
Caching and reliability - Computer Systems Laboratory...
28
Caching and reliability
Transcript of Caching and reliability - Computer Systems Laboratory...

Caching and reliability

Block cache
• Caching disk contents in RAM
– Hit ratio h : probability of data existing in cache
– 𝑠𝑝𝑒𝑒𝑑𝑢𝑝 =10ℎ+106 1−ℎ
106 10 for h=0.9, 2 for h=0.5
Vs.
Latency ~10 ns 1~ ms
Access unit Byte (word) Sector
Capacity Gigabytes Terabytes
Price Expensive Cheap

Block cache operation in OS
File A
Process A Process B Process Z
File A File B File A
File B
Inode A Inode B Directory A
File A File B
Inode A Inode B
Directory A
FP a FP b FP c

What to cache?
• Best scenario
– Caching data to access in near future: high hit rate
– Impossible: cannot foresee the future
• Replacement algorithms
– FIFO / LIFO
– Least-Recently Used• Simple and known to be universal solution
– Least-Frequently Used
– Second chance algorithms: clock, multi-queue, …

LRU-approximate algorithms
• x86 page table
– Accessed / dirty bits per page
• Check page table regularly identify recently-accessed pages

Cache eviction algorithms
• Clock
– Round robin page scanning
– Check accessed flag• If set, clear
• If not set, evict
• Second chance
– Improved clock algorithm
– Give second chance to the not accessed pages
– Evict at the second chance
accessed
accessed
accessedaccessed
accessed

Cache eviction algorithms
• Multi-queue
– Multiple LRU/FIFO queues
– Promote when accessed
– Demote at the end of Q
– Evict the lowest Q’s LRU entry
Most Recent
Q1
Q2
Q3
Evict
DemotePromote
Swapping vs. eviction
Cached page: page with an associated inode and a file offset
Anonymous page: page allocated by an application

Linux 2-queue algorithm
• Clock algorithm for each queue
Head
Tail
mark_page_accessed()
Reclamation
Act
ive
list
Head
Tail
lru_cache_add()
Eviction (write-back)In
acti
ve li
st

Linux page cache API
• Adding to page cache
– void add_to_page_cache(struct page * page, struct address_space * mapping, unsigned long offset)
– struct page * page_cache_alloc(struct address_space *x)
– int page_cache_read(struct file * file, unsigned long offset)
• Removing from page cache
– Case: file is erased while it is in page cache
– void remove_inode_page(struct page *page)
– void page_cache_release(struct page *page)c.f.) void page_cache_get(struct page *page)

Caching and consistency
• Out-of-order writes
– A transaction of pages update completes an atomic I/O• Ex. Append to a file:
Data block – new dataFree block bitmap – mark allocated blocksInode – increase size, add allocated blocksSuperblock – decrease the number of free blocks
– Higher-level objects are updated frequently prone to write
– Buffer cache evicts pages in unpredictable order
RAM
FS
i b Ds D
i b Ds D

Consistency problem
• Failure in-writing
– Power failure
– Device failure: bad blocks, bit-flip, wear-out, …
– S/W Bugs
RAM
FS
i b Ds D
i b Ds D

Low-level mechanisms
• Surviving hardware failures
– Replication (RAID, backup)
– Checksum (ECC)
– Remapping and warning (SMART)
– UPS
• Out-of-order writes
– Blocking I/O
– I/O Barrier (NCQ)
I/O barrier

Enforcing Reliability
• Static mapping
– Read-only file system, root directory of FAT, …
– Reliable but inflexible
• Synchronous write
– Low performance
– Reliable?• ex. rename(a, b)
a
b
file

Enforcing Reliability <Journaling>
• Journaling : write-ahead logging [Hagmann, SOSP’87]
– Log file system operation
– Redo in recovery time
– Fast disaster recovery
– Additional overhead
• Log and checkpoint: after checkpoint, discards logs
FS
i d Ds D
RAM
i d Ds D
Log
d i s
Logging Check-pointing

Enforcing Reliability <Shadow paging>
• Shadow paging [Chamberlin, ACM Comm’81]
– Btrfs, XFS, DFS, …
– Avoid in-place updates
– Cascaded updates propagation
• Log-structured file system [Rosenblum, ACM ToCS’92]
– Transform every file system updates to log operations
– Good for write operations
– Heavy garbage collection overhead
inode
data data data

