
Bloom Based Filters for Hierarchical Data Georgia Koloniari and Evaggelia Pitoura University of...
38
Bloom Based Filters Bloom Based Filters for Hiera for Hiera r r chical Data chical Data Georgia Koloniari and Evaggelia Pitoura University of Ioannina, Greece
-
Upload
unique-enix -
Category
Documents
-
view
217 -
download
1
Transcript of Bloom Based Filters for Hierarchical Data Georgia Koloniari and Evaggelia Pitoura University of...

Bloom Based Filters for Bloom Based Filters for HieraHierarrchical Datachical Data
Georgia Koloniari and Evaggelia Pitoura University of Ioannina, Greece

2
OutlineOutline• Motivation• Problem Description• Related Work• Our approach: Multi-Level Bloom Filters• Performance Evaluation• Hierarchical Distribution of Filters• Experimental Results• Conclusions• Future Work

3
MotivationMotivation
• Evolution of peer-to-peer systems as an effective way of sharing data
• Wide use of XML for data representation and exchange in the Internet
• Service Descriptions in XML-based languages• Growing interest in content-based routing of data
Challenge: How to efficiently discover the appropriate data based on their content?
4
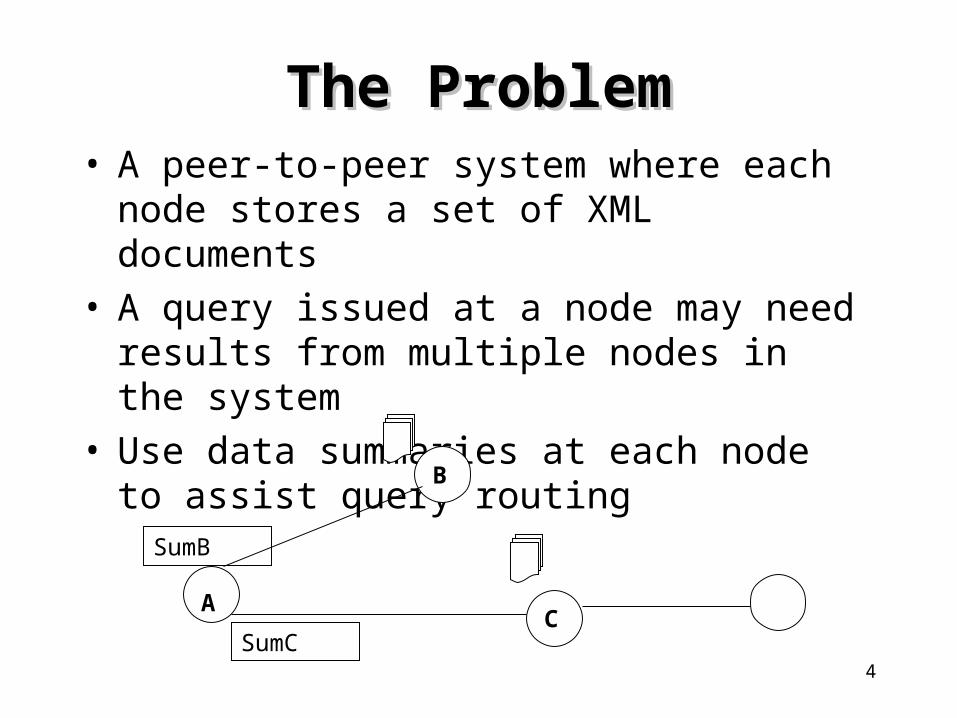
The ProblemThe Problem• A peer-to-peer system where each node stores a
set of XML documents• A query issued at a node may need results from
multiple nodes in the system• Use data summaries at each node to assist query
routing
A
B
C
SumB
SumC

5
Summaries RequirementsSummaries Requirements
• Scalability: summaries should be able to scale to a large number of users and shared documents.
• Distribution: should be distributed across the nodes of the peer-to-peer system without requiring any central point of control.
• Dynamic: should support updates, since in a peer-to-peer system, users join and leave the system at will.

