
Creating Coarse-Grained Parallelism Chapter 6 of Allen and Kennedy Dan Guez.
53
Creating Coarse- Grained Parallelism Chapter 6 of Allen and Kennedy Dan Guez
-
date post
22-Dec-2015 -
Category
Documents
-
view
231 -
download
1
Transcript of Creating Coarse-Grained Parallelism Chapter 6 of Allen and Kennedy Dan Guez.

Creating Coarse-Grained Parallelism
Chapter 6 of Allen and Kennedy
Dan Guez

Introduction Pervious lectures: Fine-Grained
Parallelism Superscalar and vector architecture Parallelizing Inner loops
This lecture: Coarse-Grained Parallelism Symmetric Multi Processor (SMP)
architecture Parallelizing Outer loops

SMP Architecture
Multiple asynchronous Processors Shared memory Synchronization required!
Communication between processors Barrier as synchronization mechanism Expensive!

Roadmap
Single Loop Methods Privatization Alignment Loop Fusion
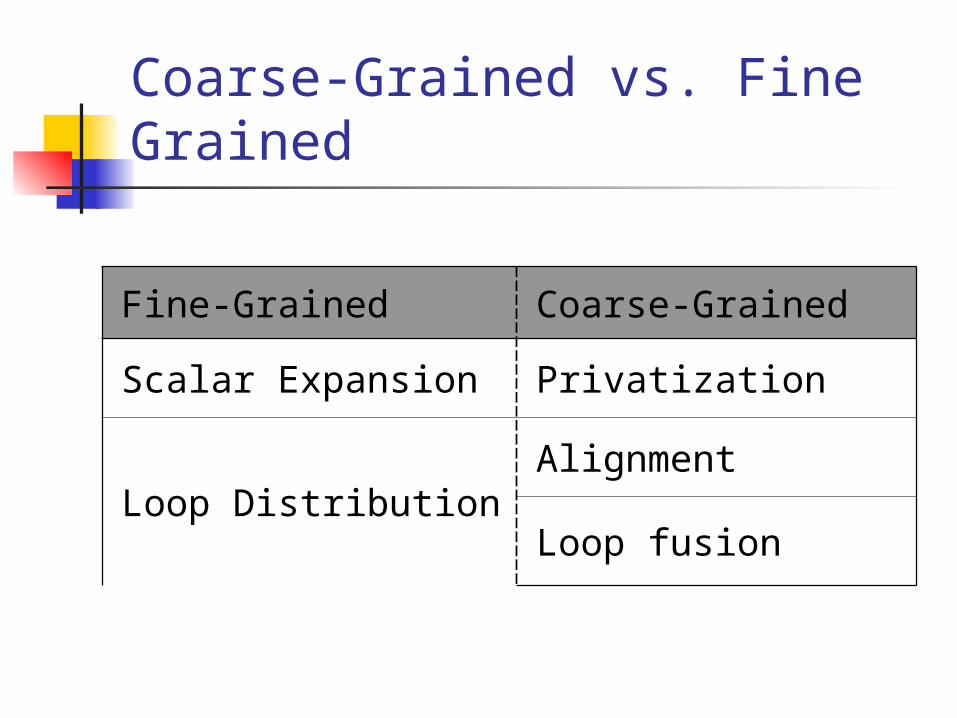
Coarse-Grained vs. Fine Grained
Coarse-GrainedFine-Grained
PrivatizationScalar Expansion
AlignmentLoop Distribution
Loop fusion

Roadmap
Privatization Alignment Loop Fusion

Scalar Expansion - Reminder
Scalar Expansion – loop carried dependences elimination+ vectorizaion
DO I = 1, NT = A(I)A(I) = B(I)B(I) = T
ENDDO
DO I = 1, NT(I) = A(I)A(I) = B(I)B(I) = T(I)
ENDDO
T(1:N) = A(1:N)A(1:N) = B(1:N)B(1:N) = T(1:N)
Scalar
Expansion
Vectoring

