
7 Models of Con Currency
24
The Problem Hardware Models Programmer Models Models of Concurrency David Chisnall February 22, 2011
Transcript of 7 Models of Con Currency

The Problem Hardware Models Programmer Models
Models of Concurrency
David Chisnall
February 22, 2011

The Problem Hardware Models Programmer Models
Computers are Slow!
• Buying two computers is cheaper than buying one that’s twiceas fast
• Sometimes buying a faster processor is not even possible, butbuying twice as many is
Author's Note
Comment
It's always easier (and cheaper) to take an existing processor and buy two of them than it is to buy one twice as fast. Modern supercomputers are built using a few thousand (or tens of thousand) off-the-shelf processors, so making use of them requires significant awareness of the problems with concurrent programming.

The Problem Hardware Models Programmer Models
Trivial Concurrency
Multiple users, multiple computers
Author's Note
Comment
The simplest form of concurrency is just to have a set of independent computers. In aggregate, they have greater throughput than a single machine, and they also have the advantage that multiple users can do 'work' on them without interfering.

The Problem Hardware Models Programmer Models
Collaboration Problem
Old problem:
• It takes one woman nine months to produce a baby.
• How many women do you need to produce a baby in onemonth?
Author's Note
Comment
Just having two computers lets you do twice as many things, but it doesn't let you do one thing faster, which was the goal.

The Problem Hardware Models Programmer Models
Shared Memory
• Uniform Memory Architecture (UMA)
• Symmetric Multiprocessor (SMP)
• Duplicate the processors, nothing else
The Problem Hardware Models Programmer Models
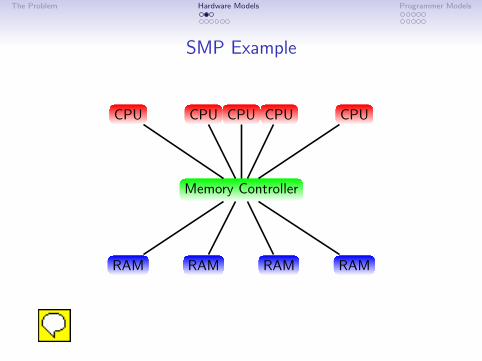
SMP Example
CPU
Memory Controller
RAM RAM RAM RAM
CPU CPU CPU CPU
Author's Note
Comment
The simplest SMP architecture just bolts some extra CPUs on in front of the memory controller.

The Problem Hardware Models Programmer Models
Problems with SMP
• Memory controller can handle one memory request at a time
• Each CPU needs to wait for others to complete
• Memory starvation
• Cache coherency
Author's Note
Comment
This simple design suffers from problems. We already looked at cache coherency a little bit. This version also has the problem that the memory controller needs to service requests one at a time, so there is greater latency when processors fetch from RAM.

The Problem Hardware Models Programmer Models
Solution: Private Memory
• Non-Uniform Memory Architecture (NUMA)
• Each processor has private memory
• Access to other CPU’s memory is indirect and explicit
Author's Note
Comment
Many modern desktops are actually NUMA, with a memory controller per core, but the difference in speed between local memory and remote is so small that they look like SMP systems to the OS.

The Problem Hardware Models Programmer Models
NUMA Example
MemoryController
MemoryController
MemoryController
MemoryController
RAM RAM RAM RAM
CPU CPU CPU CPU
Author's Note
Comment
The simplest SMP architecture just bolts some extra CPUs on in front of the memory controller. This simple arrangement is similar to the one found in AMD chips - one HyperTransport link to adjacent cores. More complex ones involve hypercube layouts or crossbar switching. In simple cases, each CPU may have a direct connection to each other CPU, but that gets expensive quickly.

The Problem Hardware Models Programmer Models
Emulating UMA with NUMA
• Done by most cluster operating systems and supercomputers
• Single global address space
• Remote memory fetched and cached as required
Author's Note
Comment
This is done in the hardware on AMD and recent Intel systems. On clusters, it's done in software. The OS implements on of the cache coherency protocols that we looked at previously and ensures that concurrent updates to memory happen in the correct order.

