
Frank Vahid, UC Riverside 1 System-on-a-Chip Platform Tuning for Embedded Systems Frank Vahid...
37
Frank Vahid, UC Riverside 1 System-on-a-Chip Platform Tuning for Embedded Systems Frank Vahid Associate Professor Dept. of Computer Science and Engineering University of California, Riverside Also with the Center for Embedded Computer Systems at UC Irvine http://www.cs.ucr.edu/~vahid This research has been supported by the National Science Foundation, NEC, Trimedia, and Triscend
-
date post
20-Dec-2015 -
Category
Documents
-
view
231 -
download
0
Transcript of Frank Vahid, UC Riverside 1 System-on-a-Chip Platform Tuning for Embedded Systems Frank Vahid...

Frank Vahid, UC Riverside
1
System-on-a-Chip Platform Tuning for Embedded Systems
Frank VahidAssociate Professor
Dept. of Computer Science and EngineeringUniversity of California, Riverside
Also with the Center for Embedded Computer Systems at UC Irvine
http://www.cs.ucr.edu/~vahid
This research has been supported by the National Science Foundation, NEC, Trimedia, and Triscend

Frank Vahid, UC Riverside 2
How Much is Enough?

Frank Vahid, UC Riverside 3
How Much is Enough?
Perhaps a bit small

Frank Vahid, UC Riverside 4
How Much is Enough?
Reasonably sized

Frank Vahid, UC Riverside 5
How Much is Enough?
Probably plenty big

Frank Vahid, UC Riverside 6
How Much is Enough?
More than typically necessary

Frank Vahid, UC Riverside 7
How Much is Enough?
Very few people could use this

Frank Vahid, UC Riverside 8
How Much is Enough for an IC?
1993: ~ 1 million logic transistors
IC package IC
Perhaps a bit small

Frank Vahid, UC Riverside 9
How Much is Enough for an IC?
1996: ~ 5-8 million logic transistors
Reasonably sized

Frank Vahid, UC Riverside 10
How Much is Enough for an IC?
1999: ~ 10-50 million logic transistors
Probably plenty big

Frank Vahid, UC Riverside 11
How Much is Enough for an IC?
2002: ~ 100-200 million logic transistors
More than typically necessary

Frank Vahid, UC Riverside 12
How Much is Enough for an IC?
2008: >1 BILLION logic transistors
1993: 1 M
Perhaps very few people could design this
Point of diminishing returns
8-bit uC: ~15K 32-bit ARM: ~30K MPEG dcd: ~1M 100M good enough
for audio/video/etc.? Other examples
Fast cars (> 100 mph)
High res digital cameras (> 4M)
Disk space Even IC
performance

Frank Vahid, UC Riverside 13
Very Few Companies Can Design High-End ICs
Designer productivity growing at slower rate 1981: 100 designer months ~$1M 2002: 30,000 designer months ~$300M
10,000
1,000
100
10
1
0.1
0.01
0.001
Logic transistors per chip
(in millions)
100,000
10,000
1000
100
10
1
0.1
0.01
Productivity(K) Trans./Staff-Mo.
1981
1983
1985
1987
1989
1991
1993
1995
1997
1999
2001
2003
2005
2007
2009
IC capacity
productivity
Gap
Design productivity gap
Source: ITRS’99

Frank Vahid, UC Riverside 14
Meanwhile, ICs Themselves are Costlier
And take longer to fabricate While market windows are shrinking Less than 1,000 out of 10,000 ASIC designs
have volumes to justify fabrication in 0.13 micron
Tech: 0.8 0.35 0.18 0.13
NRE: $40k $100k $350k $1,000k
Turnaround 42 days 49 days 56 days 76 days
Market: $3.5B $6B $12B $18BSource: DAC’01 panel on embedded programmable logic

