

![[PAPER] WSDM a User Centered Design Method for Web](https://static.fdocuments.in/doc/165x107/563dba42550346aa9aa40ff2/paper-wsdm-a-user-centered-design-method-for-web.jpg)
Graph Embedding and Reasoning - SIGKDD · Graph Embedding and Reasoning ... unifying deepwalk,...
97
1 Graph Embedding and Reasoning Jie Tang Department of Computer Science and Technology Tsinghua University The slides can be downloaded at http://keg.cs.tsinghua.edu.cn/jietang
Transcript of Graph Embedding and Reasoning - SIGKDD · Graph Embedding and Reasoning ... unifying deepwalk,...

1
Graph Embedding and Reasoning
Jie Tang
Department of Computer Science and Technology
Tsinghua University
The slides can be downloaded at http://keg.cs.tsinghua.edu.cn/jietang
2
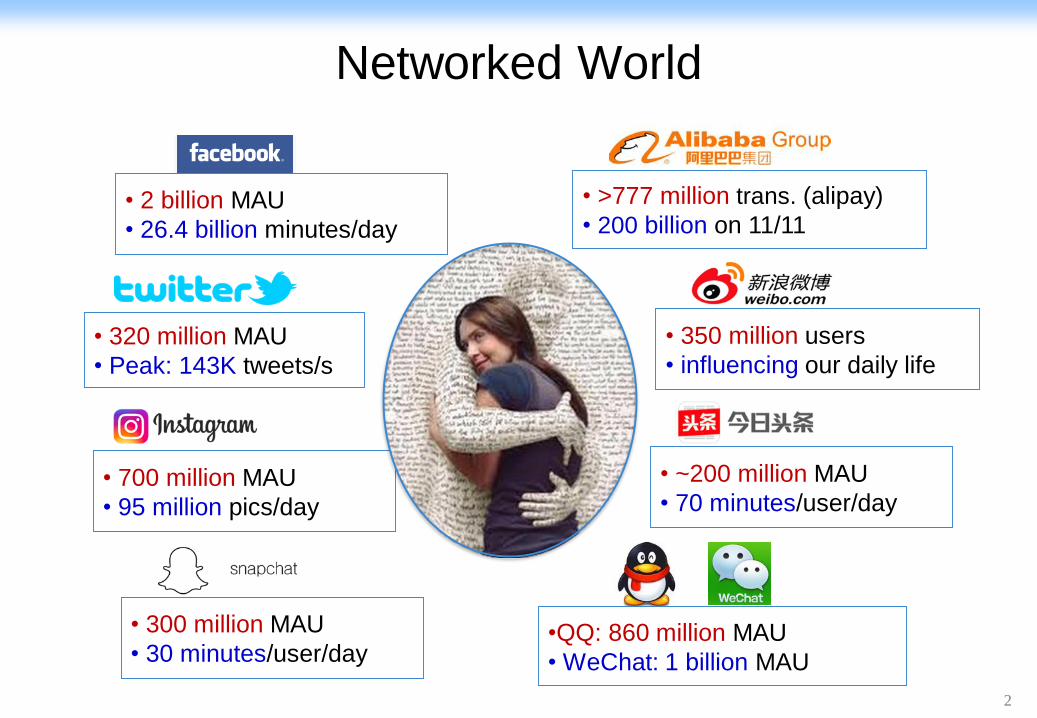
Networked World
• 2 billion MAU
• 26.4 billion minutes/day
• 350 million users
• influencing our daily life• 320 million MAU
• Peak: 143K tweets/s
•QQ: 860 million MAU
• WeChat: 1 billion MAU
• 700 million MAU
• 95 million pics/day
• >777 million trans. (alipay)
• 200 billion on 11/11
• 300 million MAU
• 30 minutes/user/day
• ~200 million MAU
• 70 minutes/user/day

3
Mining Big Graphs/Networks
• An information/social graph is made up of a set of
individuals/entities (“nodes”) tied by one or more
interdependency (“edges”), such as friendship.
1. David Lazer, Alex Pentland, Lada Adamic, Sinan Aral, Alber-Laszlo Barabasi, et al. Computational Social Science. Science 2009.
Mining big networks: “A field is emerging that leverages the capacity to
collect and analyze data at a scale that may reveal patterns of individual
and group behaviors.” [1]

4
Info.
Space
Social
Space
Info. Space + Social Space
Challenges
big
hetero
geneous
dynamic
Interaction
Interaction
1. J. Scott. (1991, 2000, 2012). Social network analysis: A handbook.
2. D. Easley and J. Kleinberg. Networks, crowds, and markets: Reasoning about a highly connected world. Cambridge University Press, 2010.
Challenges

5
1930s o Sociogram [Moreno]
o Homophily [Lazarsfeld & Merton]
o Balance Theory [Heider et al.]o Random Graph [Erdos, Renyi, Gilbert]
o Degree Sequence [Tuttle, Havel, Hakami]
1950s
1960s
1970s
o Small Worlds [Migram]
o The Strength Of Weak Tie [Granovetter]
1992 o Structural Hole [Burt]
o Dunbar’s Number [Dunbar]
o Small Worlds [Watts & Strogatz]
o Scale Free [Barabasi & Albert]
o Power Law [Faloutsos 3]o HITS [Kleinberg]
o PageRank [Page & Brin]
o Hyperlink Vector Voting [Li]
1997
1998/9
2000~2004o Influence Max’n [Domingos & Kempe et al.]
o Community Detection [Girvan & Newman]
o Network Motifs [Milo et al.]
o Link Prediction [Liben-Nowell & Kleinberg]
o Graph Evolution [Leskovec et al.]
o 3 Deg. Of Influence [Christakis & Fowler]
o Social Influence Analysis [Tang et al.]
o Six Deg. Of Separation [Leskovec & Horvitz]
o Network Heterogeneity [Sun & Han]
o Network Embedding [Tang & Liu]
o Computer Social Science [Lazer et al.]
o Info. vs. Social Networks (Twitter) [Kwak et al.]
o Signed Networks [Leskovec et al.]
o Semantic Social Networks [Tang et al.]
o Four Deg. Of Separation [Backstrom et al.]
o Structural Diversity [Ugander et al.]
o Computational Social Science [Watts]
o Network Embedding [Perozzi et al.]2005~2009
2010~2014
2015~2019
o Graph Neural Networks
o Deep Learning for Networks
o High-Order Networks [Benson et al.]
Social & Information Network Analysis
The Late 20th Century:
CS & Physics
The 20th Century:
Sociology &
Anthropology
The 1st decade of the 21st
Century:
More Computer & Data
Scientists
Recent Trend:
Deep Learning for
Networks

6
Recent Trend
0.8 0.2 0.3 … 0.0 0.0
d-dimensional vector, d<<|V|
Users with the same label are located in
the d-dimensional space closer than those
with different labels
label1
label2
e.g., node classification
Representation Learning/
Graph Embedding

7
Example1: Open Academic Graph—how can we benefit from graph embedding?
• 189M publications• 113M researchers• 8M concepts• 8M IP accesses
data intelligenceknowledge
240M Authors
25K Institutions
220M Publications
664K Fields of Studies
Event
50K Venues
Open Academic
Graph@
Open Academic
Society
Tsinghua University AMiner Microsoft Academic Graph
Linking large-scale heterogeneous academic graphs
https://www.openacademic.ai/oag/
Open Academic Graph (OAG) is a large knowledge graph by linking two
billion-scale academic graphs: Microsoft Academic Graph (MAG) and AMiner.
1. F. Zhang, X. Liu, J. Tang, Y. Dong, P. Yao, J. Zhang, X. Gu, Y. Wang, B. Shao, R. Li and K. Wang. OAG: Toward Linking Large-scale Heterogeneous
Entity Graphs. KDD'19.

