
ETL Best Practices for IBM DataStage 8.0
36
ETL Best Practices for IBM DataStage Version 1.2 Date: 04-10-2008 Submitted by Approved by: <name> Date: <mm-dd-yyyy>
-
Upload
preethy-senthil -
Category
Documents
-
view
242 -
download
9
description
ETL
Transcript of ETL Best Practices for IBM DataStage 8.0

ETL Best Practices for IBM DataStage
Version 1.2Date: 04-10-2008
Submitted by
Approved by: <name>Date: <mm-dd-yyyy>

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 2 of 36
CONTENTS
1 Introduction ...................................... .............................................................................................................. 4
1.1 Objective ................................................................................................................................................... 41.2 Scope........................................................................................................................................................ 4
2 IBM WebSphere DataStage ........................... ................................................................................................ 5
3 DataStage Job Types............................... ...................................................................................................... 6
3.1 Server ....................................................................................................................................................... 63.2 Parallel ...................................................................................................................................................... 63.3 Mainframe................................................................................................................................................. 63.4 Server vs. Parallel..................................................................................................................................... 6
4 DataStage – Stages................................ ........................................................................................................ 7
4.1 Sequential File .......................................................................................................................................... 74.2 Complex Flat File Stage ........................................................................................................................... 74.3 DB2 UDB Stages .................................................................................................................................... 10
4.3.1 DB2 UDB API .................................................................................................................................. 104.3.2 DB2 UDB Load ................................................................................................................................ 104.3.3 DB2 Enterprise ................................................................................................................................ 114.3.4 Database Operations....................................................................................................................... 11
4.4 FTP Enterprise Stage ............................................................................................................................. 134.5 Look up vs. Join...................................................................................................................................... 164.6 Transformer ............................................................................................................................................ 194.7 Sort Stage............................................................................................................................................... 274.8 DataSet ................................................................................................................................................... 274.9 Change Data Capture Stage .................................................................................................................. 274.10 CDC Vs UPSERT mode in DB2 stages.................................................................................................. 284.11 Parameter Sets ....................................................................................................................................... 284.12 Slowly Changing Dimension Stage ........................................................................................................ 30
5 Job Representation................................ ...................................................................................................... 31
6 Performance Tuning ................................ .................................................................................................... 32
6.1 General ................................................................................................................................................... 326.2 Sequential File Stage.............................................................................................................................. 336.3 Complex Flat File Stage ......................................................................................................................... 346.4 DB2 UDB API.......................................................................................................................................... 356.5 DB2 ENTERPRISE STAGE.................................................................................................................... 36
ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 3 of 36
Revision HistoryVersion(x.yy)
Date ofRevision
Description of Change Reason forChange
Affected Sections Approved By
1.0 3-21-2008
1.1 3-31-2008 Added examples LabCorpReviewcomments
1.2 4-10-2008 Added Examples andDetails on sections
LabCorpReviewcomments
Affected GroupsEnterprise Results Repository Team
Wipro ETL COE team

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 4 of 36
1 Introduction
Laboratory Corporation of America, referred as LabCorp, has invited Wipro Technologies to setup an ETLCenter of excellence at LabCorp. In doing so, Wipro will understand the existing ETL architecture and processesand recommend best practices. Wipro will also mentor the LabCorp ETL development team in implementing thebest practices on a project chosen for Proof of Concept.
1.1 Objective
The purpose of this document is to suggest the DataStage Best practices for the Results Repositoryimplementation to ETL developers. It is assumed that the developers understand the stages and the terminologyused in this document.
In doing so, The Wipro team considered all the components involved in the Enterprise Results Repository
1.2 ScopeThe components involved in Enterprise Results Repository are
• Input: Flat Files and DB2 tables• Output: DB2 tables• Reject Handling: Flat Files• Restartability: Datasets/flat files will be used as intermediate sources• Business Logic:
♦ Identify the records for insert and update♦ Check for referential integrity
The DataStage stages discussed in this document are all the stages that are required to cover the componentsmentioned above. What each stage does and why choose a particular stage have been discussed in detail.For few of the components multiple implementations have been discussed. Best suitable implementation has tobe decided based on the considerations mentioned.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 5 of 36
2 IBM WebSphere DataStage
The Results Repository project has been chosen for proof of concept. Currently, the Results repository project isin the development phase.
IBM® WebSphere® DataStage®, a core component of the IBM® WebSphere® Data Integration Suite, enablesyou to tightly integrate enterprise information, despite having many sources or targets and short time frames.Whether you're building an enterprise data warehouse to support the information needs of the entire company,building a "real time" data warehouse, or integrating dozens of source systems to support enterpriseapplications like customer relationship management (CRM), supply chain management (SCM), and enterpriseresource planning (ERP). WebSphere DataStage helps ensure that you will have information you can trust.
Although primarily aimed at data warehousing environments, DataStage tool can also be used in any datahandling, data migration, or data reengineering projects. It is basically an ETL tool that simplifies the datawarehousing process. It is an integrated product that supports extraction of the source data, cleansing,decoding, transformation, integration, aggregation, and loading of target databases.
DataStage has the following features to aid the design and processing required building a data warehouse:• Uses graphical design tools. With simple point-and-click techniques you can draw a scheme to represent
your processing requirements.• Extracts data from any number or type of database.• Handles all the Metadata definitions required to define your data warehouse. You can view and modify the
table definitions at any point during the design of your application.• Aggregates data. You can modify SQL SELECT statements used to extract data.• Transforms data. DataStage has a set of predefined transforms and functions you can use to convert your
data. You can easily extend the functionality by defining your own transforms to use.• Loads the data warehouse

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 6 of 36
3 DataStage Job Types
3.1 Server
These are compiled and run on the DataStage server. A server job will connect to databases on other machinesas necessary, extract data, process it, and then write the data to the target data warehouse.
3.2 Parallel
These are compiled and run on the DataStage server in a similar way to server jobs, but support parallelprocessing on SMP (Symmetric Multiprocessing), MPP (Massively Parallel Processing), and cluster systems.Parallel jobs can significantly improve performance because the different stages of a job are run concurrentlyrather than sequentially. There are two basic types of parallel processing, pipeline and partitioning.
3.3 Mainframe
These are available only if you have Enterprise MVS Edition installed. A mainframe job is compiled and run onthe mainframe. Data extracted by such jobs is then loaded into the data warehouse.
3.4 Server vs. ParallelDataStage offers two distinct types of technologies that provide individual costs and benefits. When making thedecision as to whether to use DataStage Server or DataStage Parallel you need to assess the strengths of eachand apply the type that will best suit the needs of the particular module under development. The Licenseacquired is good for either of them.