The Problem Hardware Models Programmer Models
Problems with Emulating UMA
• Memory in different locations costs different amounts toaccess
• The programmer doesn’t see this
• Reasoning about performance is very hard
Author's Note
Comment
Emulating is popular, because it means that you can take code written to use multiple threads and run it on a cluster. Unfortunately, it generally runs very slowly.

The Problem Hardware Models Programmer Models
Hidden in the Details
What’s this black line?
CPU CPU
• HyperTransport / QuickPath Interconnect
• Infiniband
• Gigabit Ethernet
• The Internet
• Carrier Pigeons (see RFC1149)
Author's Note
Comment
The basic architecture is the same in all cases, but the performance characteristics vary a lot. If it's HyperTransport across 1cm of silicon, then it's not going to cost very much compared with the cost of going to memory. If it's TCP/IP across a continent, then it may take 3 or more orders of magnitude longer than going to local memory.

The Problem Hardware Models Programmer Models
INMOS Transputer
Author's Note
Comment
First parallel microprocessor. Individual nodes had private memory for each CPU and microcoded instructions for communicating with other nodes.

The Problem Hardware Models Programmer Models
What Does the Programmer See?
• Shared memory?
• Independent Processes?
• Some combination?

The Problem Hardware Models Programmer Models
Shared-Everything: Threads
• Private stack
• Everything else shared

The Problem Hardware Models Programmer Models
Multithreaded Memory Layout
0x00000000
0xffffffff
Program Code0x00001000
0x0000f000
Library Code
0x00100000
0x00140000
Static Data
0x000fe000
Heap Memory
0xf0000000
stack 10xffffffff
stack 2
0xffffffff
Author's Note
Comment
Small change from traditional C memory layout. Now there are two stacks, instead of just one. This means two sets of executing functions, each with their own - independent - local memory.

The Problem Hardware Models Programmer Models
Aside: Coroutines
• The ucontext() C library call allows you to create stacks
• And switch between them
• Concurrent programming style, but only one real thread: notrue concurrency
Author's Note
Comment
You can emulate threads in C using the ucontext() stuff. This lets you create stacks and switch between them. You can trigger this switch from a timer and have something that looks like concurrency, but it will only use one CPU (core).

The Problem Hardware Models Programmer Models
Advantages of Threads
• Threads can share pointers
• Data structures are implicitly shared
• Easy to extend serial code to use threads
Author's Note
Comment
Threads are conceptually very simple, which means that they are implemented everywhere.

The Problem Hardware Models Programmer Models
Disadvantages of Threads
• Everything is shared, but not always safe to access
• Hard to reason about cost of operations
• Hard to model interactions - any byte in memory is apotential interaction point
• Debugging code using threads is incredibly painful
Author's Note
Comment
The complexity of debugging concurrent code is roughly proportional to the number of places where threads can interact, multiplied by the number of threads. With a shared-everything model, this becomes insanely complex with small numbers of thread.

The Problem Hardware Models Programmer Models
The Opposite Extreme: Shared Nothing
• Separate processes
• Exchange data explicitly
• No implicit sharing
Author's Note
Comment
Several models fit this broad definition. Typically they some form of message passing.

The Problem Hardware Models Programmer Models
Message Passing
• Explicit data exchange
• Usually asynchronous
• Helps latency hiding

The Problem Hardware Models Programmer Models
Latency Hiding
• Process sends a message
• Continues working
• Message reply arrives
Author's Note
Comment
The important bit here is that the process does not have to wait until the reply arrives. Sending a message across a network can take a very long time (in CPU terms), so waiting for every reply can kill performance.

The Problem Hardware Models Programmer Models
Contrast with Distributed Shared Memory
• Attempts to access remote memory
• Waits for fetch to local cache
• Continues
Author's Note
Comment
Shared memory systems have implicit synchronisation, which means implicit blocking while waiting for remote data.

The Problem Hardware Models Programmer Models
Questions?















![Currency crises · 2018-04-04 · Currency crises Tomasz Michalski1 1GREGHEC: HEC Paris [International Macroeconomics] Typology of currency crisis models First-generation models Second-generation](https://static.fdocuments.in/doc/165x107/5edacb4da22bb1624d6d8fc0/currency-crises-2018-04-04-currency-crises-tomasz-michalski1-1greghec-hec-paris.jpg)