Privatization Privatization - loop carried
dependences elimination
DO I = 1, NT = A(I)A(I) = B(I)B(I) = T
ENDDO
PARALLEL DO I = 1, NPRIVATE tt = A(I)A(I) = B(I)B(I) = t
END PARALLEL DO
Privatization

Privatization - Definition
A scalar variable x defined within a loop is said to be privatizable with respect to that loop if and only if every path from the beginning of the loop body to a use of x within the loop body must pass through a definition of x before reaching that use

Privatization – formal solution For each block x in the loop body
define equation (upward-exposed variables):
use(x) – the set of all variables used within block x that have no prior definitions within the block
def(x) – variables defined in x Solve the above equations…

Privatization – formal solution
The set of private variables is:
B – collection of loop body blocks b0 – the entry block to the loop body

Privatization - Theorem
A variable x defined in a loop may be made private if and only if the SSA graph for the variable does not have a Φ-node at the entry to the loop

Roadmap
Privatization Alignment Loop Fusion

Loop Distribution
Distributing loops using codegen
DO I = 1, 100DO J = 1, 100
A(I,J) = B(I,J) + C(I,J)D(I,J) = A(I,J-1) *2
ENDDOENDDO
codegenDO I = 1, 100
DO J = 1, 100A(I,J) = B(I,J) + C(I,J)
ENDDODO J = 1, 100
D(I,J) = A(I,J-1) *2ENDDO
ENDDO
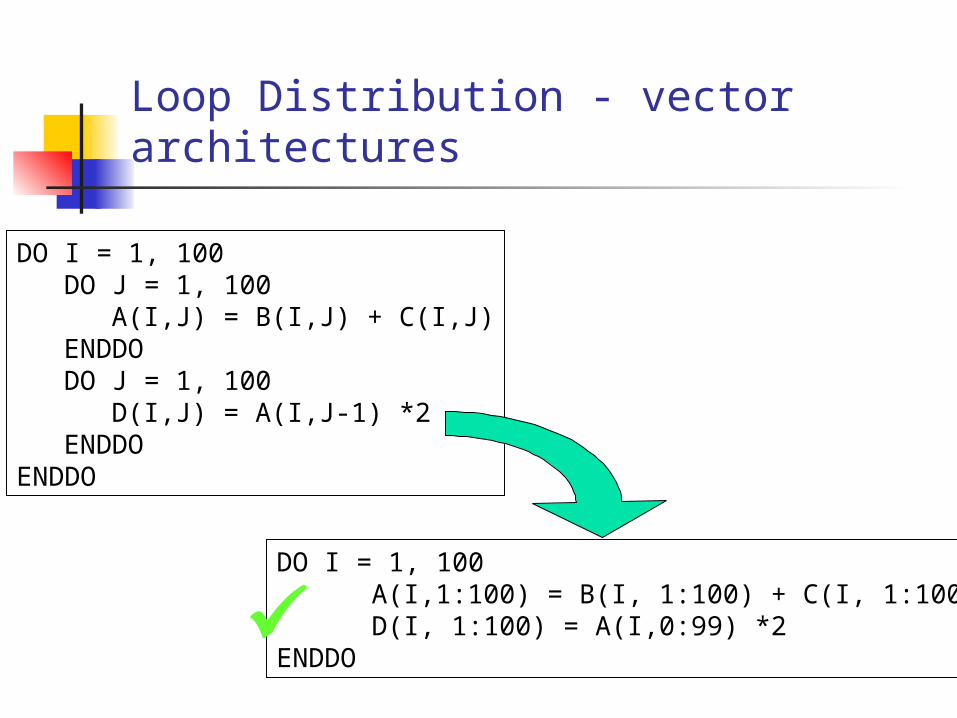
Loop Distribution - vector architectures
DO I = 1, 100DO J = 1, 100
A(I,J) = B(I,J) + C(I,J)ENDDODO J = 1, 100
D(I,J) = A(I,J-1) *2ENDDO
ENDDO
DO I = 1, 100A(I,1:100) = B(I, 1:100) + C(I, 1:100)D(I, 1:100) = A(I,0:99) *2
ENDDO

