
I256 Applied Natural Language Processing Fall 2009 Lecture 10 Classification Barbara Rosario.
65
I256 Applied Natural Language Processing Fall 2009 Lecture 10 Classificat ion Barbara Rosario
-
date post
21-Dec-2015 -
Category
Documents
-
view
216 -
download
0
Transcript of I256 Applied Natural Language Processing Fall 2009 Lecture 10 Classification Barbara Rosario.

I256
Applied Natural Language Processing
Fall 2009
Lecture 10
Classification
Barbara Rosario

2
Today
• Classification tasks• Various issues regarding classification
– Clustering vs. classification, binary vs. multi-way, flat vs. hierarchical classification, variants…
• Introduce the steps necessary for a classification task– Define classes (aka labels)– Label text– Define and extract features– Training and evaluation
• NLTK example

3
Classification tasks
Assign the correct class label for a given input/object
In basic classification tasks, each input is considered in isolation from all other inputs, and the set of labels is defined in advance.
Examples:
Adapted from: Foundations of Statistical NLP (Manning et al)
Problem Object Label’s categories Tagging Word POSSense Disambiguation Word The word’s sensesInformation retrieval Document Relevant/not relevantSentiment classification Document Positive/negativeText categorization Document Topics/classesAuthor identification Document AuthorsLanguage identification Document Language

4
Author identification • They agreed that Mrs. X should only hear of the departure
of the family, without being alarmed on the score of the gentleman's conduct; but even this partial communication gave her a great deal of concern, and she bewailed it as exceedingly unlucky that the ladies should happen to go away, just as they were all getting so intimate together.
• Gas looming through the fog in divers places in the streets, much as the sun may, from the spongey fields, be seen to loom by husbandman and ploughboy. Most of the shops lighted two hours before their time--as the gas seems to know, for it has a haggard and unwilling look. The raw afternoon is rawest, and the dense fog is densest, and the muddy streets are muddiest near that leaden-headed old obstruction, appropriate ornament for the threshold of a leaden-headed old corporation, Temple Bar.

5
Author identification
• Called Stylometry in the humanities
• Jane Austen (1775-1817), Pride and Prejudice
• Charles Dickens (1812-70), Bleak House

6
Author identification
• Federalist papers – 77 short essays written in 1787-1788 by Hamilton,
Jay and Madison to persuade NY to ratify the US Constitution; published under a pseudonym
– The authorships of 12 papers was in dispute (disputed papers)
– In 1964 Mosteller and Wallace* solved the problem– They identified 70 function words as good candidates
for authorships analysis – Using statistical inference they concluded the author
was Madison
Mosteller and Wallace 1964. Inference and Disputed Authorship: The Federalist.

7
Function words for Author Identification

8
Function words for Author Identification

9
Language identification
• Tutti gli esseri umani nascono liberi ed eguali in dignità e diritti. Essi sono dotati di ragione e di coscienza e devono agire gli uni verso gli altri in spirito di fratellanza.
• Alle Menschen sind frei und gleich an Würde und Rechten geboren. Sie sind mit Vernunft und Gewissen begabt und sollen einander im Geist der Brüderlichkeit begegnen.
Universal Declaration of Human Rights, UN, in 363 languages

10
Language identification• égaux • eguali • iguales • edistämään• Ü• ¿• How to do determine, for a stretch of text, which language it is from?• Turns out to be really simple• Just a few character bigrams can do it (Sibun & Reynar 96)
– Using special character sets helps a bit, but barely

11
Language Identification
(Sibun & Reynar 96)

12
Confusion Matrix
• A table that shows, for each class, which ones your algorithm got right and which wrong
Algorithm’s guess
Gold standard

13

14
Text categorization
• Topic categorization: classify the document into semantics topics
The U.S. swept into the Davis Cup final on Saturday when twins Bob and Mike Bryan defeated Belarus's Max Mirnyi and Vladimir Voltchkov to give the Americans an unsurmountable 3-0 lead in the best-of-five semi-final tie.
One of the strangest, most relentless hurricane seasons on record reached new bizarre heights yesterday as the plodding approach of Hurricane Jeanne prompted evacuation orders for hundreds of thousands of Floridians and high wind warnings that stretched 350 miles from the swamp towns south of Miami to the historic city of St. Augustine.

