. (6.4.1c) El problema con el que ahora tratamos es más difícil de resolver que su contraparte de camino único MMF/FIXSP, debido a que ahora las soluciones de la apropiada extensión al problema LP (6.2.3) son, en general, no únicas. La extensión es como sigue. maximizar t (6.4.2a) sujeto a (6.4.2b) (6.4.2c) (6.4.2d) todos los 0dpx ≥ (6.4.2e) La función objetivo (6.4.2a), junto con la restricción (6.4.2c) es equivalente al objetivo en el que estamos interesados en realidad: maximizar min {Xd : d = 1, 2,…, D} Eso se debe a que por la ecuación (6.4.2c), si queremos maximizar t, esto equivale a querer maximizar el mínimo de Xd. Es decir, max{t, t- Xd ≤ 0, d: 1,2,…D} = max min{ Xd, d:1,2,…D}. El problema (6.4.2) puede tener múltiples soluciones. La solución de MMF/FLMP, tal como el Algoritmo 3 que se expondrá a continuación es substancialmente más complicada. Consiste también en una aplicación iterativa de una extensión del problema LP (6.4.2), pero el uso de la extensión incluye un

48
' '
' ' '
' ''
' 1, 2,...,
0 ' 1, 2,..., ( )1,2,...,
d d pp
d d d
ed p d p ed p
X x d D
t X d D t constx c e Eδ
= =
− ≤ = −
≤ =
∑
∑∑
paso que chequea qué demanda de asignación Xd puede seguir siendo incrementada sin afectar al resto de las demandas. La eficacia del Algoritmo 3 depende de la eficiencia del test de no bloqueo (NBT) usado en el Paso 1. El test llamado NBT1 consiste en resolver el siguiente problema LP para cada demanda fija d ∈ Z1: maximizar Xd (6.4.3a) sujeto a (6.4.3b) (6.4.3c) (6.4.3d) todos los ' 0d px ≥ (6.4.3e) 6.4.1 Pasos para resolver el Algoritmo 3 (usando NBT1): Paso 0: Resolver el problema LP (6.4.2) y nombremos (t*, x*, X*) a la solución óptima del mismo. Pongamos n := 0, Z0 := ∅ , Z1 := {1, 2,…, D}, y td := t* para cada d ∈ Z1. Paso 1: Pongamos n := n + 1. Empecemos considerando las demandas d ∈ Z1 una por una, para chequear si el volumen total de asignación *
dX puede hacerse mayor a t*, sin decrementar las máximas asignaciones ya encontradas td’ para el resto de todas las demandas d’. El chequeo es llevado a cabo por un test de no bloqueo (6.4.3). Si no hay demandas que bloqueen en Z1 (demanda d ∈ Z1 se considera que bloquea, si Xd no puede incrementarse más) entonces ir al Paso 2. En caso contrario, cuando la primer demanda que bloquee se encuentre, digamos demanda d, agregar d al conjunto Z0 y borrarla del conjunto Z1 (Z0 := Z0 ∪ {d}, Z1 := Z1\{d}). Si Z1 = ∅ , entonces detenerse (el vector
* * * *1 2 1 2( , ,..., ) ( , ,..., )D DX X X X t t t= = es la solución para el Problema (6.4.1); en caso
contrario proceder al Paso 2. Paso 2: Solucionar el problema LP siguiente (modificación del (6.4.2)) para mejorar las mejores asignaciones totales actuales: maximizar t

49
1
0
1,2,...,
00 ( )
1,2,...,
d dpp
d
d d d
edpd p
dp e
X x d D
t X d Zt X d Z t const
e E
x c
δ
= =
− ≤ =− ≤ = −
=
≤
∑
∑∑
sujeto a (6.4.4a) (6.4.4b) (6.4.4c) (6.4.4d) (6.4.4e) todos los 0dpx ≥ (6.4.4f) Nombremos (t*, x*, X*) a la solución de (6.4.4). Pongamos td := t* para cada d ∈ Z1 y vayamos entonces al Paso 1 nuevamente. Observar que puede suceder que la solución óptima de (6.4.4) no incremente al t* porque puede que haya más demandas que bloqueen además de la detectada en el Paso 1. La salida de NBT1 (6.4.3) es positiva, lo cual significa que la demanda d es no bloqueadora si el óptimo Xd es estrictamente mayor que t*. En otro caso, la demanda considerada resulta ser bloqueadora en realidad. Notar también que la solución de NBT1 para algunos d ∈ Z1 puede mostrar que para algunas otras d’ ∈ Z1 el volumen resultante Xd’ es mayor que t*. Esas demandas d’ son no bloqueadoras y no necesitan de tests separados. Los cálculos deben ser realizados usando la solución resultante del Paso 0 (o Paso 2) como solución inicial de NBT1 para cada d ∈ Z1. Cerramos finalmente esta sección con la siguiente proposición. Proposición 8.2: El vector final de volumenes de asignación total * * * *
1 2( , ,..., )DX X X X= , que resulta de la solución del Problema (6.4.4) obtenida en la última iteración del Algoritmo 3, es único.
6.5 Algoritmo 4: Max Min Fairness para múltiples caminos acotado
El siguiente problema es para múltiples caminos flexibles (MMF/FLMP, Max-Min Fairness for Flexible Multiple Paths). La idea detrás de este algoritmo es la siguiente. Es básicamente el mismo algoritmo que el expuesto anteriormente. La principal diferencia es que se detiene una vez que se llega a obtener el ancho de banda requerido por el usuario. En el algoritmo anterior, se veía cuánto era la mayor cantidad de recursos que la red me podía ofrecer

50
para cada demanda, determinando a su vez cuánta carga llevaría cada sub-demanda. En este caso lo que se hace, es una especie de tratamiento sobre el resultado arrojado por el algoritmo 3. Se toman todas las demandas y sus respectivas sub-demandas (resultados obtenidos del algoritmo 3), y se ordenan de mayor a menor, según el ancho de banda que portan. Supongamos que analizamos primero la primer demanda. Tenemos ya sus sub-demandas ordenadas de mayor a menor. Entonces comparamos el ancho de banda que lleva la primer sub-demanda con el ancho de banda requerido (valor dado por el usuario). En caso que el ancho de banda de la sub-demanda ya sea mayor que el requerido para la demanda número uno, se resta el ancho de banda requerido al que porta la sub-demanda y se descartan el resto de las sub-demandas (ya que al ancho de banda requerido ya fue satisfecho). Ahora, en caso de no ser mayor, se prosigue a la siguiente sub-demanda y se ve si el ancho de banda de la primer sub-demanda conjuntamente con el que lleva la segunda sub-demanda es mayor o no que el requerido. En caso de serlo se descartan el resto de las sub-demandas y se realiza la resta. Sino, se prosigue de la misma manera, una y otra vez. Este proceso se repite para todas las demandas. Como vemos entonces, los pasos para resolver el algoritmo 4 son los mismos que los usados en el algoritmo 3. La única diferencia es que se hace un tratamiento de los resultados arrojados por el algoritmo 3 de manera de, en caso de ser suficiente el ancho de banda que porta cada demanda, detenerse en cuanto se llega al valor del ancho de banda requerido.

51
Parte III
Arquitectura de Software

52
Capítulo 7
Representación de la red e interacción con ARCA En los próximos capítulos presentaremos la estructura en la que fue creado el software NET-TE. Se presentarán los packages utilizados y especificará las principales tareas de las clases que los conforman, así como su implementación. El orden en el que se presentaran los packages será el siguiente. En un principio, se empezará en este Capítulo 7 con el Package correspondiente a la topología de la red en donde se presentarán los elementos que la constituyen así como una breve descripción de los mismos. En una diferente sección dentro de este mismo capítulo, también se presentará al package encargado de la interacción con el ARCA. El mismo tiene como objetivo el poder crear un área común entre ambas aplicaciones para poder así utilizar el archivo de salida del ARCA como entrada al nuestro y que exista así, compatibilidad entre ambas aplicaciones. Pasamos posteriormente a presentar en el Capítulo 8 al Package Programa. El mismo se encarga de la interfaz gráfica de la aplicación. Se encarga de ofrecerle al usuario, por medio del modo gráfico, la manera de acceder a las distintas funcionalidades del software, como ser ingresar la topología manualmente, configurar los parámetros de los enlaces, desplegar los LSPs ya creados y eliminar los que se desee, obtener información sobre el porcentaje de utilización de cada enlace en la red y observar de manera gráfica por medio de la diferenciación de colores los distintos rangos de utilización que el usuario desee analizar, etc. Luego en el Capítulo 9 describimos el Package Cargar Red, encargado de implementar la funcionalidad de cargar la topología de la red sobre la cual se esta trabajando de manera automática. Más adelante, en el Capítulo 10, presentamos el Package Crear LSPs, que es donde se implementa el algoritmo CSPF de computación de caminos para hayar los LSPs. Por último, en el Capítulo 11, se trata el Package MT, el cual se encarga de crear o cargar (en caso de que exista una ya creada) la matriz de tráfico de la red, en donde el usuario especifica todos las demandas representadas por los pares origen-destino, para luego darla como parámetro de entrada a los algoritmos de redes justas y MIRA. 7.1 El Package topología
Una parte fundamental del presente proyecto consistió en abstraer la arquitectura de la red en estudio y representarla de una manera simple mediante un conjunto de clases.

53
El package Topología fue el primer package desarrollado en el proyecto y en él se encuentran las clases con las que representamos los elementos de una red MPLS, que cuenta con los atributos necesarios para poder aplicar algoritmos de TE.
En la Figura 7.1 podemos ver el diagrama UML del package.
Figura 7.1: Diagrama UML del package Topología A continuación se describe más en detalle las clases anteriormente mencionadas.

54
7.2 La clase Elemento Esta clase define un objeto Elemento del cual heredarán los objetos LER, LSR y Link y define los atributos comunes a ellos. Esto sirve para poder referirnos a estos objetos como si fueran de la clase Elemento, y mantener así un nivel de abstracción. 7.3 Las clases LER y LSR Los LERs y LSRs representan dentro de nuestra arquitectura de red un elemento de poca complejidad, ya que cada instancia de ellos sólo lleva registros de los enlaces que en él convergen y los LSPs que por él pasan. Debido a esto es que cuando el usuario crea un nuevo nodo en la red no se desplegará ninguna ventana de configuración. Aunque las clases LER y LSR son muy similares, al tomar nuestro proyecto como referencia las redes MPLS es que se decidió crear dos clases por separado y no una sola, logrando por ejemplo que la representación en la interfaz gráfica sea distinta. 7.4 La clase Link La clase Link es el elemento fundamental de nuestra arquitectura de red. Esta clase concentra la mayoría de los atributos necesarios para hacer TE como ser capacidad, capacidad reservada, pesos administrativos, afinidades, etc. Cada instancia de Link representa una conexión bidireccional entre dos instancias de LER o LSR que recibe en su construcción y lleva un registro de los LSPs que por él pasan. La clase Link cuenta con métodos que permiten determinar si es un posible candidato para la creación de un nuevo LSP basado en el ancho de banda que tiene disponible mediante el ruteo explícito o corriendo alguno de los algoritmos desarrollados en el software. 7.5 La clase LSP La clase LSP, modela los caminos virtuales, que se pueden establecer en las redes MPLS y que permiten dirigir un flujo agregado de tráfico. Cada LSP consta de un vector de links, a la cual se le agrega el Nodo desde el cual se origina el LSP y el ancho de banda requerido, atributos necesarios a la hora de correr los distintos algoritmos de SNMP que en el software se implementan. 7.6 El Package Arca.InterfazGráfica Debido a que este package está exclusivamente relacionado con la compatibilidad entre el NET-TE y el ARCA, realizamos los comentarios sobre ésta relación en la sección 7.6.1.

55
7.6.1 Compatibilidad con ARCA - Analizador de Redes de Caminos Virtuales ARCA es el nombre del software que realizaron Darío Buschiazzo Malveira, Andrés Ferragut Varela y Alejandro Vázquez Paganini con motivo de su proyecto de fin carrera para el Instituto de Ingeniería Eléctrica de la Facultad de Ingeniería, Universidad de la República. El proyecto se llevó a cabo en el período comprendido entre el mes de Junio de 2003 y el mes de Mayo de 2004 en Montevideo, bajo la tutoría del Ing. Pablo Belzarena. El proyecto analiza el problema de brindar garantías de Calidad de Servicio (QoS), así como realizar Ingeniería de Tráfico sobre redes de datos. En dicho proyecto se desarrolló una herramienta de software que permite relevar el funcionamiento de una red dada, estimando parámetros de QoS permitiendo predecir el comportamiento de la red en presencia de carga y evaluar el impacto de diferentes políticas en dicho funcionamiento, así como conocer las garantías de QoS que la red está en condiciones ofrecer. Por ser un proyecto que está relacionado con el nuestro, es que se decidió hacer que sean compatibles en el sentido que un usuario podrá con nuestro software crear topologías que luego podrán ser usadas en el software ARCA. Cuando se decide guardar cierta topología con todas sus características (LSPs, nodos, enlaces, etc.) se abre una ventana en el que el usuario puede elegir guardarla con formato .txt o con formato .arc (de ARCA). El formato .txt es el formato elegido por nosotros para guardar las configuraciones, en las que simplemente se escriben en formato de texto simple los elementos de la red y atributos, que luego son leídos por el software para representarlas gráficamente. Cuando el usuario elige guardar la topología en formato .arc (de ARCA) para luego abrirla con el software ARCA, el software llama a un intérprete que lo que hace es “convertir” las clases de NET-TE en el formato específico que utiliza el ARCA. De este modo un usuario podrá abrir y guardar archivos en formato .arc para poder luego utilizarlos en el ARCA. En la Figura 7.2 podemos apreciar el diagrama UML de este package.

56
Figura 7.2: Diagrama UML del Package Arca.InferfazGráfica

57
Capítulo 8
Interfaz Gráfica Este capítulo se dedica en su mayoría a la interfaz gráfica de la aplicación. En el package Programa, se implementan las distintas ventanas que permitirán al usuario el acceso a las distintas funcionalidades que posee el software. Entre ellas se puede enumerar por ejemplo todo lo relacionado al abrir y guardar distintas configuraciones topológicas con sus respectivos parámetros; también la barra de herramientas ubicada a la derecha de la pantalla que es la principal herramienta para acceder a las utilidades del software; además, la ventana en la cual se introduce la información requerida para poder cargar la red automáticamente, así como las utilizadas para ver el estado actual de la red en cuanto a lo que utilización y características de los LSPs creados hasta el momento se refiere. Se procuró agrupar los botones de acuerdo a la tarea que cumplen: ingreso de elementos de red, algoritmos para el establecimiento de los LSPs y herramientas de visualización del estado actual de la red. Todo esto, por medio de una interfaz gráfica sencilla e intuitiva, que sea de fácil manejo para el usuario. Pasemos ahora a describir el package Programa. 8.1 El package Programa Las clases que contiene el package Programa definen las funcionalidades de la Interfaz de Usuario, y concentra todas las tareas referentes al despliegue del programa a través de una interfaz gráfica mediante el uso de elementos como ser ventanas, menúes, diálogos, etc. A continuación se presenta el diagrama de clases UML del package y luego se detallan las clases que lo componen.