Ext* File System Journaling Mechanism

Goal of file system journaling
• Until ext2, on every system crash
– File can be lost or corrupted
– File system itself is corrupted
– File system checker (fsck) must be executed before mountLong time to check and correct the file system
• Journaling: a safety measure
– All data is conserved
– Some data can be lost, but file system must be consistent
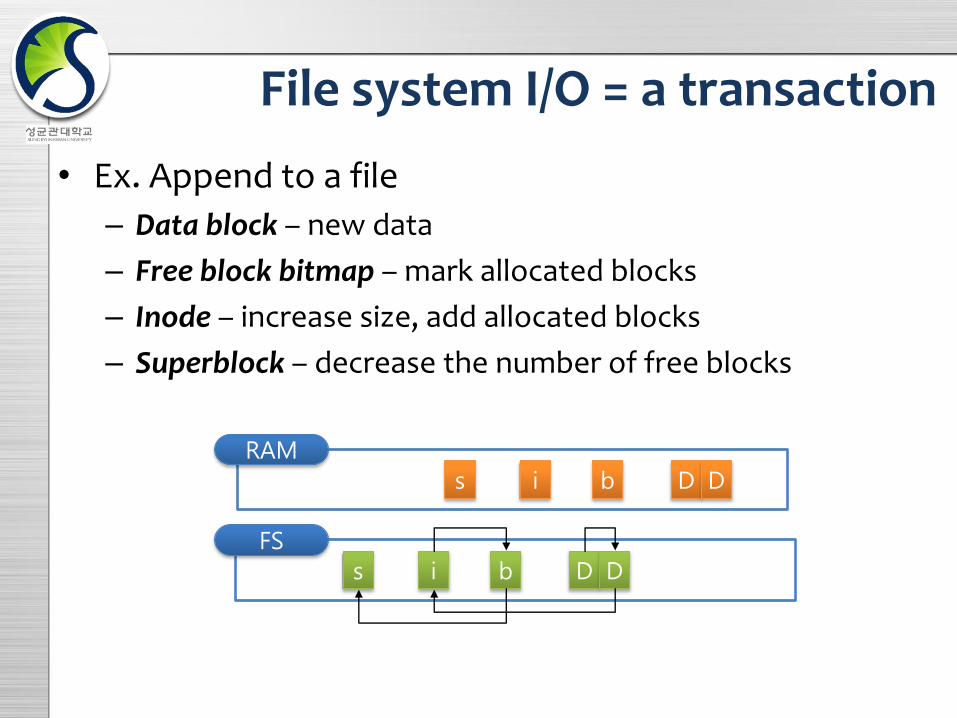
File system I/O = a transaction
• Ex. Append to a file
– Data block – new data
– Free block bitmap – mark allocated blocks
– Inode – increase size, add allocated blocks
– Superblock – decrease the number of free blocks
RAM
FS
i b Ds D
i b Ds D

• Write log of updates before applying them to FS
• System failure cases
– Crash while logging Ignore the log
– Crash after logging: during file system update
Replay log to apply
– Crash after file system updates No need to replay
Write ahead logging
FS
i d Ds D
RAM
i d Ds D
File system updateLog
d i s D D
Logging

Elements of transaction
• Log records
– Low-level operation of ext3fs: every updated blocks
– Whole block or changes only?
• Buffer_head in ext3/jbd journal_head
• Transaction
– An atomic group of log records• Modified blocks consisting an atomic operation
– One transaction for each FS operation
bh buf bh
bufbuf

Transaction group
• Problem: High overhead for small I/Os
– A few blocks updates for each transaction
• Solution
– Group some transactions to update journal
Descriptor block
Transaction 1 Transaction 2 Transaction 3Commit
block
Tx IDblock offsets
Modified blocksEnd of
transaction

Journal structure
• File or external device
– Special inode (5) for journal
• Journal file: circular log
– At the center of partition
journalsb sb
S_blocksize Block size
S_maxlen Nr. Blocks in journal file
S_first First block of log information
S_sequence First commit ID
S_start Block no. of start of log
S_errno Errno of last journal abort

Commit and Checkpoint
• Commit
– Write a transaction group to journal
– Two stage: (descriptor block, log blocks) (commit block)
– After commit complete, they can be recovered by replay
– Cached updated blocks remain in memory after commit File system update are done using the cached blocks
• Checkpoint
– Force flush modified blocks to file system
– No need to read from log (cached in memory)
– Blocks can be written between commit and checkpoint

Commit a transaction
• Condition: every 5 sec / sync I/O / too many buffers
– kernel thread kjournald
Transaction group
Trans 1 Trans 2 Trans 3
Transaction group
handle
Running RunningLocked
CommittingCommit
Descriptor block
Transact 1 Transact 2 Transact 3Commit
blockDescriptor
blockTransact 1
Now, updated blocks in the transaction can be written to FS

Checkpoint
• Flushing dirty blocks in journal
– To restrict journal size and recovery time
– Replay: logs after the checkpoint
– Optimal checkpoint interval?
• Ext3: circular log
– Write dirty blocks (in page cache) in the oldest transaction
tx1 tx2 tx3 tx4tx0 tx5 tx6 tx7 tx8
Checkpoint!
tx9
tx1 tx2 tx3 tx4tx0 tx5 tx6 tx7 tx8
Checkpoint!
tx9

Journaling modes
• Journal data
– Journal metadata and data blocks
– Highest safety with high overhead
• Ordered data (default)
– Journal metadata only
– Data blocks must be updated before commit
• Writeback data
– Journal metadata only
– Don’t care when the data blocks are written
– Unsafe but fast

Journaling modes in ext3

Recovery
• When: mount time
• Procedure
– Check superblock: nothing to do on clean unmount
– Round 1: find start and end of the log
– Round 2: update revoke table
– Round 3: write valid journal blocks in to FS
– Start a new transaction at the end of the journal• Update superblock
tx1 tx2 tx3 tx4 tx5 tx6 tx7 tx8
Checkpoint!
tx9


















