An Adaptive Query Execution Engine for Data Integration
56
An Adaptive Query Execution Engine for Data Integration … Based on Zachary Ives, Alon Halevy & Hector Garcia-Molina’s Slides
-
Upload
stuart-hinton -
Category
Documents
-
view
34 -
download
4
description
An Adaptive Query Execution Engine for Data Integration. … Based on Zachary Ives, Alon Halevy & Hector Garcia-Molina’s Slides. Data Integration Systems. Uniform query capability across autonomous, heterogeneous data sources on LAN, WAN, or Internet: in enterprises, WWW, big science. - PowerPoint PPT Presentation
Transcript of An Adaptive Query Execution Engine for Data Integration

An Adaptive Query Execution Engine for Data Integration
… Based on Zachary Ives, Alon Halevy & Hector Garcia-Molina’s Slides

2
ReviewsSh ip p in gO rd ersIn ven toryBooks
m ybooks .com M edia ted S chem a
W e s t
...
F e dE x
W A N
a lt.bo o ks .re v ie w s
In te rne tIn te rne t In te rne t
UP S
E a s t O rde rs C us to me rR e v ie w s
NY Time s
...
M o rga n-K a ufma n
P re ntic e -Ha ll
Data Integration Systems
Uniform query capability across autonomous, heterogeneous data sources on LAN, WAN, or Internet: in enterprises, WWW, big science.

3
parse
convert
apply laws
estimate result sizes
consider physical plans estimate costs
pick best
execute
{P1,P2,…..}
{(P1,C1),(P2,C2)...}
Pi
answer
SQL query
parse tree
logical query plan
“improved” l.q.p
l.q.p. +sizes
statistics
Traditional Query Processing

4
Example: SQL query
SELECT titleFROM StarsInWHERE starName IN (
SELECT nameFROM MovieStarWHERE birthdate LIKE ‘%1960’
);
(Find the movies with stars born in 1960)

5
Example: Logical Query Plan
title
starName=name
StarsIn name
birthdate LIKE ‘%1960’
MovieStar

6
Example: Improved Logical Query Plan
title
starName=name
StarsIn name
birthdate LIKE ‘%1960’
MovieStar

7
Example: Estimate Result Sizes
Need expected size
StarsIn
MovieStar

8
Example: One Physical Plan
Parameters: join order, memory size, project
attributes,...
Hash join
SEQ scan index scan Parameters:Select Condition,...
StarsIn MovieStar

9
Hash function h, range 0 k Buckets for R1: G0, G1, ... Gk Buckets for R2: H0, H1, ... Hk
Algorithm (Grace Hash Join)(1) Hash R1 tuples into G buckets(2) Hash R2 tuples into H buckets(3) For i = 0 to k do
match tuples in Gi, Hi bucketsPartitioning (steps 1—2); probing (step 3)
Example: (Grace) Hash Join

10
Simple example hash: even/odd
R1 R2 Buckets R1 R22 5 Even: 4 4 3 12 Odd: 5 38 139 8
1114
2 4 8 4 12 8 14
3 5 9 5 3 13 11

11
Hash Join Variations
Question: what if there is enough memoryto hold R1?
R2 R154
123
138
1114
243589

12
Hash Join VariationsQuestion: what if there is enough memory to hold R1?
R2 R154
123
…
2, 4, 8 (1) Load entire R1 into memory
(2) Build hash table for R1(using hash function h)
(2) For each tuple r2 in R2 do- read r2- probe hash table for R1 using h(r2)- for matching tuple r1,
output <r1,r2>
R1 hashtable
3, 5, 95
<5,5>

13
Example: Estimate costs
L.Q.P
P1 P2 …. Pn
C1 C2 …. Cn Pick best!

14
New Challenges for Processing Queries in DI Systems
Little information for cost estimates
Unreliable, overlapping sources
Unpredictable data transfer rates
Want initial results quickly
Need “smarter” execution

15
The Tukwila Project
Key idea: build adaptive features into the core of the system
Interleave planning and execution (replan when you know more about your data) Compensate for lack of information Rule-based mechanism for changing behavior
Adaptive query operators: Revival of the double-pipelined join better
latency Collectors (a.k.a. “smart union”) handling
overlap