Frank Vahid, UC Riverside 15
Summarizing So Far...
* Transistors are less scarce
• ICs are big enough, fast enough
* ICs take more time and money to design and fabricate
• While market windows are shrinking
Buy pre-fabricated system-level ICs: platforms
Designers
Frank Vahid, UC Riverside 16
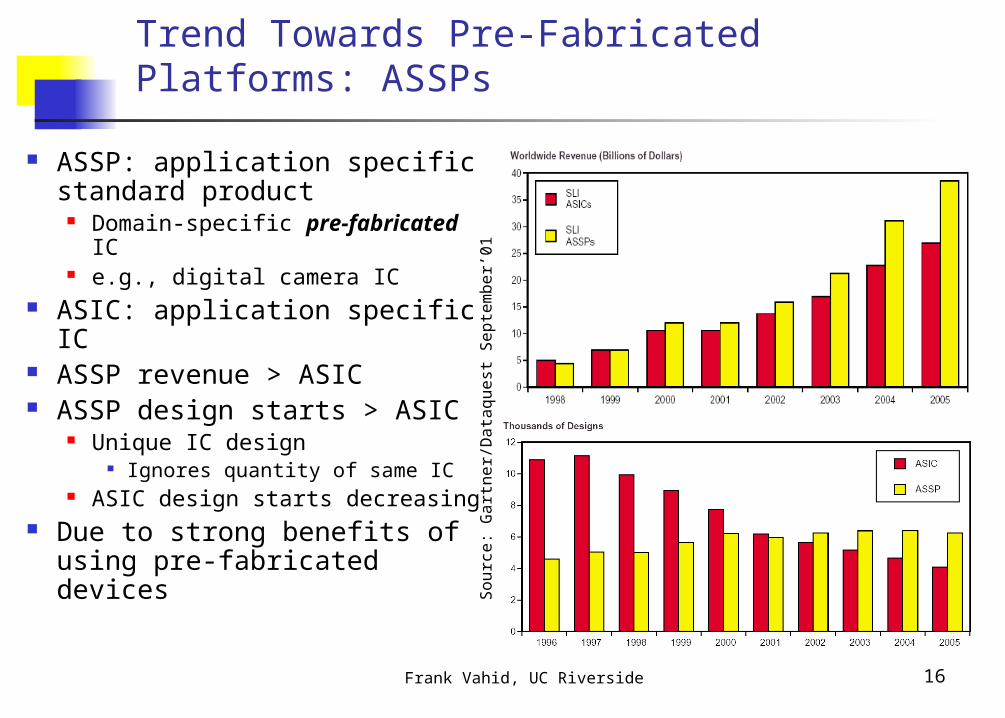
Trend Towards Pre-Fabricated Platforms: ASSPs
ASSP: application specific standard product
Domain-specific pre-fabricated IC
e.g., digital camera IC ASIC: application specific IC ASSP revenue > ASIC ASSP design starts > ASIC
Unique IC design Ignores quantity of same IC
ASIC design starts decreasing Due to strong benefits of
using pre-fabricated devices
Sourc
e:
Gart
ner/
Data
quest
Septe
mber’
01
Frank Vahid, UC Riverside 17
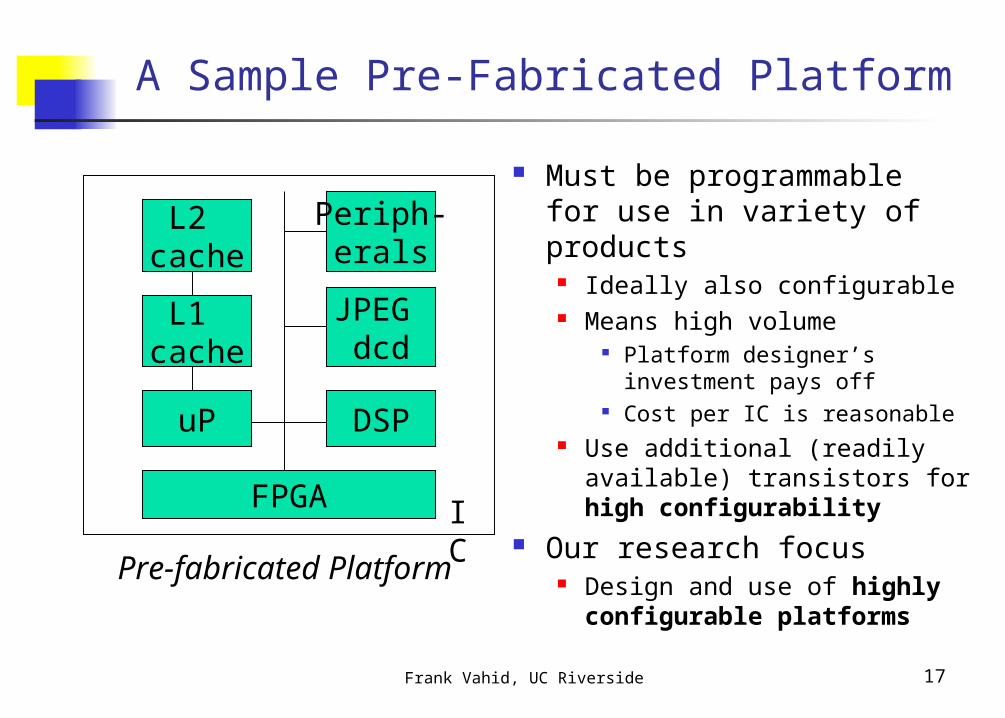
A Sample Pre-Fabricated Platform
uP
L1 cache
L2 cache
DSP
JPEG dcd
Periph-erals
FPGA
Pre-fabricated Platform
Must be programmable for use in variety of products
Ideally also configurable Means high volume
Platform designer’s investment pays off
Cost per IC is reasonable Use additional (readily
available) transistors for high configurability
Our research focus Design and use of highly
configurable platforms
IC

