
Database Readiness Workshop Summary
28
Database Readiness Workshop Summary Dirk Duellmann, CERN IT For the LCG 3D project http://lcg3d.cern.ch GDB meeting, March 8th 06
-
Upload
leo-dorsey -
Category
Documents
-
view
17 -
download
0
description
Database Readiness Workshop Summary. Dirk Duellmann, CERN IT For the LCG 3D project http://lcg3d.cern.ch GDB meeting, March 8th 06. Why a LCG Database Deployment Project?. LCG today provides an infrastructure for distributed access to file based data and file replication - PowerPoint PPT Presentation
Transcript of Database Readiness Workshop Summary

Database Readiness Workshop Summary
Dirk Duellmann, CERN IT
For the LCG 3D project http://lcg3d.cern.ch
GDB meeting, March 8th 06
GDB meeting, 8th March 06 Dirk Duellmann 2
Why a LCG Database Deployment
Project?
• LCG today provides an infrastructure for distributed access to file based data and file replication
• Physics applications (and grid services) require a similar services for data stored in relational databases
– Several applications and services already use RDBMS
– Several sites have already experience in providing RDBMS services
• Goals for common project as part of LCG
– increase the availability and scalability of LCG and experiment components
– allow applications to access data in a consistent, location independent way
– allow to connect existing db services via data replication mechanisms
– simplify a shared deployment and administration of this infrastructure during 24 x 7 operation
• Scope set by PEB
– Online - Offline - Tier sites

GDB meeting, 8th March 06 Dirk Duellmann 3
3D Participants and Responsibilities
• LCG 3D is a joint project between
– Service users: experiments and grid s/w projects
– Service providers: LCG tier sites including CERN
• Project itself has (as all projects) limited resources (2 FTE)
– Mainly coordinating requirement discussions, testbed and production configuration, setup and support
– Rely on experiments/projects to define and validate their application function and requirements
– Rely on sites for local implementation and deployment of testbed and production setup

GDB meeting, 8th March 06 Dirk Duellmann 4
DB Readiness Workshop last Monday
• http://agenda.cern.ch/fullAgenda.php?ida=a058495
• Readiness of the production services at T0/T1
– status reports from tier 0 and tier 1 sites
– technical problems with the proposed setup (RAC clusters)?
– open questions from sites to experiments?
• Readiness of experiment (and grid) database applications
– Application list, code release, data model and deployment schedule
– Successful validation at T0 and (if required T1)?
– Any new deployment problems seen by experiment users which need a service change
• Review site/experiment milestones from the database project plan
– (Re-)align with other work plans - eg experiment challenges, SC4

GDB meeting, 8th March 06
Dirk Duellmann 5
Online-Offline Connection
A well-documented schema was reported at the last LCG3D Workshop
Artwork by Richard Hawkings
Slide : A. Vaniachine
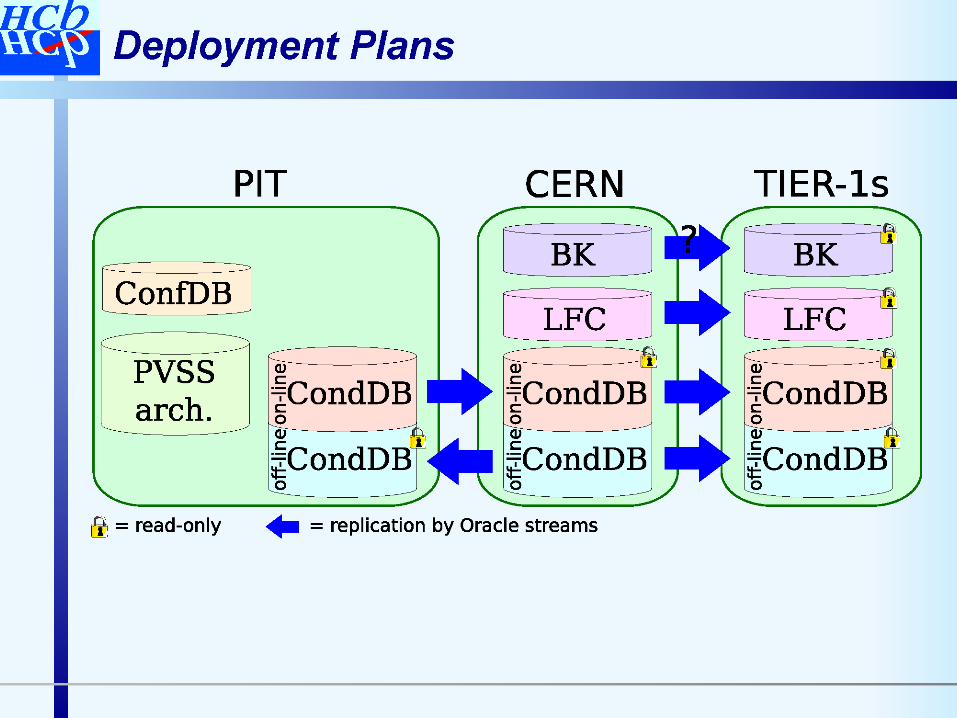
GDB meeting, 8th March 06 Dirk Duellmann 6
GDB meeting, 8th March 06 Dirk Duellmann 7