Several factors determine whether an interface will be constructed using DataStage Server or DataStageParallel:
• Volume• Complexity• Batch window
As a general guide, larger volume (i.e. 2 million rows or more) jobs with small batch window (30 minutes or less)constraint should be considered for the Parallel job. This is an important decision because Parallel jobs willconsume more hardware (memory and processor) resources than a Server Job, so it is definitely moreadvisable to do simpler jobs in Server and complex in Parallel and then manage them accordingly using aSequencer. (Another component in DataStage used to manage the flow of multiple jobs).
Complexity depends on the business rules to be applied in the job and the kind of table it will load. A job thatloads a fact table may be categorized as complex as it involves one or more lookup, join, merge or funnel stage.A dimension table load is simple if all the data is available in one data source.
It is difficult to quantify complexity, as it is very relative. As a rule of thumb, if the business rules dictate t heuse of more than one source of data to load a table , then the job may be considered complex .
If the load window is small, the data volumes are h igh and the business rules are complex, then alwaysprefer a parallel job to a server job.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 7 of 36
4 DataStage – Stages
4.1 Sequential File
The sequential file stage is used to read or write to flat files. The files can be fixed length or delimited. It canperform operation on a single file or a set of files using file pattern.
When reading or writing a single file the stage operates in sequential mode, but if the operation is beingperformed on multiple files, the mode of operation is parallel .
Reading from and Writing to Fixed-Length Files
Particular attention must be taken when processing fixed-length fields using the Sequential File stage:
If the incoming columns are variable-length data types (e.g. Integer, Decimal, and Varchar), the field widthcolumn property must be set to match the fixed-width of the input column. Double-click on the column number inthe grid dialog to set this column property.
If a field is nullable, you must define the null field value and length in the nullable section of the column property.Double-click on the column number in the grid dialog to set these properties.
When writing fixed-length files from variable-length fields (e.g. Integer, Decimal, Varchar), the field width andpad string column properties must be set to match the fixed-width of the output column. Double-click on thecolumn number in the grid dialog to set this column property.
Reading Bounded-Length VARCHAR Columns
Care must be taken when reading delimited, bounded-length Varchar columns (Varchars with the length optionset). By default, if the source file has fields with values longer than the maximum Varchar length, these extracharacters will be silently truncated.
Converting Binary to ASCII
Export EBCDIC as ASCII. Select this to specify that EBCDIC characters are written as ASCII characters.Applies to fields of the string data type and record.
Reject Links
The reject link can be used to write the records that do not satisfy the specified format to a reject file. For writingfiles, the link uses the column definitions for the input link. For reading files, the link uses a single column calledrejected containing raw data for columns rejected after reading because they do not match the schema. Thedata written to reject file is raw binary.
4.2 Complex Flat File StageThe Complex Flat File (CFF) stage is a file stage. You can use the stage to read a file or write to a file, but youcannot use the same stage to do both. As a source, the CFF stage can have multiple output links and a singlereject link. You can read data from one or more complex flat files, including MVS data sets with QSAM andVSAM files. You can also read data from files that contain multiple record types.
ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 8 of 36
In reading a single file, the CFF is no different from the sequential file. Use the default options on the FILEoption and RECORD option tab. When reading a file with varying record length and writing the output tomultiple links, the column list for each varying record type should be identified in the RECORDS tab.The recommendations for sequential file stage apply to this stage as well.
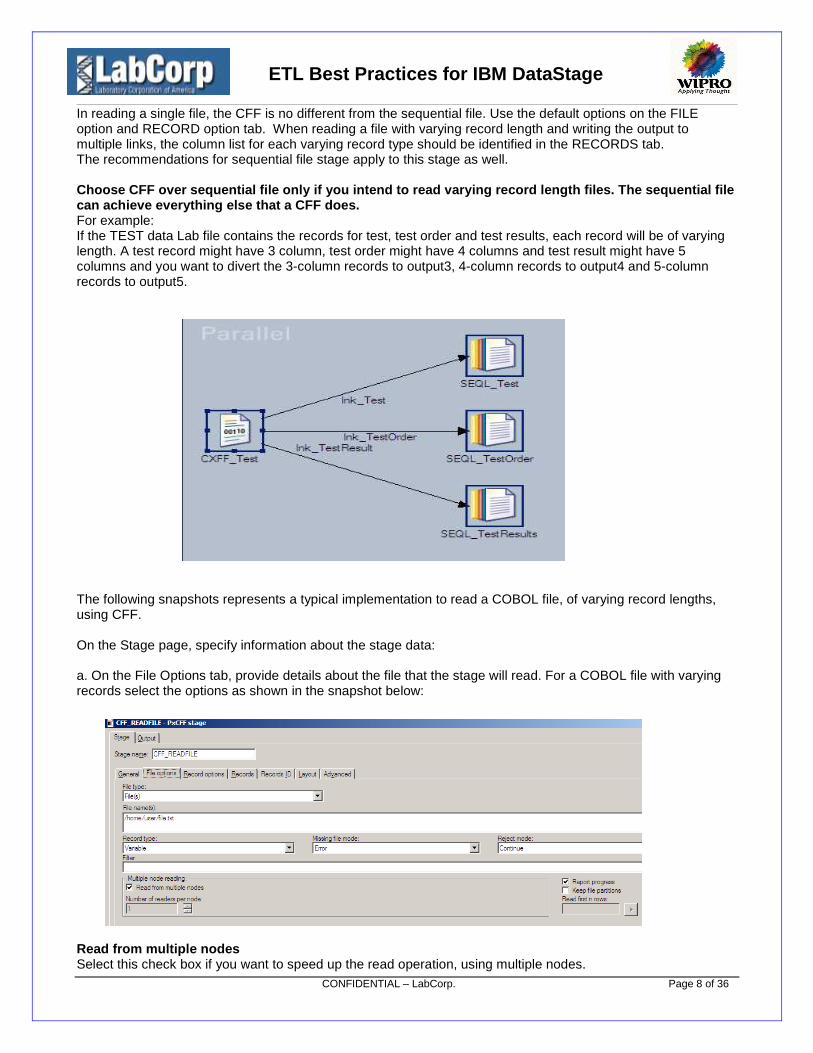
Choose CFF over sequential file only if you intend to read varying record length files. The sequential filecan achieve everything else that a CFF does.For example:If the TEST data Lab file contains the records for test, test order and test results, each record will be of varyinglength. A test record might have 3 column, test order might have 4 columns and test result might have 5columns and you want to divert the 3-column records to output3, 4-column records to output4 and 5-columnrecords to output5.
The following snapshots represents a typical implementation to read a COBOL file, of varying record lengths,using CFF.
On the Stage page, specify information about the stage data:
a. On the File Options tab, provide details about the file that the stage will read. For a COBOL file with varyingrecords select the options as shown in the snapshot below:
Read from multiple nodesSelect this check box if you want to speed up the read operation, using multiple nodes.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 9 of 36
Report progressSelect this check box to display a progress report at each 10% interval when the stage can determine the filesize.
