
How saccadic models help predict where we look during a visual task? Application to visual quality...
30
Visual attention O. Le Meur Introduction Covert vs overt Bottom-Up vs Top-Down Saliency models Saccadic models Presentation Proposed model Tuning saccadic model A flexible framework Example: the quality task Conclusion How saccadic models help predict where we look during a visual task? Application to visual quality assessment. Olivier Le Meur 1 Antoine Coutrot 2 [email protected] 1 IRISA - University of Rennes 1, France 2 CoMPLEX, University College London, UK February 17, 2016 1 / 25
-
Upload
olivier-le-meur -
Category
Science
-
view
257 -
download
0
Transcript of How saccadic models help predict where we look during a visual task? Application to visual quality...

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
How saccadic models help predict where welook during a visual task?
Application to visual quality assessment.
Olivier Le Meur 1 Antoine Coutrot 2
1IRISA - University of Rennes 1, France
2CoMPLEX, University College London, UK
February 17, 20161 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Preamble
These slides are based on the following papers:
O. Le Meur & Z. Liu, Saccadic model of eyemovements for free-viewing condition, VisionResearch, 2015, doi:10.1016/j.visres.2014.12.026.
O. Le Meur & A. Coutrot, Introducingcontext-dependent and spatially-variant viewing
biases in saccadic models, Vision Research,2016.
2 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Outline
1 Introduction
2 Saliency models
3 Saccadic models
4 Tuning saccadic model
5 Conclusion
3 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Outline
1 IntroductionI Covert vs overtI Bottom-Up vs Top-Down
2 Saliency models
3 Saccadic models
4 Tuning saccadic model
5 Conclusion
4 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Introduction (1/2)
Visual attentionPosner proposed the following definition (Posner, 1980). Visual atten-tion is used:
ß to select important areas of our visual field (alerting);ß to search for a target in cluttered scenes (searching).
There are several kinds of visual attention:ß Overt visual attention: involving eye movements;ß Covert visual attention: without eye movements (Covert
fixations are not observable).
5 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Introduction (2/2)
Bottom-Up vs Top-Downß Bottom-Up: some things draw attention reflexively, in a
task-independent way (Involuntary; Very quick; Unconscious);
ß Top-Down: some things draw volitional attention, in atask-dependent way (Voluntary; Very slow; Conscious).
6 / 25
Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Outline
1 Introduction
2 Saliency models
3 Saccadic models
4 Tuning saccadic model
5 Conclusion
7 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saliency model (1/3)
Computational models of visual attention aim at predictingwhere we look within a scene.
ß Saliency model computes a 2D static saliency map from an inputimage.
ß Most of state-of-the-art models simulate the Bottom-Up Overtvisual attention.
8 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saliency model (2/3)
Taxonomy of models:ß Information Theoretic
models;ß Cognitive models;ß Graphical models;ß Spectral analysis
models;ß Pattern classification
models;ß Bayesian models.
Extracted from (Borji and Itti, 2013).9 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saliency model (3/3)
The picture is much clearer than 10 years ago!
New datasets, new metrics/benchmarks, new protocols, newmethods, new devices.....
10 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saliency model (3/3)
The picture is much clearer than 10 years ago!
New datasets, new metrics/benchmarks, new protocols, newmethods, new devices.....
BUTImportant aspects of our visual system are clearly overlooked:
Current models implicitly assume that eyes are equally likely tomove in any direction;
Viewing biases are not taken into account;
The temporal dimension is not considered (static saliency map).10 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Outline
1 Introduction
2 Saliency models
3 Saccadic modelsI PresentationI Proposed model
4 Tuning saccadic model
5 Conclusion
11 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Presentation (1/1)
ß Eye movements are composed of fixations and saccades. Asequence of fixations is called a visual scanpath.
ß When looking at visual scenes, we perform in average 4 visualfixations per second.
Saccadic models are used:1 to compute plausible visual
scanpaths (stochastic,saccade amplitudes /orientations...);
2 to infer the scanpath-basedsaliency map ⇔ to predictsalient areas!!
12 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saccadic model (1/6)
Let I : Ω ⊂ R2 7→ R3 an image and xt a fixation point at time t.We consider the 2D discrete conditional probability:
p (x|xt−1, . . . , xt−T) ∝ pBU (x)pB(d, φ)pM (x, t)
ß pBU : Ω 7→ [0, 1] is the grayscale saliency map;ß pB(d, φ) represents the joint probability distribution of saccade
amplitudes and orientations. d is the saccade amplitude between twofixation points xt and xt−1 (expressed in degree of visual angle), andφ is the angle (expressed in degree between these two points);
ß pM (x, t) represents the memory state of the location x at time t. Thistime-dependent term simulates the inhibition of return.
