
AUDITORIAS ESPECIFICAS BASES DE DATOS DE …auditoriauc20102miju02.wikispaces.com/file/view/... ·...
34
AUDITORIAS ESPECIFICAS DATOS, BASES DE DATOS, DATAWAREHOUSE, MINERÍA DE DATOS, BASES DE DATOS DE CONTENIDO (ORACLE, SQL, SAS, IBM, MICROSOFT SQL, MYSQL, POSTGRESS) MANUEL ARROYAVE HENAO JHON FREDY GIRALDO PRESENTADO A: CARLOS HERNAN GÓMEZ INGENIERO DE SISTEMAS UNIVERSIDAD DE CALDAS FACULTAD DE INGENIRIAS INGENIERIA DE SISTEMAS Y COMPUTACION MANIZALES, 24 DE NOVIEMBRE DE 2010
Transcript of AUDITORIAS ESPECIFICAS BASES DE DATOS DE …auditoriauc20102miju02.wikispaces.com/file/view/... ·...

AUDITORIAS ESPECIFICAS
DATOS, BASES DE DATOS, DATAWAREHOUSE, MINERÍA DE DATOS, BASES DE DATOS DE CONTENIDO (ORACLE, SQL, SAS, IBM,
MICROSOFT SQL, MYSQL, POSTGRESS)
MANUEL ARROYAVE HENAO
JHON FREDY GIRALDO
PRESENTADO A:
CARLOS HERNAN GÓMEZ INGENIERO DE SISTEMAS
UNIVERSIDAD DE CALDAS FACULTAD DE INGENIRIAS
INGENIERIA DE SISTEMAS Y COMPUTACION MANIZALES, 24 DE NOVIEMBRE DE 2010

Contenido Datos ................................................................................................................................. 4
Base de Datos .................................................................................................................... 4
Ventajas: ............................................................................................................................ 5
A) Independencia de los datos respecto a los tratamientos y viceversa: .................. 5
B) Coherencia de los resultados: ................................................................................ 5
C) Mejor disponibilidad de los datos para el conjunto, de los usuarios: ..................... 5
D) Mayor eficiencia en la recogida, validación entrada de los datos al sistema: ....... 6
E) Reducción del espacio de almacenamiento: ......................................................... 6
Bases de Datos Orientadas a Objetos ............................................................................... 6
Datawarehouse ................................................................................................................. 7
Requerimientos ......................................................................................................... 7
Minería de Datos (Data Mining) ........................................................................................ 8
Bases de Datos de Contenido............................................................................................ 9
Oracle ............................................................................................................................ 9
Versiones ..................................................................................................................... 10
Herramientas ............................................................................................................... 11
Patrón de Consulta ...................................................................................................... 12
Agrupamiento de Datos .............................................................................................. 12
Subconsultas ............................................................................................................... 13
SQL................................................................................................................................... 15
SAS ................................................................................................................................... 19
IBM – DB2 ........................................................................................................................ 21
Características ............................................................................................................. 21
Ventajas ....................................................................................................................... 22
MICROSOFT SQL .............................................................................................................. 23
MySQL ............................................................................................................................. 24
Características de la versión 5.0.22 ............................................................................. 24
POSTGRESQL ................................................................................................................... 25
Características ............................................................................................................. 25
GUIA AUDITORIA A BASES DE DATOS ............................................................................. 26
Guía DB-AUDT01 ......................................................................................................... 27
Matriz de responsabilidades ....................................................................................... 29
GUIA DB-AUDT02 ........................................................................................................ 29

Matriz de evaluación ................................................................................................... 31
Estado de la guía DB-AUDT02 ..................................................................................... 31
GUIA DB-AUDT03 ........................................................................................................ 32
Estado de la guía DB-AUDT02 ..................................................................................... 33
Referencia ....................................................................................................................... 34

Datos
En general, los datos de la base de datos serán tanto integrados como compartidos. Por integrada, se puede entender que la base de datos es como una unificación de varios archivos que de otro modo serian distintos, con una redundancia entre ellos eliminada al menos principalmente. Por compartida, es decir que las piezas individuales de datos en la base pueden ser compartidas entre diferentes usuarios y que cada uno de ellos puede tener acceso a la misma pieza de datos, probablemente con fines diferentes.
Base de Datos
Se puede definir una base de datos, como un fichero que se guarda en campos o delimitadores, por ejemplo, podemos almacenar el nombre y el apellido de las personas de modo separado, de ésta forma es posible obtener del fichero todos los nombres o todos los apellidos, tanto de forma separada como conjunta. Una base de Datos se compone de estos 3 elementos: Hardware: constituido por dispositivo de almacenamiento como discos, tambores, cintas, etc.
Software: que es el DBMS o Sistema administrador de Base de Datos.
Datos: los cuales están almacenados de acuerdo a la estructura externa y van a ser procesados para convertirse en información.
Y pueden tener los siguientes tipos de usuarios:
Usuario Final: es la persona que utiliza los datos, esta persona ve datos convertidos en información:
Desarrollador de Aplicaciones: es la persona que desarrolla los sistemas que interactúan con la Base de Datos.
DBA: es la persona que asegura integridad, consistencia, redundancia, seguridad este es el Administrador de Base de Datos quien se encarga de realizar el mantenimiento diario o periódico de los datos.
Normalmente el número de campos que se tienen en una base varía según las necesidades en cuanto a gestión de datos, de forma que después se pueda explotar la información de forma ordenada y

separada, aunque el resto de la información sigue almacenada y guardada en la base de datos Una base de datos, no es solo el fichero en donde están datos, sino que en dicho archivo se encuentra la estructura de los datos, o sea, para saber que longitud tiene para contener desde letras a números o incluso otros datos más complejos, dependiendo de la estructura de la base y del sistema gestor.
Ventajas:
A) Independencia de los datos respecto a los tratamientos y
viceversa:
La mutua independencia de datos y tratamientos lleva a que un cambio de los programas no implican tener que cambiar el diseño lógico y/o físico de la base de datos. Por otra parte, la inclusión de nuevas informaciones, desaparición de otras, cambios en la estructura física o en los caminos de acceso, etc., no deben obligar a alterar los programas. Esta independencia de los tratamientos frente a la estructura de la base de datos, evita el importante esfuerzo que origina la reprogramación de las aplicaciones cuando se producen cambios en los datos.
- Independencia lógica de los datos: Se refiere a que las
modificaciones de la representación lógica del problema no afecta a los programas que los manipulan, y viceversa.
- Independencia física de los datos: Se refiere a que la distribución
en unidades de almacenamiento es independiente de la estructura lógica general, y viceversa.
B) Coherencia de los resultados:
Debido a que la información de la base de datos se recoge y almacena una sola vez. En todos los programas se utilizan los mismos datos, por lo que los resultados de todos ellos son coherentes y perfectamente comparables.
C) Mejor disponibilidad de los datos para el conjunto, de los
usuarios:
Cuando se aplica la metodología de bases de datos, cada usuario ya