Missing file modeSpecify the action to take if a file to be read does not exist. It should be set to Error to stop the processing if thefile does not exist.
Reject modeSpecify the action to take if any source records do not match the specified record format, or if any records arenot written to the target file (for target stages). It should be set to Save so as to create a reject file using thereject link.
FilterFilter will allow you to use a UNIX command to split input files as the data is read from each file. This will makesthe file reading faster using the parallelism and multiple nodes.
b. On the Record Options tab, describe the format of the data in the file. For the COBOL files, the typicalsettings are shown in the snapshot below:
c. If the stage is reading a file that contains multiple record types, on the Records tab, create record definitionsfor the data. On the Records tab, create or load column definitions for the data. To load the columns for theCOBOL files import the column definition file (.cfd).

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 10 of 36
On the output tab specify the columns which should be mapped to the output file or stage.
4.3 DB2 UDB Stages
4.3.1 DB2 UDB APIThis stage allows you to read from or write to a DB2 database table. The execution mode for DB2 API stage issequential (by default). When data is read using a DB2 API stage, the data is loaded entirely to the coordinatingnode only. If the execution mode is set to Parallel for DB2 API stage, the data is duplicated from thecoordinating node to all the participating nodes. Unless you have business scenarios that require such dataduplication, set the DB2 API stage to run sequentially.
The DB2/API plugin should only be used to read from and write to DB2 on other, non-UNIX platforms.You might, for example, use it to access mainframe editions through DB2 Connect.
4.3.2 DB2 UDB LoadThis is a bulk load option. If the job writes data of 2GB bytes or more, then c onsider using this stageinstead of a DB2 API stage.The Restart Count option can be used as a restartability option. By default it is set to 0 to single that the loadhas to start at row 1.
For example: When loading 10000 records to a table using the DB2 load stage, if the job aborts after 5000records, the job can be rerun with the restart count set to 5000.
This will ensure that the job starts the load from 5001 record. For better code management, this value can bepassed as a parameter.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 11 of 36
4.3.3 DB2 EnterpriseThis stage executes in parallel and allows handling partitioned data properly. Consider this over DB2 APIstage to read data if you intent to read large volu mes in partitions . IBM DB2 databases distribute data inmultiple partitions. DB2/UDB enterprise stage can match the partitioning when reading data from or writing datato an IBM DB2 database.
By default, the DB2 enterprise stage partitions data in DB2 partition mode i.e., it takes the partitioning methodfrom a selected IBM DB2 database.
The DB2 Data Partitioning Feature (DPF) offers the necessary scalability to distribute a large database overmultiple partitions (logical or physical). ETL processing of a large bulk of data across whole tables is verytime-expensive using traditional plug-in stages lik e DB2 API . DB2 Enterprise Stage however provides aparallel execution engine, using direct communication with each database partition to achieve the best possibleperformance.
DataStage starts up processes across ETL and DB2 nodes in the cluster. DB2/UDB Enterprise stage passesdata to/from each DB2 node through the DataStage parallel framework, not the DB2 client. The parallelexecution instance can be examined from the job monitor of the DataStage Director.
If the setup to support DB2 Enterprise stage, i.e., both DB2 database and DataStage server are on thesame platform, is in place then always use Enterpri se over, API and Load.
4.3.4 Database Operations
4.3.4.1 Appropriate Use of SQL and DataStage Stages
When using relational database sources, there is often a functional overlap between SQL and DataStagestages. Although it is possible to use either SQL or DataStage to solve a given business problem, the optimalimplementation involves leveraging the strengths of each technology to provide maximum throughput anddeveloper productivity.
While there are extreme scenarios when the appropriate technology choice is clearly understood, there may be“gray areas” where the decision should be made on factors such as developer productivity, metadata captureand re-use, and ongoing application maintenance costs.
The following guidelines can assist with the appropriate use of SQL and DataStage technologies in a given jobflow:
When possible, use a SQL filter (WHERE clause) to limit the number of rows sent to the DataStage job. Thisminimizes impact on network and memory resources, and leverages the database capabilities.
Use a SQL Join to combine data from tables with a small number of rows in the same database instance,especially when the join columns are indexed.When combining data from very large tables, or when the source includes a large number of database tables,the efficiency of the DataStage EE Sort and Join stages can be significantly faster than an equivalent SQLquery. In this scenario, it can still be beneficial to use database filters (WHERE clause) if appropriate.Avoid the use of database stored procedures on a per-row basis within a high-volume data flow. For maximumscalability and parallel performance, it is best to implement business rules natively using DataStagecomponents.
4.3.4.2 Optimizing Select Lists
For best performance and optimal memory usage, it is best to explicitly specify column names on all sourcedatabase stages, instead of using an unqualified “Table” or SQL “SELECT *” read. For “Table” read method,

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 12 of 36
always specify the “Select List” sub-property. For “Auto-Generated” SQL, the DataStage Designer willautomatically populate the select list based on the stage’s output column definition.For example:Let us consider a scenario of reading the LAB_CD and LAB_TYPE_CD from the LAB table. The lab tablecontains 37 columns.
If the Table read method is used, always mention the select list as shown below
This will ensure that data for only 2 columns will be loaded into the memory instead of loading all the 37columns, thus saving time and precious memory.
Alternatively if the read method is set To USER DEFINED SQL then, ensure that you mention the columnnames as shown in the screenshot below. Do not use the SELECT * FROM LAB to achieve this.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 13 of 36
The only exception to this rule is when building dynamic database jobs that use runtime column propagation toprocess all rows in a source table.
For example:
While doing an UPSERT using enterprise DB2 stage it is possible to create a reject link to trap rows that fail anyupdate or insert statements. There is a feature in the enterprise stage where a reject link out of the stage willcarry two new fields, SQLSTATE and SQLCODE. These hold the return codes from the database engine forfailed UPSERT transactions. The fields are called SQLSTATE and SQLCODE.
By default this reject link holds just the columns written to the stage, they do not show any columns indicatingwhy the row was rejected and often no warnings or error messages appear in the job log.
To trap these values add SQLSTATE and SQLCODE to the list of output columns, on the output column tab andcheck the "Runtime column propagation" check box, this will turn your two new columns from invalid redcolumns to black and let your job compile.
When the job runs and a reject occurs the record is sent down the reject link, two new columns are propagateddown that link and can then be written out to an error handling table of file.
4.4 FTP Enterprise StageThe FTP Enterprise stage transfers multiple files in parallel. These are sets of files that are transferred from oneor more FTP servers into WebSphere DataStage or from WebSphere DataStage to one or more FTP servers.The source or target for the file is identified by a URI (Universal Resource Identifier). The FTP Enterprise stageinvokes an FTP client program and transfers files to or from a remote host using the FTP Protocol.
When reading files using this stage, it is required to specify the exact record format. This is a drawback if youwould want to use this stage to read files of different record formats.
