
Gerhard Weikum ([email protected]) Peer-to-Peer Web Search with Minerva In collaboration with:...
36
Gerhard Weikum ([email protected]) Peer-to-Peer Web Search with Minerva laboration with: as Bender, Debora Donato, Alessandro Linari, Julia Luxenburger, ian Michel, Nikos Ntarmos, Josiane Parreira, Peter Triantafillou, ian Zimmer
-
Upload
conner-boarman -
Category
Documents
-
view
225 -
download
1
Transcript of Gerhard Weikum ([email protected]) Peer-to-Peer Web Search with Minerva In collaboration with:...

Gerhard Weikum ([email protected])
Peer-to-Peer Web Search with Minerva
In collaboration with:Matthias Bender, Debora Donato, Alessandro Linari, Julia Luxenburger, Sebastian Michel, Nikos Ntarmos, Josiane Parreira, Peter Triantafillou, Christian Zimmer

Gerhard Weikum August 3, 2006 2/36
Peer-to-Peer (P2P) SystemsDecentralized, self-organizing, highly dynamicloose coupling of many autonomous computers
Applications:• Large-scale computation (SETI@home, etc.)• File sharing (Napster, Gnutella, KaZaA, BitTorrent, etc.)• Publish-Subscribe (Blogs, Marketplaces, etc.)• Collaborative work (Games, etc.) • IP telephony (Skype)
Any applications that are useful and legal ?And scientifically challenging?
unstructured overlay networks with epidemic dissemination (flooding) structured overlay networks based on distributed hash tables (DHTs)

Gerhard Weikum August 3, 2006 3/36
• Scalable & Self-Organizing Data Structures and Algorithms (DHTs, Semantic Overlay Networks, Epidemic Spreading, Distr. Link Analysis, etc.)
• Powerful Search Methods for Each Peer (Concept-based Search, Query Expansion, XML IR, Personalization, etc.)
• Leverage User/Community Input („Wisdom of Crowds“) (Bookmarks, Feedback, Query Logs, Click Streams, Evolving Web, etc.)
• Collaboration among Peers (Query Routing, Incentives, Fairness, Anonymity, etc.)
• Better Search Result Quality (Precision, Recall, etc.)
• Benefit of Large-scale Social Networks:• Small-World Phenomenon • Breaking Information Monopolies
Peer-to-Peer Web SearchVision: Self-organizing P2P Web Search Engine
with Google-or-better functionality

Gerhard Weikum August 3, 2006 4/36
Solution without Problem?no killer app with business value !?
but:• P2P potentially useful also for server farms & grids• interesting non-business applications
> 1 Mio. scholars and graduate students• produce valuable text & scientific data, knowledge, annotations, etc.• leverage NLP, statistical learning, data curation & enrichment, etc.• would benefit from P2P system with XML IR
ex.: recent conference papers by computer scientists on percolation theory with application of phase transition models to the analysis of Web graph dynamics
> 100 Bio. page versions in Web archive• produced at > 20 TB/month by millions of Web sites• P2P system with time-travel queries could replace & enhance IA
ex.: „search engine scoring models“ as of Aug 1998 „Jacques Chirac EU constitution“ from Jan 2005 to Jan 2006
TopX engine for XPath Full-Text[M. Theobald et al.: VLDB 05]
Time-aware rank synopses[K. Berberich et al.: WWW 06]

Gerhard Weikum August 3, 2006 5/36
Outline
Motivation and Research Directions
P2P Query Routing
• P2P Link Analysis
•
• Conclusion
Overlap Awareness•
Discriminative Posting•
JXP Authority Scoring•
• Personalized and Community-aware RankingQRank and QReward•