8
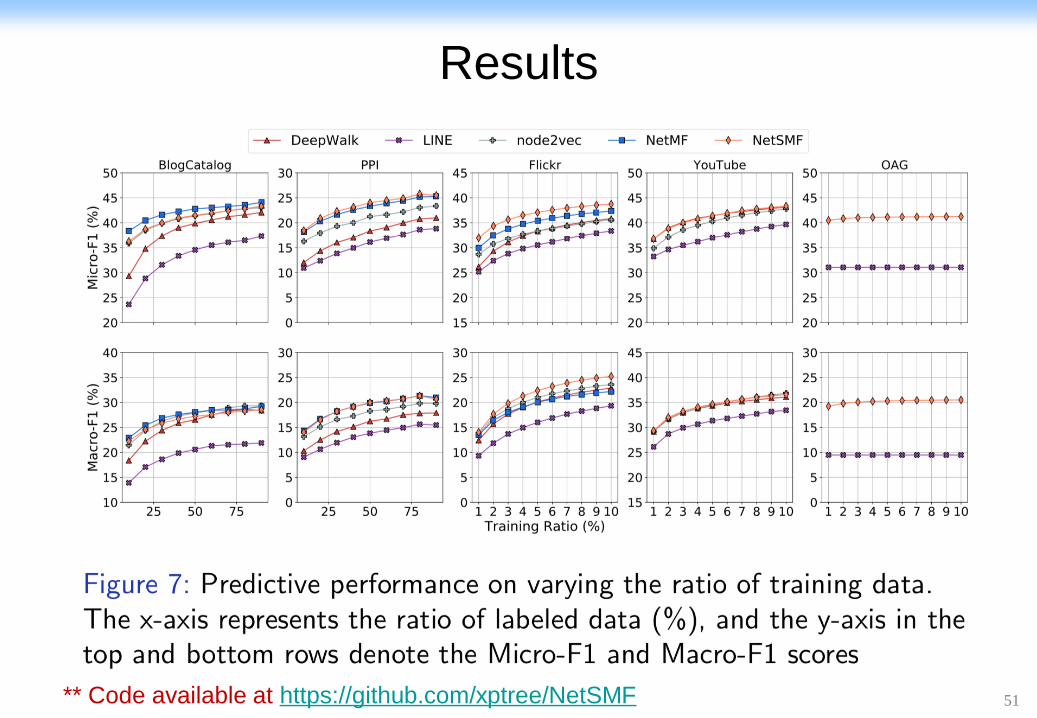
Results
Our methods based
on graph embeddings
** Code&Data available at https://github.com/zfjsail/OAG
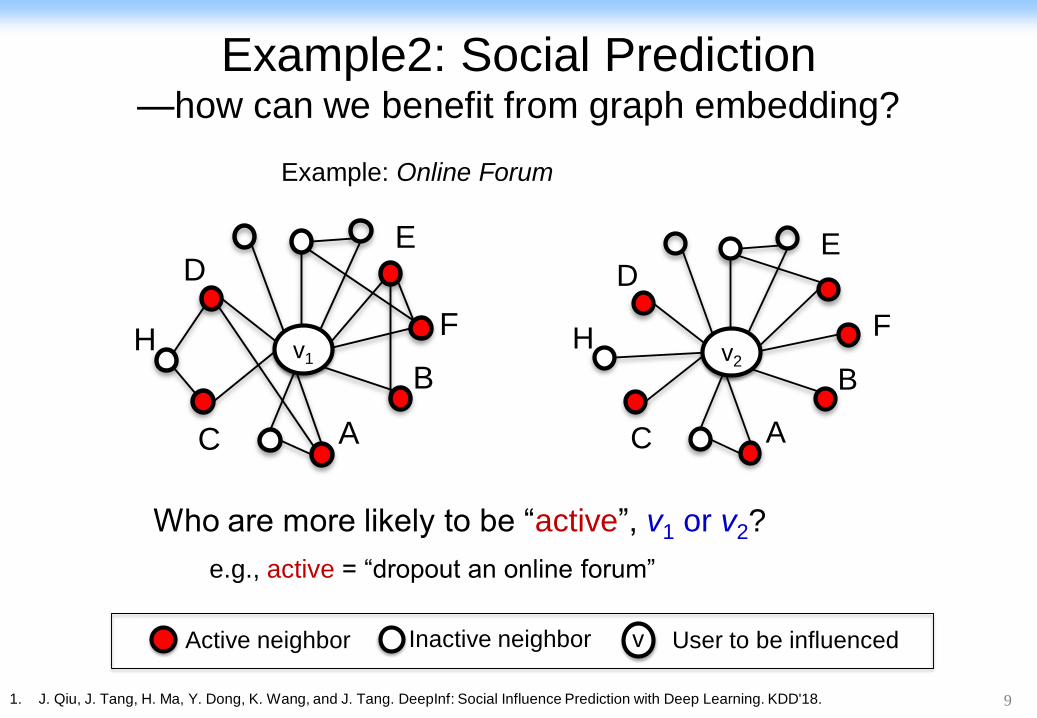
9
Active neighbor Inactive neighbor v User to be influenced
Who are more likely to be “active”, v1 or v2?
v
A
B
D E
F
C
H v
A
B H
D E
F
C
v1 v2
e.g., active = “dropout an online forum”
Example: Online Forum
Example2: Social Prediction—how can we benefit from graph embedding?
1. J. Qiu, J. Tang, H. Ma, Y. Dong, K. Wang, and J. Tang. DeepInf: Social Influence Prediction with Deep Learning. KDD'18.

10
Dropout Prediction
• Dropout prediction with influence
– Problem: dropout prediction
– Game data: King of Glory (王者荣耀)
With Influence w/o influence
Top k #message #success ratio #message #success ratio
1 3996761 1953709 48.88% 6617662 2732167 41.29%
2 2567279 1272037 49.55% 9756330 4116895 42.20%
3 1449256 727728 50.21% 10537994 4474236 42.46%
4 767239 389588 50.78% 9891868 4255347 43.02%
5 3997251 2024859 50.66% 15695743 6589022 41.98%

11
Outline
• Representation Learning for Graphs
– Unified graph embedding as matrix factorization
– Scalable graph embedding
– Fast graph embedding
• Extensions and Reasoning
– Dynamic
– Heterogeneous
– Reasoning
• Conclusion and Q&A

12
Input:
Adjacency Matrix
𝑨
Output:
Vectors
𝒁
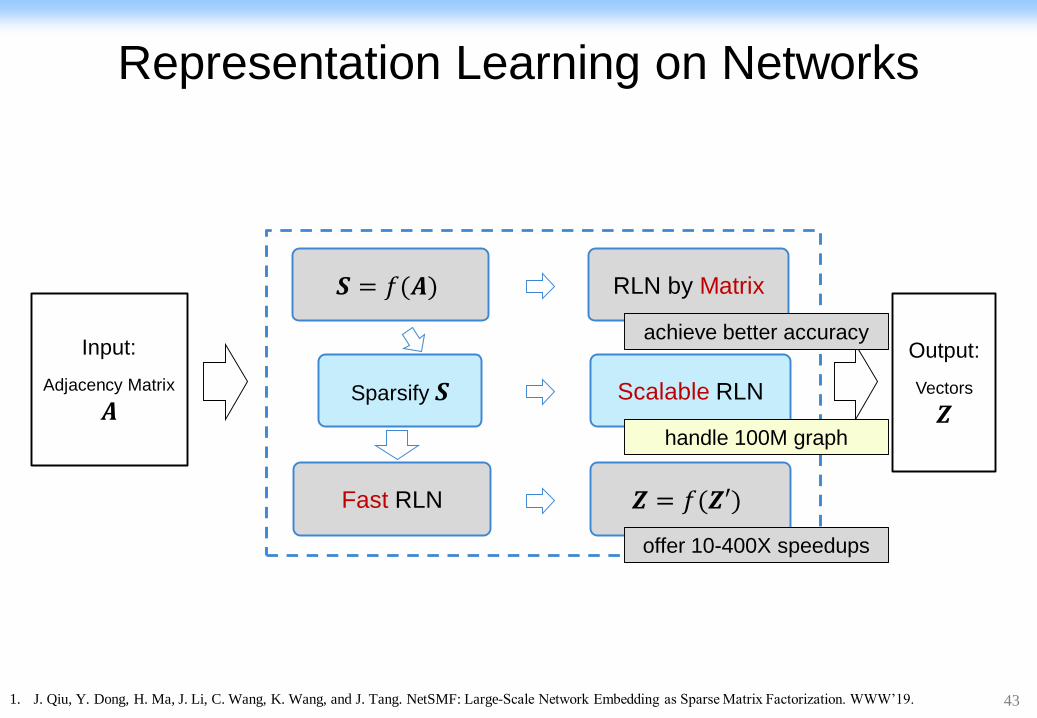
Representation Learning on Networks
𝑺 = 𝑓(𝑨) RLN by Matrix
Fast RLN 𝒁 = 𝑓(𝒁′)
Scalable RLN Sparsify 𝑺
offer 10-400X speedups
handle 100M graph
achieve better accuracy
1. Qiu et al. Network embedding as matrix factorization: unifying deepwalk, line, pte, and node2vec. WSDM’18. The most cited paper in WSDM’18 as of May 2019
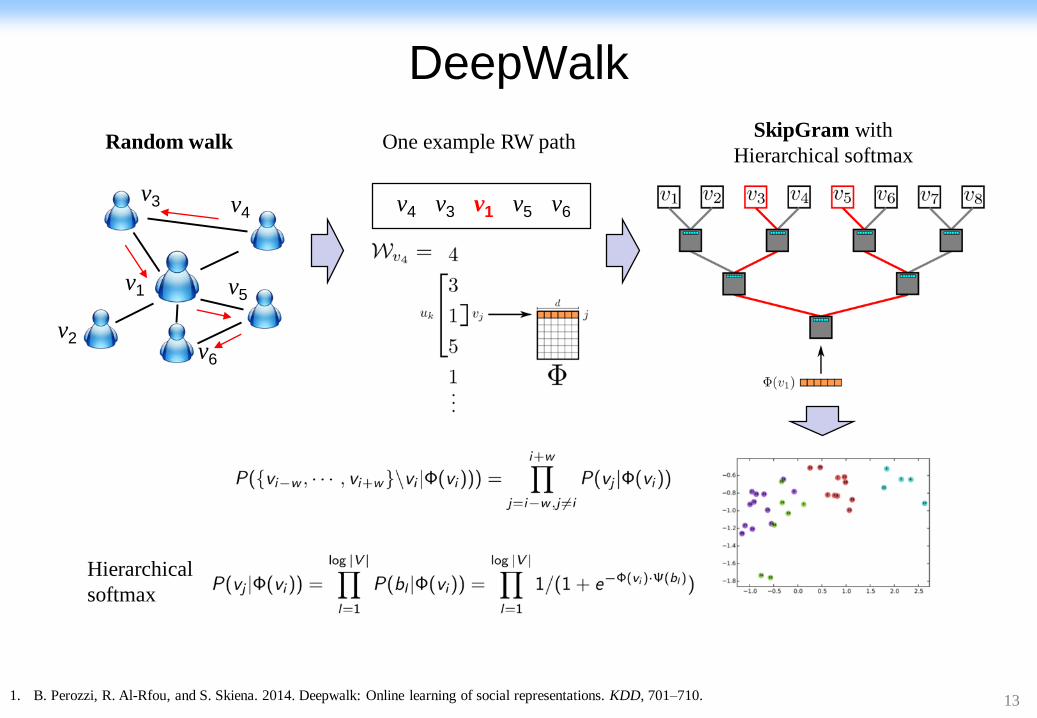
13
DeepWalk
1. B. Perozzi, R. Al-Rfou, and S. Skiena. 2014. Deepwalk: Online learning of social representations. KDD, 701–710.
v1
v2
v3 v4
v6
v5
v4 v3 v1 v5 v6
Random walk One example RW pathSkipGram with
Hierarchical softmax
Hierarchical
softmax

