
Computing Inexactly: A Potential Approach to Living with...
23
It is the mark of an instructed mind to rest satisfied with the degree of precision which the nature of the subject permits and not to seek an exactness where only an approximation of the truth is possible. Aristotle Sandip Tiwari [email protected] Computing Inexactly: A Potential Approach to Living with Constraints of Nanoscale Acknowledgements: Arvind Kumar, Ravi Nair, Chris Liu, Ravishankar Sundararaman, Howard Davidson, Jae Yoon Kim, Wei Min Chan, Moon Kyung Kim, … Funding: NSF, TND, DARPA, Mellowes Endowment, … Complexity of scales connecting “nano” to “tera” Agenda Tiwari_07_2009_NanoArch.pptx Today’s information processing systems are designed to be totally predictable, reproducible, and are designed hierarchically to be manageable. Plenty of room for inefficiencies. What can we do within this model? Are there other opportunities at the hardware - software wall? Working at the limits of energy for computation in the presence of noise, random and non-random variability, and defects. Exploiting inexactness by relaxing determinism
Transcript of Computing Inexactly: A Potential Approach to Living with...

It is the mark of an instructed mind to rest satisfied with the degree of precision which the nature of the subject permits and not to seek an exactness where only an approximation of the truth is possible. Aristotle
Sandip [email protected]
Computing Inexactly: A Potential Approach to Living with
Constraints of Nanoscale
Acknowledgements: Arvind Kumar, Ravi Nair, Chris Liu, Ravishankar Sundararaman, Howard Davidson, Jae Yoon Kim, Wei Min Chan, Moon Kyung Kim, …Funding: NSF, TND, DARPA, Mellowes Endowment, …
Complexity of scales connecting “nano” to “tera”
Agenda
Tiwari_07_2009_NanoArch.pptx
Today’s information processing systems are designed to be totally predictable, reproducible, and are designed hierarchically to be manageable.
Plenty of room for inefficiencies. What can we do within this model?
Are there other opportunities at the hardware - software wall?
Working at the limits of energy for computation in the presence of noise, random and non-random variability, and defects.
Exploiting inexactness by relaxing determinism
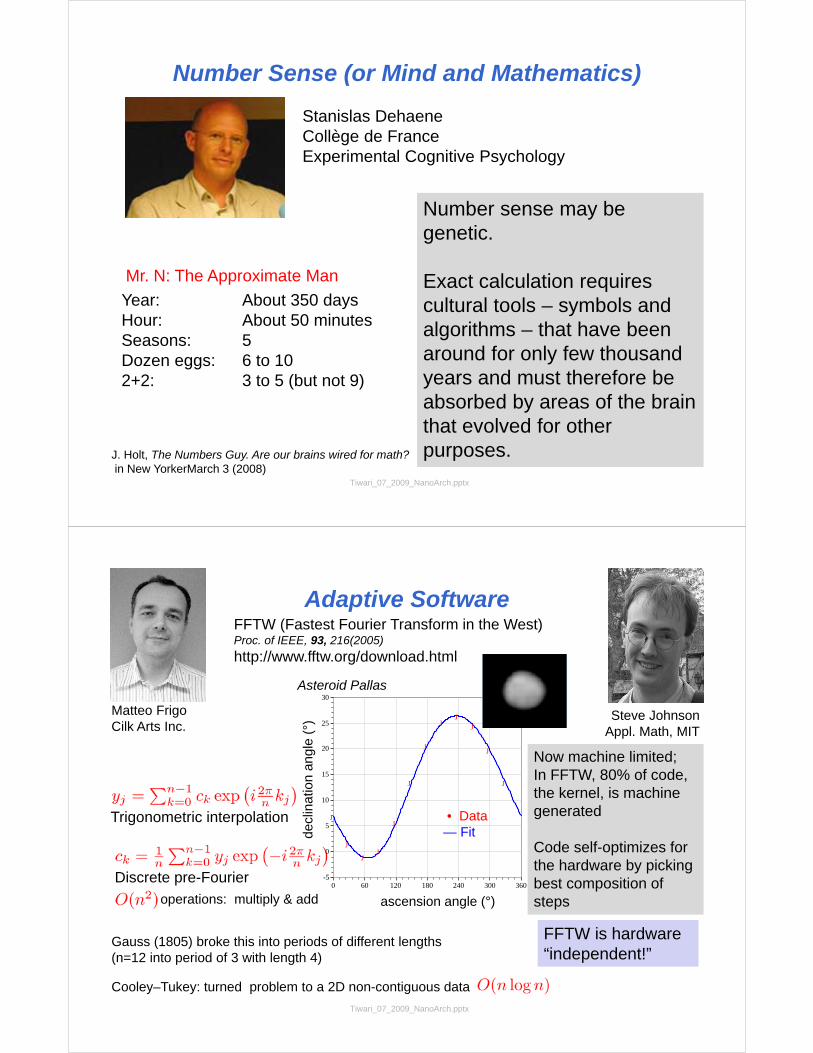
Number Sense (or Mind and Mathematics)
Tiwari_07_2009_NanoArch.pptx
Stanislas DehaeneCollège de FranceExperimental Cognitive Psychology
Mr. N: The Approximate Man
Year: About 350 daysHour: About 50 minutesSeasons: 5Dozen eggs: 6 to 102+2: 3 to 5 (but not 9)
Number sense may be genetic.
Exact calculation requires cultural tools – symbols and algorithms – that have been around for only few thousand years and must therefore be absorbed by areas of the brain that evolved for other purposes. J. Holt, The Numbers Guy. Are our brains wired for math?
in New YorkerMarch 3 (2008)
Adaptive Software
Tiwari_07_2009_NanoArch.pptx
FFTW (Fastest Fourier Transform in the West)Proc. of IEEE, 93, 216(2005)
http://www.fftw.org/download.html
Steve JohnsonAppl. Math, MIT
Matteo FrigoCilk Arts Inc.
Trigonometric interpolation
Discrete pre-Fourier
operations: multiply & add
Now machine limited;In FFTW, 80% of code, the kernel, is machine generated
Code self-optimizes for the hardware by picking best composition of steps
FFTW is hardware “independent!”
Cooley–Tukey: turned problem to a 2D non-contiguous data
Gauss (1805) broke this into periods of different lengths (n=12 into period of 3 with length 4)
J
J
JJ
J
J
J
JJ
J
J
J
-5
0
5
10
15
20
25
30
0 60 120 180 240 300 360
ascension angle (°)
decl
inat
ion
angl
e (°
)
Asteroid Pallas
• Data— Fit

