
CLAS12 software paradigm My two cents… Vardan Gyurjyan Friday, August 26, 2005.
23
CLAS12 software paradigm My two cents… Vardan Gyurjyan Friday, August 26, 2005
-
Upload
eugene-higgins -
Category
Documents
-
view
218 -
download
1
Transcript of CLAS12 software paradigm My two cents… Vardan Gyurjyan Friday, August 26, 2005.

CLAS12 software paradigm
My two cents…
Vardan GyurjyanFriday, August 26, 2005

CLAS12 software requirements
• Give users an access to increasingly sophisticated software packages, while hiding its complexity.
• Incorporate rapidly changing software technologies into the long life time of the CLAS12 physics programs.
• Handle the wide dispersion of software providers and users.
• EEEE…• Easy to use• Easy to extend• Easy to manage• Easy to maintain

Tirgger
Slow Control
PartialReconstruction
Online Monitoring
Reconstruction
Calibration
EventVisualization
Simulation Analysis
CLAS12Detector
Geant
Offline Object Store
Database
In Memory OnlineStorage
Permanent Storage
SimulationFramework
AnalysisFramework
ReconstructionFramework
Foundation Libraries
CLAS12 Data Processing
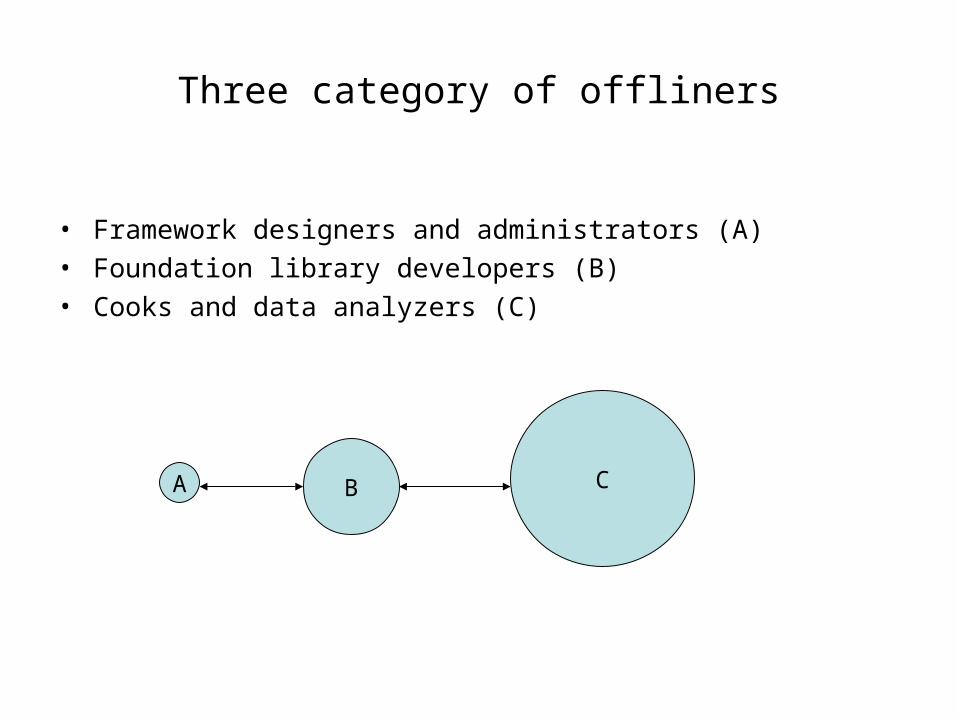
Three category of offliners
• Framework designers and administrators (A)• Foundation library developers (B)• Cooks and data analyzers (C)
A B C

Requirements for A
1. Larger, dispersed user community2. Make best use of new IT technologies3. Establishing coding standards and computing polices
4. Increase flexibility and coherence of the offline system• ability to plug-in new algorithms• ability to run the same algorithm on multiple
environments• quality and reproducibility• user friendliness
documentation, documentation, documentation…

Establishing coding standards and computing polices
• Version control system (CVS, BFD, Aegis, Arch, BitKeeper, Subversion, Vesta, etc.)
• Documentation (Doxygen, javadoc, ROBODoc, POD or TwinText)
• Coding standards• Administrative requirements

Technologies for the offline environment
• C++ & OO• Runtime dynamic loading• State machines• Persistent object store• P2P communications• Messaging systems• Layered architecture to shield the user from the above!!!

Principal design choices
• Separation between data and algorithms: data object and algorithm object
data• Three basic categories of data:
a) event data b) detector data c) statistical data
• Data can be transient or established
simple, simple, simple…

Principal design choices
• An algorithm knows only which data (name, type, etc.) is used as an input and produces as an output.
• The only connection between the algorithm objects is through data objects.
• The execution order of the sub-algorithms is the responsibility of the parent algorithm.
algorithm
Data store
A1 A2 A3
d1 d2, d3
d2 d4
d5d3, d4
A1
A2
A3
d1
d2
d3
d4
d5

Principal design choices. Abstract interface.
• Analysis objects have to understand only one, defined protocol.
• Access an object through defined interface only.• Define pure virtual methods, and leave the implementation
details to the analysis tool provider (custom foundation classes programmer).
• Use factories to be able to switch between implementations, without changing users code.