Loop Distribution - SMP architectures
DO I = 1, 100DO J = 1, 100
A(I,J) = B(I,J) + C(I,J)ENDDOBarrier()DO J = 1, 100
D(I,J) = A(I,J-1) *2ENDDO
ENDDO
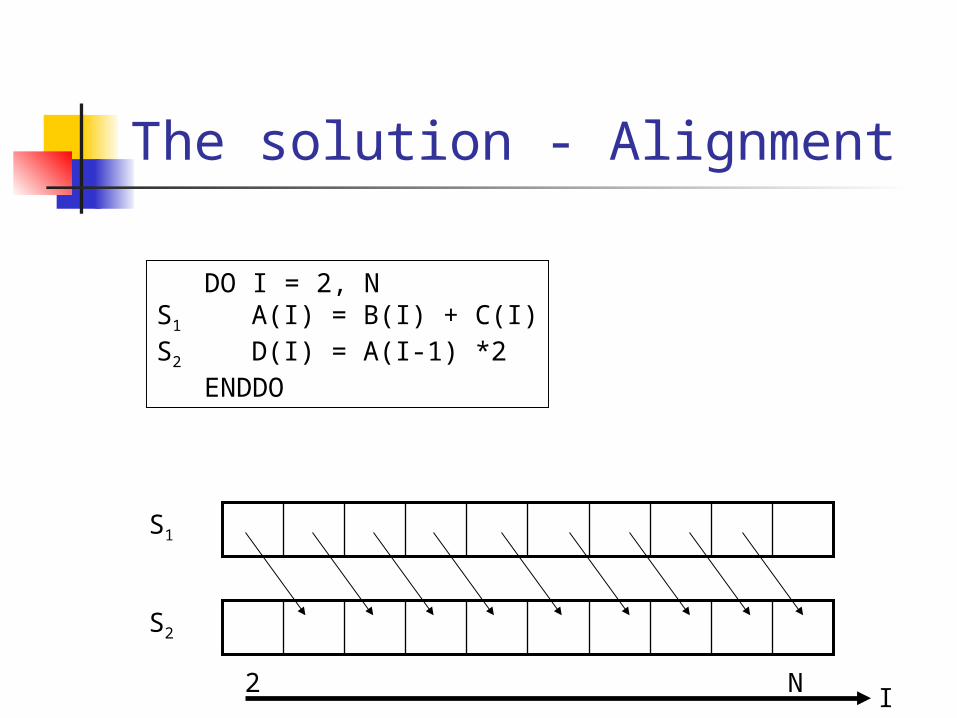
The solution - Alignment
DO I = 2, NS1 A(I) = B(I) + C(I)S2 D(I) = A(I-1) *2
ENDDO
S1
S2
I2 N
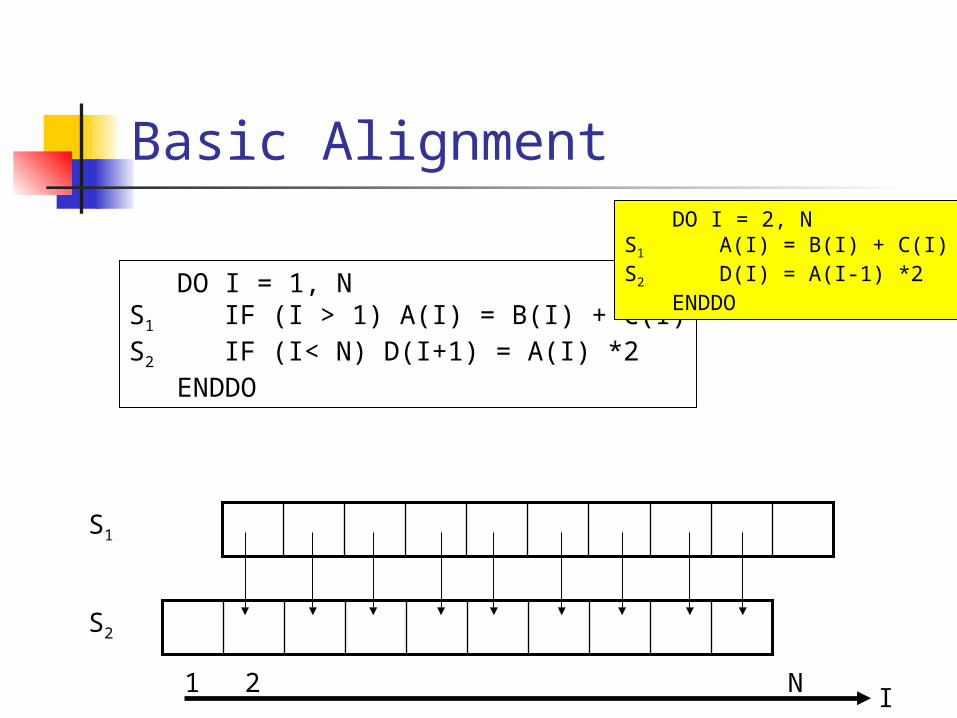
Basic Alignment
S1
S2