no es propietario de los datos, puesto que éstos se comparten entre el conjunto de aplicaciones, existiendo una mejor disponibilidad de los datos para todos los que tienen necesidad de ellos, siempre que estén autorizados para su acceso.
D) Mayor eficiencia en la recogida, validación entrada de los
datos al sistema:
Al no existir apenas redundancias, los datos se recogen y validan una
sola vez, aumentando así el rendimiento de todo el proceso previo al almacenamiento.
E) Reducción del espacio de almacenamiento:
La desaparición (o disminución) de las redundancias, así como la aplicación de técnicas de compactación, lleva en los sistemas de bases de datos a una menor ocupación de almacenamiento secundario -disco magnético-.
Bases de Datos Orientadas a Objetos Una BD Orientada a Objetos (BDOO) es una base de datos en el sentido de la definición introductoria, donde los elementos de datos son objetos y las relaciones se mantienen por medio inclusión lógica. Las entidades de aplicación están representadas como clases. La auto descripción se obtiene porque las clases son meta objetos que contiene los nombres de atributos y métodos de señal. Una BDOO contiene un método sistemático de representación de relación, y la interfaz uniforme de usuario es un sistema de mensajes que puede explorar los objetos y sus interconexiones. Las Bases de datos orientados a objetos se propusieron con la idea de satisfacer las necesidades de las aplicaciones más complejas. El enfoque orientado a objetos ofrece la flexibilidad para cumplir con algunos de estos requerimientos sin estar limitado por los tipos de datos y los lenguajes de consulta disponibles en los sistemas de bases de datos tradicionales. Como cualquier Bases de Datos programables, una Base de Datos Orientada a Objetos (BDOO) proporciona un ambiente para el desarrollo de aplicaciones y un depósito persistente listo para su explotación. Una BDOO almacena y manipula información que puede ser digitalizada (presentada) como objetos, además proporciona un acceso ágil y permite una gran capacidad de manipulación. Los principales conceptos que se utilizan en las Bases de Datos Orientada a Objetos (BDOO) son las siguientes:
• Identidad de objetos
• Constructores de tipos

• Encapsulamiento
• Compatibilidad con los lenguajes de programación
• Jerarquías de tipos y herencia
• Manejo de objetos complejos
• Polimorfismo y sobrecarga de operadores y
• Creación de versiones.
Datawarehouse
Un Datawarehouse es una base de datos corporativa que se caracteriza por integrar y depurar información de una o más fuentes distintas, para luego procesarla permitiendo su análisis desde infinidad de pespectivas y con grandes velocidades de respuesta. La creación de un datawarehouse representa en la mayoría de las ocasiones el primer paso, desde el punto de vista técnico, para implantar una solución completa y fiable de Business Intelligence.
La ventaja principal de este tipo de bases de datos radica en las estructuras en las que se almacena la información (modelos de tablas en estrella, en copo de nieve, cubos relacionales... etc). Este tipo de persistencia de la información es homogénea y fiable, y permite la consulta y el tratamiento jerarquizado de la misma (siempre en un entorno diferente a los sistemas operacionales).
Requerimientos
Un Data Warehouse es simplemente un sistema de aplicación empresarial con su propia base de datos. Esta base de datos se genera a partir de otras bases de datos operacionales, no de información inicial que se introduce. El Data Warehouse ofrece una serie de características y funciones para implementar procesos empresariales y enlazarlos con otros procesos fuera del ámbito del Data Warehouse. En forma muy similar a otros sistemas de aplicaciones empresariales, se requiere que el Data Warehouse proporcione al usuario final estos conjuntos prescritos de características y funciones del modo más eficiente posible. Un Data Warehouse es una capacidad latente. Almacena información resumida que se organiza de acuerdo con temas empresariales, tales como clientes y productos, para analizar la información con más facilidad. La carga de mostrar, organizar y reportar la información que guarda el Data Warehouse corresponde a las herramientas que deben incorporarse en el Data Warehouse. En esta visión, un Data Warehouse tiene una capacidad latente que sólo se vuelve útil cuando las herramientas de análisis y reporte se aplican con inteligencia a los datos que conserva el Data Warehouse. Se requiere que el Data Warehouse sustente un extenso rango de herramientas de acceso, operadas por una extensa

gama de usuarios finales. El Data Warehouse también debe guardar y administrar un ámbito de informaci6n grande para servir a una extensa clientela. El Data Warehouse es una base de datos históricos, la cual es una acumulación de muchos años de informaci6n transaccional en línea, organizada para hacer eficiente el almacenamiento y facilitar la recuperación. Es necesario que el Data Warehouse organice grandes cantidades de información de manera compacta y eficiente. También se requiere que proporcione técnicas para resumir, a fin de que los usuarios finales comprendan las lecciones de los antecedentes con más facilidad. En ocasiones, el Data Warehouse es una tienda de datos operacionales. Entrega información operacional a un amplio rango de usuarios copiando información de los sistemas operacionales de bases de datos. En este caso, se requiere que el Data Warehouse distribuya información operacional de manera eficiente a un gran rango de usuarios. También se necesita que el Data Warehouse haga los cambios tecnológicos necesarios para mover la información de su base de datos operacional a la tecnología de almacenamiento que se emplea en el Data Warehouse. Es evidente que los requerimientos de un Data Warehouse son tan variados y diversos como las clases de usuario que lo utilizan para obtener beneficios empresariales. Por lo tanto, es necesario clasificar los requerimientos del Data Warehouse utilizando técnicas clásicas.
Minería de Datos (Data Mining)
La minería de datos es una tecnología compuesta por etapas que integra variasáreas y que no se debe confundir con un gran software. Durante el desarrollode un proyecto de este tipo se usan diferentes aplicaciones software en cada etapa que pueden ser estadísticas, de visualización de datos o de inteligencia artificial, principalmente. Actualmente existen aplicaciones o herramientas comerciales de data mining muy poderosas que contienen un sinfín de utilerías que facilitan el desarrollo de un proyecto. Sin embargo, casi siempre acaban complementándose con otra herramienta. Básicamente, el datamining surge para intentar ayudar a comprender el contenido de un repositorio de datos. Con este fin, hace uso de prácticas estadísticas y, en algunos casos, de algoritmos de búsqueda próximos a la Inteligencia Artificial y a las redes neuronales. De forma general, los datos son la materia prima bruta. En el momento que el usuario les atribuye algún significado especial pasan a convertirse en información. Cuando los especialistas elaboran o encuentran un modelo, haciendo que la interpretación que surge entre la información y

