
XML Fundamentals Transparency No. 1 XML Fundamentals Cheng-Chia Chen.
Upload
gary-anthonyCategory
view
231download
0
Cheng, Chen, Chen, Xie
Evaluating Probability Threshold k-Nearest-Neighbor Queries over Uncertain Data
Reynold Cheng (University of Hong Kong)Lei Chen (Hong Kong University of Science &Tech)Jinchuan Chen (Hong Kong Polytechnic University)Xike Xie (University of Hong Kong)
International Conference on Extending Database Technology 2009

Cheng, Chen, Chen, Xie
Agenda
1. Introduction 2. Problem Definition 3. Basic Solution 4. Efficient Solution 5. Results

Cheng, Chen, Chen, Xie
Data Uncertainty
Inherent in various applicationsLocation-based services (e.g., using GPS,
RFID) [TDRP98, SSDBM99]Natural habitat monitoring with sensor
networks [VLDB04a]Biomedical and biometric databases[ICDE06,
ICDE07]

Cheng, Chen, Chen, Xie
Attribute Uncertainty Model [TDRP98,ISSD99,VLDB04b]
y
PreciseLocation
x
yL
CloakedLocation
x
y
probabilitydensity function
U
(pdf)
Uncertainty region
We represent an uncertainty pdf as a histogram

Cheng, Chen, Chen, Xie
k-NN Queries
k-NN Query over Precise Data- application in LBS [VLDB03]- natural habitat monitoring system [VLDB04a]- network traffic analysis [ICDCS07]- pattern matching in CAM [VLDB04c]
k-NN over Uncertain Objects- [VLDB08a] ranks the probability each object is the NN of the query point.- [ICDE07a] use expected distance and does not discuss the probability.

Cheng, Chen, Chen, Xie
Agenda
1. Introduction 2. Problem Definition 3. Basic Solution 4. Efficient Solution 5. Results

Cheng, Chen, Chen, Xie
Probability Threshold k-Nearest-Neighbor Query (T-k-PNN)
INPUT
1. A query point q, parameter k, threshold T
2. A set of n objects with uncertainty regions and pdfs
OUTPUT A number of k-subset
p(S) is the qualification probability of the k-subset S})(|||{ TSpkSDSS
}...,{ 21 nOOOD

Cheng, Chen, Chen, Xie
Example of a k-PNN query (k=3)
{O1, O2 , O3}
{O1, O2 , O4}
O2
O3
O1
O4
O5
O6
O7
O8
q

Cheng, Chen, Chen, Xie
Example of a k-PNN query (k=3)
O2
O3
O1
O4
O5
O6
q
{O1, O2, O3} {O1, O2, O4}
…
{O6, O7, O8}
5683 C
k-bound
2063 C
{O1, O2, O3} {O1, O2, O4}
…
{O4, O5, O6}
O7
O8

Cheng, Chen, Chen, Xie
k-bound Filtering (k=3)
O2
O3
O1
O4
O5
O6
q
k-bound
O7
O8
f1
f2
f3
fk (k-bound): is the k-th minimum maximum distance
Since min(r7)> f3, O7 can not be 3-NN of q. Because there are always 3 objects with distances smaller than f3.We apply k-bound filtering on an index (e.g. R-tree) to prune unqualified objects.

Cheng, Chen, Chen, Xie
Agenda
1. Introduction 2. Problem Definition 3. Basic Solution 4. Efficient Solution 5. Results

Cheng, Chen, Chen, Xie
Basic solution for a T-k-PNN query (k=3,T=0.1)
3-subset QP
{O1, O2, O3} 0.2
{O1, O2, O4} 0.1
{O1, O3, O4} 0.1
{O2, O3, O4} 0.1
0.05{O2, O3, O5}
0.05{O1, O3, O5}
……
0.05{O1, O2, O5}
0.05{O1, O2, O5}
0.1{O2, O3, O4}
0.1{O1, O3, O4}
0.1{O1, O2, O4}
0.2{O1, O2, O3}
QP3-subset
O2
O3
O1
O4
O5
O6
q
k-bound
T=0.1
Exact QP is expensive to compute!
Too many k-subsets!
Step1: k-bound filteringStep2: QP CalculationStep3: Accept S, if qp(S)≥T
Symbol Meaning
ri |oi − q|
di(r) pdf of ri (distance pdf)
Di(r) cdf of ri (distance cdf)

