
Hdfs architecture
16
-
Upload
aisha-siddiqa -
Category
Education
-
view
57 -
download
1
Transcript of Hdfs architecture

Hadoop Distributed File System: The Architecture Aisha Siddiqa

Outlines
• Motivation
• Introduction
• Basic Features
• Architecture
• Namenode
• Datanodes
• File System namespace
• Replication
• Replica Placement
• Replica Selection
• Namenode Startup
• Conclusion 2

Motivation
• Recent research trends are towards exploring and developing solutions for big data
• Hadoop is the most popular framework for analyzing big data
• There is a need to have knowledge of distributed file system implemented on Hadoop
3

INTRODUCTION 4

Basic Features
• Highly fault-tolerant
• Suitable for applications with large data sets
• High throughput
• Streaming access to file system data
• Can be built out of commodity hardware
• Platform Independent
• Write-once-read-many: append is supported
• A map-reduce application fits perfectly with this model
5

ARCHITECTURE 6
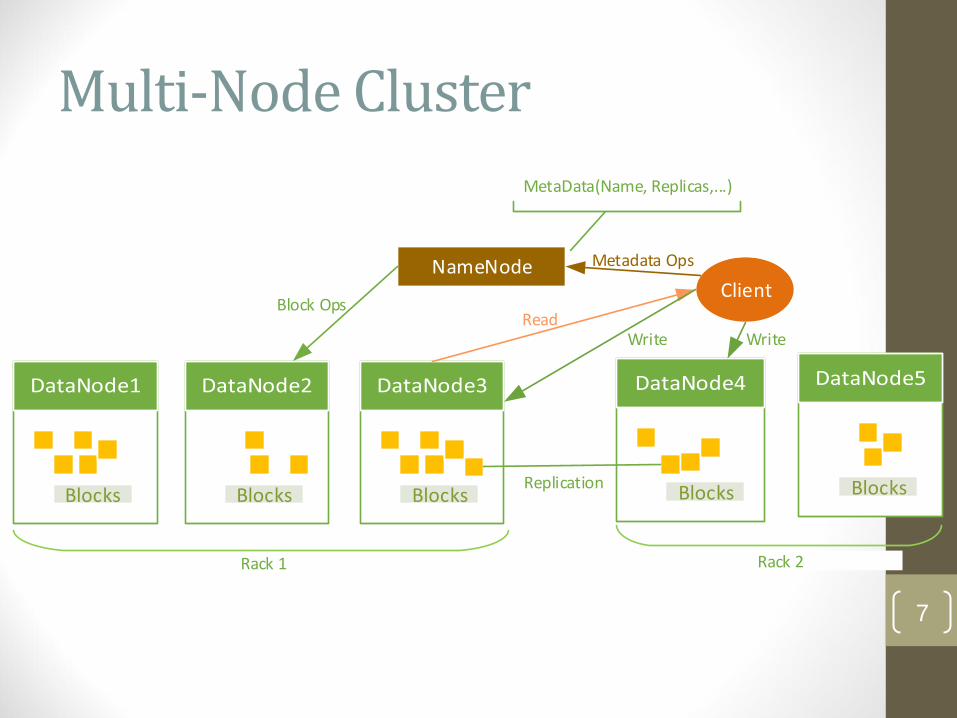
Multi-Node Cluster
7
Block Ops
Metadata Ops
ReadWrite Write
Blocks
NameNode
Blocks Blocks BlocksBlocks
Client
Rack 1 Rack 2
Replication
MetaData(Name, Replicas,...)

Master/slave architecture
Namenode
Single Namenode in a cluster
manages the file system namespace and regulates access to files by clients
Datanodes
A number of DataNodes usually one per node in a cluster
manage storage attached to the nodes that they run on
serve read/write requests, perform block creation, deletion and replication upon instruction from Namenode
multiple DataNodes on the same machine is rare
8

Namenode
Keeps image of entire file system namespace and file Blockmap in memory
4GB of local RAM is sufficient
Periodic checkpointing
• gets the FsImage and Editlog from its local file system at startup
• update FsImage with EditLog information
• stores a copy of the FsImage on filesytstem as a checkpoint
• the system can recover back to the last checkpointed state in case of crash
EditLog
• a transaction log to record every change that occurs to the filesystem metadata
FsImage
• stores file system namespace with mapping of blocks to files and file system properties
9

Datanode
stores data in files in its local file system
no knowledge about HDFS filesystem
stores each block of HDFS data in a separate file
Datanode does not create all files in the same directory
heuristics to determine optimal number of files per directory and create directories appropriately:
Research issue?
When the filesystem starts up it generates a list of all HDFS blocks and send this report to Namenode: Blockreport
10

File system Namespace • Hierarchical file system with directories and files
• Create, remove, move, rename etc.
• Namenode maintains the file system
Metadata
• Any meta information changes to the file system is recorded by the Namenode
• number of replicas of the file can be specified by application
• replication factor of the file is stored in the Namenode
11

Data Replication
each file is a sequence of blocks
same size blocks
for fault tolerance
configurable block size and replicas (per file)
a Heartbeat and a BlockReport is sent to Namenode
Heartbeat notifies activeness of Datanode
BlockReport contains record of all the blocks on a Datanode
12

Replica Selection
• to minimize the bandwidth consumption and latency
• local replica node is most preferred
• replica in the local data center is preferred over the remote one
13

Replica Placement
Optimized replica placement
Rack-aware replica placement:
to improve reliability, availability and network bandwidth utilization
Research topic
Many racks, communication between racks are through switches
Network bandwidth is different
Replicas are typically placed on unique racks
Simple but non-optimal
Writes are expensive
Replication factor is 3
Another research topic?
Replicas are placed: one on a node in a local rack, one on a different node in the local rack and one on a node in a different rack.
1/3 of the replica on a node, 2/3 on a rack and 1/3 distributed evenly across remaining racks.
14

Namenode Startup
Safemode
Replication is not possible
Each DataNode checks in with Heartbeat and BlockReport
Namenode verifies that each block has acceptable number of replicas
Namenode exits Safemode
list of blocks that need to be replicated.
Namenode then proceeds to replicate these blocks to other Datanodes.
15

Conclusion
• A discussion of HDFS Architecture
• Some policies are unique and provide future research directions
• Files and Directories per datanode
• Replica Placement
• Rack-aware replica placement
16


