Frank Vahid, UC Riverside 18
Commercial Highly-Configurable Platform Type: Single-Chip Microprocessor/FPGA Platforms
Triscend E5 chip
Con
fig
ura
ble
log
ic8051 processor plus other peripherals
Memory
Triscend E5: based on 8-bit 8051 CISC core 10 Dhrystone MIPS at
40MHz 60 kbytes on-chip
RAM up to 40K logic gates Cost only about $4 (in
volume)

Frank Vahid, UC Riverside 19
Single-Chip Microprocessor/FPGA Platforms
Atmel FPSLIC Field-Programmable
System-Level IC Based on AVR 8-bit
RISC core 20 Dhrystone MIPS 5k-40k configurable
logic gates On-chip RAM (20-
36Kb) and EEPROM $5-$10 Courtesy of Atmel

Frank Vahid, UC Riverside 20
Single-Chip Microprocessor/FPGA Platforms
Triscend A7 chip Based on ARM7
32-bit RISC processor 54 Dhrystone MIPS
at 60 MHz Up to 40k logic
gates On-chip cache and
RAM $10-$20 in volume
Courtesy of Triscend

Frank Vahid, UC Riverside 21
Single-Chip Microprocessor/FPGA Platforms
Altera’s Excalibur EPXA 10
ARM (922T) hard core ~200 Dhrystone MIPS at
~200 MHz Devices range from
~200k to ~2 million programmable logic gates
Source: www.altera.com

Frank Vahid, UC Riverside 22
Single-Chip Microprocessor/FPGA Platforms
Xilinx Virtex II Pro PowerPC based
420 Dhrystone MIPS at 300 MHz
1 to 4 PowerPCs 4 to 16 gigabit
transceivers 12 to 216 multipliers 3,000 to 50,000 logic
cells 200k to 4M bits RAM 204 to 852 I/O $100-$500 (>25,000
units)
Con
fig
.lo
gic
Up to 16 serial transceivers• 622 Mbps to 3.125 Gbps622 Mbps to 3.125 Gbps
Pow
erP
Cs
Courtesy of Xilinx

Frank Vahid, UC Riverside 23
Why wouldn’t future microprocessor chips include some amount of on-chip FPGA?
Single-Chip Microprocessor/FPGA Platforms

Frank Vahid, UC Riverside 24
Single-Chip Microprocessor/FPGA Platforms
Lots of silicon area taken up by configurable logic As discussed earlier, less of an issue
every year Smaller area doesn’t necessarily mean
higher yield (lower costs) any more Previously could pack more die onto a wafer But die are becoming pad (pin) limited in
nanoscale technologies Configurable logic typically used for
peripherals, glue logic, etc. We have investigated another use...