6
Related WorkRelated Work• XML Indices
– The Index Fabric [Cooper & Shadmon, RightOrder Inc 2001]– XSKETCH Synopsis [Polyzotis & Garofalakis, VLDB 2002]– APEX [Chung, Min & Chim, ACM SIGMOD 2002 ]– Path Tree [Aboulnaga, Alameldeen & Naughton, VLDB 2001]– Signature-based Indices [Park & Kim, DASFAA 2001]
• Routing in P2P– Secure Service Discovery [Hodes et al, Mobicom ’99]– Routing indices [Crespo & Garcia-Molina, ICDCS 2002]

7
Data ModelData Model
<xml> <device> <printer> <color></color> <postscript></postscript> </printer> <camera> <digital></digital> </camera> </device>
camera printer
device
color postscript digital
</xml>

8
QueryingQuerying
• XML-based data or service descriptions• Find the documents that satisfy a given query• Queries that exploit content and structure of the
data
• Membership Queries: “Is element X in set Y?”• Path Queries: consisting of regular path
expressions, i.e. device/*/camera

9
Bloom FiltersBloom Filters• Compact data structures for a probabilistic
representation of a set
• Appropriate to answer membership queries

10
Bloom Filters (cont’d)Bloom Filters (cont’d)
1
1
1
1
Element a
H1(a) = P1
H2(a) = P2
H3(a) = P3
H4(a) = P4
m bits
Bit vector v
Query for b: check the bits at positions H1(b), H2(b), ..., H4(b).

11
Bloom Filters (cont’d)Bloom Filters (cont’d)• Appearance of false positives.
False positive: the probabilty that the filter recognizes an elemnt as belonging to the set although it does not.
P = (1 - e-kn/m)k
• Ease of updates with the use of an array of counters• Unable to represent relationships between elements

12
Our approach:Our approach:
• Bloom filters suitable for distributed environments• Main drawback: Unable to represent hierarchies
• Extend to multi-level Bloom Filters in order to support path queries
• Two approaches:– Breadth Bloom Filters
– Depth Bloom Filters

13
Breadth Bloom FiltersBreadth Bloom Filters• One Bloom Filter BBFi for each level of the tree i• In each filter BBFi we insert the elements of all the nodes of
level i.• An additional BBF0 with all the elements to improve
performance• Different sizes of the filter for each filter
Look-up:– check BBF0 for all elements of the path– check each element ai of the path to the corresponding level

14
Breadth Bloom FiltersBreadth Bloom Filters
1 11 1 11 11 111 10 0 1 11 1
01 00 0 01 1 0 0 0 0 0
0 1 11 01 00 1 0 0 1
0 0 0 1 0 0 01 0 11 1
BBF0
BBF1
BBF3
BBF2
(deviceprintercamera colorpostscriptdigital)
device
printer camera
(colorpostscriptdigital)
Queries: $device/printer/color
/printer/postscript
camera printer
device
color postscript digital

15
Depth Bloom FiltersDepth Bloom Filters• One Bloom Filter DBFi for each path of the tree
with length i, i.e. each path with i+1 nodes
• In each DBFi we insert all paths of the tree with length i.
Look-up for path of length p:– Check all elements of the query in DBF– Check for every sub-path of length 2 to p– For * split the path at the positition of * and
check each sub-path seperately

16
Depth Bloom FiltersDepth Bloom Filters
(deviceprintercamera colorpostscriptdigital)
(device/printerdevice/cameracamera/digitalprinter/colorprinter/postscript)
(device/camera/digitaldevice/printer/colordevice/printer/postscript)
Queries: /device/printer/color
/device/*/postscript
1 0 1 1 0 0 1 0 1 1 0 0
DBF0 Paths of length 0
0 1 1 1 0 0 1 0 0 1 0 1
1 0 0 1 1 0 0 1 0 1 1 0
DBF1
DBF2
Paths of length 1
Paths of length 2
camera printer
device
color postscript digital