15
Text Categorization Applications
• Web pages organized into category hierarchies• Journal articles indexed by subject categories
(e.g., the Library of Congress, MEDLINE, etc.)• Patents archived using International Patent
Classification• Patient records coded using international
insurance categories• E-mail message filtering• Spam vs. anti-palm• Customer service message classification• News events tracked and filtered by topics

16
News topic categorization
• http://news.google.com/
• Reuters– Gold standard– Collection of (21,578) newswire
documents. – For research purposes: a standard text
collection to compare systems and algorithms
– 135 valid topics categories

17
Reuters
• Top topics in Reuters

18
Reuters
<REUTERS TOPICS="YES" LEWISSPLIT="TRAIN" CGISPLIT="TRAINING-SET" OLDID="12981" NEWID="798">
<DATE> 2-MAR-1987 16:51:43.42</DATE>
<TOPICS><D>livestock</D><D>hog</D></TOPICS>
<TITLE>AMERICAN PORK CONGRESS KICKS OFF TOMORROW</TITLE>
<DATELINE> CHICAGO, March 2 - </DATELINE><BODY>The American Pork Congress kicks off
tomorrow, March 3, in Indianapolis with 160 of the nations pork producers from 44 member states determining industry positions on a number of issues, according to the National Pork Producers Council, NPPC.
Delegates to the three day Congress will be considering 26 resolutions concerning various issues, including the future direction of farm policy and the tax law as it applies to the agriculture sector. The delegates will also debate whether to endorse concepts of a national PRV (pseudorabies virus) control and eradication program, the NPPC said.
A large trade show, in conjunction with the congress, will feature the latest in technology in all areas of the industry, the NPPC added. Reuter
</BODY></TEXT></REUTERS>

19
Outline
• Classification tasks• Various issues regarding classification
– Clustering vs. classification, binary vs. multi-way, flat vs. hierarchical classification, variants…
• Introduce the steps necessary for a classification task– Define classes (aka labels)– Label text– Define and extract features– Training and evaluation
• NLTK example

20
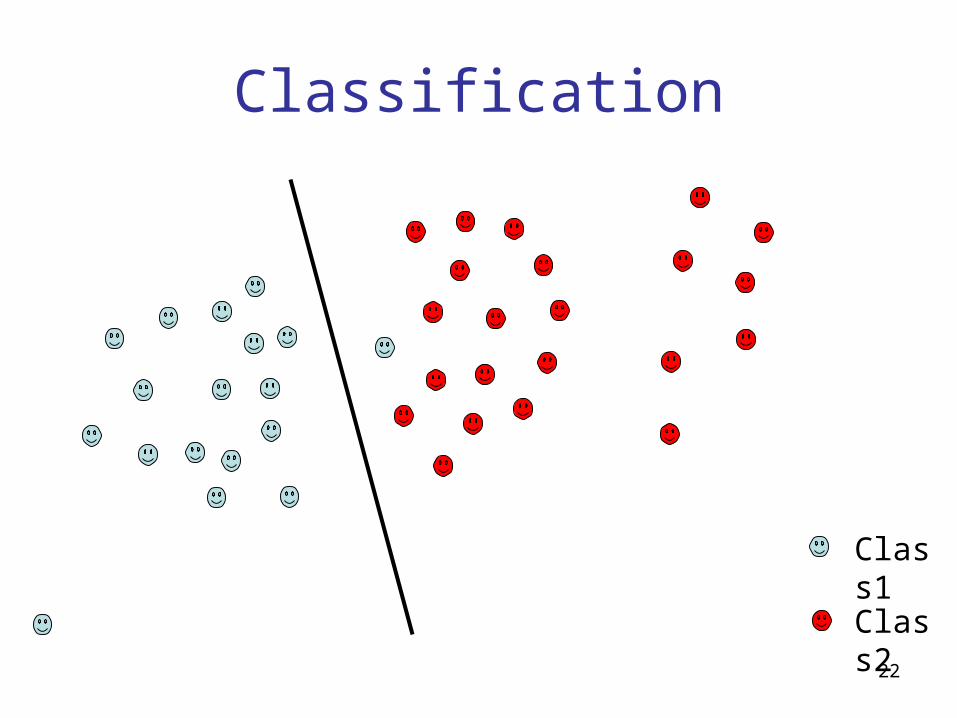
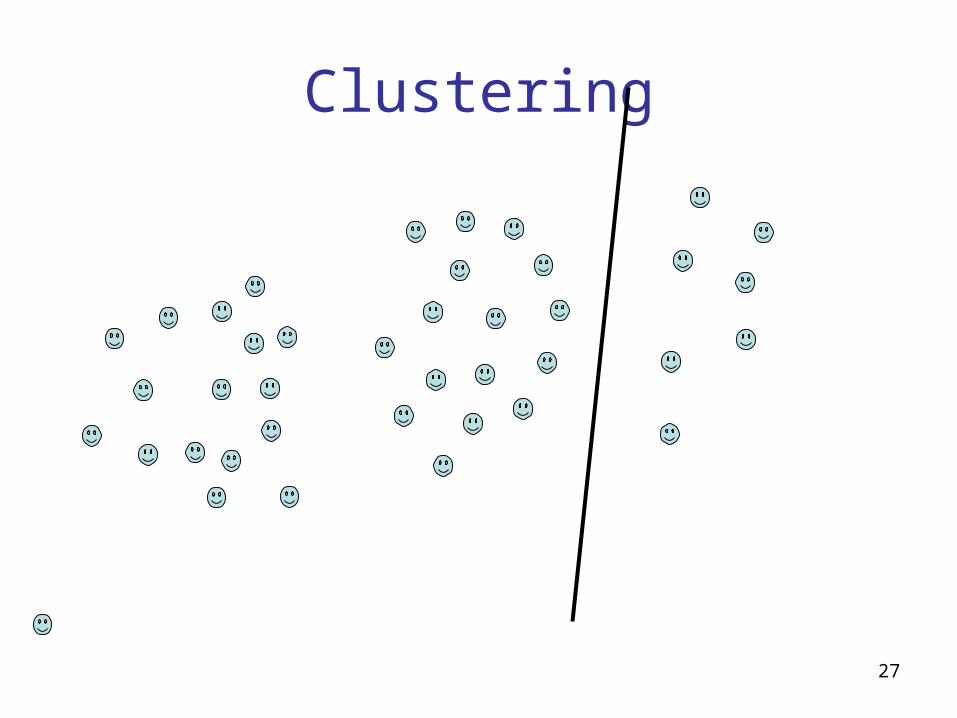
Classification vs. Clustering
• Classification assumes labeled data: we know how many classes there are and we have examples for each class (labeled data).
• Classification is supervised• In Clustering we don’t have labeled data; we
just assume that there is a natural division in the data and we may not know how many divisions (clusters) there are
• Clustering is unsupervised