Computational Complexity
Tiwari_07_2009_NanoArch.pptx
MergeSort
Fast Fourier Transform
Multiplication:
Matrix Multiplication:
Prime Number:
or
oror
Avoiding Indiscriminate Computing
Tiwari_07_2009_NanoArch.pptx
Efficient sparse approaches using self-learning via simpler basis vectors: edge-like patches L1 sparsity term
Learned models ~ correspond ~ to visual recognition region V1 (van Hataren & van de Schaaf, 1998)
Coeff. / Basis learning method natural image speech stereo videoA. Ng's algorithm 260.0 248.2 438.2 186.6Previous work (LARS+GD) 13085.1 17219.0 12174.6 11022.8
Run time
Improving algorithms => increased programmability + efficiency and speed
A. Ng, (2007)
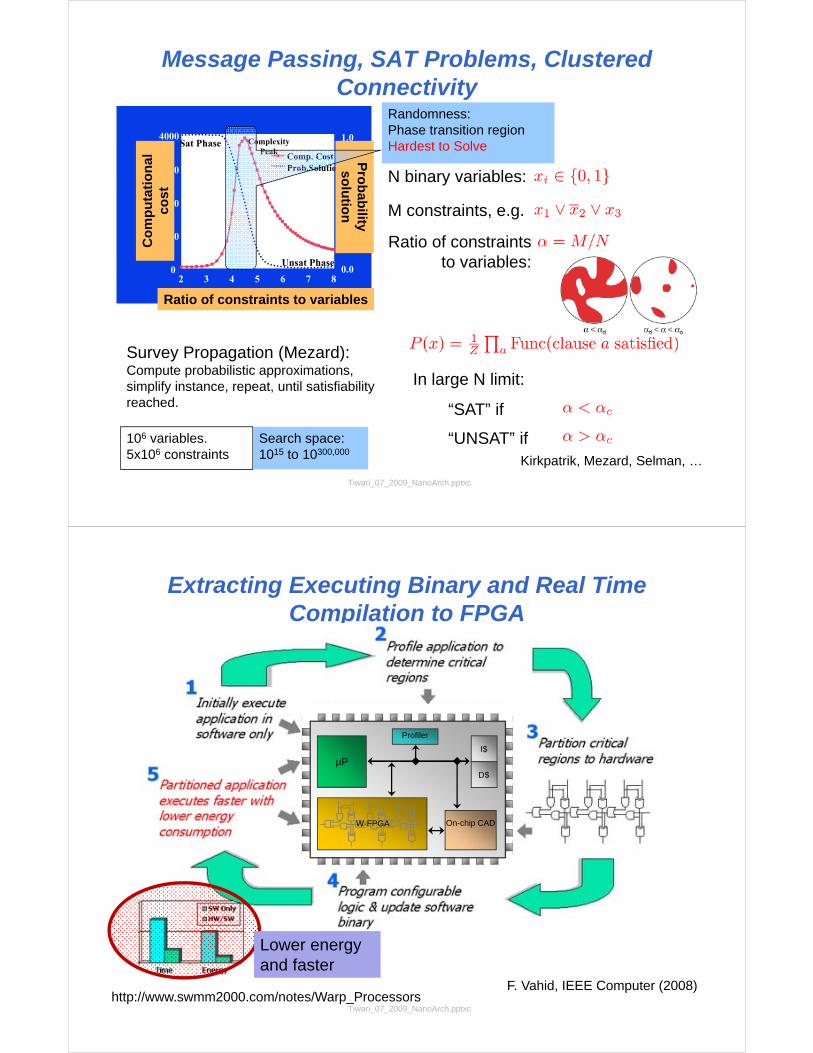
Message Passing, SAT Problems, Clustered Connectivity
0.0
1.0
0
1000
3000
2000
4000
0.5
0.25
0.75Comp. Cost Prob.Solution
ComplexityPeak
Sat Phase
Unsat Phase
2 3 4 5 6 7 8
Co
mp
uta
tio
nal
co
st
Pro
bab
ility so
lutio
n
Ratio of constraints to variables
Randomness:Phase transition region Hardest to Solve
Survey Propagation (Mezard):Compute probabilistic approximations, simplify instance, repeat, until satisfiabilityreached.
Kirkpatrik, Mezard, Selman, …
106 variables. 5x106 constraints
Search space: 1015 to 10300,000
N binary variables:
M constraints, e.g.
In large N limit:
“SAT” if
“UNSAT” if
Ratio of constraints to variables:
Tiwari_07_2009_NanoArch.pptxc
Extracting Executing Binary and Real Time Compilation to FPGA
http://www.swmm2000.com/notes/Warp_ProcessorsF. Vahid, IEEE Computer (2008)
Lower energy and faster
Tiwari_07_2009_NanoArch.pptxc
µP
On-chip CAD
I$
D$
Profiler
W-FPGA

