
19. TESTS DE HIPÓTESIS PARA LA MEDIA DE UNA … Tests para una... · Supongamos que estamos...
23
Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 125 ESTADÍSTICA (Q) 19. TESTS DE HIPÓTESIS PARA LA MEDIA DE UNA POBLACIÓN NORMAL CON VARIANZA CONOCIDA 19.1 Desarrollo de un ejemplo Interesa saber si el método de absorción atómica de vapor frío para determinar mercurio introduce errores sistemáticos. Se determina el porcentaje de mercurio en un material estándar de referencia que contiene 38.9% de mercurio, obteniéndose los siguientes valores expresados en porcentaje: 37.9, 37.4, 37.1. Esperamos que el promedio de los valores observados ( que en este caso vale 46 . 37 = x ) esté cerca del valor verdadero. ¿Es la diferencia entre el valor promedio observado y el valor medio esperado atribuible al azar, ó es por algo más: presencia de error sistemático? Podemos plantear la pregunta anterior como una decisión entre las dos hipótesis siguientes: - Hipótesis nula (H 0 ): diferencia atribuible al azar - Hipótesis alternativa (H a ): fue por algo más (error sistemático). Sea X = porcentaje de mercurio obtenido en una determinación, supongamos que X es una variable aleatoria con distribución X ~ N ( μ, 1). Esto significa que el valor observado es igual a μ más un error que tiene media 0 y varianza 1: X = μ + ε ε ~ N ( 0,1 ). Consideremos X1, X2, X3 variables aleatorias independientes e igualmente distribuidas que X, suponemos que los datos (37.9, 37.4, 37.1) son valores observados de dichas variables. Si las mediciones no tienen sesgo μ = 38.9% ( μ 0 ). Si además no se tienen razones para suponer que el sesgo debe ser en algún sentido ya sea mayor o menor, podemos escribir las hipótesis nula y alternativa de la siguiente manera: H 0 : μ = μ 0 contra H a : μ ≠ μ 0 Esta hipótesis alternativa conduce a un test a dos colas, test bilateral. Esto significa que valores de la media muestral observada suficientemente mayores o suficientemente menores que 38.9% son evidencia a favor de la hipótesis alternativa. Equivalentemente, la hipótesis nula no se rechaza cuando x no está demasiado lejos de 38.9%. “Demasiado lejos” corresponde a valores poco probables cuando la hipótesis nula es verdadera. Estos valores constituyen la Región de Rechazo del test. Si la hipótesis nula es verdadera tenemos ) 1 , 0 ( ~ 1 9 . 38 3 N X Z − =
Transcript of 19. TESTS DE HIPÓTESIS PARA LA MEDIA DE UNA … Tests para una... · Supongamos que estamos...

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 125ESTADÍSTICA (Q) 19. TESTS DE HIPÓTESIS PARA LA MEDIA DE UNA POBLACIÓN NORMAL CON VARIANZA CONOCIDA 19.1 Desarrollo de un ejemplo Interesa saber si el método de absorción atómica de vapor frío para determinar mercurio introduce errores sistemáticos. Se determina el porcentaje de mercurio en un material estándar de referencia que contiene 38.9% de mercurio, obteniéndose los siguientes valores expresados en porcentaje: 37.9, 37.4, 37.1. Esperamos que el promedio de los valores observados ( que en este caso vale
46.37=x ) esté cerca del valor verdadero. ¿Es la diferencia entre el valor promedio observado y el valor medio esperado atribuible al azar, ó es por algo más: presencia de error sistemático? Podemos plantear la pregunta anterior como una decisión entre las dos hipótesis siguientes: - Hipótesis nula (H0): diferencia atribuible al azar - Hipótesis alternativa (Ha): fue por algo más (error sistemático). Sea X = porcentaje de mercurio obtenido en una determinación, supongamos que X es una variable aleatoria con distribución X ~ N ( μ, 1). Esto significa que el valor observado es igual a μ más un error que tiene media 0 y varianza 1:
X = μ + ε ε ~ N ( 0,1 ). Consideremos X1, X2, X3 variables aleatorias independientes e igualmente distribuidas que X, suponemos que los datos (37.9, 37.4, 37.1) son valores observados de dichas variables. Si las mediciones no tienen sesgo μ = 38.9% ( μ0 ). Si además no se tienen razones para suponer que el sesgo debe ser en algún sentido ya sea mayor o menor, podemos escribir las hipótesis nula y alternativa de la siguiente manera:
H0: μ = μ0 contra Ha: μ ≠ μ0 Esta hipótesis alternativa conduce a un test a dos colas, test bilateral. Esto significa que valores de la media muestral observada suficientemente mayores o suficientemente menores que 38.9% son evidencia a favor de la hipótesis alternativa. Equivalentemente, la hipótesis nula no se rechaza cuando x no está demasiado lejos de 38.9%. “Demasiado lejos” corresponde a valores poco probables cuando la hipótesis nula es verdadera. Estos valores constituyen la Región de Rechazo del test. Si la hipótesis nula es verdadera tenemos
)1,0(~1
9.383 NXZ −=

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 126ESTADÍSTICA (Q)
19.383 −
=XZ es llamado estadístico del test
Regla de decisión a nivel α
Rechazo H0 si |Z|≥ zα/2 No rechazo H0 si |Z| < zα/2
Supongamos que estamos realizando un test con nivel de significación 5%, z0.025 = 1.96. Para todas las medias muestrales que se encuentren a más de 1.96 desvíos (σ/√3) de 38.9 el test resultará en rechazo. ¿Qué significa que el test tenga nivel α = 0.05? Es la probabilidad de tomar la decisión equivocada de decidir que se están realizando determinaciones con sesgo cuando en realidad las mediciones no tienen sesgo. P (rechazar H0 cuando H0 es verdadera (μ = 38.9)) = Pμ0( |Z|≥ 1.96) = 0.05 Ejemplo. Continuación. ¿Qué decisión se toma en este caso con 46.37=x a nivel α = 0.05?
49.2|49.2|1
|9.3846.37|3|| =−=−
=zobs
Como el valor observado del estadístico del test es -2.49, su valor absoluto es mayor que 1.96, luego se rechaza la hipótesis nula. Los datos proveen suficiente evidencia a nivel α = 0.05 para decidir que el método introduce sesgo. 19.2 TESTS DE HIPÓTESIS PARA LA MEDIA DE UNA POBLACIÓN NORMAL CON VARIANZA CONOCIDA. FORMA GENERAL. a) TEST BILATERAL Sea X1, ... , Xn una muestra aleatoria de una población normal, N(μ,σ2). Interesa testear las hipótesis