14
Later…
• LINE[1]: explicitly preserves both first-
order and second-order proximities.
• PTE[2]: learn heterogeneous text
network embedding via a semi-
supervised manner.
• Node2vec[3]: use a biased random
walk to better explore node’s
neighborhood.
1. J. Tang, M. Qu, M. Wang, M. Zhang, J. Yan, and Q. Mei. 2015. Line: Large-scale information network embedding. WWW, 1067–1077.
2. J. Tang, M. Qu, and Q. Mei. 2015. Pte: Predictive text embedding through large-scale heterogeneous text networks. KDD, 1165–1174.
3. A. Grover and J. Leskovec. 2016. node2vec: Scalable feature learning for networks. KDD, 855–864.

15
Questions
• What are the fundamentals underlying the
different models?
or
• Can we unify the different network embedding
approaches?

16
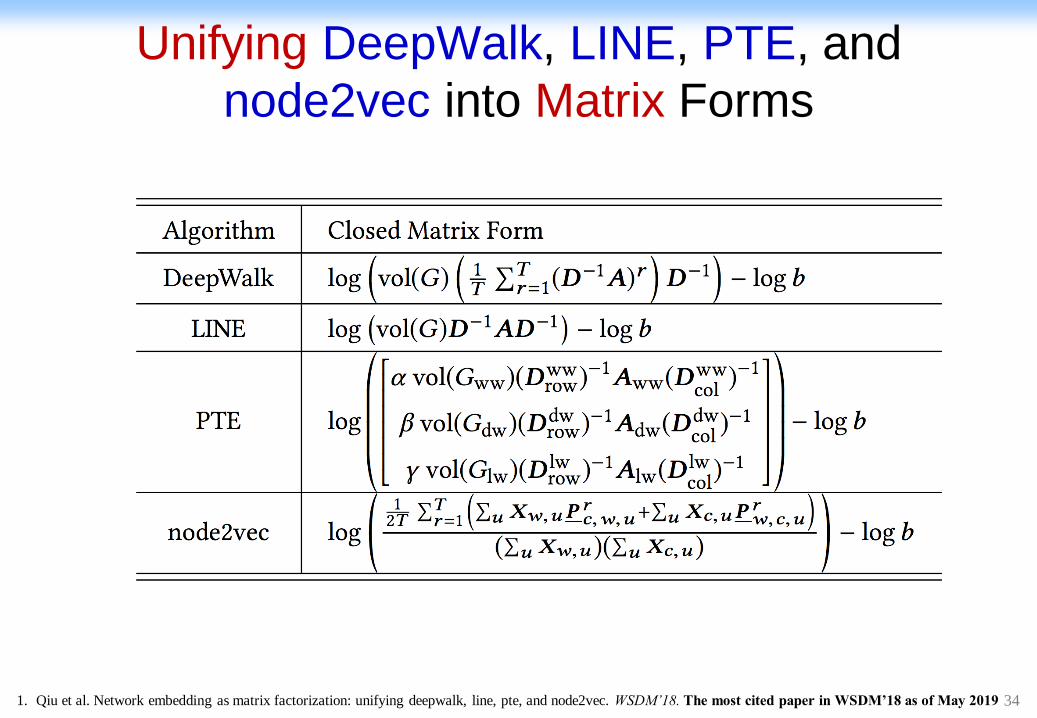
Unifying DeepWalk, LINE, PTE, and
node2vec into Matrix Forms
1. Qiu et al. Network embedding as matrix factorization: unifying deepwalk, line, pte, and node2vec. WSDM’18. The most cited paper in WSDM’18 as of May 2019

17
Starting with DeepWalk

18
DeepWalk Algorithm

19
Skip-gram with Negative Sampling
1. Levy and Goldberg. Neural word embeddings as implicit matrix factorization. In NIPS 2014
• SGNS maintains a multiset 𝓓 that counts the occurrence of
each word-context pair (𝑤, 𝑐)
• Objective
ℒ =
𝑤
𝑐
(# 𝑤, 𝑐 log 𝑔 𝑥𝑤𝑇𝑥𝑐 +
𝑏# 𝑤 #(𝑐)
|𝒟|log 𝑔(−𝑥𝑤
𝑇𝑥𝑐))
where xw and xc are d-dimenational vector
• For sufficiently large dimension d, the objective above is
equivalent to factorizing the PMI matrix[1]
log#(𝑤, 𝑐)|𝒟|
𝑏#(𝑤)#(𝑐)

20
DeepWalk

21
Understanding random walk + skip gram
Suppose the multiset 𝒟 is constructed based on random
walk on graphs, can we interpret 𝑙𝑜𝑔#(𝑤,𝑐)|𝒟|
𝑏#(𝑤)#(𝑐)with graph
structures?

22
Understanding random walk + skip gram
• Partition the multiset 𝒟 into several sub-multisets according to the
way in which each node and its context appear in a random walk
node sequence.
• More formally, for 𝑟 = 1, 2,⋯ , 𝑇, we define
Distinguish direction
and distance

23
Understanding random walk + skip gram

24
Understanding random walk + skip gram

25
Understanding random walk + skip gram
the length of random walk 𝐿 → ∞
1. Qiu et al. Network embedding as matrix factorization: unifying deepwalk, line, pte, and node2vec. WSDM’18. The most cited paper in WSDM’18 as of May 2019

26
Understanding random walk + skip gram
the length of random walk 𝐿 → ∞
1. Qiu et al. Network embedding as matrix factorization: unifying deepwalk, line, pte, and node2vec. WSDM’18. The most cited paper in WSDM’18 as of May 2019
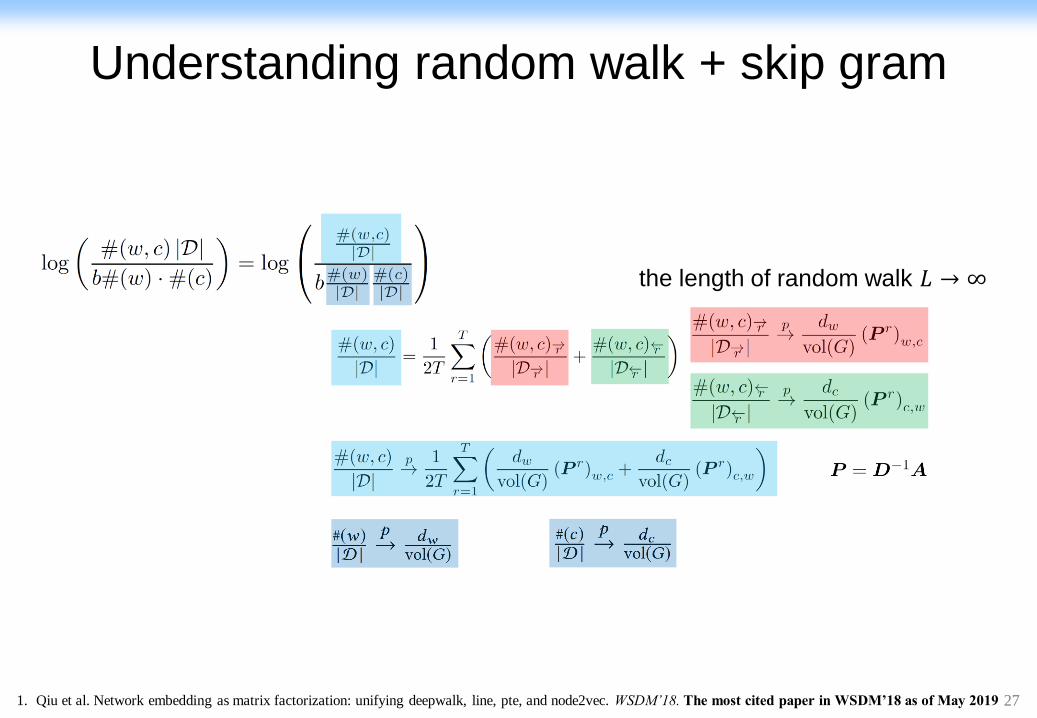
27
Understanding random walk + skip gram
the length of random walk 𝐿 → ∞
1. Qiu et al. Network embedding as matrix factorization: unifying deepwalk, line, pte, and node2vec. WSDM’18. The most cited paper in WSDM’18 as of May 2019

