
Unification of Temporary Storage in the NodeKernel Architecture · 2019-07-29 · HDFS, S3 HDFS, S3...
54
Patrick Stuedi, Animesh Trivedi, Jonas Pfefferle, Ana Klimovic, Adrian Schuepbach, Bernard Metzler Unification of Temporary Storage in the NodeKernel Architecture
Transcript of Unification of Temporary Storage in the NodeKernel Architecture · 2019-07-29 · HDFS, S3 HDFS, S3...

Patrick Stuedi, Animesh Trivedi, Jonas Pfefferle, Ana Klimovic, Adrian Schuepbach, Bernard Metzler
Unification of Temporary Storage in the NodeKernel Architecture
2
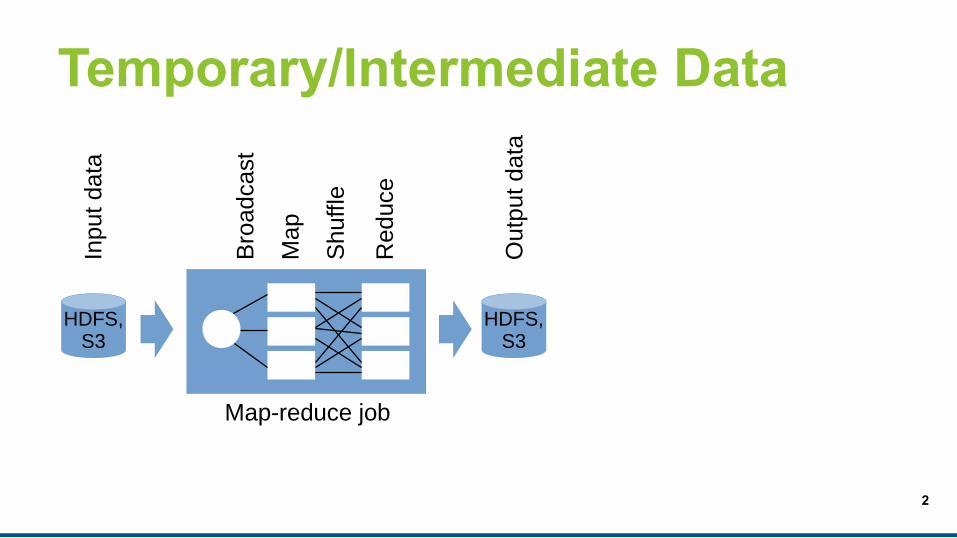
Temporary/Intermediate Data
Bro
adca
st
Shu
ffle
Map
Red
uce
Inpu
t da
ta
Out
put d
ata
Map-reduce job
HDFS,S3
HDFS,S3
3
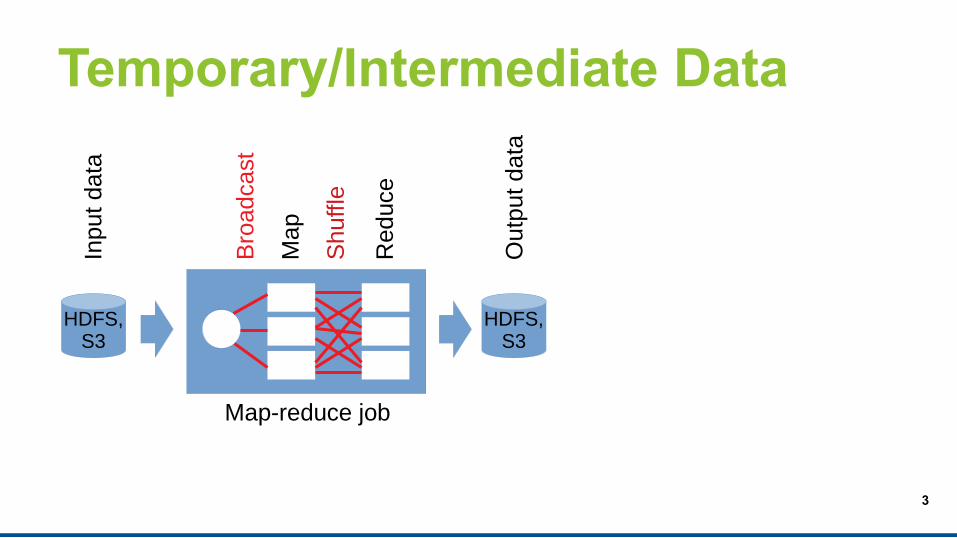
Temporary/Intermediate Data
Bro
adca
st
Shu
ffle
Map
Red
uce
Inpu
t da
ta
Out
put d
ata
Map-reduce job
HDFS,S3
HDFS,S3

4
Temporary/Intermediate Data
Bro
adca
st
Shu
ffle
Map
Red
uce
Inpu
t da
ta
Inte
rmed
iate
da
ta
HDFS,S3
HDFS,S3
HDFS,S3
Map-reduce job ML training
Out
put
data
5
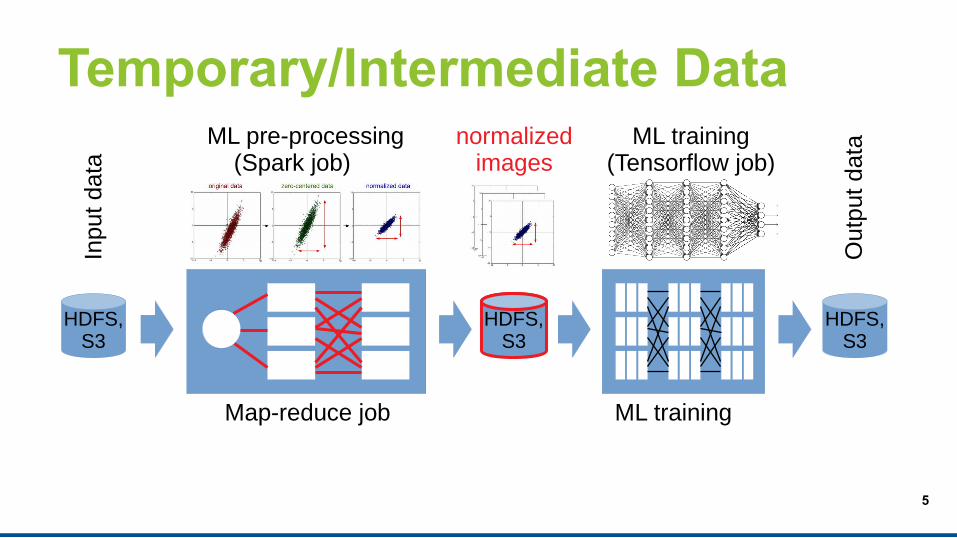
Temporary/Intermediate DataIn
put
data
HDFS,S3
HDFS,S3
HDFS,S3
ML pre-processing (Spark job)
ML training(Tensorflow job)
normalizedimages
Map-reduce job
Out
put
data
ML training
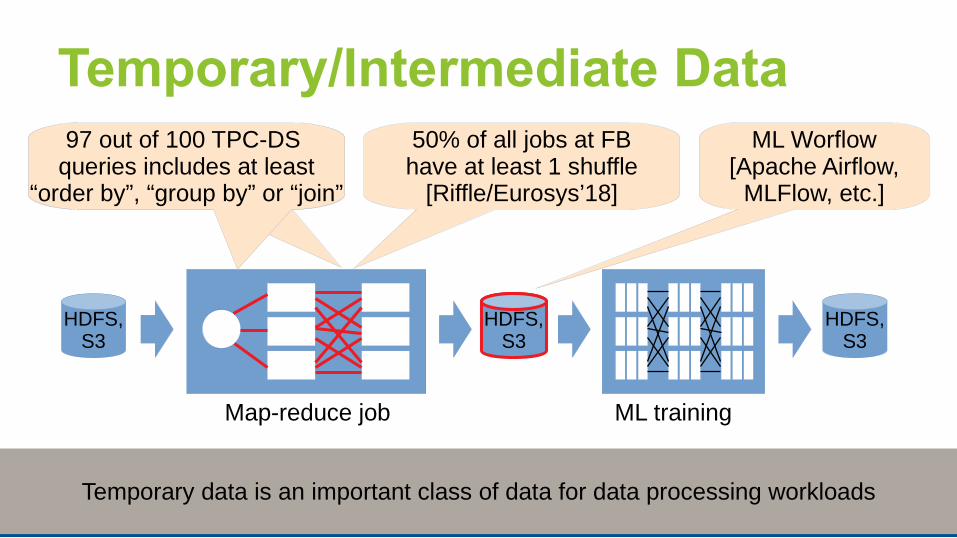
6Temporary data is an important class of data for data processing workloads
Temporary/Intermediate Data
HDFS,S3
HDFS,S3
HDFS,S3
Map-reduce job ML training
97 out of 100 TPC-DS queries includes at least
“order by”, “group by” or “join”
50% of all jobs at FBhave at least 1 shuffle
[Riffle/Eurosys’18]
ML Worflow[Apache Airflow,
MLFlow, etc.]