ese modelo represente un valor agregado, entonces nos referimos al conocimiento. Las técnicas de Data Mining son el resultado de un largo proceso de investigación y desarrollo de productos. Esta evolución comenzó cuando los datos de negocios fueron almacenados por primera vez en computadoras, y continuó con mejoras en el acceso a los datos, y más recientemente con tecnologías generadas para permitir a los usuarios navegar a través de los datos en tiempo real. Data Mining toma este proceso de evolución más allá del acceso y navegación retrospectiva de los datos, hacia la entrega de información prospectiva y proactiva. Data Mining está listo para su aplicación en la comunidad de negocios porque está soportado por tres tecnologías que ya están suficientemente maduras: • Recolección masiva de datos. • Potentes computadoras con multiprocesadores. • Algoritmos de Data Mining.
Bases de Datos de Contenido
Oracle
Oracle es una potente herramienta cliente/servidor para la gestión de Bases de Datos. Explicamos la herramienta y las ayudas que ofrece al desarrollador
Oracle es básicamente una herramienta cliente/servidor para la gestión de Bases de Datos. Es un producto vendido a nivel mundial, aunque la gran potencia que tiene y su elevado precio hace que sólo se vea en empresas muy grandes y multinacionales, por norma general. En el desarrollo de páginas web pasa lo mismo: como es un sistema muy caro no está tan extendido como otras bases de datos, por ejemplo, Access, MySQL, SQL Server, etc. Aunque su dominio en el mercado de servidores empresariales ha sido casi total hasta hace poco, recientemente sufre la competencia del Microsoft SQL Server de Microsoft y de la oferta de otros RDBMS con licencia libre como PostgreSQL, MySql o Firebird. Las últimas versiones de Oracle han sido certificadas para poder trabajar bajo GNU/Linux. Para desarrollar en Oracle utilizamos PL/SQL un lenguaje de 5ª generación, bastante potente para tratar y gestionar la base de datos, también por norma general se suele utilizar SQL al crear un formulario. Es posible lógicamente atacar a la base de datos a través del SQL plus

incorporado en el paquete de programas Oracle para poder realizar consultas, utilizando el lenguaje SQL. El Developer es una herramienta que nos permite crear formularios en local, es decir, mediante esta herramienta nosotros podemos crear formularios, compilarlos y ejecutarlos, pero si queremos que los otros trabajen sobre este formulario deberemos copiarlo regularmente en una carpeta compartida para todos, de modo que, cuando quieran realizar un cambio, deberán copiarlo de dicha carpeta y luego volverlo a subir a la carpeta. Este sistema como podemos observar es bastante engorroso y poco fiable pues es bastante normal que las versiones se pierdan y se machaquen con frecuencia. Los problemas anteriores quedan totalmente resueltos con Designer que es una herramienta que se conecta a la base de datos y por tanto creamos los formularios en ella, de esta manera todo el mundo se conecta mediante Designer a la aplicación que contiene todos los formularios y no hay problemas de diferentes versiones, esto es muy útil y perfecto para evitar machacar el trabajo de otros.
Versiones
Oracle 5 y Oracle 6: fueron las dos primeras versiones de Oracle, quedando aun rezagadas por las versiones sucesoras. Oracle 7: La base de datos relacional componentes de Oracle Universal Server. Posee además las versiones 7.1, 7.1.2, y 7.1.3. Oracle 7 Parallel: Ofrece a los usuarios un método seguro y administrable para incrementar la performance de sus bases de datos existentes introduciendo operaciones en paralelo y sincrónicas dentro de sus ambientes informáticos. Oracle 8: Incluye mejoras de rendimiento y de utilización de recursos. Independiente de que se necesite dar soporte a decenas de miles de usuarios y cientos de terabytes de datos, o se disponga de un sistema mucho más pequeño, pero igualmente critico, todos se benefician del rendimiento de Oracle8. Este soporta aplicaciones de procesamiento de transacciones online (OLTP) y de data warehousing mayores y más exigentes. Oracle Fail Safe: Protege al sistema de caída de entornos Clúster Windows NT. Este producto es para que el sistema operativo Windows NT disponga de una mayor oferta de soluciones en entornos clúster. Oracle Universal Server: Con soporte completo de Web, mensajería y datos multimedia, Oracle Universal Server es el eslabón fundamental en el camino de transición de la industria de la tecnología a la informática de red, donde la complejidad de software es transferida desde la PC de

escritorio a poderosos servidores y redes. El uso de memoria en el RDBMS Oracle (Sistema Manejador de Base de Dato Relacional) tiene como propósito lo siguiente:
- Almacenar los códigos de los programas para empezar a ejecutarse.
- Almacenar los datos necesarios durante la ejecución de un
programa.
- Almacenar información sobre como es la transferencia entre procesos y periféricos.
Un RDBMS Oracle está compuesto por tres partes principales, que son:
- El Kernel de Oracle
- Las instancias del Sistema de Base de Datos.
- Los Archivos relacionados al sistema de Base de Datos. El Kernel de Oracle El Kernel es el corazón del RDBMS Oracle, el cual maneja las siguientes tareas:
- Manejar el almacenamiento y definición de los datos.
- Suministrar y limitar el acceso a los datos y la concurrencia de los usuarios.
- Permitir los backup y la recuperación de los datos.
- Interpretar el SQL y PL/SQL.
Así como el Kernel es un sistema operativo, el Kernel Oracle es cargado a la memoria al inicio de las operaciones y es usado por cada base de datos existente en el equipo.
Herramientas
SQLForms: es la herramienta de Oracle que permite, de un modo sencillo y eficiente, diseñar pantallas para el ingreso, modificaciones, bajas y consultas de registros. El usuario podrá, una vez definida la forma, trabajar con ella sin necesidad de generar códigos, dado que Oracle trae incorporado un conjunto de procedimientos y funciones asociados a las teclas de funciones, como por ejemplo la tecla [F7], que se usa para iniciar una consulta.

La herramienta fundamental de SQL es la sentencia SELECT, que permite seleccionar registros desde las tablas de la Base de Datos, devolviendo aquellos que cumplan las condiciones establecidas y pudiendo presentar el resultado en el orden deseado. SQL (Structured Query Languague = Lenguaje de Consulta estructurado). La orden FROM identifica la lista de tablas a consultar. Si alguna de las tablas a consultar no es propiedad del usuario, debe especificarse el nombre del propietario antes que el nombre de la tabla en la forma nombre_propietario.nombre_tabla. La orden WHERE decide los registros a seleccionar según las condiciones establecidas, limitando el número de registros que se muestran. La orden ORDER BY indica el orden en que aparece el resultado de la consulta.
Patrón de Consulta
Una de las herramientas lógicas más poderosas de SQL es el reconocimiento de un patrón de consulta, instrumento éste que permite la búsqueda por nombre, dirección u otro dato parcialmente recordado. Los patrones de consulta juegan un papel importante en el momento de realizar consultas, ya que es común que necesitemos encontrar un texto y no recordemos exactamente cómo fue ingresado. Con el uso del operador LIKE podemos comparar patrones y ubicar un texto, independientemente de la posición en que se encuentre. Para la definición del patrón de consulta existen dos tipos de caracteres especiales: % (signo de porcentaje) llamado comodín, representa cualquier cantidad de espacios o caracteres en esa posición. Significa que se admite cualquier cosa en su lugar: un carácter, cien caracteres o ningún carácter. _ (signo de subrayado) llamado marcador de posición, representa exactamente una posición e indica que puede existir cualquier carácter en esa posición.
Agrupamiento de Datos

