
Edinburgh mt lecture 9: features
64
a north . the was and was the the the though the , the sky However , the sky remained clear under the strong north wind . Despite the strong northerly winds , the sky remains very clear . The sky was still crystal clear , though the north wind was howling . Although a north wind was howling , the sky remained clear and blue . Precision: 11/15 tokens 4/14 bigrams 1/13 trigrams Recall: BLEU
-
Upload
alopezfoo -
Category
Technology
-
view
243 -
download
3
Transcript of Edinburgh mt lecture 9: features

a north . the was and was the the the though the , the sky
However , the sky remained clear under the strong north wind .
Despite the strong northerly winds , the sky remains very clear .
The sky was still crystal clear , though the north wind was howling .
Although a north wind was howling , the sky remained clear and blue .
Precision: 11/15 tokens4/14 bigrams1/13 trigrams
Recall: BLEU

Why Not Use all Translations?(Dreyer & Marcu ’12)

Why Not Use all Translations?
el primer ministro italiano Silvio Berlusconi
(Dreyer & Marcu ’12)

〈PM〉 〈IT〉 〈SB〉
Why Not Use all Translations?
el primer ministro italiano Silvio Berlusconi
(Dreyer & Marcu ’12)

〈PM〉 〈IT〉 〈SB〉
Why Not Use all Translations?
el primer ministro italiano Silvio Berlusconi
〈PM〉 → prime-minister〈PM〉 → PM〈PM〉 → prime minister〈PM〉 → head of government〈PM〉 → premier
〈IT〉 → Italian
〈SB〉 → Silvio Berlusconi〈SB〉 → Berlusconi
(Dreyer & Marcu ’12)

〈PM〉 〈IT〉 〈SB〉
Why Not Use all Translations?
el primer ministro italiano Silvio Berlusconi
〈PM〉 → prime-minister〈PM〉 → PM〈PM〉 → prime minister〈PM〉 → head of government〈PM〉 → premier
〈IT〉 → Italian
〈SB〉 → Silvio Berlusconi〈SB〉 → Berlusconi
〈S〉 → 〈SB〉 , 〈IT〉 〈PM〉〈S〉 → 〈IT〉 〈PM〉 〈SB〉〈S〉 → the 〈IT〉 〈PM〉 , 〈SB〉〈S〉 → the 〈PM〉 of Italy
(Dreyer & Marcu ’12)

HyTER
•Entire set is exponential, but finite.
•Can be encoded as an FST.
•Then compute edit distance as FST composition!

HyTER statistics
•3-4 annotators per sentence.
•2-3 hours per annotator per sentence.
•>1M translations per annotator per sentence.
•>1B translations per sentence (combined).
•Shockingly low overlap between annotators (~10K).

Summary of evaluation•Evaluating machine translation is really, really hard.
•Human evaluation: expensive, slow, unreproducible. But arguably what we want.
•Automatic evaluation: fast, cheap, consistent. But might not have anything to do with what we want.
•It’s also really, really important.
•It’s easier to improve what you measure.
•Research funding often driven by evaluation.
•What should we be measuring?

Feature-Based Models

•Some (not all) key ingredients in Google Translate:
•Phrase-based translation models
•... Learned heuristically from word alignments
•... Coupled with a huge language model
•... And very tight pruning heuristics
•Today: more flexible parameterizations.

p(English|Chinese) ∼
p(English) × p(Chinese|English)
Bayes’ Rule
translation modellanguage model

English
p(Chinese|English)

English
p(Chinese|English)
× p(English)

English
p(Chinese|English)
× p(English)
� p(English|Chinese)