7
put your #assignedhashtag here by setting the footer in view-header/footer● Inefficient:
– Difficult to leverage modern networking and storage hardware (e.g., 100 Gb/s Ethernet, NVMe Flash, etc.)
Inflexible: emporary data management hard-wired with data processing framework
Difficult to change deployment (e.g., disaggregation, tiered storage, etc.)
Shortcomings of Temporary Data Storage

8
put your #assignedhashtag here by setting the footer in view-header/footer● Inefficient:
– Difficult to leverage modern networking and storage hardware (e.g., 100 Gb/s Ethernet, NVMe Flash, etc.)
Inflexible: emporary data management hard-wired with data processing framework
Difficult to change deployment (e.g., disaggregation, tiered storage, etc.)
Shortcomings of Temporary Data Storage
Trivedi/HotCloud’16Ousterhout/NSDI’16

9
put your #assignedhashtag here by setting the footer in view-header/footer● Inefficient:
– Difficult to leverage modern networking and storage hardware (e.g., 100 Gb/s Ethernet, NVMe Flash, etc.)
● Inflexible: – Temporary data management hard-wired with data processing
framework
– Difficult to change deployment (e.g., disaggregation, tiered storage, etc.)
Shortcomings of Temporary Data Storage
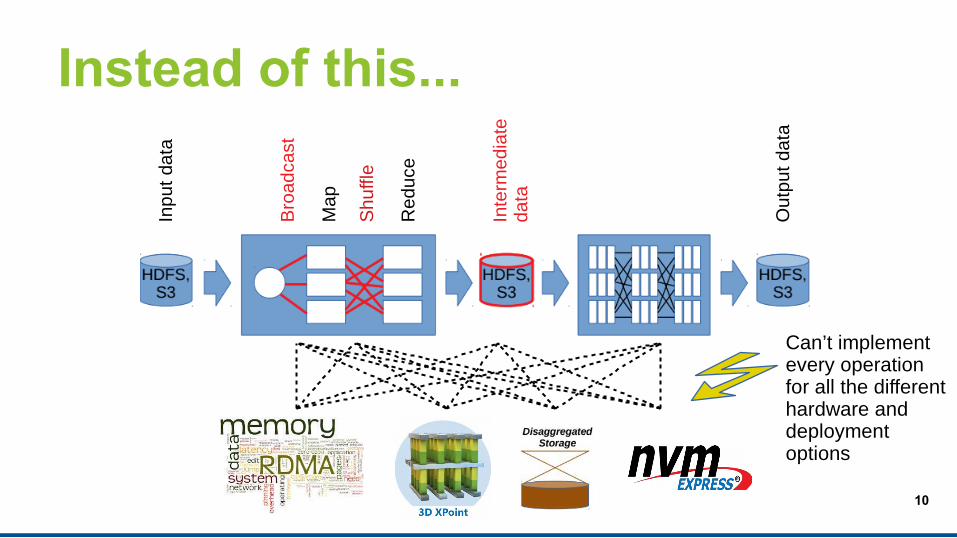
10
Bro
adca
st
Shu
ffle
Map
Red
uce
Inpu
t da
ta
Inte
rmed
iate
da
ta
Out
put
data
Instead of this...
Can’t implementevery operationfor all the differenthardware and deployment options

11
Bro
adca
st
Shu
ffle
Map
Red
uce
Inpu
t da
ta
Inte
rmed
iate
da
ta
Out
put
data
...better do this
Implement hardwaresupport once and support different operations and frameworks