Consider FTP stage if you will be reading multiple files of the same record format from the same ordifferent directory path.
Consider Unix script if you will be reading multipl e files of different record format from the same ordifferent directory path.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 14 of 36
For example:If sales files are written to the same directory on a daily basis and your requirement is to read the files on aweekly basis, then you could consider using the FTP enterprise stage to read all the files
The format of the URI is very important in reading the files, especially from a Mainframe server.
The syntax for an absolute path on UNIX or LINUX servers is:
ftp://host//path/filename
While connecting to the mainframe system, the syntax for an absolute path is:
ftp://host/\’path.filename\’
Scenario-1: FTP multiple files of same record formatFor Instance Test_Order table is loaded on weekly basis and files are provided on a daily basis, then FTP Stagecan be used to transfer all 7 files using a single job.
The following snapshot describes the metadata for 7 daily Test order files. A single job can be used to FTP thefiles.
Scenario-2 FTP multiple files of different record formatFor Instance Test,Test_Order,Test_Result tables use files of different formats, then a single DataStage job willnot serve the purpose as FTP stage is dependent on the record format to transfer the file. Instead a single Unixscript can be used to transfer these files. Following snapshots represents the different record formats:
File Name: Test.txt

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 15 of 36
File Name: Test_Order.txt
File Name: Test_result.txt

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 16 of 36
4.5 Look up vs. Join
The Lookup stage is most appropriate when the reference data for all lookup stages in a job is small enough tofit into available physical memory. Each lookup reference requires a contiguous block of physical memory. If thedataset is larger than available contiguous block of physical memory, the JOIN or MERGE stage should beused.
Lookup Stage Partitioning ConsiderationLookup stage does not requires input data to be sorted. There are some special partitioning considerations forLookup stages. You need to ensure that the data being looked up in the lookup table is in the same partition asthe input data referencing it. To ensure this partition the lookup tables using the Entire method.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 17 of 36
Join Stage Partitioning ConsiderationThe data sets input to the Join stage must be hash partitioned and sorted on key columns. This ensures thatrows with the same key column values are located in the same partition and will be processed by the samenode.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 18 of 36
For example:If the contiguous block of physical memory is 4KB and the dataset is 8KB, then use JOIN or MERGE.
When deciding between Join and Merge, consider the following:• Join can have only one output link and no reject links.• Merge can have multiple output and reject links.• Merge requires datasets to be sorted and without any duplication.• When unsorted input is very large or sorting is not feasible, Lookup is preferred. When all inputs are of
manageable size or are pre-sorted, Join is the preferred solution.
If the reference to a Lookup is directly from a table, and the number of input rows is significantly smaller (e.g.1:100 or more) than the number of reference rows, a Sparse Lookup may be appropriate.
For example:When loading the fact table, we lookup on the dimension table to get the appropriate surrogate keys. When anormal lookup is performed on a dimension table, the dimension table data is loaded into the memory and thecomparison is done in the memory.
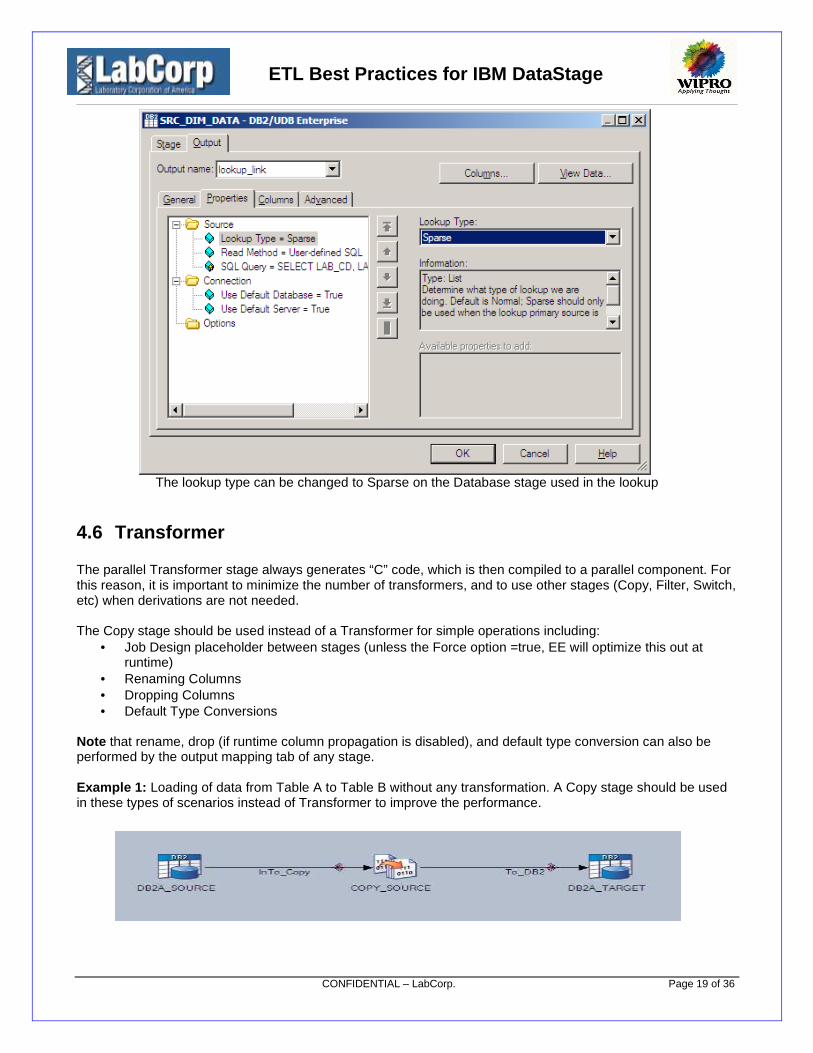
Consider a scenario, where input for fact table is only 100 records and it has to be compared to 10000dimension records. A sparse lookup is advised in such a scenario. When the lookup type is changed to sparse,the data from the lookup table is not loaded to the memory. Instead, the fact records are sent to the database toperform the lookup.
Note that a sparse lookup can only be done if the lookup is done on a database table.
Sparse Lookup on a database table
ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 19 of 36
The lookup type can be changed to Sparse on the Database stage used in the lookup
4.6 Transformer
The parallel Transformer stage always generates “C” code, which is then compiled to a parallel component. Forthis reason, it is important to minimize the number of transformers, and to use other stages (Copy, Filter, Switch,etc) when derivations are not needed.
The Copy stage should be used instead of a Transformer for simple operations including:• Job Design placeholder between stages (unless the Force option =true, EE will optimize this out at
runtime)• Renaming Columns• Dropping Columns• Default Type Conversions
Note that rename, drop (if runtime column propagation is disabled), and default type conversion can also beperformed by the output mapping tab of any stage.