58
Figura 8.1: Diagrama de clases del Package Programa 8.2 Clase Principal y VentanaConf La clase Principal genera el marco principal que contiene las barras de menú y herramientas con el que se pueden crear, abrir y modificar distintas topologías de red. La clase VentanaConf implementa los dos paneles principales del software que son el panel gráfico en el que se representan los elementos que componen la red y el panel que contiene los botones que implementan todas las funcionalidades del software como ser, crear elementos de red, ver estadísticas o correr distintos algoritmos de ingeniería de tráfico.

59
Figura 8.2: Marco Principal del software
8.3 Clase Intérprete
Esta clase permite al usuario generar un archivo de salida, que guarda en forma de texto todos los elementos de la red y sus atributos. De esta manera el usuario podrá simular varias topologías y guardar los diferentes estados de la red en un archivo .txt que luego podrá abrirlo para que la clase Intérprete lo convierta en elementos gráficos de una forma sencilla.

60
Formato del archivo según el elemento de red: Enlace Nodo LSP Link name Link_4 coord 208 125 372 87 connection LSR_1 LSR_2 ipinterfaz 10.10.10.1 bw 155.0 delay 0.0 down 0.0 peso 1.0 end
LSR name LSR_1 coord 208 125 routerid 10.10.10.1 ip 10.10.10.1 comunnity xxxxxxxx descubierto end
LSP name LSP_1 nodoOrigen LER_1 ancho 100.0 Link_8 Link_11 end
Observaciones: el atributo coord refiere a las coordenadas espaciales (x, y) que en que el elemento gráfico asociado al elemento se ubicará en la pantalla. End es utilizado por el intérprete para indicar que se terminaron los atributos del elemento. 8.4 Clases TxtFileFilter y ArcFileFilter Las clases TxtFileFilter y ArcFileFilter heredan de la clase javax.swing.filechooser.FileFilter y son filtros que al abrirse una ventana de diálogo del tipo jFileChooser cuando un usuario decide abrir o guardar un archivo, permiten que sólo se muestren los archivos con los formatos específicos de entrada-salida del software. La extensión .txt corresponde al formato de texto simple elegido para nuestro software y el formato arc corresponde al software ARCA. Ver Figura 8.3.
Figura 8.3: Formatos de salida del software

61
8.5 Clase ConfLink Esta clase implementa el marco en el cual el usuario podrá al crear un enlace nuevo en la red configurar todos sus atributos como ser el nombre, ancho de banda, peso asociado al enlace (usado como costo en CSPF) y afinidades. El mismo marco permite al usuario crear un nuevo tipo de afinidad que luego podrá ser utilizada en todos los enlaces de la red. Si en algún momento el usuario necesitase modificar alguno de los atributos, el software creará una nueva instancia a ésta clase, pero cargando los atributos actuales del enlace.
Figura 8.4: Ventana de configuración de enlaces Al usuario crear un nuevo Link se abre la ventana que se muestra en la Figura 8.4, asociando valores por defecto a los distintos atributos del nuevo enlace. El software cuenta los enlaces ya creados en la red y le asigna el nombre correspondiente. En la parte inferior de la ventana el usuario podrá asociar al enlace afinidades ya creadas en la red o crear una, escribiendo la nueva afinidad en el campo Escribir Afinidad. Esta nueva afinidad podrá luego ser asociada a todos los enlaces de la red. Se decidió agregar el concepto de afinidad a los enlaces de modo de restringir usar ciertos enlaces por ejemplo por tráfico del tipo Best Effort en enlaces críticos. De esta manera el usuario podrá correr CSPF y usar como restricciones las afinidades creadas en la red.

62
8.6 Clase Cargar Topología Esta clase implementa el marco en el cual el usuario podrá ingresar los parámetros necesarios para poder “descubrir” la topología en estudio.
Figura 8.5: Ventana Cargar Topología Algunos parámetros son obligatorios como la dirección IP de algún router de la red (casi siempre el que tiene directamente conectado), para comenzar la iteración hasta descubrir completamente la red. Otros parámetros obligatorios a ingresar, tal como se puede apreciar en la Figura 8.5 son la versión SNMP que se desea ejecutar, teniéndose como opciones en primera instancia la versión 1 y 2, pudiéndose agregar la versión 3 en futuras versiones. Luego, el “community” que es el password que utiliza SNMP, que es previamente configurado en los routers para impedir que se modifiquen los MIBs del router por personas no autorizadas. Si este password es mal configurado (o es distinto) en alguno de los routers el software lo reconocerá como un nodo que habla ospf pero no podrá conocer a sus vecinos (ya que no tiene acceso a él). Como opcionales se pueden modificar el puerto (por defecto 161 sino se ingresa ninguno), reintentos, timeout (también con valores por defecto en caso de no ser ingresados por parte del usuario) y continuar carga de red (para permitir se siga con la carga de la red una vez hallada una zona donde el community es distinto y deba ser ingresado nuevamente por el usuario). 8.7 Clases Estadísticas y Propiedades Estas clases son las que permiten al usuario conocer los atributos y estados de los elementos que componen la red en estudio. La clase propiedades es una ventana que muestra los atributos configurables de cada elemento de la red así como por ejemplo los

63
LSPs que pasan por el elemento, o en el caso de los enlaces su utilización. Ver Figura 8.6. Por otro lado la clase Estadísticas, genera un marco más general en el que se puede
Figura 8.6: Ventana Propiedades: a) para un enlace b) para un nodo ver el estado actual de la red como ser los atributos de los elementos de la red, ver los enlaces críticos y ver detalles de los LSPs establecidos en la red. Observar la Figura 8.7.
Figura 8.7: Ventana Estadísticas

64
8.8 Clase Utilización Es otra de las clases creadas que permiten al usuario conocer el estado de la red de una manera sencilla. La clase genera un marco al que el usuario puede ingresar valores que se toman como referencia para definir rangos de utilización. Luego se llama a un método que recorre todos los enlaces de la red y los pinta de un color que depende de la utilización actual del enlace. Observar Figura 8.8.
Figura 8.8: Ventana Utilización Esta ventana puede estar abierta siempre y con sólo apretar el botón Aceptar se reflejará de un modo rápido los cambios de utilización en los enlaces debido a los nuevos LSPs creados en la red.

65
Capítulo 9
Carga automática de la topología Tal como el nombre del capítulo lo indica, presentaremos ahora el package encargado de la funcionalidad de extraer la información necesaria de los routers para poder cargar la topología automáticamente, y no de manera manual tal como lo podría hacer el usuario al crear una topología desde cero o cargar una ya existente. 9.1 El package CargarRed - Implementación En nuestro caso cargar la topología de red se entiende como descubrir todos los routers presentes en la red que estén intercambiando información de ruteo mediante el protocolo de enrutamiento OSPF. Al ser OSPF un protocolo de estado de enlace cada router sólo conoce los routers de la red con los que forma adyacencias e intercambia información de ruteo (generalmente en ospf sólo se forman adyacencias entre los routers directamente conectados). Para conocer los vecinos de un router y las velocidades de las interfaces que lo conectan es necesario acceder a los MIBs de los routers, específicamente a los definidos en el RFC-1213 y en los OSPF-MIB. En la siguiente Figura 9.1 se pueden ver los grupos y tablas que lo componen.

66
OSPF-MIB DEFINITIONS RFC1213-MIB DEFINITIONS
Figura 9.1: Grupos y Tablas que componen los MIBs de OSPF y RFC-1213
Específicamente dada la red en la Figura 9.2, se conecta una PC con el software instalado a uno de los routers que hablan ospf, que sería el NMS si tenemos en cuenta la especificación del protocolo SNMP.
Figura 9.2: Ejemplo de una red
ospfGeneralGroup
ospfAreaTable
ospfStubAreaTable
ospfLsdbTable
ospfAreaRangeTable
ospfHostTable
ospfIfTable
ospfIfMetricTable
ospfVirtIfTable
ospfNbrTable
ospfVirtNbrTable
ospfExtLsdbTable
ospfRouteGroup
ospfAreaAggregateTable
ospfConformance
mib-2
system
interfaces
ifNumber
ifTable
at
ip
icmp
tcp
udp
egp
transmission
snmp
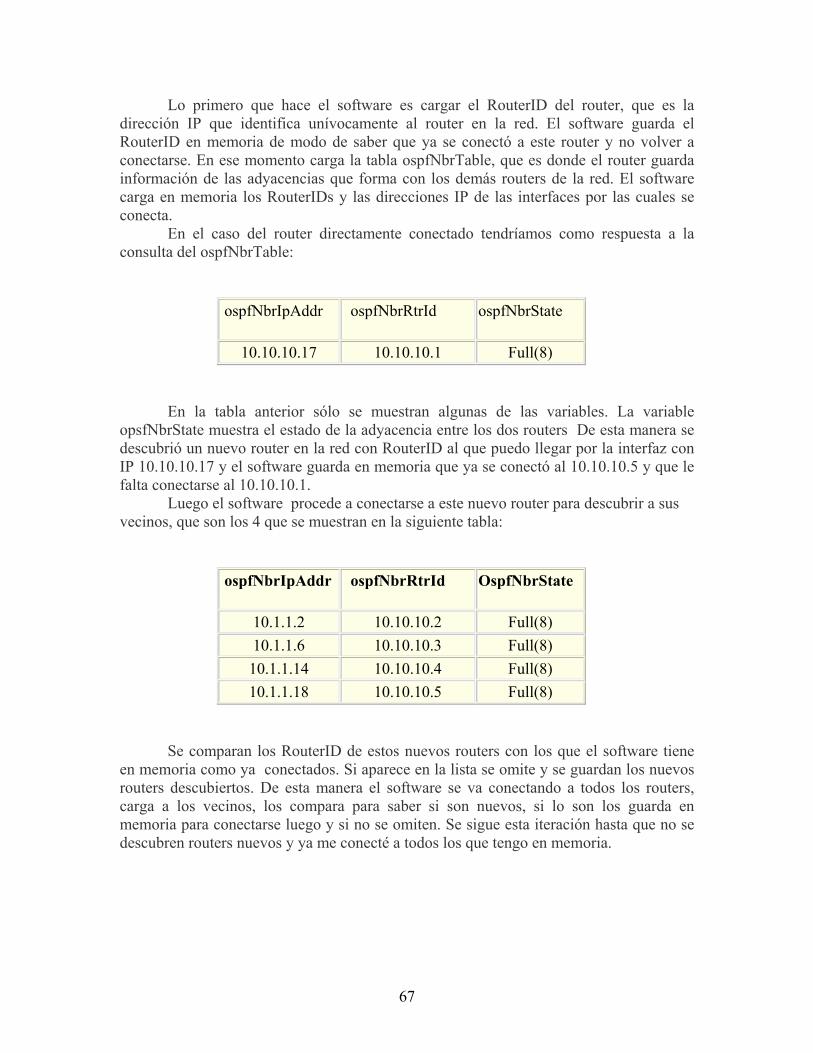
67
Lo primero que hace el software es cargar el RouterID del router, que es la dirección IP que identifica unívocamente al router en la red. El software guarda el RouterID en memoria de modo de saber que ya se conectó a este router y no volver a conectarse. En ese momento carga la tabla ospfNbrTable, que es donde el router guarda información de las adyacencias que forma con los demás routers de la red. El software carga en memoria los RouterIDs y las direcciones IP de las interfaces por las cuales se conecta. En el caso del router directamente conectado tendríamos como respuesta a la consulta del ospfNbrTable:
ospfNbrIpAddr
ospfNbrRtrId
ospfNbrState
10.10.10.17 10.10.10.1 Full(8) En la tabla anterior sólo se muestran algunas de las variables. La variable opsfNbrState muestra el estado de la adyacencia entre los dos routers De esta manera se descubrió un nuevo router en la red con RouterID al que puedo llegar por la interfaz con IP 10.10.10.17 y el software guarda en memoria que ya se conectó al 10.10.10.5 y que le falta conectarse al 10.10.10.1. Luego el software procede a conectarse a este nuevo router para descubrir a sus vecinos, que son los 4 que se muestran en la siguiente tabla:
ospfNbrIpAddr
ospfNbrRtrId
OspfNbrState
10.1.1.2 10.10.10.2 Full(8) 10.1.1.6 10.10.10.3 Full(8) 10.1.1.14 10.10.10.4 Full(8) 10.1.1.18 10.10.10.5 Full(8)
Se comparan los RouterID de estos nuevos routers con los que el software tiene en memoria como ya conectados. Si aparece en la lista se omite y se guardan los nuevos routers descubiertos. De esta manera el software se va conectando a todos los routers, carga a los vecinos, los compara para saber si son nuevos, si lo son los guarda en memoria para conectarse luego y si no se omiten. Se sigue esta iteración hasta que no se descubren routers nuevos y ya me conecté a todos los que tengo en memoria.

68
En resúmen, 1- Me conecto al primer router y lo guardo en las listas RoutersRed y RoutersDescubiertosNoConectados (en esta lista además guardo la IP por la que llegó al router) que al principio están vacías. 2- Cargo vecinos del router. 3- Para cada vecino: no está en RoutersRed, entonces se agrega a RoutersRed y RoutersDescubiertosNoConectados. 4- Elimino el router de RoutersDescubiertosNoConectados. 5- Si hay más routers en RoutersDescubiertosNoConectados, me conecto al primero de la lista y vuelvo a 2. Si RoutersDescubiertosNoConectados no tiene elementos, entonces ya descubrí toda la red y la lista de routers que la componen se encuentra en RoutersRed Un parámetro que es fundamental para correr algoritmos de TE es la capacidad de los enlaces. Estos se cargan de la tabla ifTable definida en el RFC 1213 que tiene el formato de la siguiente forma: ifIndex ifDescr ifType ifMtu ifSpeed ifAdminStatus ifOperStatus1 ATM4/0 sonet 4470 149760000 down down 2 FastEthernet0/0 ethernetCsmacd 1500 100000000 up up 3 FastEthernet1/0 ethernetCsmacd 1500 100000000 up up 4 Ethernet2/0 ethernetCsmacd 1500 10000000 down down 5 Ethernet2/1 ethernetCsmacd 1500 10000000 down down A la dirección IP que tiene asociada la interfaz se le asocia un número de interfaz (ifIndex). Esta asociación se encuentra en la tabla ospfAddrTable que también se carga al conectarse al router. Ya con el ifIndex entro al IfTable y cargo la capacidad del enlace. Veamos por último el diagrama UML del package CargarRed.