28
Understanding random walk + skip gram
the length of random walk 𝐿 → ∞
1. Qiu et al. Network embedding as matrix factorization: unifying deepwalk, line, pte, and node2vec. WSDM’18. The most cited paper in WSDM’18 as of May 2019

29

30
𝑤𝑖
𝑤𝑖−2
𝑤𝑖−1
𝑤𝑖+1
𝑤𝑖+2
DeepWalk is asymptotically and implicitly factorizing
DeepWalk is factorizing…
𝑣𝑜𝑙 𝐺 =
𝑖
𝑗
𝐴𝑖𝑗
𝑨 Adjacency matrix
𝑫 Degree matrix
b: #negative samples
T: context window size

31
LINE

32
PTE

33
node2vec — 2nd Order Random Walk
34
Unifying DeepWalk, LINE, PTE, and
node2vec into Matrix Forms
1. Qiu et al. Network embedding as matrix factorization: unifying deepwalk, line, pte, and node2vec. WSDM’18. The most cited paper in WSDM’18 as of May 2019
35
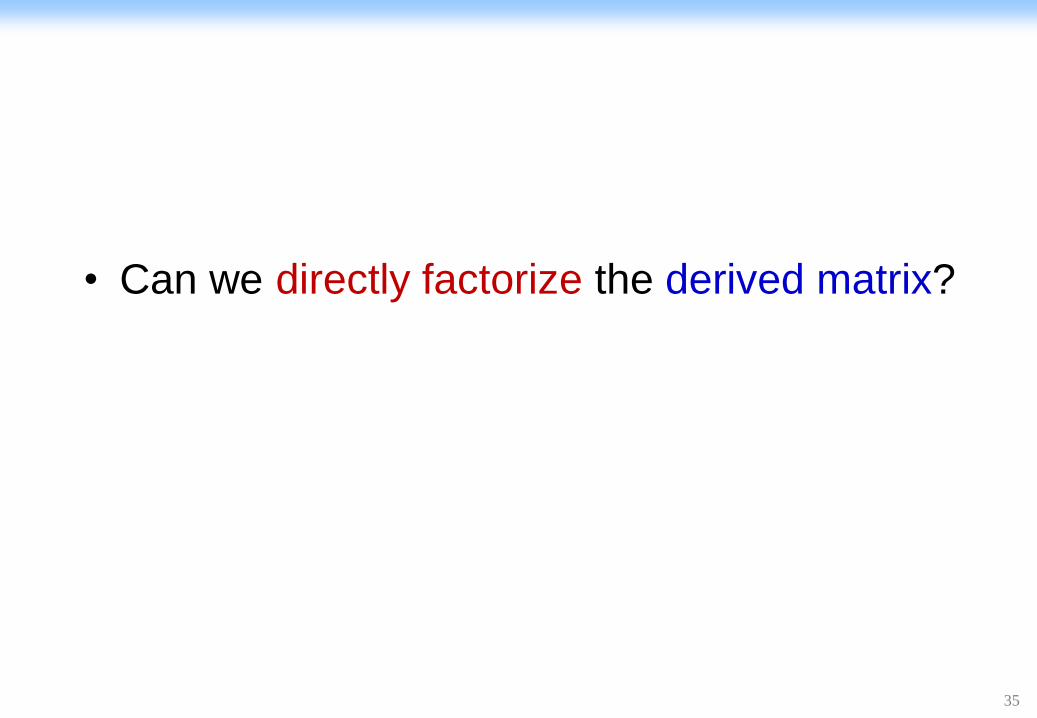
• Can we directly factorize the derived matrix?

36
NetMF: explicitly factorizing the DW matrix
𝑤𝑖
𝑤𝑖−2
𝑤𝑖−1
𝑤𝑖+1
𝑤𝑖+2
DeepWalk is asymptotically and implicitly factorizing
Matrix
Factorization
1. Qiu et al. Network embedding as matrix factorization: unifying deepwalk, line, pte, and node2vec. WSDM’18. The most cited paper in WSDM’18 as of May 2019

37
Explicitly factorize the matrix
1. R. Lehoucq, D. Sorensen, and C.Yang. 1998. ARPACK users’ guide: solution of large-scale eigenvalue problems with implicitly restarted Arnoldi methods. SIAM.
* approximate D-1/2AD-1/2 with
its top-h eigenpairs Uh𝝠hUhT
* decompose using Arnoldi
algorithm[1]
* decompose using Arnoldi
algorithm[1]

38
Error Bound Analysis for NetMF
• According to Frobenius norm’s property
• and because M’i,j=max(Mi,j, 1)>=1, we have
• Also because the property of NGL,

39
Experimental Setup
** Code available at https://github.com/xptree/NetMF
40
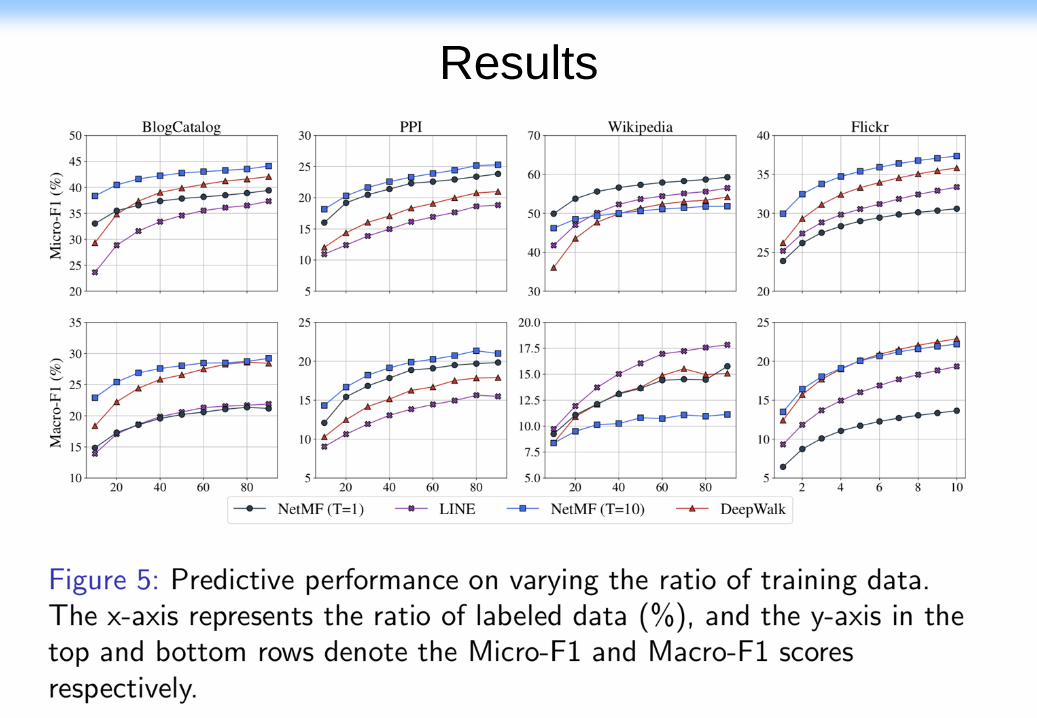
Results

41
Results
• NetMF significantly outperforms LINE and
DeepWalk when sparse labeled vertices are
provided
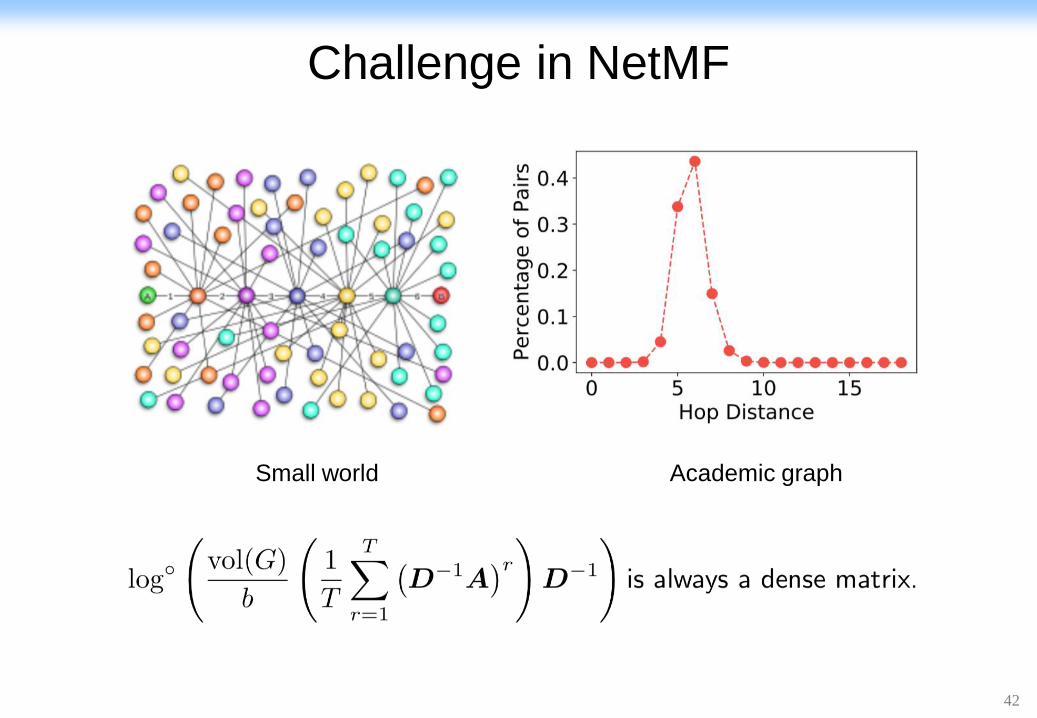
42
Challenge in NetMF
Academic graphSmall world
43
Input:
Adjacency Matrix
𝑨
Output:
Vectors
𝒁
Representation Learning on Networks
𝑺 = 𝑓(𝑨) RLN by Matrix
Fast RLN 𝒁 = 𝑓(𝒁′)
Scalable RLN Sparsify 𝑺
offer 10-400X speedups
handle 100M graph
achieve better accuracy
1. J. Qiu, Y. Dong, H. Ma, J. Li, C. Wang, K. Wang, and J. Tang. NetSMF: Large-Scale Network Embedding as Sparse Matrix Factorization. WWW’19.

