
1 Fault Tolerance Chapter 7. 2 Fault Tolerance An important goal in distributed systems design is to...
39
1 Fault Tolerance Chapter 7
-
date post
21-Dec-2015 -
Category
Documents
-
view
213 -
download
0
Transcript of 1 Fault Tolerance Chapter 7. 2 Fault Tolerance An important goal in distributed systems design is to...

1
Fault Tolerance
Chapter 7

2
Fault Tolerance
• An important goal in distributed systems design is to construct the system in such a way that it can automatically recover from partial failure without seriously affecting the overall performance.
• A distributed system should tolerate faults and continue to operate to some extent even in their presence.

3
Basic Concepts
• The essence of a fault tolerant system is a dependable system. Dependability Includes:– Availability: a system is ready to be used
immediately. – Reliability: a system can run continuously
without failure. – Safety: when a system temporarily fails to
operate, nothing catastrophic happens.– Maintainability: how easy a failed system can
be repaired.

4
Basic Concepts• A system is said to fail when it cannot meet its promises.
• An error is a part of a system’s state that may lead to a failure.
• The cause of an error is a fault.
• Fault tolerance means that a system can provide its services even in the presence of faults.
• A transient fault occurs once and then disappears.
• An intermittent fault occurs, then vanishes of its own accord, then reappears, and so on.
• A permanent fault is one that continues to exist unitl the faulty component is repaired.

5
Failure Models
Different types of failures.
Type of failure Description
Crash failure A server halts, but is working correctly until it halts
Omission failure Receive omission Send omission
A server fails to respond to incoming requestsA server fails to receive incoming messagesA server fails to send messages
Timing failure A server's response lies outside the specified time interval
Response failure Value failure State transition failure
The server's response is incorrectThe value of the response is wrongThe server deviates from the correct flow of control
Arbitrary failure A server may produce arbitrary responses at arbitrary times

6
Failure Model
• The most serious failures are arbitrary failures, also known as Byzantine failures.
• Crash failures are also referred to as fail-stop failures.
• Fail-silent systems are systems which do not announce they are going to stop.
• A server is producing random output recognized by other processes as plain junk. These faults are referred to as being fail-safe.

7
Failure masking by redundancy
• The key technique for masking faults is to use redundancy.
• With information redundancy, extra bits are added to allow recovery from garbled bits (e.g. Hamming code).
• With time redundancy, an action is performed, and then, if needed, it is performed again (e.g., message retransmission, transaction restart).
• With physical redundancy, extra equipment or processes are added to make it possible for the system as a whole to tolerate the loss or malfunctioning of some components.

8
Failure masking by redundancy
• A TMR (Triple Modular Redundancy) is a design in which– Each device is replicated 3 times.– Following each stage in the circuit is a triplicated
voter.– Each voter is a circuit that has three inputs and one
output.– If two or three of the inputs are the same, the output
is equal to that input. If all three inputs are different, the out is undefined.

9
Failure Masking by Redundancy
Triple modular redundancy.

10
Flat Groups versus Hierarchical Groups
a) Communication in a flat group.b) Communication in a simple hierarchical group

11
Agreement in Faulty Systems
• The Byzantine generals problem for 3 loyal generals and 1 traitor.
a) The generals announce their troop strengths (in units of 1 kilosoldiers).
b) The vectors that each general assembles based on (a)c) The vectors that each general receives in step 3.

12
Agreement in Faulty Systems
• The same as in previous slide, except now with 2 loyal generals and one traitor.
• In general, a system with m faulty processes, agreement can be achieved only if 2m + 1 correctly functioning processes are present, for a total of 3m + 1.

13
Reliable client-server communication • Point-to-point communication
– Omission failures occur in the form of lost message, and can be masked by using acknowledgements and retransmissions.
– Connection crash failures are often not masked. The client can be informed of the channel crash by raising an exception.
• RPC semantics in the presence of failures1. The client is unable to locate the server.2. The request message from the client to the server is lost.3. The server crashes after receiving a request.4. The reply message from the server to the client is lost.5. The client crashes after sending a request.