DO I = 1, NS1 IF (I > 1) A(I) = B(I) + C(I)S2 IF (I< N) D(I+1) = A(I) *2
ENDDO
DO I = 2, NS1 A(I) = B(I) + C(I)S2 D(I) = A(I-1) *2
ENDDO
I2 N1
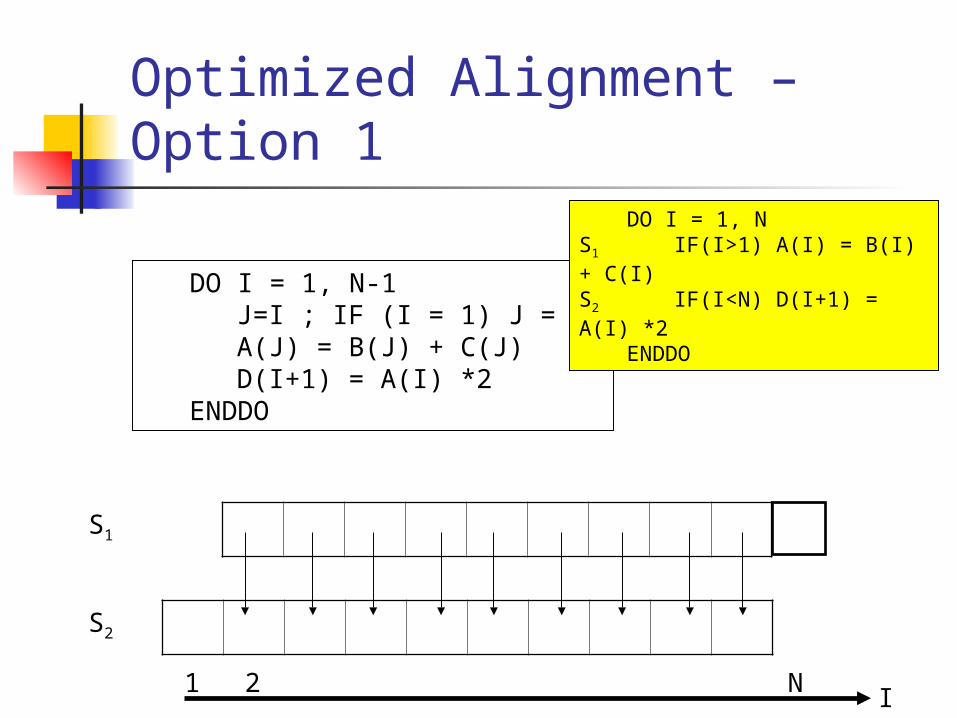
Optimized Alignment – Option 1
S1
S2
DO I = 1, N-1J=I ; IF (I = 1) J = N A(J) = B(J) + C(J)D(I+1) = A(I) *2
ENDDO
DO I = 1, NS1 IF(I>1) A(I) = B(I) + C(I)S2 IF(I<N) D(I+1) = A(I) *2
ENDDO
I2 N1