Example 1: Loading of data from Table A to Table B without any transformation. A Copy stage should be usedin these types of scenarios instead of Transformer to improve the performance.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 20 of 36
Example 2: Using Copy stage we can also drop the unwanted columns from the source table before loading thedata into Target table.
Example 3: Loading the same set of data from Table A to Table B by adding the current timestamp condition orany transformation logic-using transformer. A Transformer stage should be used only when there is need toapply business logic.
1. Consider, if possible, implementing complex derivation expressions using regular patterns by Lookup tablesinstead of using a Transformer with nested derivations.
ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 21 of 36
For example, the derivation expression:
If A=0,1,2,3 Then B=”X” If A=4,5,6,7 Then B=”C”
This Could be implemented with a lookup table containing values for column A and corresponding values ofcolumn B.
2. Optimize the overall job flow design to combine derivations from multiple Transformers into a singl eTransformer stage when possible.
3. The Filter and/or Switch stages can be used to separate rows into multiple output links based on SQL-likelink constraint expressions.
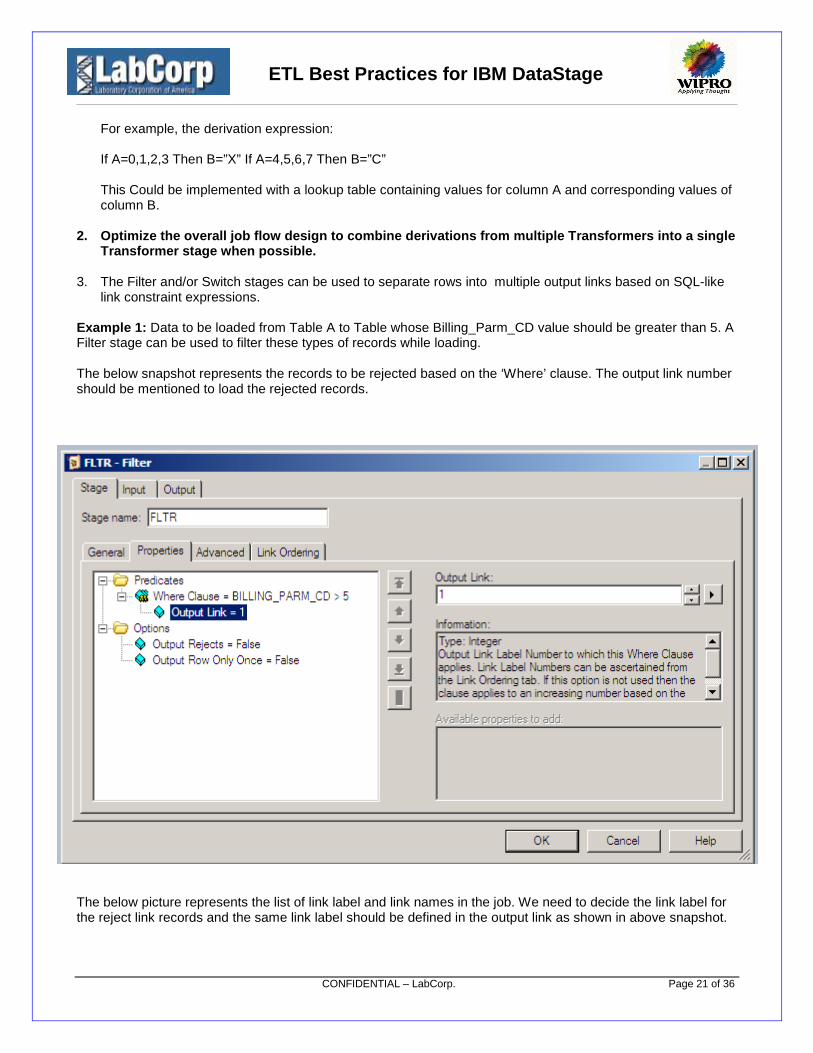
Example 1: Data to be loaded from Table A to Table whose Billing_Parm_CD value should be greater than 5. AFilter stage can be used to filter these types of records while loading.
The below snapshot represents the records to be rejected based on the ‘Where’ clause. The output link numbershould be mentioned to load the rejected records.
The below picture represents the list of link label and link names in the job. We need to decide the link label forthe reject link records and the same link label should be defined in the output link as shown in above snapshot.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 22 of 36

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 23 of 36
Example 2: SWITCH stage over transformer
Switch stage can be used to load data into different target tables or dataset or reject link based on the decision.The main difference between the Transformer and Switch stage is, we can use Transformer when we need todo some validations on data like If..Then..Else, Max (), Min (), Len () and CurrentTimestamp() etc.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 24 of 36
Below snapshot represents the properties for Switch stage. Here we need to select the key column for ‘Selector’and the output of the data to be loaded in different stages is based on the value defined in ‘User-DefinedMapping’ section.
Below snapshot represents the column mapping for output dataset’s in the job. Here we can drop the columnsbased on the table structure of the target table.
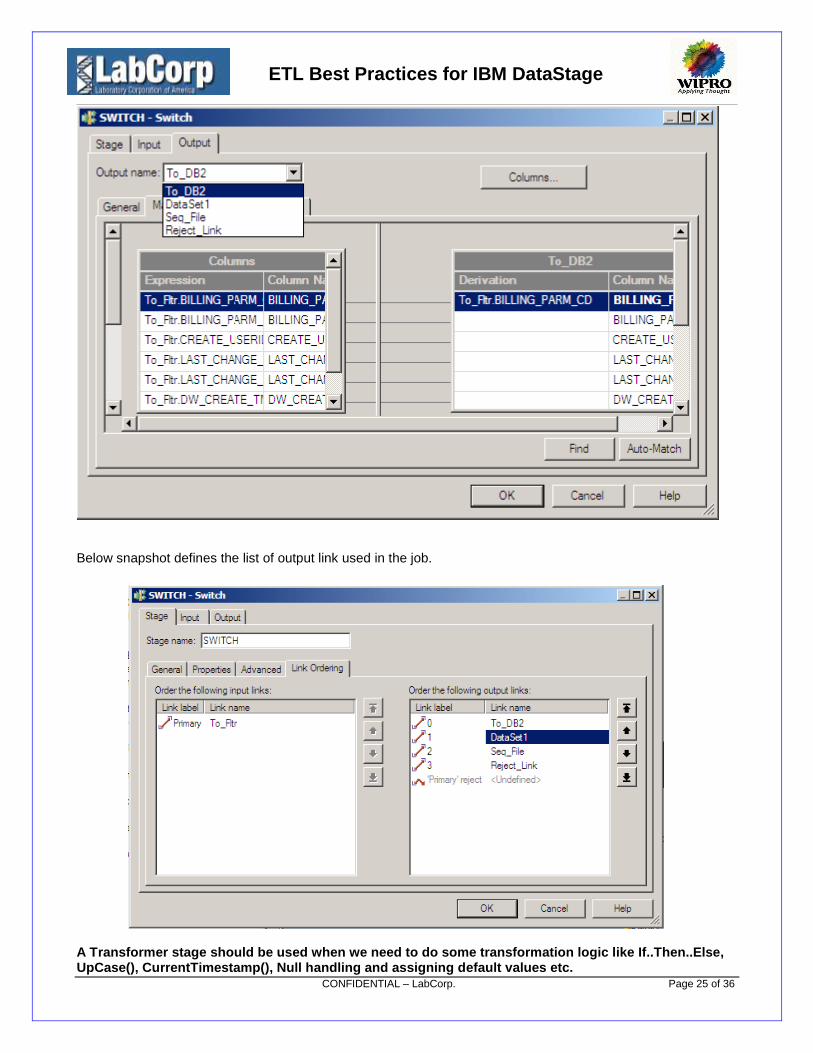
ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 25 of 36
Below snapshot defines the list of output link used in the job.