GDB meeting, 8th March 06
Dirk Duellmann 8
Offline FroNTier Resources/Deployment
• Tier-0: 2-3 Redundant FroNTier servers.• Tier-1: 2-3 Redundant Squid servers.• Tier-N: 1-2 Squid Servers.• Typical Squid server requirements:
– CPU/MEM/DISK/NIC=1GHz/1 GB/100GB/Gbit
– Network: visible to Worker LAN (private network) and WAN (internet)
– Firewall: Two Ports open for URI (FroNTier Launchpad) access and SNMP monitoring (typically 8000 and 3401 respectively)
• Squid non-requirements– Special hardware (although high-throughput
Disk I/O is good)– Cache backup (if disk dies or is corrupted,
start from scratch and reload automatically)• Squid is easy to install and requires little
on-going administration.
Squid(s)Tomcat(s)
Squid Squid Squid
DB
Squid Squid Squid
Tier 0
Tier 1
Tier N
FroNTierLaunchpad
http
JDBC
Slide : Lee Lueking
GDB meeting, 8th March 06 Dirk Duellmann 9
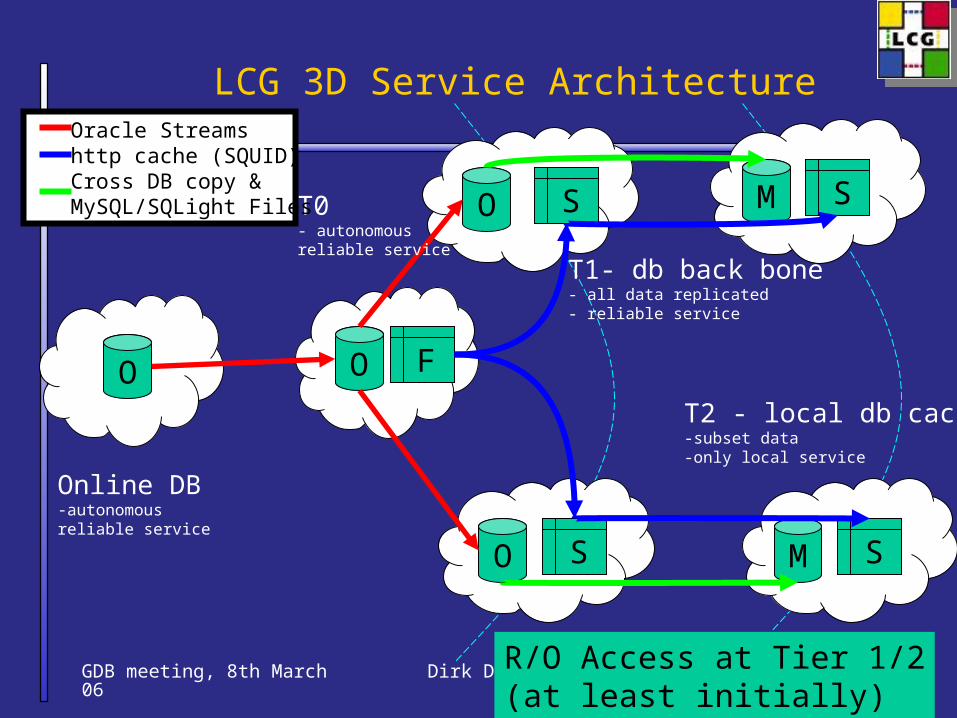
LCG 3D Service Architecture
T2 - local db cache-subset data-only local service
MO
O
O
M
T1- db back bone- all data replicated- reliable service
T0- autonomous reliable service
Oracle Streamshttp cache (SQUID)Cross DB copy &MySQL/SQLight Files
O
Online DB-autonomous reliable service
F
S S
S S
R/O Access at Tier 1/2(at least initially)

