

Improvements in ICT Continuity
25
-
Upload
bert-hilberink -
Category
Documents
-
view
10 -
download
0
Transcript of Improvements in ICT Continuity

ContentsOverview:
Observations
Analogy
Recommendations
In Detail:
Redundancy & Backups
CMDB
Recovery Plans
3rd Parties
Exercises
Summary
Annex:
Failover: Definition
CMDB: Configuration Items
RASCI
2

Overview

ICT Continuity: ObservationsICT is at a crossroads; on the one hand:
Turnover is decreasing
Costs are increasing
Clients expect ‘always on’
On the other hand:
Systems get rapidly more complex
Large outages will occur more frequently, so will cause more disruption to clients and more cost
Involved departments don’t have ICT Continuity as 1st priority (or not even 2nd/3rd), and they don’t necessarily coordinate their efforts
As a result, Resilience and Recovery will deteriorate quickly, leading to lower client satisfaction and higher costs
4

ICT Continuity: AnalogyIn aviation industry: federal administration (‘law makers’), accident investigation, aircraft companies, and airlines cooperate to increase disaster resilience and recovery
They do not always agree, but they are continually learning from disasters and incidents; over the past 50+ years this has led to big strides in aviation safety via:
Improved redundancy
Improved training (pilots, Air Traffic Control, maintenance) and resource management
Improved and simplified procedures and documentation
Regular checks
Possibility of loss of life aside, aviation industry is similar to ICT: it is concerned with maximising client satisfaction and profit, so also with minimising outages
ICT could take this cooperation and these measures as an example
5
+

ICT Continuity: Recommendations
Resilience and Recovery will both be improved by cooperation between Innovation, Operations, Calamity Team and 3rd Parties; this can be implemented by:
Sufficient redundancy and backups in Datacentres, Infrastructure and IT Applications
Complete and correct CMDB*
Sufficient and up2date Disaster Recovery Plans
Knowledgeable and experienced staff in Demand & Supply
Recurring and sufficient (‘live’) exercises; using all of the above
Starting points are the organisation’s risk appetite, and pragmatic approach:
Solve whatever possible (= needed + economically viable)
Formally accept ‘the rest’
Frequently revisit these principles; adapt and act where necessary
6
*: Configuration Management Database

ICT Continuity: Summary
7
Redundancy
3rd PartiesExercises
Recovery Plans
CMDB
Cooperation

In Detail

Redundancy & Backups: Observations
(Production like) redundancy for Infrastructure and Applications hardly ever available (‘5%’)
Backups (Data or Full System) frequently done (’80%’), but hardly ever tested (‘10%’); resulting in additional problems and time loss during calamities or incidents
Life Cycle Management often only partly implemented; older Datacentres and Applications are often left to ‘die out’, so redundancy suffers
Innovation, Operations and Functional Management frequently outsourced to 3rd Parties
Consequence: if something goes (seriously) wrong, there is (almost) no fallback, and precious little knowledge within the organisation
9

Redundancy & Backups: Improvements
Add Failovers (see Annex) where needed and economically viable:
Start with ‘Top-X’ Applications in modern Datacentres, as for these benefits outweigh cost
Introduce further redundancy in phases as far as needed and viable
Remove unnecessary Failovers
Improve Backup implementation (retention period, version control, checks, …) where needed
10

Often not present
If present, usually:
Not required (centralised) functionality
Information incomplete, incorrect and non-uniform
Redundancy not explicitly mentioned
Consequences: if organisation assets (or their location) are unknown:
It is difficult to perform proper maintenance
It is difficult to prevent or quickly recover from disaster
11
CMDB: Observations

Introduce central (‘Master’) CMDB (see Annex):
Merge existing local CMDB’s
Supplement existing information to necessary combination of Functionality, Completeness, Correctness and Uniformity, and include Redundancy
Remove unnecessary information
Standardise nomenclature
Arrange assurance via standard Asset and Configuration Management, using automatic discovery and reporting wherever possible
Arrange weekly overview for Calamity Team (according to their needs)
12
CMDB: Improvements