SQL proporciona una forma eficiente para manejar la información con el agrupamiento de datos a través de la formación de grupos y las funciones correspondientes, dando la posibilidad de procesar no solo registros individuales como hemos hecho hasta ahora. También podemos agrupar registros por un criterio determinado, como por ejemplo, agrupar por clientes las ventas realizadas. Cada grupo tendrá como resultado de la consulta una fila resumen que contiene la información del grupo. Para la formación de grupos adicionamos, a la forma básica de la sentencia SELECT, la orden GROUP BY ubicada antes de ORDER BY. Las funciones para el procesamiento de grupos son:
- COUNT(columna) Cantidad de registros en que la columna tiene valores no nulos.
- COUNT(*) Cantidad de registros que hay en la tabla, incluyendo
los valores nulos.
- MIN(columna) Valor mínimo del grupo.
- MAX(columna) Valor máximo del grupo.
- SUM(columna) Suma los valores del grupo.
- AVG(columna) Calcula valor medio del grupo, sin considerar los valores nulos.
La lista de columnas a mostrar en la consulta puede contener las funciones de grupo, así como la columna o expresión usada para formar los grupos en la orden GROUP BY. En una misma consulta no se pueden mezclar funciones de grupo con columnas o funciones que trabajan con registros individuales. El orden en las consultas por grupos, cuando no está presente la orden ORDER BY, está dado por la columna que forma los grupos. Si deseamos cambiar ese orden, como es el caso de ordenar por el valor total de ventas, se debe adicionar al final la orden ORDER BY SUM(VALOR).
Subconsultas
Otro aspecto de fácil diseño y uso que muestra una vez más las posibilidades de SQL son las subconsultas. Subconsulta es aquella consulta de cuyo resultado depende otra consulta, llamada principal, y se define como una sentencia SELECT que

está incluida en la orden WHERE de la consulta principal. Una subconsulta, a su vez, puede contener otra subconsulta y así hasta un máximo de 16 niveles. Índices El índice es un instrumento que aumenta la velocidad de respuesta de la consulta, mejorando su rendimiento y optimizando su resultado. El manejo de los índices en ORACLE se realiza de forma inteligente, donde el programador sólo crea los índices sin tener que especificar, explícitamente, cuál es el índice que va a usar. Es el propio sistema, al analizar la condición de la consulta, quien decide qué índice se necesita. Por ejemplo cuando en una consulta se relacionan dos tablas por una columna, si ésta tiene definido un índice se activa, como en el caso cuando relacionamos la tabla de clientes y ventas por la columna código para identificar al cliente (WHERE clientes.codigo=ventas.codigo) La identificación del índice a usar está relacionada con las columnas que participan en las condiciones de la orden WHERE. Si la columna que forma el índice está presente en alguna de las condiciones éste se activa. PL/SQL: es un lenguaje portable, procedural y de transacción muy potente y de fácil manejo, con las siguientes características fundamentales:
1. Incluye todos los comandos de SQL.
2. Es una extensión de SQL, ya que este es un lenguaje no completo dado que no incluye las herramientas clásicas de programación. Por eso, PL/SQL amplia sus posibilidades al incorporar las siguientes sentencias:
- Control condicional
- Ciclos
3. Incorpora opciones avanzadas en:
- Control y tratamiento de errores llamado excepciones
- Manejo de cursores.

SQL
El lenguaje de consulta estructurado (SQL) es un lenguaje de base de datos normalizado, utilizado por los diferentes motores de bases de datos para realizar determinadas operaciones sobre los datos o sobre la estructura de los mismos. Pero como sucede con cualquier sistema de normalización hay excepciones para casi todo; de hecho, cada motor de bases de datos tiene sus peculiaridades y lo hace diferente de otro motor, por lo tanto, el lenguaje SQL normalizado (ANSI) no nos servirá para resolver todos los problemas, aunque si se puede asegurar que cualquier sentencia escrita en ANSI será interpretable por cualquier motor de datos.
El lenguaje SQL está compuesto por comandos, cláusulas, operadores y funciones de agregado. Estos elementos se combinan en las instrucciones para crear, actualizar y manipular las bases de datos.
Existen dos tipos de comandos SQL:
- DLL que permiten crear y definir nuevas bases de datos, campos e
índices.
- DML que permiten generar consultas para ordenar, filtrar y extraer datos de la base de datos.
Comandos DLL
Comando Descripción
CREATE Utilizado para crear nuevas tablas, campos e índices
DROP Empleado para eliminar tablas e índices
ALTER
Utilizado para modificar las tablas agregando campos o cambiando la
definición de los campos.
Comandos DML
Comando Descripción
SELECT
Utilizado para consultar registros de la base de datos que satisfagan un
criterio determinado

INSERT UPDATE DELETE
Utilizado para cargar lotes de datos en la base de datos en una única operación. Utilizado para modificar los valores de los campos y registros especificados Utilizado para eliminar registros de una tabla de una base de datos

Las cláusulas son condiciones de modificación utilizadas para definir los datos que desea seleccionar o manipular.
Cláusula Descripción
FROM
Utilizada para especificar la tabla de la cual se van a seleccionar los
registros
WHERE
Utilizada para especificar las condiciones que deben reunir los
registros que se van a seleccionar
GROUP BY
Utilizada para separar los registros seleccionados en grupos
específicos
HAVING Utilizada para expresar la condición que deb e satisfacer cada grupo
ORDER BY
Utilizada para ordenar los registros seleccionados de acuerdo con un
orden específico
El SQL es un lenguaje de acceso a bases de datos que explota la flexibilidad y potencia de los sistemas relacionales permitiendo gran variedad de operaciones en éstos últimos.
Es un lenguaje declarativo de "alto nivel" o "de no procedimiento", que gracias a su fuerte base teórica y su orientación al manejo de conjuntos de registros, y no a registros individuales, permite una alta productividad en codificación y la orientación a objetos. De esta forma una sola sentencia puede equivaler a uno o más programas que se utilizarían en un lenguaje de bajo nivel orientado a registros.
Optimización
Suele ser común en los lenguajes de acceso a bases de datos de alto nivel, el SQL es un lenguaje declarativo. O sea, que especifica qué es lo que se quiere y no cómo conseguirlo, por lo que una sentencia no establece explícitamente un orden de ejecución.
El orden de ejecución interno de una sentencia puede afectar gravemente a la eficiencia del SGBD, por lo que se hace necesario que éste lleve a cabo una optimización antes de su ejecución. Muchas veces, el uso de índices acelera una instrucción de consulta, pero ralentiza la actualización de los datos. Dependiendo del uso de la aplicación, se priorizará el acceso indexado o una

rápida actualización de la información. La optimización difiere sensiblemente en cada motor de base de datos y depende de muchos factores.