A Transformer stage should be used when we need to do some transformation logic like If..Then..Else,UpCase(), CurrentTimestamp(), Null handling and ass igning default values etc.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 26 of 36
Example : Need to do some business validations on data like If..Then..Else, UpCase(), CurrentTimestamp(),Null handling and assigning default values etc.
4. The Modify stage can be used for non-default type conversions, null handling, and character string trimming.
Transformer NULL Handling and Reject Link
When evaluating expressions for output derivations or link constraints, the Transformer will reject (through thereject link indicated by a dashed line) any row that has a NULL value used in the expression. To create aTransformer reject link in DataStage Designer, right-click on an output link and choose “Convert to Reject”.
The Transformer rejects NULL derivation results because the rules for arithmetic and string handling of NULLvalues are by definition undefined. For this reason, always test for null values
before using a column in an expression, for example:
If ISNULL(link.col) Then… Else…
Note that if an incoming column is only used in a pass-through derivation, the Transformer will allow this row tobe output.
Transformer Derivation Evaluation
Output derivations are evaluated BEFORE any type conversions on the assignment. For example, thePadString function uses the length of the source type, not the target. Therefore, it is important to make sure thetype conversion is done before a row reaches the Transformer.
For example, TrimLeadingTrailing (string) works only if string is a VarChar field. Thus, the incoming columnmust be type Varchar before it is evaluated in the Transformer.
Conditionally Aborting Jobs
The Transformer can be used to conditionally abort a job when incoming data matches a specific rule. Create anew output link that will handle rows that match the abort rule. Within the link constraints dialog box, apply theabort rule to this output link, and set the “Abort After Rows ” count to the number of rows allowed before the jobshould be aborted (e.g. 1).
Since the Transformer will abort the entire job flow immediately, it is possible that valid rows will not have beenflushed from Sequential File (export) buffers, or committed to database tables. It is important to set theSequential File buffer flush (see section 7.3) or database commit parameters.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 27 of 36
4.7 Sort Stage
• Try not to use a sort stage when you can use an ORDER BY clause in the database.• Sort the data as much as possible in DB and reduced the use of DS-Sort for better performance of jobs.• If necessary sorting can also be done on the input links of the stages by using the properties tab of the
stage. This can be done when some simple sorting or partitioning has to be done and only if some complexsorting has to be done then only use the SORT STAGE.
• If data has already been partitioned and sorted on a set of key columns, specify the ″don’t sort, previouslysorted″ option for the key columns in the Sort stage. This reduces the cost of sorting.
• When writing to parallel data sets, sort order and partitioning are preserved. But when reading from thesedata sets, try to maintain this sorting if possible by using Same partitioning method.
• Use hash partitioning on key columns for the Sort stage.
For example, assume you sort a data set on a system with four processing nodes and store the results to a dataset stage. The data set will therefore have four partitions. You then use that data set as input to a stageexecuting on a different number of nodes, possibly due to node constraints. DataStage automatically repartitionsa data set to spread out the data set to all nodes in the system, unless you tell it not to, possibly destroying thesort order of the data. You could avoid this by specifying the Same partitioning method. The stage does notperform any repartitioning as it reads the input data set; the original partitions are preserved.
4.8 DataSet• The Data Set stage allows you to store data being operated on in a persistent form, which can then be used
by other WebSphere DataStage jobs.• Data sets are operating system files, each referred to by a control file, which by convention has the suffix
.ds. These files are stored on multiple disks in your system.• A data set is organized in terms of partitions and segments. Each partition of a data set is stored on a single
processing node. Each data segment contains all the records written by a single WebSphere DataStage job.So a segment can contain files from many partitions, and a partition has files from many segments.
• As the dataset store the values across the nodes and it is tough to view the data in UNIX.
4.9 Change Data Capture StageChange Capture stage compares two dataset based on key columns provided and marks the differences usinga change code.
• If the key column is available in both datasets, then it is marked for update, CHANGE_CODE = 3• If the key column is available in the target and not in the source dataset, then it is marked for delete,
CHANGE_CODE = 2• If the source dataset has a key values that is not available in the target, then the record is marked for insert,
CHANGE_CODE= 1
Note1: Change data capture stage does not insert, update or delete records from the dataset or table. It onlyadds an extra column, CHANGE_CODE and records the change.To apply changes, you will have to use a DB2 stage as target.
Note2 : Change data capture can be used to compare identical data sets. By dataset we do not mean theDataStage dataset but any set or records, flat files, database input or DataStage datasets.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 28 of 36
4.10 CDC Vs UPSERT mode in DB2 stagesThere are different ways of capturing the inserts and updates on a table and there is no one particular stage thatis correct for all scenarios. What a CDC does can also be achieved by using the UPSERT mode of DB2 stage.
UPSERT operates on a record-by-record basis where in it tries to update first and if the update fails it inserts therecord. Alternatively, you could change the order to insert first and update when the insert fails to meet yourbusiness logic.
CDC on the other hand compares the source and target and identifies the insert, update and delete records.Once the records are identified, they could be processed by separate DB2 stages to insert, update or delete.The inserts or updates can then be handles in a batch mode, saving some crucial load time. Though the CDCcomparison up-front uses system resources and time, the batch mode inserts and updates compensate the timeloss.If the incoming file is incremental data only, then processing records for no change and delete does not makesense. You could set the Drop Output for Copy and Drop Output for Delete to True.
Consider the following points before making your decision.• How many records would you be processing in this job? If the number of records is 100000 or less then
choose UPSERT to CDC• Consider if you will be using just the key column(s) to identify the change or would you want to compare the
entire row to row? Consider CDC over UPSERT if you will compare the entire source record to the targetrecord to identify the changes.
• What percentage of records being processed are updates? This could be a definitive figure, say 95% fortoday and few months to come. But in the long run, say 3 years down the line , will the percentage ofupdates or inserts remain the same? As it is hard to predict this, jobs are developed to cope with any insert/update percentage fluctuations. CDC is a better candidate in designing for such changes.