14
The client is unable to locate the server
• A possible cause: obsolete client stub which does not match the current server skeleton.
• A possible solution: raise an exception or signal to the client.
• Drawbacks of the solution:1. Not every language has exceptions or signals.
2. Requiring the programmer to write an exception or signal handler destroys the transparency.

15
Lost Request and Reply Messages
• The Solution: retransmission (using timer and sequence number)
• If multiple retransmissions are lost, the client gives up and falsely concludes that the server is down (back to the “Cannot locate server” problem).

16
Server Crashes
A server in client-server communication
a) Normal case
b) Crash after execution
c) Crash before execution
The problem is that the client cannot differentiate case b) from case c).

17
Server Crashes
Different combinations of client and server strategies in the presence of server crashes.
Client Server
Strategy M -> P Strategy P -> M
Reissue strategy MPC MC(P) C(MP) PMC PC(M) C(PM)
Always DUP OK OK DUP DUP OK
Never OK ZERO ZERO OK OK ZERO
Only when ACKed DUP OK ZERO DUP OK ZERO
Only when not ACKed OK ZERO OK OK DUP OK
Possible RPC semantics: (1) at least once; (2) at most once; (3) no guarantee (the easiest to implement); and (4) exact once (impossible to implement, as explained below).

18
Client Crashes• What happens if the client sends a request to a server to do
some work and crashes before the server replies? The left server computation is called orphan, which wastes CPU cycles, ties up system resources, and causes confusion.
• Possible solutions to the orphan problem:1. Extermination: before send an RPC message, makes a log entry in the
disk. After rebooting the client, the log is checked and the orphan is explicitly killed off.
2. Reincarnation: divide time into sequentially numbered epochs. When a client reboots, it broadcasts a message to declare a new epoch. After receiving such a message, all remote computations for that client are killed off.
3. 3. Gentle reincarnation: when an epoch comes in, a remote computation is killed only if its own cannot be contacted.
4. Expiration: each RPC is given a standard amount of time T to do the job. If it cannot finish, it must ask for another quantum from the client. If the client crashed and rebooted after waiting a time T, all orphans are sure to be gone.
19
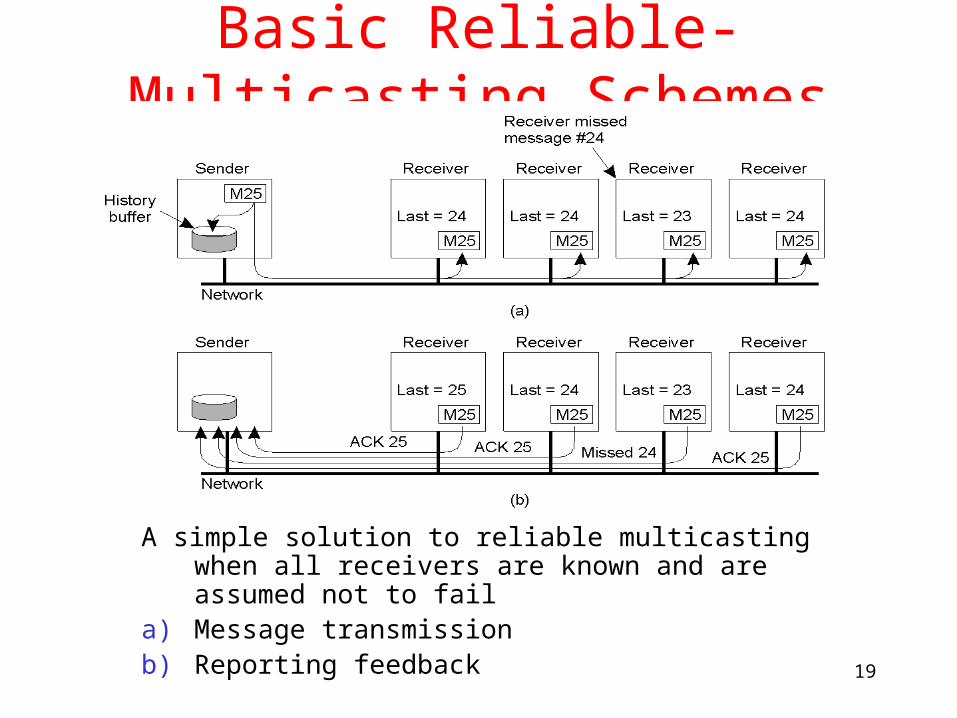
Basic Reliable-Multicasting Schemes
A simple solution to reliable multicasting when all receivers are known and are assumed not to fail
a) Message transmissionb) Reporting feedback

