Chapter 6 Query Execution. Query Query Compilation (Chapter 7 ) query plan Query execution...
91
Chapter 6 Query Execution
-
Upload
brianne-white -
Category
Documents
-
view
286 -
download
6
Transcript of Chapter 6 Query Execution. Query Query Compilation (Chapter 7 ) query plan Query execution...

Chapter 6
Query Execution

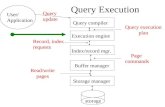
Query
Query Compilation (Chapter 7 )
query plan
Query execution metadata
( Chapter 6 ) data
the major parts Of the query processor

Query Compilation
1. Parse Query parse tree
2. Rewrite Query logical query plan
3. Implement Query physical query plan
2+3 => Query Optimization

Metadata for Query Optimization
• The size of each relation
• Statistics such as the approximate number and frequency of different values for an attribute.
• The existence of certain indexes
• The layout of data on disk.

Overview of Query Optimization

parse
convert
apply laws
estimate result sizes
consider physical plans estimate costs
pick best
execute
{P1,P2,…..}
{(P1,C1),(P2,C2)...}
Pi
answer
SQL query
parse tree
logical query plan
“improved” l.q.p
l.q.p. +sizes
statistics

Example: SQL query
SELECT title
FROM StarsIn
WHERE starName IN (
SELECT name
FROM MovieStar
WHERE birthdate LIKE ‘%1960’
);
(Find the movies with stars born in 1960)

Example: Parse Tree<Query>
<SFW>
SELECT <SelList> FROM <FromList> WHERE <Condition>
<Attribute> <RelName> <Tuple> IN <Query>
title StarsIn <Attribute> ( <Query> )
starName <SFW>
SELECT <SelList> FROM <FromList> WHERE <Condition>
<Attribute> <RelName> <Attribute> LIKE <Pattern>
name MovieStar birthDate ‘%1960’

Example: Generating Logical Query Plan
title
StarsIn <condition>
<tuple> IN name
<attribute> birthdate LIKE ‘%1960’
starName MovieStar

Example: Logical Query Plan
title
starName=name
StarsIn name
birthdate LIKE ‘%1960’
MovieStar

Example: Improved Logical Query Plan
title
starName=name
StarsIn name
birthdate LIKE ‘%1960’
MovieStar
Question:Push project to
StarsIn?

Example: Estimate Result Sizes
Need expected size
StarsIn
MovieStar

Physical Query Plan
• Selecting algorithms to implement each of the operators of the logical query plan.
• Selecting an order of execution for these operators.

Example: One Physical Plan
Parameters: join order, memory size, project
attributes,...
Hash join
SEQ scan index scan Parameters:Select Condition,...
StarsIn MovieStar

Example: Estimate costs
L.Q.P
P1 P2 …. Pn
C1 C2 …. Cn
Pick best!

Query Execution
• To execute the operations of physical query plan
• Major approaches: scanning, hashing, sorting, and indexing
• Different costs and structures due to the amount of available main memory

Textbook outline
Chapter 66.1 Algebra for queries [bags vs set
s]- Select, project, join, …. [project list
a,a+b->x,…]- Duplicate elimination, grouping, sorting
6.2 Physical operators- Scan,sort, …
6.3-6.10 Implementing operators +estimating their cost

An Algebra for QueriesRelational Algebra SQLOperators Operators
Union ∪ UNIONIntersection ∩ INTERSECTIO
N
Difference - EXCEPT
Selection σ WHERE
Projection Π SELECT
Product × FROM
Join ∞ JOIN
Duplicate elimination δ DISTINCT
Grouping γ GROUP BY
Sorting τ ORDER BY

Differences Between SQL Relations and Set
• Relations are bags
• Relations have schemas

Union, Intersection, and Difference
1. For R U S, a tuple t is in the result as many times as the number of times it is in R plus the number of times it is in S ;
2. For R ∩ S, a tuple t is in the result the minimum of the number times it is in R and S ;
3. For R – S, a tuple t is in the result the number of times it is in R minus it is in S, but not fewer than zero times 。
For example : Suppose R={A, B, B} S={C, A, B, C}
R U S={A, A, B, B, B ,C, C}
R ∩ S={A, B}
R – S={B}

The Selector Operator
• Selection σc(R) , produces the bag of those tuples in R that satisfy the condition C 。
Condition C may involve : 1. Arithmetic or string operators on constants and/or attributes ; 2. Comparison between terms constructed in 1 ; 3. Boolean connectives AND, OR, and Not applied to terms cons
tructed in 2.For example : R a b σa≥1(R): a b σb≥3 AND a+b≥6(R) 0 1 2 3 a b 2 3 4 5 4 5 4 5 2 3 2 3