44
Sparsify 𝑺
For random-walk matrix polynomial
where and non-negative
One can construct a 1 + 𝜖 -spectral sparsifier ෨𝑳 with non-zeros
in time
for undirected graphs
1. D. Cheng, Y. Cheng, Y. Liu, R. Peng, and S.H. Teng, Efficient Sampling for Gaussian Graphical Models via Spectral Sparsification, COLT 2015.
2. D. Cheng, Y. Cheng, Y. Liu, R. Peng, and S.H. Teng. Spectral sparsification of random-walk matrix polynomials. arXiv:1502.03496.

45
Sparsify 𝑺
For random-walk matrix polynomial
where and non-negative
One can construct a 1 + 𝜖 -spectral sparsifier ෨𝑳 with non-zeros
in time

46
Sparsify 𝑺
For random-walk matrix polynomial
where and non-negative
One can construct a 1 + 𝜖 -spectral sparsifier ෨𝑳 with non-zeros
in time

47
Sparsify 𝑺
For random-walk matrix polynomial
where and non-negative
One can construct a 1 + 𝜖 -spectral sparsifier ෨𝑳 with non-zeros
in time

48
NetSMF --- Sparse
Factorize the constructed matrix
1. J. Qiu, Y. Dong, H. Ma, J. Li, C. Wang, K. Wang, and J. Tang. NetSMF: Large-Scale Network Embedding as Sparse Matrix Factorization. WWW’19.

49
NetSMF — Approximation Error
52
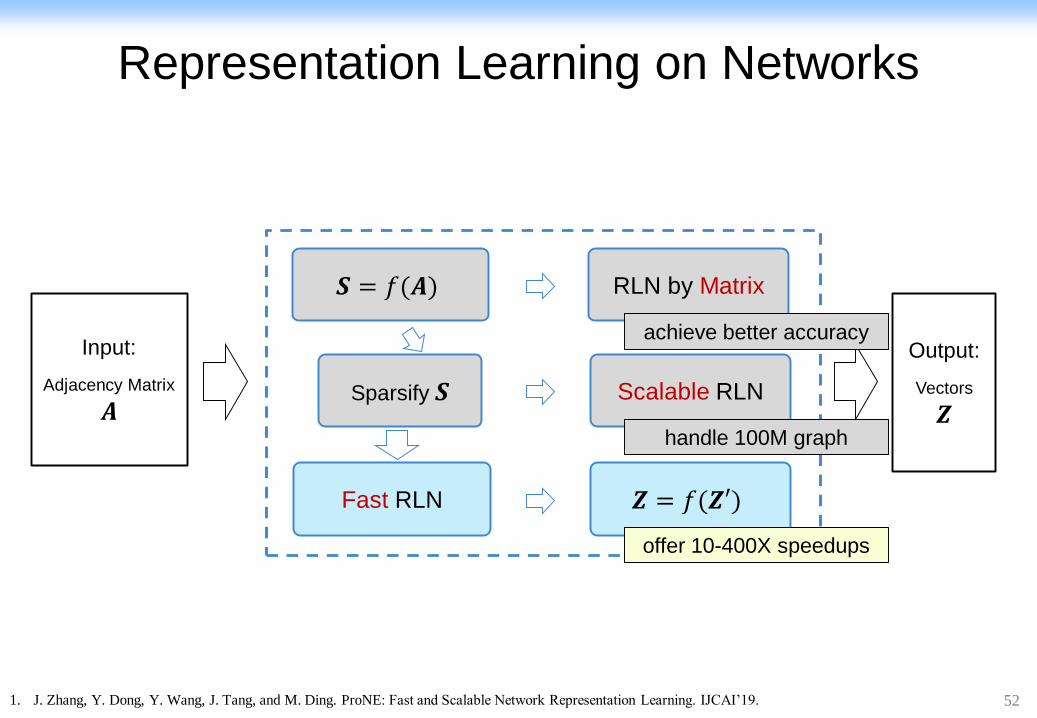
Input:
Adjacency Matrix
𝑨
Output:
Vectors
𝒁
Representation Learning on Networks
𝑺 = 𝑓(𝑨) RLN by Matrix
Fast RLN 𝒁 = 𝑓(𝒁′)
Scalable RLN Sparsify 𝑺
offer 10-400X speedups
handle 100M graph
achieve better accuracy
1. J. Zhang, Y. Dong, Y. Wang, J. Tang, and M. Ding. ProNE: Fast and Scalable Network Representation Learning. IJCAI’19.
53
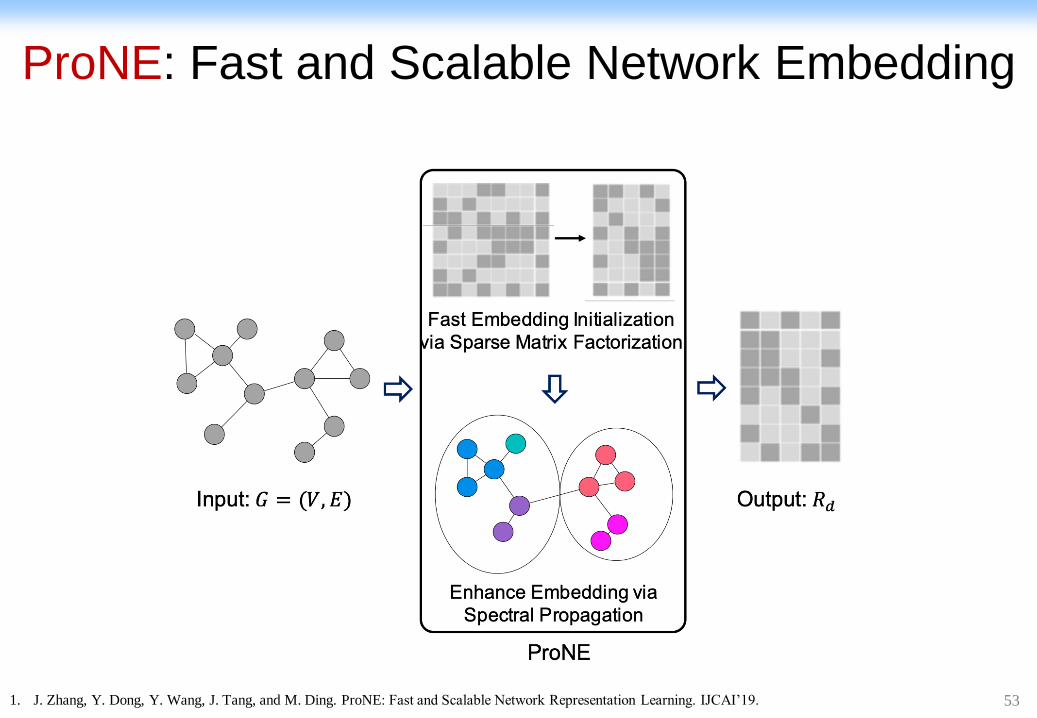
ProNE: Fast and Scalable Network Embedding
1. J. Zhang, Y. Dong, Y. Wang, J. Tang, and M. Ding. ProNE: Fast and Scalable Network Representation Learning. IJCAI’19.

54** Code available at https://github.com/THUDM/ProNE
* ProNE (1 thread) v.s.
Others (20 threads)
ProNE: Fast and Scalable Network Embedding
* 10 minutes on
Youtube (~1M nodes)

55
NE as Sparse Matrix Factorization
• node-context set (sparsity)
• For edge (i, j), the occurrence probability of context j given
node i
• objective (weighted sum of log-loss)

56
NE as Sparse Matrix Factorization
• To avoid the trivial solution
• Local negative samples drawn from
• Modify the loss (sum over the edge-->sparse)

57
NE as Sparse Matrix Factorization
• Let the partial derivative w.r.t. be zero
• Matrix to be factorized (sparse)

58
NE as Sparse Matrix Factorization
• Matrix to be factorized (sparse)
• Many methods for truncated SVD with the sparse matrix
(e.g., randomized tSVD, )
• This optimization method (single thread) is much faster than
SGD used in DeepWalk, LINE, etc. and is still scalable!!!
• Orthogonality, avoid direct non-convex optimization

59
NE as Sparse Matrix Factorization
• Compared with matrix factorization method (e.g., NetMF)
• Sparsity (local structure and local negative samples)→
much faster and scalable
• Challenge: may lose high order information!
• Improvement via spectral propagation
V.S.