O. Le Meur & Z. Liu, Saccadic model of eye movements for free-viewingcondition, Vision Research, 2015.O. Le Meur & A. Coutrot, Introducing context-dependent and spatially-variantviewing biases in saccadic models, Vision Research, 2016.
13 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saccadic model (1/6)
Let I : Ω ⊂ R2 7→ R3 an image and xt a fixation point at time t.We consider the 2D discrete conditional probability:
p (x|xt−1, . . . , xt−T) ∝ pBU (x)pB(d, φ)pM (x, t)
ß pBU : Ω 7→ [0, 1] is the grayscale saliency map;ß pB(d, φ) represents the joint probability distribution of saccade
amplitudes and orientations. d is the saccade amplitude between twofixation points xt and xt−1 (expressed in degree of visual angle), andφ is the angle (expressed in degree between these two points);
ß pM (x, t) represents the memory state of the location x at time t. Thistime-dependent term simulates the inhibition of return.
O. Le Meur & Z. Liu, Saccadic model of eye movements for free-viewingcondition, Vision Research, 2015.O. Le Meur & A. Coutrot, Introducing context-dependent and spatially-variantviewing biases in saccadic models, Vision Research, 2016.
13 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saccadic model (1/6)
Let I : Ω ⊂ R2 7→ R3 an image and xt a fixation point at time t.We consider the 2D discrete conditional probability:
p (x|xt−1, . . . , xt−T) ∝ pBU (x)pB(d, φ)pM (x, t)
ß pBU : Ω 7→ [0, 1] is the grayscale saliency map;ß pB(d, φ) represents the joint probability distribution of saccade
amplitudes and orientations. d is the saccade amplitude between twofixation points xt and xt−1 (expressed in degree of visual angle), andφ is the angle (expressed in degree between these two points);
ß pM (x, t) represents the memory state of the location x at time t. Thistime-dependent term simulates the inhibition of return.
O. Le Meur & Z. Liu, Saccadic model of eye movements for free-viewingcondition, Vision Research, 2015.O. Le Meur & A. Coutrot, Introducing context-dependent and spatially-variantviewing biases in saccadic models, Vision Research, 2016.
13 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saccadic model (1/6)
Let I : Ω ⊂ R2 7→ R3 an image and xt a fixation point at time t.We consider the 2D discrete conditional probability:
p (x|xt−1, . . . , xt−T) ∝ pBU (x)pB(d, φ)pM (x, t)
ß pBU : Ω 7→ [0, 1] is the grayscale saliency map;ß pB(d, φ) represents the joint probability distribution of saccade
amplitudes and orientations. d is the saccade amplitude between twofixation points xt and xt−1 (expressed in degree of visual angle), andφ is the angle (expressed in degree between these two points);
ß pM (x, t) represents the memory state of the location x at time t. Thistime-dependent term simulates the inhibition of return.
O. Le Meur & Z. Liu, Saccadic model of eye movements for free-viewingcondition, Vision Research, 2015.O. Le Meur & A. Coutrot, Introducing context-dependent and spatially-variantviewing biases in saccadic models, Vision Research, 2016.
13 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saccadic model (2/6)Bottom-up saliency map
p (x|xt−1, . . . , xt−T ) ∝ pBU (x)pB(d, φ)pM (x, t)
ß pBU is the bottom-up saliency map.• Saliency aggregation (Le Meur and Liu, 2014) GBVS
model (Harel et al., 2006) and RARE2012 model (Riche et al.,2013). These models present a good trade-off between qualityand complexity.
• pBU (x) is constant over time. (Tatler et al., 2005) indeeddemonstrated that bottom-up influences do not vanish over time.
14 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saccadic model (3/6)Memory effect and inhibition of return (IoR)
p (x|xt−1, . . . , xt−T ) ∝ pBU (x)pB(d, φ)pM (x, t)
ß pM (x, t) represents the memory effect and IoR of the location xat time t. It is composed of two terms: Inhibition and Recovery.
• The spatial IoR effect declines as a Gaussian function Φσi (d)with the Euclidean distance d from the attendedlocation (Bennett and Pratt, 2001);
• The temporal decline of the IoR effect is simulated by a simplelinear model.
15 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Saccadic model (4/6)Viewing biases
p (x|xt−1, . . . , xt−T ) ∝ pBU (x)pB(d, φ)pM (x, t)
ß pB(d, φ) represents the joint probability distribution of saccadeamplitudes and orientations.d and φ represent the distance and the angle between each pair ofsuccessive fixations, respectively.
16 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Proposed model (5/6)Selecting the next fixation point
p (x|xt−1, . . . , xt−T ) ∝ pBU (x)pB(d, φ)pM (x, t)
ß Stochastic behavior:
We generate Nc = 5 random locations according to the 2Ddiscrete conditional probability p (x|xt−1, · · · , xt−T).