Reconstruction framework
• There is no the track reconstruction algorithm (there are many, each optimized for a specific task).
• We need a flexible framework for developing, evaluating and implementing tracking algorithms. For example we can develop classes encapsulating:a) reconstruction information (strip, hit, etc.) (inherited from the data class)b) the detector model (sector, layer, etc.) (again, extending the data class)c) algorithmic strategies (cluster finding, track finding, pattern reconstruction, alignment, etc.) (inherited from the algorithm class).

Foundation libraries. LHC++
• Modular replacement of current CERNLIB• Memory management• Persistency (I/O)• Math libraries.• CLHEP (foundation classes).• Random number generators.• HTL Histogram package.• Fitting and minimizing packages (Gemini, HepFitting,
Minuit, NAG)• Pythia-7 event generator (Lund people contribution)

Abstract interface for data analyses (AIDA)
• Factories - Used to instantiate new AIDA objects • Histograms - 1D, 2D and 3D binned histograms. • Clouds - 1D, 2D, and 3D un-binned histograms, useful for scatter
plots, rebinnable histograms and for unbinned fits. • Tuples - Arbitrary dimension Tuples • Trees - Used for arranging objects into folders, and for IO. • Plotting - Used for displaying plots • Functions - Used for plotting functions and fitting • Fitter - Used to perform binned and unbinned fits to the AIDA
data storage objects
Powerful set of interfaces for common physics analysis objects, such as histograms, ntuples, fitters, IO etc., which can be used regardless of which analysis tool is used (for example ROOT, JAS, etc.)

Why AIDA?
• The user needs to learn only one set of interfaces.• Same user code can be used with the different, AIDA-compliant
analysis applications.• Different analysis tools can exchange analysis objects (same
storage format, different functionalities from other tools).• LHC++, OpenScientist, GAUDI, JAS, etc.• C++ and Java

Abstract interface for data analyses (AIDA)
import hep.aida.*; import java.util.Random;
public class Histogram { public static void main(String[] argv) {
IAnalysisFactory af = IAnalysisFactory.create();
IHistogramFactory hf = af.createHistogramFactory(af.createTreeFactory().create());
IHistogram1D h1d = hf.createHistogram1D("test 1d",50,-3,3); IHistogram2D h2d = hf.createHistogram2D("test 2d",50,-3,3,50,-3,3); Random r = new Random(); for (int i=0; i<10000; i++) { h1d.fill(r.nextGaussian()); h2d.fill(r.nextGaussian(),r.nextGaussian()); } IPlotter plotter = af.createPlotterFactory().create("Plot"); plotter.createRegions(1,2,0); plotter.region(0).plot(h1d); plotter.region(1).plot(h2d); plotter.show(); } }

ITuple
• ITuple - interface to the Data– “get/set” methods for double, float, int, …– Information about columns: min, max, mean,
rms– Navigating: start(), next(), skip(int nRows)– Project ITuple into 1D, 2D, 3D histogram– New features for AIDA 3.0:
• Support for complex internal structures (subfolders)
• Chaining of ITuples

ITuple

IHistogram
• Binned histogram: IHistogram1D, 2D, 3D
– “fill” methods (with/without weight)– Histogram info: entries, mean, rms, axis– Bin info: centre, entries, height, error– Histogram arithmetic: add, multiply, divide– Convenience methods, like coordinate-to-
index conversion

IHistogram

ITree
• ITree– directory-like structure (Unix directory
convention)• Methods like: cd, ls, mkdir, etc.
– AIDA analysis objects (tuples, histograms, clouds, ets.) exist within ITree directories
– “save/restore” functionality, hides storage details from the user
• Compatible with database or file storage• Can support multiple file formats• Mount/Unmount functionality (like unix)
allows multiple stores to be seamlessly merged
• AIDA XML format is defined for data interchange

ITree

IFunction and Fetting
• Fitting: IFunction, IFitFunction– IFunction – simple interface, allows to set
parameters and get function value– IFitFunction – fit function to a histogram
• Extends IFunction• Various fit control methods: step size,
bounds, etc.• Allows to perform fit and get results• IFitter, IOptimizer, IFitResult, IPlotter

Conclusion
• Do not try to invent the wheel.• Start research projects to evaluate the following packages:
a) LHC++(http://wwwasd.web.cern.ch/wwwasd/lhc++/indexold.html)
b) AIDA (http://aida.freehep.org/index.thtml)
c) FLUKA (http://wwwasd.web.cern.ch/wwwasd/lhc++/clhep/manual/RefGuide )
d) Geant4 (http://wwwasd.web.cern.ch/wwwasd/geant4/geant4.html)
e) GAUDI (http://cern.ch/gaudi) f) VERTIGO and RecPack (CHEP04)
• Time to start defining the class structures for analysis, reconstruction and simulation frameworks.

