Optimized Alignment – Option 2
S1
S2
D(2) = A(1)*2DO I = 2, N - 1
A(I) = B(I) + C(I)D(I+1) = A(I) *2
ENDDOA(N) = B(N)+C(N)
DO I = 1, NS1 IF(I>1) A(I) = B(I) + C(I)S2 IF(I<N) D(I+1) = A(I) *2
ENDDO
I2 N1

Alignment problems
Recurrence – impossible to align Different dependency distances –
Alignment fails (Alignment conflict)
DO I = 1, NA(I+1) = B(I) + C
X(I) = A(I+1) +A(I) ENDDO
DO I = 0, NIF (I>0) A(I+1) = B(I) + C
IF (I<N) X(I+1) = A(I+2) +A(I+1) ENDDO

Code Replication
Solves Alignment conflict
DO I = 1, NA(I+1) = B(I) + CX(I) = A(I+1)
+A(I)ENDDO
DO I = 1, NA(I+1) = B(I) + CIF (I=1)
t = A(I)ELSE
t = B(I-1) + CX(I) = A(I+1) + t
ENDDO

Alignment Graph
G = (V,E) – Directed Acyclic Graph. V - Set of loop body statements
Labeling o(v) – vertex offset E – Set of dependences
Labeling d(e) - dependence distance

Alignment Graph - Example
DO I = 1, N S1 A(I+2) = B(I) + CS2 X(I+1) = A(I) + DS3 Y(I) = A(I+1) +X(I)
ENDDO
S1
S2
S3
d=2d=1
d=1o = 0
o = 0
o = 0

Alignment Goal
The Graph G = (V,E) is said to be carry-free if for each edge e=(u,v)
o(u) + d(e) = o(v) Alignment procedure gets
alignment graph and generated carry-free alignment graph

Align Procedure
While V is not empty Add to worklist W arbitrary vertex v
from V While W is not empty
Remove vertex u from worklist W Align all adjacent vertices of u, replicate
node if different alignments required Add new aligned nodes in W

Align Procedure-Example
S1
S2
S3
d=2d=1
d=1o = 0
o = 0
o = 0
o = -1
o = -1
S1`
o = -3
d=2

GenAlign Procedure Set variables
hi maximal vertex offset lo minimal vertex offset Ivar original iteration variable Lvar original loop lower bound Uvar original loop upper bound
Generate loop statement “DO Ivar = Lvar-hi, Uvar + lo”

GenAlign Procedure cont. Scan vertices in a topological sort order
Let v be the current vertex if o(v) = lo then generate
“IF (Ivar >= Lvar-o(v) ) THEN “ + The related statement of v with Ivar+o(v)
substituted for Ivar else if o(v) = hi then generate
“IF (Ivar =< Uvar-o(v) ) THEN “… else generate
“IF (Ivar>=Lvar-o(v) AND Ivar<=Uvar-o(v)) THEN“…

GenAlign Procedure cont. if v is a replicated vertex, replace the
statement S with the following “THEN
tv = RHS(S) with Ivar+o(v) substituted for IvarELSE
tv = LHS(S) with Ivar+o(v) substituted for IvarENDIF”
Where tv is new unique scalar. Replace reference at the sink of every
dependence from v by tv

