

Big Search - telecom-valley.fr
54
BIG SEARCH Aurélien MAZOYER Olivier TAVARD Cédric ULMER SophiaConf – 3 juillet 2012
Transcript of Big Search - telecom-valley.fr

BIG SEARCH
Aurélien MAZOYER
Olivier TAVARD
Cédric ULMER
SophiaConf – 3 juillet 2012

Plan
Big Search
Solr/Constellio
Hadoop
Démonstration par l’exemple
Démonstration Hadoop/Solr

Le Big Search dans cette session
Big Search:
Analyser plusieurs centaines de milliers de docs,
temps de réponse de quelques centaines de ms,
Gestion des fonctionnalités modernes
Pas forcément Big data

WARNING ! MARKETING SLIDE !!!
Domaine: Les moteurs de recherche open source pour entreprise
2 activités:
Consulting/sous-traitance autour de Lucene/Solr/Constellio
R&D (algorithmes de ranking, connecteurs)
A propos de France Labs

SEARCH le mal-aimé
Utilisé dans de nombreux scénarios
De plus en plus commun dans les usages utilisateur
Les entreprises n’ont pas le reflexe Search
Elles en aiment un autre (BI, KM, CMS…)
Le Cyrano des applis d’entreprise

Les problématiques du Search…
Les entreprises ont de multiples défis liés au search
Documentation générée
Historique d’interactions clients
Données marketing
Catalogue produits
Recommandations eCommerce
Logistique ……
… en entreprise

Comment ça marche ?
3 étapes clés:
Le crawling
L’indexation
Le requêtage
Le search for le nul

Le crawling en entreprise
Web
Type de fichiers: pdf, word, html, zip, images,
videos…
Types de systèmes: web avec HTTP GET
Pas de sécurité
Entreprise
Types de fichiers: pdf, word, html, zip, images, videos, tables, autocad,
fichiers exotiques…
Types de systèmes: web, CMS, Sharepoint,
SAP, Oracle, LDAP, fileshare…
Sécurité: LDAP, AD, Kerberos…
Le cauchemar des connecteurs

L’indexation
Lecture des textes
Rejet des stopwords
Stemming/
Lemmatisation
Indexation des token et des
fields
Calcul du ranking statique
La performance en background
Défi big data:
• Nombre
de fichiers
à indexer
• Mise à
jour de
l’index
• Calcul du
ranking

Le requêtage
La performance au runtime
Analyse de la requête
Identification des documents correspondants
Calcul du classement
Génération des extraits et des
facets
Affichage des résultats
Défi big data:
• Nombre de
fichiers
• Calcul du
ranking
• Gestion
des extraits
de texte

Solutions existantes
Lucene/Solr: orienté servlet et entreprise
Elastic Search: orienté scalabilité et distribué
Sphinx: orienté BDD
Constellio: orienté connecteurs et entreprise (sécurité)
OpenSearchServer, Xapian….
L’open source est productif

Notre choix
Problématique des entreprises: avoir un produit performant avec un support fiable.
D’où notre choix de Lucene/Solr et Constellio:
Enorme communauté Lucene/Solr
Offre de support professionnel pour Lucene/Solr et Constellio
Solr 4 pensé pour le distribué
Scotty, support pleine puissance!

Exemples de BIG BIG Search
Linkedin: Calcul des recommandations en Hadoop, réinjection vers Voldemort, recherche par Lucene
Netflix: Lucene pour le search, Hadoop pour la BI des logs. 1 TB / day
Zoosk: Tout en Solr

Les 6 éléments à retenir
Dimensionnement
Evolution de la taille
Support
Sécurité
Disponibilité des connecteurs
Interface utilisateur
(France Labs ;) )
Pour votre projet de Big Search

Plan
Big Search
Solr/Constellio
Hadoop
Démonstration par l’exemple
Démonstration Hadoop/Solr

A quoi ressemble un moteur de recherche aujourdhui?