16
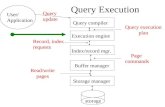
Tukwila Data Integration System
ExecutionEngine
Optim izer,Scheduler
Tem p Store
EventHandler
OperatorExecution
LogicalP lan
Exec.QueryP lan
Data from sources
Reformulator
Execution Stats
Q uery
Results
Novel components: Event handler Optimization-execution loop

17
Handling Execution Events
Adaptive execution via event-condition-action rules
During execution, events generatedTimeout, n tuples read, operator opens/closes, memory
overflows, execution fragment completes, …
Events trigger rules: Test conditions
Memory free, tuples read, operator state, operator active, …
Execution actionsRe-optimize, reduce memory, activate/deactivate
operator, …

18
Interleaving Planning and ExecutionRe-optimize if at unexpected state: Evaluate at key
points, re-optimize un-executed portion of plan [Kabra/DeWitt SIGMOD98]
Plan has pipelined units, fragments
Send back statistics to optimizer.
Maintain optimizer state for later reuse.
Fragm ent 1
Fragm ent 0
H ashJo in
East
H ashJo in
M ateria lize& Test
FedExOrders
WHEN end_of_fragment(0) IF card(result) > 100,000 THEN re-optimize

19
Handling LatencyOrders from data source A
OrderNo1234123513991500
TrackNo01-23-4502-90-8502-90-85 03-99-10
UPS from data source BTrackNo01-23-4502-90-8503-99-1004-08-30
StatusIn TransitDeliveredDeliveredUndeliverable
tuple
relation
SelectStatus = “Delivered” UPS
attribute
Data from B often delayed due to high volume of requests

20
Join Operation
Orders
UPS
Need to combine tuples from Orders & UPS:
JoinOrders.TrackNo = UPS.TrackNo (Orders, UPS)
OrderNo1234123513991500
TrackNo01-23-4502-90-8502-90-8503-99-10
StatusIn TransitDeliveredDeliveredDelivered
(2nd TrackNo attribute is removed)
OrderNo1234123513991500
TrackNo01-23-4502-90-8502-90-85 03-99-10
TrackNo01-23-4502-90-8503-99-1004-08-30
StatusIn TransitDeliveredDeliveredUndeliverable

21
Query plan represented as data-flow tree:
Query Plan Execution
Pipelining vs. materialization
Control flow? Iterator (top-down)
Most common database model
Easier to implement
Data-driven (bottom-up)
Threads or external scheduling
Better concurrency
SelectStatus = “Delivered”
JoinOrders.TrackNo = UPS.TrackNo
ReadOrders
ReadUPS
“Show which orders havebeen delivered”

22
Standard Hash Join
Standard Hash Joinread entire inneruse outer tuples to probe inner hash table
Double Pipelined Hash Join

23
Standard Hash Join
Standard hash join has 2 phases: Non-pipelined: Read entire inner relation, build hash table Pipelined: Use tuples from outer relation to probe the hash
table
Advantages: Only one hash table Low CPU overhead
Disadvantages: High latency: need to wait for all inner tuples Asymmetric: need to estimate for inner Long time to completion: sum of two data sources

24
Adaptive Operators: Double Pipelined Join
Standard Hash JoinDouble Pipelined Hash Join Hash table per source As tuple comes in, add
to hash table and probe opposite table

25
Double-Pipelined Hash Join
R2 R14
123
…
2, 4
R1 hashtable
3, 5
<5,5>
89
R2 hashtable
5
5
probe
(1) 2,4,3,5 arrived(2) 5 arrives
store5

26
Double-Pipelined Hash Join
Proposed for parallel main-memory databases (Wilschut 1990)
Advantages: Results as soon as tuples received Can produce results even when one source delays Symmetric (do not need to distinguish inner/outer)
Disadvantages: Require memory for two hash tables Data-driven!

27
Double-Pipelined Join Adapted to Iterator Model
Use multiple threads with queues Each child (A or B) reads tuples until full,
then sleeps & awakens parent
DPJoin sleeps until awakened, then: Joins tuples from QA or QB, returning all
matches as output
Wakes owner of queue
Allows overlap of I/O & computation in iterator model
Little overlap between multiple computations
DPJoin
A B
QA QB

28
Experimental Results(Joining 3 data sources)
Normal: DPJoin (yellow) as fast as optimal standard join (pink)
Slow sources: DPJoin much better
DPJoinOptimal StdSuboptimal Std
0
60
120
180
1 31 61 91
Tuples (100's)
Tim
e (
s)
0
80
160
240
1 31 61 91
Tuples (100's)
Tim
e (
s)