The location with the highest saliency gain is chosen as the nextfixation point x∗
t .
17 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Proposed model (6/6)Scanpaths and saliency maps
ß Scanpaths composed of 10 fixations:
ß Scanpath-based saliency maps:
(a) original image; (b) human saliency map; (c) GBVS saliency map; (d)GBVS-SM saliency maps computed from the simulated scanpaths.
See papers for more details18 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Outline
1 Introduction
2 Saliency models
3 Saccadic models
4 Tuning saccadic modelI A flexible frameworkI Example: the quality task
5 Conclusion
19 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Tuning saccadic model (1/1)
The proposed framework allows us to adapt the saccadic model fordifferent conditions (thanks to the 2D conditional probability pM ):
ß for specific visual scenes: scene-dependent and spatially-variantdistributions.
ß for specific category of people, e.g. young or elder.ß for a given task...
20 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Tuning saccadic model for a quality task (1/3)
Our goal is to reproduce the visual behavior of observers whilethey are performing a quality task.
We re-analyse eye tracking data of (Ninassi et al., 2007):
ß FT: eye movements were recorded while observers freely lookedat unimpaired images;
ß Ref. QT: eye movements were recorded while observers lookedat the unimpaired images during the quality task;
ß Deg. QT: eye movements were recorded while observers lookedat the degraded images during the quality task.
Double Stimulus Impairment Scale was used to perform the subjectivequality evaluation.
21 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Tuning saccadic model for a quality task (2/3)
From left to right: FT, Ref. QT and Deg. QT.
ß The joint distribution of the condition Deg. QT is less focussedthan the two others ⇒ higher visual exploration.
ß Observers performed smaller saccades in the condition Ref. QTcompared to FT and Deg. QT conditions ⇒ Memorization.
22 / 25
Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
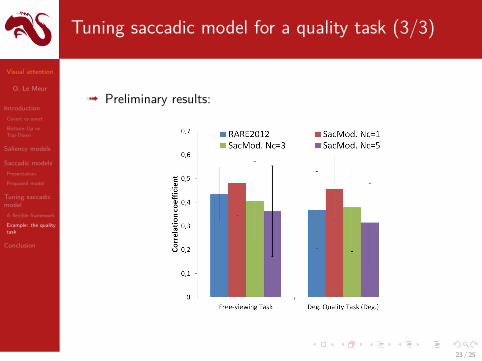
Tuning saccadic model for a quality task (3/3)
ß Preliminary results:
23 / 25

Visual attention
O. Le Meur
IntroductionCovert vs overt
Bottom-Up vsTop-Down
Saliency models
Saccadic modelsPresentation
Proposed model
Tuning saccadicmodelA flexible framework
Example: the qualitytask
Conclusion
Conclusion (1/1)
The key take-home messages:ß A new saccadic model performing well to
• produce plausible scanpaths;• detect the most salient regions of visual scenes.
ß A flexible approach!
Future works:ß Dealing with the limitations of the current implementation.
The presentation is available on my slideShare account:http://fr.slideshare.net/OlivierLeMeur.
24 / 25
Thanks to Adrien.

Visual attention
O. Le Meur
References
ReferencesP. J. Bennett and J. Pratt. The spatial distribution of inhibition of return:. Psychological Science, 12:76–80, 2001.
A. Borji and L. Itti. State-of-the-art in visual attention modeling. IEEE Trans. on Pattern Analysis and Machine Intelligence, 35:185–207, 2013.
J. Harel, C. Koch, and P. Perona. Graph-based visual saliency. In Proceedings of Neural Information Processing Systems (NIPS),2006.
O. Le Meur and Z. Liu. Saliency aggregation: Does unity make strength? In ACCV, 2014.
A. Ninassi, O. Le Meur, P. Le Callet, and D. Barba. Does where you gaze on an image affect your perception of quality? applyingvisual attention to image quality metric. In ICIP, 2007.
M. I. Posner. Orienting of attention. Quarterly Journal of Experimental Psychology, 32:3–25, 1980.
N. Riche, M. Mancas, M. Duvinage, M. Mibulumukini, B. Gosselin, and T. Dutoit. Rare2012: A multi-scale rarity-based saliencydetection with its comparative statistical analysis. Signal Processing: Image Communication, 28(6):642 – 658, 2013. ISSN0923-5965. doi: http://dx.doi.org/10.1016/j.image.2013.03.009.
B.W. Tatler, R. J. Baddeley, and I.D. Gilchrist. Visual correlates of fixation selection: effects of scale and time. Vision Research,45:643–659, 2005.
25 / 25


