The Projection Operator• ΠL(R) is the projection of R onto the list L 。 L can have the following kinds of elements : 1. A single attribute of R ; 2. An expression x y, where x and y are names for attr
ibutes 。 In the result, the attribute x of R is renamed with y;
3. An expression E z, where E is an expression, z is a new name for the attribute that results from calculation implied by E 。
For example : R a b c Πa,b+c→x(R) a x 0 1 2 0 3 0 1 2 0 3 3 4 5 3 9

The Product of Relations The product RXS is a relation whose
schema consists of attributes of R and the attributes of S.
For example : R: a b S: b c 0 1 1 4 2 3 1 4 2 3 2 5
a R.b S.b c
000222222
1 1 1 3 3 3 3 3 3
1 1 2 1 1 2 1 1 2
4 4 5 4 4 5 4 4 5
R×S:

JoinsNatural Join: R ∞ S = ΠL(σc(RXS)), where :1. C is a condition that equates all pairs of attribute
s of R and S that have the same name.2. L is a list of all the attributes of R and S, except t
hat one copy of each pair of equated attributes is omitted.
For example : R: a b S: b c
0 1 ∞ 1 4
2 3 1 4 2 3 2 5
a b c0 1 40 1 4

The theta-join: R ∞ S = σc(RXS), c
If C is x = y, x from R and y from S, we call it equijoin
For example : R: a b S: b c 0 1 1 4 2 3 1 4 2 3 2 5
∞ a+R.b<c+S.b
a R.b S.b c
0 1 1 40 1 1 40 1 2 52 3 2 52 3 2 5
For example : R: a b S: b c 0 1 1 4 2 3 1 4 2 3 2 5
∞ b=b
a R.b S.b c
0 1 1 40 1 1 4

Duplicate Elimination
For example : R: a b 0 1 2 3 2 3
For relation R, δ ( R) returns the set consisting of one copy of every tuple that appears one or more times in relation R.
δ ( R ): a b 0 1 2 3

Grouping and Aggregation
• Grouping: According to Attribute (s)
• Having: Grouping Condition
• Aggregation operators: AVG, SUM, COUNT,MIN and MAX

For StarsIn (title, year, starName), to find , for each star who has appeared in at least three movies, the earliest year in which they appeared.
SQL: SELECT starNme, MIN(year) AS minYear FROM StarsIn GROUP BY starName HAVING COUNT(title)>=3; Π starName,minYear
σ ctTitle>=3
γ starName, MIN(year) → minYear, COUNT(title) → ctTitle
StarsIn

The Sorting Operator
τL(R) denotes relation R is sorted in the order indicated by L 。
For example, for R(a, b, c), τc,b(R) orders the tuples of R by their value of c, and tuples with the same c-value are ordered by their b value. Tuples that agree on both b and c may be ordered arbitrarily.

Logical Query PlanFor example, there are two tables : MovieStar
(name,addr,gender,birthdate)
StarsIn(title,year,starName)
Convert SQL statements into logical query plan : SELECT title,birthdate
FROM MovieStar,StarIn
WHERE year = 1996 AND gender=‘F’ AND starName=name;
Π title,birthdate Πtitle,birthdate
∞
σ year=1996 AND gender=‘F’AND starName=name starName=name
× σ gender=‘F’ σ year=1996
MovieStar StarIn MovieStar StarsIn

Physical-Query-Plan
• Scanning a table• Executing algebraic operators• Passing data among operators

Scanning Tables
• Table–scan
• Index–scan

Sorting While Scanning Tables
(1) scanning index
(2) main-memory sorting algorithm
(3) multiway merge sort

The Model of Computation for Physical Operators
• Use the number of disk I/O as the measure of cost for an operation
• Assume the arguments of any operator on disk and the result left in memory
• Pipeline the result of one operator to another operator

Parameters for Measuring Costs
• M: the number of main-memory buffers available to an execution of a particular operator
• B(R): the number of blocks that are needed to hold all the tuples of R
• T(R): the number of tuples in R
• V(R,a): the number of distinct values of the column for a in R

I/O Cost for Sort-Scan Operator
Fits in main memory
Does not fit in main memory
Clustered B 3B
Not Clustered T T+2B