12
How should the temporary data store look?
Can we use an existing storage platform, e.g., KV store, FS, etc.?
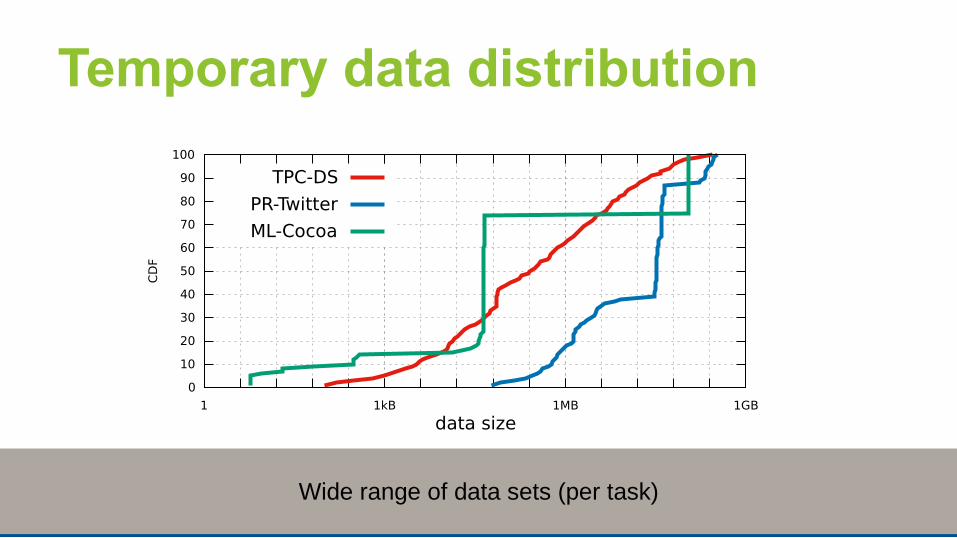
13
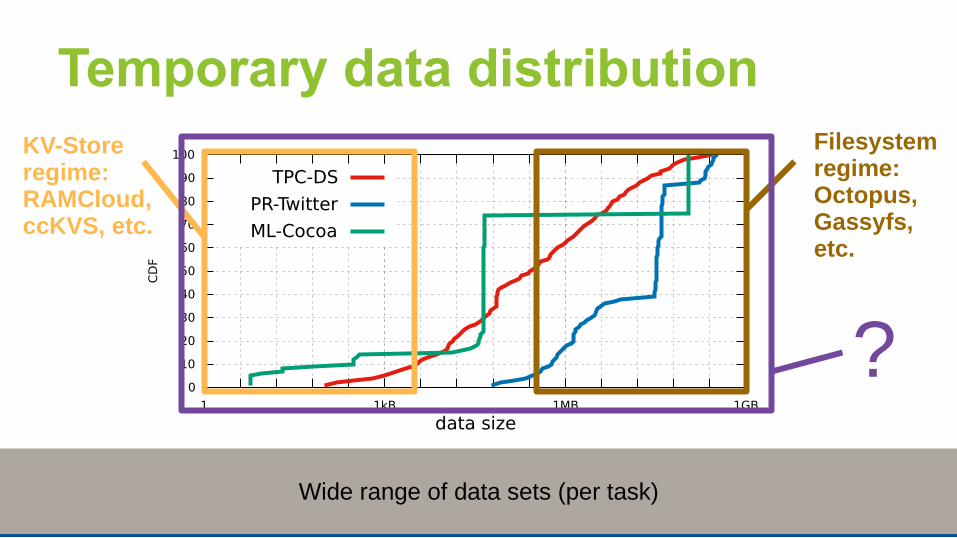
Temporary data distribution
0
10
20
30
40
50
60
70
80
90
100
1 1kB 1MB 1GB
CD
F
data size
TPC-DS
PR-Twitter
ML-Cocoa
Wide range of data sets (per task)
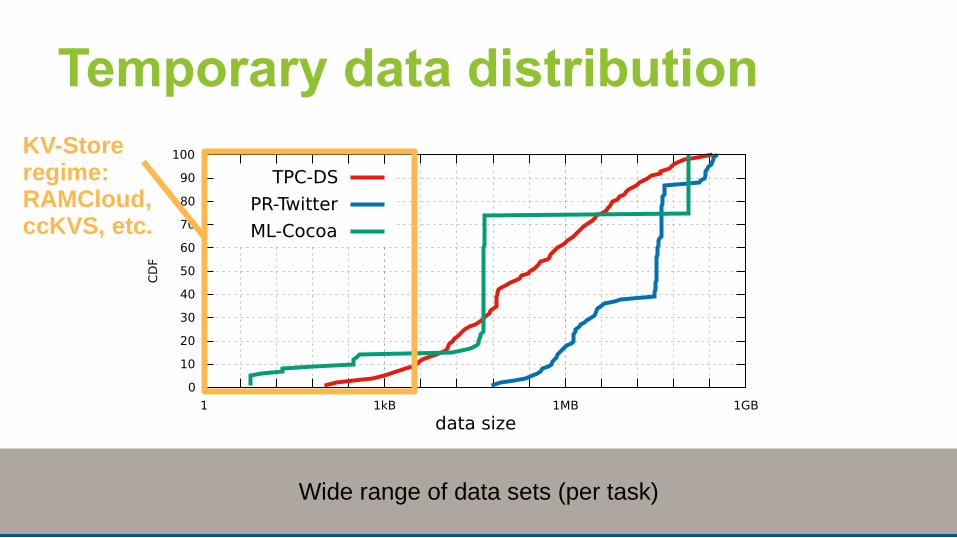
14
Temporary data distribution
0
10
20
30
40
50
60
70
80
90
100
1 1kB 1MB 1GB
CD
F
data size
TPC-DS
PR-Twitter
ML-Cocoa
Wide range of data sets (per task)
KV-Store regime:RAMCloud, ccKVS, etc.
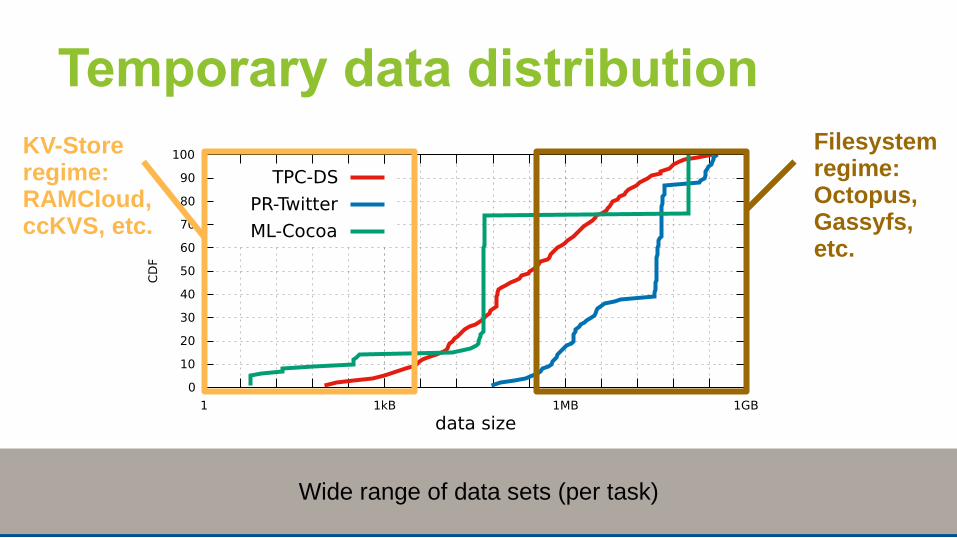
15
Temporary data distribution
0
10
20
30
40
50
60
70
80
90
100
1 1kB 1MB 1GB
CD
F
data size
TPC-DS
PR-Twitter
ML-Cocoa
Wide range of data sets (per task)
KV-Store regime:RAMCloud, ccKVS, etc.
Filesystem regime:Octopus, Gassyfs, etc.
16
Temporary data distribution
0
10
20
30
40
50
60
70
80
90
100
1 1kB 1MB 1GB
CD
F
data size
TPC-DS
PR-Twitter
ML-Cocoa
Wide range of data sets (per task)
KV-Store regime:RAMCloud, ccKVS, etc.
Filesystem regime:Octopus, Gassyfs, etc.
?