Frank Vahid, UC Riverside 25
Software Improvements using On-Chip Configurable Logic
Partitioned software critical loops onto on-chip FPGA for several benchmarks
Performed physical measurements on Triscend A7 and E5 devices
A7 results
Benchmark Timeorig Timesw/hw Sp. Porig Psw/hw Eorig Esw/hw E sav
PS_g3fax 11.47 7.44 1.5 1.320 1.332 15.140 9.910 35%PS_crc 10.92 4.51 2.4 1.320 1.320 14.414 5.953 59%PS_brev 9.84 3.28 3.0 1.332 1.344 13.107 4.408 66%
Average: 2.3 Average: 53%
E5 results
Benchmark Timeorig Timesw/hw Sp. Porig Psw/hw Eorig Esw/hw E sav
PS_g3fax 15.16 7.11 2.1 0.252 0.270 3.820 1.920 50%PS_crc 10.64 4.64 2.3 0.207 0.225 2.202 1.044 53%PS_brev 17.81 1.81 9.8 0.252 0.270 4.488 0.489 89%
Average: 4.8 Average: 64%
A7 IC
Triscend A7 development
boardWork done by Greg Stitt, Brian Grattan, Shawn Nematbaktsh at UCR
Frank Vahid, UC Riverside 26
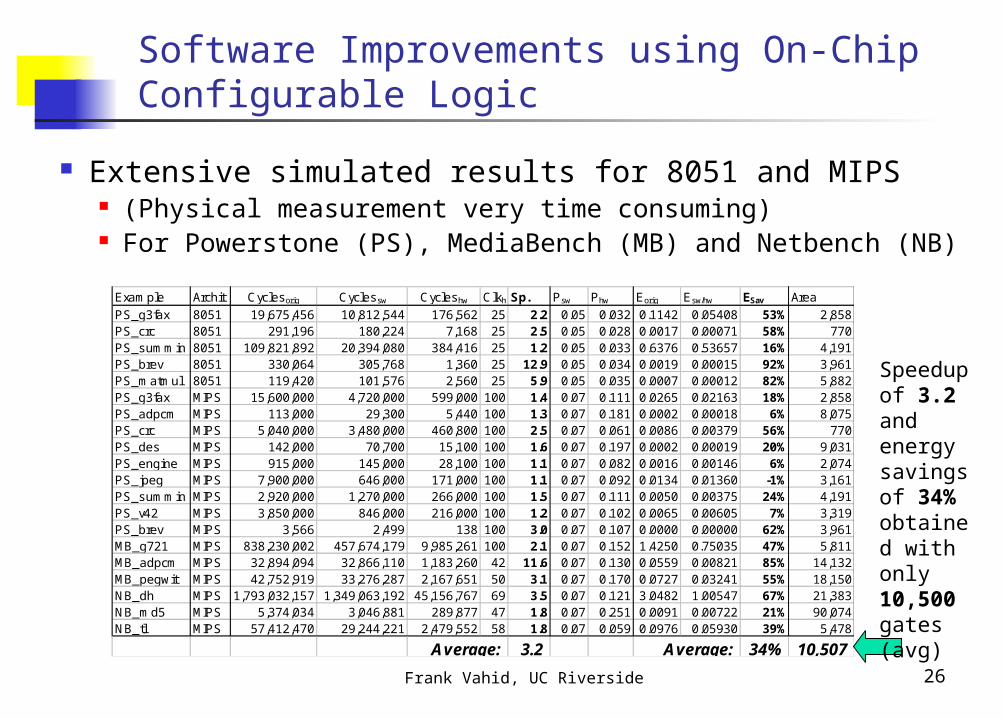
Software Improvements using On-Chip Configurable Logic
Extensive simulated results for 8051 and MIPS (Physical measurement very time consuming) For Powerstone (PS), MediaBench (MB) and Netbench (NB)
Example Archit Cyclesorig Cyclessw Cycleshw ClkhwSp. Psw Phw Eorig Esw/hw ESav Area
PS_g3fax 8051 19,675,456 10,812,544 176,562 25 2.2 0.05 0.032 0.1142 0.05408 53% 2,858PS_crc 8051 291,196 180,224 7,168 25 2.5 0.05 0.028 0.0017 0.00071 58% 770PS_summin 8051 109,821,892 20,394,080 384,416 25 1.2 0.05 0.033 0.6376 0.53657 16% 4,191PS_brev 8051 330,064 305,768 1,360 25 12.9 