Cheng, Chen, Chen, Xie
Agenda
1. Introduction 2. Problem Definition 3. Basic Solution 4. Efficient Solution 5. Results

Cheng, Chen, Chen, Xie
Efficient Solution Framework (GVR)
Lower bound
Upper bound3.
4. Refinement
k-subset Generation
k-subset VerificationAndRefinement
k-subsets
rejectedk-subsets
acceptedk-subsets
Candidate Objects
1. k-bound Filtering
2. Probabilistic Candidate Selection
k-subsets GenerationVerificationRefinement

Cheng, Chen, Chen, Xie
Probabilistic Candidates Selection
so kii
frScp )Pr()(
)()( ScpSqp
O2
O3
O1
O4
O5
O6
q
k-bound
0.1
0.2
0.5
Cutoff Probability of Oi : Pr(ri ≤fk)
SSScpScp '),()(
S1={O4, O5,O6}cp(S1)=0.5*0.2*0.1 = 0.01S2={O4, O5}
cp(S2)=0.5*0.2 = 0.1Given T=0.2, if cp(S2) < T, then qp(S1)<cp(S1)<T.S1 can be pruned.

Cheng, Chen, Chen, Xie
Probabilistic Candidates Selection
0.5{O4}
0.2{O5}
0.1{O6}
1{O3}
1{O2}
1{O1}
CP1-subset
0.2{O2, O3, O5}
0.2{O1, O3, O5}
0.1{O1, O4, O5}
0.5{O2, O3, O4}
0.1{O2, O4, O5}
0.1{O3, O4, O5}
0.5{O1, O3, O4}
0.2{O1, O2, O5}
0.5{O1, O2, O4}
1{O1, O2, O3}
CP3-subset
1{O2,O3}
0.5{O2,O4}
0.2{O2,O5}
0.5{O3,O4}
0.2{O3,O5}
0.2{O1,O5}
0.1{O4,O5}
0.5{O1,O4}
1{O1,O3}
1{O1,O2}
CP2-subset
T=0.2, k=3

Cheng, Chen, Chen, Xie
Storage Efficient Compression
1{O2,O3}
0.5{O2,O4}
0.2{O2,O5}
0.5{O3,O4}
0.2{O3,O5}
0.2{O1,O5}
0.5{O1,O4}
1{O1,O3}
1{O1,O2}
CP2-subset
Subsets are sorted in descending order of their CPs.
{O3,O5}
{O2,O5}
{O1,O5}
Size-2 Set
Original subsets
Compressed subsets
Store the common prefix of the subsetsAnd the last element of the subset that has the minimum product of cutoff probability greater than T

Cheng, Chen, Chen, Xie
Storage Efficient Compression
0.5{O4}
0.2{O5}
0.1{O6}
1{O3}
1{O2}
1{O1}
CP1-subset
0.2{O2, O3, O5}
0.2{O1, O3, O5}
0.1{O1, O4, O5}
0.5{O2, O3, O4}
0.1{O2, O4, O5}
0.1{O3, O4, O5}
0.5{O1, O3, O4}
0.2{O1, O2, O5}
0.5{O1, O2, O4}
1{O1, O2, O3}
CP3-subset
1{O2,O3}
0.5{O2,O4}
0.2{O2,O5}
0.5{O3,O4}
0.2{O3,O5}
0.2{O1,O5}
0.1{O4,O5}
0.5{O1,O4}
1{O1,O3}
1{O1,O2}
CP2-subset
{O4}
{O5}
{O3}
{O2}
{O1}
Size-1 Set
{O3,O5}
{O2,O5}
{O1,O5}
Size-2 Set Size-3 Set
{O1,O2,O5}
{O1,O3,O5}
{O2,O3,O5}
T=0,2, k=3

Cheng, Chen, Chen, Xie
O3
Seeds Pruning
O1
O2
q
O4
k=3
f1
f2f3
min(r4) > f2 > f1
Seeds: o1, o2, o3
If o4 belongs to a 3-nn set S, o1 and o2 must also belong to S.
r4 > r2 r4 > r1
min(r4)
For example, we can prune the set {o1,o3,o4}, according to the above rule.
max(r1) =f1 max(r2) =f2 max(r3) =f3
No CP calculation is needed.
Can prune more candidate k-sets

