
BWT-Based Compression Algorithms Haim Kaplan and Elad Verbin Tel-Aviv University Presented in CPM...
46
BWT-Based Compression Algorithms Haim Kaplan and Elad Verbin Tel-Aviv University Presented in CPM ’07, July 8 , 2007
-
Upload
melvyn-summers -
Category
Documents
-
view
215 -
download
1
Transcript of BWT-Based Compression Algorithms Haim Kaplan and Elad Verbin Tel-Aviv University Presented in CPM...

BWT-Based Compression Algorithms
Haim Kaplan and Elad VerbinTel-Aviv University
Presented in CPM ’07, July 8 , 2007

Results
• Cannot show constant c<2 s.t.
• Similarly,• no c<1.26 for BWRL
• no c<1.3 for BWDC
• Probabilistic technique.
0. 0( ) ( ) ( )s BW s c nH s o n

Outline● Part I: Definitions● Part II: Results● Part III: Proofs● Part IV: Experimental Results

Part I: Definitions

BW0The Main Burrows-Wheeler Compression
Algorithm:
Compressed String S’
String S BWTBurrows-Wheeler Transfor
m
MTFMove-to-
front
Order-0 Encoding
Text with local uniformity
Text in English (similar contexts -> similar character)
Integer string with many small numbers

The BWT
● Invented by Burrows-and-Wheeler (‘94)● Analogous to Fourier Transform (smooth!)
string with context-regularity
BWT
string with spikes (close repetitions)
s
s
mississippi
ipssmpissii
[Fenwick]

p i#mississi pp pi#mississ is ippi#missi ss issippi#mi ss sippi#miss is sissippi#m i
i ssippi#mis s
m ississippi #i ssissippi# m
The BWTT = mississippi#
mississippi#ississippi#mssissippi#mi sissippi#mis
sippi#missisippi#mississppi#mississipi#mississipi#mississipp#mississippi
ssippi#missiissippi#miss Sort the rows
# mississipp ii #mississip pi ppi#missis s
F L=BWT(T)
T
BWT sorts the characters by their post-context

BWT Facts
1. permutes the text2. (≤n+1)-to-1 function

Move To Front
● By Bentley, Sleator, Tarjan and Wei (’86)
string with spikes (close repetitions)
ipssmpissii
integer string with small numbers
0,0,0,0,0,2,4,3,0,1,0
move-to-front
s
's

Move to Front
a,b,r,c,dabracadabra

Move to Front
a,b,r,c,d0abracadabraa,b,r,c,dabracadabra

Move to Front
b,a,r,c,d0,1abracadabraa,b,r,c,d0abracadabraa,b,r,c,dabracadabra

Move to Front
r,b,a,c,d0,1,2abracadabrab,a,r,c,d0,1abracadabraa,b,r,c,d0abracadabraa,b,r,c,dabracadabra

Move to Front
a,r,b,c,d0,1,2,2abracadabrar,b,a,c,d0,1,2abracadabrab,a,r,c,d0,1abracadabraa,b,r,c,d0abracadabraa,b,r,c,dabracadabra

Move to Front
c,a,r,b,d0,1,2,2,3abracadabraa,r,b,c,d0,1,2,2abracadabrar,b,a,c,d0,1,2abracadabrab,a,r,c,d0,1abracadabraa,b,r,c,d0abracadabraa,b,r,c,dabracadabra

Move to Front
a,c,r,b,d0,1,2,2,3,1abracadabrac,a,r,b,d0,1,2,2,3abracadabraa,r,b,c,d0,1,2,2abracadabrar,b,a,c,d0,1,2abracadabrab,a,r,c,d0,1abracadabraa,b,r,c,d0abracadabraa,b,r,c,dabracadabra

Move to Front
0,1,2,2,3,1,4,1,4,4,2abracadabraa,c,r,b,d0,1,2,2,3,1abracadabrac,a,r,b,d0,1,2,2,3abracadabraa,r,b,c,d0,1,2,2abracadabrar,b,a,c,d0,1,2abracadabrab,a,r,c,d0,1abracadabraa,b,r,c,d0abracadabraa,b,r,c,dabracadabra