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 127ESTADÍSTICA (Q)
H0: μ = μ0 contra Ha: μ ≠ μ0 El estadístico del test
σμ0−
=XnZ
tiene distribución N(0,1) cuando μ = μ0 (H0 es verdadera) Región de rechazo ó región crítica de nivel α está dada por: |Z| ≥ zα/2 b) c) TESTS UNILATERALES Al testear la hipótesis nula, H0: μ=μ0, hemos elegido rechazarla para aquellos valores de X alejados de μ0. Si sabemos que la única manera en que no ocurre esa hipótesis es con valores de μ mayores que μ0 , la hipótesis alternativa es b) Ha: μ > μ0. En esta situación no interesa rechazar H0 para valores pequeños de X (ya que un valor de X pequeño es más probable cuando H0 es verdadera que cuando lo es Ha).
Resumen. Tests para la media de una población Normal con varianza conocida Sea X1, ... , Xn una muestra aleatoria de una población normal, N(μ,σ2)

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 128ESTADÍSTICA (Q) Hipótesis a testear: tipo a)
H0: μ = μ0 vs. Ha: μ μ0 ≠
Región de rechazo:
|Z| ≥ zα/2
Hipótesis a testear: tipo b)
H0: μ = μ0 vs. Ha: μ > μ0
Región de rechazo: Z ≥ zα
Hipótesis a testear: tipo c)
H0: μ = μ0 vs. Ha: μ < μ0
Región de rechazo: Z ≤ - zα
donde el estadístico del test es σ
μ0−=
XnZ
Es incorrecto utilizar una región de rechazo unilateral cuando en realidad debería utilizarse una bilateral. ¿Por qué? Observe que zα/2 > zα . ¿Qué significa el nivel del test? Consideremos un test bilateral, en los unilaterales es similar. P(Rechazar H0, cuando H0 es verdadera) = P(|Z|≥ zα/2) = α Mediante el nivel α utilizado controlamos la probabilidad de equivocarnos al rechazar H0 cuando H0 es verdadera. 19.3 TIPOS DE ERRORES
REALIDAD DECISIÓN H0 Ha
H0 Error de Tipo II Ha Error de Tipo I