20
Nonhierarchical Feedback Control
Several receivers have scheduled a request for retransmission, but the first retransmission request
leads to the suppression of others.
21
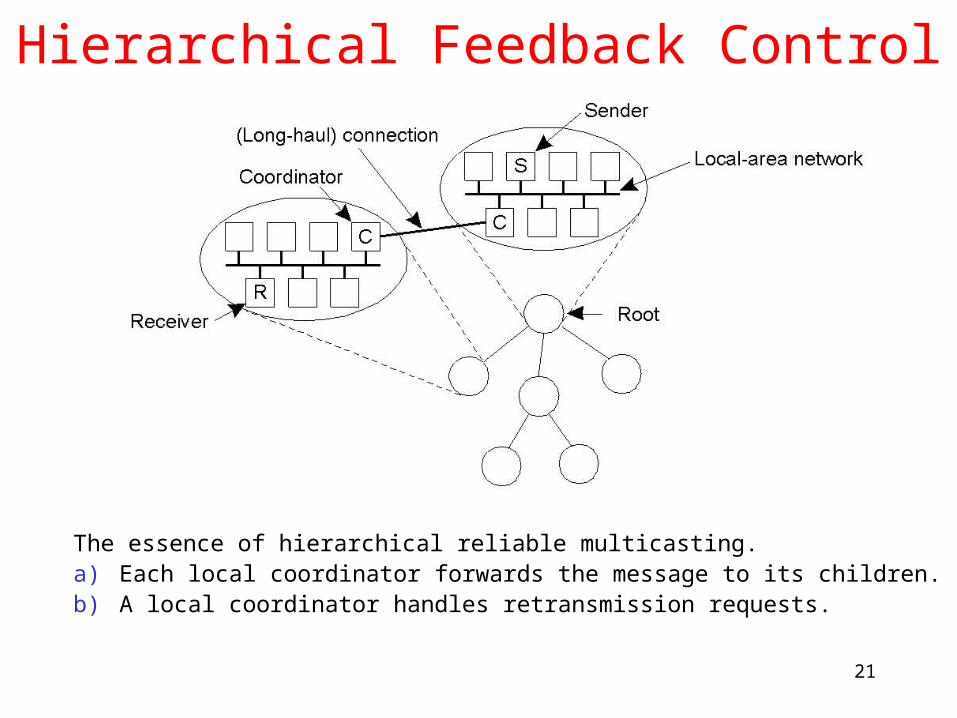
Hierarchical Feedback Control
The essence of hierarchical reliable multicasting.a) Each local coordinator forwards the message to its children.b) A local coordinator handles retransmission requests.

22
Virtual Synchrony
The logical organization of a distributed system to distinguish between message receipt and message delivery

23
Virtual Synchrony
The principle of virtual synchronous multicast.

24
Message Ordering
Unordered multicasts
Three communicating processes in the same group. The ordering of events per process is shown along
the vertical axis.
Process P1 Process P2 Process P3
sends m1 receives m1 receives m2
sends m2 receives m2 receives m1

25
Message Ordering
FIFO-ordered multicasts
Four processes in the same group with two different senders, and a possible delivery order of messages
under FIFO-ordered multicasting
Process P1 Process P2 Process P3 Process P4
sends m1 receives m1 receives m3 sends m3
sends m2 receives m3 receives m1 sends m4
receives m2 receives m2
receives m4 receives m4