Power and Heat
Tiwari_07_2009_NanoArch.pptx
energy per operation
x-section area of heat removal
density of heat removal
activity factor
time constant of energy consuming operation
Rapid changes in fields -> excess charged particle energy loss to medium -> heat
3D Heat Spreading: Logic regions1D Heat Spreading: Array regions
10 nm 7.5x1012 2 in 1 inch2 => 1012 devices/chip
S. Tiwari et al., IEEE NMDC (2006)
Only a very small fraction can be in use at any given time
Hierarchy and Data Movement: Energy
Tiwari_07_2009_NanoArch.pptx
SystemScale
Circuit Scale
Interconnects
Device
Network
RoadRunner Supercomputer
1 Petaflops6562 Dual-core AMD Opteron chips12240 Cell chips (used in Sony Playstation 3)
~15 Tera transistors98 Terabytes of memory
~800 Terabits278 racks2.35 MW of power
Element Energy Units
32b integer op 0.35 pJ
64b floating op 7 pJ
Instruction exec 210 pJ
32b 16K RAM read 11 pJ
32b across 1mm 5 pJ
32b across 20mm 100 pJ
32b off chip 320 pJ
Moving data is expensive; LVDS mitigates only partly
A 16 nm processor!Source: W. Dally (2008)
We hear plenty about devices, wiring, …-- The corollary of the discussion is power-- this is also true for communications

Computation Problems
Most computation problems are inexact Speech and Video’s
Recognition
Machine learning
Data compression
…
Decision making
Inexact inputs
Inexact model
Limited resources for decision making
FFTs, GPUs, ALUs, Compression Engines, Transform Engines, Neurons, Analog, … in coprocessing with Exact Computing.
Tiwari_07_2009_NanoArch.pptx
Example: The Current Economic Crisis
Inexact Techniques
Google’s Search is inexact Does not work with a coherent, up-to-date database of Web
pages Query sent to many nodes, some of which may fail while
computing Lack of “prompt” response from a node causes query to be sent
to one or more others
Google’s Map-Reduce programming provisions for ignoring consistently failing records Dropping an occasional record does not affect computations
that are statistical in nature
Failing nodes, failing channels, but the search still works!
Tiwari_07_2009_NanoArch.pptx

Self-Assembly
Tiwari_07_2009_NanoArch.pptx
W. M. Chan et al., unpublished
PS(68k)-PMMA(33.5k) HCP BCP film on ps-r-pmma brush (inset FFT)
Process VariabilityDefects Activation Energies
CNT: 20% diameter control, chirality?
Energy and Defect Rates
Tiwari_07_2009_NanoArch.pptx
C. Harrison et al., Europhysics Letters (2005)
Time evolution afm snapshot of self-assembly front propagation
dependence

Stochastic Effects: Error Rates - Noise
Tiwari_07_2009_NanoArch.pptx
Transmitting Inverter
K.-U Stein, , IEEE J. SSC, SC12 (1977)
Open: CapacitiveShort: InductiveTransmission Line
Intrinsic minimum energy per logic operation:
Mean thermal energy generated within ckt:
For “0” and “1” states, with random fluctuations,
Total error rate:
Pro
babi
lity
Den
sity
“1” transmitted “0” received
“0” transmitted “1” received
normalizedswitching threshold
Total Error Rate:
Energy and Errors due to Noise
Tiwari_07_2009_NanoArch.pptx
One error in 10 years for
Normalized energy per operation
Err
or r
ate
10-40
10-30
10-20
10-10
100
100 200 300 400
CMOS Static Inverter
VDD
Let be the probability of correctness of logical operation;
P. Korkmaz et al., IEEE C&S-1, 8 (2008)
Probability of failure
Vm: voltage at which input = output