El nivel del test controla la probabilidad del Error de Tipo I 19.4 P-Valor En la práctica, se obtiene primero el valor del estadístico del test que resulta de los valores observados. Luego se calcula la probabilidad de que la distribución Normal estándar se obtenga un valor más alejado que el valor observado del estadístico del test. Esta probabilidad, llamada p-valor, da el nivel de significación crítico. Es el nivel que se obtendría al utilizar el valor observado como punto de corte entre la región de rechazo y la región de no rechazo. Es el menor nivel para el cual se obtendría rechazo con los datos observados.
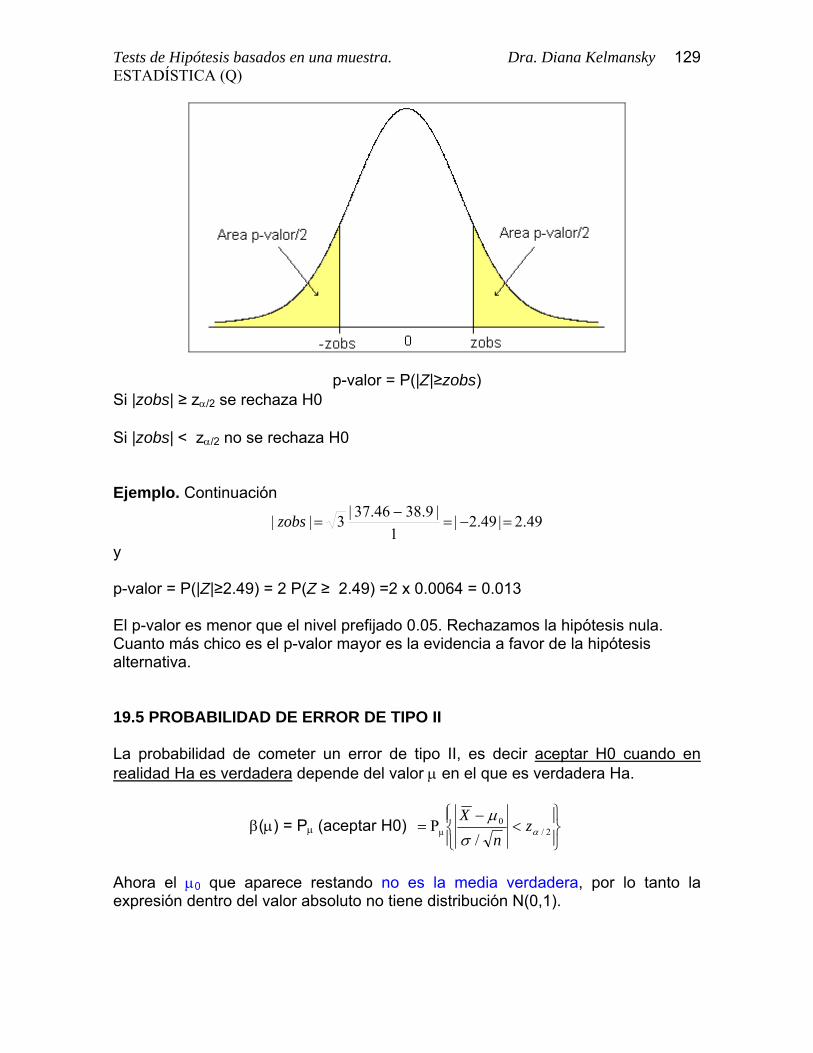
Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 129ESTADÍSTICA (Q)
p-valor = P(|Z|≥zobs) Si |zobs| ≥ zα/2 se rechaza H0 Si |zobs| < zα/2 no se rechaza H0 Ejemplo. Continuación
49.2|49.2|1
|9.3846.37|3|| =−=−
=zobs
y p-valor = P(|Z|≥2.49) = 2 P(Z ≥ 2.49) =2 x 0.0064 = 0.013 El p-valor es menor que el nivel prefijado 0.05. Rechazamos la hipótesis nula. Cuanto más chico es el p-valor mayor es la evidencia a favor de la hipótesis alternativa. 19.5 PROBABILIDAD DE ERROR DE TIPO II La probabilidad de cometer un error de tipo II, es decir aceptar H0 cuando en realidad Ha es verdadera depende del valor μ en el que es verdadera Ha.
β(μ) = Pμ (aceptar H0) ⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
<−
= 2/0
μ /P α
σμ
zn
X
Ahora el μ0 que aparece restando no es la media verdadera, por lo tanto la expresión dentro del valor absoluto no tiene distribución N(0,1).
Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 130ESTADÍSTICA (Q)
⎪⎭
⎪⎬⎫
⎪⎩
⎪⎨⎧
<−+−
= 2/0
μ/
P ασ
μμμz
nX
⎭⎬⎫
⎩⎨⎧
<−
+= 2/0
μ /P α
σμμ
zn
Z
donde )1,0(~/
Nn
XZσ
μ−=
Luego
β(μ) ⎭⎬⎫
⎩⎨⎧
<−
+<−= 2/0
2/μ /P αα
σμμ
zn
Zz ⎭⎬⎫
⎩⎨⎧ −
+<<−
+−=n
zZn
z//
P 02/
02/μ
σμμ
σμμ
αα
⎟⎠
⎞⎜⎝
⎛ −−
Φ−⎟⎠
⎞⎜⎝
⎛ +−
Φ= 2/0
2/0
// αα σμμ
σμμ z
nz
n (6)
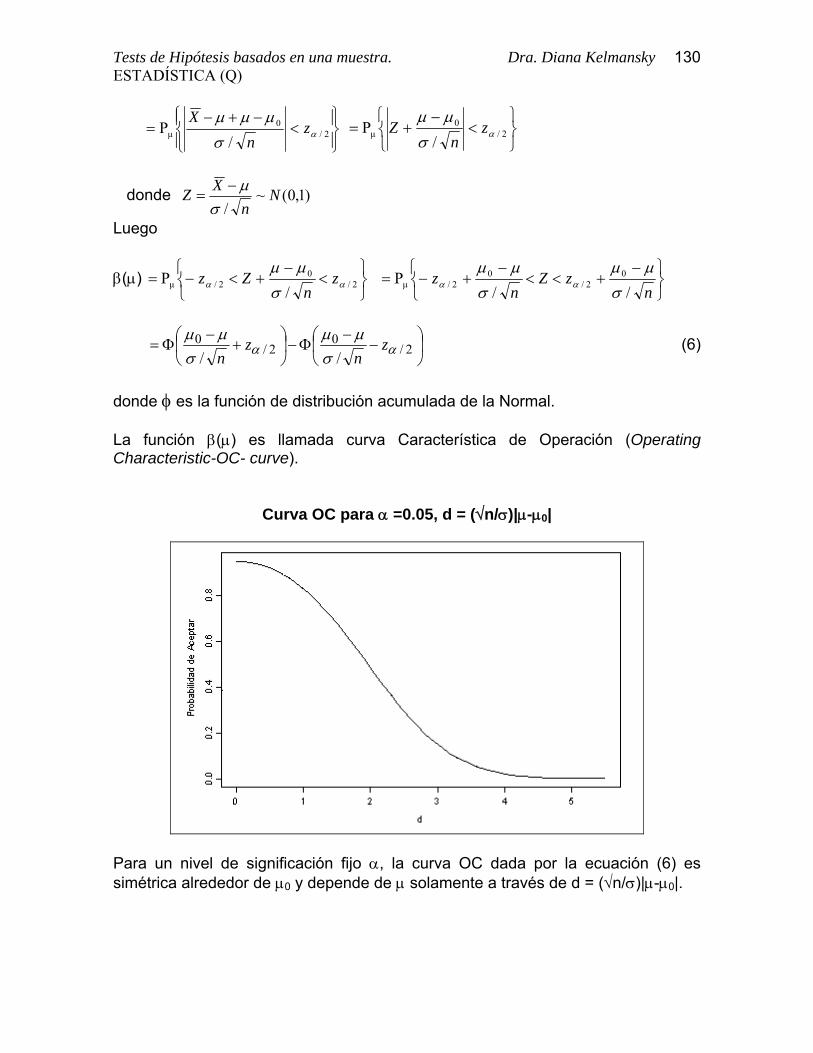
donde φ es la función de distribución acumulada de la Normal. La función β(μ) es llamada curva Característica de Operación (Operating Characteristic-OC- curve).
Curva OC para α =0.05, d = (√n/σ)|μ-μ0|
Para un nivel de significación fijo α, la curva OC dada por la ecuación (6) es simétrica alrededor de μ0 y depende de μ solamente a través de d = (√n/σ)|μ-μ0|.

