
ICMR 2014 - Sparse Kernel Learning Poster
1
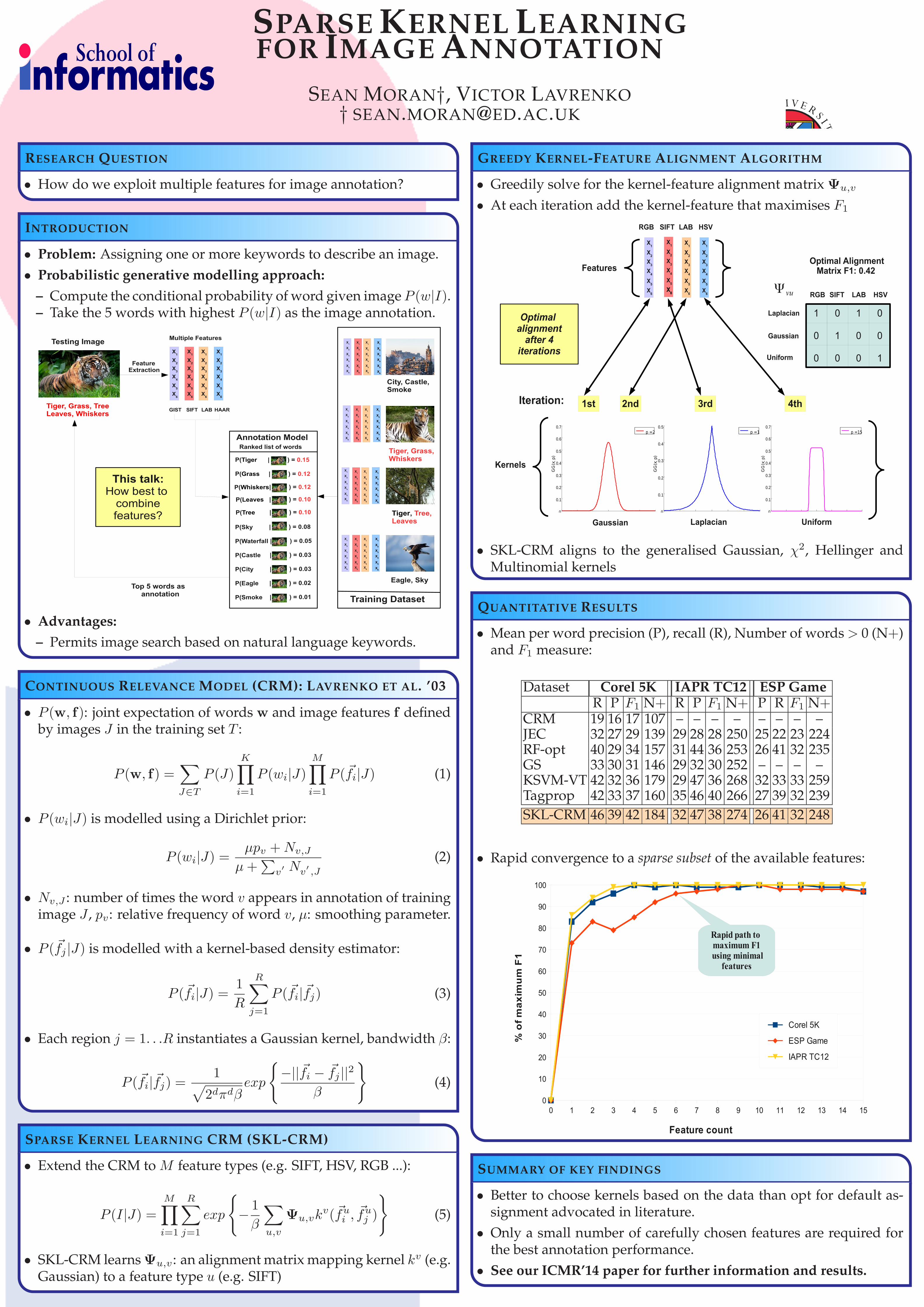
S PARSE K ERNEL L EARNING FOR I MAGE A NNOTATION S EAN M ORAN † ,V ICTOR L AVRENKO † SEAN . MORAN @ ED . AC . UK R ESEARCH Q UESTION • How do we exploit multiple features for image annotation? I NTRODUCTION • Problem: Assigning one or more keywords to describe an image. • Probabilistic generative modelling approach: – Compute the conditional probability of word given image P (w |I ). – Take the 5 words with highest P (w |I ) as the image annotation. Feature Extraction GIST SIFT LAB HAAR Tiger, Grass, Whiskers City, Castle, Smoke Tiger, Tree, Leaves Eagle, Sky Training Dataset P(Tiger | ) = 0.15 P(Grass | ) = 0.12 P(Whiskers| ) = 0.12 Top 5 words as annotation This talk: How best to combine features? Multiple Features Ranked list of words Tiger, Grass, Tree Leaves, Whiskers Annotation Model P(Leaves | ) = 0.10 P(Tree | ) = 0.10 P(Smoke | ) = 0.01 Testing Image P(City | ) = 0.03 P(Waterfall | ) = 0.05 P(Castle | ) = 0.03 P(Eagle | ) = 0.02 P(Sky | ) = 0.08 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 6 X 5 X 4 X 3 X 2 X 1 X 6 X 5 X 4 X 3 X 2 X 1 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 6 X 5 X 4 X 3 X 2 X 1 X 6 X 5 X 4 X 3 X 2 X 1 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 6 X 5 X 4 X 3 X 2 X 1 X 6 X 5 X 4 X 3 X 2 X 1 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 6 X 5 X 4 X 3 X 2 X 1 X 6 X 5 X 4 X 3 X 2 X 1 X 1 X 2 X 3 X 4 X 5 X 6 • Advantages: – Permits image search based on natural language keywords. C ONTINUOUS R ELEVANCE M ODEL (CRM): L AVRENKO ET AL . ’03 • P (w, f ): joint expectation of words w and image features f defined by images J in the training set T : P (w, f )= X J ∈T P (J ) K Y i=1 P (w i |J ) M Y i=1 P ( ~ f i |J ) (1) • P (w i |J ) is modelled using a Dirichlet prior: P (w i |J )= μp v + N v,J μ + ∑ v 0 N v 0 ,J (2) • N v,J : number of times the word v appears in annotation of training image J , p v : relative frequency of word v , μ: smoothing parameter. • P ( ~ f j |J ) is modelled with a kernel-based density estimator: P ( ~ f i |J )= 1 R R X j =1 P ( ~ f i | ~ f j ) (3) • Each region j =1. . .R instantiates a Gaussian kernel, bandwidth β : P ( ~ f i | ~ f j )= 1 p 2 d π d β exp ( -|| ~ f i - ~ f j || 2 β ) (4) S PARSE K ERNEL L EARNING CRM (SKL-CRM) • Extend the CRM to M feature types (e.g. SIFT, HSV, RGB ...): P (I |J )= M Y i=1 R X j =1 exp ( - 1 β X u,v Ψ u,v k v ( ~ f u i , ~ f u j ) ) (5) • SKL-CRM learns Ψ u,v : an alignment matrix mapping kernel k v (e.g. Gaussian) to a feature type u (e.g. SIFT) G REEDY K ERNEL -F EATURE A LIGNMENT A LGORITHM • Greedily solve for the kernel-feature alignment matrix Ψ u,v • At each iteration add the kernel-feature that maximises F 1 Features Kernels Laplacian RGB HSV Optimal Alignment Matrix F1: 0.42 Gaussian Uniform X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 X 1 X 2 X 3 X 4 X 5 X 6 SIFT LAB 1 0 1 0 0 1 0 0 0 0 0 1 RGB SIFT LAB HSV Laplacian Gaussian Uniform Ψ vu X 6 −6 −4 −2 0 2 4 6 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 GG(x ; p) p =2 −6 −4 −2 0 2 4 6 0 0.1 0.2 0.3 0.4 0.5 GG(x ; p) p =1 −6 −4 −2 0 2 4 6 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 GG(x ; p) p =15 2nd 1st Iteration: 3rd 4th Optimal alignment after 4 iterations • SKL-CRM aligns to the generalised Gaussian, χ 2 , Hellinger and Multinomial kernels Q UANTITATIVE R ESULTS • Mean per word precision (P), recall (R), Number of words > 0 (N+) and F 1 measure: Dataset Corel 5K IAPR TC12 ESP Game R P F 1 N+ R P F 1 N+ P R F 1 N+ CRM 19 16 17 107 – – – – – – – – JEC 32 27 29 139 29 28 28 250 25 22 23 224 RF-opt 40 29 34 157 31 44 36 253 26 41 32 235 GS 33 30 31 146 29 32 30 252 – – – – KSVM-VT 42 32 36 179 29 47 36 268 32 33 33 259 Tagprop 42 33 37 160 35 46 40 266 27 39 32 239 SKL-CRM 46 39 42 184 32 47 38 274 26 41 32 248 • Rapid convergence to a sparse subset of the available features: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 0 10 20 30 40 50 60 70 80 90 100 Corel 5K ESP Game IAPR TC12 Feature count % of maximum F1 Rapid path to maximum F1 using minimal features S UMMARY OF KEY FINDINGS • Better to choose kernels based on the data than opt for default as- signment advocated in literature. • Only a small number of carefully chosen features are required for the best annotation performance. • See our ICMR’14 paper for further information and results.
-
Upload
sean-moran -
Category
Technology
-
view
523 -
download
5
Transcript of ICMR 2014 - Sparse Kernel Learning Poster
SPARSE KERNEL LEARNINGFOR IMAGE ANNOTATION
SEAN MORAN†, VICTOR LAVRENKO† [email protected]
RESEARCH QUESTION
• How do we exploit multiple features for image annotation?
INTRODUCTION
• Problem: Assigning one or more keywords to describe an image.• Probabilistic generative modelling approach:
– Compute the conditional probability of word given image P (w|I).– Take the 5 words with highest P (w|I) as the image annotation.