SAS
SAS es un sistema integrado de productos software proporcionados por SAS Institute Inc. - que permite a los programadores realizar:
- Entrada de datos , recuperación , gestión , y minería
- Informe escrito y gráfico
- Análisis estadístico
- Planificación empresarial , previsión y apoyo a las decisiones
- Investigación de operaciones y gestión de proyectos
- Mejora de la calidad
- Aplicaciones de desarrollo
- Almacenamiento de datos ( extracción, transformación, carga )
- Independiente de la plataforma y la informática a distancia Además, SAS negocia muchas soluciones que permiten a escala dar soluciones de software para áreas como la administración de TI, gestión de recursos humanos, gestión financiera, inteligencia empresarial, gestión de relaciones con clientes y mucho más. SAS es impulsada por los programas que definen una secuencia de operaciones que se efectúan en los datos almacenados en tablas. Los componentes de SAS exponen sus funcionalidades a través de interfaces de programación de aplicaciones, en forma de declaraciones y procedimientos. Un programa SAS se compone de tres partes principales:
1. DATA
2. Pasos de procedimiento (en realidad, todo lo que no está encerrado en un paso DATA)
3. Un lenguaje de macros
SAS Motores Biblioteca y Servicios de Bibliotecas a distancia permite el acceso a los datos almacenados en las estructuras de datos externas y en las plataformas de ordenador remoto. La sección de paso DATA de un programa SAS, al igual que otros de cuarta generación de lenguajes orientada a la programación de bases de datos como

SQL, asume por defecto una estructura de archivos, y automatiza el proceso de identificar los archivos en el sistema operativo, abriendo el archivo de entrada, la lectura del registro siguiente, abriendo el archivo de salida, escribiendo el siguiente registro, y cerrando los archivos. Esto permite al usuario/programador concentrarse en los detalles de trabajar con los datos de cada registro. Todas las otras tareas se llevan a cabo mediante procedimientos que operan en el conjunto de datos. Tareas típicas incluyen la impresión o la realización de análisis estadístico, y sólo podrá exigir al usuario/programador identificar el conjunto de datos. Los procedimientos no están restringidos a una sola conducta y por lo tanto permiten una amplia personalización, controlada por el mini-lenguajes definidos dentro de los procedimientos. SAS también tiene un amplio procedimiento SQL, permitiendo a los programadores de SQL utilizar el sistema con el conocimiento adicional mínimo. En comparación con los lenguajes de programación de propósito general, esta estructura permite que el usuario/programador pueda concentrarse menos en los detalles técnicos de los datos y cómo se almacenan, y más en la información contenida en los datos. Esto desdibuja la línea entre el usuario y el programador, apelando a las personas que entran más en el área de "negocio" o "investigación" y menos en la zona de "tecnología de la información”, de tal forma que centraliza un enfoque estructurado a los datos y la gestión de infraestructuras. SAS se ejecuta en mainframes de IBM, máquinas Unix, OpenVMS Alfa, y Microsoft Windows, y el código que circula entre estos entornos es casi transparente. Las versiones anteriores se han apoyado en PC-DOS, Macintosh de Apple, SLB, VM / CMS, datos generales del AM y OS/2.

IBM – DB2
Muchos expertos de la industria y usuarios han elogiado las nuevas herramientas que IBM desarrollo para facilitar la administración y uso de DB2 Universal Database, constituido en base a dos productos incluidos en el DB2 de AIX en 1994: el DB2 Common Server, que para propósitos generales incluía funciones avanzadas para el mercado de servidores de bases de datos con soporte de hardware SMP y OLTP; y el DB2 Parallel Edition, que fue desarrollado para soportar aplicaciones de gran escala, como el Data Warehousing y Data Minino y aplicaciones de negocios a nivel mundial como la SAP, People Soft y Baan. DB2 incluye todo lo necesario para implementar una solución de replicación de datos en cualquier tipo de ambiente distribuido o heterogéneo, pues permite enviar los datos a cualquier sitio para cubrir todos los requerimientos de una empresa, desde oficinas centrales a sucursales, usuarios móviles, proveedores, clientes y socios de negocios. Gracias a su alcance global y de bajo costo, Internet puede ser una solución de negocios muy poderosa para realizar operaciones comerciales garantizando un nivel de seguridad y confiabilidad con sus servicios de autorización y autenticación integrados a redes y sistema operativos, soportando el network−computing utilizando Java y JDBC, incluyendo capacidad nueva de almacenar varios tipos de datos: alfanuméricos, video, imagen, audio y los definidos por el usuario. DB2 y SQL Server tenían grandes compañías detrás con otros negocios que les permitió aguantar la política agresiva de Oracle. Recientemente IBM adquirió Informix con lo que el mercado de las bases de datos comerciales en UNIX (Linux) quedó entre IBM y Oracle.
Características
Permite el manejo de objetos grandes (hasta 2 GB), la definición de datos y funciones por parte del usuario, el chequeo de integridad referencial, SQL recursivo, soporte multimedia: texto, imágenes, video, audio; queries paralelos, commit de dos fases, backup/recuperación on−line y offline. Además cuenta con un monitor gráfico de performance el cual posibilita observar el tiempo de ejecución de una sentencia SQL y corregir detalles para aumentar el rendimiento. Esta capacidad se utiliza en sistemas de búsqueda de personas por huellas digitales, en sistemas información geográfica, etc. Internet es siempre la gran estrella, con DB2 es posible acceder a los datos usando JDBC (tan potente como escribir directamente C contra la base de

datos), Java y SQL (tanto el SQL estático, como complementa el SQL dinámico).
- Plataformas host:
OS/390(MVS), VM & VSE, OS/400
- Plataformas de servidor:
OS/2 Warp Server, Sinix, SCO Open server, Windows NT, Aix, HP Ux, Solaris.
- Plataformas Cliente:
OS/2, DOS, Sinix, SCO Open Server, Windows 3.1/95/NT, Macintosh System 7, Aix, HP Ux, Solaris.
Ventajas
� Permite agilizar el tiempo de respuestas de esta consulta
� Recuperación utilizando accesos de sólo índices. � Predicados correlacionados. � Tablas de resumen
� Tablas replicadas � Uniones hash
� DB2 utiliza una combinación de seguridad externa y control interno de
acceso a proteger datos. � DB2 proporciona un juego de datos de acceso de las interfaces para los
diferentes tipos de usuarios y aplicaciones. � DB2 guarda sus datos contra la pérdida, acceso desautorizado, o
entradas inválidas. � Usted puede realizar la administración de la DB2 desde cualquier puesto
de trabajo. � La tecnología de replicación heterogénea en SQL Server permite la
publicación automática de los datos en otros sistemas que no sean SQL Server, entre los que se incluyen DB2.
� La mayoría de los que utilizan equipos IBM utilizan DB2 porque es
confiable y tiene un muy buen soporte técnico". � El DB2 se basa en dos ejes que lo hacen fuerte en su rendimiento: utiliza
un sistema multiprocesador (SMP) simétrico y un sistema de procesador