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 131ESTADÍSTICA (Q) Ejemplo. Continuación. Para el test propuesto, obtengamos la probabilidad de aceptar la hipótesis nula de que μ = 38.9 (esto es que medimos sin sesgo) cuando en realidad estamos cometiendo un error sistemático de -0.5 = μ-μ0 Luego d = (√3/1)|-0.5| = 0.5√3 = 0.866. Luego, como z0.025 = 1.96, β(10) = φ(0.866 + 1.96) - φ(0.866 - 1.96) = φ(2.826) -φ(-1.094) = 0.99764 - 0.13698 = 0.86066 OBSERVACIÓN La función π(μ) = 1-β(μ) es llamada función de potencia del test. Para cada valor de μ, la potencia del test es la probabilidad de rechazo cuando el verdadero valor es μ. 19. 6 DETERMINACIÓN DEL TAMAÑO DE MUESTRA La función Característica de Operación (y equivalentemente la función de potencia) es útil para determinar cuan grande debe ser el tamaño de la muestra de manera que se cumplan ciertas especificaciones sobre la probabilidad de un error de tipo II. De acuerdo con la curva Característica de Operación (ver figura), como d = (√n/σ)|μ-μ0|, para una diferencia μ-μ0 fija a medida que aumenta n también aumenta d y por lo tanto decrece la probabilidad de aceptar H0. Valores de d y β de la función Característica de Operación con α = 0.05
d β d β d β 2.499 0.295 2.549 0.278 2.599 0.261 2.649 0.245 2.699 0.230 2.749 0.215 2.799 0.201 2.849 0.187
2.899 0.174 2.949 0.161 2.999 0.149 3.049 0.138 3.099 0.127 3.149 0.117 3.199 0.108 3.249 0.099
3.299 0.090 3.349 0.082 3.399 0.075 3.449 0.068 3.499 0.062 3.549 0.056 3.599 0.051 3.649 0.046
Si nos interesa un β aproximadamente igual a 0.25 resulta d = (√n/σ)|μ-μ0|= 2.649 n ≅ (2.649 σ / |μ-μ0|)2 Ejemplo. Continuación.

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 132ESTADÍSTICA (Q) ¿Cuántas determinaciones deben realizarse para que la probabilidad de no rechazar H0: μ=38.9 sea β ≅ 0.25 cuando en realidad las observaciones tienen un sesgo de -0.5 ? y para β ≅ 0.15? Para β ≅ 0.25 resulta n ≅ (2.649 1 / |0.5|)2=(2*2.649)2 = 28.69 Para β ≅ 0.15 resulta n ≅ (2*2.999)2 = 35.97 Si se realizan 36 determinaciones el porcentaje de veces que se cometerá el error de no rechazar H0 cuando se están realizando determinaciones sesgadas es del 15%. DESARROLLO ANALÍTICO Por ejemplo, supongamos que nos interesa determinar un tamaño de muestra de manera que la probabilidad de aceptar H0 μ= μ0 cuando la verdadera media es μ1 sea aproximadamente β. Queremos hallar n de manera que β(μ1) ≅ β. De la ecuación (6) resulta
β ⎟⎠
⎞⎜⎝
⎛ −−
Φ−⎟⎠
⎞⎜⎝
⎛ +−
Φ≈ 2/10
2/10
// αα σμμ
σμμ z
nz
n (7)
La ecuación anterior no tiene una solución analítica inmediata, sin embargo podemos hallar una solución aproximada. Si μ1 > μ0 , como φ es una función creciente
( ) 2// 2/2/
10 ασ
μμαα =−Φ≤⎟
⎠
⎞⎜⎝
⎛ −−
Φ zzn
Por lo tanto podemos despreciar el segundo sumando de (7)
β ⎟⎠
⎞⎜⎝
⎛ +−
Φ≈ 2/10
/ ασμμ zn
⎟⎠
⎞⎜⎝
⎛ +−
Φ≈−Φ 2/10
/)( αβ σ
μμ zn
z
Luego
2/10
/ αβ σμμ zn
z +−
≈−

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 133ESTADÍSTICA (Q) ó
210
222/
)(
)(
μμ
σβα
−
+≈
zzn
Ejemplo. Continuación. Recordemos que interesaba calcular cuántas determinaciones es necesario realizar para que la probabilidad de no rechazar H0: μ=38.9 sea β ≅ 0.25 cuando en realidad las observaciones tienen un sesgo de -0.5 y también para β ≅ 0.15? Como z0.025 = 1.96, z0.25 = 0.67, z0.15 = 1.04, μ-μ0 = 0.5, σ = 1
• para β ≅ 0.25 resulta n ≅ (1.96+0.67)2 4= 27.68,
• para β ≅ 0.15 resulta n ≅ (1.96+1.04)2 4= 36. Los resultados son similares a los obtenidos directamente de la curva O C. En el caso de tests unilaterales teníamos
Hipótesis a testear
b) H0: μ = μ0 vs. Ha: μ > μ0
Región de rechazo: Z ≥ zα
Hipótesis a testear
c) H0: μ = μ0 vs. Ha: μ < μ0
Región de rechazo: Z ≤ - zα
por lo tanto a probabilidad de cometer un error de tipo II, es decir no rechazar H0 cuando en realidad (la alternativa) Ha es verdadera en el valor μ es:
β(μ) = Pμ (no rechazar H0)
Ha: μ > μ0 Ha: μ < μ0
β(μ)⎭⎬⎫
⎩⎨⎧
<−
= ασ
μz
nX
/P 0μ
⎭⎬⎫
⎩⎨⎧
<−
+= ασ
μμz
nZ
/P 0μ
⎭⎬⎫
⎩⎨⎧
+−
<= ασ
μμz
nZ
/P 0μ
β(μ)⎭⎬⎫
⎩⎨⎧
−>−
= ασ
μz
nX
/P 0μ
⎭⎬⎫
⎩⎨⎧
−>−
+= ασ
μμz
nZ
/P 0μ
⎭⎬⎫
⎩⎨⎧
−−
>= ασ
μμz
nZ
/P 0μ