Tiwari_07_2009_NanoArch.pptx
Fundamental Limits: Energy per Operation
10-22
10-20
10-18
10-16
10-14
10-12
1 10 100 Feature Size (nm)
Ene
rgy
per
Ope
ratio
n (J
)
Limit in dissipative information processingBits deleted
Memory Read
1000 e-
10000 e-
100 e-
10 e-
Paramagnetic Stability Limit
S. Tiwari et al., IEEE NMDC (2006)
Electrical Error Rates and Power
Tiwari_07_2009_NanoArch.pptx
10 Million Gates 90% yield for functional block
is the probability of failure of a gate
for cmos static inverter
VDD
If 100 Million gates with 90% yield,
Power Supplies: ~0.5 V tied to variability
A circuit example:
S. Tiwari et al., IEEE Nanoelectronics (2005)

Tiwari_07_2009_NanoArch.pptx
Working with Defects & Power Penalty
T - the average no. of external terminals (pins) in a subcircuit or partition
N - is the number of modules in the subcircuitk - Rent’s constant (average no. of pins per module)p - Rent’s exponent (0 < p < 1)
If logic blocks defective: Naccessible ~ ((1-d)N)p
If wiring defective, the number of testable logic blocks: Naccessible ~ (1-d) Np - a considerably more serious problem
13
2
N
1
2
T
Rent’s Rule
Defects: Configurability Penalty on Power
Tiwari_07_2009_NanoArch.pptx
A. Kumar et al., DFT, 280(2004)
Defects limit testability and limit the usable devices and interconnects
0 500 1000 1500 20000
20
40
60
80
100
Per
cent
age
of m
odul
es te
sted
Number of iterations
dINT=10-2
dINT=10-3
dINT=10-4
dINT=10-5
dINT=0
N=1x106
p=0.5
Interconnect Defects
Defect rate Optimum size of maximum functional unit that is testable and configurable
104 105 106
0
4
8
12
dINT = 0.001
Fac
tor
incr
ease
in p
ower
dis
sipa
tion
Number of modules
p=0.5 p=0.6 p=0.7
Interconnect DefectsPower penalty

Redundancy
Tiwari_07_2009_NanoArch.pptx
Nikolic et al.
Redundancy
Allo
wab
le p
roba
bilit
y of
failu
re
Using R-fold modular redundancyNAND multiplexingReconfiguration (using knowledge of faulty devices)
1012 devices assumed
Defects place severe constraints
Implications of Hierarchy - Communication
1. When M parts connected in series, the system fails when one component does.
2. If N components, w work per component over time T, and in communication to N-1 others
a: rate at which individual component works b: rate at which transmitting to others and rate at which receiving from others
Total work output:
Rate of work:
If become large
Work produced in time T by individual component
Two Component Communications
Tiwari_07_2009_NanoArch.pptx
Brain small-world network
(O. Sporns)
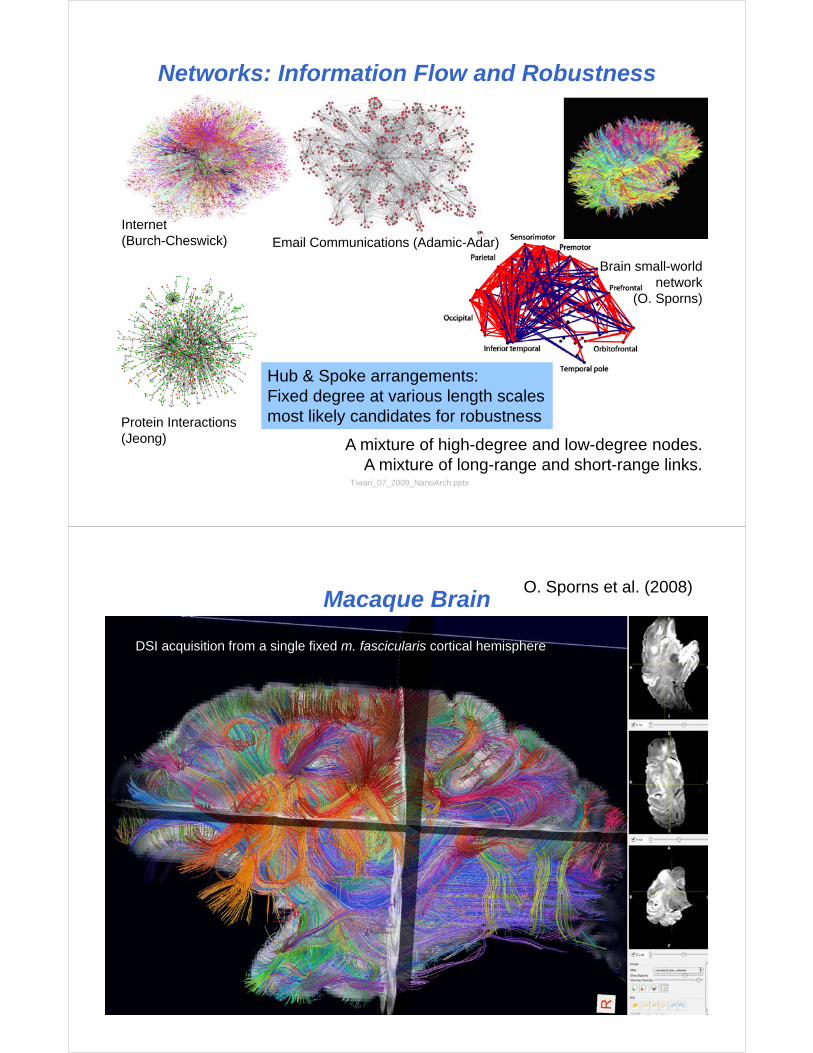
Networks: Information Flow and Robustness
Tiwari_07_2009_NanoArch.pptx
Hub & Spoke arrangements:Fixed degree at various length scales most likely candidates for robustness
Internet (Burch-Cheswick) Email Communications (Adamic-Adar)
Protein Interactions (Jeong) A mixture of high-degree and low-degree nodes.
A mixture of long-range and short-range links.
Macaque Brain
Tiwari_07_2009_NanoArch.pptx
O. Sporns et al. (2008)
DSI acquisition from a single fixed m. fascicularis cortical hemisphere