GDB meeting, 8th March 06 Dirk Duellmann 10
LCG Database Deployment Plan
• After October ‘05 workshop a database deployment plan has been presented to LCG GDB and MB
– http://agenda.cern.ch/fullAgenda.php?ida=a057112
• Two production phases • April - Sept ‘06 : partial production service
– Production service (parallel to existing testbed)– H/W requirements defined by experiments/projects– Based on Oracle 10gR2– Subset of LCG tier 1 sites: ASCC, CERN, BNL, CNAF, GridKA, IN2P3, RAL
• October ‘06- onwards : full production service– Adjusted h/w requirements (defined at summer ‘06 workshop)
– Other tier 1 sites joined in: PIC, NIKHEF, NDG, TRIUMF

GDB meeting, 8th March 06 Dirk Duellmann 11
Proposed Tier 1 Hardware Setup
• Propose to setup for first 6 month
– 2/3 dual-cpu database nodes with 2GB or more• Setup as RAC cluster (preferably) per experiment• ATLAS: 3 nodes with 300GB storage (after mirroring) • LHCb: 2 nodes with 100GB storage (after mirroring) • Shared storage (eg FibreChannel) proposed to allow for clustering
– 2-3 dual-cpu Squid nodes with 1GB or more• Squid s/w packaged by CMS will be provided by 3D• 100GB storage per node• Need to clarify service responsibility (DB or admin team?)
• Target s/w release: Oracle 10gR2
– RedHat Enterprise Server to insure Oracle support
• Production setups for Castor and Grid Services will be required in addition
– Schedule setup consolidation into SC4 workplan

GDB meeting, 8th March 06 Dirk Duellmann 12
T0 Database Service Evolution
• Until summer 2005
– Solaris based shared Physics DB cluster (2-nodes for HA)• Low CPU power, hard to extend, shared by all experiments
– (many) linux disk servers as DB servers• High maintenance load, no resource sharing, no redundancy
• Now consolidation on extensible database clusters
– No sharing across experiments
– Higher quality building blocks • Midrange PCs (RedHat ES)• FibreChannel attached disk arrays
• As of January- all LHC services moved to RAC
Slide : Maria Girone
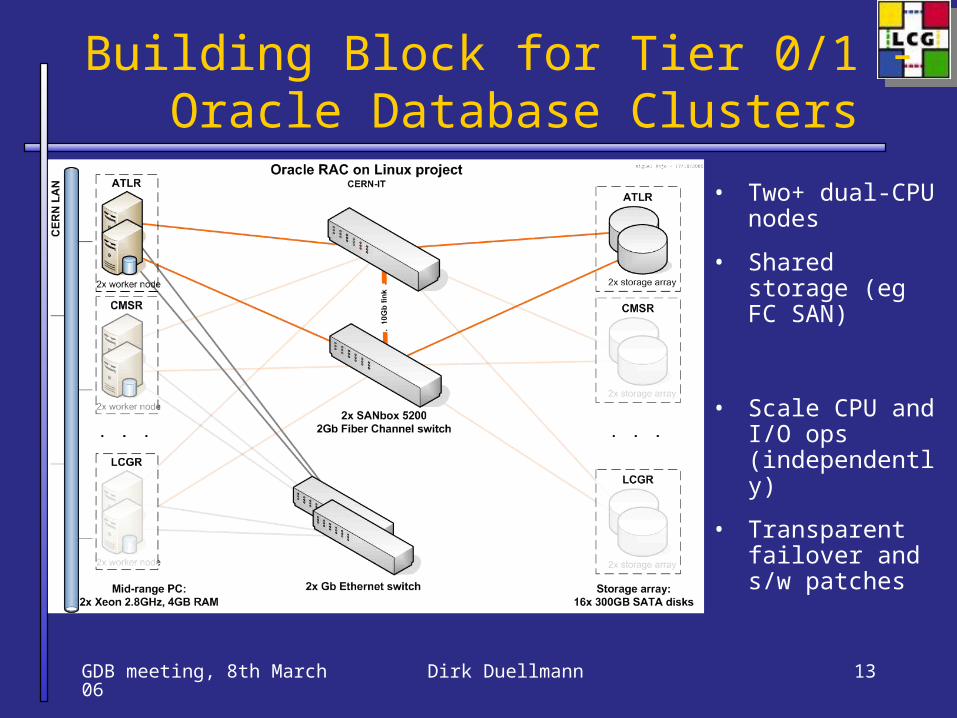
GDB meeting, 8th March 06 Dirk Duellmann 13
Building Block for Tier 0/1 -
Oracle Database Clusters• Two+ dual-CPU
nodes
• Shared storage (eg FC SAN)
• Scale CPU and I/O ops (independently)
• Transparent failover and s/w patches