60
Higher-order Cheeger’s inequality
•
• Bridge graph spectrum and graph partitioning
• k-way Cheeger constant :reflects the effect of the
graph partitioned into k parts. A smaller value of
means a better partitioning effect.
1. J. R. Lee, S. O. Gharan, L. Trevisan. Multiway spectral partitioning and higher-order cheeger inequalities. Journal of the ACM (JACM), 2014, 61(6): 37.

61
Higher-order Cheeger’s inequality
• Bridge graph spectrum and graph partition
• low eigenvalues control the global information
• high eigenvalues control the local information
•
• spectral propagation: propagate the initial network
embedding in the spectrally modulated network !
62
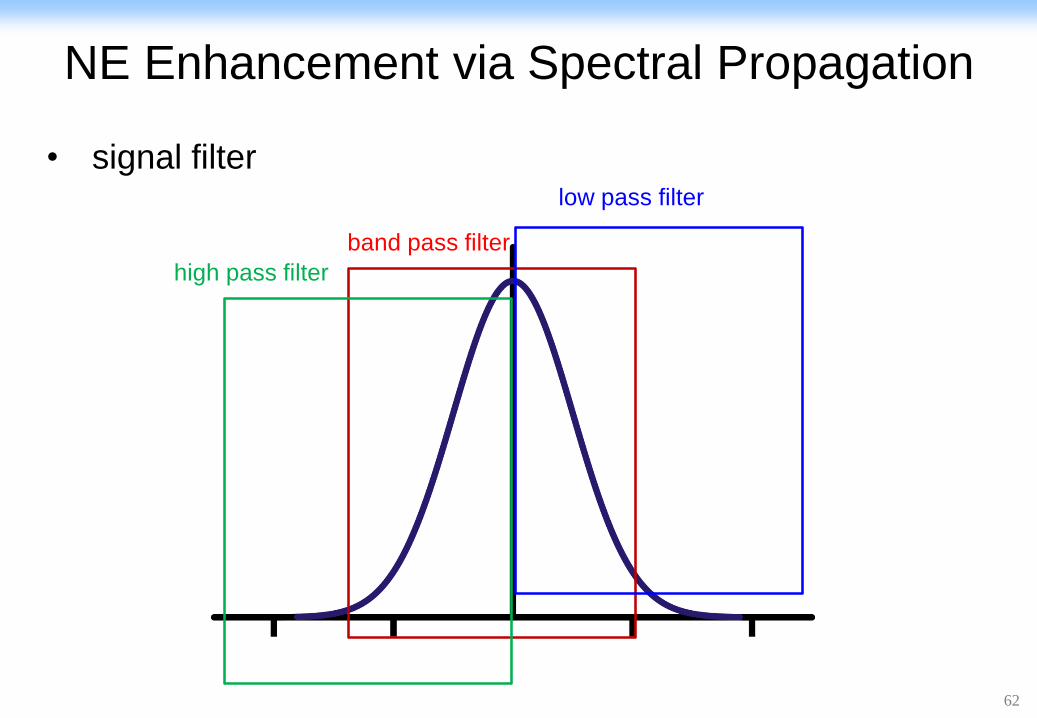
NE Enhancement via Spectral Propagation
• signal filterlow pass filter
band pass filter
high pass filter
63
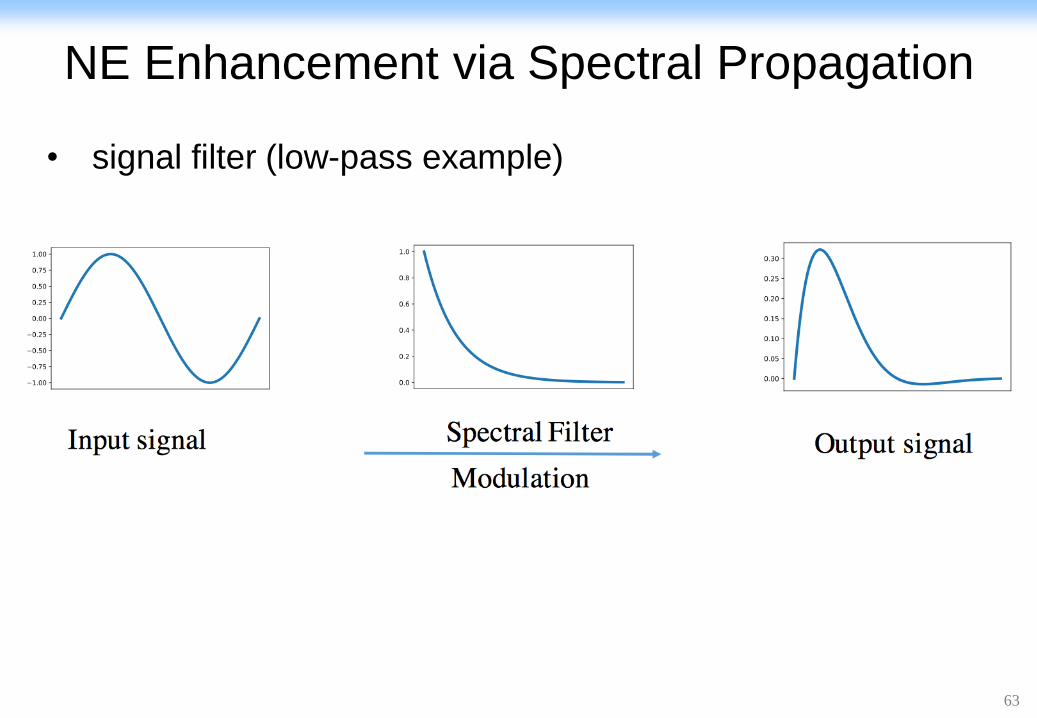
NE Enhancement via Spectral Propagation
• signal filter (low-pass example)

64
NE Enhancement via Spectral Propagation
• spectral propagation for NE
• is the spectral filter of
• is the spectral filter of
• is modulated by the filter in the spectrum

65
NE Enhancement via Spectral Propagation
• the form of the spectral filter
• Band-pass (low-pass, high-pass)
• pass eigenvalues within a certain range and weaken
eigenvalues outside that range
• amplify local and global network information

66
Chebyshev Expansion for Efficiency
• Utilize truncated Chebyshev expansion to avoid explicit
eigendecomposition and Fourier transform
• Calculate the coefficient of Chebyshev expansion
where is the modified Bessel function of the first kind

67
Chebyshev Expansion for Efficiency
• NE
• Denote and calculate the Equation in the
following recursive way

68
Complexity of ProNE
• Spectral propagation only involves sparse matrix
multiplication! The complexity is linear!
• sparse matrix factorization + spectral propagation
= O(|V|d2 + k|E|)

70
Results
** Code available at https://github.com/THUDM/ProNE
* ProNE (1 thread) v.s.
Others (20 threads)
* 10 minutes on
Youtube (~1M nodes)

71
Effectiveness experiments
** Code available at https://github.com/THUDM/ProNE
* ProNE (SMF) = ProNE w/
only sparse matrix factorization
Embed 100,000,000 nodes by one thread:
29 hours with performance superiority

72
Spectral Propagation: k-way Cheeger

73
Outline
• Representation Learning for Graphs
– Unified graph embedding as matrix factorization
– Scalable graph embedding
– Fast graph embedding
• Extensions and Reasoning
– Dynamic
– Heterogeneous
– Reasoning
• Conclusion and Q&A

74
BurstGraph: Dynamic Network Embedding
with Burst Detection
• GraphSage aggregates structural information for each snapshot of dynamic networks.
• VAE reconstructs the vanilla evolution and bursty evolution.
• RNN Structure extends the model for dynamic networks.
1. Y. Zhao, X. Wang, H. Yang, L. Song, and J. Tang. Large Scale Evolving Graphs with Burst Detection. IJCAI’19.

75
Information Aggregation
• To get the feature information of each snapshot, we utilize
GraphSage to aggregate the hidden representation from vertices’
neighbors.
• In each network snapshot, GraphSage samples neighbors via
uniform distribution.
• Then GraphSage uses simple max-pooling operator to aggregate
information from neighbors.

