
Database Recovery – Heisenbugs, Houdini’s Tricks, and the Paranoia of Science Gerhard Weikum...
44
Database Recovery – Heisenbugs, Houdini’s Tricks, and the Paranoia of Science Gerhard Weikum [email protected] http://www-dbs.cs.uni-sb.de (Rationale, State of the Art, and Research Directions) What and Why? Correct Undo Where and How? Correct and Efficient Redo Quantitative Guarantees • • • • • Outline:
-
Upload
jared-martin -
Category
Documents
-
view
216 -
download
0
Transcript of Database Recovery – Heisenbugs, Houdini’s Tricks, and the Paranoia of Science Gerhard Weikum...

Database Recovery – Heisenbugs, Houdini’s Tricks,
and the Paranoia of Science
Gerhard [email protected]
http://www-dbs.cs.uni-sb.de
(Rationale, State of the Art,and Research Directions)
What and Why?
Correct Undo
Where and How?
Correct and Efficient Redo
Quantitative Guarantees
•••••
Outline:

Why This Topic?
exotic and underrated•fits well with theme of graduate studies program•critical for dependable Internet-based E-services•I wrote a textbook on the topic•Paranoia of science:hope (and strive) for the best, but prepare for the worst
•
„All hardware and software systems must be verified.“(Wolfgang Paul, U Saarland)
„Software testing (and verification) doesn‘t scale.“(James Hamilton, MS and Ex-IBM)
„If you can‘t make a problem go away, make it invisible.“(David Patterson, UC Berkeley) Recovery Oriented Computing
Recovery: repair data after software failures

Why Exactly is Recovery Needed?Database Cache
Log Buffer
Stable Database
Stable Log
VolatileMemory
StableStorage
page qpage q
page ppage p
page ppage p
page qpage q
155
155
88
219
215
page z page z 217
write(b,t1)...
page zpage z158
216 write(q,t2)
217 write(z,t1)
218 commit(t2)
219 write(q,t1)
220 begin(t3) nil
page bpage b215
page bpage b215
fetch flush force
Atomic transactions(consistent state transitions on db)
Log entries:• physical (before- and after-images)• logical (record ops)• physiological (page transitions)timestamped by LSNs

How Does Recovery Work?• Analysis pass: determine winners vs. losers (by scanning the stable log)• Redo pass: redo winner writes (by applying logged op)• Undo pass: undo loser writes (by applying inverse op)
Stable Database
Stable Log
page qpage q
page ppage p155
88
215 write(b,t1)...
page zpage z158
208
216 write(q,t2) 199
217 write(z,t1) 215
218 commit(t2) page bpage b
215
losers: {t1}, winners: {t2}redo(216, write(q,t2) )undo (215, write(b,t1) )
LSN in page headerimplementstestable state
217 write(z,t1) page qpage q216
page bpage b214
216 write(q,t2)
215 write(b,t1)
undo (217, write(z,t1) ) ?

Heisenbugs and the Recovery Rationale
„Self-healing“ recovery =amnesia + data repair (from „trusted“ store) + re-init
Failure causes:• power: 2 000 h MTTF or with UPS• chips: 100 000 h MTTF• system software: 200 – 1 000 h MTTF • telecomm lines: 4 000 h MTTF• admin error: ??? or with auto-admin• disks: 800 000 h MTTF• environment: > 20 000 h MTTF
Transient software failures are the main problem: Heisenbugs(non-repeatableexceptions caused bystochastic confluenceof very rare events)
Failure model for crash recovery:• fail-stop (no dynamic salvation/resurrection code)• soft failures (stable storage survives)

Goal: Continuous AvailabilityBusiness apps and e-services demand 24 x 7 availability
99.999 availability would be acceptable (5 min outage/year)
down
1 / M
TT
F 1 / MT
TR
upDowntime costs (per hour): Brokerage operations: $ 6.4 Mio.Credit card authorization: $ 2.6 Mio.Ebay: $ 225 000Amazon: $ 180 000Airline reservation: $ 89 000Cell phone activation: $ 41 000
(Source: Internet Week 4/3/2000)
State of the art:DB servers 99.99 to 99.999 %Internet e-service (e.g., Ebay) 99 %
Stationary availability =
MTTRMTTFMTTF