Brain Plasticity (Ferret Experiments)
Tiwari_07_2009_NanoArch.pptx
S. H. Horng and M. Sur, “Visual activity and cortical rewiring: activity dependent plasticity of cortical networks”, Progress in Brain Research, 157, 3-14
J. Sharma, A. Angelucci & M. Sur, “Induction of visual orientation modules in audirotry cortex”, Nature, 404, 841-847
By keeping connectivity simple - hub & spoke, capable of learning, … reconnect
Networks
Tiwari_07_2009_NanoArch.pptx
Real-world networks exist in many domains: technological, informational, social, metabolic, neural, …
The structure affects the dynamics:
1
1 2
2
3
3
22
3 3
44
33
Target Search: Information flow from start to target via hard-wired, multi-path, … with local and non-local information
Diffusion: Information spreading from starting node to all others; can be hierarchical
Attributes depend on the mixtures of high-degree and low-degree nodes, long-range and short-range links, heterogeneity, …
Some are robust, some not so.

Decentralized Algorithms
Tiwari_07_2009_NanoArch.pptx
Build a mixture of long range and short range
Small World Network: A class of networks with orderly local structure and small diameter (Watts-Strogatz (1998)
Long range percolation model: For each node v, add directed link to random node w with probability proportional to p(v,w)- where p(v,w) is the lattice distance from v to w.
Low
er b
ound
Ton
del
iver
y tim
e (lo
g nT
) nxn gridwith long range links
1 2 3 4 5
.2
.4
.6
.8
1
Optimal timing
Algorithmic Noise Tolerance
Employ statistical signal processing techniques Main block designed for average case
Makes intermittent errors
Estimator approximates Main Block output Error-correction: Compare and replace Approximate, because error is not accurately known
| | > TH
Estimator
Main Block
N. ShanbagTiwari_07_2009_NanoArch.pptx