29
Insufficient Memory?
May not be able to fit hash tables in RAM
Strategy for standard hash join Swap some buckets to overflow files
As new tuples arrive for those buckets, write to files
After current phase, clear memory, repeat join on overflow files

30
Overflow Strategies
3 overflow resolution methods: Naive conversion — conversion into standard join;
asymmetric
Flush left hash table to disk, pause left source
Read in right source
Pipeline tuples from left source
Incremental Left Flush — “lazy” version of above
As above, but flush minimally
When reading tuples from right, still probe left hash table
Incremental Symmetric Flush — remains symmetric
Choose same hash bucket from both tables to flush

31
Simple Algorithmic Comparison
Assume s tuples per source (i.e. sources of equal size), memory fits m tuples: Left Flush:
If m/2 < s m (only left overflows): Cost = 2(s - m/2) = 2s - m
If m < s 2m (both overflow): Cost = 2(s + m2/2s - 3m/2) + 2(s - m) = 4s - 4m + m2/s
Symmetric Flush:If s < 2m:
Cost = 2(2s - m) = 4s - 2m

32
Experimental Results
0
140
280
420
1 31 61
Tuples (100's)
Tim
e (
s)
0
150
300
450
1 31 61
Tuples (100's)
Tim
e (
s)
Low memory (4MB): symmetric as fast as optimal
Medium memory (8MB): incremental left is nearly optimal
SymmetricIncrem. LeftNaiveOptimal (16MB)
Adequate performance for overflow cases Left flush consistent output; symmetric sometimes faster

33
Adaptive Operators: Collector
Utilize mirrors and overlapping sources to produce results quickly Dynamically adjust
to source speed & availability
Scale to many sources without exceeding net bandwidth
Based on policy expressed via rules
C
CustReviews
NYTim es
alt.books
WHEN timeout(CustReviews) DO activate(NYTimes), activate(alt.books)
WHEN timeout(NYTimes) DO activate(alt.books)

34
Summary
DPJoin shows benefits over standard joins Possible to handle out-of-memory conditions
efficiently Experiments suggest optimal strategy depends
on: Sizes of sources Amount of memory I/O speed

35
The Unsolved Problem
Find interleaving points? When to switch from optimization to execution?
Some straightforward solutions worked reasonably, but student who was supposed to solve the problem graduated prematurely.
Some work on this problem: Rick Cole (Informix) Benninghoff & Maier (OGI).
One solution being explored: execute first and break pipeline later as needed.
Another solution: change operator ordering in mid-flight (Eddies, Avnur & Hellerstein).

36
More Urgent Problems
Users want answers immediately: Optimize time to first tuple Give approximate results earlier.
XML emerges as a preferred platform for data integration: But all existing XML query processors are
based on first loading XML into a repository.

37
Tukwila Version 2
Able to transform, integrate and query arbitrary XML documents.
Support for output of query results as early as possible: Streaming model of XML query execution.
Efficient execution over remote sources that are subject to frequent updates.
Philosophy: how can we adapt relational and object-relational execution engines to work with XML?

38
Tukwila V2 Highlights
The X-scan operator that maps XML data into tuples of subtrees.
Support for efficient memory representation of subtrees (use references to minimize replication).
Special operators for combining and structuring bindings as XML output.

39
Tukwila V2 Architecture

40
Example XML File<db> <book publisher="mkp"> <title>Readings in Database Systems</title> <editors> <name>Stonebraker</name> <name>Hellerstein</name> </editors> <isbn>123-456-X</isbn> </book><company ID="mkp"> <name>Morgan Kaufmann</title> <city>San Mateo</city> <state>CA</state> </company></db>

41
XML Data Graph
db
#1
#2
#7mkp
ReadingsIn DatabaseSystems
123-456-X
#2#3 #6
Principlesof TransactionProcessing
235-711-Y
#8
#9
Morgan Kaufmann
San Mateo
#11 #12 #13
#4
StonebrakerHellerstein
#5
CA
#4
#5
#10
Bernstein
Newcomer

42
Example Query
WHERE <db> <book publisher=$pID> <title>$t</> </> ELEMENT_AS $b </> IN "books.xml", <db> <publication title=$t> <source ID=$pID>$p</>
<price>$pr</> </> </> IN "amazon.xml", $pr < 49.95CONSTRUCT <book> <name>$t</> <publisher>$p</> </>

43
Query
Execution
Plan

44
X-ScanThe operator at the leaves of the plan.Given an XML stream and a set of
regular expressions – produces a set of bindings.
Supports both trees and graph data.Uses a set of state machines to traverse
match the patterns.Maintains a list to unseen element Ids,
and resolves them upon arrival.