17
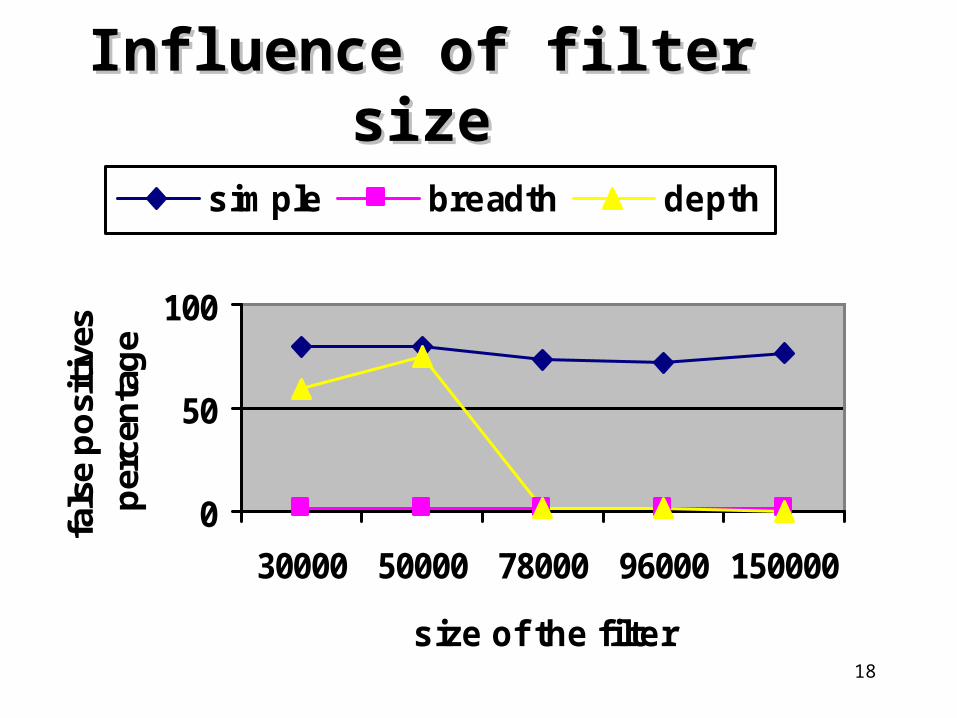
Experimental EvaluationExperimental Evaluation• 200 XML documents produced by the Niagara Generator (
www.cs.wisc.edu/niagara)• 4 hash functions using the MD5 message digest algorithm
(RFC1321)• Size of the filter: 78000 bits, about 2% of the size of the documents• Levels of the documents: 4• Elements per document: 50• No repetition between element names• Length of queries: 3 (e.g. /device/camera/digital)• 90% of the elements forming the queries were contained in the
documents• Metric: Percentage of false positives
18
0
50
100
30000 50000 78000 96000 150000
size of the filter
fals
e p
osi
tive
s p
erce
nta
ge
simple breadth depth
Influence of filter sizeInfluence of filter size