paralelo masivo. � El DB2 distribuye y recuerda la ubicación de cada pista donde se encuentra
la información. En el contexto de una larga base de datos, este sistema de partición hace que la administración sea mucho más fácil de manejar que una base de datos de la misma medida no particionada.
� La base de datos se puede programar para tener una exacta cantidad de
particiones que contienen la información del usuario, índice, clave de transacción y archivos de configuración. De esta forma, los administradores definen grupos de nodos, que son una serie de particiones de la base, lo que posteriormente facilita cualquier búsqueda.
MICROSOFT SQL
Microsoft SQL es un sistema para la gestión de bases de datos producido por Microsoft basado en el modelo relacional. Sus lenguajes para consultas son T-SQL y ANSI SQL. Características � Soporte de transacciones. � Escalabilidad, estabilidad y seguridad. � Soporta procedimientos almacenados.
� Incluye también un potente entorno gráfico de administración, que
permite el uso de comandos DDL y DML gráficamente. � Permite trabajar en modo cliente-servidor, donde la información y datos
se alojan en el servidor y las terminales o clientes de la red sólo acceden a la información.
� Además permite administrar información de otros servidores de datos.
Este sistema incluye una versión reducida, llamada MSDE con el mismo motor de base de datos pero orientado a proyectos más pequeños, que en sus versiones 2005 y 2008 pasa a ser el SQL Express Edition, que se distribuye en forma gratuita. Es común desarrollar completos proyectos complementando Microsoft SQL Server y Microsoft Access a través de los llamados ADP (Access Data Project). De esta forma se completa la base de datos (Microsoft SQL Server), con el entorno de desarrollo (VBA Access), a través de la implementación de aplicaciones de dos capas mediante el uso de formularios Windows. En el manejo de SQL mediante líneas de comando se utiliza el SQLCMD.

Para el desarrollo de aplicaciones más complejas (tres o más capas), Microsoft SQL Server incluye interfaces de acceso para varias plataformas de desarrollo, entre ellas .NET, pero el servidor sólo está disponible para Sistemas Operativos Windows.
MySQL
El sistema de base de datos operacional MySQL es hoy en día uno de los más importantes en lo que hace al diseño y programación de base de datos de tipo relacional. Cuenta con millones de aplicaciones y aparece en el mundo informático como una de las más utilizadas por usuarios del medio. El programa MySQL se usa como servidor a través del cual pueden conectarse múltiples usuarios y utilizarlo al mismo tiempo. La historia del MySQL (cuya sigla en inglés se traslada a My Structured Query Language o Lenguaje de Consulta Estructurado) se remite a principios de la década de 1980. Programadores de IBM lo desarrollaron para contar con un código de programación que permitiera generar múltiples y extendidas bases de datos para empresas y organizaciones de diferente tipo. Desde esta época numerosas versiones han surgido y muchas de ellas fueron de gran importancia. Hoy en día MySQL es desarrollado por la empresa Sun Mycrosystems. Una de las características más interesantes de MySQL es que permite recurrir a bases de datos multiusuario a través de la web y en diferentes lenguajes de programación que se adaptan a diferentes necesidades y requerimientos. Por otro lado, MySQL es conocida por desarrollar alta velocidad en la búsqueda de datos e información, a diferencia de sistemas anteriores. Las plataformas que utiliza son de variado tipo y entre ellas podemos mencionar LAMP, MAMP, SAMP, BAMP y WAMP (aplicables a Mac, Windows, Linux, BSD, Open Solaris, Perl y Phyton entre otras). Se están estudiando y desarrollando nuevas versiones de MySQL que buscan presentar mejoras y avances para permitir un mejor desempeño en toda aquella actividad que requiera el uso de bases de datos relacionales. Entre estas mejoras podemos mencionar un nuevo dispositivo de depósito y almacenamiento, backup para todos los tipos de almacenamientos, replicación segura, planificación de eventos y otras más.
Características de la versión 5.0.22
� Un amplio subconjunto de ANSI SQL 99, y varias extensiones. � Soporte a multiplataforma � Procedimientos almacenados � Disparadores (triggers) � Cursores