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 134ESTADÍSTICA (Q)
⎟⎠
⎞⎜⎝
⎛ +−
Φ= ασμμ zn/
0
⎟⎠
⎞⎜⎝
⎛ −−
Φ−= ασμμ zn/
1 0
⎟⎠
⎞⎜⎝
⎛ +−
−Φ= ασμμ zn/
0
Para ambas hipótesis alternativas unilaterales el tamaño de muestra para obtener una probabilidad de cometer un error de tipo II β es:
210
22
)(
)(
μμ
σβα
−
+=
zzn
OBSERVACIONES
1. En el caso de tests unilaterales no es necesario aproximar para obtener el tamaño de muestra. 2. Como φ es una función de distribución acumulada, es una función creciente
de su argumento. Resulta entonces que β(μ) ⎟⎞+ α
μ z es una función ⎠
⎜⎝
⎛ −Φ=
σμ
n/0
decreciente de μ. Esto es coherente con la intuición ya que es razonable que cuanto más alejada de μ0 esté la media verdadera μ tanto menos probable será no rechazar H0. 3. El test cuya región de rechazo es Z ≥ zα , fue diseñado para decidir entre
H0: μ = μ0 y Ha: μ > μ0 también puede utilizarse para testear las hipótesis
H0: μ ≤ μ0 contra Ha: μ > μ0. Para verificar que el test sigue siendo de nivel α, tenemos que verificar que la probabilidad de rechazar H0 cuando H0 es verdadera nunca supera a α. Debemos verificar que
1-β(μ) ≤ α para todo μ ≤ μ0
ó β(μ) ≥ 1 - α para todo μ ≤ μ0
Pero
β(μ) ⎟⎠
⎞⎜⎝
⎛ +−
Φ= ασμμ zn/
0 ( ) αα −=Φ≥ 1z

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 135ESTADÍSTICA (Q) 4. Análogamente, cuando la alternativa es Ha: μ < μ0 la hipótesis nula se puede extender a H0: μ ≥ μ0 es decir que el test unilateral se extiende a
H0: μ ≥ μ0 contra Ha: μ < μ0 19.7 RELACIÓN ENTRE INTERVALOS DE CONFIANZA Y TESTS DE HIPÓTESIS BILATERALES Un intervalo de confianza para μ basado en una muestra normal con varianza conocida σ2 con nivel de confianza 100(1-α)% es
⎟⎠
⎞⎜⎝
⎛ +−n
zXn
zX σσαα 2/2/ ,
Por lo tanto si μ = μ0
ασσμ αα −=⎭⎬⎫
⎩⎨⎧
⎟⎠
⎞⎜⎝
⎛ +−∈ 1, 2/2/0 nzX
nzXP
Un test de nivel α para testear H0: μ = μ0 contra Ha: μ ≠μ0 de nivel α, basado en el intervalo, consiste en rechazar H0 cuando
⎟⎠
⎞⎜⎝
⎛ +−∉n
zXn
zX σσμ αα 2/2/0 ,
ασσμ αα =⎭⎬⎫
⎩⎨⎧
⎟⎠
⎞⎜⎝
⎛ +−∉n
zXn
zXP 2/2/0 ,
Este test es idéntico al presentado anteriormente:

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 136ESTADÍSTICA (Q)
{ }2/
2/02/0
2/02/0
2/2/0
/)(/)(
,
α
αα
αα
αα
σμσμ
σμσμ
σσμα
zZP
zn
Xózn
XP
nzXó
nzXP
nzX
nzXP
≥=⎭⎬⎫
⎩⎨⎧
≥−−≤−=
⎭⎬⎫
⎩⎨⎧
+≥−≤=
⎭⎬⎫
⎩⎨⎧
⎟⎟⎠
⎞⎜⎜⎝
⎛+−∉=
19.8 TESTS DE HIPÓTESIS PARA LA MEDIA DE UNA POBLACIÓN NORMAL CON VARIANZA DESCONOCIDA Sea X1, ... , Xn una muestra aleatoria de una población Normal con media = μ y varianza = σ2, N(μ,σ2). Supongamos ahora que la varianza es desconocida y consideremos los mismos tres tipos de hipótesis alternativas sobre μ que vimos cuando la varianza era conocida.
Tipos de Hipótesis a) b) c)
H0: μ = μ0 vs. Ha: μ μ0 ≠ H0: μ = μ0 vs. Ha: μ > μ0 H0: μ = μ0 vs. Ha: μ < μ0
Como la varianza es desconocida, la estimamos por S y resulta el siguiente:
Estadístico del test: S
XnT 0μ−
= . Bajo H0: μ = μ0, T ~ tn-1
es el mismo cualquiera sea la hipótesis alternativa de interés y tiene distribución t con n-1 grados de libertad cuando μ = μ0 Región de rechazo: La forma de la zona de rechazo depende del tipo de hipótesis alternativa y del nivel del test.
Tipo de Hipótesis alternativa
Región de Rechazo de nivel α
a) Ha: μ μ0 ≠ b) Ha: μ > μ0 c) Ha: μ < μ0
2/ ,1 α−≥ ntT
α ,1−≥ ntT
α ,1−−≤ ntT

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 137ESTADÍSTICA (Q) Ejemplo: Se quiere decidir si un espectrofotómetro está calibrado. Para ello se obtienen 5 determinaciones de un gas estándar cuya concentración de CO es de 70 ppm obteniéndose los siguientes datos: 78, 83, 68, 72, 88. Supongamos que las observaciones se realizan de manera que pueden considerarse independientes e idénticamente distribuidas y que provienen de una distribución Normal. Esto es: Modelo: (X1, X2, X3, X4, X5) v.a.i.i.d. N(μ,σ2) Pregunta: ¿Existe evidencia para pensar que el espectrofotómetro funciona mal y las mediciones tienen un error sistemático ó el hecho que 4 de los valores sean mayores que 70 pueden explicarse por variabilidad aleatoria? A priori no podemos suponer en qué sentido será el sesgo. Planteo 1. Consideramos un test bilateral Hipótesis: H0: μ = 70 vs. Ha: μ ≠ 70
Estadístico del test: S
XnT 70−=
como n = 5 y α = 0.05 utilizando el valor crítico = 2.78 resulta la siguiente 0.025 ,4tRegión de Rechazo a nivel α = 0.05: 78.2 ≥T Valor observado del estadístico del test:
1532.21.8
708.775705 =−
=−
=S
xTobs
Conclusión Como Tobs = 2.1532 < 2.78 no rechazo H0 a nivel 0.05 P-valor Es la probabilidad de rechazar H0 cuando μ = μ0 y utilizo el Tobs como valor crítico: Utilizando el Statistix (Statistics -> Probability functions-> 2-Tail (x, df)) p-valor = P( 1532.2 ≥T ) = 0.09763 Utilizando las tablas de la t con 4 grados de libertad = 2 P(T 2.1532) ≈ 2 P(T 2.132) = 2 (0.05) = 0.10 ≥ ≥ Si el técnico que utiliza el espectrofotómetro sabe que este tiende a dar únicamente valores mayores que el esperado utilizamos el Planteo 2. Consideramos un test unilateral