After MTF● Now we have a string with small numbers:
lots of 0s, many 1s, …● Skewed frequencies: Run Arithmetic!
Character frequencies

BW0The Main Burrows-Wheeler Compression
Algorithm:
Compressed String S’
String S BWTBurrows-Wheeler Transfor
m
MTFMove-to-
front
Order-0 Encoding
Text with local uniformity
Text in English (similar contexts -> similar character)
Integer string with many small numbers
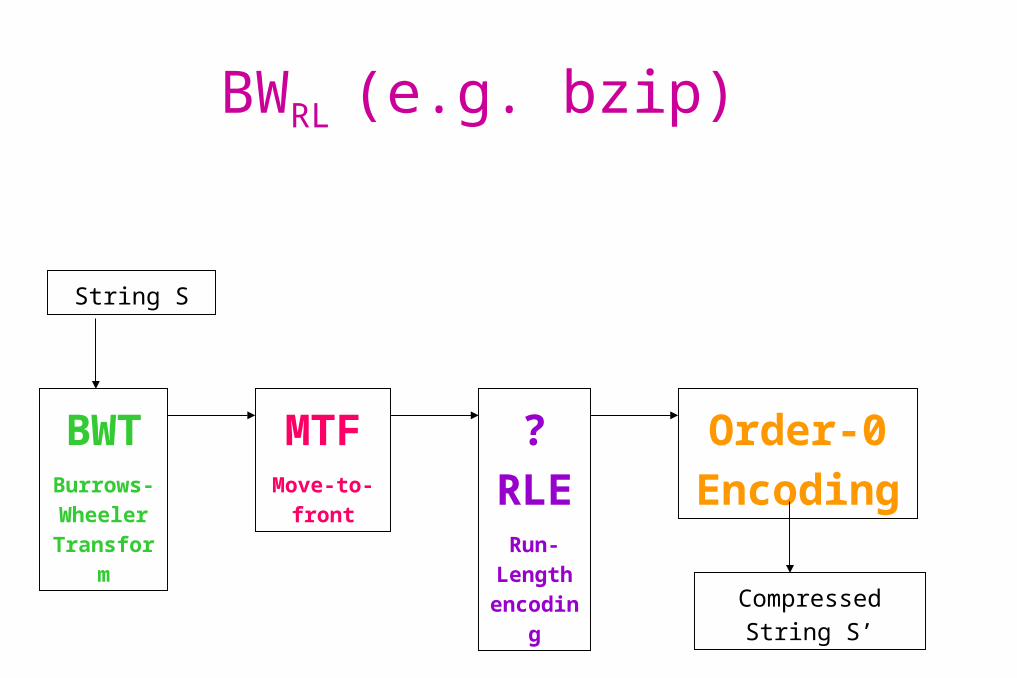
BWRL (e.g. bzip)
Compressed String S’
String S
BWTBurrows-Wheeler Transfor
m
MTFMove-to-
front
? RLE
Run-Length encodi
ng
Order-0 Encoding

Many more BWT-based algorithms
● BWDC: Encodes using distance coding instead of MTF
● BW with inversion frequencies coding● Booster-Based [Ferragina-Giancarlo-
Manzini-Sciortino]● Block-based compressor of Effros et al.

order-0 entropy
Lower bound for compression without context information
n
nnsnH log)(0
S=“ACABBA”
1/2 `A’s: Each represented by 1 bit
1/3 `B’s: Each represented by log(3) bits
1/6 `C’s: Each represented by log(6) bits
6*H0(S)=3*1+2*log(3)+1*log(6)

order-k entropy
= Lower bound for compression with order-k contexts
)(snH k
)()( 0 sw
sk wHwsnHk

order-k entropy
mississippi:Context for i: “mssp”Context for s: “isis”Context for p: “ip”
6)"("4 0 msspH4)"("4 0 isisH
2)"("2 0 ipH
1(" ") 12nH mississippi
0 (" ") 20.03nH mississippi