What Do We Need to Optimize for?
Correctness (and simplicity)in the presence of many subtleties
•
Fast restart (for high availability)by bounding the log andminimizing page fetches
•
Low overhead during normal operation by minimizing forced log writes (and page flushes)
•
High transaction concurrencyduring normal operation
•Tradeoffs &Tensions

State of the Art: Houdini’s Trickstricks, patents, and recovery gurus:
very little work on verification of (toy) algorithms:• C. Wallace / N. Soparkar / Y. Gurevich• D. Kuo / A. Fekete / N. Lynch• C. Martin / K. Ramamritham

Outline
What and Why?
Correct Undo
••
Where and How?•
Correct and Efficient Redo
Quantitative Guarantees •
Murphy‘s Law: Whatever can go wrong, will go wrong.

Data Structures for Logging & Recoverytype Page: record of PageNo: id; PageSeqNo: id; Status: (clean, dirty); Contents: array [PageSize] of char; end;persistent var StableDatabase: set[PageNo] of Page;var DatabaseCache: set[PageNo] of Page;type LogEntry: record of LogSeqNo: id; TransId: id; PageNo: id; ActionType:(write, full-write, begin, commit, rollback); UndoInfo: array of char; RedoInfo: array of char; PreviousSeqNo: id; end;persistent var StableLog: list[LogSeqNo] of LogEntry;var LogBuffer: list[LogSeqNo] of LogEntry;
modeled in functional manner with test op state:
write s on page p StableDatabase StableDatabase[p].PageSeqNo s
write s on page p CachedDatabase ( ( p DatabaseCache DatabaseCache[p].PageSeqNo s ) ( p DatabaseCache StableDatabase[p].PageSeqNo s ) )

Correctness Criterion
A crash recovery algorithm is correct if it guarantees that, after a system failure, the cached database will eventually beequivalent (i.e., reducible) to a serial order of the committed transactions that coincides with the serialization order of the history.

Simple Redo Passredo pass ( ):min := LogSeqNo of oldest log entry in StableLog;max := LogSeqNo of most recent log entry in StableLog;for i := min to max do if StableLog[i].TransId not in losers then pageno = StableLog[i].PageNo; fetch (pageno); case StableLog[i].ActionType of full-write: full-write (pageno) with contents from StableLog[i].RedoInfo; write: if DatabaseCache[pageno].PageSeqNo < i then read and write (pageno) according to StableLog[i].RedoInfo; DatabaseCache[pageno].PageSeqNo := i; end /*if*/; end /*case*/;end /*for*/;

Correctness of Simple Redo & UndoInvariants during redo pass (compatible with serialization):
processedbeenhaves'sall:StableLogs :StableLogottransppages sowinnerstppageid.ottransid.o
CachedDbo
Invariant of undo pass(based on serializability / reducibility of history):
:StableLogs processedbeenhaves'swithStableLog'sall losers
:StableLogottransppages soloserstppageid.ottransid.o
CachedDbo
StableDboStableLogo:CachedDbo

Redo Optimization 1: Log Truncation & Checkpoints
continuously advance the log begin (garbage collection):for redo, can drop all entries for page p that precede the last flush action for p =: RedoLSN (p) SystemRedoLSN := min{RedoLSN (p) | dirty page p}
track dirty cache pages and periodically write DirtyPageTable (DPT) into checkpoint log entry: type DPTEntry: record of PageNo: id; RedoSeqNo: id; end; var DirtyPages: set[PageNo] of DPTEntry;+ add potentially dirty pages during analysis pass
+ flush-behind demon flushes dirty pages in background