69
Figura 9.3: Diagrama UML del package CargarRed.

70
Capítulo 10
Computación de caminos El presente capítulo analiza los distintos mecanismos para la computación de caminos que van a ser futuros LSPs. Se destaca el algoritmo Constraint Shortest Path First (CSPF) utilizado para encontrar caminos basándose en el conocido algoritmo Shortest Path First (SPF) o Dijkstra, con el requerimiento extra de que debe satisfacer ciertas restricciones. Se le ofrecen al usuario además distintos criterios a aplicar de Ingeniería de Tráfico (TE), de manera que pueda optimizar el resultado arrojado por el CSPF, filtrando todas las soluciones posibles y dejando solamente las que más se aproximan a lo que desea. También se presenta otro algoritmo online para el establecimiento de rutas que es el MIRA. Se expone también el método manual en donde el usuario establece los LSP de manera explícita indicando el camino que desee. 10.1 El package CrearLSPs Este package esta conformado por 5 clases: Ruteo Explícito, CSPF, Algoritmo, CarConf y MIRA. Para poder visualizar mejor el relacionamiento entre dichas clases que componen este package, a continuación se muestra el diagrama UML del mismo.
Figura 10.1: Diagrama UML del package CrearLSPs

71
A continuación pasamos a describir en más detalle cada una de las clases mencionadas anteriormente.
10.2 La clase Ruteo Explícito Esta es la clase usada cuando el usuario de la red desea establecer los LSPs de manera manual, señalando enlace a enlace, cuál es el camino que desea conforme el LSP. Como cualquier otro LSP, al momento de desplegarse la ventana, se le asigna un nombre al LSP próximo a crearse. El usuario debe ingresar como parámetro de entrada el ancho de banda que desea tenga el LSP y cuál es el Nodo de Origen donde desea comience el LSP. Podemos observar a continuación en la Figura 10.2 una imagen de cómo luce la ventana desplegada.
Figura 10.2: Ventana usada para el Ruteo Explícito de un LSP.
Una vez ingresados ambos parámetros, el programa va desplegando en un combo la lista de enlaces que contienen en uno de sus extremos al Nodo Origen elegido y que cumplen con la condición del ancho de banda. Con esto último nos referimos a que sólo se despliegan los enlaces que contienen al nodo origen y cuyo ancho de banda disponible es mayor o igual al requerido por el futuro LSP. De la misma manera, a medida que el usuario va creando el LSP manualmente, en pantalla se va pintando con color el mismo, de manera que el usuario lo pueda apreciar también gráficamente. Finalmente una vez presionado Aceptar, se guardará automáticamente dicho LSP y se actualizarán los valores de ancho de banda disponibles en los enlaces que se vieron afectados.

72
10.3 La clase CSPF Esta clase es la usada para computar caminos para futuros LSPs por medio del algoritmo CSPF explicado en el Capítulo 4. Esta clase lo que básicamente hace es recolectar toda la serie de parámetros ingresados por el usuario, necesarios para determinar cuáles son las restricciones que desea cumpla el o los LSPs solución y qué criterio de ingeniería de tráfico desea usar. Posteriormente, de acuerdo a las opciones elegidas, pasa a llamar a la clase Algoritmo (explicada en la Sección 10.4) que es donde reside el método que implementa el Dijkstra y los demás métodos encargados de ejecutar el criterio de ingeniería de tráfico, si es que se eligió alguno. Son varias las distintas opciones que se le presentan al usuario al momento de ingresar los parámetros al sistema, de manera que pueda crear varias situaciones y analizar cuál es la que más le conviene. Esto claramente aumenta la cantidad de escenarios del tipo “what if” que puede plantearse. Todo esto con el objetivo de poder ofrecerle al usuario tantas herramientas como sea posible para conseguir la solución que más se ajuste a sus necesidades. Podemos observar el aspecto de la ventana creada por esta clase en la Figura 10.3.
Figura 10.3: Ventana CSPF

73
Empecemos señalando cuáles son los distintos parámetros que debe ingresar el usuario y las opciones que se le ofrecen para pasar luego a comentar ciertas características de cómo fue implementada la clase CSPF. Así como lo muestra la Figura 10.3, automáticamente que se abre la ventana el programa ya le asigna un nombre determinado al LSP a crearse. Paso siguiente, el usuario debe ingresar, como es usual, el ancho de banda que va a requerir el LSP que desea establecer. Asimismo tiene la posibilidad de elegir una Afinidad determinada, del grupo de Afinidades que hayan sido creadas. Esto permite al usuario el poder correr el algoritmo CSPF sólo sobre los enlaces que pertenecen a una determinada Afinidad, lo cual es práctico en caso de tener distintos tipos de tráficos circulando por los enlaces de la red y desear correr el algoritmo sólo sobre los que portan un determinado tipo. Finalmente, los siguientes parámetros obligatorios a ingresar son el Nodo de Origen y de Destino. Como comentario al margen, vale destacar que la ventana fué diseñada para que las opciones se vayan habilitando a medida que los parámetros vayan siendo ingresados en orden. Esto obliga al usuario a ingresar si o si los parámetros que son obligatorios para correr el Dijkstra o SPF. Ahora pasamos a la parte en donde el usuario debe elegir qué criterio usar para asignar los pesos a los enlaces. Esto es particularmente importante ya que determina la métrica en la cual se basará luego el SPF para el cálculo de los caminos solución. Las opciones presentadas son las siguientes;
• Ruteo Mínimo por Pesos Administrativos: en este caso se le asigna a cada
enlace un determinado peso que es elegido por el usuario. El peso en este caso es un valor numérico entero mayor que 0. Este valor es una manera de priorizar determinados enlaces frente a otros. Cuanto más grande este valor, menor será la probabilidad de que el camino pase por ese enlace. Básicamente el camino tendera a utilizar los enlaces con menor peso.
• Ruteo por Mínima Cantidad de Saltos: en este caso se le asigna un peso igual a 1 a cada enlace. De esta manera, al utilizar el Dijkstra, éste calcula los caminos basándose en la cantidad de saltos. Básicamente, se desplegará como resultado los caminos con la menor cantidad de saltos de origen a destino.
• 1/(Bwreservado): en este caso, tal como lo sugiere el nombre, asigno a los pesos el valor correspondiente a 1/(BW reservado). Esto quiere decir que los caminos solución tenderán a ir por los enlaces más ocupados (con menos ancho de banda disponible). De esta manera se intenta no usar los enlaces más libres (dejándolos para futuros LSPs), sino que terminar de ocupar los más utilizados.
• 1/(BWlibre): en este caso, tal como lo indica el nombre, asigno a los pesos el valor correspondiente a 1/(BW disponible). Esto quiere decir que los caminos solución tenderán a ir por los enlaces más libres, no molestando a los más ocupados. Es una manera de establecer los LSPs por lugares de baja utilización.

74
A continuación, una vez elegida la métrica que se va a tomar en cuenta, el usuario tiene la posibilidad de elegir un determinado enlace por el que pase el o los caminos solución si o si. De esta manera se obliga a las posibles soluciones que contengan determinado enlace aún cuando este no estaría contenido en los caminos arrojados por el Dijkstra. Además se le da también la posibilidad de lo opuesto, que no pase por determinado enlace, aún cuando éste estuviera contenido en los caminos arrojados por el Dijkstra. La razón de estas dos opciones es que quizás por razones políticas o de determinado Service Level Agreement (SLA), el usuario esté obligado a que se pase o no por determinado enlace. Por último, se le da la posibilidad al usuario de elegir entre no usar criterio de Ingeniería de Tráfico alguno, o usar dos posibles. De la primer manera, no se usa criterio de TE alguno, lo cual implica que las soluciones desplegadas al usuario serán las arrojadas por el algoritmo SPF en su totalidad y que cumplen con las restricciones elegidas por el usuario previamente. La segunda opción es usar un criterio de TE basado en filtrar los caminos solución brindados por el SPF y desplegar de entre esas soluciones, sólo aquellas que no utilizan a los enlaces más críticos contenidos en los caminos (de ahí el nombre “no saturación de enlaces críticos”). Y por último, se tiene el MINHOP, el cual, simplemente de todas las soluciones arrojadas por el SPF, se queda con las más cortas en cuanto a lo que a cantidad de saltos se refiere. Lo único que resta es correr el Algoritmo y se desplegarán en pantalla todas las posibles soluciones. En caso de haber elegido el segundo o tercer criterio de TE, se despliega en pantalla una ventana que muestra los caminos que fueron elegidos y los descartados luego de aplicar esos criterios de TE. Esta ventana muestra además la utilización y otros útiles datos de los enlaces que conforman los caminos elegidos y descartados. Se comentará más en detalle el algoritmo SPF, criterios de TE y la ventana mencionada anteriormente, en las próximas secciones. Pasemos ahora a comentar los métodos más importantes y características de la implementación de la clase CSPF. El primer método a destacar es el método podar(). Dicho método es el encargado de “podar” todos los enlaces de la red para pasar como parámetro de entrada al algoritmo SPF (Dijkstra) solamente a aquellos que cumplen con la condición del ancho de banda requerido y pertenecen al mismo tiempo a la Afinidad seleccionada en caso de haberse elegido una. Para el caso de haber elegido algún enlace del combo Enlace Ausente, simplemente retiro a ese enlace de la lista de enlaces a considerar que entran como parámetro de entrada al algoritmo SPF. La situación es más complicada cuando se elige un Enlace Presente. En este caso, se debe empezar dividiendo el problema en dos. En caso que no se elija esta opción, simplemente se redefinen los pesos de los enlaces de acuerdo a la opción de métrica elegida. Luego se corre el Dijkstra. Si encuentra una solución ya de entrada, entonces en ese caso ya la despliega en pantalla. Si se encuentra más de una, se pasa a fijar si se eligió algún criterio de TE en particular y de ser así, se aplica ese criterio y despliega en

75
pantalla el resultado conjuntamente con los datos de los caminos descartados, en caso de haberlos. Sin embargo en caso de haber elegido la opción Enlace Presente, se debe tener más cuidado en la manera de correr el Dijkstra y cómo hacerlo. Primeramente se redefinen los pesos de los enlaces de acuerdo a la métrica elegida. Se deben tomar en cuenta casos particulares como que uno de los nodos que conforman al Enlace Presente sea de casualidad el Nodo de Origen o Nodo de Destino, o que justo Enlace Presente sea el enlace que une al Nodo Origen con el Destino, en cuyo caso ya sería la solución. En todos estos casos en particular, se corre el SPF sólo 1 vez. Ahora, si no caemos en ninguno de estos casos en particular, entonces se deberá correr el SPF 4 veces. Si llamamos al Nodo Origen, nodoA; y al Nodo Destino, nodoB. Y supongamos que los nodos que conforman a Enlace Presente son nodo1 y nodo2. Entonces se corre primero el Dijkstra entre el NodoA y el nodo1 y luego entre el nodo2 y el NodoB. Así se deben tomar en cuenta todos los posibles caminos que surjan en cada pasada del Dijkstra, y en caso de haber un error en alguna pasada, también se debe tomar en cuenta ya que quizás no se encuentre camino alguno. Se agrega el Enlace Presente entonces a cada una de todas las posibles combinaciones que surjan entre todas las soluciones encontradas en las 2 pasadas. Posteriormente, corremos el Dijkstra entre el nodoA y el nodo2 y luego entre el nodo1 y el nodoB. Acá tomamos también en cuenta todos los caminos posibles que surjan en cada pasada. Y repetimos el razonamiento. En caso de haber encontrado soluciones en el primer par de pasadas del Dijkstra y en el segundo, se deben juntar todas y ésa es la solución a mostrar. En todo caso se deberá tener especial cuidado con la aparición de errores en alguna pasada debido a la no existencia de una solución. Finalmente, recurre a la clase Algoritmo en caso de haber más de una solución posible arrojada por el SPF y elegido algún criterio de TE en particular. Una vez elegida la solución deseada, quedará guardada con el resto de los LSPs ya establecidos. 10.4 La clase Algoritmo En esta clase se encuentra la implementación del algoritmo Dijkstra, y los de SNMP SNMP. En cuanto al algoritmo de Dijkstra, éste es implementado por medio del método shortestPath(), el cual es encargado de calcular todos los caminos solución del origen a destino, con la métrica más chica. Recibe como parámetros de entrada, la lista de nodos de la red a tomar en cuenta, la lista de enlaces, el Nodo Origen y Destino y una variable booleana que indica si fue elegida la opción de Enlace Presente. Ya ambas listas de nodos y enlaces fueron filtradas con las restricciones de ancho de banda y Afinidad ingresadas por el usuario. Otro método a destacar es el podar2(). Este es encargado de aplicar el segundo criterio de TE (no saturación de enlaces críticos). Básicamente lo que procura es descartar a aquellas soluciones que poseen los enlaces más críticos. Con eso nos referimos a aquellos enlaces que están casi saturados y que poseen muy poco ancho de banda disponible, lo cual causaría que de pasar el LSP por ellos, queden prácticamente inutilizables para futuros LSPs. Lo que se hace es tomar de cada camino solución

76
arrojado por el Dijkstra, el enlace con menor ancho de banda disponible (llamemos enlaceCrítico al valor de ancho de banda de dicho enlace). Se compara cada enlaceCrítico de cada solución y se descartan los caminos con el enlaceCrítico más pequeño. En caso de quedar aún más de una solución posible, significa que el enlaceCrítico para cada uno de estos caminos tiene el mismo valor. Entonces se pasa a ver cuántos enlaces en cada uno de esos caminos, tienen un ancho de banda similar al guardado en enlaceCrítico. Los caminos que tengan más cantidad de enlaces con ese valor, se descartan (ya que se estaría perjudicando a un número mayor de enlaces en esos caminos). Y si aún después de eso, seguimos con más de una posible solución, buscamos el siguiente valor más pequeño que sea mayor que enlaceCrítico y redefinimos enlaceCrítico para cada solución. Repetimos así el proceso iterativamente hasta quedarnos con una solución solamente o con varias que sean indistintas unas de las otras en lo que a este criterio se refiere. Por último, se debe destacar el método podar3(), el cual se encarga de filtrar también las soluciones arrojadas por el Dijkstra, quedándose sólo con las más cortas en cuanto a lo que número de saltos se refiere.
10.5 La clase CarConf Esta clase es la que implementa la ventana que se despliega cuando tenemos más de un camino posible y se eligió algún criterio de TE en particular. Podemos apreciar la ventana en la Figura 10.4.
Figura 10.4: Ventana CarConf
Presenta dos botones. Uno de ellos muestra los caminos que son solución luego de aplicar alguno de los criterios de TE. El otro muestra información sobre los caminos que

77
fueron descartados (éstos son los caminos que pertenecían a la solución brindada por el Dijkstra, pero que no cumplieron el requerimiento de TE elegido). La información desplegada es la siguiente para cada camino: los enlaces que conforman dicho camino, la capacidad de cada uno de los enlaces, la cantidad de Mbps que está siendo usada en ellos y el porcentaje de utilización. 10.6 La clase MIRA Debido a los packages ya utilizados en nuestro software se decidió calcular el MNF corriendo el SPF repetidamente y actualizando el MNF hasta que no se encuentren caminos y por ende ancho de banda disponible entre los dos nodos en cuestión. Existen varios algoritmos para calcular el MNF como el presentado por Goldberg Tarjan [8] o el algoritmo de Gomory-Hu [9], pero debido a lo complejo de estos algoritmos se optó por una solución más sencilla pero computacionalmente más costosa. Por más información referirse al Capítulo 5. La implementación de la ventana usada para el algoritmo MIRA se comenta en el Capítulo 11.