GDB meeting, 8th March 06 Dirk Duellmann 14
Service Throttling - Resource Usage Reports
• Run into degraded service after single remote user submitted many (idle) jobs
– Defined account profile for larger apps
• Db accounts are shared among many users
– Switched on idle session “sniping” (default = 3h idle time)
• Producing weekly resource overviews to experiment database coordinator
– Allow experiment to prioritize resources and identify unexpected usage patterns
– Which jobs/users got affected by what limit?
Slide : Maria Girone

GDB meeting, 8th March 06 Dirk Duellmann 15
CERN Hardware evolution for 2006
Current State
ALICE ATLAS CMS LHCb Grid 3D Non-LHC Validation
- 2-node offline
2-node 2-node 2-node - - 2x2-node
2-node online test
Pilot on disk server
Proposed structure in Q2 2006 2-node
4-node 4-node 4-node 4--node
2-node 2-node (PDB replacement
)
2-node valid/tes
t
2-node valid/te
st
2-node valid/test
2-node pilot
Compass??
Online?
• Linear ramp-up budgeted for hardware resources in 2006-2008
• Planning next major service extension for Q3 this year
Slide : Maria Girone

GDB meeting, 8th March 06 Dirk Duellmann 16
CERN RAC Expansion for Q2
• New mid-range servers and disk-arrays received and installed
– Under acceptance tests by IT-FIO
• Waiting for additional fibre channel switches (this week)
• Planning the setting up in collaboration with IT-FIO
• Proceed in two steps
– February: Extension of existing RACs with additional CPUs • Almost done!
– March: Creation of new RACs • eg dedicated experiment validation servers• after disk-arrays and switches arrived
Slide : Maria Girone
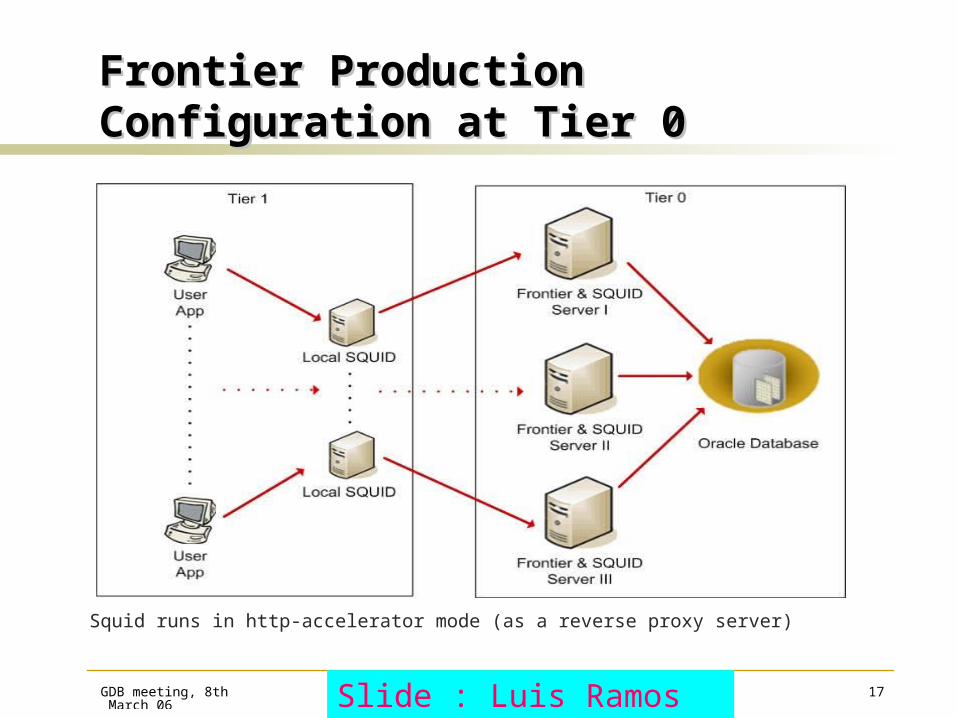
GDB meeting, 8th March 06
Dirk Duellmann 17
Frontier Production Frontier Production Configuration at Tier 0Configuration at Tier 0
Squid runs in http-accelerator mode (as a reverse proxy server)
Slide : Luis Ramos