21
Classification
Class1
Class2
22
Classification
Class1
Class2

23
Classification
Class1
Class2

24
Classification
Class1
Class2

25
Clustering

26
Clustering
27
Clustering

28
Clustering

29
Clustering

30
Supervised classification
• A classifier is called supervised if it is built based on training corpora containing the correct label for each input.

31
Binary vs. multi-way classification
• Binary classification: two classes
• Multi-way classification: more than two classes
• Sometime it can be convenient to treat a multi-way problem like a binary one: one class versus all the others, for all classes

32
Flat vs. Hierarchical classification
• Flat classification: relations between the classes undetermined
• Hierarchical classification: hierarchy where each node is the sub-class of its parent’s node

33
Variants• In single-category text classification each
text belongs to exactly one category• In multi-category text classification, each
text can have zero or more categories• In open-class classification, the set of
labels is not defined in advance• In sequence classification, a list of inputs
are jointly classified. – E.g. POS tagging

34
Reuters (multi-category)<REUTERS TOPICS="YES" LEWISSPLIT="TRAIN" CGISPLIT="TRAINING-SET" OLDID="12981" NEWID="798">
<DATE> 2-MAR-1987 16:51:43.42</DATE>
<TOPICS><D>livestock</D><D>hog</D></TOPICS>
<TITLE>AMERICAN PORK CONGRESS KICKS OFF TOMORROW</TITLE>
<DATELINE> CHICAGO, March 2 - </DATELINE><BODY>The American Pork Congress kicks off
tomorrow, March 3, in Indianapolis with 160 of the nations pork producers from 44 member states determining industry positions on a number of issues, according to the National Pork Producers Council, NPPC.
Delegates to the three day Congress will be considering 26 resolutions concerning various issues, including the future direction of farm policy and the tax law as it applies to the agriculture sector. The delegates will also debate whether to endorse concepts of a national PRV (pseudorabies virus) control and eradication program, the NPPC said.
A large trade show, in conjunction with the congress, will feature the latest in technology in all areas of the industry, the NPPC added. Reuter
</BODY></TEXT></REUTERS>