0.05 0.034 0.0019 0.00015 92% 3,961PS_matmul 8051 119,420 101,576 2,560 25 5.9 0.05 0.035 0.0007 0.00012 82% 5,882PS_g3fax MIPS 15,600,000 4,720,000 599,000 100 1.4 0.07 0.111 0.0265 0.02163 18% 2,858PS_adpcm MIPS 113,000 29,300 5,440 100 1.3 0.07 0.181 0.0002 0.00018 6% 8,075PS_crc MIPS 5,040,000 3,480,000 460,800 100 2.5 0.07 0.061 0.0086 0.00379 56% 770PS_des MIPS 142,000 70,700 15,100 100 1.6 0.07 0.197 0.0002 0.00019 20% 9,031PS_engine MIPS 915,000 145,000 28,100 100 1.1 0.07 0.082 0.0016 0.00146 6% 2,074PS_jpeg MIPS 7,900,000 646,000 171,000 100 1.1 0.07 0.092 0.0134 0.01360 -1% 3,161PS_summin MIPS 2,920,000 1,270,000 266,000 100 1.5 0.07 0.111 0.0050 0.00375 24% 4,191PS_v42 MIPS 3,850,000 846,000 216,000 100 1.2 0.07 0.102 0.0065 0.00605 7% 3,319PS_brev MIPS 3,566 2,499 138 100 3.0 0.07 0.107 0.0000 0.00000 62% 3,961MB_g721 MIPS 838,230,002 457,674,179 9,985,261 100 2.1 0.07 0.152 1.4250 0.75035 47% 5,811MB_adpcm MIPS 32,894,094 32,866,110 1,183,260 42 11.6 0.07 0.130 0.0559 0.00821 85% 14,132MB_pegwit MIPS 42,752,919 33,276,287 2,167,651 50 3.1 0.07 0.170 0.0727 0.03241 55% 18,150NB_dh MIPS 1,793,032,157 1,349,063,192 45,156,767 69 3.5 0.07 0.121 3.0482 1.00547 67% 21,383NB_md5 MIPS 5,374,034 3,046,881 289,877 47 1.8 0.07 0.251 0.0091 0.00722 21% 90,074NB_tl MIPS 57,412,470 29,244,221 2,479,552 58 1.8 0.07 0.059 0.0976 0.05930 39% 5,478
Average: 3.2 Average: 34% 10,507
Speedup of 3.2 and energy savings of 34% obtained with only 10,500 gates (avg)