76
Vanilla Evolution
• Based on the feature information 𝐺𝑖,𝑡 aggregated by GraphSAGE, vanilla and
bursty evolution both choose VAE to reconstruct the structure of network
snapshot;
• The random variable 𝒛𝑡 of vanilla evolution follows a normal Gaussian
distribution:

77
Bursty Evolution
• Due to the sparsity and contingency of bursty evolution, the random variable
𝒔𝑡 of bursty evolution follows a Spike-and-Slab distribution:
78
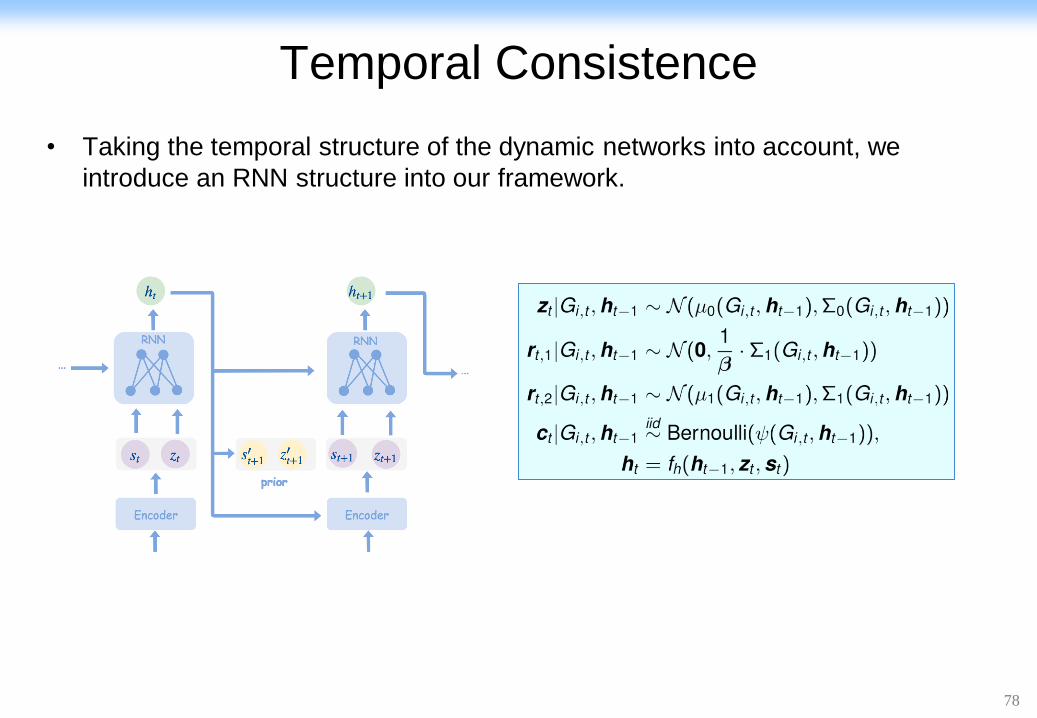
Temporal Consistence
• Taking the temporal structure of the dynamic networks into account, we
introduce an RNN structure into our framework.

79
Link Prediction Result
• Data
– Alibaba: one of the largest E-commerce platform
• Methods
– Static NE: DeepWalk, GraphSage
– Dynamic NE: TNE, CTDNE
* Task: predicting links between users and items
** Code available at https://github.com/ericZhao93/BurstGraph

80
Outline
• Representation Learning for Graphs
– Unified graph embedding as matrix factorization
– Scalable graph embedding
– Fast graph embedding
• Extensions and Reasoning
– Dynamic
– Heterogeneous
– Reasoning
• Conclusion and Q&A

81
Multiplex Heterogeneous Graph Embedding
users items
click
add-to-preference
add-to-cart
conversionGender: male
Age: 23
Location: Beijing
…
Price: $1000
Brand: Lenovo
…
Gender: male
Age: 35
Location: Boston
…
Gender: female
Age: 26
Location: Bangalore
…
Price: $800
Brand:Apple
…
Price: $50
Brand: Nike
…
• Multiplex networks comprise not only multi-typed nodes and/or edges but also a rich
set of attributes.
• How do we deal with the multiplex edges?
1. Y. Cen, X. Zou, J. Zhang, H. Yang, J. Zhou and J. Tang. Representation Learning for Attributed Multiplex Heterogeneous Network. KDD’19.

82
Related Network Embedding Methods
83
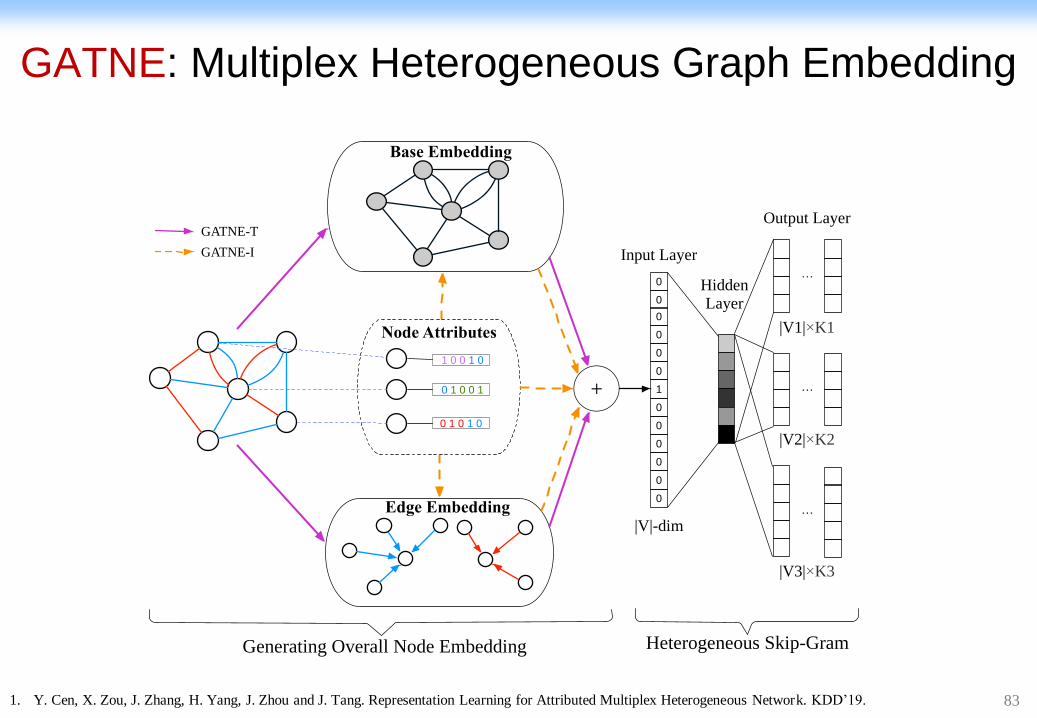
GATNE: Multiplex Heterogeneous Graph Embedding
Generating Overall Node Embedding
Base Embedding
Edge Embedding
0 1 0 0 1
1 0 0 1 0
0 1 0 1 0
Node Attributes
GATNE-T
GATNE-I
0
0
0
0
1
0
0
0
0
0
0
0
0
Heterogeneous Skip-Gram
Input Layer
Hidden Layer
Output Layer
…
|V|-dim
|V1|×K1
…
…
|V2|×K2
|V3|×K3
1. Y. Cen, X. Zou, J. Zhang, H. Yang, J. Zhou and J. Tang. Representation Learning for Attributed Multiplex Heterogeneous Network. KDD’19.
84
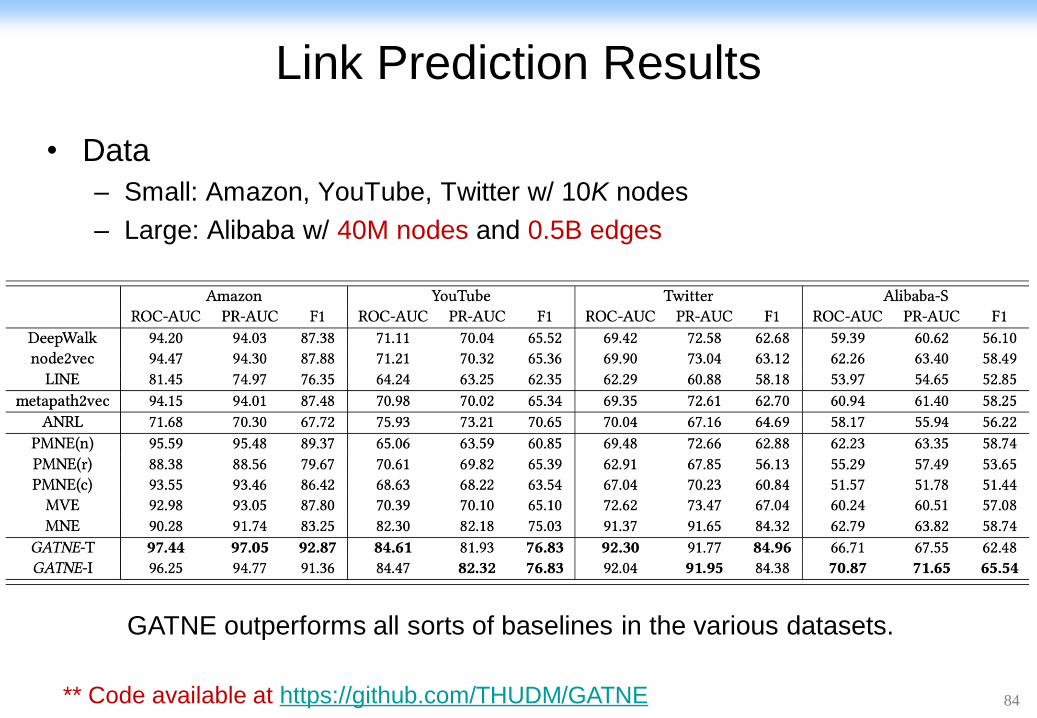
Link Prediction Results
• Data
– Small: Amazon, YouTube, Twitter w/ 10K nodes
– Large: Alibaba w/ 40M nodes and 0.5B edges
GATNE outperforms all sorts of baselines in the various datasets.
** Code available at https://github.com/THUDM/GATNE