Redo Pass with CP and DPTredo pass ( ):cp := MasterRecord.LastCP;SystemRedoLSN := min{cp.DirtyPages[p].RedoSeqNo};max := LogSeqNo of most recent log entry in StableLog;for i := SystemRedoLSN to max do if StableLog[i].ActionType = write or full-write and StableLog[i].TransId not in losers then pageno := StableLog[i].PageNo; if pageno in DirtyPages and i >= DirtyPages[pageno].RedoSeqNo then fetch (pageno); if DatabaseCache[pageno].PageSeqNo < i then read and write (pageno) according to StableLog[i].RedoInfo; DatabaseCache[pageno].PageSeqNo := i; else DirtyPages[pageno].RedoSeqNo := DatabaseCache[pageno].PageSeqNo + 1;end; end; end;
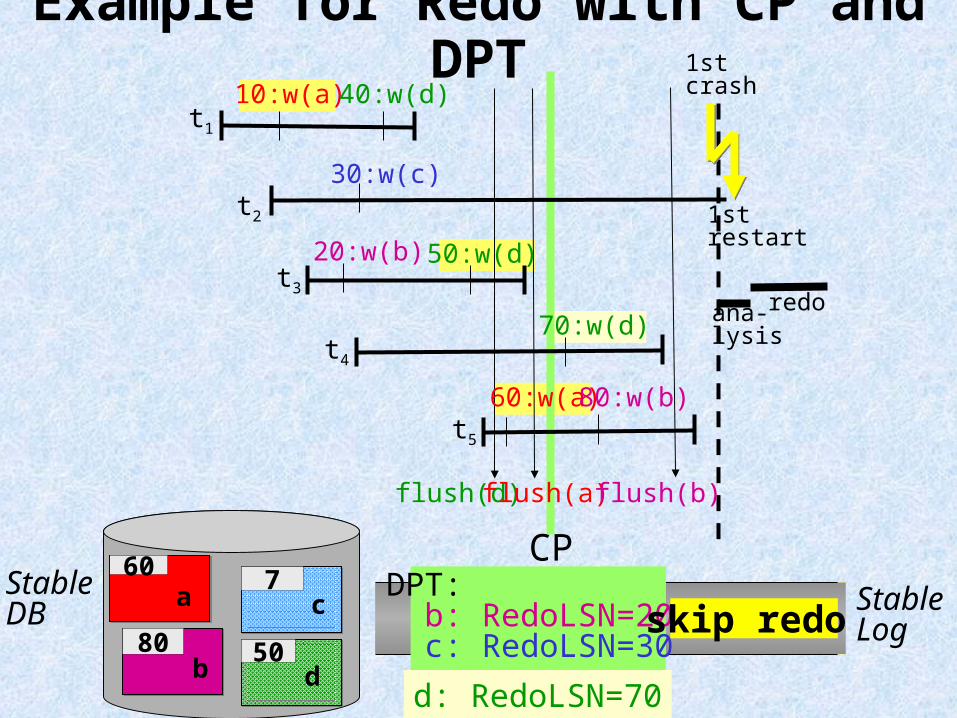
Example for Redo with CP and DPT1st crash
ana-lysis
redo
t1
t2
t3
t4
t5
flush(d) flush(a)
1st restart
10:w(a)
20:w(b)
30:w(c)
40:w(d)
50:w(d)
60:w(a)
70:w(d)
80:w(b)
flush(b)
80
7
50
60
b
a c
d
Stable DB Stable
Log
DPT: b: RedoLSN=20 c: RedoLSN=30
CP
d: RedoLSN=70
skip redo

Benefits of Redo Optimization• can save page fetches• can plan prefetching schedule for dirty pages (order and timing of page fetches)
• for minization of disk-arm seek time• and rotational latency
seek opt.: rot. opt.:
global opt.:TSP based on tseek + trot

Redo Optimization 2: Flush Log Entriesduring normal operation: log flush actions (without forcing the log buffer)during analysis pass of restart: construct more recent DPTanalysis pass ( ) returns losers, DirtyPages:...if StableLog[i].ActionType = write or full-write and StableLog[i].PageNo not in DirtyPages then DirtyPages += StableLog[i].PageNo; DirtyPages[StableLog[i].PageNo].RedoSeqNo := i; end;if StableLog[i].ActionType = flush then DirtyPages -= StableLog[i].PageNo; end;...
can save many page fetches allows better prefetch scheduling
advantages:

Example for Redo with Flush Log Entries1st crash
ana-lysis
redo
t1
t2
t3
t4
t5
flush(d) flush(a)
1st restart
10:w(a)
20:w(b)
30:w(c)
40:w(d)
50:w(d)
60:w(a)
70:w(d)
80:w(b)
flush(b)
80
7
50
60
b
a c
d
Stable DB Stable
Log
DPT: b: RedoLSN=20 c: RedoLSN=30
CP
d: RedoLSN=70
skip redo

Redo Optimization 3: Full-write Log Entries
during normal operation: „occasionally“ log full after-image of a page p (absorbs all previous writes to that page)during analysis pass of restart: construct enhanced DPT DirtyPages[p].RedoSeqNo := LogSeqNo of full-writeduring redo pass of restart: can ignore all log entries of a page that precede its most recent full-write log entry
can skip many log entries can plan better schedule for page fetches allows better log truncation
advantages:

Correctness of Optimized Redo
Invariant during optimized redo pass:
:logstableo:ppages
doSeqNoRe].p[DirtyPagesoDirtyPagesp doSeqNoRe].p[DirtyPagesoDirtyPagesp
ppageid.o doSeqNoRe].p[DirtyPagesoDirtyPagesp
StableDBo
builds on correct DPT construction during analysis pass

•
•
Why is Page-based Redo Logging Good Anyway?
much faster than logical redo logical redo would require replaying high-level operations with many page fetches (random IO)
can be applied to selective pages independently
can exploit perfectly scalable parallelism for redo of large multi-disk db
can efficiently reconstruct corrupted pages when disk tracks have errors (without full media recovery for entire db)
• testable state with very low overhead

Outline
What and Why?
Correct Undo •
Where and How?•
Correct and Efficient Redo
Quantitative Guarantees •
Corollary to Murphy‘s Law: Murphy was an optimist.

Winners Follow Losers crash
t1
10:w(a)
t2
20:w(a)
t3
30:w(a)
t4
50:w(a)40:w(b)
rollback
restartcomplete
t5
60:w(a)
occurs because of:• rollbacks during normal operation• repeated crashes• soft crashes between backup and media failure• concurrency control with commutative ops on same page

Winners Follow Losers
2a redo (10: w(a) , t1)
crash
t1
10:w(a)
t2
20:w(a)
t3
30:w(a)
t4
50:w(a)40:w(b)
rollback
restartcomplete
t5
60:w(a)
Problems:• old losers prevent log truncation• LSN-based testable state infeasible
2a
10a redo (30: w(a) , t3)
30a redo (60: w(a) , t5)
60a undo (50: w(a) , t4)
49a
49a

10:w(a)
20:w(a)
30:w(a)
50:w(a)40:w(b) 60:w(a)
Treat Completed Losers as Winnersand Redo History
t1
t2
t3
t4t5
Solution:• Undo generates compensation log entries (CLEs)• Undo steps are redone during restart
25:w-1(a)
55:w-1(a)
57:w-1(b)

CLE Backward Chaining forBounded Log Growth (& More Goodies)
... 40:w(b)
50:w(a)
t1
10:w(a)
t2
20:w(a)
t3
30:w(a)
t4
50:w(a)40:w(b)
25:w-1(a)
55:w-1(a)
57:w-1(b)
CLE55:w-1(a)
CLE57:w-1(b)
committ4
begint4
CLE points to predecessorof inverted write

CLE Backward Chaining forBounded Log Growth (& More Goodies)
... 40:w(b)
50:w(a)
t1
10:w(a)
t2
20:w(a)
t3
30:w(a)
t4
50:w(a)40:w(b)
25:w-1(a)
55:w-1(a)
CLE55:w-1(a)
begint4
CLE points to predecessorof inverted write

Undo Algorithm...while exists t in losers with losers[t].LastSeqNo <> nil do nexttrans = TransNo in losers such that losers[nexttrans].LastSeqNo = max {losers[x].LastSeqNo | x in losers}; nextentry := losers[nexttrans].LastSeqNo;
case StableLog[nextentry].ActionType of compensation: losers[nexttrans].LastSeqNo := StableLog[nextentry].NextUndoSeqNo; write: ... newentry.LogSeqNo := new sequence number; newentry.ActionType := compensation; newentry.PreviousSeqNo := ActiveTrans[transid].LastSeqNo; newentry.NextUndoSeqNo := nextentry.PreviousSeqNo; ActiveTrans[transid].LastSeqNo := newentry.LogSeqNo; LogBuffer += newentry; ...