Gerhard Weikum August 3, 2006 6/36
Computational Model• Peers connected by overlay network (e.g. DHT, random graph) and IP
• Each peer has autonomously compiled (e.g. crawled) its own content according to the user‘s thematic interests peer-specific collections
• Each peer has a full-fledged local search engine with crawler/importer, indexer, query processor
• When a query is issued by a peer, it is first executed locally and then possibly routed to carefully selected other peers
• Peers can post summaries / synopses / metadata / QoS info to (distr.) network-wide directory (space O(#terms * #peers))
with efficient per-key lookup
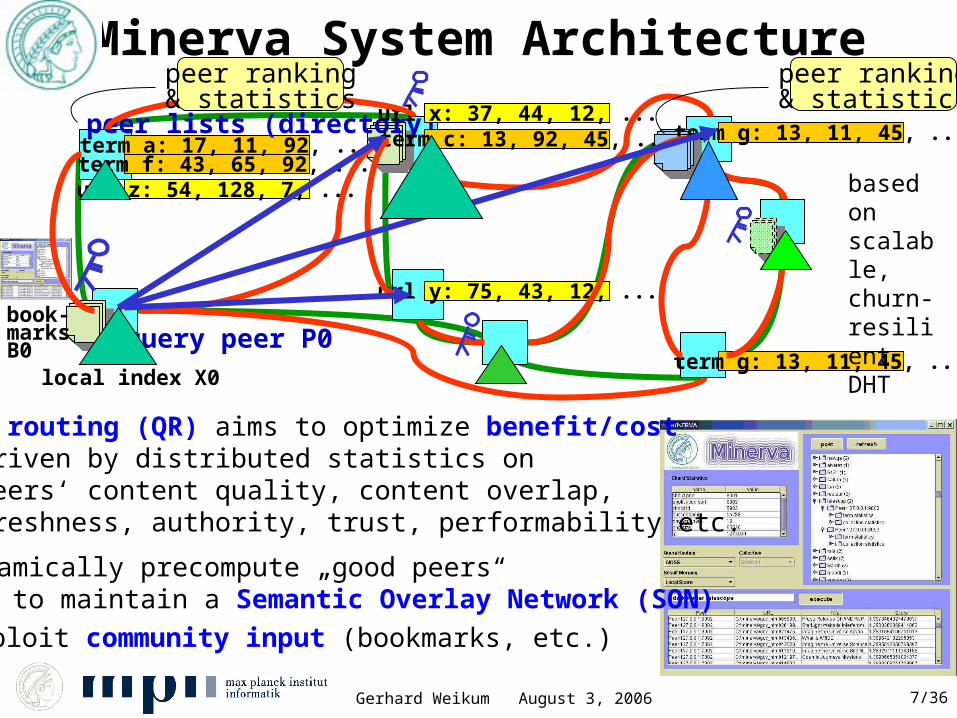
Gerhard Weikum August 3, 2006 7/36
Minerva System Architecture
book-marksB0
term g: 13, 11, 45, ...term a: 17, 11, 92, ...term f: 43, 65, 92, ...
peer lists (directory)
term g: 13, 11, 45, ...
term c: 13, 92, 45, ...url x: 37, 44, 12, ...
url y: 75, 43, 12, ...
url z: 54, 128, 7, ...
query peer P0
Query routing (QR) aims to optimize benefit/cost driven by distributed statistics on peers‘ content quality, content overlap, freshness, authority, trust, performability etc.
Dynamically precompute „good peers“ to maintain a Semantic Overlay Network (SON)
local index X0
based onscalable,churn-resilientDHT
peer ranking& statistics
peer ranking& statistics
Exploit community input (bookmarks, etc.)

Gerhard Weikum August 3, 2006 8/36
P2P Query Routing (Resource Selection)
e.g. for sim(q,Xi) use prob.-IR CORI [Callan 95] and for sim(X0, Xi) use rel. entropy
• Precompute per-term peer-quality scores & keep in directory• QR aggregates PeerLists for query terms & selects top-k peers
Principle:Select peers with highest benefit/cost ratio where
• benefit(Pi) = quality(Pi, q) ~ sim(q, Xi) + (1- ) sim (X0, Xi) • cost(Pi) ~ estimated response time or communication costs
terms x
freq( x,X 0 )KL( X 0,Xi ) : freq( x,X 0 ) log
freq( x,Xi )
Method:
Caveat:• Peer-peer similarity overfits to content quality and ignores overlap