78
Capítulo 11
Algoritmos de justicia y el MIRA En este capítulo se analiza el package MT. El mismo tiene varias tareas de las cuales es responsable. En primer lugar, se encarga de crear la Matriz de Tráfico (MT) que contiene todas las demandas y sus respectivos anchos de banda. En caso de que ya exista un archivo de MT, se implementó un Intérprete que pudiera leer dicho archivo y lo cargue en el software. Se muestra el formato de salida del archivo MT. También contiene los tres algoritmos implementados para el cálculo de caminos en las llamadas redes justas. Con esto se trata de ofrecerle al usuario distintos criterios en la búsqueda de caminos para el establecimiento de los LSPs de manera de poder distribuir todas las demandas solicitadas de la mejor manera posible. En la búsqueda de ese mismo objetivo se presenta también la ventana que implementa el algoritmo online MIRA. 11.1 El package MT
El package MT concentra todas las tareas referentes a calcular los mejores caminos posibles para la topología de red cargada y una matriz de tráfico dada. En este package se encuentran las clases con las que representamos los caminos encontrados para cada ruta y cuenta con los atributos necesarios para poder asignar el ancho de banda a cada camino de forma justa. La ruta indica entre qué nodos, qué ancho de banda y qué afinidad deberá tener el LSP que se quiere establecer y el camino indica por los enlaces deberá pasar el LSP. En la siguiente figura podemos ver el diagrama UML del package:

79
Figura 11.1: Diagrama UML del package MT. A continuación se describe más en detalle las clases anteriormente mencionadas. 11.2 La clase Caminos La clase Caminos, modela el camino virtual que se puede establecer para una ruta dada. Cada camino consta de un nombre, nodo origen, nodo destino, ancho de banda deseado, ancho de banda final (es el ancho de banda que se le asigna al camino), afinidad y de un arraylist enlacesGr (en donde se guardan los enlaces por donde pasa el camino). Tiene dos atributos más que son prioridad (es la prioridad del camino, por defecto es 1) y demandamin (demanda mínima del camino, por defecto es 0), estos atributos sólo son usados en la clase FairnessNetwork al elegir el método algoritmo2() (correspondiente al Fairness acotado). 11.3 La clase InterpreteMT Esta clase permite al usuario generar un archivo de salida, que guarda en forma de texto una lista de rutas con sus atributos que representan la matriz de tráfico. De esta manera el usuario podrá simular para una topología dada y posibles variantes de ésta, como quedan los LSPs para la misma matriz de tráfico.

80
11.4 La clase GeneroMT Esta clase implementa el marco en el cual el usuario podrá crear el archivo que representa la matriz de tráfico. Al crear cada ruta se debe configurar sus atributos como ser el nombre (tiene por defecto Ruta seguido de un número que se incrementa al crear una ruta nueva), ancho de banda deseado, nodo origen, nodo destino y afinidad (es opcional, el camino sólo puede pasar por los enlaces con esa afinidad).
Figura 11.2: Ventana GeneroMT A cada ruta creada se le puede modificar todos sus atributos excepto el nombre, o se puede borrar la ruta completa. El archivo que se crea es con terminación “.txt” y será usado por las clases FairnessNetwork y OffLineMira y también por GeneroMT cuando se desea modificar un archivo de matriz de tráfico ya creado. Formato del archivo:
Matriz de tráfico Camino name Ruta_1 connection LER_1 LER_2 ancho 1.0 afinidad: no tiene end

81
El archivo comienza con Matriz de tráfico que es utilizado por el intérprete para indicar que es un archivo generado por la clase GeneroMT. End es utilizado por el intérprete para indicar que se terminaron los atributos del elemento. 11.5 La clase FairnessNetwork Esta clase permite al usuario correr los distintos algoritmos Fairness, comparar sus resultados para después crear los LSPs para las distintas rutas. Primero se llama al método que carga el archivo de matriz de tráfico al oprimir el botón Cargar Matriz y se llama al método shortestPath() de la clase Algoritmo que calcula todos caminos posibles con la menor métrica para las distintas rutas de la matriz de tráfico.
Figura 11.3: Ventana FairnessNetwork
Después de calcular todos los caminos posibles para cada ruta, se elige uno de los cuatro algoritmos Fairness. Se selecciona la métrica a utilizar entre Peso o Minhop y al apretar el botón Correr se calcula el ancho de banda final de cada camino. Para los últimos dos algoritmos no se usan los parámetros Peso o Minhop, por lo que no se habilitan en ése caso. También, en caso de elegir uno de los dos primeros algoritmos, si existen varios caminos posibles para cada demanda, se le ofrece la posibilidad al usuario de elegir el que desee por medio del combobox Caminos posibles. Los métodos algoritmo1() (que implementa el Fairness Básico) y algoritmo2() (que implementa el Fairness acotado) usan un sólo camino de los calculados para cada ruta a diferencia del algoritmo3() (que implementa el Fairness con múltiples caminos) y algoritmo4() (que implementa el Fairness con múltiples caminos acotado) que usan todos los caminos calculados para cada ruta.

82
El método algoritmo1() corre el método buscar() que cuenta los caminos que pasan por cada enlace y el método mínimo1() que incrementa el ancho de banda reservado de todos los enlaces por donde pasa algún camino, esto lo hace hasta que satura al menos un enlace de cada camino, a ese enlace le fija su ancho de banda. El método termina cuando todos caminos tienen fijo su ancho de banda. El ancho de banda final de cada camino puede ser menor, igual o hasta mayor que el ancho de banda deseado. El método algoritmo2() corre el método buscar(), pero antes de llamar al método mínimo1() se abre una ventana que genera un marco donde el usuario puede ingresar los valores de prioridad y demandamin de cada ruta.
Figura 11.4: Ventana para el Fairness acotado Después se crean por cada camino un enlace virtual con el ancho de banda deseado para esa ruta y se llama método mínimo1(). Los enlaces virtuales creados no se muestran en pantalla y son necesarios para que el ancho de banda final de cada camino no sea mayor que el ancho de banda deseado. Estas diferencias con el método algoritmo1() permiten que el ancho de banda final de cada camino sea como mínimo igual a demandamin y como máximo igual al ancho de banda deseado. El método algoritmo3() corre el método calculatodos() que calcula todos los caminos posibles para cada ruta, sin considerar métrica alguna, ni el ancho de banda de los enlaces. Después corre los siguientes métodos creaMatrizFairLink(), OptimizacionLineal(), OptimizacionLinealChequeo(). Estos métodos son los encargados de maximizar las demandas, asignando a cada sub-demanda el ancho de banda calculado. El ancho de banda final de cada demanda es la suma de los anchos de banda de sus sub-demandas. El método algoritmo4() corre los métodos calculatodos(), creaMatrizFairLink(), OptimizacionLineal(), OptimizacionLinealChequeo(), igual que en el algoritmo3(). La única diferencia es que después de tener calculado el ancho de banda final de todas las demandas y sub-demandas, busca las demandas que su ancho de banda final supera el ancho de banda deseado y setea éste igual al ancho de banda deseado.

83
Esto lo hace seteando el ancho de banda final de cada sub-demanda de forma que la suma de éstas no supere el ancho de banda deseado de la demanda a la que pertenecen. Se pueden correr los cuatro algoritmos sin cerrar la ventana y así poder comparar los resultados obtenidos para cada uno de ellos. Los resultados obtenidos de cada ruta para el algoritmo seleccionado se pueden ver al elegir una ruta de Lista de rutas. En pantalla muestra los enlaces por donde pasa y en la misma ventana muestra sus atributos como se observa en la siguiente figura.
Figura 11.5: Ventana que despliega resultados Para el caso del tercer y cuarto algoritmo, donde se pueden tener múltiples caminos para cada ruta, se muestran en la pantalla ubicada a la izquierda, las sub-demandas o caminos que conforman cada ruta. Al hacer click en cada camino, se pinta en pantalla el mismo y en la pantalla de la derecha se muestran sus atributos en particular. Si se quieren apreciar todos los caminos que constituyen cierta demanda al mismo tiempo, nuevamente, conjuntamente con sus atributos, basta hacer click en la ruta deseada otra vez. Aquellas demandas que no llegan a obtener el ancho de banda requerido, se pintarán de color rojo a rayas en pantalla, para su diferenciación.
11.6 La clase LasDemandas Esta clase se encarga de desplegar una ventana cuando se elige el tercer algoritmo de fairness (fairness con múltiples caminos). La misma exhibe datos numéricos sobre cada una de las demandas, de manera que sea más fácil para el usuario el poder apreciar cuáles demandas llegó a satisfacer y sobrepasar el ancho de banda requerido, y cuáles no. Los datos que despliega son los siguientes: nombre de la ruta o demanda, ancho de banda deseado, ancho de banda final, diferencia de ancho de banda (la resta entre los dos valores anteriores) y cantidad de caminos o sub-demandas que contiene cada ruta.

84
Figura 11.6: Ventana de la clase LasDemandas
11.7 La clase OfflineMira Esta clase implementa el marco en el cual el usuario podrá correr el algoritmo MIRA para una matriz de tráfico previamente configurada y guardada en un archivo .txt con el formato que se explicó anteriormente. Luego de haber cargado la matriz de tráfico el usuario tiene que elegir cuáles son los pares de nodos que se van a tomar como referencia como los futuros generadores de LSPs en el sector de la ventana Nodos ingreso-egreso. El usuario puede optar entre tres opciones, todos los nodos de la red, sólo los LER`s o elegirlos manualmente.
Figura 11.7: Ventana configuración MIRA
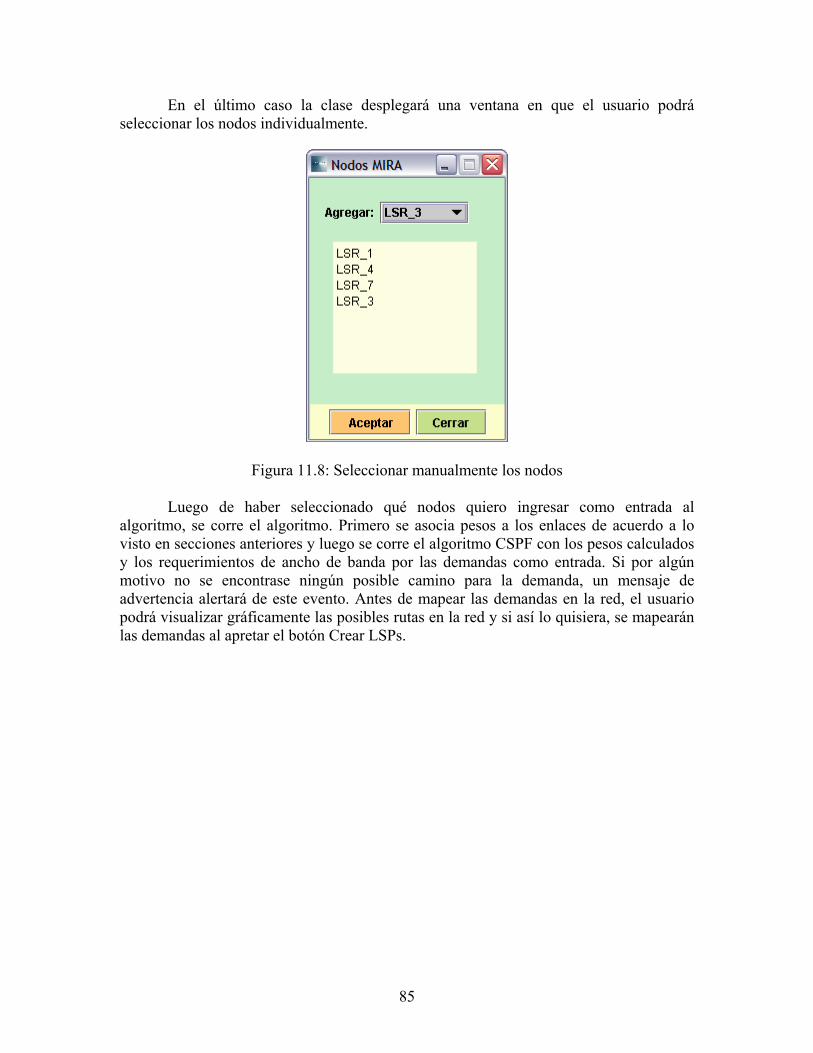
85
En el último caso la clase desplegará una ventana en que el usuario podrá seleccionar los nodos individualmente.
Figura 11.8: Seleccionar manualmente los nodos Luego de haber seleccionado qué nodos quiero ingresar como entrada al algoritmo, se corre el algoritmo. Primero se asocia pesos a los enlaces de acuerdo a lo visto en secciones anteriores y luego se corre el algoritmo CSPF con los pesos calculados y los requerimientos de ancho de banda por las demandas como entrada. Si por algún motivo no se encontrase ningún posible camino para la demanda, un mensaje de advertencia alertará de este evento. Antes de mapear las demandas en la red, el usuario podrá visualizar gráficamente las posibles rutas en la red y si así lo quisiera, se mapearán las demandas al apretar el botón Crear LSPs.