Minimizing Energy within the Current Model
Adaptation
CV2f and standby …
Step back from errors (e.g. Razor)
1.52 1.56 1.60 1.64 1.68 1.72 1.760.70
0.75
0.80
0.85
0.90
0.95
1.00
1.05
1.10
1.15
1.20
1E-8
1E-7
1E-6
1E-5
1E-4
1E-3
0.01
0.1
1
10
120MHz
No
rmal
ized
En
erg
y
Per
cen
tag
e E
rro
r R
ate
140MHz
Voltage (in Volts)
Point of First Failure
Sub-critical
Source: D. Blauw
Canary approaches
Tiwari_07_2009_NanoArch.pptx
Adaptation
Tiwari_07_2009_NanoArch.pptx
•A<7:0>
•B<7:0>
Modified Booth Encoder
•PP0•<15:0>
•PP1•<13:0>
•PP2•<11:0>
•PP3•<9:0>
•PP4•<7:0>
Wallace Tree Adder
CLA
•<15:0> •<15:0>
•Final Product•<15:0>
DGFET Multiplier
Number of bits
8
Power 7.72 mW
Frequency ≈500 MHz
Device 100 nm
VDD 1 V
Booth MultiplierNearly x10 reduction in power without sacrificing high speed. Compact and dense
An encoder
A 4-2 compressor
W. M. Chan (2007)
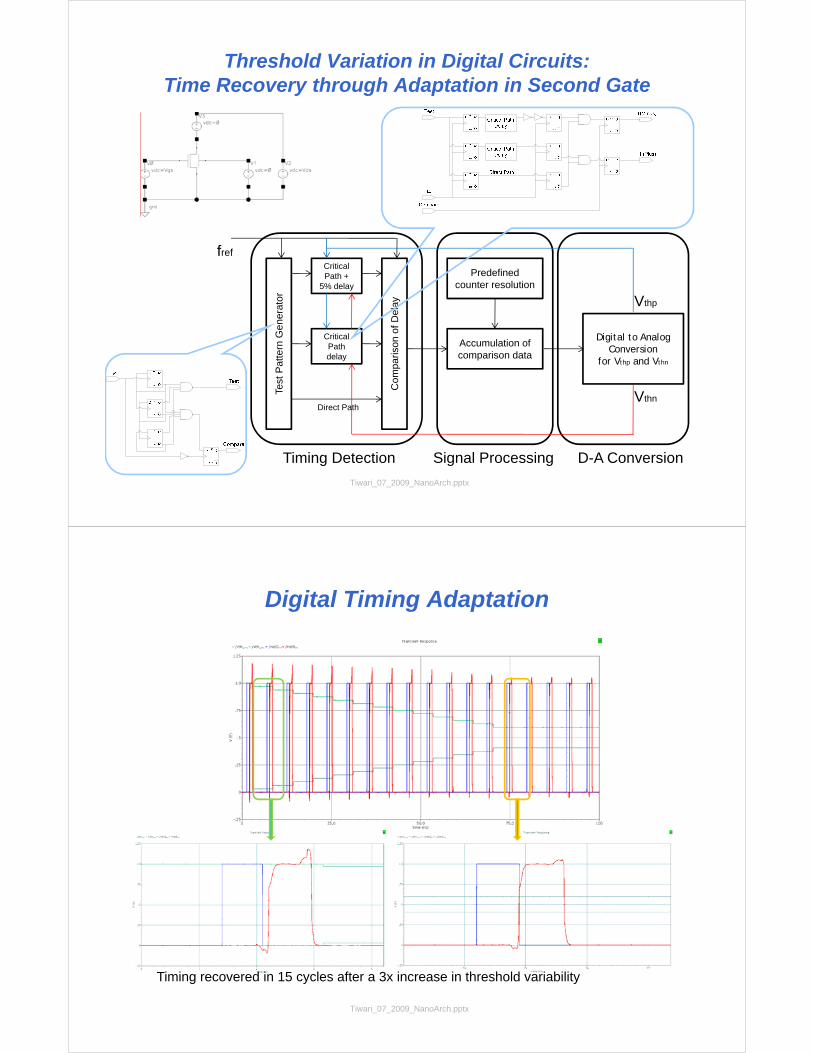
Threshold Variation in Digital Circuits: Time Recovery through Adaptation in Second Gate
Test
Pat
tern
Gen
erat
orCritical Path +
5% delay
Critical Path delay
Com
paris
on o
f Del
ay
fref
Predefined counter resolution
Accumulation of comparison data
Digital to Analog Conversion
for Vthp and Vthn
Vthp
VthnDirect Path
Timing Detection Signal Processing D-A Conversion
Tiwari_07_2009_NanoArch.pptx
Digital Timing Adaptation
Timing recovered in 15 cycles after a 3x increase in threshold variability
Tiwari_07_2009_NanoArch.pptx

Probabilistic CMOS
VDD
Let be the probability of correctness of logical operation
Probability of failure
Vm: voltage at which input = output
0.00001
0.0001
0.001
0.01
0.1
1
10
100
log
perc
ent e
rror
rat
erms value of Gaussian noise (V)
Simulation
Analytic
J.Y. Kim et al. (unpublished)Tiwari_07_2009_NanoArch.pptx
Probabilistic Adder
Tiwari_07_2009_NanoArch.pptx
ABCin
ABCin
Cout
Sum
P. Korkmaz et al., IEEE C&S-1, 8 (2008)

Errors and Power Dissipation in ALU’s
Tiwari_07_2009_NanoArch.pptx
LSBMSB
Radix-4, tree multiplier with4:2 compressor
Relax the demands on accuracy on the lowest bits
Error Adaptive Adder (pipelined)
Tiwari_07_2009_NanoArch.pptx
Conditional Carry Selection with min. propagation
Carry out calculated for ‘0’ and ‘1’ carry-in, and multiplexed by propagated carry-in signal, Bias voltage scaled: DVS
8, 4-bit CCS Adder blocks
Carry out signals from each blocks multiplexed by the carry-in signal of previous blocks
Conditional Sum Selection 40 nm Transistors 1 V Vdd with 90.6 ps critical path delay
1111 1111 1111 1111 1111 1111 111 1111+ 0000 1111 0000 1111 0000 1111 0000 11111 0000 1111 0000 1111 0000 1111 0000 1110
or4,294,967,295 + 252,645,135 = 4,547,612,430
J.Y. Kim et al. (unpublished)