� Vistas actualizables � Soporte a VARCHAR � INFORMATION_SCHEMA � Modo Strict � Soporte X/Open XA de transacciones distribuidas; transacción en dos fases
como parte de esto, utilizando el motor InnoDB de Oracle � Motores de almacenamiento independientes (MyISAM para lecturas
rápidas, InnoDB para transacciones e integridad referencial) � Transacciones con los motores de almacenamiento InnoDB, BDB Y Cluster;
puntos de recuperación (savepoints) con InnoDB � Soporte para SSL � Query caching � Sub-SELECTs (o SELECTs anidados) � Réplica con un maestro por esclavo, varios esclavos por maestro, sin
soporte automático para múltiples maestros por esclavo. � Indexing y buscando campos de texto completos usando el motor de
almacenamiento MyISAM � Embedded database library � Soporte completo para Unicode � Conforme a las reglas ACID usando los motores InnoDB, BDB y Cluster � Shared-nothing clustering through MySQL Cluster
POSTGRESQL
PostGreSQL es un sistema de gestión de bases de datos objeto-relacional (ORDBMS) basado en el proyecto POSTGRES, de la universidad de Berkeley. El director de este proyecto es el profesor Michael Stonebraker, y fue patrocinado por Defense Advanced Research Projects Agency (DARPA), el Army Research Office (ARO), el National Science Foundation (NSF), y ESL, Inc. PostGreSQL es una derivación libre (OpenSource) de este proyecto, y utiliza el lenguaje SQL92/SQL99, así como otras características que comentaremos más adelante. Fue el pionero en muchos de los conceptos existentes en el sistema objeto-relacional actual, incluido, más tarde en otros sistemas de gestión comerciales. PostGreSQL es un sistema objeto-relacional, ya que incluye características de la orientación a objetos, como puede ser la herencia, tipos de datos, funciones, restricciones, disparadores, reglas e integridad transaccional. A pesar de esto, PostGreSQL no es un sistema de gestión de bases de datos puramente orientado a objetos.
Características
� Implementación del estándar SQL92/SQL99.
� Soporta distintos tipos de datos: además del soporte para los tipos base, también soporta datos de tipo fecha, monetarios, elementos gráficos, datos sobre redes (MAC, IP...), cadenas de bits, etc. También permite la creación de tipos propios.
� Incorpora una estructura de datos array. � Incorpora funciones de diversa índole: manejo de fechas, geométricas,
orientadas a operaciones con redes, etc. � Permite la declaración de funciones propias, así como la definición de
disparadores. � Soporta el uso de índices, reglas y vistas.
� Incluye herencia entre tablas (aunque no entre objetos, ya que no
existen), por lo que a este gestor de bases de datos se le incluye entre los gestores objeto-relacionales.
� Permite la gestión de diferentes usuarios, como también los permisos
asignados a cada uno de ellos.
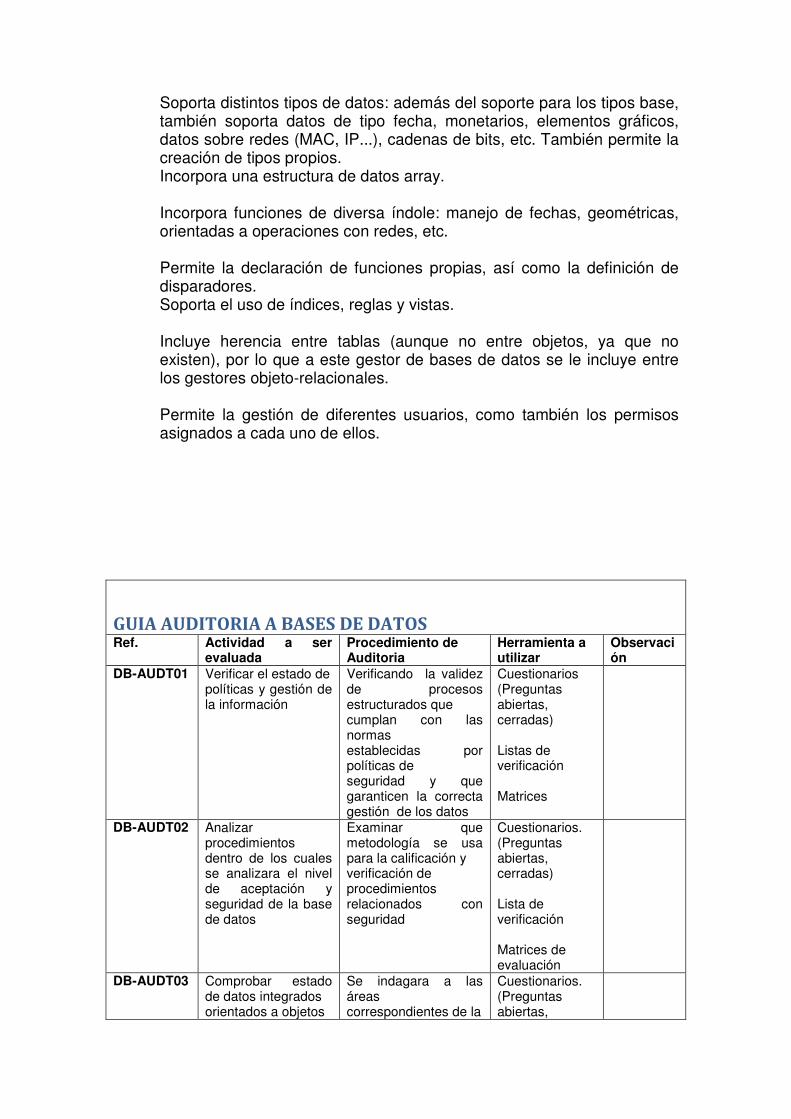
GUIA AUDITORIA A BASES DE DATOS Ref. Actividad a ser
evaluada Procedimiento de Auditoria
Herramienta a utilizar
Observación
DB-AUDT01 Verificar el estado de políticas y gestión de la información
Verificando la validez de procesos estructurados que cumplan con las normas establecidas por políticas de seguridad y que garanticen la correcta gestión de los datos
Cuestionarios (Preguntas abiertas, cerradas) Listas de verificación Matrices
DB-AUDT02 Analizar procedimientos dentro de los cuales se analizara el nivel de aceptación y seguridad de la base de datos
Examinar que metodología se usa para la calificación y verificación de procedimientos relacionados con seguridad
Cuestionarios. (Preguntas abiertas, cerradas) Lista de verificación Matrices de evaluación
DB-AUDT03 Comprobar estado de datos integrados orientados a objetos
Se indagara a las áreas correspondientes de la
Cuestionarios. (Preguntas abiertas,

dentro de la empresa para la toma de decisiones y almacenamiento de datos
integración de datos antiguos y nuevos para ver su nivel de gestión de conocimiento en la aplicación de herramientas de ayuda
cerradas)
Guía DB-AUDT01
Lista de verificación
Preguntas Si No Observaciones ¿Existe una metodología de diseño de la base de datos? ¿La alta dirección revisa los diferentes informes de los estudios de viabilidad?
¿Se evalúan los riesgos que puede tener la base de datos?
¿Existen privilegios y perfiles dentro del administrador de bases de datos?
¿Ha tenido salidas del sistema por ataques externos? ¿Existe un correo interno de la empresa, para la comunicación de los empleados?
¿Existe un responsable directo de determinado tipo de información?
¿El administrador de la base de datos, está al tanto de que funcionarios tiene acceso y restricciones a diferente información del sistema?
¿Existe una regulación de almacenamiento y retención de datos en la dependencia correspondiente?
¿Existen módulos que lleven a cabo revisiones de precisión, suficiencia y autorización de captura en el ingreso de datos?
¿Se cuenta con una plantilla de tareas para el manejo de la base de datos?
¿Se cuenta con una arquitectura de información? ¿Contempla el plan estratégico las ventajas de la tecnología usada en la base de datos?
¿Cuenta con consistencia en la base de datos?
Observaciones:_________________________________________________________________________________________________________________________________________________________________________________
• ¿Qué base de datos maneja y en que versión?
• ¿Existen manuales de instalación y manejo del motor de la base de datos?
• ¿Qué lenguajes se utilizarán y en que software?
• ¿Qué clase de servidores tiene almacenado el motor de la BD?

• ¿Cómo se maneja el soporte de la BD?
• ¿Con cuanta capacidad cuenta actualmente su base de datos?
• ¿Se maneja un Modelo Entidad Relación para el modelo de negocios?
• ¿Cómo se asignan los perfiles de acceso a la base de datos?
• ¿Qué protocolos y procedimientos existen para la transferencia de datos? ¿Se garantiza la confidencialidad de los datos?
• ¿Cómo utilizan los modelos de bases de datos orientadas a objetos?
• ¿Qué utilidades de inicio de sesión utilizado para administrar la base de datos?
• ¿Quién es el encargado de revisar permisos y políticas de seguridad para la gestión de la base de datos?
• ¿Los modelos de datos orientados a objetos tienen transacciones de larga duración?
• ¿Qué tipo de organigramas identifican a los propietarios y encargados del mantenimiento del sistema?
• ¿Existe una disponibilidad de la información almacenada en la base de datos?
Generalmente no existe_______ Hay ocasionalmente_________
Siempre________________ Regularmente_____________
¿Por qué? __________________________________________________________
• ¿Se realizan revisiones de flujo de información? Si___ No___
¿Cada cuanto se realizan estas revisiones de flujo de información?
Diario____________
Semanal___________
Mensual___________
Nunca__________
Otro___________

Observaciones:_________________________________________________________________________________________________________________________________________________________________________________
Matriz de responsabilidades
En la siguiente matriz se requiere establecer quién es el responsable o el actor en los diferentes entornos de la base de datos.
Edad Experiencia Antigüedad en el cargo
Usos a la base de datos
Personal de desarrollo de sistemas
Personal de explotación a la DB.
Personal de control de datos.
Administración de la base de datos.
Desarrollo de la base de datos.
Observaciones:_______________________________________________________________________________________________________________________________________
Estado de la guía DB-AUDT01
Nivel de madurez Estado de la guía No existe Inicial / Ad hoc Repetible - Intuitivo Proceso definido Administrado y medible Optimizado
Observaciones:_________________________________________________________________________________________________________________________________________________________________________________
Recomendaciones:_______________________________________________________________________________________________________________
GUIA DB-AUDT02
Lista de verificación
Preguntas Si No Observaciones ¿Los procedimientos de manejo de errores, aseguran razonablemente los errores e irregularidades que son detectados, reportados y corregidos?