GenAlign - Example
DO I = 1, N S1 A(I+2) = B(I) + CS2 X(I+1) = A(I) + DS3 Y(I) = A(I+1) +X(I)
ENDDO DO I = 1, N+3 S1 IF (I>=4) A(I-1) = B(I-3) + CS1` IF (I>=2 AND I<=N+1) THEN
t = B(I-1) + CELSE
t = A(I+1)ENDIF
S2 IF (I>=2 AND I<=N+1) X(I)=A(I-1)+DS3 IF (I<=N) Y(I)=t+X(I)
ENDDO

Roadmap
Privatization Alignment Loop Fusion

Loop Fusion - Motivation
DO I = 1, NA(I) = B(I) + 1C(I) = A(I) + C(I-1)D(I) = A(I) + X
ENDDO
DO I = 1, NA(I) = B(I) + 1
ENDDODO I = 1, N
C(I) = A(I) + C(I-1)ENDDODO I = 1, N
D(I) = A(I) + XENDDO
Distribution
Parallelizable
Serial

Loop Fusion - Motivation
PARALLEL DO I = 1, NA(I) = B(I) + 1
ENDDODO I = 1, N
C(I) = A(I) + C(I-1)ENDDOPARALLE DO I = 1, N
D(I) = A(I) + XENDDO
Fusion
PARALLEL DO I = 1, NA(I) = B(I) + 1D(I) = A(I) + X
ENDDODO I = 1, N
C(I) = A(I) + C(I-1)ENDDO

Loop Fusion – Graphical View
L1
L2
L3
L1,
3
L2

Loop Fusion - Safety Constraints
PARALLEL DO I = 1, NA(I) = B(I) + 1
ENDDOPARALLE DO I = 1, N
D(I) = A(I+1) + XENDDO
FusionPARALLEL DO I = 1, N
A(I) = B(I) + 1
D(I) = A(I+1) + XENDDO
Fusion-preventing dependence constraint: the fused loops generates backward loop carried dependence
X

Loop Fusion - Safety Constraints
Ordering constraint: there is a path that contains a loop-independent dependence between the loops that can’t be fused with them
L1
L2
L3
L1,
3
L2X Fusion

Loop Fusion - Profitability Constraints
Separation constraint: do not fuse parallel loops with sequential loops…
Parallelism inhibiting constraint: the fused loop will have a forward carried dependence.PARALLEL DO I = 1, NA(I) = B(I) + 1
ENDDOPARALLE DO I = 1, N
D(I) = A(I-1) + XENDDO
FusionPARALLEL DO I = 1, N
A(I) = B(I) + 1
D(I) = A(I-1) + XENDDO

Typed Fusion - Definition
P=(G, T, m, B, t0) G=(V,E) directed acyclic graph
(dependence graph) T – set of types (parallel, sequential) m:VT mapping of types to vertices B – set of bad edges (constraints) t0 – objective type (parallel)