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 138ESTADÍSTICA (Q) Hipótesis: H0: μ = 70 vs. Ha: μ > 70
Estadístico del test: S
XnT 70−=
como n = 5 y α = 0.05 utilizando el valor crítico = 2.13 resulta la siguiente 0.05 ,4tRegión de Rechazo a nivel α = 0.05: T ≥ 2.13 Valor observado del estadístico del test:
1532.21.8
708.775705 =−
=−
=S
xTobs
Conclusión Como Tobs = 2.1532 2.13 ≥ sí rechazo H0 a nivel 0.05 p-valor = P(T 2.1532)= 0.04882 (Utilizando el Statistix) ≥Utilizando las tablas de la t con 4 grados de libertad = P(T 2.1532) ≈ P(T ≥2.132) = 0.05 ≥ ¿Cómo se explica esta aparente contradicción? Función de potencia y cálculo del tamaño de muestra para obtener una probabilidad de error tipo II dada: La función de potencia de este test es complicada porque la distribución del estadístico cuando μ ≠ μo es una distribución t no central. Aunque hay tablas y gráficos que permiten obtener probabilidades para una distribución de este tipo, no los estudiaremos en este curso. Por la misma razón, no calcularemos tamaño de muestra para obtener una probabilidad de error tipo II dada para una alternativa fija. Respecto al p-valor, cuando se utilizan tablas sólo es posible obtener una cota, ya que las tablas proveen solamente algunos valores críticos de la distribución t. 19.9 TESTS PARA LA VARIANZA DE UNA POBLACIÓN NORMAL CUANDO LA MEDIA ES DESCONOCIDA Sea X1, ... , Xn una muestra aleatoria de una población Normal, N(μ,σ2). Los tres tipos de hipótesis a testear son a) H0: vs Ha: 2
02 σσ = 2
02 σσ ≠
b) H0: vs Ha: 20
2 σσ = 20
2 σσ >

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 139ESTADÍSTICA (Q) c) H0: vs. Ha: 2
02 σσ = 2
02 σσ <
Estadístico del test: 20
2)1(
σ
SnU
−= . Bajo H0: , U ~ 2
02 σσ = 2
1−nχ
Región de rechazo: Como siempre la forma de la zona de rechazo depende del tipo de hipótesis alternativa. Para cada tipo, estará dada por
a) ó 22/-1 ,1
22/ ,1 αα χχ −− ≤≥ nn UU
b) 2 ,1 αχ −≥ nU
c) 21 ,1 αχ −−≤ nU
respectivamente. Función de potencia y cálculo del tamaño de muestra para obtener una probabilidad de error tipo II dada: Como en el caso del test t, la función de potencia de este test es complicada porque la distribución del estadístico cuando
es una distribución no central. No la estudiaremos en este curso y, por la misma razón, no calcularemos tamaño de muestra para obtener una probabilidad de error tipo II dada, para una alternativa fija.
22oσσ ≠
Respecto al p-valor, también como en el caso del test t, cuando se utilizan tablas sólo es posible obtener una cota, ya que las tablas proveen solamente algunos valores críticos de la distribución χ2. Ejemplo: Se toman 25 determinaciones de la temperatura en cierto sector de un reactor, obteniéndose Cs o8.2 = Interesa saber, a nivel 0.05 si existe evidencia para decidir que la varianza de la temperatura en ese sector del reactor es mayor que ( )22 Co . Hipótesis a testear H0: vs Ha: 42 =σ 42 >σ
Estadístico del test 2
2)1(
σ
SnU −= ,
Región de rechazo 205.0 ,1
2
4)1(
−≥−
= nSnU χ
Tenemos que n = 25, luego de la tabla de una ji-cuadrado con 24 grados de

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 140ESTADÍSTICA (Q) libertad obtenemos . Como el valor observado de U es 47.04, se rechaza H0. Es decir, hay evidencia a nivel 0.05 de que la varianza de la temperatura del reactor es mayor que
42.36205.0 ,24 =χ
( )22 Co . 20. TESTS DE HIPÓTESIS DE NIVEL APROXIMADO (O ASINTÓTICO) α PARA LA MEDIA DE UNA DISTRIBUCIÓN CUALQUIERA Sea una m.a. de una distribución con media μ y varianza σ2 < ∞. El Teorema Central del Límite establece que para n suficientemente grande
nXXX ,...,, 21
)1,0(~ /
)(N
nX a
σμ−
Además, como S es un estimador consistente de σ, 1S
⎯→⎯pσ , luego
)1,0(~ 1
S
)1,0(~ )()(
NS
XnNXn a
p
a
μσ
σμ
−⇒
⎪⎪⎭
⎪⎪⎬
⎫
⎯→⎯
−
Observación: No se establece ninguna condición sobre la distribución de los datos solamente es necesario que el tamaño de la muestra sea grande. Los valores críticos de las regiones de rechazo se obtendrán de la distribución Normal estándar. Nuevamente consideremos los siguientes
Tipos de hipótesis a) b) c)
H0: μ = μ0 vs. Ha: μ μ0 ≠ H0: μ = μ0 vs. Ha: μ > μ0 H0: μ = μ0 vs. Ha: μ < μ0
Estadístico del test: S
XnZ oμ−
= . Bajo Ho: μ = μo, Z )(
~a
N(0,1)
es el mismo cualquiera sea la hipótesis alternativa de interés y tiene una distribución aproximadamente Normal cuando μ = μo Región de rechazo: La forma de la zona de rechazo depende de la hipótesis alternativa.
Tipo de Región de Rechazo