19
Influence of the number of Influence of the number of elements per documentelements per document
0
50
100
10 25 50 100 150
elements per document
fals
e p
osi
tive
s p
erce
nta
ge
simple breadth depth
20
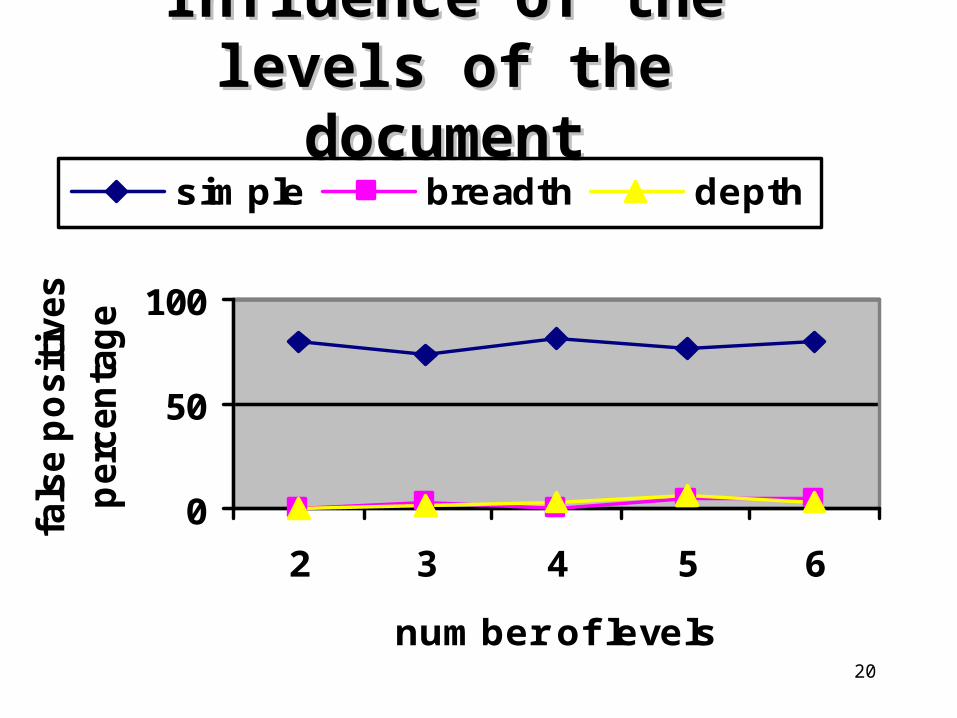
Influence of the Influence of the levels of the levels of the documentdocument
0
50
100
2 3 4 5 6
number of levels
fals
e p
osit
ives
perc
en
tag
e
simple breadth depth
21
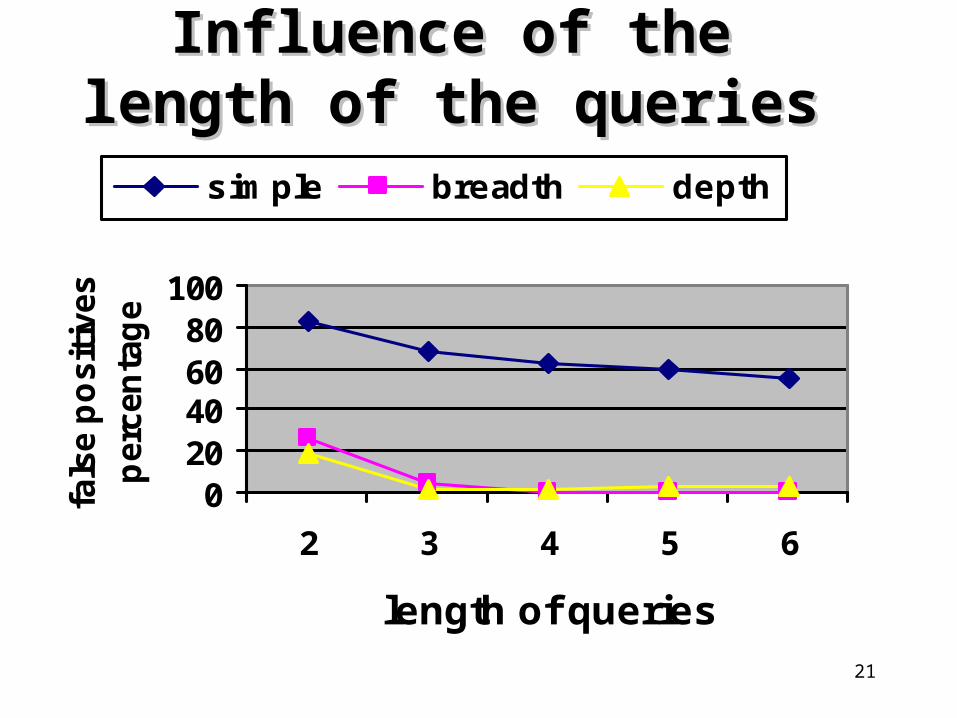
Influence of the length of the Influence of the length of the queriesqueries
020406080
100
2 3 4 5 6
length of queries
fals
e p
osit
ives
perc
en
tag
e
simple breadth depth

22
Varying the query workloadVarying the query workload
0
20
40
60
80
100
120
0% 10% 20% 50% 75% 100%
percentage of queries
fals
e p
osi
tive
s p
erce
nta
ge
simple breadth depth
Workload type: /printer/digital

23
Summary of ResultsSummary of Results• Multi-level Bloom filters outperform Simple Bloom filters
in evaluating path queries.
• For 2% of the total size of the data, multi-level Bloom filters evaluate path queries for a false positives ratio below 3%, while Simple Blooms fail to recognize the correct paths, no matter how much the filter size increases.
• Breadth Blooms work better than Depth Blooms.
• Depth Blooms require more space but are suitable for handling queries for which Breadth Blooms present a high ratio of false positives (exp. 5)

24
DistributionDistribution• Each node stores:
– local summary– merged summary of neighbours– merged summary constructed by applying the bit-wise
OR per level
• Nodes organized according to topological proximity
• Two organizations of nodes:– hierarchical – horizons

25
Distribution: Hierarchical Distribution: Hierarchical OrganizationOrganization
BA
E
C
F
G H
Droot peer
peer
main channel
Node C:
Local filter
Merged filter :E F G H
Root filters: A, B, D

26
Bloom Filter SimilarityBloom Filter Similarity
• Nodes organized according to Bloom Filter Similarity
• Measure: similarity measure based on the Manhattan distance metric.
Let two filters B and C of size m
d(B, C) = |B[1] – C[1]| + |B[2] – C[2]| + … |B[m] – C[m]|.
similarity(B, C) = m – d(B, C).