Qu’y a-t-il dans Constellio?
Un oignon

Qu’y a-t-il dans Constellio?
Créé en 2000 par Doug Cutting. Version Actuelle : Lucene v. 3.6 (Avril 2012)
Projet Open Source, Apache depuis 2001
Librairie de recherche “full-text”
Rapide, stable, performant, modulable
100% Java (pas de dépendances)
Lucene

Lucene
Un outil qui permet:
De créer un index à partir de documents
INDEX
Indexation
Lucene
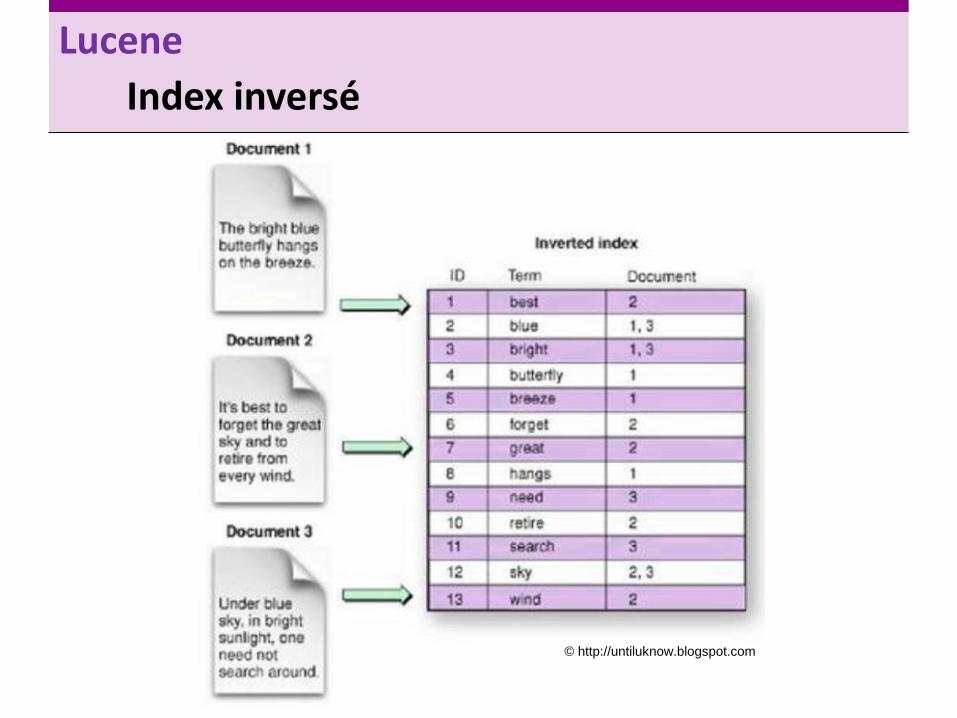
Index inversé
© http://untiluknow.blogspot.com

Lucene
Un outil qui permet:
De créer un index à partir de documents
D’effectuer des recherches dans cet index
INDEX
Recherche

Lucene
Récupérer les bons résultats…
… et seulement ceux là
Precision
Pourcentage de docs pertinents sur les docs retournés
Recall
Pourcentage de docs pertinents retournés sur le total des docs pertinents
Trouver un bon compromis…
Documents Pertinents
Document Retournés
Documents Pertinents
Docs retournés
et pertinents
Recherche pertinente

Lucene
Différence avec une base de données
Plus rapide pour récupérer un doc à partir de son contenu
Résultats scorés
Non relationnelle, structure non fixe
Champs qui peuvent contenir plusieurs valeurs

Lucene
Indexation et Recherche
Query Parser
Analyzer Results Parser
Index Writer
Analyzer Index Searcher

Lucene
Analyzers
Moules SaintJacques
WordDelimiter
Moules Saint Jacques
Analyse du document
moules jacques
LowerCaseFilter
WhitespaceTokenizer
Moules SaintJacques
Moules saint-jacques
WordDelimiter
Moules saint jacques
Analyse de la requête
moules saint jacques
LowerCaseFilter
WhitespaceTokenizer
Moules saint-jacques
saint

Lucene
Formule paramètrable
Combinaison de
Boolean Model
Vector Space Model
• Term Frequency
• Inverse Document Frequency
• …
Scoring

Lucene
Simple bibliothèque
Besoin d’une couche serveur
Pourquoi n’est pas suffisant?