Frank Vahid, UC Riverside 27
Speedup Gained with Relatively Few Gates
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
0 5,000 10,000 15,000 20,000 25,000
Gates
Sp
ee
du
p
G721(MB)
ADPCM(MB)
PEGWIT(MB)
DH(NB)
MD5(NB)
TL(NB)
URL(NB)
27. 27.
2.05 at 90,000
Created several partitioned versions of each benchmarks Most speedup gained with first 20,000 gates; diminishing returns after that Surprisingly few gates
Stitt, Grattan and Vahid, Field-programmable Custom Computing Machines (FCCM) 2002
Stitt and Vahid, IEEE Design and Test, Dec. 2002 J. Villarreal, D. Suresh, G. Stitt, F. Vahid and W. Najjar, Design Automation of
Embedded Systems, 2002 (to appear).

Frank Vahid, UC Riverside 28
Other Types of Configurability
Microprocessor (other researchers)
VLIW configurations Voltage scaling
Memory hierarchy Our focus: build a highly-configurable cache that
can be tuned to a particular program Work by Chaunjun Zhang, along with Walid Najjar, at UCR

Frank Vahid, UC Riverside 29
Cache Contributes Much to Performance and Power
Well-known for performance Energy
ARM920T: caches consume nearly half of total power (Segars 01) M*CORE: unified cache consumes half of total power
(Lee/Moyer/Arends 99)
ARM920T. Source: Segars ISSCC’01
Mem
L1 Cache
Processor

Frank Vahid, UC Riverside 30
Associativity Plays a Big Role
Reduces miss rate – thus improving performance Impact on power and energy?
(Energy = Power * Time)
0.0%
0.5%
1.0%
1.5%
2.0%
1 2 4Associativity
Mis
s r
ate
epic
mpeg2

Frank Vahid, UC Riverside 31
Associativity is Costly
Associativity improves hit rate, but at the cost of more power per access
Are the power savings from reduced misses outweighed by the increased power per hit?
sa_data
wordline_databitline_data
decode_data
data output driver
mux driver
comparator
bitline_tag sa_tag
wordline_tag
decode_tag
Energy access breakdown for 8 Kbyte, 4-way set associative cache (considering dynamic power only)
0.0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1.0
1w ay 2w ay 4w ay
Associativity
En
erg
y p
er a
ccess(n
J)
Energy per access for 8 Kbyte cache