27
Bloom Filter Similarity Bloom Filter Similarity (cont’d)(cont’d)
1 0 1 10 00 1
1 1 0 0 1 0 0 1C
B
similarity(B, C) =8 - (1 + 0 + 0 + 1 + 0 + 1+ 0 + 1) = 4
For multi-level Bloom filters similarity is defined as the sum of each pair of corresponding levels

28
Content-Based OrganizationContent-Based Organization
• When a node joins the system:– it broadcasts its local summary and attaches to the most
«similar» node available

29
Performance in Distributed Performance in Distributed SettingSetting
• Hierarchical organization of nodes• Metric: Number of hops• Parameters:
– Variable number of nodes– Number of hierarchies: 5– Maximum out-degree: 5– Every 10% of all docs 70% similar– Length of queries: 2– 10% of the documents have results– 70% of the documents contain the elements of the path query– One document per node

30
Finding the first result with Finding the first result with respect to the nodesrespect to the nodes
31
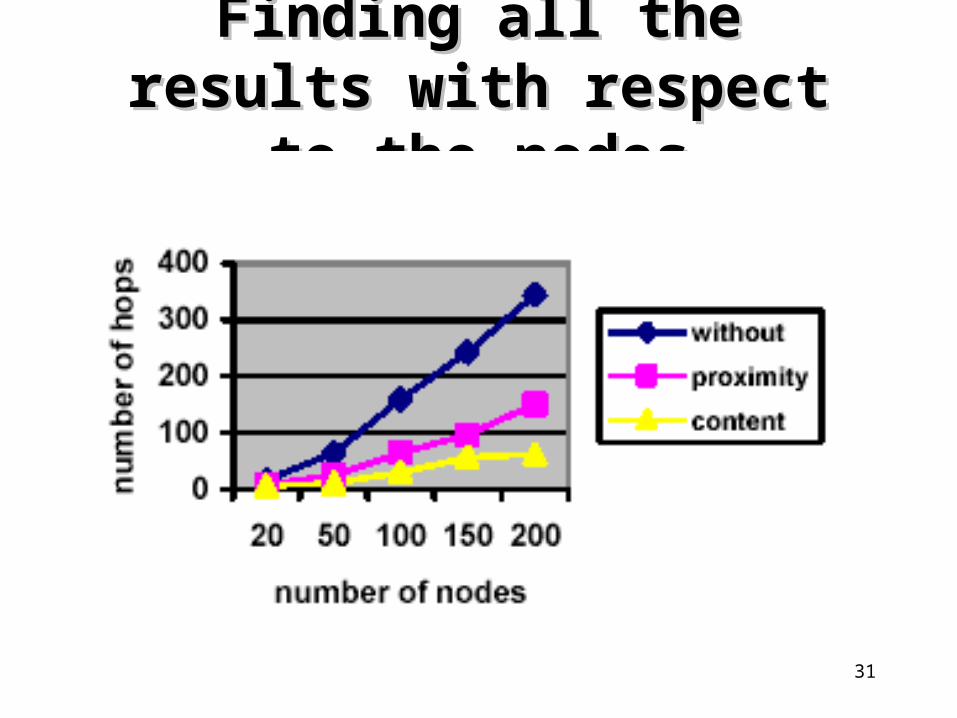
Finding all the results with Finding all the results with respect to the nodesrespect to the nodes
32
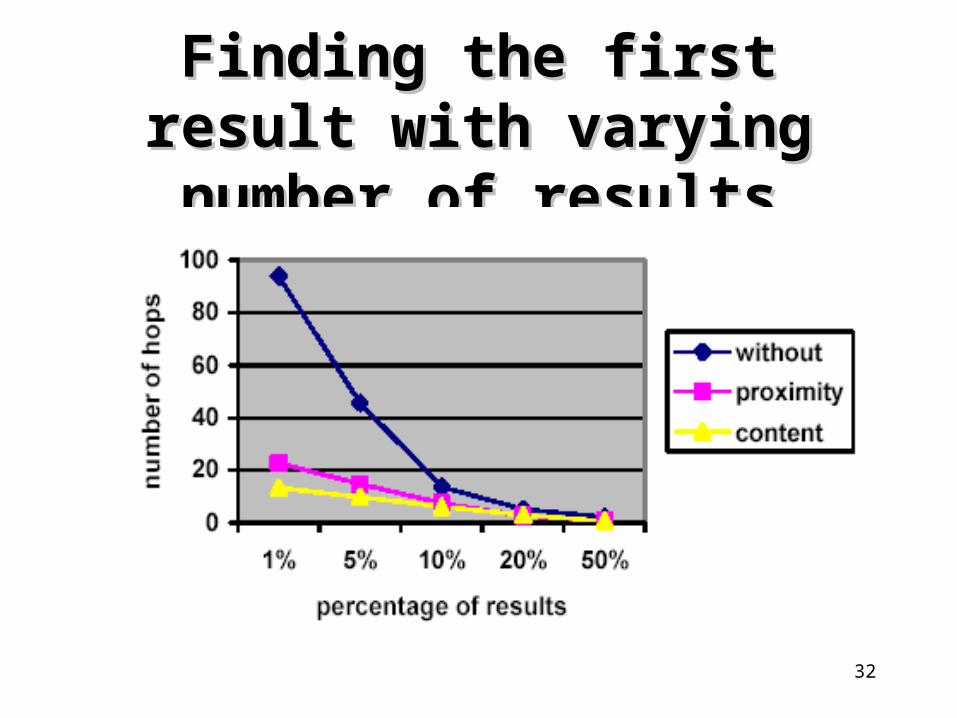
Finding the first result with Finding the first result with varying number of resultsvarying number of results