English
p(Chinese|English)1
× p(English)1
� p(English|Chinese)
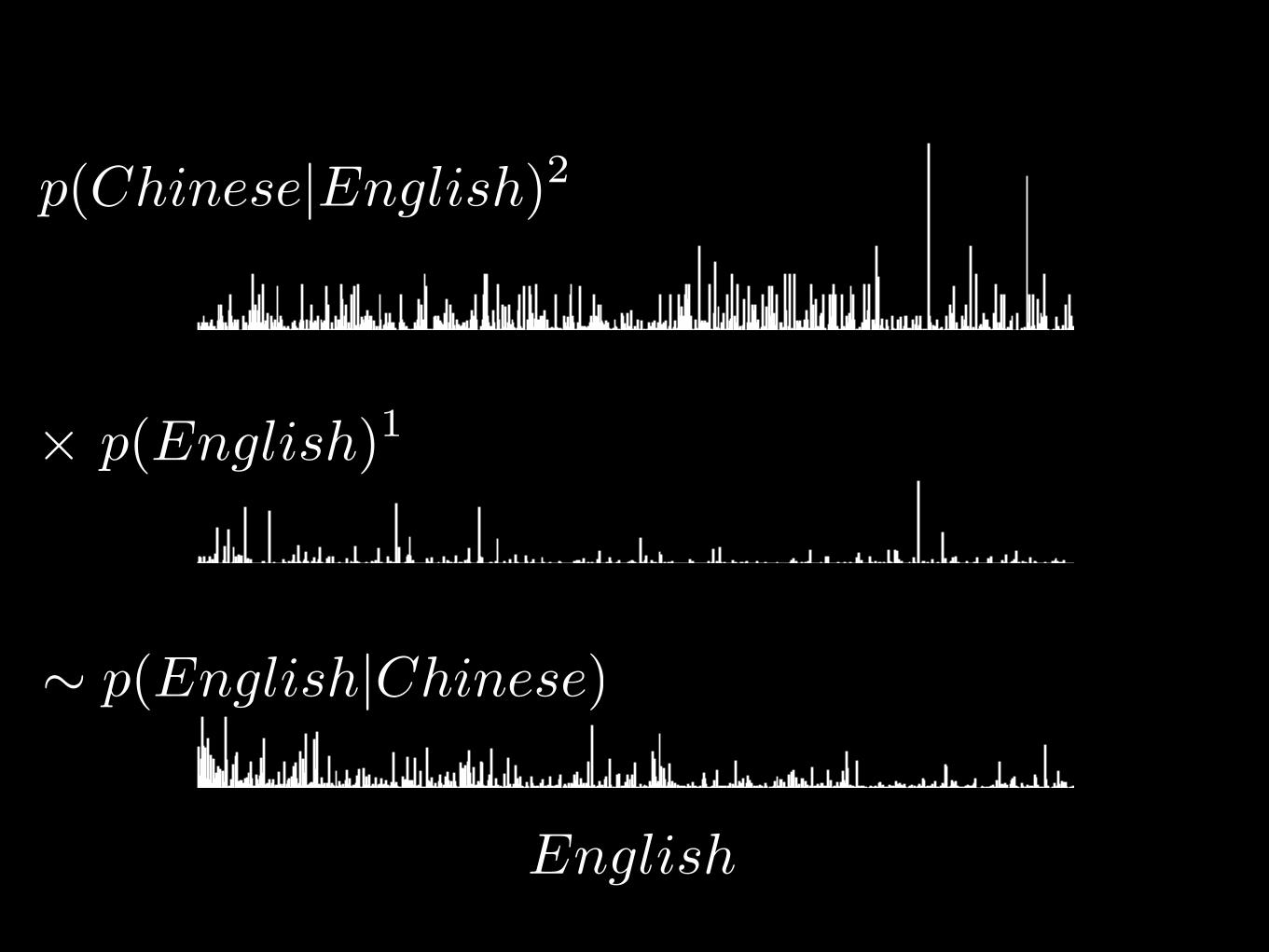
English
p(Chinese|English)2
× p(English)1
� p(English|Chinese)

English
p(Chinese|English)1/2
× p(English)1
� p(English|Chinese)

English
p(Chinese|English)0
× p(English)1
� p(English|Chinese)

English
0 · log p(Chinese|English)
+1 · log p(English)
⇠ log p(English|Chinese)

English
0 · log p(Chinese|English)
+1 · log p(English)
⇠ log p(English|Chinese)
log(x) is monotonic for positive x:log(x) > log(y) iff x>y

English
0 · log p(Chinese|English)
+1 · log p(English)
⇠ log p(English|Chinese)
log(x) is monotonic for positive x:log(x) > log(y) iff x>y
Local historic footnote: logarithms were invented in Edinburgh by John Napier,
whose ancient family home in Merchiston is now part of Edinburgh Napier University.

English
0 · log p(Chinese|English)
+1 · log p(English)
⇠ log p(English|Chinese)
log(x) is monotonic for positive x:log(x) > log(y) iff x>y

English
0 · log p(Chinese|English)
+1 · log p(English)
= score(English|Chinese)

score(English|Chinese) =
�1 log p(Chinese|English) + �2 log p(English)

score(English|Chinese) =
exp(�1 log p(Chinese|English) + �2 log p(English))

exp(�1 log p(Chinese|English) + �2 log p(English))
X
English
exp(�1 log p(Chinese|English) + �2 log p(English))
p(English|Chinese) =

exp(�1 log p(Chinese|English) + �2 log p(English))
X
English
exp(�1 log p(Chinese|English) + �2 log p(English))
p(English|Chinese) =
log-linear modelmaximum entropy modelconditional random field
undirected model

p(English|Chinese) =
log-linear modelmaximum entropy modelconditional random field
undirected model
p(English) × p(Chinese|English)
Note: Original model is a special case of this model!