Qu’y a-t-il dans Constellio?
Solr

Solr
Lucene « embarqué » dans une webapp
Créé en 2004 par Yonik Seeley à CENT Networks
In 2006, Solr devient open-source et été cédé à la Apache Software Foundation
En 2010, fusion des projets Lucene et Solr
Version Actuelle : Sorl 3.6 (Avril 2012)

Solr
APIs XML/HTTP de type REST
ajouter des documents (POST)
• http://localhost:8983/solr/update
effectuer des recherches (GET)
• http://localhost:8983/solr/select
Configuration par fichiers XML
Mécanisme de Cache, Réplication
Interface admin web

Pas suffisant?
Solr
Pas de gestion de la
sécurité
Pas de connecteurs
Interface web « limitée »

Qu’y a-t-il dans Constellio?
Constellio

Constellio
Fonctionnalités supplémentaires
Interface Web 2.0
Sécurité
Gestions des ACLs sur les fichiers
Connexion avec un LDAP
Gestion du SSO (Kerberos, SAML)

Constellio
Connectors
Compatible avec les Google Connectors (open source)
Http
File
Database (MySQL, Oracle)
GED (Alfresco, Nuxeo)
XML

Plan
Big Search
Solr/Constellio
Hadoop
Démonstration par l’exemple
Démonstration Hadoop/Solr

Hadoop
Créé par Doug Cutting
Framework open source
Inspiré par les papiers sur Google Map Reduce et Google File System
Vue d’ensemble

Hadoop
Données converties en blocs et distribuées sur des nœuds
Chaque bloc est répliqué
HDFS
JobTracker
NameNode
NameNode secondaire
TaskTracker
DataNode
TaskTracker
DataNode
TaskTracker
DataNode
Nœud maître
Nœ
ud
s e
sc
lave
s
© Inovia Conseil

Hadoop
Map : données sous forme clés/valeurs
Reduce : fusion par clé pour former résultat
Map/Reduce
http://blog.inovia-conseil.fr/?p=46
fichier d’entrée découpage map tri reduce résultat

Hadoop
Ecosystème Hadoop
http://cloudstory.in/2012/04/introduction-to-big-data-hadoop-ecosystem-part-1/

Hadoop
Traiter des grands volumes de données en un minimum de temps
Stocker des immenses volumes de données : plusieurs To ou même Po
Fonctionne sur machines de configuration faible et peu coûteuses
Avantages

Plan
Big Search
Solr/Constellio
Hadoop
Démonstration par l’exemple
Démonstration Hadoop/Solr

Démonstration par l’exemple
Exemples d’entreprises utilisant différentes technologies pour différents scénarios BIIIIG
Hadoop
Hadoop / Solr
MapReduce / Search
Solr
Big Search dans la vraie vie

Démonstration par l’exemple
1 000 000 000 000 d’URLS uniques (2008)
Pagerank : le ranking d’une page est estimé par sa popularité plutôt que par son contenu

Démonstration par l’exemple
Construire PageRank grâce à Map/reduce
Web
Google Map/Reduce (≠ Hadoop
Mapreduce) :
Calcul PageRank
Moteur de recherche (≠ Lucene Solr)

Démonstration par l’exemple

Démonstration par l’exemple 1er cas : Hadoop pur pour les recommandations
Hadoop (pour le calcul)
Voldemort (Linkedin
filesystem)
Web Server (pour l’affichage)
Données brutes
Calcul distribué
des recommandations
Injection des recommandations
par utilisateur
Lecture des données utilisateur et
leur recommandations
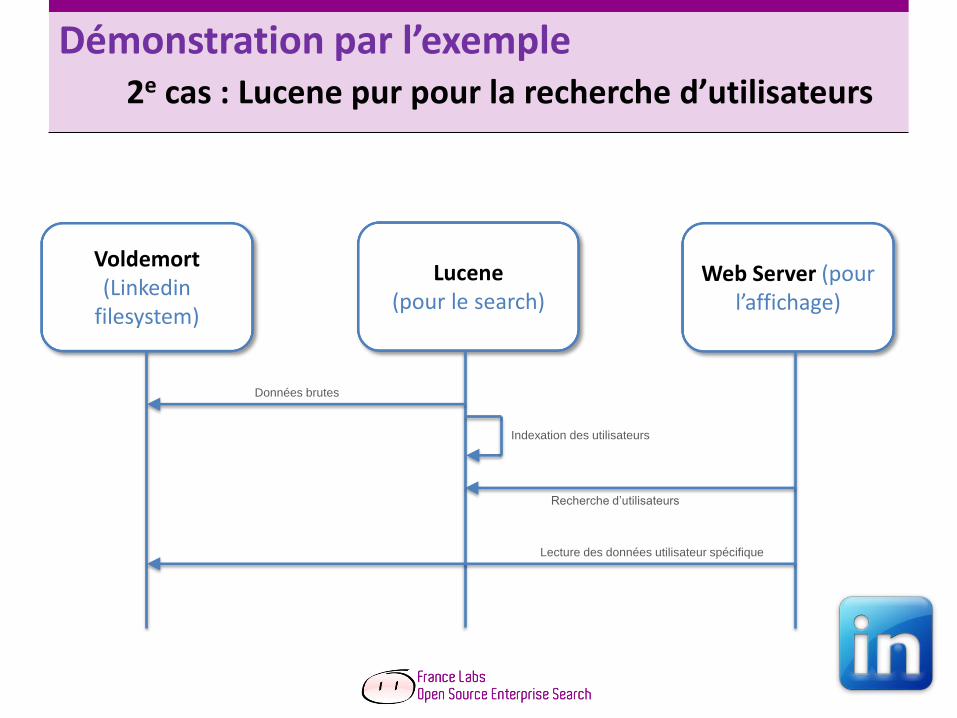
Démonstration par l’exemple 2e cas : Lucene pur pour la recherche d’utilisateurs
Lucene (pour le search)
Voldemort (Linkedin
filesystem)
Web Server (pour l’affichage)
Données brutes
Indexation des utilisateurs
Recherche d’utilisateurs
Lecture des données utilisateur spécifique