Recovery Plans: ObservationsGeneral state of affairs can be summarised by Arnold’s Laws of Documentation:
1. “If it should exist, it doesn’t”
2. “If it does exist, it’s out of date”
3. “Only useless documentation transcends first two laws”
Senior members Calamity Team quotes:
“Recovery Plans should be accessible and usable behind kitchen table at 3:00 AM on small laptop; currently they are not”
“Recovery Plans - when available - don’t have necessary information and are not concise enough”
“Recovery Plans are only available on operational level; not on strategic and tactical level that we manage”
“Because of the above: we never use them”
13
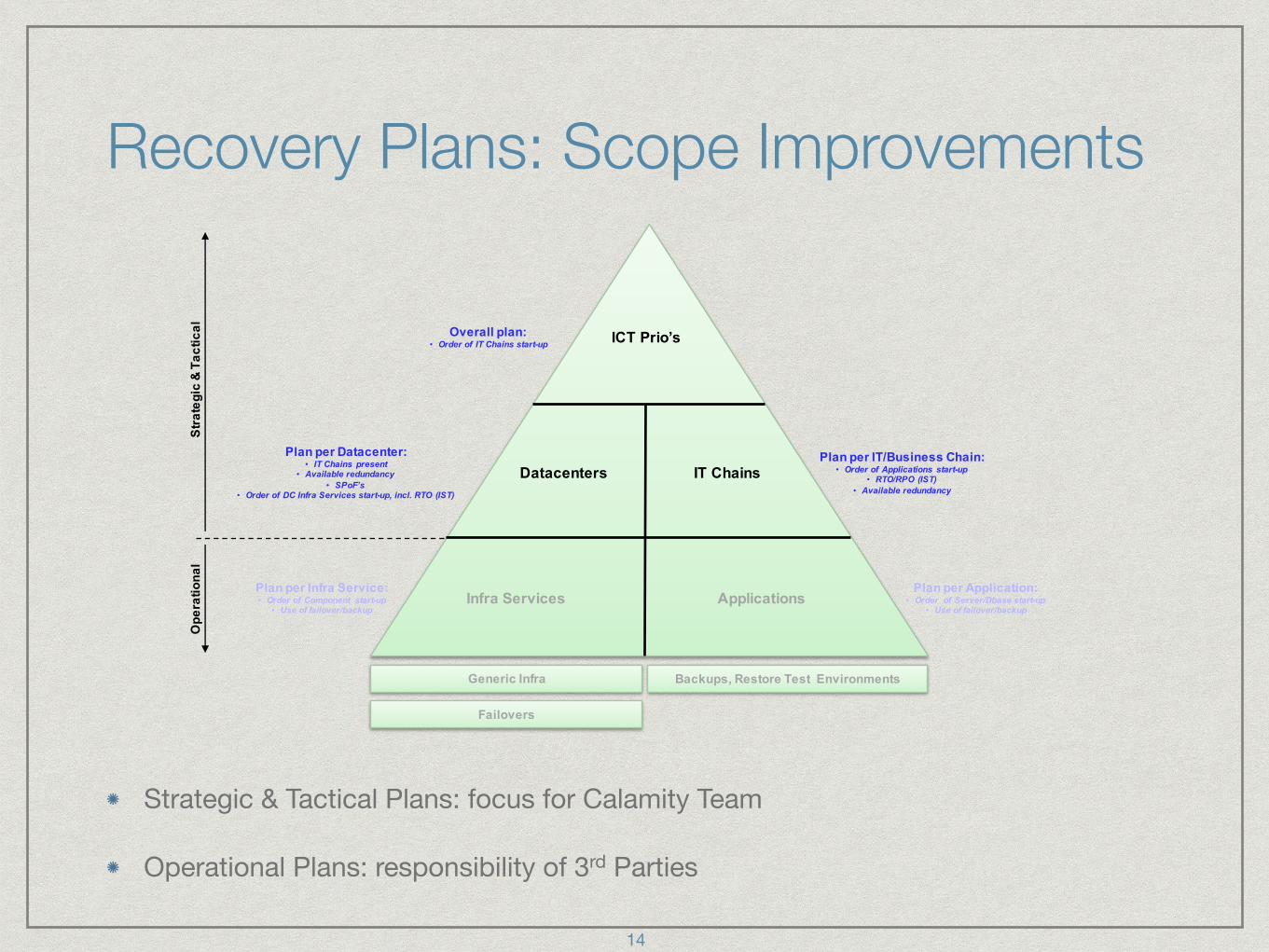
Recovery Plans: Scope Improvements
14
Strategic & Tactical Plans: focus for Calamity Team
Operational Plans: responsibility of 3rd Parties
Datacenters
ICT,Prio’s
Plan,per,Datacenter:• IT#Chains#present
• Available#redundancy• SPoF’s
• Order#of#DC#Infra#Services#start>up,#incl.#RTO# (IST)
Overall,plan:• Order#of# IT#Chains#start>up
Plan,per,Application:• Order##of#Server/Dbase start>up
• Use of#failover/backup