26
Implementing Virtual Synchrony
Six different versions of virtually synchronous reliable multicasting.
Multicast Basic Message Ordering Total-ordered Delivery?
Reliable multicast None No
FIFO multicast FIFO-ordered delivery No
Causal multicast Causal-ordered delivery No
Atomic multicast None Yes
FIFO atomic multicast FIFO-ordered delivery Yes
Causal atomic multicast Causal-ordered delivery Yes
27
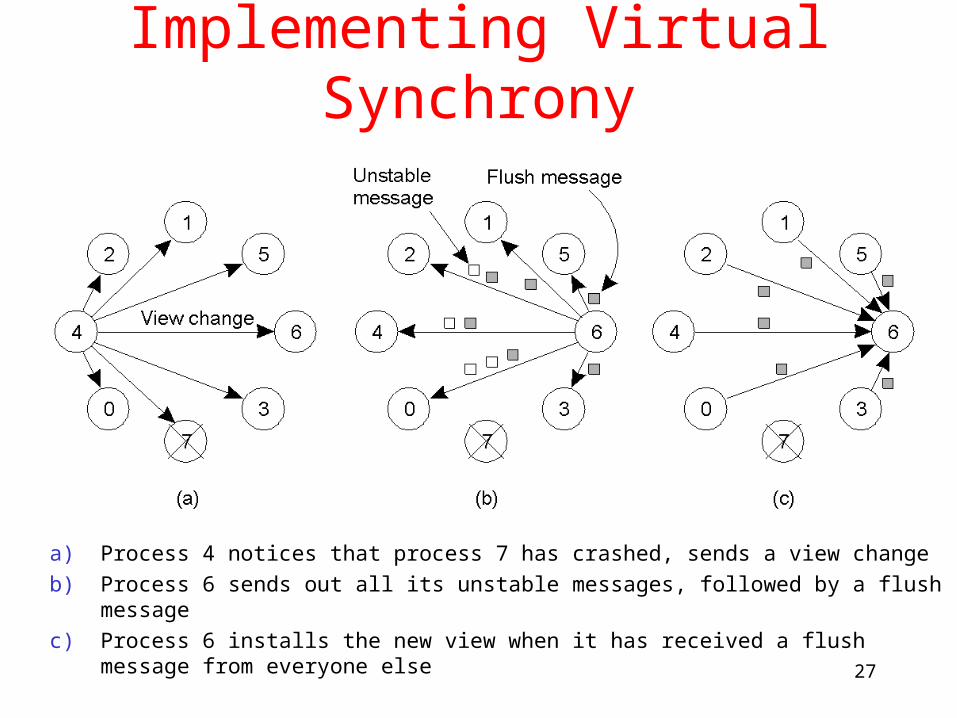
Implementing Virtual Synchrony
a) Process 4 notices that process 7 has crashed, sends a view change
b) Process 6 sends out all its unstable messages, followed by a flush message
c) Process 6 installs the new view when it has received a flush message from everyone else