17
put your #assignedhashtag here by setting the footer in view-header/footer● Perform well for wide range of data sizes– A few KB to many GBs per storage object
● Support large data volumes– Can’t keep all data in memory all the time
● Provide convenient abstractions for storing temporary– Key-value, File, what else?
● Scalability
● Fault-tolerance, Durability– Temporary data is short-lived, can we use coarse grained recovery?
Temporary Data Storage Requirements

18
put your #assignedhashtag here by setting the footer in view-header/footer● Perform well for wide range of data sizes– A few KB to many GBs per storage object
● Support large data volumes– Can’t keep all data in memory all the time
● Provide convenient abstractions for storing temporary– Key-value, File, what else?
● Scalability
● Fault-tolerance, Durability– Temporary data is short-lived, can we use coarse grained recovery?
Temporary Data Storage Requirements

19
put your #assignedhashtag here by setting the footer in view-header/footer● Perform well for wide range of data sizes– A few KB to many GBs per storage object
● Support large data volumes– Can’t keep all data in memory all the time
● Provide convenient abstractions for storing temporary– Key-value, File, what else?
● Scalability
● Fault-tolerance, Durability– Temporary data is short-lived, can we use coarse grained recovery?
Temporary Data Storage Requirements

20
put your #assignedhashtag here by setting the footer in view-header/footer● Perform well for wide range of data sizes– A few KB to many GBs per storage object
● Support large data volumes– Can’t keep all data in memory all the time
● Provide convenient abstractions for storing temporary– Key-value, File, what else?
● Scalability
● Fault-tolerance, Durability– Temporary data is short-lived, can we use coarse grained recovery?
Temporary Data Storage Requirements

21
put your #assignedhashtag here by setting the footer in view-header/footer● Perform well for wide range of data sizes– A few KB to many GBs per storage object
● Support large data volumes– Can’t keep all data in memory all the time
● Provide convenient abstractions for storing temporary– Key-value, File, what else?
● Scalability
● Fault-tolerance, Durability– Temporary data is short-lived, can we use coarse grained recovery?
Temporary Data Storage Requirements

22
put your #assignedhashtag here by setting the footer in view-header/footer
● Distributed storage architecture for temporary data
● Fusion of filesystem and key-value semantics
● Designed for high-performance hardware
NodeKernel
23
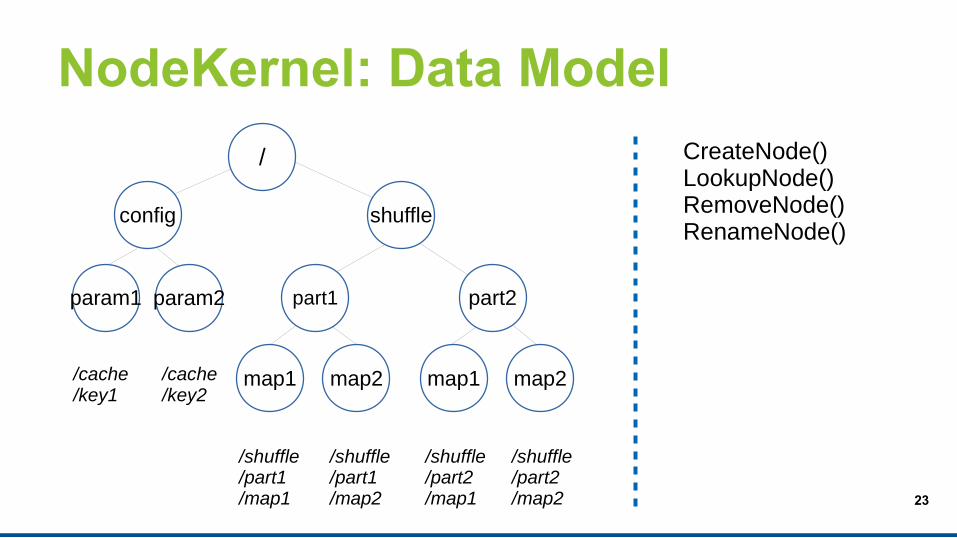
NodeKernel: Data Model
/shuffle/part1/map1
/shuffle/part1/map2
/shuffle/part2/map1
/shuffle/part2/map2
/cache/key1
/cache/key2
config shuffle
part1 part2
map1 map2 map1 map2
param1 param2
/ CreateNode()LookupNode()RemoveNode()RenameNode()
24
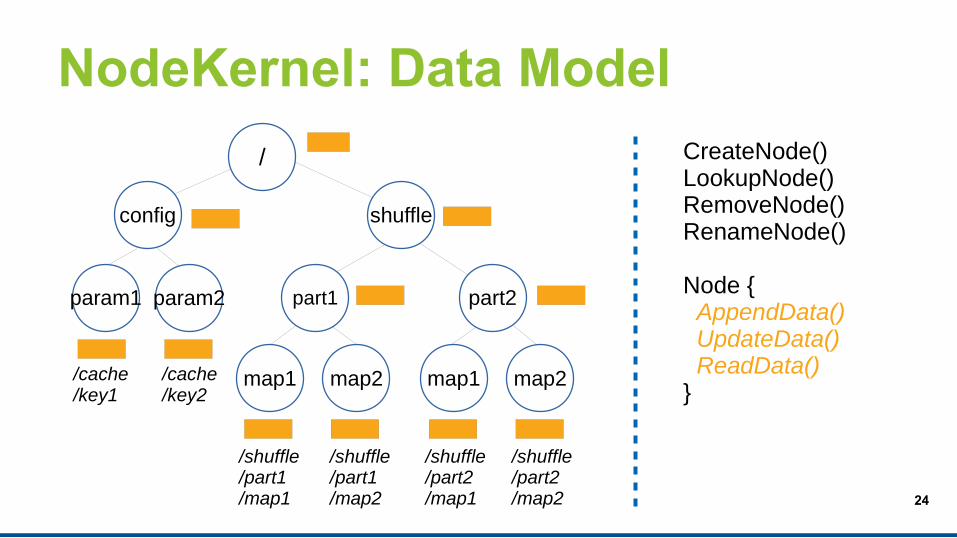
NodeKernel: Data Model
/shuffle/part1/map1
/shuffle/part1/map2
/shuffle/part2/map1
/shuffle/part2/map2
/cache/key1
/cache/key2
config shuffle
part1 part2
map1 map2 map1 map2
param1 param2
/ CreateNode()LookupNode()RemoveNode()RenameNode()
Node { AppendData() UpdateData() ReadData()}