33
Finding the first result with Finding the first result with respect to the nodesrespect to the nodes
34
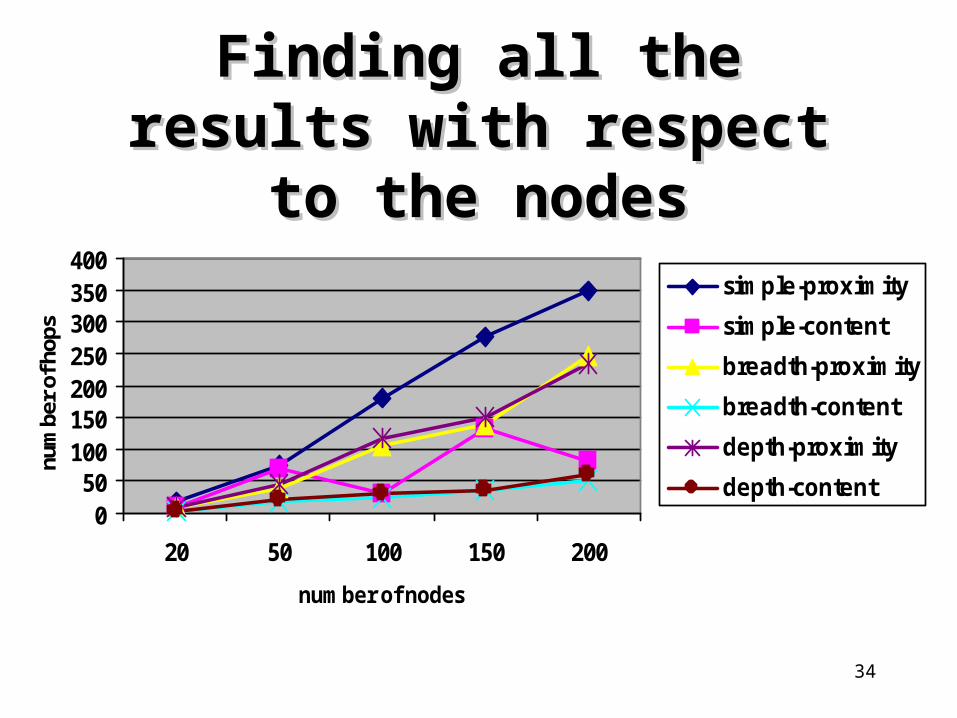
Finding all the results with Finding all the results with respect to the nodesrespect to the nodes
050
100150200250300350400
20 50 100 150 200
number of nodes
num
ber
of h
ops
simple-proximity
simple-content
breadth-proximity
breadth-content
depth-proximity
depth-content

35
Summary of ResultsSummary of Results• The content-based organization is much more efficient in
finding all the results for a query, than the proximity organization.
• They both perform similarly in discovering the first result.
• The content-based organization outperforms the proximity one when the nodes that satisfy a given query are limited.
• Both Simple and multi-level Blooms can be efficiently used as distributed filters.
• For path queries, multi-level Blooms outperform Simple ones.

36
ConclusionsConclusions • We introduced two novel data structures: Breadth and
Depth Bloom Filters that exploit both the content and structure of the XML documents given a small space overhead.
• The new data structures outperform simple Bloom Filters with respect to false positives when addresing regular path expression queries
• Distributed in large-scale systems to support efficient service discovery
• Extended the use of Bloom filters to organize the nodes according to their content.

37
Future WorkFuture Work
• Explore different policies for the filters distribution.
• Explore different types of data summaries (e.g. Signatures)
• Extend the data model to XML graphs and incorporate values into the indexes

38
Thank youThank you


