Frank Vahid, UC Riverside 32
Associativity and Energy
Best performing cache is not always lowest energy
0.0%
0.5%
1.0%
1.5%
2.0%
1 2 4Associativity
Mis
s ra
te
epic
mpeg2
0.0
0.2
0.4
0.6
0.8
1.0
1 2 4
AssociativityN
orm
aliz
ed e
nerg
y
epic
mpeg2
Significantly poorer energy
Frank Vahid, UC Riverside 33
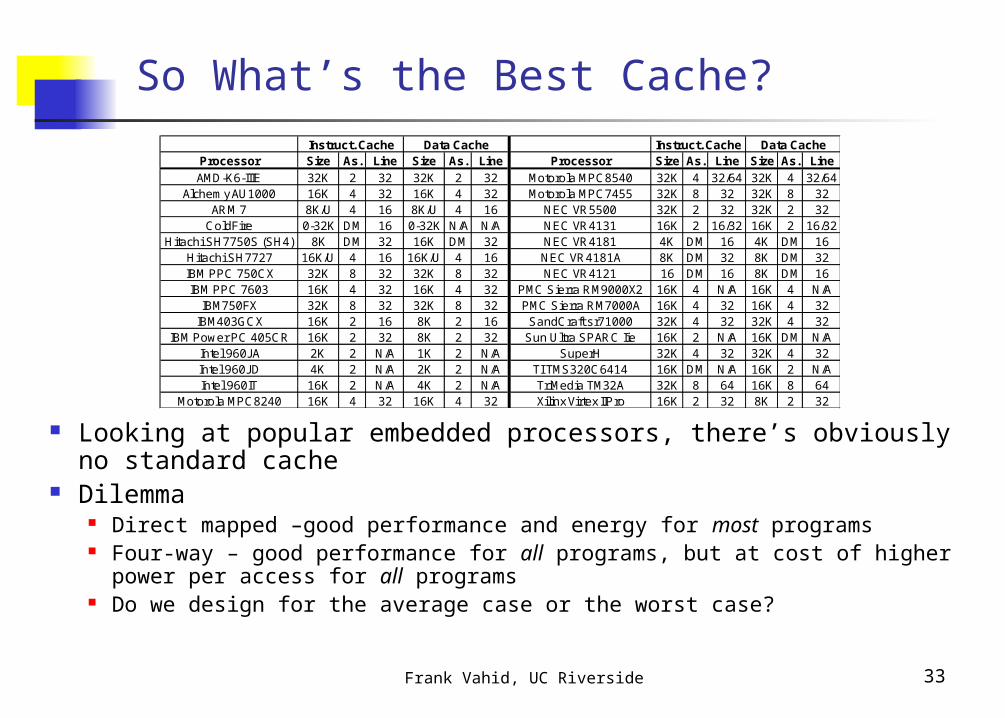
So What’s the Best Cache?
Looking at popular embedded processors, there’s obviously no standard cache
Dilemma Direct mapped –good performance and energy for most programs Four-way – good performance for all programs, but at cost of higher power
per access for all programs Do we design for the average case or the worst case?
Processor Size As. Line Size As. Line Processor Size As. Line Size As. Line
AMD-K6-IIIE 32K 2 32 32K 2 32 Motorola MPC8540 32K 4 32/64 32K 4 32/64Alchemy AU1000 16K 4 32 16K 4 32 Motorola MPC7455 32K 8 32 32K 8 32
ARM 7 8K/U 4 16 8K/U 4 16 NEC VR5500 32K 2 32 32K 2 32ColdFire 0-32K DM 16 0-32K N/A N/A NEC VR4131 16K 2 16/32 16K 2 16/32
Hitachi SH7750S (SH4) 8K DM 32 16K DM 32 NEC VR4181 4K DM 16 4K DM 16Hitachi SH7727 16K/U 4 16 16K/U 4 16 NEC VR4181A 8K DM 32 8K DM 32IBM PPC 750CX 32K 8 32 32K 8 32 NEC VR4121 16 DM 16 8K DM 16IBM PPC 7603 16K 4 32 16K 4 32 PMC Sierra RM9000X2 16K 4 N/A 16K 4 N/A
IBM750FX 32K 8 32 32K 8 32 PMC Sierra RM7000A 16K 4 32 16K 4 32IBM403GCX 16K 2 16 8K 2 16 SandCraft sr71000 32K 4 32 32K 4 32
IBM Power PC 405CR 16K 2 32 8K 2 32 Sun Ultra SPARC Iie 16K 2 N/A 16K DM N/AIntel 960JA 2K 2 N/A 1K 2 N/A SuperH 32K 4 32 32K 4 32Intel 960JD 4K 2 N/A 2K 2 N/A TI TMS320C6414 16K DM N/A 16K 2 N/AIntel 960IT 16K 2 N/A 4K 2 N/A TriMedia TM32A 32K 8 64 16K 8 64
Motorola MPC8240 16K 4 32 16K 4 32 Xilinx Virtex IIPro 16K 2 32 8K 2 32
Instruct. Cache Data Cache Instruct. Cache Data Cache