Gerhard Weikum August 3, 2006 9/36
Overlap Awareness [Bender et al.: SIGIR’05, EDBT‘06]
Estimate overlap(p0, pj) = |X0Xj| / |X0Xj| between query initiator peer p0 and QR candidate pj
using min-wise independent permutations (MIPs) [Broder 97]on the URLs in the collections of p0 and pj (with precomputed per-term MIPs posted to directory)
Consider candidates pj in desc. order of estimated quality for qand re-rank peers by:
qt jjj ppoverlaptpqualityqpbenefit ),()1(),(),( 0
||||)|( BAABAnovelty 1),(
|)||(|),(||
BAoverlap
BABAoverlapA
Better: estimate novelty of additional pj
with jXA : and 10: j XB
and rank peers by integrated quality-novelty (IQN)

Gerhard Weikum August 3, 2006 10/36
Min-Wise Independent Permutations [Broder 97]
MIPs are unbiased estimator of overlap: P [min {h(x) | xA} = min {h(y) | yB}] = |AB| / |AB|
MIPs can be viewed as repeated sampling of x, y from A, B
set of ids
17 21 3 12 24 8
20 48 24 36 18 8
40 9 21 15 24 46
9 21 18 45 30 33
h1(x) = 7x + 3 mod 51
h2(x) = 5x + 6 mod 51
hN(x) = 3x + 9 mod 51
…
compute N randompermutations with:
…
8
9
9
N
MIPs vector:minimaof perm.
8
9
33
24
36
9
8
24
45
24
48
13
MIPs(set1)
MIPs(set2)
estimatedoverlap = 2/6
P[min{(x)|xS}=(x)] =1/|S|

Gerhard Weikum August 3, 2006 11/36
IQN Experimental Results
# queried peers
Experiment:based on 100 .Gov partitions (1.25 Mio. docs), assigned to 50 peers,with each peer holding 10 partitions and 80% overlap for peers Pi, Pi+1
with 50 TREC-2003 Web queries, e.g.: „pest safety control“ „juvenile delinquency“, „Marijuana legalization“, etc.
rela
tive
rec
all
00,10,20,30,40,50,60,70,80,9
1
overlap-awareMinerva
CORI baseline
For more experiments see our papers (Bender et al.: SIGIR’05, EDBT’06, WIRI’06)

Gerhard Weikum August 3, 2006 12/36
Discriminative Postingpeer pj posts a term only if pj has term-specific contentabove average (or above quantile) of quality measure reduces load on P2P directory may ease decision on good query routing requires global statistics on quality measures !
e.g. peer posts only if local df > *(global df) with < 1
Experiment: 250 000 Web pages on 40 peerspopular Google queries (e.g. „national hurricane center“)

Gerhard Weikum August 3, 2006 13/36
Efficiently Capturing Global Statistics
gdf (global doc. freq.) of a term is interesting key measure,• for discriminative posting or • for P2P result merging,
but overlap among peers makes simple distr. counting infeasible
hash sketches [Flajolet/Martin 85]:duplicate-sensitive cardinality estimator for multisets
• hash each multiset element x onto m-bit bitvector and remember ls 1 bit (h(x))
• maxxS (h(x)) estimates log2 0.77351 |S|
with std.dev. / |S| = • rough intuition: • average multiple iid sketches
)/1( mOkkS maxlog|| 2