exp(�1 log p(Chinese|English) + �2 log p(English))
X
English
exp(�1 log p(Chinese|English) + �2 log p(English))
p(English|Chinese) =
log-linear modelmaximum entropy modelconditional random field
undirected model
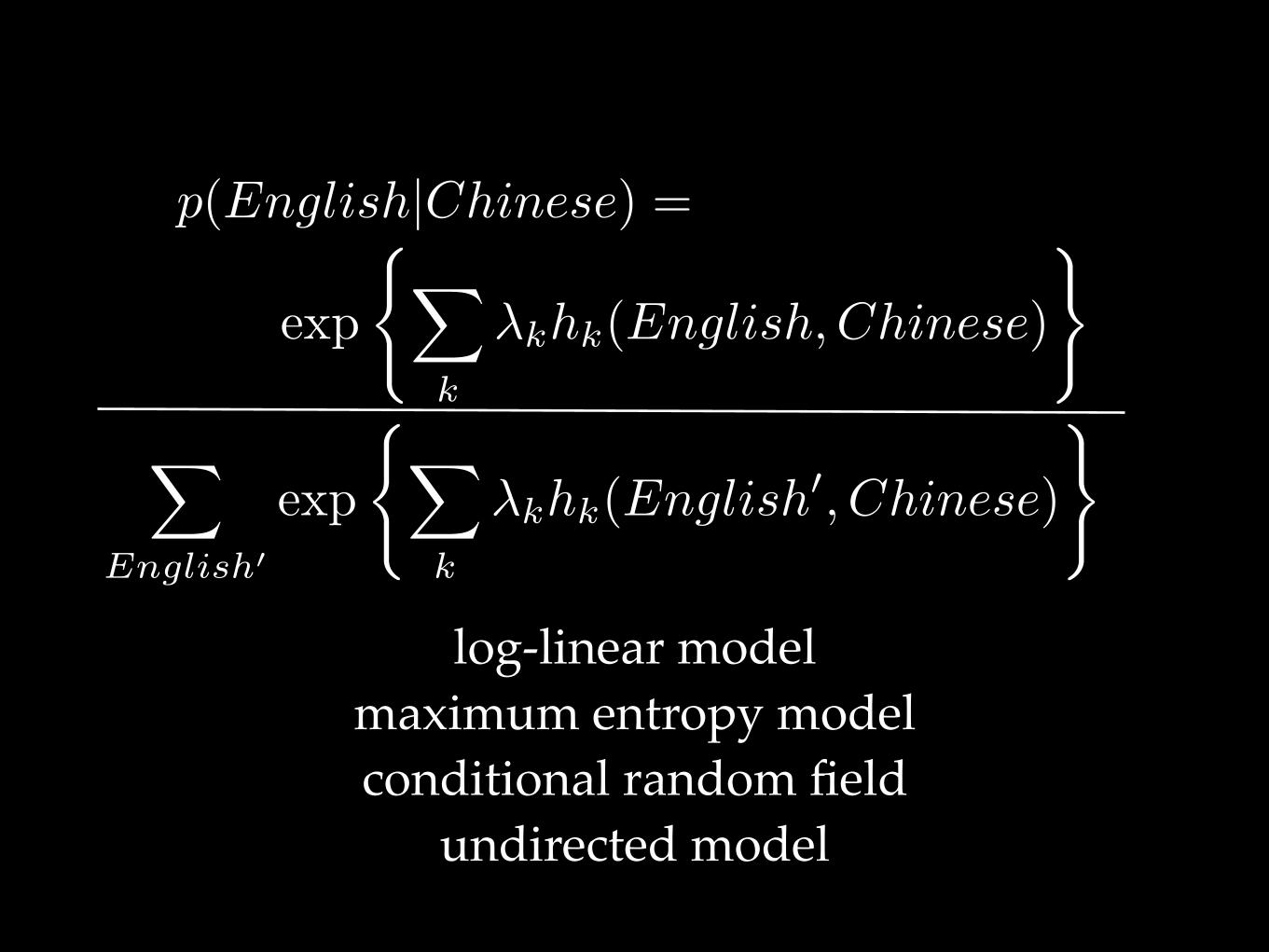
p(English|Chinese) =
log-linear modelmaximum entropy modelconditional random field
undirected model
exp
(X
k
�khk(English, Chinese)
)
X
English0
exp
(X
k
�khk(English0, Chinese)
)

p(English|Chinese) =
log-linear modelmaximum entropy modelconditional random field
undirected model
1
Zexp
(X
k
�khk(English, Chinese)
)

p(English|Chinese) =
log-linear modelmaximum entropy modelconditional random field
undirected model
1
Zexp
(X
k
�khk(English, Chinese)
)
Z is the normalization term or partition function

p(English|Chinese) =
1
Zexp
(X
k
�khk(English, Chinese)
)
Z is the normalization term or partition function
The functions hk are features or feature functionsThey are deterministic (fixed) functions of the
input/output pair.
The parameters of the model are the terms.�k

What’s a Feature?