Cheng, Chen, Chen, Xie
Verifiers: Upper and Lower Bounds (T=0.2)
Candidates k-subsets
(After PCS)
0
1
S1 1
0
0.190.19
0.6
0.10.5 ?
0.4
0.540.14
0.15
0.180.03
Verifier Incremental Refinement
Classifier
1
1
0
S2
1 S3
0
1

Cheng, Chen, Chen, Xie
Verification and Refinement
0.3 0.3 0.1
0.3 0.7
0.30.7
r1
r2
r3
0.3 0.5 0.8
0.3 1
0.9
10.7
P1 P2 P3 P4
D1(e4)
e2 e3 e4e1
P1 P2 P3
r1
r2
r3
q
e5
f2
0.1
P4
0.2
Partitions Stair-Case Model
Divide the range [min(r1), fk] into a series of partitions.
Extended from the probabilistic verifiers in [ICDE08b]
Build a data structure, i.e. stair-case model, to store the distance cdf of each object.
Derive the lower and upper bounds of a k-set’s QP based on the stair-case model.
Reject (Accept) a k-set once its QP must be lower (larger) than the threshold.

Cheng, Chen, Chen, Xie
Agenda
1. Introduction 2. Problem Definition 3. Basic Solution 4. Efficient Solution 5. Results

Cheng, Chen, Chen, Xie
Experiment Setup
Uncertain Object DB
Long Beach (53k)(http://www.census.gov/geo/www/tiger/)
Uncertainty pdf Uniform (default)Gaussian (represented by histograms)
Threshold (T) 0.1
k 6
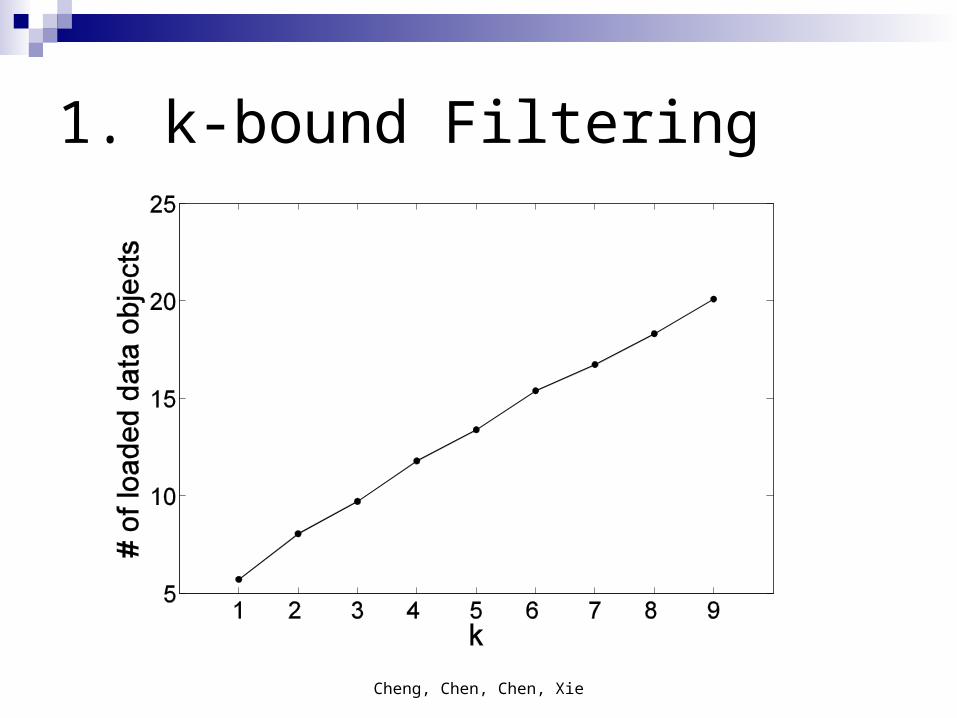
Cheng, Chen, Chen, Xie
1. k-bound Filtering