Gerhard Weikum August 3, 2006 14/36
Efficient & Accurate gdf Estimation [Bender et al.: WebDB 06]
Hash sketches of different peers collected at directory peerdistributivity is free: i {(h(x)) | x Si} = {(h(x)) | x i Si}
gdf estimation algorithm:• each peer p posts hash sketch for each (discriminative) term t to directory • directory peer for term t forms union of incoming hash sketches • when a peer needs to know gdf(t), simply ask directory peer for t• sliding-window techniques for dynamic adjustment
dir(t)dir(c)
dir(d)
dir(e)
dir(f)
dir(a)
00101000c:
10110000a:
00100000t:post
post
post
00101000c:
10110000a:
00100000t:
00110000t:
00110100t:00010000t:
00010010t:
00110110t:
lookup(t.gdf)
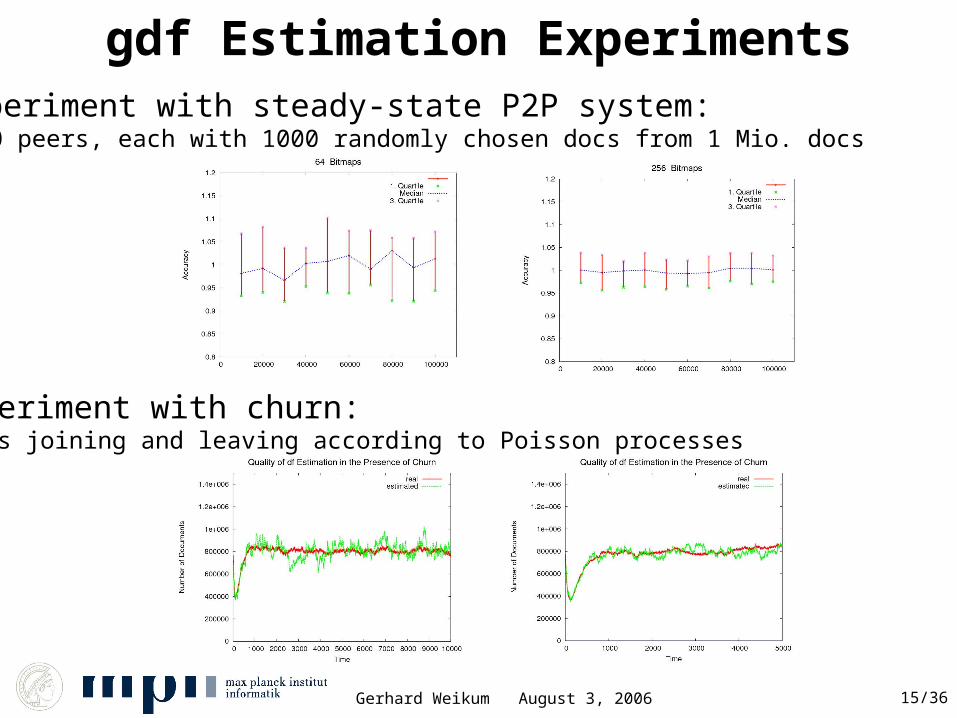
Gerhard Weikum August 3, 2006 15/36
gdf Estimation ExperimentsExperiment with steady-state P2P system:1000 peers, each with 1000 randomly chosen docs from 1 Mio. docs
Experiment with churn:Peers joining and leaving according to Poisson processes

Gerhard Weikum August 3, 2006 16/36
Outline
Motivation and Research Directions
P2P Query Routing
• P2P Link Analysis
• Conclusion
Overlap Awareness•
Discriminative Posting•
JXP Authority Scoring•
• Personalized and Community-aware RankingQRank and QReward•

Gerhard Weikum August 3, 2006 17/36
Exploit locality in Web link graph: construct block structure(disjoint graph partitioning) based on sites or domains
Distributed PageRank (PR)
Compute page PR within site/domain & site/domain weights, • combine page scores with site/domain scores [Kamvar03, Lee03, Broder04, Wang04, Wu05] or• communicate PR mass propagation across sites [Abiteboul00, Sankaralingam03, Shi03, Jelasity05]
)( )(
)(1)( qINp pout
p
Nq
Page authority important for final result scoring

Gerhard Weikum August 3, 2006 18/36
PageRank (PR) in a P2P NetworkEvery peer crawls Web fragments at its discretionand has its own local & personalized search engine overlaps between peers’ graphs may occur
Global Graph
Peer B
Peer A
Peer C

Gerhard Weikum August 3, 2006 19/36
JXP (Juxtaposed Approximate PageRank) [J.X. Parreira et al.: WebDB 05, VLDB 06]
based on Markov-chain aggregation (state lumping) [Courtois 1977, Meyer 1988; cf. Chien et al. 2004, Langville/Meyer 2005] each peer represents external, a priori unknown part of the global graph by one superstate, a „world node“
peers meet randomly• exchange their local graph fragments and PR vectors• learn about incoming edges to nodes of local graph• compute local PR on merged graphs or enhanced local graph• keep only improved PR and own local graph• don‘t keep other peers‘ graph fragments
converges to global PR (experiments + theoretical arguments)
convergence sped up by biased p2pDating strategy:prefer peers whose nodeset of outgoing links has high overlaps with our nodeset (use MIPs as synopses)