Feature Extraction
GIST SIFT LAB HAAR
Tiger, Grass, Whiskers
City, Castle, Smoke
Tiger, Tree, Leaves
Eagle, Sky
Training Dataset
P(Tiger | ) = 0.15
P(Grass | ) = 0.12
P(Whiskers| ) = 0.12
Top 5 words as annotation
This talk:How best to
combinefeatures?
Multiple Features
Ranked list of words
Tiger, Grass, Tree Leaves, Whiskers
Annotation Model
P(Leaves | ) = 0.10
P(Tree | ) = 0.10
P(Smoke | ) = 0.01
Testing Image
P(City | ) = 0.03
P(Waterfall | ) = 0.05
P(Castle | ) = 0.03
P(Eagle | ) = 0.02
P(Sky | ) = 0.08
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X6
X5
X4
X3
X2
X1
X6
X5
X4
X3
X2
X1
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X6
X5
X4
X3
X2
X1
X6
X5
X4
X3
X2
X1
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X6
X5
X4
X3
X2
X1
X6
X5
X4
X3
X2
X1
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X6
X5
X4
X3
X2
X1
X6
X5
X4
X3
X2
X1
X1
X2
X3
X4
X5
X6
• Advantages:– Permits image search based on natural language keywords.
CONTINUOUS RELEVANCE MODEL (CRM): LAVRENKO ET AL. ’03
• P (w, f): joint expectation of words w and image features f definedby images J in the training set T :
P (w, f) =∑J∈T
P (J)K∏
i=1
P (wi|J)M∏i=1
P (~fi|J) (1)
• P (wi|J) is modelled using a Dirichlet prior:
P (wi|J) =µpv +Nv,J
µ+∑
v′ Nv′ ,J
(2)
• Nv,J : number of times the word v appears in annotation of trainingimage J , pv : relative frequency of word v, µ: smoothing parameter.
• P (~fj |J) is modelled with a kernel-based density estimator:
P (~fi|J) =1R
R∑j=1
P (~fi|~fj) (3)
• Each region j = 1. . .R instantiates a Gaussian kernel, bandwidth β:
P (~fi|~fj) =1√
2dπdβexp
{−||~fi − ~fj ||2
β
}(4)
SPARSE KERNEL LEARNING CRM (SKL-CRM)
• Extend the CRM to M feature types (e.g. SIFT, HSV, RGB ...):
P (I|J) =M∏i=1
R∑j=1
exp
{− 1β
∑u,v
Ψu,vkv(~fu
i ,~fuj )
}(5)
• SKL-CRM learns Ψu,v : an alignment matrix mapping kernel kv (e.g.Gaussian) to a feature type u (e.g. SIFT)
GREEDY KERNEL-FEATURE ALIGNMENT ALGORITHM
• Greedily solve for the kernel-feature alignment matrix Ψu,v
• At each iteration add the kernel-feature that maximises F1
Features
Kernels
Laplacian
RGB HSV
Optimal Alignment Matrix F1: 0.42
Gaussian Uniform
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
X1
X2
X3
X4
X5
X6
SIFT LAB
1 0 1 0
0 1 0 0
0 0 0 1
RGB SIFT LAB HSV
Laplacian
Gaussian
Uniform
Ψ vuX6
−6 −4 −2 0 2 4 60
0.1
0.2
0.3
0.4
0.5
0.6
0.7
x
GG
(x; p
)
p =2
−6 −4 −2 0 2 4 60
0.1
0.2
0.3
0.4
0.5
x
GG
(x; p
)
p =1
−6 −4 −2 0 2 4 60
0.1
0.2
0.3
0.4
0.5
0.6
0.7
x
GG
(x; p
)
p =15
2nd1stIteration: 3rd 4th
Optimal alignment
after 4iterations
• SKL-CRM aligns to the generalised Gaussian, χ2, Hellinger andMultinomial kernels
QUANTITATIVE RESULTS
• Mean per word precision (P), recall (R), Number of words > 0 (N+)and F1 measure:
Dataset Corel 5K IAPR TC12 ESP GameR P F1 N+ R P F1 N+ P R F1 N+
CRM 19 16 17 107 – – – – – – – –JEC 32 27 29 139 29 28 28 250 25 22 23 224RF-opt 40 29 34 157 31 44 36 253 26 41 32 235GS 33 30 31 146 29 32 30 252 – – – –KSVM-VT 42 32 36 179 29 47 36 268 32 33 33 259Tagprop 42 33 37 160 35 46 40 266 27 39 32 239SKL-CRM 46 39 42 184 32 47 38 274 26 41 32 248
• Rapid convergence to a sparse subset of the available features:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 150
10
20
30
40
50
60
70
80
90
100
Corel 5K
ESP Game
IAPR TC12
Feature count
% o
f m
ax
imu
m F
1
Rapid path to maximum F1
using minimalfeatures
SUMMARY OF KEY FINDINGS
• Better to choose kernels based on the data than opt for default as-signment advocated in literature.• Only a small number of carefully chosen features are required for
the best annotation performance.• See our ICMR’14 paper for further information and results.


