25
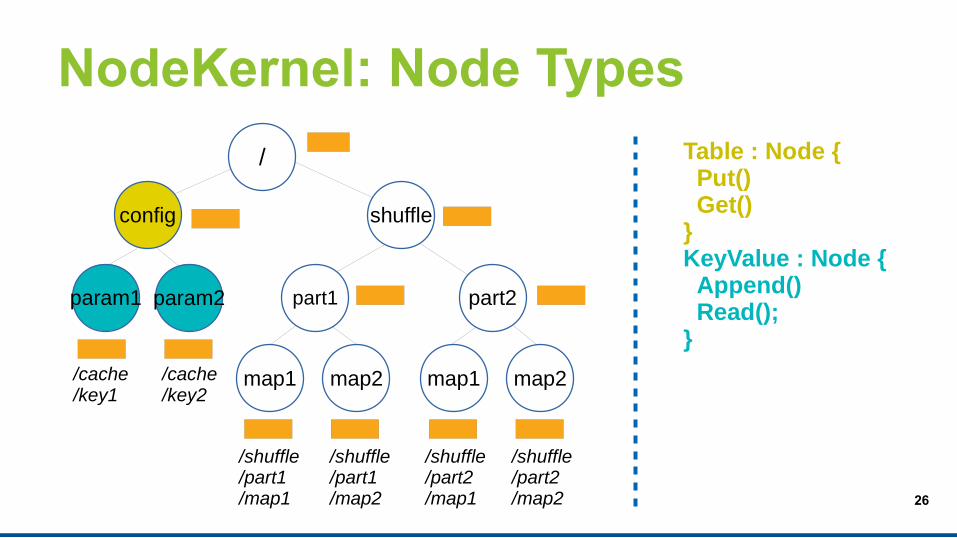
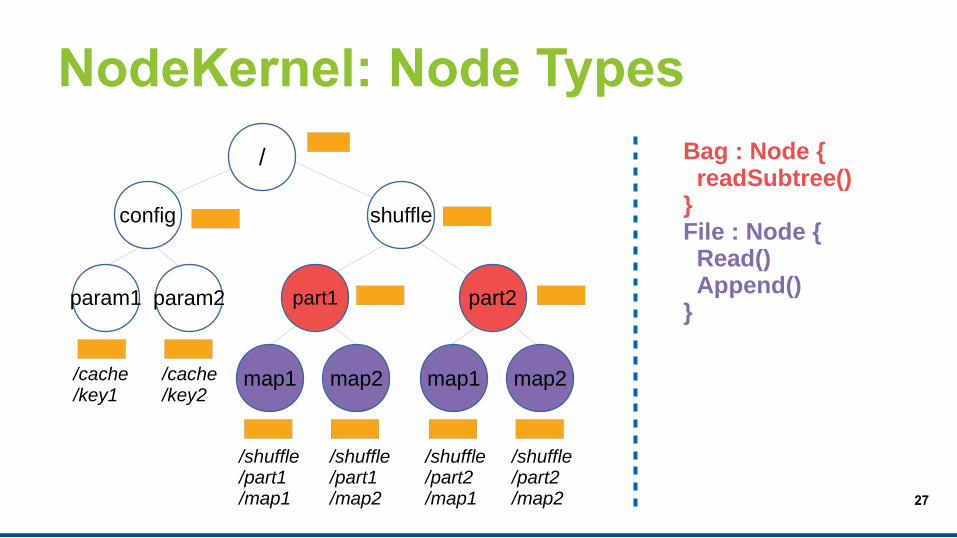
NodeKernel: Node Types
/shuffle/part1/map1
/shuffle/part1/map2
/shuffle/part2/map1
/shuffle/part2/map2
/cache/key1
/cache/key2
config shuffle
part1 part2
map1 map2 map1 map2
param1 param2
/ Directory : Node { Enumerate()}File : Node { Read() Append()}
26
NodeKernel: Node Types
/shuffle/part1/map1
/shuffle/part1/map2
/shuffle/part2/map1
/shuffle/part2/map2
/cache/key1
/cache/key2
config shuffle
part1 part2
map1 map2 map1 map2
param1 param2
/ Table : Node { Put() Get()}KeyValue : Node { Append() Read();}
27
NodeKernel: Node Types
/shuffle/part1/map1
/shuffle/part1/map2
/shuffle/part2/map1
/shuffle/part2/map2
/cache/key1
/cache/key2
config shuffle
part1 part2
map1 map2 map1 map2
param1 param2
/ Bag : Node { readSubtree()}File : Node { Read() Append()}
28
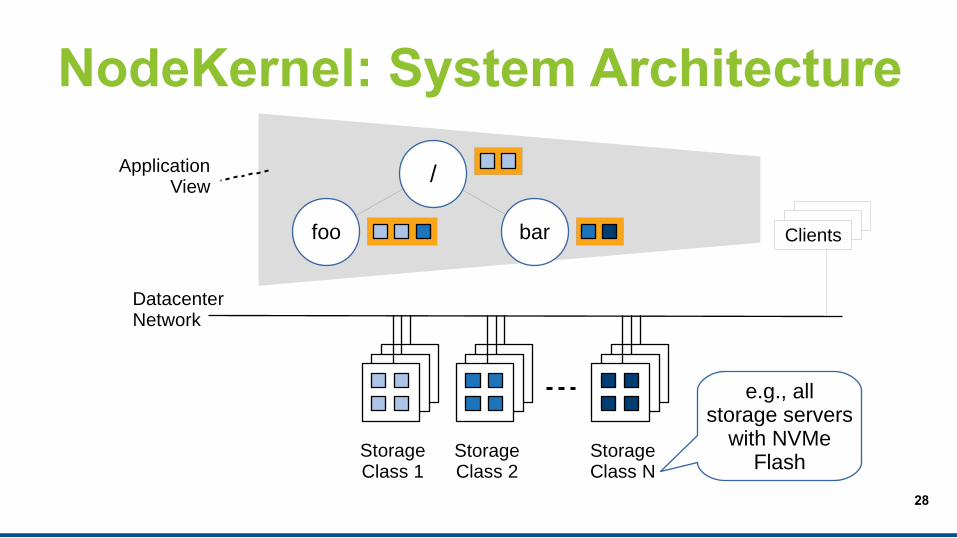
NodeKernel: System Architecture
StorageClass 1
StorageClass 2
StorageClass N
e.g., allstorage servers
with NVMeFlash
/
foo bar Clients
Datacenter Network
ApplicationView

29
NodeKernel: System Architecture
MetadataPlane
StorageClass 1
StorageClass 2
StorageClass N
e.g., allstorage servers
with NVMeFlash
tree structure,
tiering policy,block mapping
/
foo bar Clients
Datacenter Network
ApplicationView