Gerhard Weikum August 3, 2006 20/36
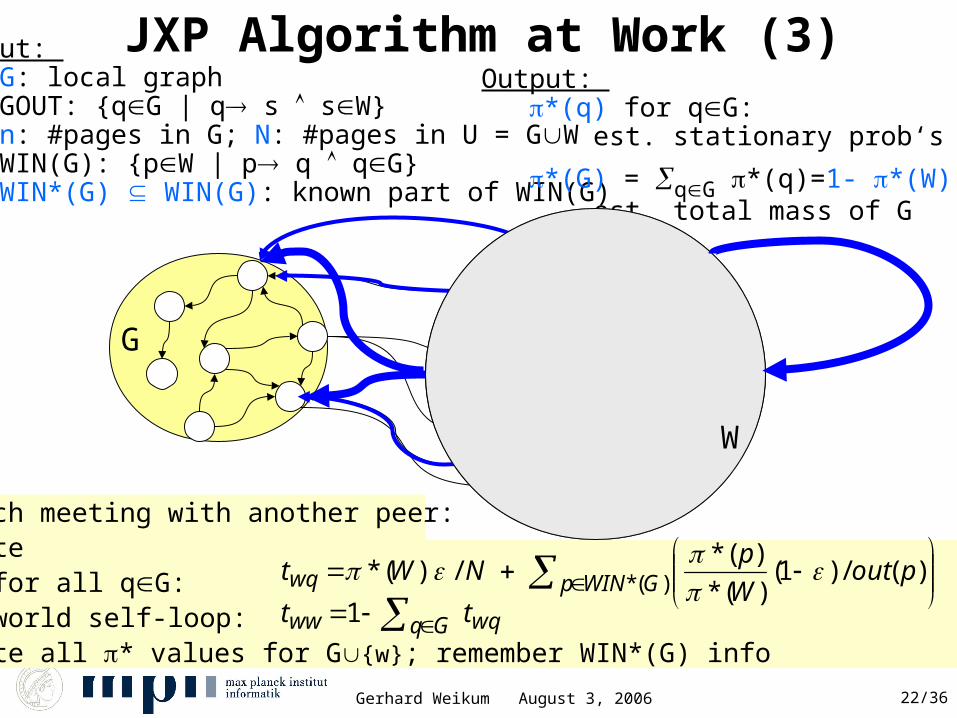
JXP Algorithm at Work (1)Input: G: local graph GOUT: {qG | q s sW}n: #pages in G; N: #pages in U = GWWIN(G): {pW | p q qG}WIN*(G) WIN(G): known part of WIN(G)
Output: *(q) for qG: est. stationary prob‘s (PR)
*(G) = qG *(q)=1- *(W) est. total mass of G
At each meeting with another peer:compute
• for all qG:• world self-loop:
compute all * values for G{w}; remember WIN*(G) info Gq wqww tt 1
)(* )(/)1(
)(*
)(*/)(* GWINpwq pout
W
pNWt
G
F
H
WW
Gq wqt1

Gerhard Weikum August 3, 2006 21/36
JXP Algorithm at Work (2)Input: G: local graph GOUT: {qG | q s sW}n: #pages in G; N: #pages in U = GWWIN(G): {pW | p q qG}WIN*(G) WIN(G): known part of WIN(G)
Output: *(q) for qG: est. stationary prob‘s (PR)
*(G) = qG *(q)=1- *(W) est. total mass of G
At each meeting with another peer:compute
• for all qG:• world self-loop:
compute all * values for G{w}; remember WIN*(G) info Gq wqww tt 1
)(* )(/)1(
)(*
)(*/)(* GWINpwq pout
W
pNWt
G
F
H
W
Gerhard Weikum August 3, 2006 22/36
JXP Algorithm at Work (3)Input: G: local graph GOUT: {qG | q s sW}n: #pages in G; N: #pages in U = GWWIN(G): {pW | p q qG}WIN*(G) WIN(G): known part of WIN(G)
Output: *(q) for qG: est. stationary prob‘s (PR)
*(G) = qG *(q)=1- *(W) est. total mass of G
At each meeting with another peer:compute
• for all qG:• world self-loop:
compute all * values for G{w}; remember WIN*(G) info Gq wqww tt 1
)(* )(/)1(
)(*
)(*/)(* GWINpwq pout
W
pNWt
G
F
H
WW