Errors
Fixed Vdd: Correct Result = 4,547,612,430Error rate = 0 %
Linear scaling: Result = 4,547,612,414Error rate = 3.52E-07 %
Convex scaling: Result = 4,547,612,428Error rate = 4.39E-08 %
Concave scaling: Result = 4,560,19,120Error rate = 0.2766 %
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
01234567V
dd
MSB LSB
MSB-LSB vs. Vdd scaling
Fixed Vdd
Linear scaling
Convex scaling
Concave scaling
J.Y. Kim et al. (unpublished)Tiwari_07_2009_NanoArch.pptx
Scaling Bias Voltages for Error
Tiwari_07_2009_NanoArch.pptx
10-15
10-10
10-5
100
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
Error rate (%)
Nor
mai
lzed
max
pow
er c
onsu
mpt
ion
Error rate vs. Normalized power consumption
Convex Scaling
Linear Scaling
Concave Scaling
Fixed Vdd
Fixed Vdd
J.Y. Kim et al. (unpublished)

Error-Power Trade Off in Arithmetic Operations
Set expectations of correctness (a distribution) of outputPower saving possible when errors acceptable tied to the lowest bit
Kogge-Stone Adder Modified Booth Multiplier
Region of maximum power savings
Energy dissipated per computation for n bits:
(Gaussian)
(Lorentzian)
(flat error everywhere)
Tiwari_07_2009_NanoArch.pptx
R. Sundararaman et al. (unpublished)
Ripple Carry
Power-Error Trade-Off
R. Sundararaman et al. (unpublished)Tiwari_07_2009_NanoArch.pptx
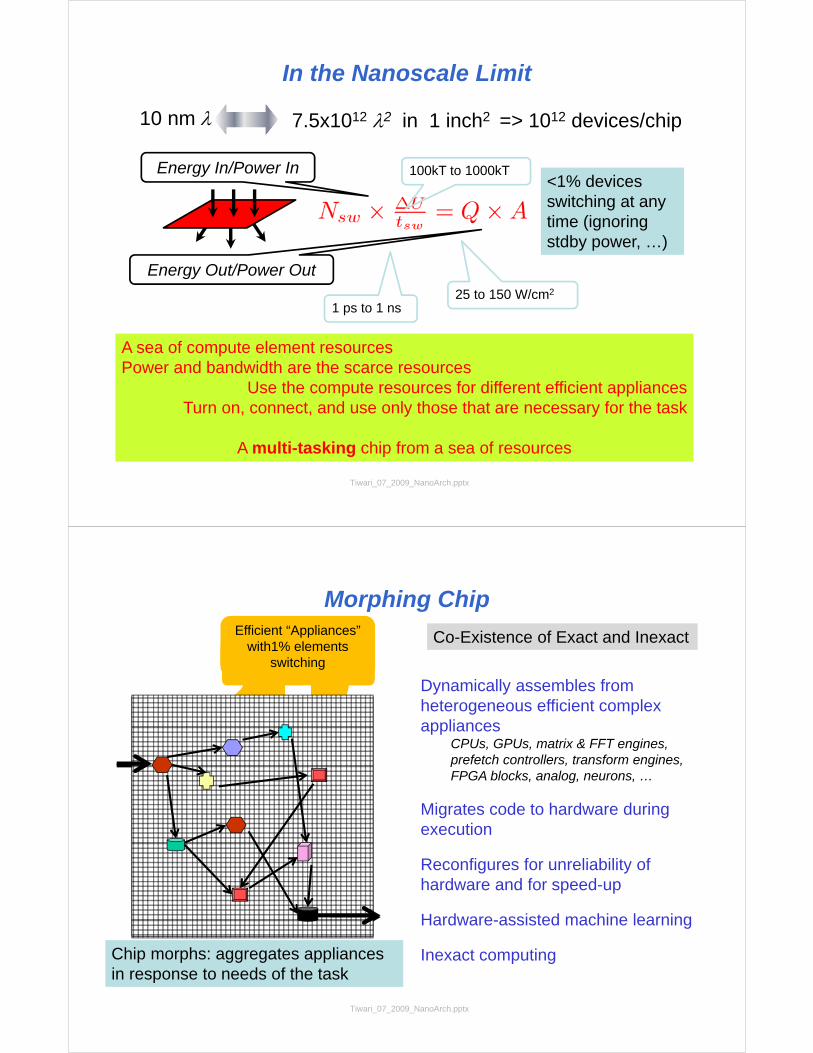
In the Nanoscale Limit
Tiwari_07_2009_NanoArch.pptx
10 nm 7.5x1012 2 in 1 inch2 => 1012 devices/chip
Energy In/Power In
Energy Out/Power Out
<1% devices switching at any time (ignoring stdby power, …)
100kT to 1000kT
25 to 150 W/cm2
1 ps to 1 ns
A sea of compute element resourcesPower and bandwidth are the scarce resources
Use the compute resources for different efficient appliancesTurn on, connect, and use only those that are necessary for the task
A multi-tasking chip from a sea of resources
Morphing Chip
Tiwari_07_2009_NanoArch.pptx
Efficient “Appliances” with1% elements
switching
Dynamically assembles from heterogeneous efficient complex appliances
CPUs, GPUs, matrix & FFT engines, prefetch controllers, transform engines, FPGA blocks, analog, neurons, …
Migrates code to hardware during execution
Reconfigures for unreliability of hardware and for speed-up
Hardware-assisted machine learning
Inexact computingChip morphs: aggregates appliances in response to needs of the task
Co-Existence of Exact and Inexact