Correctness of Undo PassInvariant of undo pass(assuming tree reducibility of history):
:loserstStableLogs LastSeqNo).t(sActiveTrans
:StableLogotTransId.o(
qNoNextUndoSe].t[sActiveTranalongreachableiso( ))CachedDbo

Outline
What and Why?
Correct Undo
Where and How?•
Correct and Efficient Redo
Quantitative Guarantees •
There are three kinds of lies:lies, damned lies, and statistics. (Benjamin Disraeli)
97.3 % of all statistics are made up. (Anonymous)

Towards Quantitative Guarantees
Online control for given system configuration:
• observe length of stable log and dirty page fraction
• estimate redo time based on observations
• take countermeasures if redo time becomes too long (log truncation, flush-behind demon priority)
Planning of system configuration:
• (stochastically) predict (worst-case) redo time as a function of workload and system characteristics
• configure system (cache size, caching policy, #disks, flush-behind demon, etc.) to guarantee upper bound

Key Factors for Bounded Redo Time
page 1
tin cache & dirty
in cache & clean
not in cache
page 2
page 3
page 4
checkpoint crash
write access
1) # dirty pages # db I/Os for redo
log scan time2) longest dirty lifetime
# redo steps3) # log entries for dirty pages
at crash time

Analysis of DB Page Fetches During Redo
N pages with:reference prob. 1 ... N (i i+1)write prob. 1 ... N
flush-behind demon I/O rate f
cache residence prob. c1 ... cN
per page Markov model: 1:out 2:clean 3:dirty
page reference arrival rate per disk I/O rate disk
p33=ci (1-fi)
p32=ci fi
p31=(1-ci)
p21=(1-ci)
p11=(1-ci)p12=ci p23=ci i
P[flush in time 1/]: f1 ... fN
p22=ci (1-i)
solve stationary equations: di := P[page i is dirty]
= 3
j
jkjk pk,j {1,2,3}1
kk
N
iid]pagesdirty[#E
1
m
i
N
miii )d(d]mpagesdirty[#P
1 11 with pages permuted
such that di di+1
:)d(g

Subproblem: Analysis of Cache Residence
timenow
3 2 13221323
bK
with LRU-K cache replacement (e.g., K=2) and cache size M:
]WwindowintimesKreferencedpagesdistinct[E:)W(P
jWi
ji
n
i
W
Kjj
W )(
11
}M)W(P|Wmin{:)M(P:W~ 1
]cacheinresidesipage[P:ci jW~
ij
iW~
Kj jW~ )(
1
][:)( hitcacheisreferencePMH
n
iiic
1
N pages with:reference prob. 1 ... N (i i+1)write prob. 1 ... N
cache residence prob. c1 ... cN

Subproblem: Analysis of Flush Prob.
t
requestarrivals
requestdepartures
exhaustive-service vacations: whenever disk queue is empty invoke flush-behind demon for time period T
M/G/1 vacation server model for each disk
response time Rvacation
time T
service time S
wait time
Laplace transforms (see Takagi 1991):
)(L)(
Te
)(Lservdiskdisk
T
wait
11
)(L)(L)(L servwaitresp
with utilizationT]S[E
]S[E
]S[E ff
1 /i
feM
f 1
1
choose max. T s.t.
0)(Leinf]tR[P R
t(Chernoff bound)
(e.g., t=10ms, =0.05)
response time R

So What?
predictability of workload configuration performance !!! !!! ???
e.g.: timeredodisks#,T,M,,
allows us to auto-tune system for workload configuration performance goals !!! ??? !!!
timeresponse

Outline
What and Why?
Correct Undo
Where and How?•
Correct and Efficient Redo
Quantitative Guarantees
More than any time in history mankind faces a crossroads. One path leads to despair and utter hopelessness, the other to total extinction.Let us pray that we have the wisdom to choose correctly. (Woody Allen)