30
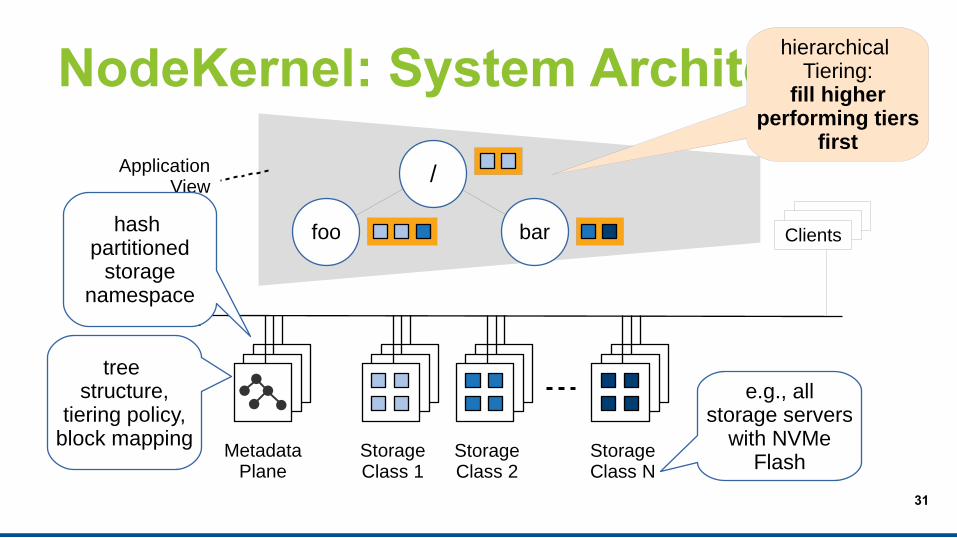
NodeKernel: System Architecture
MetadataPlane
StorageClass 1
StorageClass 2
StorageClass N
e.g., allstorage servers
with NVMeFlash
tree structure,
tiering policy,block mapping
/
foo bar Clients
Datacenter Network
ApplicationView
hierarchical Tiering:
fill higherperforming tiers
first
31
NodeKernel: System Architecture
MetadataPlane
StorageClass 1
StorageClass 2
StorageClass N
e.g., allstorage servers
with NVMeFlash
tree structure,
tiering policy,block mapping
/
foo bar Clients
Datacenter Network
ApplicationView
hierarchical Tiering:
fill higherperforming tiers
first
hash partitioned
storagenamespace
32
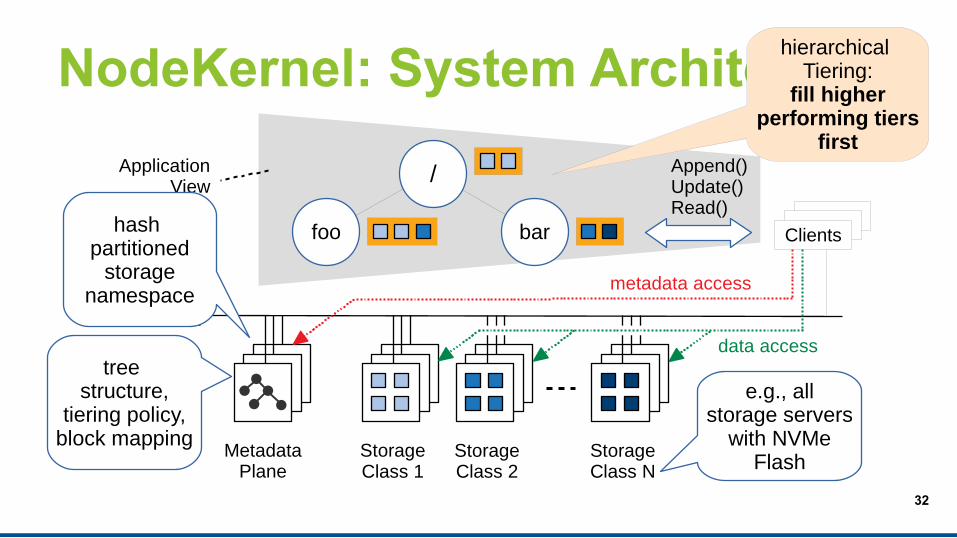
NodeKernel: System Architecture
Datacenter Network
MetadataPlane
StorageClass 1
StorageClass 2
StorageClass N
e.g., allstorage servers
with NVMeFlash
tree structure,
tiering policy,block mapping
/
foo bar Clients
metadata access
data access
Append()Update()Read()
ApplicationView
hierarchical Tiering:
fill higherperforming tiers
first
hash partitioned
storagenamespace

33
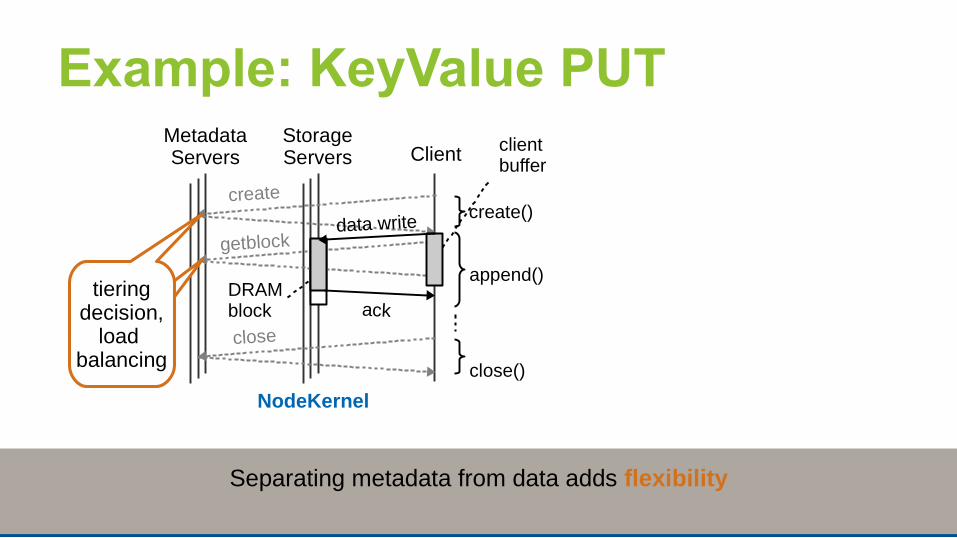
Example: KeyValue PUT
data write
MetadataServers Client
StorageServers
create
DRAM block
create()
close()
clientbuffer
append()
getblock
close
ack
NodeKernel
ClientKV
Server
Traditional KVS
PUT
ack
34
Example: KeyValue PUT
data write
MetadataServers Client
StorageServers
create
DRAM block
create()
close()
clientbuffer
append()
getblock
close
ack
NodeKernel
ClientKV
Server
Traditional KVS
PUT
acktiering
decision,load
balancing
Separating metadata from data adds flexibilitybut requires low-latency metadata operations

35
Example: KeyValue PUT
data write
MetadataServers Client
StorageServers
create
DRAM block
create()
close()
clientbuffer
append()
getblock
close
ack
NodeKernel
ClientKV
Server
Traditional KVS
PUT
acktiering
decision,load
balancing
Separating metadata from data adds flexibilitybut requires low- but requires low-latency metadata operationslatency metadata operations

36
put your #assignedhashtag here by setting the footer in view-header/footer● Implementation of the NodeKernel architecture
● Low-latency RDMA-based RPC between client and metadata servers
● Two storage classes:– Flash accessed via NVM-over-Fabrics
– DRAM accessed via RDMA
● Open source: crail.apache.org
Apache Crail

37
Pu, ur #assignedhashtag here by setting the footer in view-header/footer● 16 node cluster, machine hardware:– 100 Gb/s RDMA RoCE
– 256 GB DRAM
– Intel Optane NVMe SSD
● Evaluation questions:– Any size: how well is Crail performing for different object sizes?
– Modern hardware: are we able to accelerate workloads?
– Flexibility: what benefits we get by decoupling data processing and temporary data storage?
– Abstractions: Are KeyValue, File and Bag abstractions helpful?
Evaluation