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 141ESTADÍSTICA (Q)
Hipótesis alternativa de nivel aproximado α a) Ha: μ μ0 ≠ b) Ha: μ > μ0 c) Ha: μ < μ0
2/ αzZ ≥
αzZ ≥
α zZ −≤ Función de potencia aproximada: Consideremos como ejemplo el tipo a), la función de potencia aproximada se obtiene en la forma siguiente:
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛≤
−−=
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛≥
−= 2/2/ 1)( αμαμ
μμμπ z
ns
XPz
ns
XP oo
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛≤
−+−≤−−= 2/2/1 ααμ
μμμz
ns
XzP o
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛−
+≤−
≤−
+−−=
ns
zn
sX
ns
zP oo μμμμμααμ 2/2/1
⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛−
+−Φ+⎟⎟⎟
⎠
⎞
⎜⎜⎜
⎝
⎛−
+Φ−≅
ns
z
ns
z oo μμμμαα 2/2/1
En forma similar, se obtiene la función de potencia aproximada en los otros dos tipos de hipótesis alternativas unilaterales ( b) y c) ). En las secciones siguientes veremos que cuando la varianza y la media dependen del mismo parámetro, no es necesario reemplazar σ por un estimador. Se lo reemplaza por el valor que determina la hipótesis nula. 20.1. TEST DE HIPÓTESIS DE NIVEL APROXIMADO (O ASINTÓTICO) α PARA UNA PROPORCIÓN (PARÁMETRO p DE LA DISTRIBUCIÓN BINOMIAL)
Sea una m.a. de una distribución Bi(1,p), luego ~ Bi(n,p).
Aplicando el Teorema Central del Límite, si n es suficientemente grande,
nXXX ,...,, 21 ∑=
n
iiX
1

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 142ESTADÍSTICA (Q)
)1,0(~)1(
)(N
npp
pX a
−−
donde X = / n la proporción muestral o frecuencia relativa de éxitos. ∑=
n
iiX
1 Nuevamente consideramos los siguientes tres
Tipos de hipótesis
a) b) c) H0: p = p0 vs. Ha: p p0 ≠ H0: p = p0 vs. Ha: p > p0 H0: p = p0 vs. Ha: p < p0
Estadístico del test: Z = . Bajo H0: p = p0, Z )(
~a
N(0,1)
npp
pX)1( 00
0−
−
Región de rechazo
Tipo de Hipótesis alternativa
Región de Rechazo de nivel aproximado α
a) Ha: p ≠ p0 b) Ha: p > p0 c) Ha:p < p0
2/αzZ ≥
αzZ ≥
α zZ −≤
20.2 TEST DE HIPÓTESIS DE NIVEL APROXIMADO α PARA EL PARÁMETRO λ DE UNA DISTRIBUCIÓN POISSON Sea una m.a. de una distribución de Poisson de parámetro λ. Entonces, si n es suficientemente grande,
nXXX ,...,, 21
)1,0(~/
)(N
nX a
λλ−
Nuevamente consideramos los siguientes tres
Tipos de hipótesis a) b) c)
H0: λ = λ0 vs. Ha: λ λ0 ≠ H0: λ = λ0 vs. Ha: λ > λ0 H0: l = l0 vs. Ha: λ < λ0

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 143ESTADÍSTICA (Q)
Estadístico del test: Z =n
X/0
0λ
λ−. Bajo H0:λ = λ0 , Z
)(~a
N(0,1)
Región de rechazo
Hipótesis alternativa Región de Rechazo de nivel aproximado α
a) Ha: λ ≠ λ0 b) Ha: λ > λ0 c) Ha: λ < λ0
2/αzZ ≥
αzZ ≥
α zZ −≤ Observación: Varios de los procedimientos que hemos visto para el caso en que la muestra es pequeña requieren del supuesto de Normalidad de los datos. Para esos métodos si los datos presentan una fuerte asimetría, tienen valores atípicos o tienen un histograma marcadamente diferente de la curva Normal en algún sentido, el test NO ES VÁLIDO. Lo mismo ocurre con el intervalo de confianza.
21. EVALUACIÓN DEL SUPUESTO DE NORMALIDAD
Dado un conjunto de datos consideraremos dos estrategias para evaluar si es razonable suponer que en la población de la cual proviene la muestra, la variable de interés tiene una distribución aproximadamente normal.
Métodos Gráficos Métodos Analíticos (Tests de hipótesis) • Box-plot • Histograma • Gráfico de tallo-hojas • Gráfico de Probabilidad
normal (Q-Q plot)
• Test de Shapiro-Wilk • Otros tests que no detallaremos
tales como: Lilliefords, Kolmogorov-Smirnov, etc.
En general, se decidirá si no existen alejamientos GROSEROS de la distribución normal. Si alguno de los métodos muestra claramente que la distribución de los datos no puede suponerse normal, entonces, habrá que abandonar los métodos estadísticos que tienen como supuestos esta distribución. Gráfico de Probabilidad normal (Q-Q plot)