Frank Vahid, UC Riverside 34
Solution to the Dilemma
Configurable cache Can be configured as four way, two way, or one way
Ways can be concatenated Furthermore, ways can even be shut down to decrease total size
Memory
Dir
ect
map
ped
cach
e
Four-way Now two-way
Now one-way
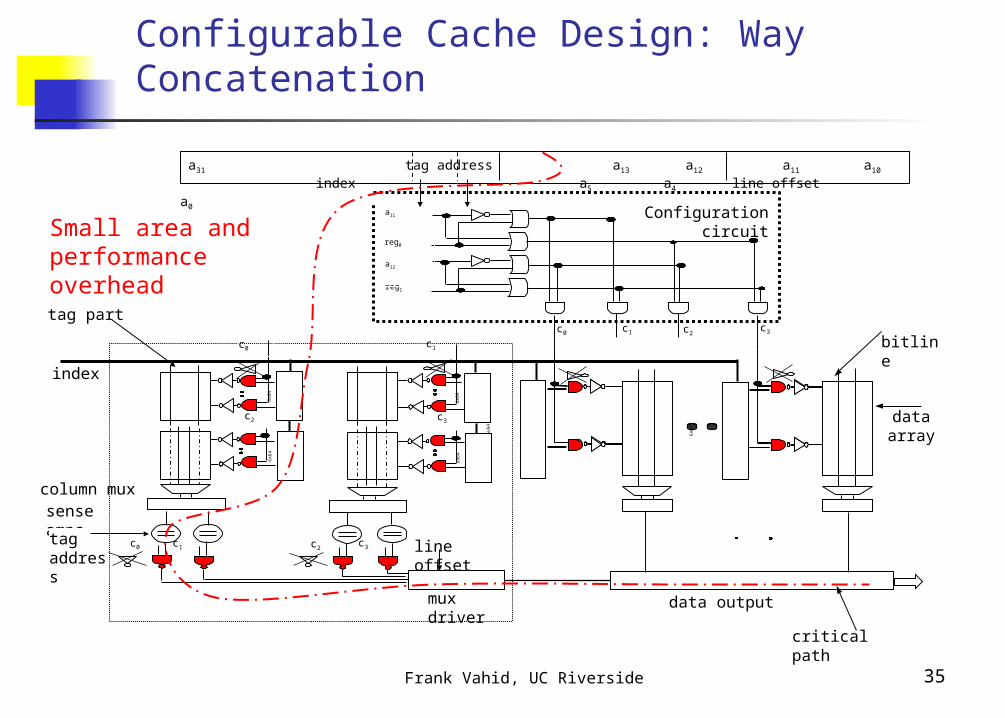
Frank Vahid, UC Riverside 35
Configurable Cache Design: Way Concatenation
index
c1 c3c0 c2
a11
a12
reg1
reg0
sense ampscolumn mux
tag part
tag address
mux driver
c1
line offset
data output
critical path
c0
c2
c0 c1
6x64
6x64
c3c2
6x64
6x64
c3
6x64
6x64
a31 tag address a13 a12 a11 a10 index a5 a4 line offset a0
Configuration circuit
data array
bitline
Small area and performance overhead

Frank Vahid, UC Riverside 36
Configurable Cache Experiments
Configurable cache with both way concatenation and way shutdown is superior on every benchmark
Considered Powerstone, MediaBench, and Spec2000 Tuning the cache to the program is important Work submitted to High-Performance Computer Architectures 2003, Zhang, Vahid and Najjar
114%268%116%
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
padp
cm crc
auto
2
bcnt
bilv
bina
ry blit
brev
g3fa
x fir
pjep
g
ucbq
sort
v42
adpc
m
epic
jpeg
mpe
g2
pegw
it
g721 ar
t
mcf
pars
er vpr
Ave
rage
Benchmarks
En
erg
y (n
orm
aliz
ed)
CnvI1D1cnctshutboth
100% = 4-way conventional cache

Frank Vahid, UC Riverside 37
Conclusions Trend is away from semi-custom IC fabrication
Big enough; other pressures encourage buying pre-fabricated platforms Platforms must be highly configurable
To be useful for a variety of applications, and hence mass produced We have discussed
Software speedup/energy benefits of on-chip configurable logic: 3x speedups with only ~10,000 gates
Creating a highly-configurable cache architecture: 40% energy savings compared to conventional cache
Current/future work (collaborators: Walid Najjar UCR, Nik Dutt UCI) Automatically partitioning software loops to configurable logic
Several approaches: platform-assisted, and dynamically on-chip Work being done by Roman Lysecky, Susan Cotterell, Greg Stitt, and Shawn
Nematbaktsh at UCR Automatically tuning a configurable cache
Ann Gordon-Ross at UCR


