Plan,per,Infra,Service:• Order#of#Component# start>up
• Use#of#failover/backup
Generic Infra
Failovers
IT,Chains
Infra,Services Applications
Plan,per,IT/Business,Chain:• Order#of#Applications# start>up
• RTO/RPO# (IST)• Available#redundancy
Strategic,&,Tactical
Operational
Backups,,Restore Test,,Environments
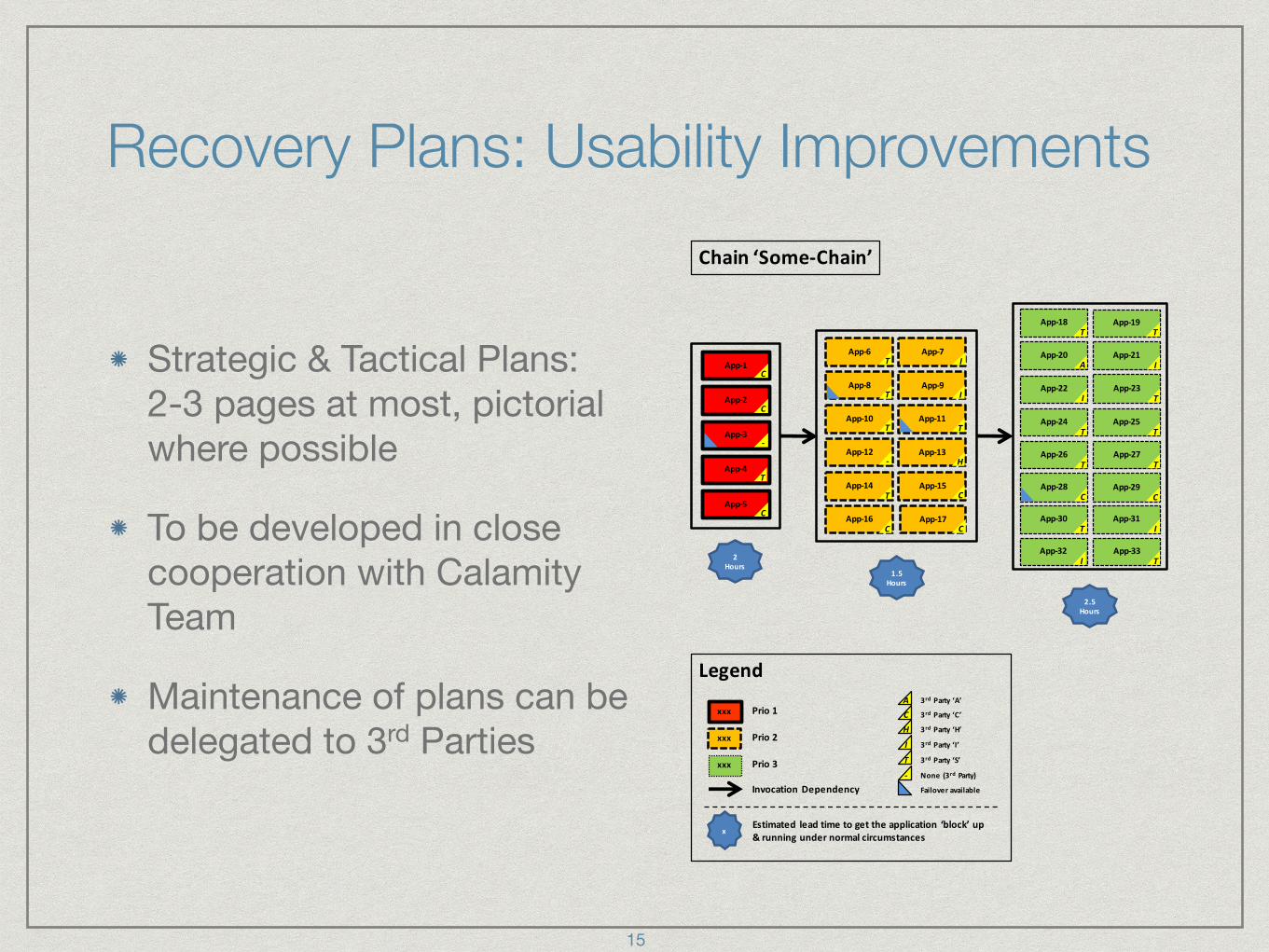
Recovery Plans: Usability Improvements
15
App#3
App#2
Chain+‘Some#Chain’
App#21I
"
CApp#10
T
App#8T
App#9I
App#6T
App#12"
App#7I
App#20A
App#22I
App#26T
App#24T
App#19T
App#1C
App#4T
App#23T
App#11T
App#13H
App#25T
App#27T
App#28C
App#29C
App#5C App#31
IApp#30
T
App#15C
App#14T
App#16C
App#17C
App#32I
App#33T
App#18T
xxx
xxx
xxx
Prio 1
Prio 2
Prio 3
Invocation+Dependency
Legend
CHIT"
3rd Party+‘C’
3rd Party+‘H’
3rd Party+‘I’
3rd Party+‘S’
None+(3rd Party)
Failover+available
xEstimated+ lead+time+to+get+the+application+ ‘block’+up+&+running+under+normal+circumstances
2+Hours
1.5+Hours
2.5+Hours
A 3rd Party+‘A’
Strategic & Tactical Plans: 2-3 pages at most, pictorial where possible
To be developed in close cooperation with Calamity Team
Maintenance of plans can be delegated to 3rd Parties