4.11 Parameter SetsParameters help in eliminating hard coding and reducing redundancy. Prior to version 8, parameters could beset at a job and at the project level. The following parameters were handled at the project levelSource/Target database connection detailsInput and Output directory paths
However, when project moved coded from one environment to another, all the parameter values had to bechanged to with the new environment details.
Parameter sets help in reducing this effort. You could define the parameters as sets and assign value sets.
For example: for database connectivity you need,• SERVER_NAME• USER_ID• PASSWORD
You know that these details are different in development, test and production environment. You create aparameter set with the three parameters and assign value sets to them. So the next time you run a job,Datastage will prompt you which value set to be used to for this parameter set and it assigns the correspondingvalues to the parameters.
For instance consider a Parameter Set “DATABASE_CONNECTIVITY” has been defined at Project level andwill be used with the jobs under that project.At runtime the user will be asked to select a value from a dropdown list (e.g. DEV,TEST,PROD). Once theselection is made, the corresponding parameter settings will be used for that job execution. Otherwise if nothingis selected the default values will be used.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 29 of 36
If “DEV” is selected from the “Value” drop down list above, the development server name, user name andpassword will be passed to the job as parameter as shown below.
If no selection is made from the “Value” drop down list, then the default server name, user name and passwordwill be passed as shown below.
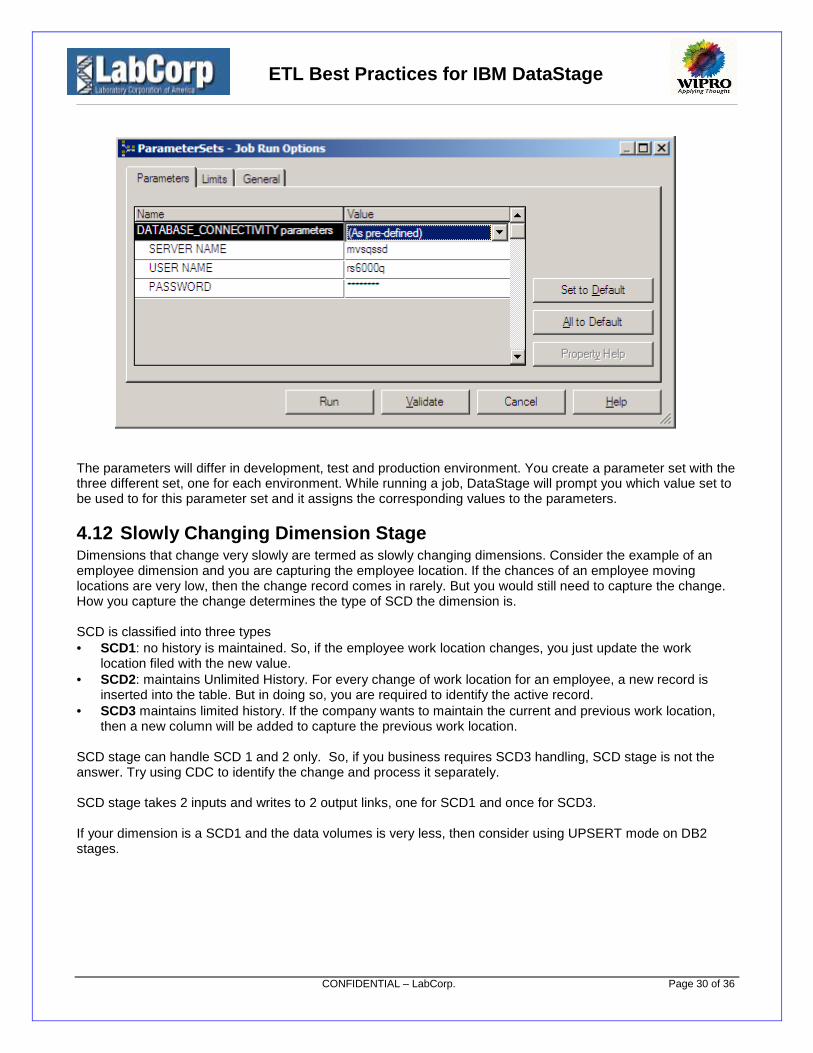
ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 30 of 36
The parameters will differ in development, test and production environment. You create a parameter set with thethree different set, one for each environment. While running a job, DataStage will prompt you which value set tobe used to for this parameter set and it assigns the corresponding values to the parameters.
4.12 Slowly Changing Dimension StageDimensions that change very slowly are termed as slowly changing dimensions. Consider the example of anemployee dimension and you are capturing the employee location. If the chances of an employee movinglocations are very low, then the change record comes in rarely. But you would still need to capture the change.How you capture the change determines the type of SCD the dimension is.
SCD is classified into three types• SCD1: no history is maintained. So, if the employee work location changes, you just update the work
location filed with the new value.• SCD2: maintains Unlimited History. For every change of work location for an employee, a new record is
inserted into the table. But in doing so, you are required to identify the active record.• SCD3 maintains limited history. If the company wants to maintain the current and previous work location,
then a new column will be added to capture the previous work location.
SCD stage can handle SCD 1 and 2 only. So, if you business requires SCD3 handling, SCD stage is not theanswer. Try using CDC to identify the change and process it separately.
SCD stage takes 2 inputs and writes to 2 output links, one for SCD1 and once for SCD3.
If your dimension is a SCD1 and the data volumes is very less, then consider using UPSERT mode on DB2stages.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 31 of 36
5 Job Representation
1. If too many stages are being used in a Job, then try splitting the job into multiple jobs.15 stages in a job isgood number to start with. If your requirement cannot be handled with multiple jobs, try grouping the stagesto local containers to reduce the number of stages on the job canvas.
2. Annotations should be added to all the complex logic stages.3. Add the short description on all the jobs4. Add the job version history in the Full description capturing the following information
• User Name: Name of the user who changed the job• Description: the brief description of the change• Date of change: Data on which the change was done• Reason: Reason to change the job
� Defect� Business Logic Change� New Business Requirement

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 32 of 36
6 Performance Tuning
6.1 General♦ When dealing with large volume of data, consider separating the extract, transform and load operations and
using dataset for capturing the intermediate results. This will help in job maintenance and handling jobrestartability.
♦ Stage the data coming from ODBC, OCI, DB2, UDB stages or any database on the server using Hash /Sequential files for optimum performance also for data recovery in case job aborts.
♦ Filter the rows and columns that will not be used from source as early as possible in the job. For example, Ifpossible, when reading from databases, use a select list to read just the columns required, rather than theentire table. Please refer to section 4.3.4.2 for more details.
♦ If a sub-query is being used in multiple jobs, store the result set of the sub-query in a dataset and use thatdataset instead.
♦ Convert some of the complex joins in DS into jobs and populate tables, which can be further used asreference stages for lookups or joins.