Main Data Structures
num[n] – holds the number of the node number of n in the fused graph
maxBadPrev[n] – holds the maximal vertex number of type t0 in the fused graph that cannot be fused with n“The maximal fused vertex that n is preventing from being further fused”
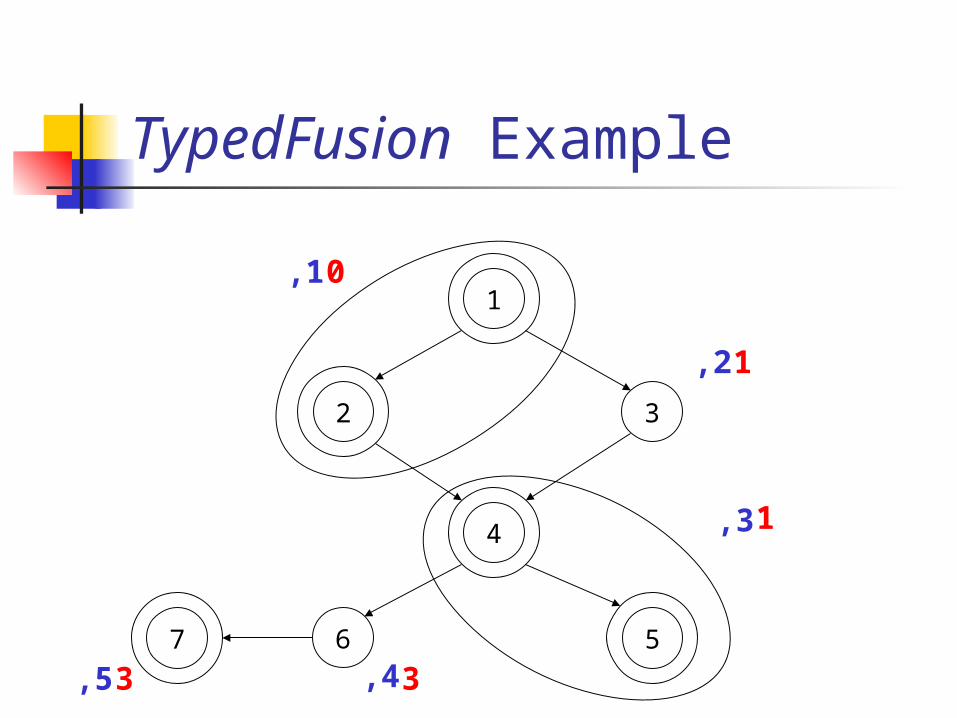
TypedFusion Example
1
3
4
6 5
2
1,
2,
3,
7
4,5,
0
1
1
33

update_successors(n) Set t = type(n) For each edge (n,m) do
If (t != t0) maxBadPrev[m] = MAX(maxBadPrev[m],
maxBadPrev[n])
Else If (type(m) != t0 or (n,m) in B) maxBadPrev[m] = MAX(maxBadPrev[m], num[n])
Else maxBadPrev[m] = MAX(maxBadPrev[m],
maxBadPrev[n])

TypedFusion Procedure
Scan the vertices in topological order For each vertex v
If v is of type t0
update_successors(v)fuse v with the first possible
available node Else
update_successors(v)create_new_node(v)
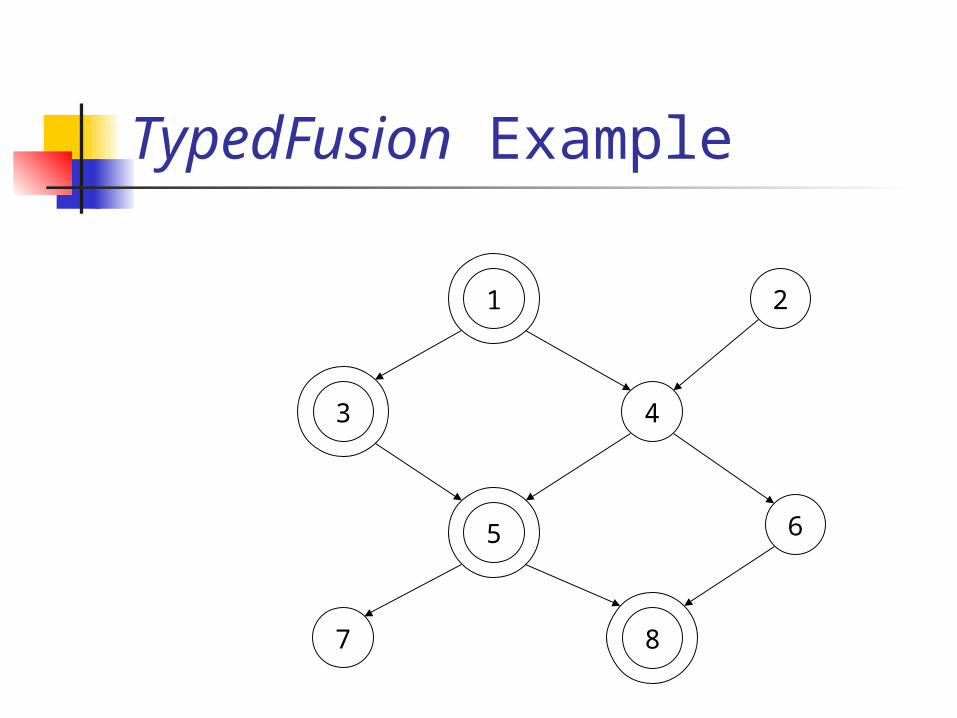
TypedFusion Example
1
4
5
7 8
6
3
2