86
Parte IV
Conclusiones

87
Capítulo 12
Conclusiones y tareas a futuro 12.1 Supuestos y objetivos El único supuesto que podemos considerar importante al momento de instalar el software, es que se debe hacer sobre una red MPLS cuyos routers manejen el protocolo de ruteo OSPF. Este supuesto es necesario en caso de desear utilizar NET-TE para levantar la red en forma automática y desplegarla en pantalla. La hipótesis sobre la red MPLS no afecta ninguna otra funcionalidad del software, ya que es principalmente una herramienta de trabajo offline, usada por el usuario para analizar distintos métodos de búsqueda de caminos para el establecimiento de LSPs. En cuanto a los objetivos marcados durante el desarrollo de este proyecto, éstos se fueron dando a medida que el proyecto avanzaba, no teniéndolos determinados desde un principio. Antes de empezar a trabajar formalmente en el proyecto, sabíamos que la idea era en rasgos generales, el crear un software que le permitiera al usuario el visualizar su red y poder brindarle ciertos mecanismos de ingeniería de tráfico al momento de establecer los LSPs a modo de poder satisfacer los distintos niveles de QoS solicitados. Llegado el final de este proyecto y mirando hacia atrás, podemos ahora distinguir claramente cuatro distintos objetivos. El primero fue el desarrollar una herramienta que permita la creación de una red, visualizar su estado actual y poder modificarla de acuerdo a las necesidades del usuario. El segundo fue el ofrecer varios algoritmos que permitieran al usuario distintas posibilidades de por dónde rutear el LSP que cubrirá a cada nueva demanda entrante a la red, de manera que se ajuste de la mejor manera a sus necesidades. Esto es para el caso donde tenemos una red con varios LSPs ya establecidos y queremos determinar por dónde irán los nuevos LSPs a medida que llegan una a la vez las nuevas demandas. Como tercer objetivo, se tuvo el implementar otros algoritmos que permitan, a diferencia de los anteriores, el poder considerar todas las demandas de la red en forma conjunta y ubicarlas de la mejor manera posible en la red, de tal manera que se vean todas cubiertas, o en caso de no ser posible, el cubrirlas de la manera más “justa” a todas ellas. Finalmente, como cuarto y último objetivo, se planteó la incorporación de una funcionalidad que le permitiera al usuario el poder levantar la red a la que está conectado de manera automática y visualizarla en pantalla. Es importante destacar que en todo momento, con respecto a la validación de los datos que son devueltos al aplicar los distintos algoritmos de Fairness, se comprobó su correcto funcionamiento basándose en distintas pruebas y ensayos realizados por nuestra parte. También se comparó con ejemplos de los cuales ya se conocían de manera confiable los resultados y viendo así que obteníamos los valores esperados. Finalmente, en cuanto a la escalabilidad de los algoritmos a medida que la red crece de tamaño, pudimos corroborar en la práctica, que el tercer y cuarto algoritmo de fairness son los que consumen más tiempo de operación debido a la gran cantidad de iteraciones que se realizan. De cualquier manera, probamos con topologías de 30 nodos aproximadamente, y vimos que el tiempo que demora en desplegar los resultados es

88
prácticamente al instante y no considerable (poco más de un par de segundos cuando máximo). 12.2 Conclusiones En cuanto a los objetivos planteados, podemos decir que se llegó a cumplirlos todos de manera satisfactoria. Se logró implementar una interfaz gráfica sencilla y fácil de usar por cualquier usuario, la cual le otorga una amplia flexibilidad al momento de diseñar o modificar su red. Además, se le brindó al usuario varios mecanismos para poder visualizar el estado actual de la red, pudiendo ver información de elementos en particular o de la red en general. Pensando en la comodidad del usuario en la manera de cómo apreciar esa información, se brinda toda esa información tanto en forma numérica como gráfica. El problema del establecimiento de los LSPs fue solucionado utilizando el algoritmo CSPF. Realizamos varias pruebas sobre distintas topologías y situaciones, y pudimos apreciar el correcto funcionamiento del mismo. Pudimos también comprobar que es muy útil el tener varias opciones a elegir, ya que esto nos permitió crear múltiples escenarios y tener así un abanico más grande de soluciones de entre las cuales elegir. También pudimos comprobar la gran utilidad que ofrece el algoritmo MIRA. Se hicieron pruebas de chequeo sobre topologías en las cuales habían claramente ciertos enlaces que eran críticos para futuras posibles demandas, y pudimos apreciar como el algoritmo tendía a evitar dichos enlaces críticos. Finalmente, nos planteamos escenarios donde el algoritmo CSPF no encontraba ningún camino posible para ubicar a cierta nueva demanda, y probamos en ese caso los algoritmos de fairness. Pudimos apreciar con éxito como, con el uso de éstos últimos, se lograba ubicar esa demanda sobre la red, cosa imposible de realizar usando el CSPF. Además, comprobamos con éxito como NET-TE lograba asignar los recursos de una manera justa en aquellos casos donde no era posible satisfacer por completo a todas las demandas. Con respecto a la carga automática de la red, se pudo comprobar con éxito su funcionamiento en la red multiservicio del PDT desde el IIE de la Facultad. Se conectó una laptop que tenía el software NET-TE instalado, a la red. Una vez conectada, y luego de ingresar la información requerida, se pudo apreciar en consola, como el software se conectaba a los routers vecinos e iba descubriendo la red. Finalmente, y tal como era de esperarse, se dibujó en pantalla la topología descubierta. Debido a restricciones de seguridad, no pudimos descubrir la red entera, ya que sólo teníamos visibilidad hasta los routers más próximos de la PC de donde estabamos conectados. De cualquier manera se pudo comprobar el correcto funcionamiento de esta funcionalidad. Es por todo lo anterior que creemos que NET-TE es una útil herramienta que puede ser usada por cualquier usuario que desee realizar pruebas y crear distintos escenarios de Ingenieria de Tráfico, sin temor de afectar de alguna manera la red real, ya que se está en todo momento trabajando sobre escenarios de prueba y no sobre la red en cuestión. Como conclusión global se puede afirmar que se lograron realizar con éxito todos los objetivos trazados, juntando diversos criterios y algoritmos para el establecimiento de

89
LSPs en un sólo software, el cual puede ahora ser usado como pilar para el desarrollo de un software más completo y grande, que agregue más funcionalidades a las ya presentes. 12.3 Tareas a futuro Si bien se completaron todos los objetivos trazados, existen varias cosas que se pueden agregar, de manera que el usuario tenga aún más posibilidades y algoritmos a los cuales acceder. En cuanto a la carga automática de la red, actualmente NET-TE se encarga solamente de levantar la topología conjuntamente con la velocidad de cada enlace. Son varios los datos que un usuario puede querer extraer de la red. En primer lugar, podría levantar y mostrar los estados de las adyacencias entre nodos de la red. En esta primera versión del software, no nos preocupamos de dichos estados. También se podría levantar las métricas de OSPF y el ancho de banda libre de los enlaces. Uno de los datos más útiles que interesaría extraer en una posible segunda versión del software, son los LSPs ya establecidos. Datos como el ancho de banda que consume cada uno de esos LSPs, o la afinidad que presenta tal o cual enlace, pueden resultar muy útiles, en especial ya que son usados como datos de entrada en los algoritmos implementados en NET-TE. A su vez, el avisar de cambios en los estados de las adyacencias entre nodos, mediante los traps de SNMP, resultaría bastante práctico. Otra posible tarea a realizar a futuro, es aumentar la variedad de algoritmos usados para el cálculo de los LSPs. Se pueden agregar tantos algoritmos como el usuario desee y que se ajusten a sus necesidades particulares. Asimismo, se pueden agregar nuevos pesos, que por ejemplo reflejen el delay de cada enlace, y calcular así el CSPF en base al retardo de los mismos. Por último, actualmente NET-TE lo que nos permite es cargar la topología de la red y extraer la velocidad de los enlaces, para así luego determinar dónde se ubicarán cada uno de los LSPs de manera que se logre la QoS requerida. Pero no hay una forma de “arrojar” esos LSPs a la red real. Por ende, una útil implementación en futuras versiones, es desarrollar una interfaz que permita cargar en los routers de la red real los LSPs que fueron calculados por NET-TE durante las distintas pruebas. De esa manera se cerraría el ciclo que comienza con la carga automática de la red conjuntamente con los LSPs ya establecidos, continúa con el cálculo realizado por NET-TE de las nuevas rutas que satisfacerán las nuevas demandas y finaliza con la descarga de dichos LSPs a los routers de la red, de manera que se vean reflejados los cambios y nuevas rutas establecidas.

90
Apéndices

91
Apéndice A
Multi Protocol Label Switching (MPLS) MPLS es un estándar emergente del IETF (RFC 3031) que surgió para consensuar diferentes soluciones de conmutación multinivel, propuestas por distintos fabricantes a mitad de los 90s. Ante todo, debemos considerar MPLS como el avance más reciente en la evolución de las tecnologías de routing y forwarding en las redes IP, lo que implica una evolución en la manera de construir y gestionar estas redes. Los problemas que presentan las soluciones actuales de IP sobre ATM, tales como la expansión sobre una topología virtual superpuesta, así como la complejidad de gestión de dos redes separadas y tecnológicamente diferentes, quedan resueltos con MPLS. Al combinar lo mejor de cada nivel (la inteligencia del routing con la rapidez del switching) en un único nivel, MPLS ofrece nuevas posibilidades en la gestión de backbones, así como en la provisión de nuevos servicios de valor añadido. A.1 Descripción funcional de MPLS La base del MPLS está en la asignación e intercambio de etiquetas, que permiten el establecimiento de los LSP por la red. Cada LSP se crea a base de concatenar uno o más saltos (hops) en los que se intercambian las etiquetas, de modo que cada paquete se envía de un "conmutador de etiquetas" (Label-Swiching Router) a otro, a través de la red MPLS. Un LSR no es sino un router especializado en el envío de paquetes etiquetados por MPLS. MPLS separa las dos componentes funcionales de control (routing) y de envío (forwarding). Del mismo modo, el envío se implementa mediante el intercambio de etiquetas en los LSPs. Sin embargo, MPLS no utiliza ninguno de los protocolos de señalización ni de encaminamiento definidos por el ATM Forum; en lugar de ello, en MPLS o bien se utiliza el protocolo RSVP o Label Distribution Protocol, LDP, del que se tratará más adelante). Pero, de acuerdo con los requisitos del IETF, el transporte de datos puede ser cualquiera. Si éste fuera ATM, una red IP habilitada para MPLS es ahora mucho más sencilla de gestionar que la solución clásica IP/ATM. Ahora ya no hay que administrar dos arquitecturas diferentes a base de transformar las direcciones IP y las tablas de encaminamiento en las direcciones y el encaminamiento ATM: esto lo resuelve el procedimiento de intercambio de etiquetas MPLS. El papel de ATM queda restringido al mero transporte de datos a base de celdas. Para MPLS esto es indiferente, ya que puede utilizar otros transportes como Frame Relay, o directamente sobre líneas punto a punto.

92
A.2 Componentes y funcionamiento de una red MPLS Los dispositivos que participan en un ambiente como éste pueden clasificarse en routers frontera de etiquetas (LER) y en routers de conmutación de etiquetas (LSR). Un LER es un dispositivo que opera en los extremos de las redes MPLS y funciona como el punto de interconexión entre ésta y la red de acceso. Cuando un paquete llega a uno de estos routers, el LER examina la información entrante y, de acuerdo con una base de datos, asigna al paquete una etiqueta. En el extremo de salida de una red MPLS se presenta la situación opuesta, siendo estos dispositivos los responsables de remover la etiqueta para entregar el paquete en la forma en que fue recibido. Después de que los paquetes han sido etiquetados por el LER, éstos comienzan su viaje a través de la red MPLS, encontrándose en su trayectoria con los routers de conmutación de etiquetas (LSRs). Estos son los encargados de dirigir el tráfico en el interior de la red, de acuerdo con las etiquetas asignadas. Cuando un paquete arriba a un LSR, éste examina su etiqueta y la utiliza como un índice en una tabla propia que especifíca el siguiente "salto" y una nueva etiqueta. El LSR intercambia entonces ésta etiqueta por la que contenía el paquete y lo envía hacia el siguiente router. La ruta que sigue un paquete entre dos nodos de la red MPLS se conoce como ruta conmutada de etiquetas (LSP). En la Figura A.1 se puede observar el esquema funcional de MPLS.
Figura A.1: Esquema funcional de MPLS

93
Como se comentó anteriormente, los LERs se encargan de clasificar paquetes con base en un nivel de calidad de servicio. A este proceso de clasificación se le conoce como Clase Equivalente de Direccionamiento (FEC, por sus siglas en inglés). Un FEC es la representación de un conjunto de paquetes que comparten los mismos requerimientos para su transporte, de manera que todos los paquetes que pertenezcan a un FEC seguirán el mismo LSP para llegar a su destino. Contrario a lo que sucede en el enrutamiento IP convencional, la asignación de un paquete a un determinado FEC en MPLS se hace una sola vez. Los LERs utilizan diferentes métodos para etiquetar el tráfico. Bajo el esquema más simple, los paquetes IP son ligados a una etiqueta y a un FEC utilizando tablas preprogramadas como la que se muestra en la Figura A.2. Cuando los paquetes abandonan el LER e ingresan al LSR correspondiente, la etiqueta MPLS es examinada y comparada contra una tabla de conectividad conocida como Base de Información de Etiquetas (LIB) para determinar la acción a seguir. El intercambio de instrucciones se llevará a cabo dependiendo de las instrucciones del LIB. Un ejemplo de esta tabla de conectividad se muestra en la Figura A.3. Debe señalarse que las etiquetas poseen únicamente un significado local dentro del router correspondiente.
Figura A.2: Ejemplo de una tabla preprogramada para LERs.
Figura A.3: Ejemplo de un LIB para LSRs. Un router frontera lleva a cabo distintas funciones de análisis: mapear un protocolo de la capa 2 del modelo OSI a MPLS, mapear MPLS a la capa 3 del modelo y clasificar el tráfico con gran flexibilidad. Adicionalmente, un LER define qué tráfico deberá ser tratado como MPLS y qué paquetes deberán tratarse como tráfico IP ordinario. A diferencia de un encabezado IP, las etiquetas en MPLS no contienen una dirección IP, sino más bien un valor numérico acordado entre dos nodos consecutivos para proporcionar una conexión a través de un LSP. La etiqueta es un identificador corto de longitud fija empleado para asociar un determinado FEC, normalmente de significado local.