Part II: Results

Measuring against Hk
● When performing worst-case analysis of lossless text compressors, we usually measure against Hk
● The goal – a bound of the form:|A(s)|≤ c×nHk(s)+lower order term
● Optimal: |A(s)|≤ nHk(s)+lower order term

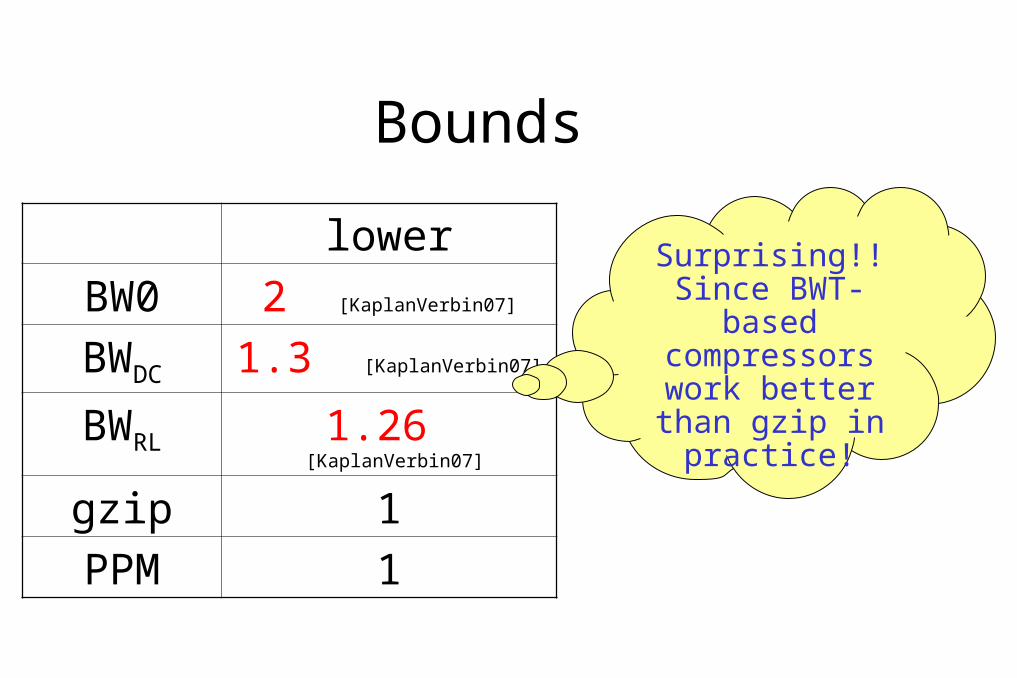
Bounds
lower Upper
BW0 2 [KaplanVerbin07] 3.33 [ManziniGagie07]
BWDC 1.3 [KaplanVerbin07] 1.7 [KaplanLandauVerbin06]
BWRL 1.26 [KaplanVerbin07] 5 [Manzini99]
gzip 1 1
PPM 1 1

Bounds
lower Upper
BW0 2 [KaplanVerbin07] 3.33 [ManziniGagie07]
BWDC 1.3 [KaplanVerbin07] 1.7 [KaplanLandauVerbin06]
BWRL 1.26 [KaplanVerbin07] 5 [Manzini99]
gzip 1 1
PPM 1 1
a
. 0( ) 2 ( ) (1)ks k BW s nH s o

Bounds
lower Upper
BW0 2 [KaplanVerbin07] 3.33 [ManziniGagie07]
BWDC 1.3 [KaplanVerbin07] 1.7 [KaplanLandauVerbin06]
BWRL 1.26 [KaplanVerbin07] 5 [Manzini99]
gzip 1 1
PPM 1 1
Bounds
lower
BW0 2 [KaplanVerbin07]
BWDC 1.3 [KaplanVerbin07]
BWRL 1.26 [KaplanVerbin07]
gzip 1
PPM 1
Surprising!! Since BWT-based compressors
work better than gzip in practice!