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 144ESTADÍSTICA (Q) El gráfico de probabilidad normal es un diagrama de dispersión de los percentiles empíricos (datos ordenados) versus los percentiles teóricos de la distribución Normal. Si la muestra proviene de una distribución normal los puntos se encontrarán, salvo por fluctuaciones aleatorias, sobre una recta. Alejamientos de la distribución normal producen diferentes curvaturas que sugieren qué tipo de distribución puede tener la variable. Para los datos de concentración de CO no se observan importantes alejamientos de la linealidad. La figura siguiente muestra el gráfico de probabilidad normal para los datos de concentración de CO (78, 83, 68, 72, 88).
Las figuras siguientes muestran los histogramas de conjuntos de datos con diferentes alejamientos de la Normalidad y sus correspondientes gráficos de probabilidad normal.
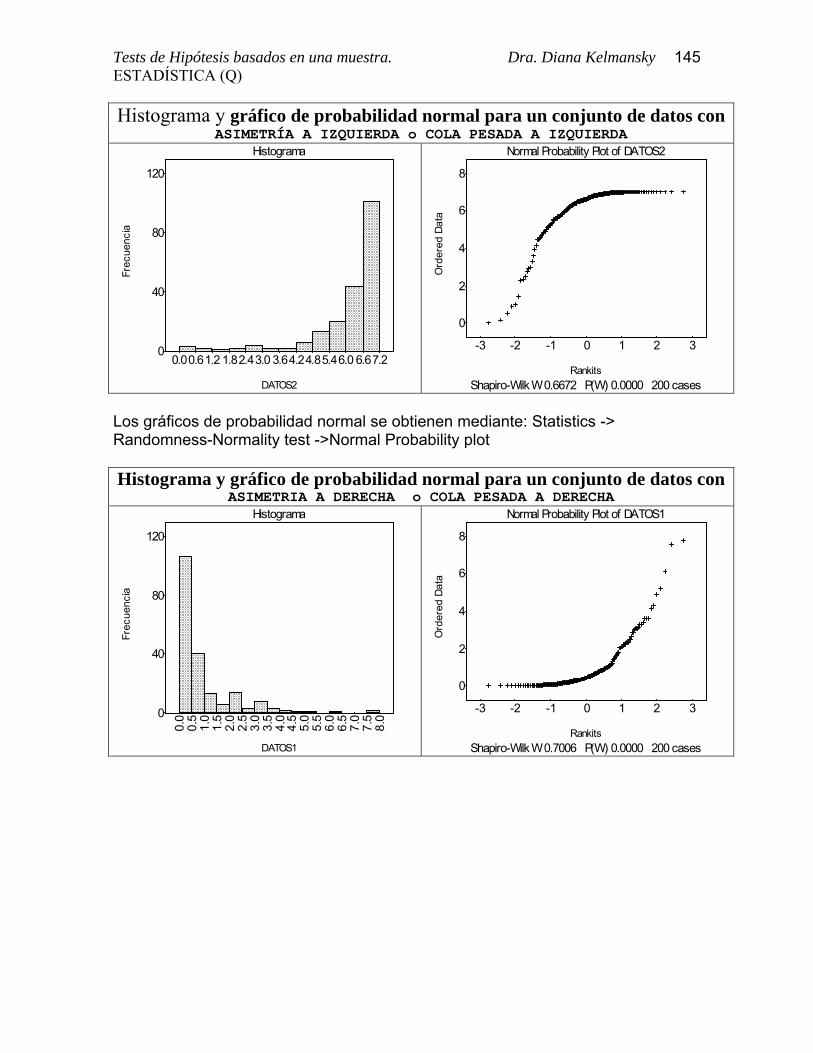
Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 145ESTADÍSTICA (Q) Histograma y gráfico de probabilidad normal para un conjunto de datos con
ASIMETRÍA A IZQUIERDA o COLA PESADA A IZQUIERDA
0.00.61.2 1.82.43.0 3.64.24.85.46.0 6.67.20
40
80
120
Histograma
Frec
uenc
ia
DATOS2
-3 -2 -1 0 1 2 3
0
2
4
6
8
Normal Probability Plot of DATOS2
Ord
ered
Dat
a
RankitsShapiro-Wilk W 0.6672 P(W) 0.0000 200 cases
Los gráficos de probabilidad normal se obtienen mediante: Statistics -> Randomness-Normality test ->Normal Probability plot Histograma y gráfico de probabilidad normal para un conjunto de datos con
ASIMETRIA A DERECHA o COLA PESADA A DERECHA
0.0
0.5
1.0
1.5
2.0
2.5
3.0
3.5
4.0
4.5
5.0
5.5
6.0
6.5
7.0
7.5
8.00
40
80
120
Histograma
Frec
uenc
ia
DATOS1
-3 -2 -1 0 1 2 3
0
2
4
6
8
Normal Probability Plot of DATOS1
Ord
ered
Dat
a
RankitsShapiro-Wilk W 0.7006 P(W) 0.0000 200 cases

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 146ESTADÍSTICA (Q) Histograma y gráfico de probabilidad normal para un conjunto de datos con
COLAS LIVIANAS o COLAS CORTAS
0.02
0.09
0.16
0.23
0.30
0.37
0.44
0.51
0.58
0.65
0.72
0.79
0.86
0.93
1.00
0
5
10
15
Histograma
Frec
uenc
ia
DATOS3120 casos
-3 -2 -1 0 1 2 3
0.0
0.2
0.4
0.6
0.8
1.0
Normal Probability Plot of DATOS3
Ord
ered
Dat
a
RankitsShapiro-Wilk W 0.9495 P(W) 0.0002 120 cases
Test de Shapiro-Wilk Las hipótesis del test son: H0: la variable tiene distribución normal (con cualquier media y varianza) Ha: la variable no tiene distribución normal El estadístico del test puede interpretarse como una medida de la asociación lineal entre los percentiles observados en la muestra y los percentiles teóricos de la normal que muestra el gráfico de probabilidad normal. El Statistix muestra el valor del estadístico del test y el correspondiente p-valor en el q-q plot. También se lo obtiene del siguiente modo:
Statistics -> Randomness-Normality test
-> Shapiro-Wilk Normality test
Para los datos correspondientes a las 5 determinaciones de la concentración de CO obtenemos
SHAPIRO-WILK NORMALITY TEST
VARIABLE N W P --------- ----- ------- ------- CONC 5 0.9752 0.9074

Tests de Hipótesis basados en una muestra. Dra. Diana Kelmansky 147ESTADÍSTICA (Q) Conclusión: El p-valor = 0.9074 (> 0.05) es altísimo. No hay evidencia suficiente para rechazar la hipótesis de que la distribución de la concentración de CO es normal. Cuanto mayor sea el p-valor tanto mayor será la evidencia a favor de la hipótesis nula.












![TESTS DE BONDAD DE AJUSTE PARA LA DISTRIBUCION´ … · 2018. 9. 3. · arXiv:1808.10777v1 [stat.ME] 30 Aug 2018 TESTS DE BONDAD DE AJUSTE PARA LA DISTRIBUCION´ POISSON BIVARIANTE](https://static.fdocuments.in/doc/165x107/6087ac142132ed0e5b15f98c/tests-de-bondad-de-ajuste-para-la-distribucion-2018-9-3-arxiv180810777v1.jpg)