TypedFusion Example
1
4
5
7 8
6
3
2
(0,1)
(0,1)
(0,2)
(1,3)
(1,4) (1,5)
(1,4)(4,6)
(maxBadPrev , num)
(0, ) (1, )
(0, )(1, ) (1, )
(4, ) (1, )

TypedFusion Example
1,3
4
5,8
7
6
2
(1) (2)
(3)
(4) (5)
(6)

Fusing sequential loops…
1,3
2,4,6
5,8
7
(1)
(3)
(4)
(6)

Ordered Fusion
More than 2 types of loops: Different loop headers
Setting the “right” order of types to fuse is NP-hard Define priorities to each type

Type conflict
1 2
3 4

Ordered Fusion
1 2
4 5
3
6
1
4
5
7 8
6
3
2
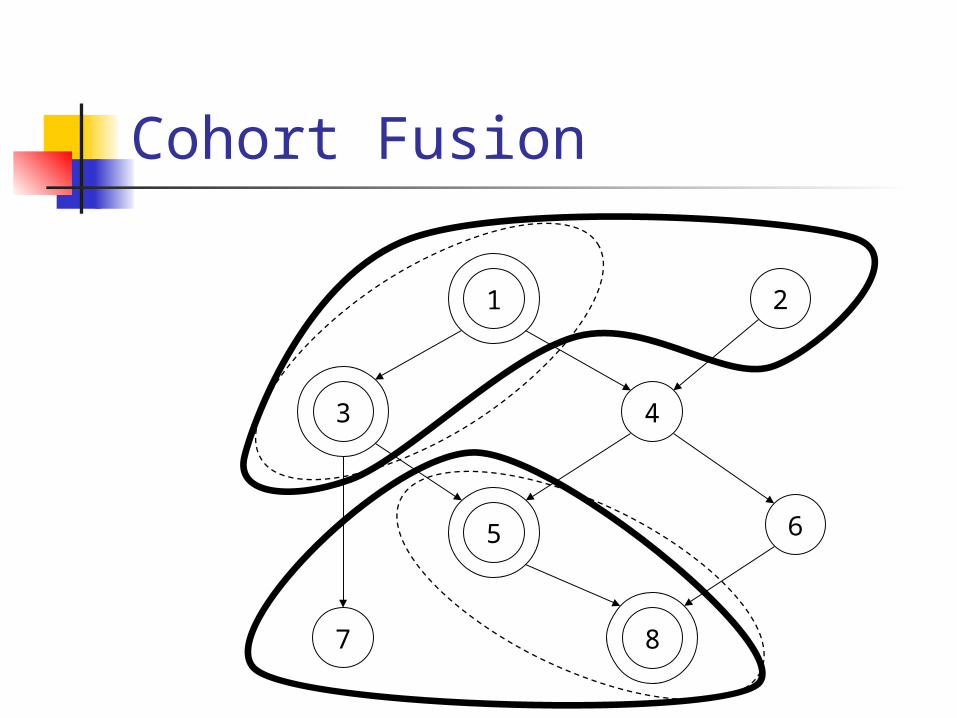
Cohort Fusion

Cohort Fusion
Allows running sequential loops with parallel loop
Settings: Single type Bad edges
Fusion-preventing edges Parallelism-inhibiting edges Edges mixing parallel and sequential loops

Cohort Fusion
Pros Minimal number of barriers
Cons Bad load balancing


