GDB meeting, 8th March 06 Dirk Duellmann 18
Tier 0 preps
• Database Service extension going according to schedule
– Resource prioritization and extension planning needs experiment involvement (and real deployment experience)
– Significant lead time for h/w orders - need experiment / project requests early!
• Also Streams and Frontier setups proceeding well
– New downstream capture proposal under test - seems promising to avoid some couplings observed in the test bed during site problems
• Need production setup for Database Monitoring (Oracle Grid Control 10gR2)
– Tier 1s may use another local grid control instance
– Two agents reporting into common 3D and local Grid Control

GDB meeting, 8th March 06 Dirk Duellmann 21
Tier 1 Progress
• Sites largely on schedule for a service start end of March
– h/w either installed already (BNL, CNAF, IN2P3) or expect delivery of order shortly (GridKA, RAL)
– Some problems with Oracle Clusters technology encountered and solved!
– Active participation from sites - DBA community building up• First DBA meeting focusing on RAC installation, setup and monitoring hosted by Rutherford scheduled for second half of March
• Need to involve remaining Tier 1 sites now!
– Established contact to PIC, NIKHEF/SARA, NSG, TRIUMF to follow workshops, email and meetings
• Next work shop 23rd of March hosted by RAL
– Focus: finalizing DB Server and monitoring setup at T0 and T1

GDB meeting, 8th March 06 Dirk Duellmann 22
Service Issues
• Oracle Issues
– X.509(proxy) certificates - will they be supported by Oracle?
– s/w and support licenses for Tier 1• Collected info including estimate for Castor / Grid services
– Instant client distribution within LCG• Proposal of possible distribution schemes under discussion in Oracle
– With commercial Oracle contact (IT-DES group) and IT license officer
• Application Server support
– During initial phase (March-Sept) CMS proposed to support tomcat/frontier/squid setup
– Will discuss other experiments requirements

GDB meeting, 8th March 06 Dirk Duellmann 23
Databases in Middleware & Castor
• Took place already for services used in SC3
– Existing setups at the sites
– Existing experience with SC workloads -> extrapolate to real production
• LFC, FTS - Tier 0 and above
– Low volume, but high availability requirements
– CERN: Run on 2-node Oracle cluster; outside single box Oracle or MySQL
• CASTOR 2 - CERN and some T1 sites
– Need to understand scaling up to LHC production rates
– CERN: Run on 3 Oracle servers
• Currently not driving the requirements for the database service
• Need to consolidate databases configs and procedures with (larger) experiment database setups