Gerhard Weikum August 3, 2006 23/36
JXP Convergence
Theorem:In a fair sequence of P2P meetings, the JXP scores of every peer converge to the global PR scores.
Proofbased on Markov-chain aggr./disaggr. theory [C.D. Meyer 1988, G.E. Cho & C.D. Meyer 1999]
• for world node w: JXP(w) is non-increasing and JXP(w) PR(w)• for nodes q in peer‘s graph fragment: JXP(q) is non-decreasing and JXP(q) PR(q)

Gerhard Weikum August 3, 2006 24/36
p2pDating
Each peer pj precomputes two MIPs synopses for• M(pj): URLs in the collection of pj (the nodes of G) and• O(pj): URLs of the out-neighbors of pages of pj (OUT(G))
repeat forever • peer pj randomly picks „blind date“ candidate pd:
• pj and pk exchange their O synopses;• they may also recommend to each other a set of friends pf
and pass on their O synopses• peer pj maintains a list of dating candidates pc ordered by resemblance (M(pj), O(pc))• peer pj chooses best candidate for next date (exchange of graphs, local PR computation, etc.)
Gerhard Weikum August 3, 2006 25/36
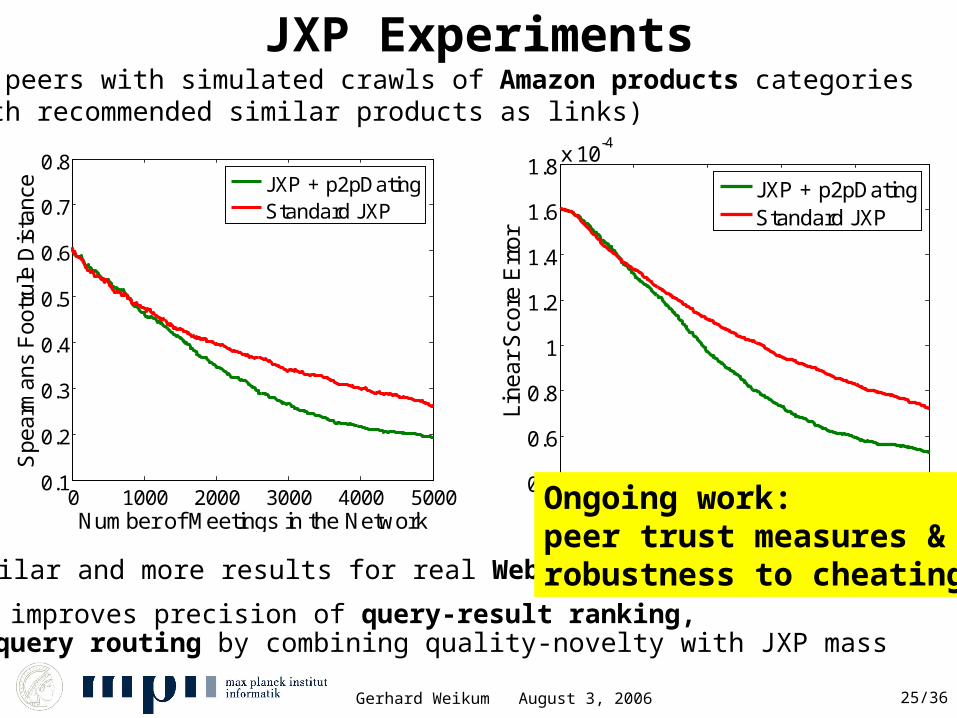
JXP Experiments
0 1000 2000 3000 4000 50000.4
0.6
0.8
1
1.2
1.4
1.6
1.8x 10
-4
Line
ar S
core
Err
orNumber of Meetings in the Network
JXP + p2pDatingStandard JXP
0 1000 2000 3000 4000 50000.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
Spe
arm
ans
Foo
trul
e D
ista
nce
Number of Meetings in the Network
JXP + p2pDatingStandard JXP
100 peers with simulated crawls of Amazon products categories(with recommended similar products as links)
similar and more results for real Web data
Ongoing work:peer trust measures &robustness to cheating
also improves precision of query-result ranking,and query routing by combining quality-novelty with JXP mass