Cheng, Chen, Chen, Xie
2. Performance of GVR

Cheng, Chen, Chen, Xie
3. k-subset Generation

Cheng, Chen, Chen, Xie
3. k-subset Generation

Cheng, Chen, Chen, Xie
4. Verification and Refinement
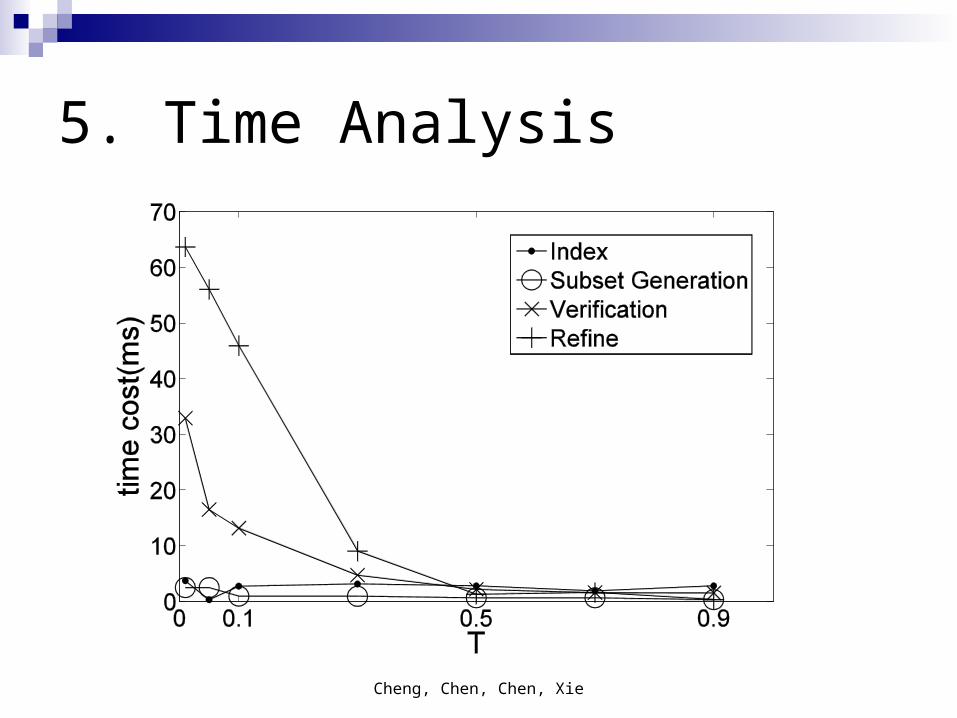
Cheng, Chen, Chen, Xie
5. Time Analysis

Cheng, Chen, Chen, Xie
6. Gaussian Distribution

Cheng, Chen, Chen, Xie
Conclusion
We proposed an efficient evaluation framework for T-k-PNN query
We proposed various techniques:- k-bound to filter away those unqualified objects- PCS to reduce the number of k-subsets- verification/refinement methods to avoid exact calculation
Future Work- extend the techniques to other queries

Cheng, Chen, Chen, Xie
Reference [TDRP98] P. A. Sistla, O. Wolfson, S. Chamberlain, and S. Dao,“Querying the uncertain position of moving objects,” in Temporal
Databases: Research and Practice, 1998. [SSDBM99] D.Pfoser and C. Jensen, “Capturing the uncertainty of moving-objects representations,” in Proc. SSDBM, 1999. [VLDB04a] A. Deshpande, C. Guestrin, S. Madden, J. Hellerstein, and W. Hong, “Model-driven data acquisition in sensor networks,” in
Proc. VLDB, 2004. [ICDE06] C. Böhm, A. Pryakhin, and M. Schubert, “The gauss-tree: Efficient object identification in databases of probabilistic feature
vectors,” in Proc. ICDE, 2006. [ICDE07a] V. Ljosa and A. K. Singh, “APLA: Indexing arbitrary probability distributions,” in Proc. ICDE, 2007. [SIGMOD03] R. Cheng, D. Kalashnikov, and S. Prabhakar, “Evaluating probabilistic queries over imprecise data,” in Proc. ACM SIGMOD,
2003. [ICDE07b] J. Chen and R. Cheng, “Efficient evaluation of imprecise location-dependent queries,” in Proc. ICDE, 2007. [VLDB06a] M. Mokbel, C. Chow, and W. G. Aref, “The new casper: Query processing for location services without compromising privacy,”
in VLDB, 2006. [TKDE92] D. Barbara, H. Garcia-Molina, and D. Porter, “The management of probabilistic data,” TKDE, vol. 4, no. 5, 1992. [VLDB04b] N. Dalvi and D. Suciu, “Efficient query evaluation on probabilistic databases,” in VLDB, 2004. [VLDB06b] P. Agrawal, O. Benjelloun, A. D. Sarma, C. Hayworth, S. Nabar, T. Sugihara, and J. Widom, “Trio: A system for data,
uncertainty, and lineage,” in VLDB, 2006. [VLDB03] G. Iwerks, H. Samet, and K. Smith, “Continuous k-nearest neighbor queries for continuously moving points with updates,” in
Proc. VLDB, 2003. [ICDCS07] S. Ganguly, M. Garofalakis, R. Rastogi, and K. Sabnani, “Streaming algorithms for robust, real-time detection of ddos attacks,”
in ICDCS, 2007. [AKDDM96] U. Fayyad, G. Piatesky-Shapiro, P. Smyth, and R. Uthurusamy, Advances in Knowledge Discovery and Data Mining. AAAI
Press/MIT Press, 1996. [VLDB04c] N. Koudas, B. Ooi, K. Tan, and R. Zhang, “Approximate NN queries on streams with guaranteed error/performance bounds,” in
Proc. VLDB, 2004. [VLDB08a] G. Beskales, M. Soliman, and I. Ilyas, “Efficient search for the top-k probable nearest neighbors in uncertain databases,” in
VLDB, 2008. [VLDB06c] O. Mar, A. Sarma, A. Halevy, and J. Widom, “ULDBs: databases with uncertainty and lineage,” in VLDB, 2006.