GDB meeting, 8th March 06 Dirk Duellmann 24
LCG Application s/w Status
• COOL and POOL have released versions based on CORAL
– Includes re-try and failover required for reliable db service use• These features need be tested for experiment • Based so far on XML based list of databases • Prototyping integration with LFC with CAT team (India)
– POOL includes production version FroNTier plug-in• Control of SQUID caching may still be required to implement more
realistic caching policies
– These releases (or bug fixes) are target for 2006 deployment
• LCG s/w expected to be stable by end of February for distributed deployment as part of SC4 or experiment challenges
• Caveats:
– COOL still has important functionality items on the development plan for this year
– Conditions schema stability will need careful planning for COOL and FroNTier

GDB meeting, 8th March 06 Dirk Duellmann 25
Experiment Applications Status
• Conditions - Driving the database service size at T0 and T1
– EventTAGs (may become significant - need replication tests and concrete experiment deployment models)
• Framework integration and DB workload generators exist
– successfully tested in various COOL and POOL/FroNTier tests
– T0 performance and replication tests (T0->T1) looks ok
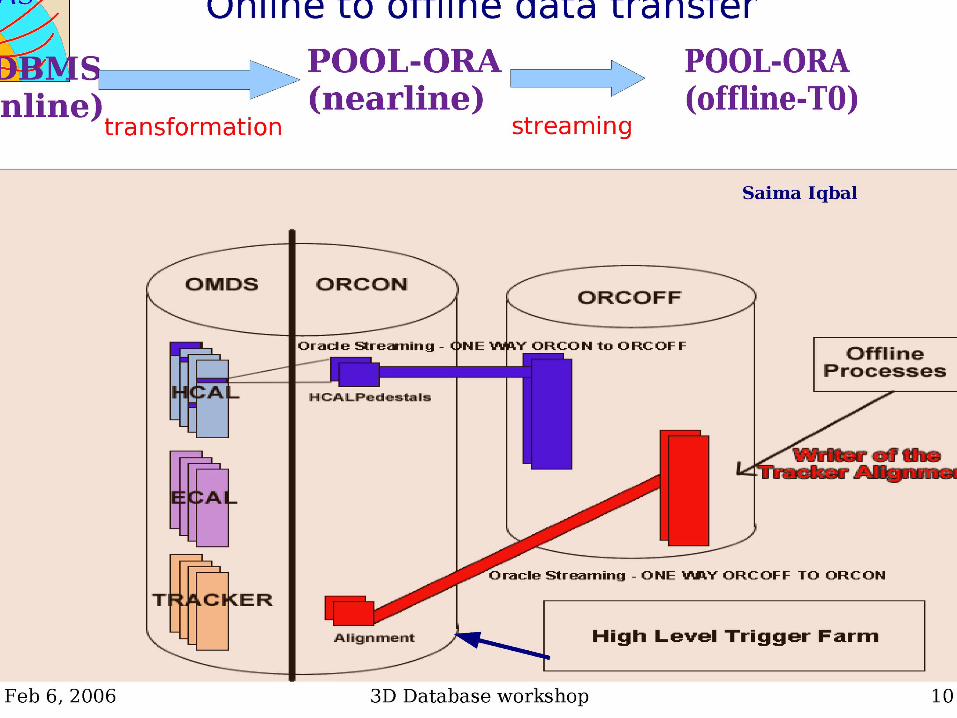
• Conditions: Online -> Offline replication only starting now
– May need additional emphasis for online tests to avoid surprises
– CMS and ATLAS are executing online test plans
• Progress in defining concrete conditions data models
– CMS showed most complete picture (for Magnet Test)
– Still quite some uncertainty about volumes, numbers of clients
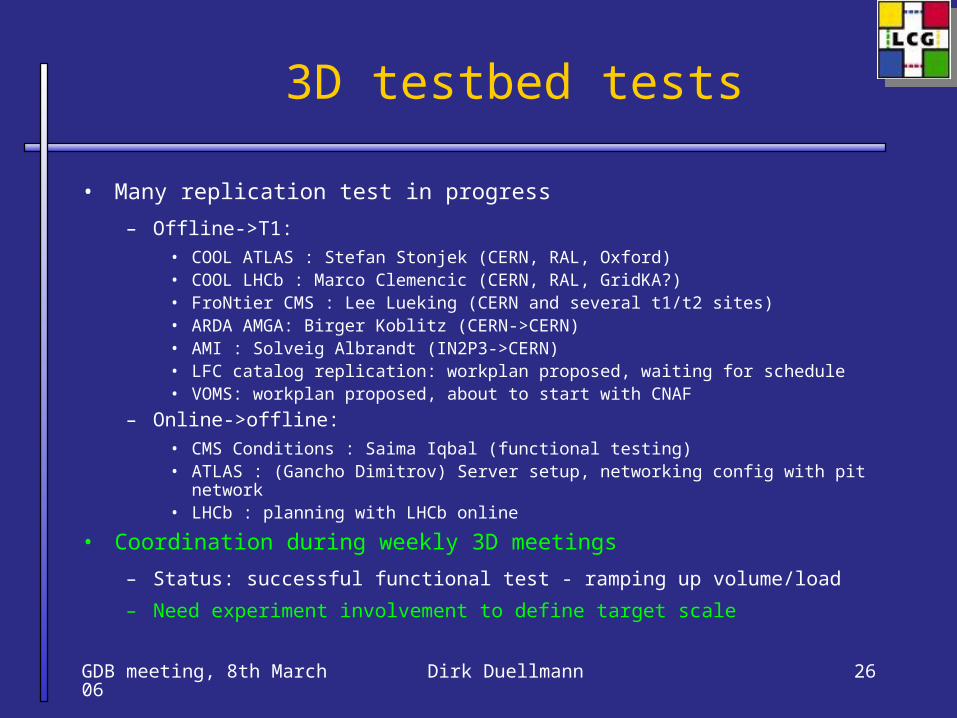
GDB meeting, 8th March 06 Dirk Duellmann 26
3D testbed tests
• Many replication test in progress
– Offline->T1: • COOL ATLAS : Stefan Stonjek (CERN, RAL, Oxford)• COOL LHCb : Marco Clemencic (CERN, RAL, GridKA?)• FroNtier CMS : Lee Lueking (CERN and several t1/t2 sites) • ARDA AMGA: Birger Koblitz (CERN->CERN) • AMI : Solveig Albrandt (IN2P3->CERN)• LFC catalog replication: workplan proposed, waiting for schedule• VOMS: workplan proposed, about to start with CNAF
– Online->offline: • CMS Conditions : Saima Iqbal (functional testing)• ATLAS : (Gancho Dimitrov) Server setup, networking config with pit
network • LHCb : planning with LHCb online
• Coordination during weekly 3D meetings
– Status: successful functional test - ramping up volume/load
– Need experiment involvement to define target scale