94
Algunas etiquetas o encabezados de determinados medios de transporte pueden utilizarse como etiquetas de MPLS. Tal es el caso del identificador de ruta virtual/identificador de circuito virtual (VPI / VCI) empleado en ATM y el identificador de conexión de enlace de datos (DLCI) de Frame Relay. Otras tecnologías, como Ethernet y enlaces punto a punto, requieren de una "etiqueta de inserción" (shimlabel) que se ubica entre el encabezado de la capa de enlace de datos y el encabezado de la capa de red (capas 2 y 3) del modelo OSI de un paquete. Aún cuando la "etiqueta de inserción" no es parte de ninguno de estos encabezados, ésta provee un medio de relación entre ambas capas.
Figura A.4: Esquema de una etiqueta MPLS La etiqueta MPLS tiene una longitud de 32 bits divididos en cuatro secciones. Los primeros 20 bits corresponden a la etiqueta en sí. Los 3 bits que siguen son considerados de uso experimental. El siguiente bit es utilizado para denotar la presencia de "stack" y, finalmente, los 8 bits restantes indican el tiempo de vida del paquete, es decir, un parámetro que decrementa su valor por cada nodo recorrido hasta llegar a cero. Obsérvese en la Figura A.4 cómo está compuesta la "etiqueta de inserción" y cuál es su ubicación dentro de los paquetes IP. A.3 Método de distribución de etiquetas Es también importante conocer la forma en que se lleva a cabo la distribución de etiquetas hacia los routers y los protocolos que pueden utilizarse para hacer esto. Un router MPLS debe conocer las "reglas" para poder asignar o intercambiar etiquetas. Aún cuando los routers convencionales suelen ser programados para determinar qué es lo que harán con un determinado paquete, es preferible contar con una asignación dinámica de reglas que permita mayor flexibilidad. Existen dos alternativas diferentes para hacer esta distribución. Cuando los routers son capaces de "escuchar" estas reglas, crear una base de datos interna y distribuir esta información a otros routers, sin necesidad de contar con un administrador de etiquetas previamente designado, el control se hace de manera independiente. La otra alternativa, preferida en MPLS, es el control ordenado. En este método de distribución, el LER de salida es, por lo regular, el encargado de la distribución de etiquetas, siendo este proceso en sentido contrario al direccionamiento de paquetes. El control ordenado ofrece como ventajas una mejor Ingeniería de Tráfico y

95
mayor control de la red, aunque, en comparación con el control independiente, presenta tiempos de convergencia mayores y el router de salida se convierte en el único punto susceptible a fallas.
Figura A.5: Alternativas de distribución de etiquetas con control ordenado. La distribución con control ordenado puede darse, a su vez, de dos maneras distintas. Una alternativa consiste en distribuir las etiquetas sin que éstas sean solicitadas por otros routers, desde el LER en el extremo de salida de la red y "empujándolas" hacia arriba. Este método de distribución, conocido como transferencia de bajada no solicitada ("downstream unsolicited”), puede hacerse cada determinado tiempo o cada vez que cambie la Base de Información de Etiquetas de un router cualquiera. La segunda opción, denominada transferencia de bajada por demanda ("downstream on-demand"), requiere que un router en particular solicite sus tablas, siendo éstas posteriormente distribuidas por el LER de salida. Véase la Figura A.5. Adicionalmente, existen dos métodos en que los routers retienen sus tablas de etiquetas. En el modo conservativo, un router retiene exclusivamente las etiquetas que necesita en ese momento. En el modo liberal, un LSR retiene todas las tablas que le fueron asignadas, aún cuando éstas no le sean útiles en ese momento. Después de que cada router posee sus tablas de etiquetas puede comenzar el direccionamiento de paquetes a través de los LSPs preestablecidos por un determinado FEC. Actualmente existe una amplia variedad de protocolos utilizados para la distribución de etiquetas. La arquitectura MPLS no especifica uno de estos en particular, sino que, más bien, recomienda su elección dependiendo de los requerimientos específicos de la red. Los protocolos utilizados pueden agruparse en dos grupos:

96
protocolos de enrutamiento explícito y protocolos de enrutamiento implícito. El enrutamiento explícito es idóneo para ofrecer Ingeniería de Tráfico y permite la creación de túneles. El enrutamiento implícito, por el contrario, permite el establecimiento de LSPs pero no ofrece características de Ingeniería de Tráfico. El Protocolo de Distribución de Etiquetas (LDP) es uno de los protocolos de enrutamiento implícito que se utilizan con frecuencia. LDP define el conjunto de procedimientos y mensajes a través de los cuales los LSRs establecen LSPs en una red MPLS. Otros protocolos de enrutamiento implícito incluyen al Protocolo de Compuerta de Frontera (BGP) y al protocolo de Sistema Intermedio a Sistema Intermedio (IS-IS). Por otro lado, entre los protocolos de enrutamiento explícito más comunes encontramos al protocolo LDP de Ruta Restringida (CR-LDP) y al Protocolo de Reservación de Recursos con Ingeniería de Tráfico (RSVP-TE). El primero de estos protocolos ofrece, en adición a LDP, características de Ingeniería de Tráfico, de manera que sea posible negociar con anticipación una ruta en especial. Esto permite establecer LSPs punto a punto con calidad de servicio en MPLS. CR-LDP es un protocolo de estado sólido, es decir, que después de haberse establecido la conexión, ésta se mantiene "abierta" hasta que se le indique lo contrario. RSVP-TE opera de manera similar que CR-LDP, pues permite negociar un LSP punto a punto que garantice un nivel de servicio de extremo a extremo. El protocolo es una extensión de la versión original RSVP, aunque incorpora el respaldo para MPLS. A diferencia de CR-LDP, este protocolo permite negociar una ruta para la transmisión de información, misma que debe "refrescarse" constantemente para que ésta se mantenga activa (estado blando). Mediante estos últimos protocolos y la aplicación de distintas estrategias de ingeniería de tráfico es posible asignar diferentes niveles de calidad de servicio en redes MPLS.

97
Apéndice B
Simple Network Management Protocol (SNMP) & Management Information Base (MIB) B.1 SNMP y Management Information Base El protocolo SNMP forma parte de la capa de aplicación y facilita el intercambio de información de gestión entre elementos de la red y es parte del stack de protocolos TCP/IP. Una red administrada con SNMP consta de tres componentes básicos: estaciones administradas, los agentes y la estación administradora NMS (Network Management System). Las estaciones administradas son elementos de red que contienen un agente SNMP y pertenecen a la red administrada. Estos elementos pueden ser routers, switches, hubs, impresoras, etc. y lo que hacen es recolectar y guardar información que hacen disponible al NMS vía SNMP. El agente SNMP es un proceso de administración que reside en la estación administrada Cada agente mantiene uno o varias variables que describen su estado. En la documentación SNMP, estas variables se llaman objetos. El conjunto de todos los objetos posibles se da en la estructura de datos llamada MIB (Management Information Base-base de información de administración). La MIB es una colección de información que es organizada jerárquicamente, y los objetos (también llamados MIBs) son accedidos por un NMS usando SNMP .Este protocolo permite al NMS consultar el estado de los objetos locales de un agente, y cambiarlo de ser necesario. La mayor parte de SNMP consiste en este tipo de comunicación consulta-respuesta. Sin embargo, a veces ocurren sucesos no planeados. Los nodos administrados pueden caerse y volver a activarse, las líneas pueden desactivarse y levantarse de nuevo, pueden ocurrir congestionamientos, etc. Cada suceso significativo se define en un módulo MIB. Cuando un agente nota que ha ocurrido un evento significativo, de inmediato le informa a todas las estaciones administradoras de su lista de configuración. La seguridad y la validación de identificación desempeñan un papel preponderante en el SNMP. Un NMS también tiene la capacidad de aprender mucho sobre cada nodo que está bajo su control, y también puede apagarlos. Por lo tanto los agentes tienen que estar seguros de que las consultas supuestamente originadas por la estación administradora realmente vienen de la estación administradora. En el SNMPv1 y SNMPv2, la estación administradora comprobaba su identidad poniendo una contraseña (de texto normal) en cada mensaje. En el SNMPv3 se mejoró considerablemente la seguridad usando técnicas criptográficas modernas.

98
B.2 ASN.1 Como ya se mencionó, el corazón del modelo SNMP es el conjunto de objetos administrados por los agentes y leídos por la estación administradora. Para hacer posible la comunicación multiproveedor, es esencial que estos objetos se definan de una manera estándar y neutral desde el punto de vista de los proveedores. Es más, se requiere una forma estándar de codificarlos para su transferencia a través de la red. Por esta razón, se requiere un lenguaje de definición de objetos estándar, así como reglas de codificación. El lenguaje usado por el SNMP se toma del OSI y se llama ASN.1 (Abstract Syntax Notation One-notación de sintaxis abstracta uno). Los tipos de datos básicos del ASN.1 se muestran en la Figura B.1.
Tipo primitivo
Significado
INTEGER Entero de longitud arbitraria
BIT STRING Cadena de 0 o más bits OCTET STRING Cadena de 0 o más bytes sin signo NULL Marcador de lugar OBJECT IDENTIFIER Tipo de datos definido oficialmente
Figura B.1: Tipos de datos básicos de ASN.1
Los OBJECT IDENTIFIER ofrecen una manera de identificar objetos. En principio cada objeto definido en cada estándar oficial puede identificarse de manera única. El mecanismo consiste en definir un árbol de estándares, y colocar cada objeto en cada estándar en una localidad única del árbol. La parte del árbol que incluye la MIB del SNMP se muestra en la figura NÚMERO. El nivel superior lista todas las organizaciones de estándares importantes del mundo y en los niveles bajos las organizaciones asociadas. Cada arco de la figura NÚMERO tiene tanto un nombre como un número. Por tanto, todos los objetos de la MIB de SNMP se identifican unívocamente por su nombre o número: iso.identified.organization.dod.internet.private.enterprise.enterprise.cisco.temporaryvariables.AppleTalk.atInput. o por su equivalente 1.3.6.1.4.1.9.3.3.1. Los proveedores pueden definir subconjuntos para administrar sus productos. MIBs que no han sido estandarizados generalmente se posicionan dentro del subconjunto experimental, 1.3.6.1.4. Pero SNMP usa sólo algunas partes del ASN.1. Las partes del ASN.1 que usan el SNMP se agrupan en un subconjunto, que recibe el nombre de SMI (Structure of Management Information). El SM1 es en lo que en realidad describe la estructura de datos del SNMP.

99
Esto es necesario ya que hay que definir algunas reglas si los productos de cientos de proveedores han de hablar entre sí y realmente entender lo que dicen. En el nivel más bajo, las variables SNMP se definen como objetos individuales. Los objetos relacionados se reúnen en grupos, y los grupos se integran en módulos. Por ejemplo existen grupos para los objetos IP y los objetos TCP. Un router puede
Figura B.2: Diferentes jerarquías asignadas a diferentes organizaciones.
Reconocer los grupos IP, dado que a su administrador le interesa tener información por ejemplo de la cantidad de paquetes perdidos. Por otra parte, un router de bajo nivel podría no reconocer el grupo TCP, dado que no necesita usar TCP para desempeñar sus funciones de enrutamiento.

100
Todos los módulos MIB comienzan con una invocación de la macro MODULE-IDENTITY que proporciona el nombre y la dirección del implementador, la historia de modificaciones y otra información administrativa. Luego le sigue una invocación de la macro OBJECT-TYPE que tiene cuatro parámetros requeridos y cuatro opcionales: SYNTAX: define el tipo de datos de la variable MAX-ACCESS: información de acceso a la variable (los más usados lectura-escritura, lectura). STATUS: estado de la variable respecto a SNMP (los más usados actual y obsoleto) DESCRIPTION: cadena ASCII que indica lo que hace la variable. Un ejemplo sencillo se da en la siguiente tabla. La variable se llama RouterID del módulo OSPF y grupo ospfGeneralGroup que es usada en el software:
ospfRouterId ObjectType Syntax RouterID MaxAccess read-write Status current Description A 32-bit integer uniquely identifying the
router in the Autonomous System. By convention, to ensure uniqueness, this should default to the value of one of the router's IP interface addresses.
Figura B.3: Ejemplo
También SM1 define una gran variedad de tablas estructuradas que son usadas para agrupar objetos que tienen múltiples variables. B.3 SNMP v1 SNMP v1 es la implementación inicial del protocolo SNMP. Es descrito en el RFC 1157. Opera bajo protocolos tales como User Datagram Protocol (UDP), Internet Protocol (IP), OSI Connectionless Network Service (CLNS), AppleTalk Datagram-Delivery Protocol (DDP) y Novell Internet Packet Exchange (IPX). Esta versión es la más extendida en su uso y es el protocolo de facto en la comunidad de Internet.

101
B.3.1 Operaciones Básicas SNMP es un protocolo simple de consulta-respuesta. El NMS hace la consulta y la estación administrada responde. Este comportamiento es implementado usando una de las 4 operaciones del protocolo: Get, GetNext, Set and Trap. Get Usado por el NMS para consultar el valor
de una variable de un objeto. GetNext Usado por el NMS para consultar el valor
de la siguiente variable de un objeto. Set Usado por el NMS para setear valores de
un objeto. Trap Usado por los agentes para informar al
NMS de eventos significativos.
Figura B.4: Operaciones básicas de SNMP
B.4 SNMP v2 Es una evolución de la versión inicial. SNMP v2 ofrece muchas mejoras así como opciones adicionales: GetBulk e Inform. GetBulk Usado por el NMS para consultar
eficientemente grandes cantidades de datos, por ejemplo varias filas de una tabla.
Inform Usado por el NMS para enviar traps a otro NMS y obtener una respuesta.
Figura B.5: Mejoras en SNMP v2

102
Apéndice C
Ejemplo de Fairness con múltiples caminos
C1 Ejemplo Veremos ahora un ejemplo para que el usuario pueda entender mejor el procedimiento llevado a cabo para aplicar el algoritmo de fairness con múltiples caminos (es decir, para la búsqueda de la asignación de los flujos considerando que se toman todos los caminos posibles para cada demanda). Vale destacar antes de exponerlo que dicho ejemplo fue facilitado al grupo gracias a Paola Bermolen, quien nos ayudó en la comprensión de los algoritmos de fairness. Es también importante comentar que los valores expuestos fueron calculados usando MatLab. Debajo de cada uno de los resultados hallados, exponemos también los valores arrojados por NET-TE, de manera de poder así compararlos. Empecemos mirando en la siguiente figura la topología a considerar en este ejemplo.
Figura C.1: topología a usar en el ejemplo
Consideraremos 2 demandas, d = 1 y d = 2, tal que,
• d = 1 es entre los nodos 1 y 2 • d = 2 es entre los nodos 1 y 4
Si resolvemos el problema anterior encontramos 2 caminos posibles para cada demanda. Para la demanda d = 1 encontramos los posibles caminos:
{ } { }1 22 1,3 1P y P demanda= = Para la demanda d = 2 encontramos los posibles caminos:
{ } { }1 21, 4 2,3, 4 2P y P demanda= =
Si resolviéramos este problema siguiendo los pasos indicados por el algoritmo llegaríamos al siguiente resultado:

103
0
dp dp
edp dp ed p
dp
x X demanda d
x c enlace e
x demanda y
δ
= ∀ ≤ ∀ ≥ ∀
∑
∑∑
11x =1 en el camino { }1 2P =
21x =1 en el camino { }2 1,3P =
12x =1 en el camino { }1 1, 4P =
22x =0 en el camino { }2 2,3, 4P =
dónde la notación jix representa el BW asignado a la demanda i por el posible camino j.
La demostración de cómo se llega a ese resultado se exhibe a continuación. Empezamos observando que la cantidad total de BW asignado a la demanda 1 (X1) y a la demanda 2 (X2) es lo siguiente:
1 21 1 1X x x= + demanda 1
1 22 2 2X x x= + demanda 2
Si X es el vector de BW total, entonces 1 2( , )X X X= . Si consideramos ( )1 2 1 2( ) ( ), ( ) ( , )f x f x f x X X= = , llegamos a que ( )i if x X= .
El objetivo es el buscar un vector 0 0 01 2( ( , ))X X X= ,
0( ) ( )LEXtal que f x f x x Q≥ ∀ ∈ Las restricciones con las que trabajaremos son, expresadas en términos generales, las siguientes:
todo camino Lo anterior, aplicado a nuestro problema en particular, se traduce en:
1 21 1 11 22 2 22 11 21 21 22 21 21 22 2
2
1
2
1
0 1, 2 1, 2ji
x x X
x x X
x x
x x
x x
x x
x i j
+ =
+ =
+ ≤
+ ≤
+ ≤
+ ≤
≥ = =
lo que nos lleva al primer cálculo de maximización:

104
1 21 11 22 2
2 11 21 21 22 21 21 22 2
max
2*
1
2
1
0 1,2 1, 2ji
x x
x x
x xcon x Q
x x
x x
x x
x i j
ℑℑ ≤ +ℑ ≤ + + ≤ ∈
+ ≤ + ≤ + ≤
≥ = =
Haciendo cuentas, 1 2 1 2 1 2 2 1
1 1 2 2 1 2 1 2
1 2
2 ( ) ( ) 3x x x x x x x x≤ ≤
ℑ ≤ + + + = + + + ≤
02 3 1.5 1ℑ ≤ ⇒ ℑ ≤ ⇒ ℑ = es el máximo (NET-TE en su caso arroja el valor 1). Observar que hay múltiples valores de j
ix para los cuales se da que 0
1 2( ) ( ) 1f x f x= = ℑ = Por ejemplo,
cumple con todas las restricciones y 0
1 2( ) ( )f x f x= = ℑ
1 21 1
1 22 2
) 0.5 0.5
1 0
b x y x
x y x
= =
= = También cumple con las restricciones. Además, siguen
habiendo más posibles soluciones.
Ahora que hayamos el máximo valor de ℑ , el siguiente paso es tratar de maximizar cada demanda d por separado, y ver si puede hacerse más grande que ese valor ℑ hayado anteriormente, con la restricción que no se vean afectadas el resto de las demandas. Según el algoritmo, si encontramos alguna demanda la cual no se puede hacer mayor que el valor de ℑ encontrado, entonces decimos que esa es una demanda bloqueadora y la apartamos del grupo, guardando su índice en un conjunto aparte B. Así entonces procedemos a elegir k = 1 (correspondiente a la demanda d = 1) y testeamos:
1 2 1 21 1 1 1 1
0 1 2 1 22 2 2 2 2
max ( ) max
1 ( ) 1
f x x x x x
f x x x x xx Q x Q
= + +
ℑ = ≤ = + ⇒ ≤ + ∈ ∈
1 21 1
1 22 2
) 1 0
1 0
a x y x
x y x
= =
= =

105
La solución a problema LP anterior es: 1 2 1 21 1 2 2
0 0.9214,1.0786,0.9214,0.0786x x x x
X =
(NET-TE en su caso arroja los valores [1, 1, 1, 0])
Si observamos cuanto quedo el X1 finalmente vemos que 0 0
1( ) 0.9214 1.0786 2 ( 1)f X = + = ≠ ℑ = , entonces aumento! Pasamos ahora a resolver el problema LP para la segunda demanda (d = 2). Eligiendo k = 2, testeamos:
1 22 2 2
1 21 1
max ( )
1
f x x x
x xx Q
= +
≤ + ∈
lo cual nos lleva a la solución: 1 2 1 21 1 2 2
0 020.7436,0.6066,0.8663,0.1337 ( ) 1
x x x x
X f X = ⇒ =
(NET-TE en su caso arroja los valores [1, 0, 1, 0])
Esto demuestra que permaneció igual que el valor de ℑ hayado previamente. No aumento! Según el algoritmo, tenemos que pasar entonces el índice k = 2 al grupo B. Por lo que, { } { } 0
22 ' 1 1BB y B con t= = = ℑ = , siendo B el conjunto que contiene a las demandas que son bloqueadoras. El siguiente paso es resolver el siguiente problema LP, tratando de hayar un nuevo valor de ℑ , pero esta vez considerando las nuevas restricciones que surgen de saber que las demandas bloqueadoras no pueden hacerse mayores a determinado valor. Resolvemos:
1 21 1
1 22 2
2 11 21 21 1 11 21 21 22 2 2 22 21 21 22 2
max
1max2( )11 ( )2
1
0 1,2 1,2
B
ji
x x
x x
x xf x x xx xt f x x x
x Q x x
x x
x i j
ℑℑ ≤ + ≤ +ℑ + ≤ℑ ≤ = + ⇒
+ ≤= ≤ = + ∈ + ≤
+ ≤
≥ = =
Resolviendo, obtenemos un 2ℑ = (NET-TE arroja el mismo valor). ¿Hay una solución tal que 1 2
1 1 1( ) 2f x x x= + = ?

106
La repuesta es Si: 1 21 11 22 2
1
1 0
x x
x y x
= =
= =
Debemos ver ahora si se pueden maximizar las demandas que quedan en el conjunto B’ de manera que sean mayores que el valor de ℑ hayado previamente. Haciendo el test siguiente para k = 1 { } { }( )22 ' 1 1BB y B t= = = , lo averiguamos:
1 2 1 2
1 1 1 1 11 2 1 2
2 2 2 2 2 2
max ( ) max
1 ( ) 1B
f x x x x x
t f x x x x xx Q x Q
= + +
= ≤ = + ⇒ ≤ + ∈ ∈
La solución obtenida es: 1 2 1 21 1 2 2
0.9214,1.0786,0.9214,0.0786x x x x
X =
(NET-TE en su caso arroja los valores [1, 1, 1, 0]).
Como podemos apreciar, X1 es igual a 2. Por lo tanto no se pudo hacer mayor que el último valor de ℑ hayado. Pasamos como es debido el índice k = 2 al conjunto B. Tenemos entonces que
1 2Bt = . El conjunto B’ ha quedado entonces vació. Hemos llegado entonces al fin del algoritmo y hayado la solución final del vector de asignación X. La solución final es: 1 2Bt = y 2 1Bt = . O lo que es igual, X = (2, 1), con cada camino para cada demanda teniendo el siguiente BW: 1
1x =1 en el camino { }1 2P =
21x =1 en el camino { }2 1,3P =
12x =1 en el camino { }1 1, 4P =
22x =0 en el camino { }2 2,3, 4P =
En el caso de NET-TE, arroja los mismos valores que los señalados anteriormente.

107
Apéndice D
Software Las acciones principales que pueden realizarse en el simulador se encuentran distribuidas en el menú Archivo, en la barra de herramientas debajo del menú Archivo y en la barra vertical a la derecha. Una vez iniciado el programa se visualizará una ventana principal como se muestra a continuación en la Figura D.1.
Figura D.1: Ventana principal.
Dentro del menú Archivo se encuentran las opciones:
• Abrir, para abrir un archivo mediante el método abrirArch() de la clase Principal. • Nuevo, para crear un nuevo archivo mediante el método nuevoArch() de la clase Principal.

108
• Guardar y Guardar como, para guardar un archivo, mediante los métodos guardarArch() y guardarNeverSaved() de la clase Principal. • Cerrar, para cerrar una archivo usando el método cerrarArch() de la clase Principal. • Salir, para salir del programa usando el método processWindowEvent(WindowEvent e) de la clase Principal. Dentro de la barra de herramientas las opciones son: • Abrir, para abrir un archivo mediante el método botonOpen_actionPerformed(ActionEvent e) de la clase Principal. • Nuevo, para crear un nuevo archivo mediante el método botonNew_actionPerformed(ActionEvent e) de la clase Principal. • Guardar, para guardar un archivo, mediante el método botonSave_actionPerformed(ActionEvent e) de la clase Principal. • Crear matriz de tráfico, para crear un archivo de una matriz de tráfico mediante el método botonRuteo_actionPerformed(ActionEvent e) la clase Principal.
D.1 Menú Archivo y Barra de Herramientas
Abrir:
Es posible abrir un archivo existente por medio de la barra de herramientas o por el menú Archivo. Por defecto los archivos que se muestran para abrir son aquellos cuya extensión sea .txt. Se puede elegir para que muestre los archivos con extensión .arc o todos los archivos. Esto se logró definiendo las clases ArcFileFilter y TxtFileFilter pertenecientes al package Programa, las cuales heredan de la clase javax.swing.filechooser.FileFilter_. Al producirse un evento sobre el ítem que llama al método abrirArch() de la clase Principal, se chequea si hay algún archivo abierto. Si lo hay, se hace una llamada el método cerrarArch() de la clase Principal. En caso que no halla algún archivo abierto o que se halla cerrado el archivo abierto (aprovado=true), se despliega una ventana por la cual el usuario puede navegar a través del sistema de archivos con el fin de seleccionar el deseado. Si el archivo seleccionado es con extensión .arc el método abrirArch() llama al método cargar(). Después de haber elegido el archivo y de haber presionado Abrir se intenta abrir. En caso que se logre realizar dicha acción, se muestra el contenido en la pantalla. Además se escribe la ruta de acceso del archivo en la barra de Título y se guarda la ruta de acceso al archivo seleccionado para que las futuras ventanas de diálogo del tipo javax.swing. JFileChooser se inicien en dicho directorio.
Nuevo:
Es posible crear un nuevo archivo por medio de la barra de herramientas o por el menú Nuevo. Para ello se debe realizar un evento sobre alguno de los ítems que llama al método nuevoArch() de la clase Principal. Al llamar a este método, se chequea si hay algún archivo abierto. En caso que lo halla, se llama al método cerrarArch() de la clase

109
Principal. En caso que este método devuelva aprovado=true, se genera un nuevo archivo. Si aprovado=false el programa no realizará acción alguna, volviendo al estado anterior al llamado del método nuevoArch() de la clase Principal.
Guardar y GuardarComo:
Es posible guardar un archivo por medio de la barra de herramientas Guardar o por el menú Guardar o GuardarComo. Hay doy formas distintas para guardar archivos de configuración. En caso que se elija el ítem Guardar, se llama el método guardarArch() de la clase Principal. Este chequea si el archivo ha sido anteriormente guardado mediante el atributo booleano neverSaved de la clase Principal. En caso que su valor sea true, se llama al método guardarNeverSaved() de la clase Principal quien dará la opción al usuario de elegir la ubicación y el nombre con el que desee guardar el archivo. Si el archivo ya ha sido guardado (neverSaved=false) se llama al método guardarSaved() de la clase Principal que sobrescribe el archivo existente. En la figura 3 puede verse el diagrama de colaboración del método guardarArch() de la clase Principal. Las acciones realizadas al llamar guardarNeverSaved() de la clase Principal son similares. Si el evento se realiza sobre GuardarComo, se invocará el método guardarNeverSaved() de la clase Principal. Si el archivo que se quiere guardar es con extensión .arc los métodos guardarSaved() y guardarNeverSaved() llaman al método salvar().
Cerrar:
Para cerrar un archivo es necesario realizar un evento que llame al método cerrarArch() de la clase Principal. Esto se puede hacer seleccionando Cerrar en el menú Archivo.
En caso que halla algún archivo abierto se da la elección de:
• salvar y cerrar • cerrar sin salvar • cancelar Si se elige la primera opción y el archivo nunca ha sido guardado se llama al método guardarNeverSaved() de la clase Principal. Si ya ha sido guardado se llama al método guardarSaved() de la clase Principal. Luego se llama al método clear() de la clase Principal. En caso de elegir cerrar sin salvar se llama directamente al método clear() de la clase Principal. Si se presiona en Cancelar no se realiza acción alguna.
Salir
Al seleccionar este ítem, se genera el evento, presionado del botón salir, el cual es tomado por el método salirArch_actionPerformed(e) de la clase Principal, que a su vez invoca al método processWindowEvent(WindowEvent e) de la clase Principal, método

110
que se encarga de cerrar el programa dando las opciones correspondientes para guardar un archivo abierto. D.2 Crear matriz de tráfico Después de tener una topología de la red, es posible crear una matriz de tráfico. Al realizar un evento sobre el ítem , se llama al método botonRuteo_actionPerformed(ActionEvent e) de la clase Principal el cual crea una instancia de la clase GeneroMT. En la clase GeneroMT se configuran los parámetros de cada ruta de la matriz de tráfico. En esta clase dentro del método jbInit() se llenan los combo de nodo origen, nodo destino con el vector nodes el cual contiene todos los nodos de la red y el combo afinidad se llena con las afinidades de todos los enlaces que se encuentran en links.afinidad. Después de asignar los parámetros de cada ruta: • BW deseado: jTextFieldNombre.getText() • Nodo Origen: comboNodoOrigen_actionPerformed(ActionEvent e) • Nodo Destino: comboNodoDestino_actionPerformed(ActionEvent e) • Afinidad: comboAfinidad_actionPerformed(ActionEvent e) se crea la ruta al apretar el botón Agregar que llama al método jButtonInsertar_actionPerformed(ActionEvent e). Si se desea modificar una ruta ya creada, se debe seleccionar la ruta y después de hacer las modificaciones deseadas se debe apretar el botón Cambiar que llama al método jButtonEditar_actionPerformed(ActionEvent e). Si se desea borrar una ruta se debe apretar el botón Borrar que llama al método jButtonBorrar _actionPerformed(ActionEvent e). Si se desea modificar una matriz de tráfico ya creada, se debe apretar el botón Cargar que llama al método jButtonCargar_actionPerformed(ActionEvent e) que a su ves llama al método stringToVectors de la clase InterpreteMT. Para crear la matriz de tráfico se debe apretar el botón Guardar que llama al método jButtonGuardar_actionPerformed(ActionEvent e) que a su ves llama al método guardarArch() el cual llama al método EditarTexto de la clase InterpreteMT.
D.3 Barra Vertical
Dentro de la barra vertical las opciones son: • Cargar red, para cargar la topología de red mediante carConfActionPerformed(ActionEvent e) el método de la clase VentanaConf. • LER, para crear un LER mediante el método botonLER_actionPerformed(ActionEvent e) de la clase VentanaConf. • LSR, para crear un LSR mediante el método botonLSR_actionPerformed(ActionEvent e) de la clase VentanaConf.

111
• LINK, para crear un LINK mediante el método botonLink_actionPerformed(ActionEvent e) de la clase VentanaConf. • Eliminar, para eliminar el objeto seleccionado mediante el método botonDel_actionPerformed(ActionEvent e) de la clase VentanaConf. • Atrás/Adelante, para deshacer la última acción realizada mediante los métodos restBack() y restForw()de la clase VentanaConf. • LSP explicito, para crear un LSP manualmente mediante el método crearLspActionPerformed(ActionEvent e) de la clase VentanaConf. • CSPF, para crear un LSP con la menor métrica posible mediante el método botonCSPFActionPerformed(ActionEvent e) de la clase VentanaConf. • Fair Network, para crear los LSPs de la matriz de tráfico elegida mediante el método botonMTActionPerformed(ActionEvent e) de la clase VentanaConf. • MIRA, para crear los LSPs de la matriz de tráfico elegida mediante el método de botonMIRAActionPerformed(ActionEvent e) de la clase VentanaConf. • Lista de LSPs, para mostrar la lista de LSPs creados mediante el método listaLsps_actionPerformed(ActionEvent e) de la clase VentanaConf. • Borrar LSP, para borrar el LSP seleccionado mediante el método borrarLspActionPerformed(ActionEvent e) de la clase VentanaConf. • Estadísticas, para mostrar las estadísticas de la topología de red mediante el método botonEstadActionPerformed(ActionEvent e) de la clase VentanaConf. • Utilización, para mostrar en pantalla la utilización de los enlaces mediante el método botonUtilActionPerformed(ActionEvent e) de la clase VentanaConf.
A continuación se detallan los métodos de la lista anterior más significativos.
botonCSPFActionPerformed(ActionEvent e) crea una instancia de la clase CSPF. En la clase CSPF primero se debe indicar el BW, nodo origen, nodo destino, la métrica y el criterio TE a utilizar y es opcional indicar afinidad, enlace presenten y enlace ausente. En esta clase dentro del método jbInit() se llenan los combo de nodo origen, nodo destino, con el vector nodes el cual contiene todos los nodos de la red, los combos enlace presente y enlace ausente se llenan con todos los enlaces de la red que se encuentran en el vector links y el combo afinidad se llena con las afinidades de todos los enlaces que se encuentran en el vector afinidad de la clase Link. Luego al oprimir el botón Aplicar Algoritmo, se llama al método jButtonAlgoritmo_actionPerformed(ActionEvent e). Este método primero se fija en la variable booleana pinto. Ver Figura D.2.