Cheng, Chen, Chen, Xie
Reference [VLDB07a] L. Antova, C. Koch, and D. Olteanu, “Query language support for incomplete information in the maybms system,” in Prof.
VLDB, 2007. [SIGMOD08a] S. Singh et al, “Orion 2.0: Native support for uncertain data,” in Prof. ACM SIGMOD, 2008. [ICDE08a] Singh et al, “Database support for pdf attributes,” in Proc. ICDE, 2008. [TKDE04] R. Cheng, D. V. Kalashnikov, and S. Prabhakar, “Querying imprecise data in moving object environments,” IEEE TKDE, vol. 16,
no. 9, Sept. 2004. [DASFAA07] H. Kriegel, P. Kunath, and M. Renz, “Probabilistic nearest-neighbor query on uncertain objects,” in DASFAA, 2007. [MUD08] Y. Qi, S. Singh, R. Shah, and S. Prabhakar, “Indexing probabilistic nearest-neighbor threshold queries,” in Proc. Workshop on
Management of Uncertain Data, 2008. [TKDE08] X. Lian and L. Chen, “Probabilistic group nearest neighbor queries in uncertain databases,” IEEE Trans. On Knowledge and
Data Engineering, vol. 20, no. 6, 2008. [ICDE08b] R. Cheng, J. Chen, M. Mokbel, and C. Chow, “Probabilistic verifiers: Evaluating constrained nearest-neighbor queries over
uncertain data,” in Proc. ICDE, 2008. [VLDB05] Y. Tao, R. Cheng, X. Xiao, W. K. Ngai, B. Kao, and S. Prabhakar, “Indexing multi-dimensional uncertain data with arbitrary
probability density functions,” in Proc. VLDB, 2005. [VLDB07b] J. Pei, B. Jiang, X. Lin, and Y. Yuan, “Probabilistic skylines on uncertain data,” in Proc. VLDB, 2007. [SIGMOD08b] X. Lian and L. Chen, “Monochromatic and bichromatic reverse skyline search over uncertain databases,” in Proc.
SIGMOD, 2008. [ICDE07c] M. Soliman, I. Ilyas, and K. Chang, “Top-k query processing in uncertain databases,” in Proc. ICDE, 2007. [SIGMOD08c] M. Hua, J. Pei, W. Zhang, and X. Lin, “Ranking queries on uncertain data: A probabilistic threshold approach,” in Proc.
SIGMOD, 2008. [VLDB08b] V. Rastogi, D. Suciu, and E. Welbourne, “Access control over uncertain data,” in Proc. VLDB, 2008. [VLDB08c] C. Koch and D. Olteanu, “Conditioning probabilistic databases,” in Proc. VLDB, 2008. [VLDB08d] R. Cheng, J. Chen, and X. Xie, “Cleaning uncertain data with quality guarantees,” in Proc. VLDB, 2008. [SIGMOD84] A. Guttman, “R-trees: A dynamic index structure for spatial searching,” Proc. of the ACM SIGMOD Int’l. Conf., 1984.

Cheng, Chen, Chen, Xie
Q & A
Thanks!


