38
Small and Large Data Sets
Crail serves small and large data sets close to the hardware limit(latency RDMA: 3us, latency Optane 15us, bandwidth RDMA: 100 Gb/s)
KeyValue GET (256B) File read (10GB)
39
Spark Shuffle using Crail::Baglocalfiles
reduce tasks
maptasks
networktransfers
computecluster
40
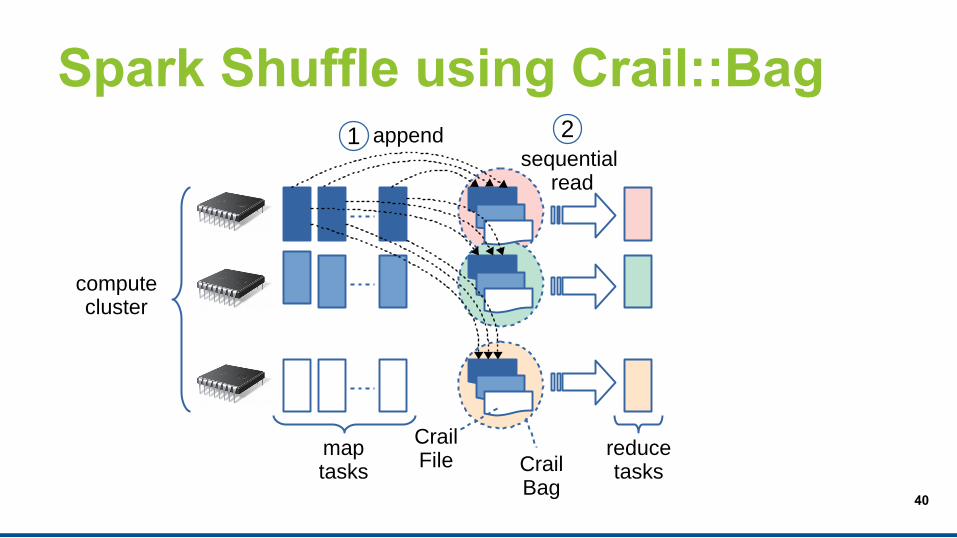
Spark Shuffle using Crail::Bag
CrailFile Crail
Bag
append 2sequential
read
1
reduce tasks
maptasks
computecluster
41
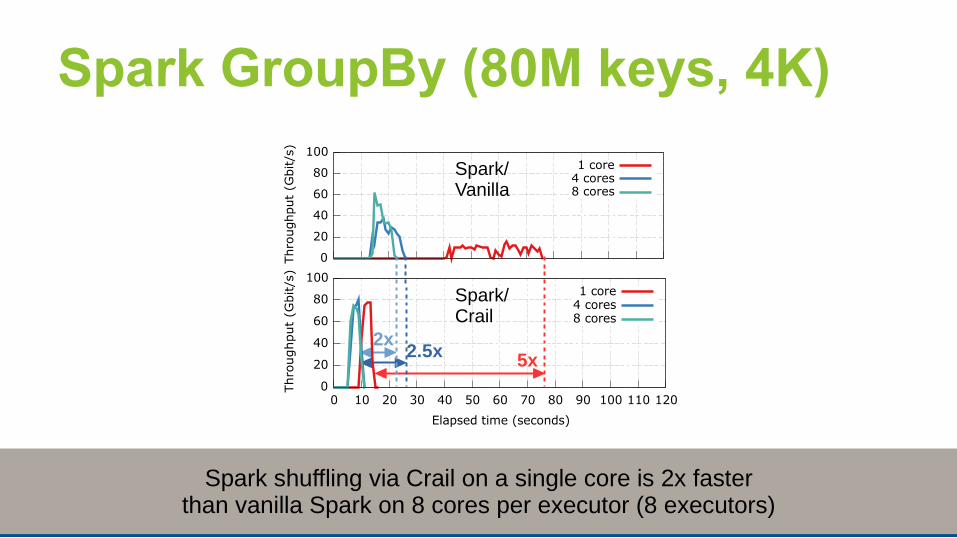
Spark GroupBy (80M keys, 4K)
Spark/Vanilla
5x2.5x2x
0
20
40
60
80
100
0 10 20 30 40 50 60 70 80 90 100 110 120Thro
ughput
(Gbit/s
)Elapsed time (seconds)
1 core4 cores8 cores
0
20
40
60
80
100
0 10 20 30 40 50 60 70 80 90 100 110 120
Thro
ughput
(Gbit/s
)
Elapsed time (seconds)
1 core4 cores8 cores
Spark/Crail
Spark shuffling via Crail on a single core is 2x fasterthan vanilla Spark on 8 cores per executor (8 executors)

42
Flexible Deployment
Crail
HDFS,S3
HDFS,S3
Data processing job
configuration
Disaggregation,Flash/DRAM ratio,
RDMA, TCP,NVM-of-Fabrics,
etc.
43
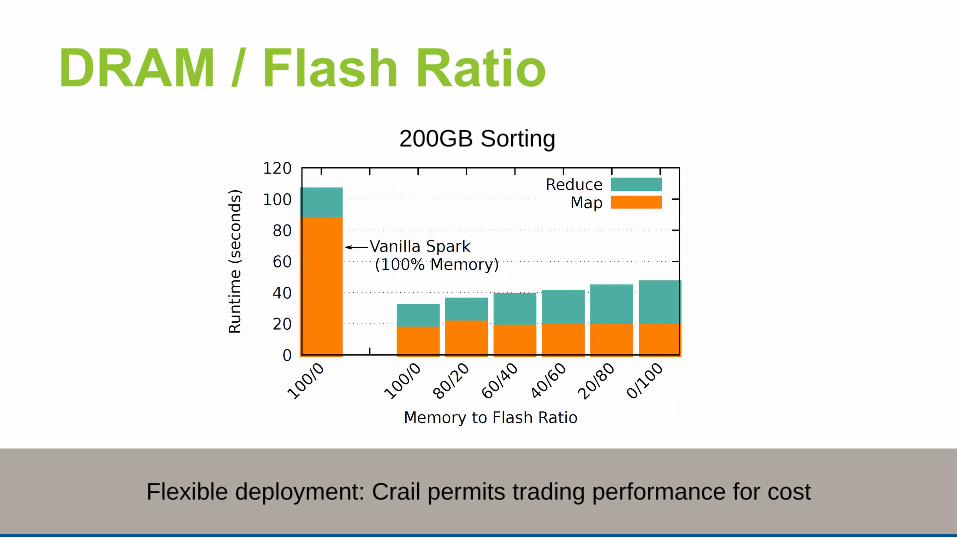
DRAM / Flash Ratio
Flexible deployment: Crail permits trading performance for cost
200GB Sorting