35
Outline
• Classification tasks• Various issues regarding classification
– Clustering vs. classification, binary vs. multi-way, flat vs. hierarchical classification, variants…
• Introduce the steps necessary for a classification task– Define classes (aka labels)– Label text– Define and extract features– Training and evaluation
• NLTK example

36
Classification
• Define classes• Label text• Extract Features• Choose a classifier
– The Naive Bayes Classifier – NN (perceptron)– SVM– …. (next class)
• Train it (and test it)• Use it to classify new examples

37
Categories (Labels, Classes)
• Labeling data• 2 problems: • Decide the possible classes (which ones,
how many)– Domain and application dependent– Trade-off between accuracy and coverage
• Label text– Difficult, time consuming, inconsistency
between annotators

38
Cost of Manual Text Categorization
• Time and money!– Yahoo!
– 200 (?) people for manual labeling of Web pages– using a hierarchy of 500,000 categories
– MEDLINE (National Library of Medicine)– $2 million/year for manual indexing of journal articles– using MEdical Subject Headings (18,000 categories)
– Mayo Clinic– $1.4 million annually for coding patient-record events– using the International Classification of Diseases (ICD) for billing
insurance companies
– US Census Bureau decennial census (1990: 22 million responses)
– 232 industry categories and 504 occupation categories– $15 million if fully done by hand

39
Features• >>> text = "Seven-time Formula One champion Michael Schumacher
took on the Shanghai circuit Saturday in qualifying for the first Chinese Grand Prix."
• >>> label = “sport” • >>> labeled_text = LabeledText(text, label)
• Here the classification takes as input the whole string
• What’s the problem with that?• What are the features that could be useful for
this example?

40
Feature terminology
• Feature: An aspect of the text that is relevant to the task• Feature value: the realization of the feature in the text• Some typical features
– Words present in text : Kerry, Schumacher, China… – Frequency of word: Kerry(10), Schumacher(1)…– Are there dates? Yes/no– Capitalization (is word capitalized?)– Are there PERSONS? Yes/no– Are there ORGANIZATIONS? Yes/no– WordNet: Holonyms (China is part of Asia),
Synonyms(China, People's Republic of China, mainland China)– Chunks, parse trees, POS

41
Feature Types
• Boolean (or Binary) Features• Features that generate boolean (binary) values. • Boolean features are the simplest and the most
common type of feature.
– f1(text) = 1 if text contain “Kerry”
0 otherwise– f2(text) = 1 if text contain PERSON
0 otherwise

42
Feature Types
• Integer Features• Features that generate integer values.
• Integer features can be used to give classifiers access to more precise information about the text.
– f1(text) = Number of times text contains “Kerry”
– f2(text) = Number of times text contains PERSON

43
Feature selection
• Selecting relevant features and deciding how to encode them for a learning method can have an enormous impact on the learning method's ability to extract a good model
• How do we choose the “right” features?• Typically, feature extractors are built through a
process of trial-and-error, guided by intuitions about what information is relevant to the problem. – But there are also more “principled” way of features
selection

44
Feature selection
• There are usually limits to the number of features that you should use with a given learning algorithm — if you provide too many features, then the algorithm will have a higher chance of relying on idiosyncrasies of your training data that don't generalize well to new examples. – This problem is known as overfitting, and
can be especially problematic when working with small training sets.

45
Feature selection
• Once an initial set of features has been chosen, a very productive method for refining the feature set is error analysis. First, we select a development set, containing the corpus data for creating the model. This development set is then subdivided into the training set and the dev-test set.
• The training set is used to train the model, and the dev-test set is used to perform error analysis. – Look at errors, change features or model
• The test set serves in our final evaluation of the system.