GDB meeting, 8th March 06 Dirk Duellmann 27

GDB meeting, 8th March 06 Dirk Duellmann 29
Summary
• Database Production Service and Schedule defined (unchanged since GDB/MB approval)
– Phase 1 - end of March: ASCC, BNL, CERN, CNAF, IN2P3, RAL
– Full deployment - end of September: PIC, NIKHEF, NDG, TRIUMF
• Consolidation with grid service oracle setups
• Setup progressing on schedule at tier 0 and 1 sites
• Application performance tests progressing
• First larger scale conditions replication tests with promising results for streams and frontier technologies
• Concrete conditions data models still missing for key detectors

GDB meeting, 8th March 06 Dirk Duellmann 30
Proposed Milestones / Schedules
• Project Documentation
– 3D Replication Technology Writeup - May ‘06• Test responsible (based on individual test docs)
– Database Service Definition Writeup - June ‘06• Site responsible (based on LCG TDR document)
– Backup/Recovery Strategy Writeup - August ‘06
• CORAL Database Lookup Service (LFC based) - August ‘06
• Conditions (Tags) Deployment Plan (dates from experiment plans)
– Concrete Conditions Data Models for main detectors defined(eg the detectors accounting for 80% in volume/access)
– Conditions deployed at Tier 1s
– Conditions replicated between Online and Offline
• Propose to organise discussion with experiment responsibles

GDB meeting, 8th March 06 Dirk Duellmann 31
“My Conclusions”
• There is little reason to believe that a distributed database service will move into stable production any quicker than any of the other grid services
• Should start now with larger scale production operation to resolve the unavoidable deployment issues
• Need the cooperation of experiments and sites to make sure that concrete requests can be quickly validated against a concrete distributed service


















