
1 I256: Applied Natural Language Processing Marti Hearst Sept 13, 2006.
25
1 I256: Applied Natural Language Processing Marti Hearst Sept 13, 2006
-
Upload
allison-sharp -
Category
Documents
-
view
215 -
download
1
Transcript of 1 I256: Applied Natural Language Processing Marti Hearst Sept 13, 2006.

1
I256: Applied Natural Language Processing
Marti HearstSept 13, 2006

2
Counting Tokens
Useful for lots of thingsOne cute application: see who talks where in a novel
Idea comes from Eick et al. who did it with The Jungle Book by Kipling

3
SeeSoft Vizualization of Jungle Book Characters, From Eick, Steffen, and Sumner ‘92

4
The FreqDist Data Structure
Purpose: collect counts and frequencies for some phenomenonInitialize a new FreqDist:
from nltk_lite.probability import FreqDist fd = FreqDist()
When in a counting loop: fd.inc(‘item of interest’)
After done counting: fd.N() # total number of tokens counted fd.B() # number of unique tokens fd.samples() # list of all the tokens seen (there are N) fd.Nr(10) # number of samples that occurred 10 times fd.count(‘red’) # number of times the token ‘red’ was seen fd.freq(‘red’) # frequency of ‘red’; that is fd.count(‘red’)/fd.N() fd.max() # which token had the highest count fd.sorted_samples() # show the samples in decreasing order of frequency
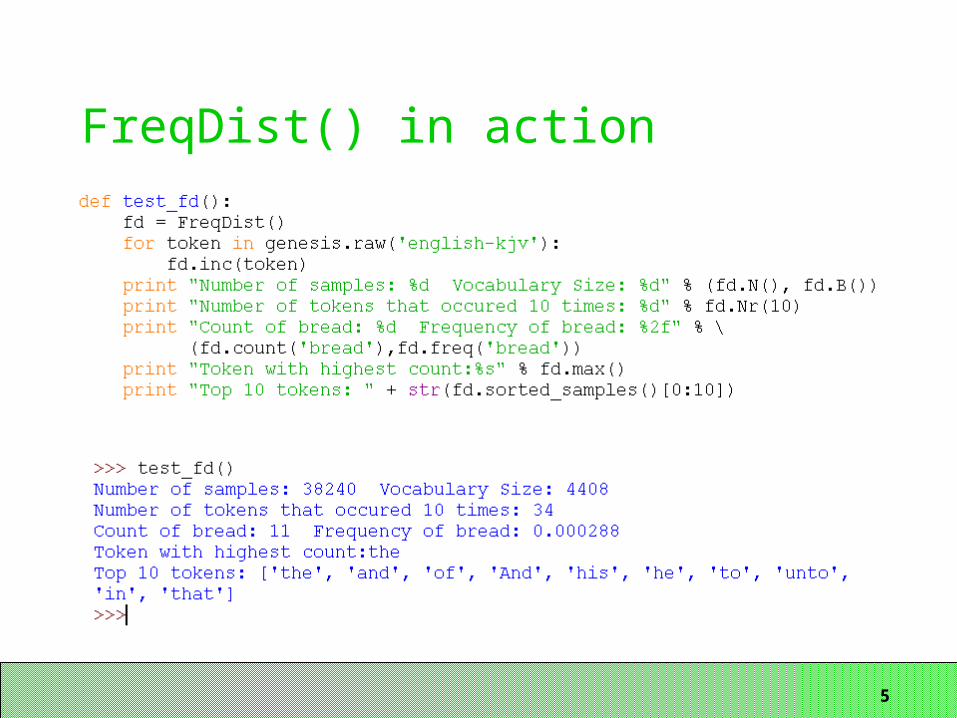
5
FreqDist() in action

6
Word Lengths by Language

7
Word Lengths by Language

8
Doing Character Distribution

9
How to determine the characters?
Write some code that takes as input a gutenberg file and quickly suggests who the main characters are.

10
How to determine the characters?
My solution: look for words that begin with capital letters; count how often each occurs.Then show the most frequent.

11

12
Language Modeling
A fundamental concept in NLPMain idea:
For a given language, some words are more likely than others to follow each other, orYou can predict (with some degree of accuracy) the probability that a given word will follow another word.

13Adapted from slide by Bonnie Dorr
Next Word Prediction
From a NY Times story...Stocks ...Stocks plunged this ….Stocks plunged this morning, despite a cut in interest ratesStocks plunged this morning, despite a cut in interest rates by the Federal Reserve, as Wall ...Stocks plunged this morning, despite a cut in interest rates by the Federal Reserve, as Wall Street began

14Adapted from slide by Bonnie Dorr
Human Word Prediction
Clearly, at least some of us have the ability to predict future words in an utterance.How?
Domain knowledgeSyntactic knowledgeLexical knowledge

15Adapted from slide by Bonnie Dorr
Simple Statistics Does a Lot
A useful part of the knowledge needed to allow word prediction can be captured using simple statistical techniquesIn particular, we'll rely on the notion of the probability of a sequence (a phrase, a sentence)

16Adapted from slide by Bonnie Dorr
N-Gram Models of Language
Use the previous N-1 words in a sequence to predict the next wordHow do we train these models?
Very large corpora

17Adapted from slide by Bonnie Dorr
Simple N-Grams
Assume a language has V word types in its lexicon, how likely is word x to follow word y?
Simplest model of word probability: 1/VAlternative 1: estimate likelihood of x occurring in new text based on its general frequency of occurrence estimated from a corpus (unigram probability)
popcorn is more likely to occur than unicorn
Alternative 2: condition the likelihood of x occurring in the context of previous words (bigrams, trigrams,…)
mythical unicorn is more likely than mythical popcorn

18
ConditonalFreqDist() Data Structure
A collection of FreqDist() objectsIndexed by the “condition” that is being tested or compared
Initialize a new one: cfd = ConditionalFreqDist()
Add a count cfd[‘berkeley’].inc(‘blue’)cfd[‘berkeley’].inc(‘gold’)cfd[‘stanford’].inc(‘red’)
Can access each FreqDist object by indexing on condition cfd[‘berkeley’].samples() cfd[‘berkeley’].N()
Can also get a list of the conditions from the cfd object cfd.conditions() >> [‘stanford’, ‘berkeley’]

19
Computing Next Words

20
Auto-generate a Story

21Adapted from slide by Bonnie Dorr
Applications
Why do we want to predict a word, given some preceding words?
Rank the likelihood of sequences containing various alternative hypotheses, e.g. for ASRTheatre owners say popcorn/unicorn sales have doubled...Assess the likelihood/goodness of a sentence
– for text generation or machine translation.
The doctor recommended a cat scan.El doctor recommendó una exploración del gato.

22
How to implement this?
Comparing Modal Verb Counts

23
Comparing Modals

24
Comparing Modals

25
Next Time
Part of Speech Tagging


