Démonstration par l’exemple
Zoosk

Démonstration par l’exemple
Big Search avec Solr
Recherche de profil
Flux d’actualités
Trouver un partenaire
Zoosk

Plan
Big Search
Solr/Constellio
Hadoop
Démonstration par l’exemple
Démonstration Hadoop/Solr

Démonstration Hadoop/Solr
Dans un texte, trouver toutes les phrases qui contiennent un mot cherché et dans quel document il se trouve (basé sur Lucid Imagination)
Objectif

Démonstration Hadoop/Solr
Etapes
‘De la Terre à la Lune’:
‘...on se conduit en héros, et, deux ans, trois ans
plus tard…’
‘Le tour du Monde en 80 jours’:
‘Mais, depuis deux ans, celui-ci n'habitait
plus la Chine…’
‘De la Terre à la Lune’: ‘...on se
conduit en héros, et, deux ans,
trois ans plus tard…’
‘Le tour du Monde en 80
jours’: ‘Mais, depuis
deux ans, celui-ci
n'habitait plus la Chine…’
‘deux ans’: ‘De la Terre à la Lune’
‘deux ans’: ‘De la Terre à la Lune’, ‘Le
tour du Monde en 80
jours‘
‘ans trois’: ‘De la Terre à la Lune’
‘ans celui’: ‘Le tour du Monde en 80 jours’
‘ans trois’ : ‘De la Terre à
la Lune’
‘deux ans’: ‘Le tour du Monde en 80 jours‘
‘ans celui’ : ‘Le tour du
Monde en 80 jours’
‘deux ans’: ‘De la Terre à la Lune’, ‘Le tour du Monde en 80 jours‘
‘ans trois’: ‘De la Terre à la Lune’
‘ans celui’: ‘Le tour du Monde en 80 jours’
Solr Field: Phrase,
indexed, stored
‘deux ans’
‘ans trois’
‘ans celui’
….
Solr Field: Doc, indexed, stored,
multivalued
‘De la Terre à la Lune’, ‘Le tour du Monde en
80 jours‘
‘De la Terre à la Lune’
‘Le tour du
Monde en 80 jours’
….
Fichiers d’entrée Découpage map reduce résultat Index de Solr

Bibliographie
Lucene In Action, Second Edition • Michael McCandless, Erik Hatcher, and Otis Gospodnetić
Apache Solr 3 Enterprise Search Server • David Smiley, Eric Pugh
Apache Lucene • Daniel Naber, Otis Gospodnetic
Constellio • Rida Benjelloun
Lucene/Solr • Grant Ingersoll, Ozgur Yilmazel, Niranjan Balasubramanian,
Glenn Engstrand
Performance Comparison of Lucene and Database • Yinan Jing, Chunwang Zhang, Xueping Wang
Hadoop • Chuck Lam, Kadda Sahnine, Ken Krugler, Grant Ingersoll, Roshan Sumbaly


