Gerhard Weikum August 3, 2006 26/36
Outline
Motivation and Research Directions
P2P Query Routing
P2P Link Analysis
• Conclusion
Overlap Awareness•
Discriminative Posting•
JXP Authority Scoring•
• Personalized and Community-aware RankingQRank and QReward•
Gerhard Weikum August 3, 2006 27/36
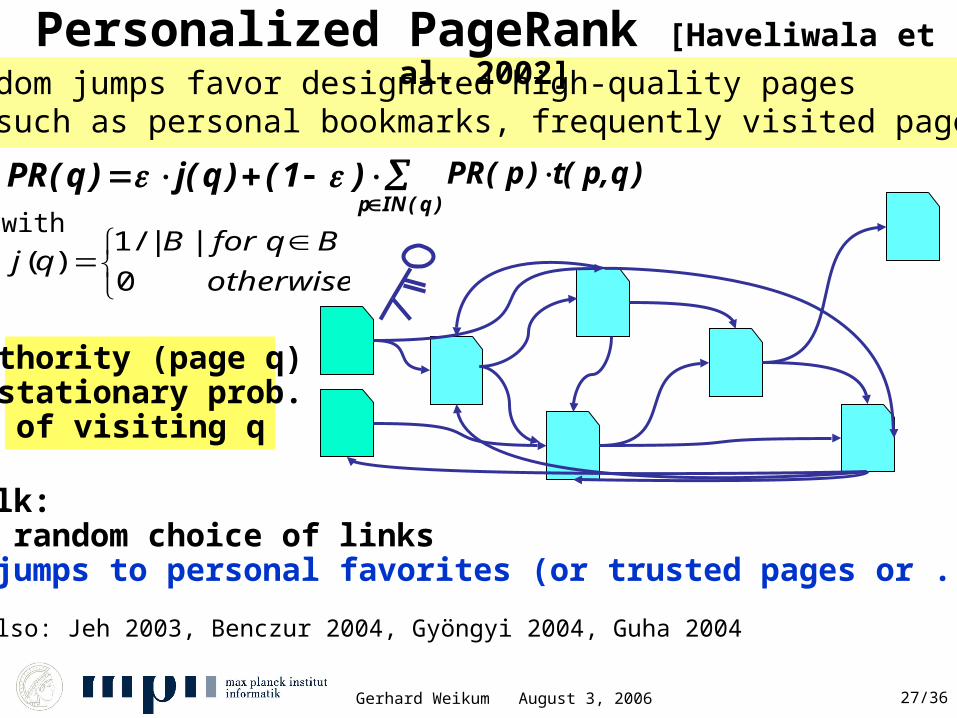
Personalized PageRank [Haveliwala et al. 2002]
random walk: uniformly random choice of links + biased jumps to personal favorites (or trusted pages or ...)
PR( q ) j( q ) ( 1 ) p IN ( q )
PR( p ) t( p,q )
Idea: random jumps favor designated high-quality pages such as personal bookmarks, frequently visited pages, etc.
with
otherwise
BqforBqj
0
||/1)(
Authority (page q) = stationary prob. of visiting q
see also: Jeh 2003, Benczur 2004, Gyöngyi 2004, Guha 2004

Gerhard Weikum August 3, 2006 28/36
from PageRank: uniformly random choice of links + random jumpsto QRank: + query-doc transitions + query-query transitions + doc-doc transitions on implicit links (w/ thesaurus)with probabilities estimated from log statistics
max planckgesellschaft
maxplanck mpg
budget
PR( q ) j( q ) ( 1 )
p IN ( q )PR( p ) t( p,q )
QR( q ) j( q ) ( 1 )
p exp licitIN ( q )PR( p ) t( p,q )
p implicitIN ( q )
( 1 ) PR( p ) sim( p,q )
Exploiting Query Logs and Click Streams[J. Luxenburger et al.: WISE 04]
J.K.
J.K.
MPII MPII