Iterators for Implementation of Physical Operators
Open (R) { b:= the first block of R; t:= the first tuple of block b; Found:= TRUE; }
GetNext(R) { IF ( t is past the last tuple on block b ) { increment b to the next block; IF ( there is no next block) { FOUND:=FALSE;RETURN;} ELSE t:= first tuple on block b; oldt:= t; increment t to the next tuple of b; RETURN oldt }
Close(R) { }

Building a union iterator from its components Open (R,S) { R.Open(); CurRel:=R; } GetNext (R,S) { IF (CurRel=R) { t:=R.GetNext(); IF (FOUND) RETURN t; ELSE S.Open(); CurRel:=S; } } RETURN S.GetNext() } Close(R,S){ R.Close() ; S.Close(); }

Implementation Algorithms for Algebraic Operators
1. Sorting-based methods
2. Hash-based methods
3. Index-based methods
Three degrees of difficulty and cost: one-pass, two-passes, three or more passes

One-Pass Algorithms for Database Operators
1. Tuple-at-a-time, unary operations
2. Full-relation, unary operations
3. Full-relation, binary operations

R
Input buffer Output buffer
Unary operate
• COST :If R is clustered , disk I/O is B;
If R is not clustered , disk I/O is T.
One-Pass Algorithms for Tuple-at-a-Time Operations

One-Pass Algorithms for Unary, Full-Relation Operations
• Duplication Eliminationδ(R) Read a block from disk , for each tuple to make a decision : 1. If it has not been seen before, copy it to the output ; 2. Otherwise, ignore it 。 In order to support this decision , keep one copy in memory 。
B(δ(R)) ≤ M-1 → B(δ(R)) ≤ M R
Input buffer
Seen before?
M-1 buffersOutput buffer
Main Memory: Hash Table or Binary Search Tree

One-Pass Algorithm for Binary Operations
• Set Union
• Set Intersection
• Set Difference
• Bag Intersection
• Bag Difference
• Product
• Natural Join
S R
∩
Output
B(S) <= M-1

Nested-Loop Joins
• Tuple-Based Nested-Loop Join
• Block-Based Nested-Loop Join
They can be used for relations of any size.

Tuple-Based Nested-Loop Join
R(X,Y)∞S(Y,Z)
FOR each tuple s in S DO FOR each tuple r in R DO IF r and s join to make a tuple t THEN output t ; Cost may be T(R)T(S) Disk I/O.

An Iterator for Tuple-Based Nested-Loop Join
Open (R,S) { R.Open(); S.Open(); S:=S.GetNext(): } GetNext (R,S) { REPEAT { r:=R.GetNext (); IF (NOT Found) { R.Close(); S:=S.GetNext(); IF (NOT Found) RETURN; R.Open(); r:=R.GetNext (); } } UNTILL (r and s join); RETURN the join of r and s; } Close (R,S) { R.Close(); S.Close() }

Block-Based Nested-Loop Join
• Organizing access to both argument relations by blocks
• Using as much main memory as we can to store tuples belonging to the relation S, the relation of the outer loop

FOR each chunk of M-1 blocks of S DO BEGIN read these blocks into main-memory buffers; organize their tuples into a search structure whose search key is the common attributes of R and S; FOR each block b of R DO BEGIN read b into main memory; FOR each tuple t of b DO BEGIN find the tuples of S in main memory that can join with t; output the join of t with each these tuples; END; END; END;
The nested-loop join algorithm

Assume B(R) = 1000, B(S) = 500 and M = 101Using S in the outer loop, we need 5X(100+1000) = 5500 Disk I/OUsing R in the outer loop, we need 10X(100+500) = 6000 Disk I/O
There is a slight advantage to using the smaller relation in the outer loop.

Summary of Algorithms
Operators Approximate M required
Disk I/O
σ Π 1 B
γ δ B B
∪ ∩ - × ∞ min (B(R),B(S)) B(R)+B(S)
∞ M≥2 B(R)B(S)/M

Two-Pass Algorithms Based on Sorting
• Two-pass algorithm for sorting B(R) (B(R)>M): Read M blocks of R into main memory
Sort M blocks, using an efficient sorting algorithm
Write the sorted list into M blocks of disk.
Main memory disk1.Read data, process in some way2.Write out to disk, again
3.Reread from disk to complete the operation
First pass

Duplicate Elimination Using Sorting
R
M buffers Same M buffers
ReadWrite
Sorting
Sorted sublists of R
Reread
Choose the first unconsidered tuple t in sorted order
Output the first copy of t and remove the other copies of t.
All of sorted sublists are exhausted.