46
Outline
• Classification tasks• Various issues regarding classification
– Clustering vs. classification, binary vs. multi-way, flat vs. hierarchical classification, variants…
• Introduce the steps necessary for a classification task– Define classes (aka labels)– Label text– Define and extract features– Training and evaluation
• NLTK example

47
Training
• Adaptation of the classifier to the data• Usually the classifier is defined by a set of
parameters• Training is the procedure for finding a “good”
set of parameters• Goodness is determined by an optimization
criterion such as misclassification rate• Some classifiers are guaranteed to find the
optimal set of parameters• (Next class)

48
(Linear) Classification
Class1
Class2
Linear classifier: g(x) = wx + w0
parameters: w, w0

49
(Linear) Classification
Class1
Class2
Linear classifier: g(x) = wx + w0
Changing the parameters: w, w0

50
(Linear) Classification
Class1
Class2
Linear classifier: g(x) = wx + w0
For each set of parameters: w, w0, calculate error

51
(Linear) Classification
Class1
Class2
Linear classifier: g(x) = wx + w0
For each set of parameters: w, w0, calculate error

52
(Linear) Classification
Class1
Class2
Linear classifier: g(x) = wx + w0
For each set of parameters: w, w0, calculate error
Choose the classier with the lower rate of misclassification

53
Testing & evaluation of the classifier
• After choosing the parameters of the classifiers (i.e. after training it) we need to test how well it’s doing on a test set (not included in the training set)– How trustworthy the model is– Evaluation can also be an effective tool for
guiding us in making future improvements to the model.

54
The Test Set
• This test set typically has the same format as the training set– It is very important that the test set be distinct from the training
corpus: if we simply re-used the training set as the test set, then a model that simply memorized its input, without learning how to generalize to new examples, would receive misleadingly high scores.
• When building the test set, there is often a trade-off between the amount of data available for testing and the amount available for training. – The more training data the better, but need to make sure the test
set is diverse• Another consideration when choosing the test set is the
degree of similarity between instances in the test set and those in the development set. The more similar these two datasets are, the less confident we can be that evaluation results will generalize to other datasets. – But they can’t be totally different either!

55
Accuracy
• The simplest metric: accuracy, measures the percentage of inputs in the test set that the classifier correctly labeled. – For example, a spam classifier that predicts correctly
spam 60 times in an test set containing 80 email would have an accuracy of 60/80 = 75%.
• Important to take into consideration the frequencies of the individual class labels – If only 1/100 is spam, an accuracy of 90% is bad– If ½ is spam, accuracy of 90% is good
• This is also why we use precision & recall and F-measure– Important: compare with fair baselines

56
Evaluating classifiers
• Contingency table for the evaluation of a binary classifier
GREEN is correct
RED is correct
GREEN was assigned a b
RED was assigned c d
• Accuracy = (a+d)/(a+b+c+d)• Precision: P_GREEN = a/(a+b), P_ RED = d/(c+d)• Recall: R_GREEN = a/(a+c), R_ RED = d/(b+d)

57
Training size• The more the better! (usually)
– Make sure that test set contains instances for all classes
• Results for text classification*
*From: Improving the Performance of Naive Bayes for Text Classification, Shen and Yang

58
Training size
*From: Improving the Performance of Naive Bayes for Text Classification, Shen and Yang

59
Training size
*From: Improving the Performance of Naive Bayes for Text Classification, Shen and Yang

60
Training Size
• Author identification
Authorship Attribution a Comparison Of Three Methods, Matthew Care

61
Document classification NLTK example
• Define a feature extractor: a feature for each word, indicating whether the document contains that word.

62
Document classification NLTK example
• Define a feature extractor: a feature for each word, indicating whether the document contains that word.

63
Document classification NLTK example
• Now that we've defined our feature extractor, we can use it to train a classifier.
• To check how reliable the resulting classifier is, we compute its accuracy on the test set

64
Document classification NLTK example
• We can examine the classifier to determine which features it found most effective for distinguishing the review’s sentiment
– Apparently in this corpus, a review that mentions "Seagal" is almost 8 times more likely to be negative than positive, while a review that mentions "Damon" is about 6 times more likely to be positive.

65
Next class
• Classification models
• Reading: Chapter 6 NLTK book (especially 6.4 on)



![CS276A Text Retrieval and Mining Lecture 16 [Borrows slides from Ray Mooney and Barbara Rosario]](https://static.fdocuments.in/doc/165x107/56649d5f5503460f94a406ad/cs276a-text-retrieval-and-mining-lecture-16-borrows-slides-from-ray-mooney.jpg)








![1 CS276 Information Retrieval and Web Search Lecture 13: Classifiers: kNN, Rocchio, etc. [Borrows slides from Ray Mooney and Barbara Rosario]](https://static.fdocuments.in/doc/165x107/56649ef75503460f94c0ac02/1-cs276-information-retrieval-and-web-search-lecture-13-classifiers-knn.jpg)