Computing Inexactly
Algorithms:
Architecture:
Implementation:
Tolerate errors in hardwareProbabilistic approaches; algorithms away from brute force and linear algebra…
Merge software and hardware through an interfaceAllow specification of precision toleranceAllow specification of incoherence tolerance…
Build in dynamic testing and configuringImplement large functions that compromise solution exactnessDevices and Circuits that address this within power and variability limits – memory, new ideas that merge functions and break boundaries effciently efficiently, … Tiwari_07_2009_NanoArch.pptx
Accept inexactness as a natural consequence of complexity
BackUp
Tiwari_07_2009_NanoArch.pptx
Lex for Lowering Power
Enduring Non-Volatile Low Power Data Mapping Memories at TeraDensity & SRAM speed
Local data:
Efficient appliances:Effective connectable appliances with local algorithms
Area and architecturally efficient fast configuration switches – fine and coarse grain
Morphing:
Software to hardware and hardware to software translation to minimize energy, work around defects and error correction
Dynamic Software – Hardware Interactions:
Area and architecturally efficient fast configuration switches – fine and coarse grain; testability determines maximum size of appliance
Built in self-testing
Tiwari_07_2009_NanoArch.pptx
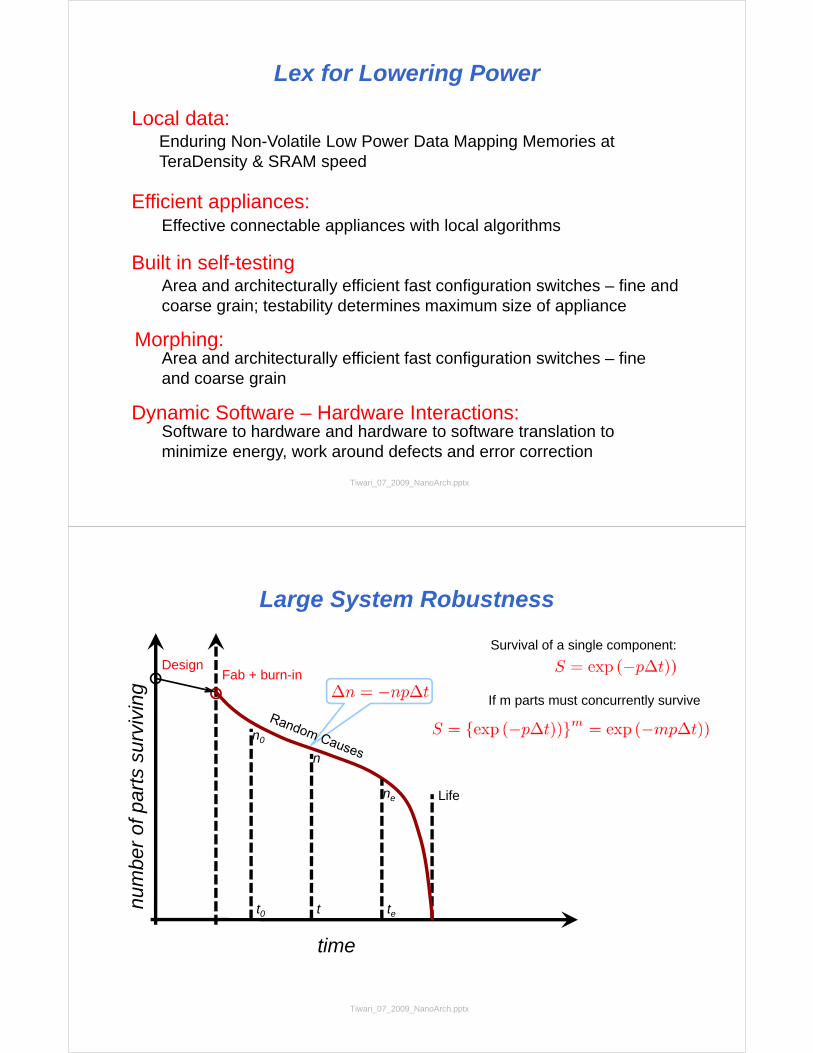
Large System Robustness
Tiwari_07_2009_NanoArch.pptx
time
Fab + burn-inDesign
Life
t0 tet
ne
n0
n
num
ber
of p
arts
sur
vivi
ng
Survival of a single component:
If m parts must concurrently survive


