Example 6.15: assume M=3, and only two tuples fit on a block. The relation R consists of 17 tuples:
(2,5,2,1,2,2,) ( 4,5,4,3,4,2,) (1,5,2,1,3)
R1 R2 R3
sublist In memory Waiting on disk
R1 1 2 2 2, 2 5
R2 2 3 4 4, 4 5
R3 1 1 2 3, 5
sublist In memory Waiting on disk
R1 2 2 2, 2 5
R2 2 3 4 4, 4 5
R3 2 3 5
sublist In memory Waiting on disk
R1 5
R2 3 4 4, 4 5
R3 3 5
sublist In memory Waiting on disk
R1 5
R2 4 4 4 5
R3 5

Analysis:• The total cost of this algorithm is 3B(R).
• to compute δ(R) with the two-pass algorithm requires only √B(R) blocks of memory since B≤M(M-1)≈M²
1.B(R) : to read each block of R when creating the sorted sublists.2.B(R) : to write each of the sorted sublists to disk.3.B(R): to read each block from the sublists at the appropriate time

Grouping and Aggregation Using Sorting
This algorithm for γ takes 3B(R) disk I/O’s, as long as B(R) ≤M ²
One pass to generate the sorted sublist of R
γL(R)
Find the least value v of the sort key ( grouping attributes)
All tuples with sort key v becomes the next group
Compute all the aggregates on the group
Output the group as tuple of the result
Until all sublists are exhausted.

Sort-Based Algorithms for Union, Intersection and Difference
Each of the algorithms takes 3(B(R)+B(S)) disk I/O’s , as long as B(R)+B(S)≤M*M
• Generate the sorted sublists for R, S respectively
• Use one buffer for each sublist of R and S.
• Repeatedly find the first remaining tuple t among all the buffers.
Union: copy t to the output, and remove all copies of t from the buffers.
If a buffer becomes empty, reload it with the next block from its sublist.
Intersection: Set: output t if it appears in both R and S.
Bag: output t the minimum of the number of times it appears in R and S.Difference :
R―s S output t if and only if it appears in R but not in S
R―B S: output t the number of times it appears in R minus the number of times it appears in S.

• Example 6.16: make the same assumptions as Ex6.15. And R has 12 tuples and S has 5 tuples. Ask R ―B S:?
(2,5,2,1,2,2,) ( 4,5,4,3,4,2,) (1,5,2,1,3)
R1 R2 S1
sublist In memory Waiting on disk
R1 1 2 2 2, 2 5
R2 2 3 4 4, 4 5
S1 1 1 2 3, 5
sublist In memory Waiting on disk
R1 2 2 2, 2 5
R2 2 3 4 4, 4 5
S1 2 3 5
sublist In memory Waiting on disk
R1 5
R2 3 4 4, 4 5
S1 3 5
sublist In memory Waiting on disk
R1 5
R2 4 4 4 5
S1 5
The output is 2,2,2,2,4,4,4,5.

A Simple Sort-Based Join Algorithm
R(X,Y) join S(Y,Z)
Sort R Sort S
Buffer for R Buffer for S
The least value y
Appears in both of R and S Does not appear in the other
Remove the tuples with sort key yIdentify all the tuples from both R and S
Output all of the joined tuples

• Example 6.17 Assume: B(R)=1000, B(S)=500, M=101. Then we use 4(B(R)+B(S))=6000 disk I/O’s to sort with two-phase multiway merge sort. When we merge the sorted R and S to find the joined tuples, we use another B(R)+B(S)=1500 disk I/O’s. So ,the total number of disk I/O’s is 5(B(R)+B(S))=7500.
• Analysis: The sort-join has linear I/O cost, taking time proportional to B(R)+B(S), while the nested-loop join is a quadratic algorithm, taking time proportional to B(R)B(S). It is only the constant factors and the small size of the example that make nested-loop join preferable. And the sort-join requires B(R)≤M*M, B(S) ≤M*M to work.

• If the tuples from one of the relations fit in M-1 buffers, perform one-pass join on the tuples with the sort key y from the two relations.
• If neither of them can fit in M-1 buffers, perform a nested-loop join on the tuples with the sort key y from the two relations.
The number of tuples with Y-value y does not fit in M buffers

A More Efficient Sort-Based Join
Sort R Sort S
Sorted Sublists of R Sorted Sublists of S
Buffer for each sublists
Find the least Y-value y
Identify all the tuples of both relations that have Y-value y
Output all the joined tuples
Repeatedly

Analysis
• Example 6.18:B(R)=1000, B(S)=500, M=101.Divide R into 10 sublists, S into 5 sublists, each of length 100. Use 15 buffers to hold the current blocks of each sublist. The total number of disk I/O’s is
3(B(R)+B(S))=4500 . It requires B(R)+B(S)≤M*M.