Gerhard Weikum August 3, 2006 29/36
Setup:70 000 Wikipedia docs, 18 volunteers posing Trivial-Pursuit queriesca. 500 queries, ca. 300 refinements, ca. 1000 positive clicksca. 15 000 implicit links based on doc-doc similarity
Results (assessment by blind-test users):• QRank top-10 result preferred over PageRank in 81% of all cases• QRank has 50.3% precision@10, PageRank has 33.9%
Untrained example query „philosophy“:
PageRank QRank x
1. Philosophy Philosophy2. GNU free doc. license GNU free doc. license3. Free software foundation Early modern philosophy4. Richard Stallman Mysticism5. Debian Aristotle
Small-Scale Experiments

Gerhard Weikum August 3, 2006 30/36
Negative Feedback & AssessmentUsers give implicit or explicit negative assessments:
• non-clicked query results ranked higher than clicked ones• encountered spam pages or personally disliked pages• ratings of pages or other users in social tagging networks
very valuable human input, but typically sparse
Approaches and problems using biased random walks for quality&trust propagation [Eiron 2004, Guha 2004, Luxenburger 2006]:
• penalize neg. pages by reducing their random-jump prob.• source-specific random-jump prob‘s and self-loops• force backward step or random jump when reaching neg. page
but probabilities are non-negative and L1-normalized ranking models become technically convoluted
Better approach:decouple random walk from trust propagation Markov reward models

Gerhard Weikum August 3, 2006 31/36
Markov Reward Modelsdiscrete-time or continuous-time Markov chain with
• state-specific lump reward rj R whenever j is entered• transition-specific lump reward rij R when ij is traversed(plus reward rates in CTMC case)
penalties expressed as negative rewards
analysis of transient and stationary properties(used in queueing and performability models textbooks by H.C. Tijms, R.W. Wolff; surveys by Haverkort/Trivedi)
ijijn
ii
nj
nj rpgg )1()1()( gained reward until step n:
)(1lim n
jnj gn
g long-run average reward:

Gerhard Weikum August 3, 2006 32/36
QReward Ranking [J. Luxenburger et al.: WebDB 06]
• Add queries and users as nodes to the state graph and connect to clicked, non-clicked, rated pages
• Perform random walk in standard way, using links and random jumps, yielding stationary prob‘s j
• Compute long-run average reward gj for each state j
• Associate transition-specific lump rewards+1 for each positive assessment-1 for each negative assessment 0 otherwise
• Quality of page j := gj + (1 ) j
++
++ ++
+

Gerhard Weikum August 3, 2006 33/36
Fast Computation of QReward
Renewal-Reward Theorem (Wolff p. 60):
)(
)(1lim
jINi ijiijn
jnj prgn
g
Compute j values as usual by power iteration (using QRank)
but we need sufficient accuracy for all i,not just for the high-ranked ones
iterate QRank for j, QReward, and quality score; stop when quality scores of top pages converge

Gerhard Weikum August 3, 2006 34/36
Setup:70 000 Wikipedia docs, 18 volunteers posing queriesca. 500 queries, ca. 300 refinements, ca. 1000 positive clicks,ca. 2000 implict negative assessments (cf. Joachims et al.: SIGIR 05)
Results (based on relevance majority votes of 3 users):• PR has MAP 0.45 for top-15 of 14 test queries, • QRank has MAP 0.51, QReward has MAP 0.56
Example query „political system China“:
PageRank QReward x
1. China One country, two systems2. People‘s Republic of China China3. List of countries Party discipline4. Country List of countries5. Chinese language Communist state
Preliminary Experiments
Ongoing work:combine with personalized LMs;trust models;larger-scale experimentation

Gerhard Weikum August 3, 2006 35/36
Outline
Motivation and Research Directions
P2P Query Routing
P2P Link Analysis
• Conclusion
Overlap Awareness•
Discriminative Posting•
JXP Authority Scoring•
Personalized and Community-aware RankingQRank and QReward•

Gerhard Weikum August 3, 2006 36/36
Conclusion: Challenges Remain Open
• Distributed Statistics Management• Key to Query Routing, Quality/Overlap Estimation, Ranking (PR etc.)• Capturing Global Statistics in Decentralized Manner• Efficiently Disseminating Statistical Synopses
• Experimental Evaluation• Benchmarking Methodology • Large-scale P2P Testbed • Capturing User/Community Behavior
• Robustness to Churn and Cheating
• „Statistically Semantic & Social“ Overlay Networks


