45
X-scan Data Structures
Structural Index
. . .
ID index
<db> <lab ID=... <name>Seattle... <location> <city>Seattle... ...
XML Tree Mgr
State MachinesStack
l c
#1 #3
Bindings
BindingTuples
ID2
. . .
ID1ID3
UnresolvedIDREFs
. . .

46
State Machines for X-scan
Mb:
MpID:
Mt:
1 2 3
4 5
db book
@publisher
6 7title

47
Other Features of Tukwila V.2
X-scan: Can also be made to preserve XML order. Careful handling of cycles in the XML graph. Can apply certain selections to the bindings.
Uses much of the code of Tukwila I.No modifications to traditional
operators.XML output producing operators.Nest operator.

48
In the “Pipeline”Partial answers: no blocking. Produce
approximate answers as data is streaming.
Policies for recovering from memory overflow [More Zack].
Efficient updating of XML documents (and an XML update language) [w/Tatarinov]
Dan Suciu: a modular/composable toolset for manipulating XML.
Automatic generation of data source descriptions (Doan & Domingos)

49
First 5 Results
4.971.48
6.381.61 3.50
34.6
0.64 2.78
47.0 190
0
10
20
30
40
50
Order 1234(R, 5MB)
LineItemQty < 32
(R, 31MB)
Orders xCust (R,
5x0.5MB)
LineItems xOrders (R,31x7MB)
Papersunder
Confs (I,0.2x9MB)
Papers withConfRefs(D, 39MB)
Query
Exe
c. T
ime
Tukwila
DOM Parse
Xalan
XT
Relational
938

50
Completion Time
22.13
104.75
20.04
363.53
208.57175.67
508.29
69.6
190
0
50
100
150
200
250
300
350
400
Order 1234(R, 5MB)
LineItemQty < 32
(R, 31MB)
Orders xCust (R,
5x0.5MB)
LineItems xOrders (R,31x7MB)
Papersunder
Confs (I,0.2x9MB)
Papers withConfRefs(D, 39MB)
Query
Exe
c. T
ime
Tukwila
Xalan
XT
Relational
938

51
Intermediate Conclusions
First scalable XML query processor for networked data.
Work done in relational query processing is very relevant to XML query processing.
We want to avoid decomposing XML data into relational structures.

52
Some Observations from Nimble
What is Nimble? Founded in June, 1999 with Dan Weld. Data integration engine built on an XML
platform. Query language is XML-QL. Mostly geared to enterprise integration,
some advanced web applications. 70+ person company (and hiring!) Ships in trucks (first customer is Paccar).

53
XML Query
User Applications
Lens™ File InfoBrowser™Software
Developers Kit
NIMBLE™ APIs
Front-End
XML
Lens Builder™Lens Builder™
Management Tools
Management Tools
Integration Builder
Integration Builder
Security T
ools
Data Administrator
Data Administrator
System Architecture
Concordance Developer
Concordance Developer
Integration
Layer
Nimble Integration Engine™
Compiler Executor
MetadataServerCache
Relational Data Warehouse/ Mart
Legacy Flat File Web Pages
Common XML View

54
The Current State of Enterprise Information
Explosion of intranet and extranet information
80% of corporate information is unmanaged
By 2004 30X more enterprise data than 1999
The average company: maintains 49 distinct
enterprise applications spends 35% of total IT
budget on integration-related efforts
1995 1997 1999 2001 2003 2005
Enterprise Information
Source: Gartner, 1999

55
Design Issues Query language for XML: tracking the W3C
committee. The algebra:
Needs to handle XML, relational, hierarchical and support it all efficiently!
Need to distinguish physical from logical algebra.
Concordance tables need to be an integral part of the system. Need to think of data cleaning.
Need to deal with down times of data sources (or refusal times).
Need to provide range of options between on-demand querying and pre-materialization.

56
Non-Technical Issues
SQL not really a standard.Legacy systems are not necessarily old.IT managers skeptical of truths.People are very confused out there.Need a huge organization to support the
effort.