Summary of Sort-Based Algorithm
Operators Approximate M Required
Disk I/O
γ δ √B 3B
∪ ∩ - √(B(R)+B(S)) 3(B(R)+B(S))
∞ √max(B(R),B(S)) 5(B(R)+B(S))
∞ √(B(R)+B(S)) 3(B(R)+B(S))

Two-Pass Algorithms Based on Hashing
• Pass One Hash all the tuples of the argument or arg
uments using an appropriate hash function.• Pass Two Perform the operation by working on one b
ucket at a time (or on a pair of buckets with the same hash value)

Partitioning Relations by Hashing
• Initialize M-1 buckets using M-1 empty buffers;• FOR each block b of relation R DO BEGIN• Read block b into the Mth buffer;• FOR each tuple t in b DO BEGIN• IF the buffer for bucket h(t) has no room for t THEN• BEGIN• Copy the buffer to disk;• Initialize a new empty block in that buffer;• END;• Copy t to the buffer for bucket h(t);• END;• END;• FOR each bucket DO• IF the buffer for this bucket is not empty THEN write the buffer to disk ;

Hash-Based Algorithms for Union, Intersection, and Difference
R SRelations
R1 Ri S1 Si… …… …Hash R and S by the same hash functions.
One-pass algorithm to each pair of corresponding buckets.
For example, R ∩ S = (R1 ∩ S1) U … (Ri ∩ Si) U …
Cost: 3(B( R ) +B(S)) disk I/O Requirement: min(B( R ), B(S)) <= M(M-1)

The Hash-Join Algorithm
R SRelations
R1 Ri S1 Si… …… …
Hash R and S by the same hash functions with the join attributes as the hash key.
One-pass algorithm to each pair of corresponding buckets.
R ∞ S = (R1 ∞ S1) U … (Ri ∞ Si) U …
Cost: 3(B( R ) +B(S)) disk I/O Requirement: min(B( R ), B(S)) <= M(M-1)

Saving Some Disk I/O’s by Hybrid Hash-Join
k-m buckets
m buckets
Requirements:
mB(S)/k+k-m≤M 。
• Keep m of the k buckets entirely in main memory.• Keep only one block for each of the other k – m buckets.
Cost: (3- 2M/B(S))(B(R)+B(S))(3- 2M/B(S))(B(R)+B(S))

Operators M I/O’s δ,γ
∩∪― ∞
√B
√B(S)
√B(S)
3B
3(B(R)+B(S))
3(B(R)+B(S))
Summary of Hash-Based Algorithms (B(S)<B(R) )

Index-Based Algorithm
The existence of an index on one or more attributes of a relation makes available some algorithms that would not be feasible without index.

Clustering and Nonclustering Indexes
A clustering index has all tuples with a fixed value packed into (close to) the minimum possible number of blocks.
a1 a1 a1 a1 a1 a1 a1 a1 a1 a1 a1 a1
All the a1-tuples

Index-Based Selection
For σa=v (R), there is an index on a,
1. Search the index with value v;
2. Get the pointers to exactly those tuples of R that have a-value v;
3. Retrieve tuples following these pointers.
Cost:Cost: B(R)/V(R,a) (Index is clustered);B(R)/V(R,a) (Index is clustered); T(R) /V(R,a) (Index is non-clustered)T(R) /V(R,a) (Index is non-clustered)

For example:
B(R)=1000, T(R)=20000, let a be one of the attributes of R, suppose there is an index on a, and consider the operation
σa=0 (R), :– If R is clustered , without index, cost is 1000– If R is not clustered , without index, cost is 20000– If V(R,a)=100, with the clustering index, cost is B(R)/V
(R,a) =10– If V(R,a)=100, with the nonclustering index , cost is T
(R) /V(R,a) =200.– If V(R,a)=20000, a is the key of R , cost is 1.