What’s a Feature?A feature can be any function in the form:
hk : English⇥ Chinese! R+

What’s a Feature?
•Language model: p(English)
A feature can be any function in the form: hk : English⇥ Chinese! R+

What’s a Feature?
•Language model: p(English)
•Translation model: p(Chinese|English)
A feature can be any function in the form: hk : English⇥ Chinese! R+

What’s a Feature?
•Language model: p(English)
•Translation model: p(Chinese|English)
•Reverse translation model: p(English|Chinese)
A feature can be any function in the form: hk : English⇥ Chinese! R+

What’s a Feature?
•Language model: p(English)
•Translation model: p(Chinese|English)
•Reverse translation model: p(English|Chinese)
•The number of words in the English sentence.
A feature can be any function in the form: hk : English⇥ Chinese! R+

What’s a Feature?
•Language model: p(English)
•Translation model: p(Chinese|English)
•Reverse translation model: p(English|Chinese)
•The number of words in the English sentence.
•The number of verbs in the English sentence.
A feature can be any function in the form: hk : English⇥ Chinese! R+

What’s a Feature?
•Language model: p(English)
•Translation model: p(Chinese|English)
•Reverse translation model: p(English|Chinese)
•The number of words in the English sentence.
•The number of verbs in the English sentence.
•1 if the English sentence has a verb, 0 otherwise.
A feature can be any function in the form: hk : English⇥ Chinese! R+

What’s a Feature?A feature can be any function in the form:
hk : English⇥ Chinese! R+

What’s a Feature?
•A word-based translation model: p(Chinese|English)
A feature can be any function in the form: hk : English⇥ Chinese! R+

What’s a Feature?
•A word-based translation model: p(Chinese|English)
•Agreement features in the English sentence.
A feature can be any function in the form: hk : English⇥ Chinese! R+

What’s a Feature?
•A word-based translation model: p(Chinese|English)
•Agreement features in the English sentence.
•Features over part-of-speech sequences in the English sentence.
A feature can be any function in the form: hk : English⇥ Chinese! R+

What’s a Feature?
•A word-based translation model: p(Chinese|English)
•Agreement features in the English sentence.
•Features over part-of-speech sequences in the English sentence.
•How many times the sentence pair includes the English word north and Chinese word 北.
A feature can be any function in the form: hk : English⇥ Chinese! R+

What’s a Feature?
•A word-based translation model: p(Chinese|English)
•Agreement features in the English sentence.
•Features over part-of-speech sequences in the English sentence.
•How many times the sentence pair includes the English word north and Chinese word 北.
•Do words north and 北 appear in a dictionary?
A feature can be any function in the form: hk : English⇥ Chinese! R+

Learning
arg max
✓
1
Zexp
(X
k
�khk(English, Chinese)
)
✓ = h�1, ...,�Kiwhere:

Learning
arg max
✓
1
Zexp
(X
k
�khk(English, Chinese)
)
✓ = h�1, ...,�Kiwhere:
Techniques: SGD, L-BFGS

Learning
arg max
✓
1
Zexp
(X
k
�khk(English, Chinese)
)
✓ = h�1, ...,�Kiwhere:
Techniques: SGD, L-BFGS
Require computing derivatives (expectations!), iterating.

Problems

Problems
•Inference is intractable!

Problems
•Inference is intractable!
•Compute over n-best lists of outputs.

Problems
•Inference is intractable!
•Compute over n-best lists of outputs.
•Compute over pruned search graphs.

Problems
•Inference is intractable!
•Compute over n-best lists of outputs.
•Compute over pruned search graphs.
•Reachability: what if data likelihood is zero?

Problems
•Inference is intractable!
•Compute over n-best lists of outputs.
•Compute over pruned search graphs.
•Reachability: what if data likelihood is zero?
•Throw away data.

Problems
•Inference is intractable!
•Compute over n-best lists of outputs.
•Compute over pruned search graphs.
•Reachability: what if data likelihood is zero?
•Throw away data.
•Pretend sentence with highest BLEU score is observed.

Problems

Problems
•Why maximize likelihood if we care about BLEU or some other metric?

BLEU(MT output)

BLEU(argmaxEnglish
score(English|Chinese))

BLEU(argmaxEnglish
score(English|Chinese))1�
Chinese�Test
BLEU

• Ôptimization


