♦ If an input file has an excessive number of rows and can be split-up then use standard logic to run jobs inparallel. For example, if you are reading a large data file containing data for the whole year and can be splitto multiple files based on the monthly data. In this case you can specify the Unix command grep “Month”(viz. grep “January” ) to limit each sequential file to have only the records of a particular month and in thejob you can specify 12 sequential file stages, one for each month. This will ensure that the single sequentialfile will be read and processed in parallel thus saving time.
♦ Unnecessary stages need to be avoided like unnecessary transformations and redundant functions. Pleaserefer to Section 4.6 for the sparing use of transformer stage.
♦ Use of lookup over join for small amount of reference data is more efficient. Please refer to section 4.5 fordetails.
♦ Share the load of query properly with DataStage; it would be a better to implement the logic in DataStageinstead of writing a complex query.
ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 33 of 36
♦ Also one of the main flaws in a job design, which eventually hampers the performance of the job, is ofunnecessary usage of Staging area; ideally Datasets need to be used for any intermediate data unless yourequire the data in the database for audit trail.
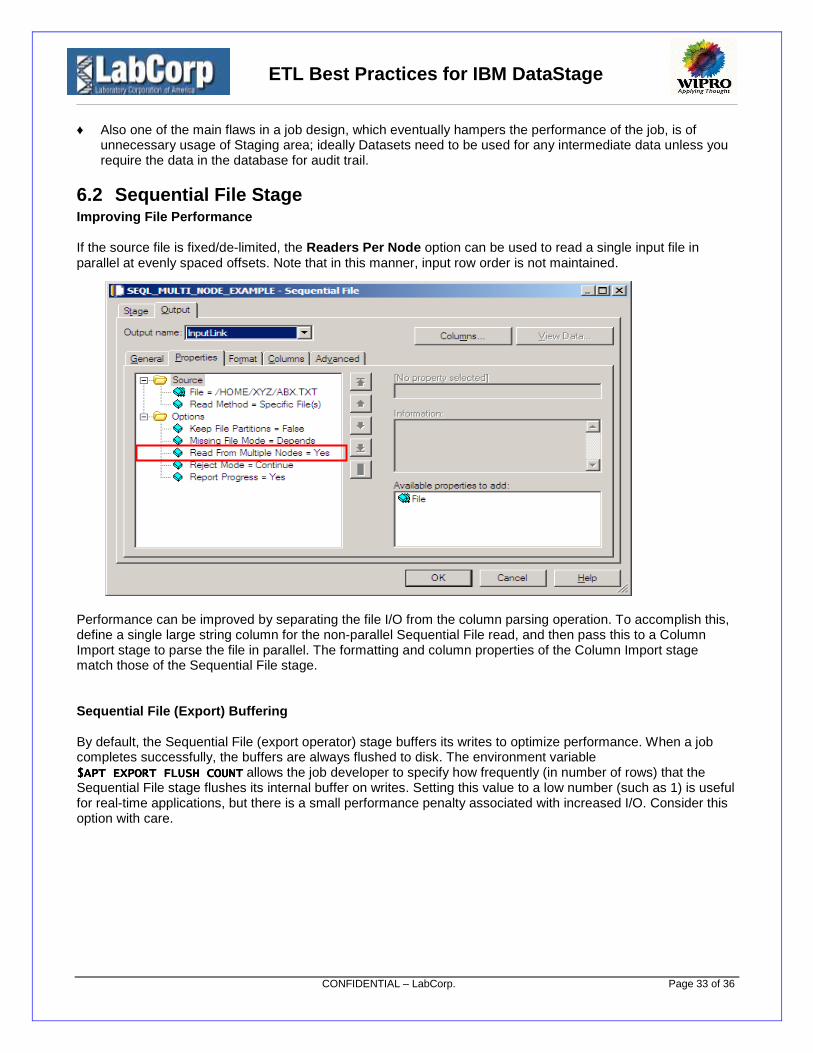
6.2 Sequential File StageImproving File Performance
If the source file is fixed/de-limited, the Readers Per Node option can be used to read a single input file inparallel at evenly spaced offsets. Note that in this manner, input row order is not maintained.
Performance can be improved by separating the file I/O from the column parsing operation. To accomplish this,define a single large string column for the non-parallel Sequential File read, and then pass this to a ColumnImport stage to parse the file in parallel. The formatting and column properties of the Column Import stagematch those of the Sequential File stage.
Sequential File (Export) Buffering
By default, the Sequential File (export operator) stage buffers its writes to optimize performance. When a jobcompletes successfully, the buffers are always flushed to disk. The environment variable$APT_EXPORT_FLUSH_COUNT$APT_EXPORT_FLUSH_COUNT$APT_EXPORT_FLUSH_COUNT$APT_EXPORT_FLUSH_COUNT allows the job developer to specify how frequently (in number of rows) that theSequential File stage flushes its internal buffer on writes. Setting this value to a low number (such as 1) is usefulfor real-time applications, but there is a small performance penalty associated with increased I/O. Consider thisoption with care.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 34 of 36
6.3 Complex Flat File Stage
Improving File Performance
If the source file is fixed/de-limited, the Multiple Node Reading sub section under the File options can be usedto read a single input file in parallel at evenly spaced offsets. Note that in this manner, input row order is notmaintained.
Performance can be improved by separating the file I/O from the column parsing operation. To accomplish this,define a single large string column for the non-parallel Sequential File read, and then pass this to a ColumnImport stage to parse the file in parallel. The formatting and column properties of the Column Import stagematch those of the Complex Flat File stage.

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 35 of 36
6.4 DB2 UDB APIThe recommendation is to separate the extract, transform and load operations. However, if the data volumesare less than 100000 records then extraction, transformation and loading could be clubbed.In doing so, the same table may be used as a lookup and as a target. This will impact the new and changedrecord identification. In order to ensure that the new records inserted into the table are not considered by thelookup, ensure that the TRANSACTION ISOLATION is set to CURSOR STABILITY as shown in the screenshotbelow

ETL Best Practices for IBM DataStage
CONFIDENTIAL – LabCorp. Page 36 of 36
6.5 DB2 ENTERPRISE STAGE
Array Size and Row commit Interval should be set as per the volume of the records to be inserted. It isadvised that these options are set at a job level instead of project level. Set the options to a large value whendealing with large volume of data.
For an example if 100,000 or more records are loaded to the database then the Row commit Interval andArray size may be set to 10,000 or more for better performance.This reduces the I/O cycles between the ETL and Database servers.

![IBM Information Server WebSphere DataStage 81].0_Overview.pdf · IBM Information Server WebSphere DataStage 8.0 Richard Hedges Program Director, Product Management IBM Information](https://static.fdocuments.in/doc/165x107/5a6fade27f8b9ab6538b4fe4/ibm-information-server-websphere-datastage-8-10overviewpdfpdf.jpg)
