44
put your #assignedhashtag here by setting the footer in view-header/footer● Sharing temporary efficiently in data processing workloads is challenging– Inefficient in deployments with modern hardware
– Inflexible: difficult to use storage tiering, disaggregation, etc.
● NodeKernel: distributed storage architecture for temporary data storage– Fusion of Filesystem and Key-Value semantics in single storage namespace
● Apache Crail: Implementation of NodeKernel for RDMA and NVMf– Accelerates temporary data storage on modern hardware
– Enable flexible deployment: storage tiering, disaggregation, etc.
Conclusions

45
put your #assignedhashtag here by setting the footer in view-header/footer● Crail:
https://github.com/apache/incubator-crail
● Crail shuffler:
https://github.com/zrlio/crail-spark-io
● YCSB benchmark:
https://github.com/brianfrankcooper/YCSB
(includes Crail)
Open Source

46
Backup

47
YCSB Benchmark: GET Latency
1KB KV pairs: ~12us (DRAM) and 30us (NVMe) 100KB KV pairs: ~30us (DRAM) and 40us (NVMe)

48
Persistence & Fault Tolerance
● Data plane – No replication
– Graceful handling of faulty or crashed storage servers
(signaled at client during read/write ops)
● Meta data plane– Persist metadata state using operation logging
– Shutdown and replay log to re-create state
● Pluggable log device– Current log is on local FS
– Could be a distributed log: maintain a hot standby metadata server
clients
Metadataserver
Metadataserver
RPC
log operation
replaylog log interface
log mplementation
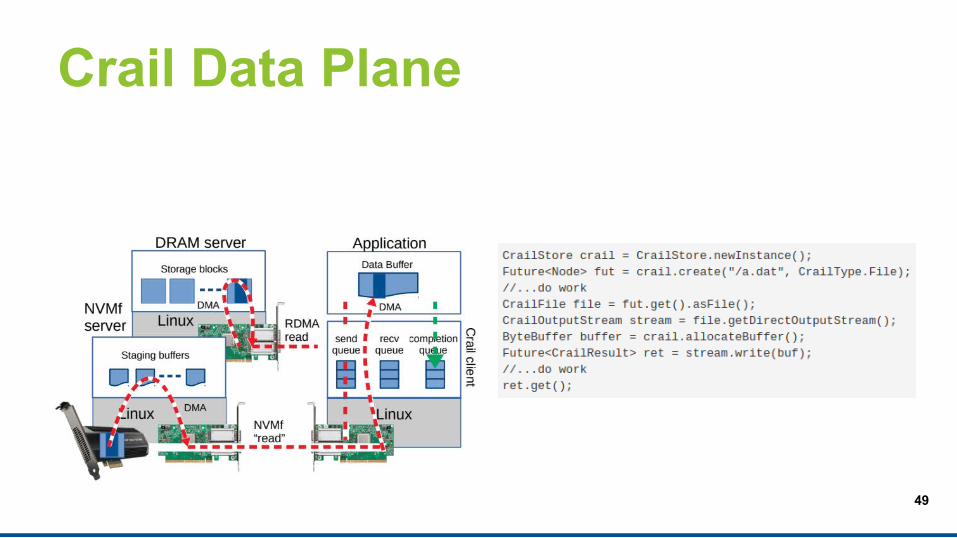
49
Crail Data Plane

50
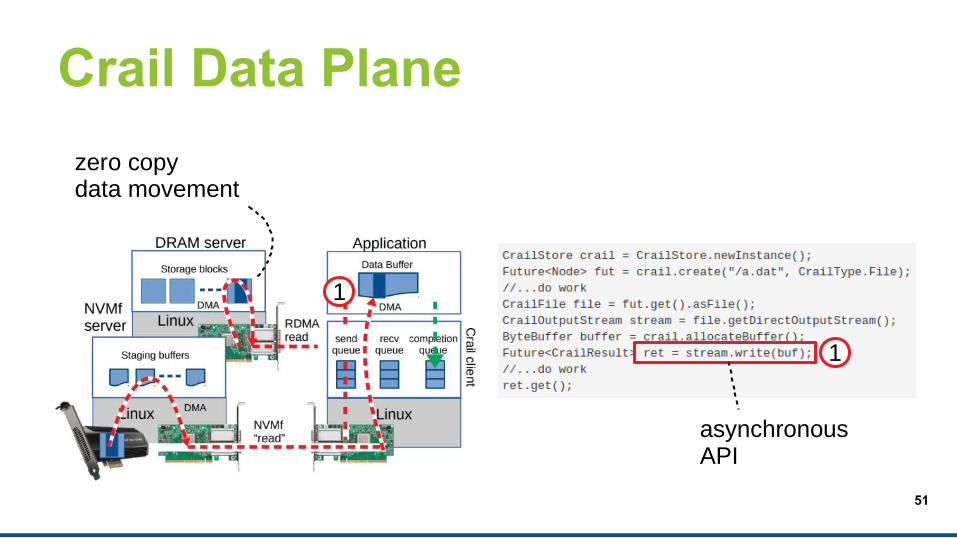
Crail Data Plane
1
1
asynchronousAPI
51
Crail Data Plane
1
1
zero copydata movement
asynchronousAPI
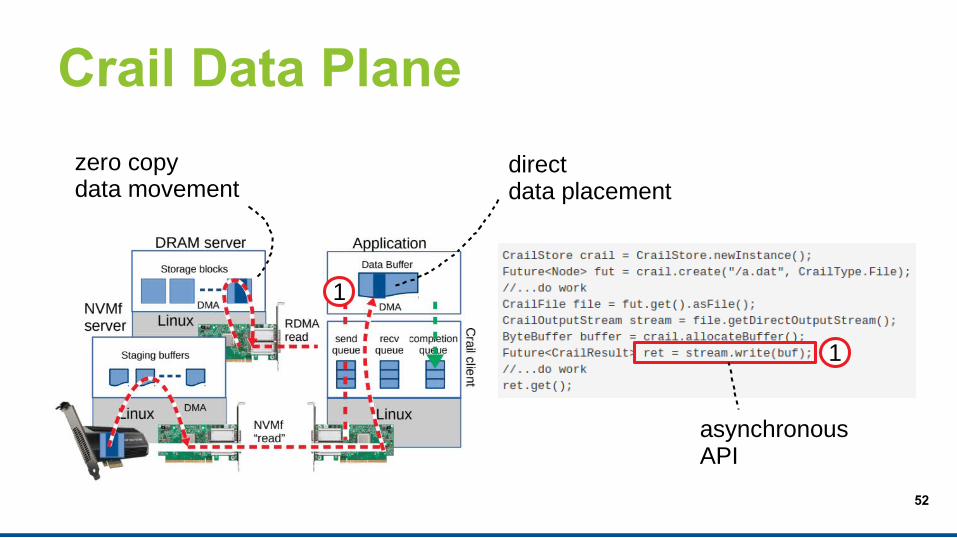
52
Crail Data Plane
1
1
zero copydata movement
asynchronousAPI
direct data placement

53
Crail Data Plane
1
1
transfer only data requestedzero copy
data movement
asynchronousAPI
direct data placement

54
Crail Data Plane
1 2
12
transfer only data requestedzero copy
data movement
asynchronousAPI
direct data placement
synchronouscall


