Possible Explanations
1. Asymptotics:
and real compressors cut into blocks, so
2. English Text is not Markovian!• Analyzing on different model might show BWT's
superiority
( ) ( ) ( / log )
( ) 1.7 ( ) (log )
k
DC k
gzip s nH s O n n
BW s nH s O n
n

Part III: Proofs

Lower bound● Wish to analyze BW0=BWT+MTF+Order0● Need to show s s.t.● Consider string s: 103 `a', 106 `b'
Entropy of s● BWT(s):
same frequencies MTF(BWT(s)) has: 2*103 `1', 106-103 `0‘ Compressed size: about
3 310 log(10 )
3 32 10 log(10 / 2)
need BWT(s) to have many isolated `a’s
00( ) 2 ( ) (1)BW s nH s o

many isolated `a’s● Goal: find s such that in BWT(s), most `a’s are
isolated● Solution: probabilistic.
BWT is (≤n+1)-to-1 function.● A random string s’ has ≥1/(n+1) chance of being a
BWT-image● A random string has ≥1-1/n2 chance of having “many”
isolated `a’s Therefore, such a string exists

General Calculation● s contains pn `a’s, (1-p)n `b’s.
Entropy of s:● MTF(BWT(s)) contains 2p(1-p)n `1’s, rest `0’s
compressed size of MTF(BWT(s)):
● Ratio:
1 1log (1 ) log
1p p
p p
12 (1 ) log
2 (1 )p p
p p
0
12 (1 ) log
2 (1 )2
1 1log (1 ) log
1
p
p pp p
p pp p

Lower bounds on BWDC, BWRL
● Similar technique. p infinitesimally small gives compressible string. So maximize ratio over p.
● Gives weird constants, but quite strong

Experimental Results
• Sanity Check: Picking texts from above Markov models really shows behavior in practice
• Picking text from “realistic” Markov sources also shows non-optimal behavior• (“realistic” = generated from actual texts)
• On long Markov text, gzip works better than BWT

Bottom Line● BWT compressors are not optimal
(vs. order-k entropy) ● We believe that they are good since English text is
not Markovian.● Find theoretical justification!
● also improve constants, find BWT algs with better ratios, ...

Thank You!

Additional Slides (taken out for lack of time)

BWT - Invertibility
● Go forward, one character at a time

Main Property: L F mapping● The ith occurrence of c in L
corresponds to the ith occurrence of c in F.
● This happens because the characters in L are sorted by their post-context, and the occurrences of character c in F are sorted by their post-context.
p i#mississi pp pi#mississ is ippi#missi ss issippi#mi ss sippi#miss is sissippi#m i
i ssippi#mis s
m ississippi #i ssissippi# m
# mississipp ii #mississip pi ppi#missis s
F Lunknown

BW0 vs. Lempel-Ziv
● BW0 dynamically takes advantage of context-regularity
● Robust, smooth, alternative for Lempel-Ziv

BW0 vs. Statistical Coding● Statistical Coding (e.g. PPM):
Builds a model for each context Prediction -> Compression
Exploits similarities between similar contexts
Optimally models each context
Explicit partitioning – produces a model for
each context
No explicit partitioning to contexts
PPMBW0

Compressed Text Indexing
● Application of BWT● Compressed representation of text, that
supports: fast pattern matching (without
decompression!) Partial decompression
● So, no need to ever decompress! space usage: |BW0(s)|+o(n)
● See more in [Ferragina-Manzini]

Musings
● On one hand: BWT based algorithms are not optimal, while Lempel-Ziv is.
● On the other hand: BWT compresses much better
● Reasons:
1. Results are Asymptotic. (EE reason)
2. English text was not generated by a Markov source (real reason?)
● Goal: Get a more honest way to analyze● Use a statistic different than Hk?


