Where Can We Contribute?
turn sketch of correctness reasoninginto verified recovery code
turn sketch of restart time analysisinto quality guarantee
address all other aspects of recovery
•
•
•
bigger picture of dependability and quality guarantees•

L1LogRecMaster *InitL1LogIOMgr (Segment *logsegment,int LogSize,int LogPageSize,int newlog) { L1LogRecMaster *recmgr = NULL; BitVector p = 1; int i; NEW (recmgr, 1); recmgr->Log = logsegment; A_LATCH_INIT (&(recmgr->BufferLatch)); A_LATCH_INIT (&(recmgr->UsedListLatch)); A_LATCH_INIT (&(recmgr->FixCountLatch)); recmgr->FixCount = 0; recmgr->StoreCounter = 0; recmgr->PendCount = 0; A_SEM_INIT (&(recmgr->PendSem),0); NEW (recmgr->Frame,BUFFSIZE); recmgr->Frame[0] = (LogPageCB *)MALLOC (LogPageSize * BUFFSIZE); for (i = 1;i < BUFFSIZE;i++) recmgr->Frame[i] = (LogPageCB *)(((char*)recmgr->Frame[i - 1]) + LogPageSize); recmgr->InfoPage = (InfoPageCB *) MALLOC (LogPageSize); recmgr->UsedList = InitHash (HASHSIZE, HashPageNo, NULL, NULL, ComparePageNo, 4); recmgr->ErasedFragList = InitHash (HASHSIZE, HashPageNo,NULL,NULL,ComparePageNo, 4); for (i = 0; i < sizeof(BitVector) * 8; i++) { recmgr->Mask[i] = p; p = p * 2; } if (newlog) { recmgr->InfoPage->LogSize = LogSize; recmgr->InfoPage->PageSize = LogPageSize; recmgr->InfoPage->Key = 0; recmgr->InfoPage->ActLogPos = 1; recmgr->InfoPage->ActBufNr = 0; recmgr->InfoPage->ActSlotNr = 0; InitLogFile (recmgr,logsegment); LogIOWriteInfoPage (recmgr); } else ReadInfoPage (recmgr);
return (recmgr);
} /* end LogIOInit */

static int log_fill(dblp, lsn, addr, len) DB_LOG *dblp; DB_LSN *lsn; void *addr; u_int32_t len; {...while (len > 0) { /* Copy out the data. */ if (lp->b_off == 0) lp->f_lsn = *lsn; if (lp->b_off == 0 && len >= bsize) { nrec = len / bsize;
if ((ret = __log_write(dblp, addr, nrec*bsize)) != 0) return (ret);addr = (u_int8_t *)addr + nrec * bsize;len -= nrec * bsize;++lp->stat.st_wcount_fill;continue;
} /* Figure out how many bytes we can copy this time. */ remain = bsize - lp->b_off; nw = remain > len ? len : remain; memcpy(dblp->bufp + lp->b_off, addr, nw); addr = (u_int8_t *)addr + nw; len -= nw; lp->b_off += nw; /* If we fill the buffer, flush it. */ if (lp->b_off == bsize) { if ((ret = __log_write(dblp, dblp->bufp, bsize)) != 0) return (ret); lp->b_off = 0; ++lp->stat.st_wcount_fill; }}return (0);}

Where Can We Contribute?
turn sketch of correctness reasoninginto verified recovery code
turn sketch of restart time analysisinto quality guarantee
address all other aspects of recovery
•
•
•
bigger picture of dependability and quality guarantees•

•
•
•
•
•
What Else is in the Jungle?more optimizations for logging andrecovery of specific data structures (e.g., B+ tree indexes)
incremental restart (early admission of new transactions while redo or undo is still in progress)
failover recovery for clusters with shared disks and distributed memory
media recovery, remote replication, and configuration for availability goals M. Gillmann
process and message recovery for failure maskingto applications and users G. Shegalov collab with MSR

Where Can We Contribute?
turn sketch of correctness reasoninginto verified recovery code
turn sketch of restart time analysisinto quality guarantee
address all other aspects of recovery
•
•
•
sw engineering sw engineering for verification
sys architecture sys architecture for predictability
••
bigger picture of dependability and quality guarantees•


