112
Figura D.2: Diagrama de razonamiento al apretar el botón Algoritmo. Si pinto=false es porque se selecciono enlace presente. Supongamos que el enlace seleccionado esta conectado al nodo A y al nodo B. Para calcular los caminos posibles es necesario llamar 4 veces al método shortestPath de la clase Algoritmo. Porque hay que calcular el camino mas corto entre nodo origen y el nodo A, llamando al método shortestPath de la clase Algoritmo y hay que calcular el camino mas corto entre nodo destino y el nodo B, llamando al método shortestPath de la clase Algoritmo. Sumo las dos distancias calculadas. Se hace el mismo procedimiento pero ahora entre el nodo destino y el nodo A y entre el nodo origen y el nodo B. Se compara la distancia calculada en el primer caso con la del segundo caso y se queda con la menor. Si se encontró más de un camino posible se puede observar en pantalla los distintos caminos encontrados al oprimir la flecha hacia la derecha que llama al método jButtonAdelante_actionPerformed(ActionEvent e). Después de oprimir la flecha hacia la derecha se puede ir hacia atrás al oprimir la flecha hacia la izquierda que llama al método jButtonAtras_actionPerformed(ActionEvent e). El método jButtonAceptar_actionPerformed(ActionEvent e), crea un LSP del camino seleccionado con los dos métodos anteriormente mencionados, lo agrega en el combo de LSPs y actualiza el ancho de banda reservado de cada enlace que pertenece al camino calculado. botonMIRAActionPerformed(ActionEvent e) crea una instancia de la clase OfflineMira. En la clase OfflineMira, para cargar el archivo de la matriz de tráfico se llama al método jButtonCargar_actionPerformed(ActionEvent e) el cual llama al método stringToVectors de la clase InterpreteMT. Luego al oprimir el botón Correr que llama al método jButtonCorrer_actionPerformed(ActionEvent e) en donde se crea una instancia a la clase MIRA. En la clase MIRA se llama al método hallamaxflows para calcular el máximo ancho de banda entre los nodos, luego este método llama al método hallpesos que calcula los pesos que asocia a cada enlace. Luego de asignar a todos los enlaces su nuevo peso, dentro de la clase OfflineMira se llama al método correr, que para cada ruta de la matriz de tráfico cargada llama al método podar, luego llama al método shortestPath de la clase Algoritmo, para calcular un camino para cada ruta y guardar el resultado en el array de vectores resultuno. El método jComboBox_actionPerformed(ActionEvent e), pinta los enlaces por los cuales pasa la ruta seleccionada en el combo Rutas posibles.

113
El método jButtonAceptar_actionPerformed(ActionEvent e), crea un LSP para cada ruta, lo agrega en el combo de LSPs y actualiza el ancho de banda reservado de cada enlace que pertenece al camino calculado. botonMTActionPerformed(ActionEvent e) crea una instancia de clase FairnessNetwork. En la clase FairnessNetwork, para cargar el archivo de la matriz de tráfico se llama al método jButtonCargar_actionPerformed(ActionEvent e) el cual llama al método stringToVectors de la clase InterpreteMT. Luego se debe el elegir uno de los siguientes algoritmos: • Fairness básico • Fairness acotado • Fairness con múltiples caminos • Fairness con mult. caminos acotado Si se eligió unos de los 2 primeros algoritmos se debe elegir la métrica entre peso o minhop. Al marcar Elegir camino manualmente se puede elegir entre todos los caminos con la menor métrica posible calculados de cada ruta, con cual quedarse. Esto se hace llamando al método jCheckBox4_actionPerformed(ActionEvent e) que llena el combo Lista de rutas con todas las rutas de la matriz de tráfico. Al seleccionar una ruta de este combo se llama al método podar, luego al método shortestPath de la clase Algoritmo, se llena el combo de Caminos posibles con los caminos calculados. Al seleccionar un camino del combo se guarda los enlaces por donde pasa el camino seleccionado en el vector enlacesGr de la clase Caminos. Para correr los algoritmos se debe oprimir el botón Correr que llama al método jButtonCorrer_actionPerformed(ActionEvent e). Este método primero se fija que algoritmo se selecciono, esto lo hace fijándose cual JCheckBox fue seleccionado. Si se eligió el algoritmo1, entonces JcheckBox().isSelected=trae. Ver Figura D.3.
Figura D.3: Diagrama de razonamiento al elegir el algoritmo a correr.

114
Si se eligió el algoritmo2, entonces JcheckBox1().isSelected=true . Se crea una instancia de la clase Requerimientos, en donde se configuran la demanda mínima y la prioridad del camino. Ver Figura D.4.
Figura D.4: Diagrama de razonamiento si se elige el Algortmo 2.
Si no se marca Elegir camino manualmente, el método correr llama para cada ruta de la matriz de tráfico cargada al método podar, luego al método shortestPath de la clase Algoritmo, si hay mas de un camino posible llama al método podar2 de la clase Algoritmo y guarda un camino para cada ruta. El método buscar, busca cuantos caminos pasan por cada enlace y lo guarda en la variable delta de la clase Link. El método mínimo calcula t, que es el paso en que se incrementa el ancho de banda reservado de cada enlace por camino que pasa por él. Esto continúa hasta que satura algún enlace. Al saturar un enlace se sacan todos los caminos que pasan por ese enlace y se fija el ancho de banda del camino. Termina cuando se fijan todos los anchos de banda de cada camino. Si se eligió el algoritmo 3, entonces JcheckBox()2.isSelected=true o si se eligió el algoritmo 4, entonces JcheckBox()3.isSelected=true.
Figura D.5: Diagrama de razonamiento si se elige el Algoritmo 3.

115
El método calculatodos, calcula todos los caminos posibles entre el nodo origen y el nodo destino sin considerar BW, métrica ni afinidad. El método OptimizacionLineal, calcula el valor de la variable auxiliar tau. El método OptimizacionLinealChequeo, maximiza de a una demanda y compara su valor con el valor de la variable auxiliar tau calculado en OptimizacionLineal. Los métodos OptimizacionLineal y OptimizacionLinealChequeo son los encargados de maximizar las demandas, asignando a cada sub-demanda el ancho de banda calculado. El ancho de banda final de cada demanda es la suma de los anchos de banda de todas sus sub-demandas. Si se eligió el algoritmo 4, después de tener el ancho de banda final de cada demanda se llama al método ordenar, que ordena de mayor a menor las sub-demandas de cada demanda según su ancho de banda. Esto se hace para asignar a las demandas que su ancho de banda final es mayor que su ancho de banda deseado, asignarle como ancho de banda final el ancho de banda deseado. El método jComboBox_actionPerformed(ActionEvent e), pinta los enlaces por los cuales pasa la ruta seleccionada en el combo Lista de rutas. Si la ruta tiene subdemandas permite mostrar en pantalla cada una de ellas por separado. El método jButtonAceptar_actionPerformed(ActionEvent e), crea un Lsp para cada ruta, lo agrega en el combo de LSPs y actualiza el ancho de banda reservado de cada enlace que pertenece al camino calculado.

116
Bibliografía
[1] NetScope: Traffic Engineering for IP Networks. Paper de AT&T Labs. Autores:
Anja Feldmann, Albert Greenberg, Carsten Lund, Nick Reingold y Jennifer
Rexford. Marzo 2000.
[2] Request for Comments (RFC): 3272. Visión y Principios de la Ingeniería de
Tráfico en Internet. Autores: D. Awduche, A. Chiu, A. Elwalid, I. Widjaja, X.
Xiao. Mayo 2002.
[3] MPLS: Technology and Applications. Capítulo 7: Constraint-Based Routing.
Autores: Bruce Davie y Yakov Rekhter. Año 2000.
[4] Engineering Internet QoS. Capítulo 12: Future. Autores: Sanjay Jha y Mahbub
Hassan. Año 2002.
[5] Data Networks: Routing, Security, and Performance Optimization. Capítulo 8:
Quality of Service. Autor: Tony Kenyon. Año 2002.
[6] Minimum interference routing with applications to MPLS traffic engineering.
Proceedings of International Workshop on QoS, Pennsylvania. Autores: M.
Kodialam y T.V.Lacksham. Junio 2000.
[7] A New Bandwidth Guaranteed Routing Algorithm for MPLS Traffic
Engineering. Autores: Bin Wang, Xu Su y C.L. Philip Chen. Noviembre 2002.
[8] Network Flows. Autores: R.K Ahuja, T.L Magnanti y J.B. Orlin . Prentice Hall.
Año 1993.
[9] Multi-terminal network flows, Journal of SIAM. Autores: R.E. Gomory y T.C.
Hu. Año 2002.
[10] Routing, Flow and Capacity Design in Communication and Computer Networks. Capítulo 8: Fair Networks. Autores: Michal Pioro y Deepankar Medhi. Año 2004.

117
Glosario de términos
ARCA: Analizador de Redes de Caminos Virtuales, software que analiza el problema de brindar garantías de Calidad de Servicio (QoS) así como realizar Ingeniería de Tráfico sobre redes de datos. AS: Autonomous System, áreas que en su conjunto modelan a una red y dentro de las cuales las rutas son determinadas por el ruteo intradominio. ASN.1: Abstract Syntax Notation 1, lenguaje de definición de objetos estándar usado por SNMP. BGP: Border Gateway Protocol, protocolo de ruteo interdominio. CBR: Constraint Based Routing, ruteo que intenta encontrar un camino que optimice cierta métrica escalar y al mismo tiempo no viole un conjunto de restricciones. CLNS: OSI Connectionless Network Service, protocolo bajo el cual opera SNMP v1. CR-LDP: Constraint Route LDP, protocolo de distribución de etiquetas del tipo enrutamiento explícito que ofrece características de Ingeniería de Tráfico. CSPF: Constraint Shortest Path First, algoritmo para la computación de caminos que toma en cuenta al mismo tiempo un conjunto de restricciones. DDP: AppleTalk Datagram-Delivery Protocol, protocolo bajo el cual opera SNMP v1. DLCI: Data Link Connection Identificator, ejemplo de etiqueta o encabezado que pueden utilizarse como etiqueta de MPLS. FEC: Forwarding Equivalence Class, representación de un conjunto de paquetes que comparten los mismos requerimientos para su transporte en MPLS. IETF: Internet Engineering Task Force, grupo de trabajo dedicado en su mayoría al control del tráfico en lo que a la ingeniería de tráfico se refiere. IPX: Novell Internet Packet Exchange, protocolo bajo el cual opera SNMP v1. IS-IS: Intermediate System to Intermediate System, protocolo de ruteo intradominio. ISP: Internet Service Provider, proveedor de acceso a Internet. LDP: Label Distribution Protocol, protocolo responsable de que el LSP sea establecido para que sea funcional mediante el intercambio de etiquetas entre los nodos de la red. LER: Label Edge Router, router encargado de la distribución de etiquetas. LIB: Label Information Base, tabla de conectividad contra la cual es examinada y comparada la etiqueta MPLS al llegar del LER al LSR, determinando la acción a seguir. LSP: Label Switched Paths, ruta que sigue un paquete entre dos nodos de la red MPLS. LSR: Lable Switch Router, router encargado de dirigir el tráfico dentro de la red MPLS. MIB: Management Information Base, colección de información organizada jerárquicamente donde los objetos son accedidos usando SNMP y la cual reside en el elemento de red. MIRA: Minumum Interference Routing Algorithm, algoritmo de ruteo de caminos que intenta minimizar la “interferencia” que provoca el establecimiento de un nuevo camino a potenciales nuevos caminos que son desconocidos. MMF: Max-Min Fairness, principio de asignación usado para formular el esquema de asignación de recursos en donde se intenta asignar la mayor cantidad de recursos a cada demanda, al mismo tiempo que se intenta mantenerlos lo más similares posible. MNF: Maximum Network Flow, máximo ancho de banda que puede traficar la red entre determinado par de nodos ya sea por un único camino o varios. MPLS: Multi Protocol Label Switching, tecnología de ruteo y reenvío de paquetes en redes IP que se basa en la asignación e intercambio de etiquetas, que permiten el establecimiento de caminos a través de la red. NET-TE: Networking Traffic Engineering, nombre del software diseñado en este proyecto que hace alusión a la Ingeniería de Tráfico en redes; tema principal de éste trabajo.

118
NMS: Network Management System, estación administradora o, lo que es similar, elemento de red que contiene un agente SNMP y pertenece a la red administrada. QoS: Quality of Service, distintos niveles de servicio que son ofrecidos al cliente en términos del ancho de banda o algún otro parámetro. RSVP-TE: Reservation Protocol with Traffic Engineering, protocolo de enrutamiento explícito. En éste caso en particular, es una extensión de la versión original RSVP que incorpora el respaldo para MPLS. SDP: Shortest Distance Path, ruteo basado en preservar los recursos de la red por medio de la selección de los caminos más cortos. SLA: Service Level Agreement, acuerdo sobre el nivel de servicio con el cliente donde se especifican parámetros como performance, confiabilidad y seguridad. SMI: Structure of Management Information, partes del ASN.1 que usan SNMP. Es lo que en realidad describe la estructura de datos del SNMP. SNMP: Simple Network Management Protocol, protocolo de la capa de aplicación que facilita el intercambio de información de gestión entre elementos de la red y es parte del stack de protocolos TCP/IP. SWP: Shortest Widest Path, ruteo que se basa en la búsqueda del camino con el ancho de banda más grande y, en caso de haber múltiples caminos, se queda con el que tiene la mínima cantidad de saltos. TE: Traffic Engineering, disciplina que procura la optimización de la performance de las redes operativas. TED: Traffic Engineering Especialized Data Base, base de datos contenida en cada router, la cual mantiene atributos de los enlaces de la red e información de la topología. UDP: User Datagram Protocol, protocolo de transporte que provee servicios de datagramas por encima de IP. VPI/VCI: Virtual Circuit Identificator used in ATM, etiqueta o encabezado que puede utilizarse como etiqueta de MPLS en redes ATM. WSP: Widest Shortest Path, ruteo que se basa en la búsqueda de caminos con el mínimo número de saltos y, si encuentra múltiples caminos, se queda con el que tiene ancho de banda mayor.


