3rd Parties: ObservationsSupport for Datacentres, Infrastructure and Applications; often foreign
Quality in Innovation & Operations generally OK
Quality in Incidents, Calamities generally lower:
Often lot to be learned: frequently bright people (straight from university), but without right knowledge or experience
Distance barrier: team normally off-site:
Language barrier
Cultural challenges
Continuity chapter in contract missing or substandard
Consequence: if something goes (seriously) wrong, there is not enough knowledge and experience within 3rd Party
16

3rd Parties: ImprovementsIn contracts: explicitly set out Continuity governance and responsibility (use RASCI; see Annex):
Interface with Operations, other 3rd Parties and Calamity Team
Compliance with company policies
Redundancy & Backups
CMDB maintenance
Recovery Plans
Exercises
Reporting & KPI’s
Let 3rd Parties be in charge where they have to be
Use regular (‘live’) exercises for fine tuning of governance and responsibilities of both Demand and Supply
17

Exercises: ObservationsInfrequent tests and exercises (if done at all):
Mostly operational or low-level
Limited scope
Hardly ever ‘live’ exercises
Consequence: organisation (Operations and Calamity Team) and 3rd Parties are not prepared:
Resilience is low
Recovery depends on individual skills (if at all present) and luck
18

Exercises: ImprovementsPerform tests and joint exercises regularly (every 6 months)
“Joint” = Operations, Calamity Team, and 3rd Parties
Scope:
Strategic and tactical level
All aspects
Live exercises wherever possible
Leave operational level to 3rd Parties; check regularly if they comply
19

SummaryImproved cooperation and sufficient measures will lead to lower probability and lower impact:
Resilience: less calamities (and less incidents)
Recovery:
Less discussion at start of calamity:
Prioritisation known beforehand
Responsibilities known beforehand
Impact easy to determine
Faster and better decisions
Faster resumption of operations
This results in sustained less time loss, so:
Higher client satisfaction
Lower costs
20

Thanks for your Attention!

Annex

Failover: Definition
23
CHARACTERISTIC CRITERIA SECONDARY LOCATION
LOCATION Geo Redundant
CONFIGURATION (GENERAL)Production Like, w.r.t. at least:- Sizing- Performance- Connectivity
CONFIGURATION (OS) Identical to Primary
CONFIGURATION (DBASE) Identical to Primary
CONFIGURATION (APPLICATION) Identical to Primary
CHANGE PROCESS Identical to Primary
TYPE
Depending on RTO:- If RTO = 0 —> ‘Twinning’- If RTO < 1 Hrs —> Hot Standby- If RTO < 4 Hrs —> Warm Standby- If RTO > 4 Hrs —> Cold Standby
EXERCISE (‘PDCA’) At least 1*/Year, with dedicated Exercise Plan
CMDB Included

CMDB: Configuration Items
24
SUBJECT CONFIGURATION ITEMS
APPLICATION Owner, Holder, 3rd Party, Importance, Service Level, IT/Business Chains
HOST Server Function: Application, DBase, …, Failover (Twin, Hot, Warm, Cold), …
Primary Location: Site, Segment, Room, Cluster
Secondary Location
Hardware: Manufacturer, Model
Operating System: Manufacturer, Version, End-Of-Life Date
Primary IP Address, Secondary IP Address
Most recent Discovery Scan Date
Starting point for IT Application Configuration Items:

RASCI: Terminology
25
TERM DEFINITION
RESPONSIBLEThose who do the work to achieve the task. There is at least one role with a participation type of responsible, although others can be delegated to assist in the work required (see support role)
ACCOUNTABLEThe one ultimately answerable for the correct and thorough completion of the deliverable or task, and the one who delegates the work to those responsible. In other words, an accountable must sign off (approve) on work that responsible provides. There must be only one accountable specified for each task or deliverable
SUPPORT Resources allocated to responsible. Unlike consulted, who may provide input to the task, support help complete the task
CONSULTED Those whose opinions are sought, typically subject matter experts; and with whom there is two-way communication
INFORMED Those who are kept up-to-date on progress, often only on completion of the task or deliverable; and with whom there is just one-way communication
Apart from missing governance, the basis for misunderstandings is often a common definition for ‘responsible’, ‘accountable’, …; the table below is a pragmatic approach:


