¿Se mantienen programas y procedimientos de detección de virus en copias no autorizadas o datos procesados en otros equipos?
¿Se cuentan con periodos de retención de información? ¿Se cuenta con copias de archivos en lugar distinto al de la computadora?
¿Utiliza estrategias que se utilizan desde la gerencia para el respaldo (back-up) y recuperación de información?
¿Se tienen establecidos procedimientos de actualización de las copias de archivos?
¿Existe un proxy que delimite la navegación por internet de los usuarios?
¿Los respaldos son verificados regularmente? ¿Existen procedimientos para asegurar que los respaldos (back-ups) sean realizados de acuerdo con la estrategia de respaldo definida?
¿Se tiene un esquema de clasificación de datos para garantizar su nivel de seguridad?
¿Los tipos de datos son tratados con su respectiva notación?
¿Se lleva a cabo en su totalidad el plan de seguridad? ¿Existen reglamento para el uso de los recursos informáticos de la empresa?
Observaciones:__________________________________________________________________________________________________________________
• ¿El manejo de los password asignados a los usuarios se rige mediante que clase de normas?
• ¿Cuáles son los procesos y herramientas para mantener la seguridad de la base de datos?
• ¿Se generan copias de seguridad y respaldo? Si_______ No________
¿Cada cuanto se generan?
Diario___________
Semanal__________
Mensual__________
Nunca__________
Otro__________
• ¿Qué piensa de la seguridad en el manejo de la información proporcionada por el sistema que utiliza?
Nula ________
Riesgosa _______

Satisfactoria _______
Excelente _________
Lo desconoce_______
¿Por qué?____________________________________________
Observaciones:_________________________________________________________________________________________________________________________________________________________________________________
Matriz de evaluación Excelente
9-10 Bueno 7-8
Aceptable 5-6
Regular 3-4
Deficiente 1-2
Calidad de la información suministrada por la base de datos
Rapidez de las consultas Protección de los datos internos
Confidencialidad de la información ingresada
Manejo de errores Perfiles de usuario de acuerdo a la necesidad de las consultas
Gestión de generación de consultas
Observaciones____________________________________________________________________
________________________________________________________________________________
Estado de la guía DB-AUDT02 Nivel de madurez Estado de la guía No existe Inicial / Ad hoc Repetible - Intuitivo Proceso definido Administrado y medible Optimizado
Observaciones:_________________________________________________________________________________________________________________________________________________________________________________

Recomendaciones:_______________________________________________________________________________________________________________
GUIA DB-AUDT03
Lista de verificación
Preguntas Si No Observaciones ¿Se tiene diseñado un sistema data warehause? De ser SI la respuesta anterior, ¿Se tiene implementado un sistema data warehause?
¿Se tienen datos antiguos? ¿Se cuenta con un Lenguaje de definición de objetos (ODL, Object Definition Language)?
¿Se cuenta con un Lenguaje de consulta de objetos (OQL, Object Query Language)?
¿Se tiene en cuenta las necesidades a futuro? ¿Han existido perdidas de datos en la extracción de datos?
¿Existen un respaldo de los datos almacenados? ¿Se aplica la minería de datos a las bases de datos del negocio?
¿Existe una taxonomía dentro del tipo de datos manipulados?
¿Existen políticas que rijan el proceso de la minería de datos?
Las bases de datos orientadas a objetos, ¿soportan mecanismos de identidad de los objetos?
¿Existen reglamento para el uso de los recursos informáticos de la empresa?
Observaciones_________________________________________________________________________________________________________________________________________________________________________________
• ¿Cómo capturan las transacciones del negocio?
• ¿Poseen modelos dimensionales? Cuáles?
• ¿Qué herramientas cuenta para el acceso de los datos por usuarios finales?
• ¿Cómo se manejan los riesgos de los datos operacionales del sistema data warehause?
• ¿Cómo se realiza la manipulación de datos históricos?
• ¿Qué tipos de análisis se realizan a las propiedades de los datos?
• ¿Cómo es el proceso de elección de la técnica de minería de datos?
• ¿Qué documentación existe del proceso de minería de datos?
• ¿Cómo son los procesos para mantenerse actualizados técnicamente?

• En cuanto a DB2 complete la siguiente información
• Cantidad de conexiones locales
• Cantidad de conexiones remotas
• Cantidad de conexiones a través de gateways
• Ratio de agentes creados
• Agentes registrados
• Agentes esperando
Estado de la guía DB-AUDT02 Nivel de madurez Estado de la guía No existe Inicial / Ad hoc Repetible - Intuitivo Proceso definido Administrado y medible Optimizado
Observaciones:__________________________________________________________________________________________________________________
Recomendaciones:_______________________________________________________________________________________________________________

Referencia
WIKILEARNING. (s.f.). Recuperado el 20 de Noviembre de 2010, de:
http://www.wikilearning.com/curso_gratis/sistemas_de_bases_de_datos-
definicion_y_caracteristicas_de_un_sbd/3621-1
DEFINICION ABC. (s.f.). Recuperado el 20 de Noviembre de 2010, de:
http://www.definicionabc.com/tecnologia/datawarehouse.php
http://www.definicionabc.com/tecnologia/mysql.php
SINNEXUS. (s.f.). Recuperado el 20 de Noviembre de 2010, de:
http://www.sinnexus.com/business_intelligence/datamining.aspx
DESARROLLO WEB. (s.f.). Recuperado el 20 de Noviembre de 2010, de:
http://www.desarrolloweb.com/articulos/840.php
PERSONAL LOBOCOM. (s.f.). Recuperado el 20 de Noviembre de 2010, de:
http://personal.lobocom.es/claudio/sql001.htm
WORLDLINGO. (s.f.). Recuperado el 20 de Noviembre de 2010, de:
http://www.worldlingo.com/ma/enwiki/es/SAS_System
MONOGRAFIAS. (s.f.). Recuperado el 20 de Noviembre de 2010, de:
http://www.monografias.com/trabajos27/d-b-dos/d-b-dos.shtml
http://www.monografias.com/trabajos27/d-b-dos/d-b-dos.shtml
DANIEL PECOS. (s.f.). Recuperado el 20 de Noviembre de 2010, de:
http://danielpecos.com/docs/mysql_postgres/x15.html


