Joining by Using an IndexSuppose R(X,Y)∞S(Y,Z) with an index on the attribute(s) Y
of S.
1. For each tuple t of R, use the index to find all those tuples of S having the same Y-value.
2. Output the join of each of these tuples with t.
Disk I/O :– Read all the tuples of R
• B(R) ( R is clustered) ;• T(R) (R is nonclustered)
– Retrieve tuples of S• Index is clustered, T(R)B(S)/V(S,Y)• Index is not clustered, T(R)T(S)/V(S,Y)

Joins Using a Sorted Index
• Suppose that we have relations R(X,Y) and S(Y,Z) with indexes on Y for both relations. A zig-zag join using two indexes are performed as follows:
• R 1, 3, 4 4, 4, 5, 6
• S 2 2 4 4 6 7

Buffer Management
Buffer manager
Read / Write
Buffers
Requests
1. The buffer manager controls main memory directly.2. The buffer manager allocates buffers in virtual memory.

Buffer Management Strategies
• Least-Recently Used (LRU)• First-In-First-Out (FIFO)• The “Clock” Algorithm
• System Control
00 1
0 1
01
1

The Relationship Between Physical Operator Selection and Buffer Management
• The selection of algorithms depends on the number of the available main-memory buffers.
• Some algorithms can adapt to changes in the number of the available main-memory buffers.
• The buffer-replacement strategy has impact on the number of disk I/Os for execution of the physical operators.

Algorithms Using More Than Two Passes
• Multipass Sort-Based Algorithm
• Multipass Hash-Based Algorithm

Multipass Sort-Based AlgorithmsBASIS: If R fits in M blocks, then read R into main memory,
sort it using your favorite main-memory sorting algorithm, and write the sorted relation to disk.
INDUCTION: If R does not fit into main memory, partition the blocks holding R into M groups, which we shall call R1, R2, …,RM. Recursively sort Ri for each i = 1,2,…,M. Then, merge the M sorted sublists.

Performance of Multipass, Sort-Based Algorithm
Let s(M,k) be the maximum size of a relation that we can sort using M buffers and k passes.
• Basis: If k=1, s(M,1)=M.• Induction : If k>1, partition R into M Pieces, e
ach of which must be sortable in k-1 passes. if B(R)=s(M,k), B(R)/M≤s(M,k-1), then s(M,k)= Ms(M,k-1).
s(M,k)= Ms(M,k-1)=M²s(M,k-2)=...=M^(k-1) s(M,1)=M^k.

Multipass Hash-Based Algorithm
• BASIS: For a unary operation, if the relation fits in M buffers, read it into memory and perform the operation. For a binary operation, if either relation fits in M-1 buffers, perform one pass algorithm.
• INDUCTION: If no relation fits in main memory, then hash each relation into M-1 buffers. Recursively perform the operation on each bucket or corresponding pair of buckets, and accumulate the output from each bucket or pair.

Performance of Multipass Hash-Based Algorithms
• Unary Operation: Let u(M,k) be the number of blocks in the largest relation that a k-pass hashing algorithm can handle.
– Basis : u(M,1)=M.– Induction : Divide the relation R into M-1 buckets of
equal size, u(M,k)=(M-1)u(M,k-1). u(M,k)=M(M-1)^(k-1)≈M^k
• Binary Operation, R(X,Y)∞S(Y,Z) : Let j(M,k) be an upper bound on the size of the smaller of R and S 。– Basis : j(M,1)=M-1.– Induction : j(M,k)=(M-1)j(M,k-1),
So j(M,k)=(M-1)^k.

Parallel Algorithms for Relational Operations
• Models of Parallelism
• Tuple-at-a-Time Operations in Parallel
• Parallel Algorithms for Full-Relation Operations
• Performance of Parallel Algorithms

Models of Parallelism
M M M
P P P
A shared-memory machine

P P P
M M M
A shared-disk machine

M M M
P P P
A shared-nothing machine

Tuple-at-a-Time Operations in Parallel
R
R1 R2 Ri Rn… …
P1 P2 Pi Pn
σc(R) = σc (R1) U σc(R2) U …U σc(Ri) U … U σc(Rn)
Partition R to n Processors evenly.

Parallel Algorithms for Full-Relation Operations
R
S
… …R1, S1 Ri, Si Rn, Sn
P1 P2 P3
Partition R and S by the same hash functions, perform the binary operation at each processor.

Performance of Parallel Algorithms
• Unary Operation: B(R)/p• Binary Operation: 5(B(R) + B(S))/p
p is the number of the parallel processors.

Exercise
• Ex 6.1.6 (d), EX 6.3.1 (e)
• Ex 6.4.3 (a), Ex 6.5.3 (a)
• Ex 6.6.2, Ex 6.7.2 (b)
• Ex 6.8.1 (c), Ex 6.10.1 (b)