85
Outline
• Representation Learning for Graphs
– Unified graph embedding as matrix factorization
– Scalable graph embedding
– Fast graph embedding
• Extensions and Reasoning
– Dynamic
– Heterogeneous
– Reasoning
• Conclusion and Q&A
86
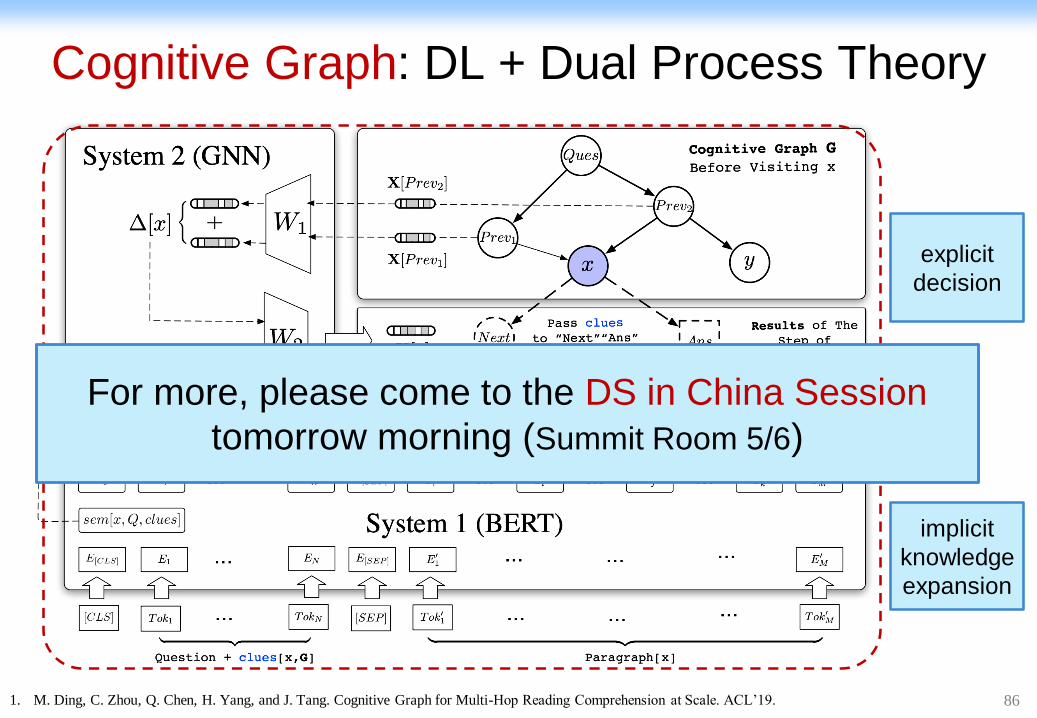
Cognitive Graph: DL + Dual Process Theory
1. M. Ding, C. Zhou, Q. Chen, H. Yang, and J. Tang. Cognitive Graph for Multi-Hop Reading Comprehension at Scale. ACL’19.
implicit
knowledge
expansion
explicit
decision
For more, please come to the DS in China Session
tomorrow morning (Summit Room 5/6)

87
CogDL—A Toolkit for Deep Learning on Graphs
** Code available at https://keg.cs.tsinghua.edu.cn/cogdl/

88
CogDL—A Toolkit for Deep Learning on Graphs

89
CogDL features
• CogDL supports these features:
✓Sparsification: fast network embedding on large-scale
networks with tens of millions of nodes
✓Arbitrary: dealing with different graph structures: attributed,
multiplex and heterogeneous networks
✓Distributed: multi-GPU training on one machine or across
multiple machines
✓Extensible: easily register new datasets, models, criterions
and tasks
• Homepage: https://keg.cs.tsinghua.edu.cn/cogdl/

91
CogDL Leaderboards
Multi-label Node ClassificationThe following leaderboard is built from unsupervised learning with
multi-label node classification setting.
http://keg.cs.tsinghua.edu.cn/cogdl/node-classification.html

92
CogDL Leaderboards
Node Classification with Attributes.
http://keg.cs.tsinghua.edu.cn/cogdl/node-classification.html

93
Leaderboards: Link Prediction
http://keg.cs.tsinghua.edu.cn/cogdl/link-prediction.html

94
Join us
• Feel free to join us with the three following ways:
✓add your data into the leaderboard
✓add your algorithm into the leaderboard
✓add your algorithm into the toolkit
• Note that, in order to collaborate with us, you may refer to the
documentation in our homepage.

95
Graph Embedding: A Quick Summary
Spectral partitioning 1973: Donath & Hoffman
2005: Gori et al., IJCNN’05
2015: Duvenaud et al., NIPS’15; Kipf & Welling ICLR’17
Spectral clustering 2000: Ng et al. & Shi, Malik
2014: Perozzi et al., KDD’14
2015: Tang et al., WWW’15; Grover & Leskovec, KDD’16
PTE, metapath2vec
2013: Mikolov et al., ICLR’13word2vec (skip-gram)
LINE, node2vec
DeepWalk
2018: Velickovic et al., ICLR’18, Chen et al., ICLR 2018
NetMF & NetSMF
FastGCNs, Graph attention
Graph convolutional network
Graph neural network
2015: Tang et al., KDD’15; Dong et al., KDD’17
2018: Qiu et al., WSDM’18 & WWW’19
Neural message passing, GraphSage 2017: Gilmer et al., ICML’17; Hamilton et al., NIPS’17
2014: Bruna et al., ICLR’14 Spectral graph convolution
Gated graph neural network 2016: Li et al., ICLR’16
structure2vec 2016: Dai et al., ICML’16
2019: Zhang et al., IJCAI’19; Cen et al., KDD’19; Zhao et al., IJCAI’19ProNE, GATNE, BurstGraph
2019: Ding et al., ACL’19Cognitive Graph

96
Input:
Adjacency Matrix
𝑨
Output:
Vectors
𝒁
Representation Learning on Networks
𝑺 = 𝑓(𝑨) RLN by Matrix
Fast RLN 𝒁 = 𝑓(𝒁′)
Scalable RLN Sparsify 𝑺
offer 10-400X speedups
handle 100M graph
achieve better accuracy
Dynamic &
HeterogeneousCognitive Graph
CogDL: A Toolkit for Deep Learning on Graphs

97
Related Publications
• Jie Zhang, Yuxiao Dong, Yan Wang, Jie Tang, and Ming Ding. ProNE: Fast and Scalable Network Representation
Learning. IJCAI’19.
• Yukuo Cen, Xu Zou, Jianwei Zhang, Hongxia Yang, Jingren Zhou and Jie Tang. Representation Learning for
Attributed Multiplex Heterogeneous Network. KDD’19.
• Fanjin Zhang, Xiao Liu, Jie Tang, Yuxiao Dong, Peiran Yao, Jie Zhang, Xiaotao Gu, Yan Wang, Bin Shao, Rui Li,
and Kuansan Wang. OAG: Toward Linking Large-scale Heterogeneous Entity Graphs. KDD’19.
• Yifeng Zhao, Xiangwei Wang, Hongxia Yang, Le Song, and Jie Tang. Large Scale Evolving Graphs with Burst
Detection. IJCAI’19.
• Yu Han, Jie Tang, and Qian Chen. Network Embedding under Partial Monitoring for Evolving Networks. IJCAI’19.
• Ming Ding, Chang Zhou, Qibin Chen, Hongxia Yang, and Jie Tang. Cognitive Graph for Multi-Hop Reading
Comprehension at Scale. ACL’19.
• Jiezhong Qiu, Yuxiao Dong, Hao Ma, Jian Li, Chi Wang, Kuansan Wang, and Jie Tang. NetSMF: Large-Scale
Network Embedding as Sparse Matrix Factorization. WWW'19.
• Jiezhong Qiu, Jian Tang, Hao Ma, Yuxiao Dong, Kuansan Wang, and Jie Tang. DeepInf: Modeling Influence
Locality in Large Social Networks. KDD’18.
• Jiezhong Qiu, Yuxiao Dong, Hao Ma, Jian Li, Kuansan Wang, and Jie Tang. Network Embedding as Matrix
Factorization: Unifying DeepWalk, LINE, PTE, and node2vec. WSDM’18.
• Jie Tang, Jing Zhang, Limin Yao, Juanzi Li, Li Zhang, and Zhong Su. ArnetMiner: Extraction and Mining of
Academic Social Networks. KDD’08.
For more, please check here http://keg.cs.tsinghua.edu.cn/jietang

98
Jie Tang, KEG, Tsinghua U http://keg.cs.tsinghua.edu.cn/jietang
Download all data & Codes https://keg.cs.tsinghua.edu.cn/cogdl/
Thank you!Collaborators:
Jie Zhang, Jiezhong Qiu, Ming Ding, Qibin Chen, Yifeng Zhao, Yukuo Cen, Yu
Han, Fanjin Zhang, Xu Zou, Yan Wang, et al. (THU)
Yuxiao Dong, Chi Wang, Hao Ma, Kuansan Wang (Microsoft)
Hongxia Yang, Chang Zhou, Le Song, Jingren Zhou, et al. (Alibaba)
















![Web Services Distributed Management: Management Using ...docs.oasis-open.org/wsdm/2004/12/muws/cd-wsdm-muws-part1...21 2] provides specific messaging formats used to enable the interoperability](https://static.fdocuments.in/doc/165x107/5fa2f29be971b429cb0909f2/web-services-distributed-management-management-using-docsoasis-openorgwsdm200412muwscd-wsdm-muws-part1.jpg)
![A Non-parametric Bayesian Approach [WSDM’14]](https://static.fdocuments.in/doc/165x107/56816611550346895dd9594c/a-non-parametric-bayesian-approach-wsdm14.jpg)