28
Two-Phase CommitPhase I (Voting):
1. The coordinator sends a VOTE_REQUEST message to all participants.
2. When a participant receives a VOTE_REQUEST message, it returns either a VOTE_COMMIT message to the coordinator telling the coordinator that it is prepared to locally commit its part of the transaction, or otherwise a VOTE_ABORT message.
Phase II (Decision):1. The coordinator collects all votes from the participants. If all have
voted to commit, then so will the coordinator. In that case, it sends a GLOBAL_COMMIT message to all participants. However, if one participant had voted to abort the transaction, the coordinator will also decide to abort and multicast a GLOBAL_ABORT message.
2. Each participant that voted for a commit waits for the final reaction from the coordinator. If a participant receives a GLOBAL_COMMIT , it locally commits the transaction. Otherwise, when receiving a GLOBAL_ABORT, it locally aborts the transaction as well.
29
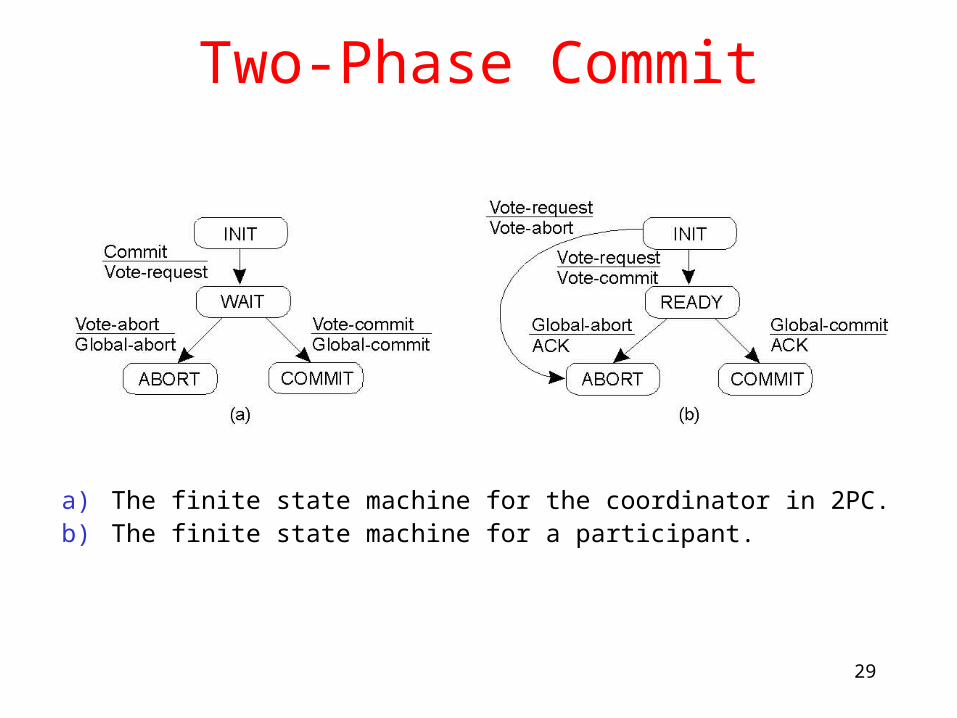
Two-Phase Commit
a) The finite state machine for the coordinator in 2PC.b) The finite state machine for a participant.

30
Two-Phase Commit
Actions taken by a participant P when residing in state READY and having contacted another participant Q.
State of Q Action by P
COMMIT Make transition to COMMIT
ABORT Make transition to ABORT
INIT Make transition to ABORT
READY Contact another participant

31
Two-Phase Commit
Outline of the steps taken by the coordinator in a two phase commit protocol
actions by coordinator:
write START _2PC to local log;multicast VOTE_REQUEST to all participants;while not all votes have been collected { wait for any incoming vote; if timeout { write GLOBAL_ABORT to local log; multicast GLOBAL_ABORT to all participants; exit; } record vote;}if all participants sent VOTE_COMMIT and coordinator votes COMMIT{ write GLOBAL_COMMIT to local log; multicast GLOBAL_COMMIT to all participants;} else { write GLOBAL_ABORT to local log; multicast GLOBAL_ABORT to all participants;}

32
Two-Phase Commit
Steps taken by participant process in
2PC.
actions by participant (the main thread):
write INIT to local log;wait for VOTE_REQUEST from coordinator;if timeout { write VOTE_ABORT to local log; exit;}if participant votes COMMIT { write VOTE_COMMIT to local log; send VOTE_COMMIT to coordinator; wait for DECISION from coordinator; if timeout { multicast DECISION_REQUEST to other participants; wait until DECISION is received; /* remain blocked */ write DECISION to local log; } if DECISION == GLOBAL_COMMIT write GLOBAL_COMMIT to local log; else if DECISION == GLOBAL_ABORT write GLOBAL_ABORT to local log;} else { write VOTE_ABORT to local log; send VOTE ABORT to coordinator;}

33
Two-Phase Commit
Steps taken for handling incoming decision requests.
actions for handling decision requests: /* executed by separate thread */
while true { wait until any incoming DECISION_REQUEST is received; /* remain blocked */ read most recently recorded STATE from the local log; if STATE == GLOBAL_COMMIT send GLOBAL_COMMIT to requesting participant; else if STATE == INIT or STATE == GLOBAL_ABORT send GLOBAL_ABORT to requesting participant; else skip; /* participant remains blocked */
34
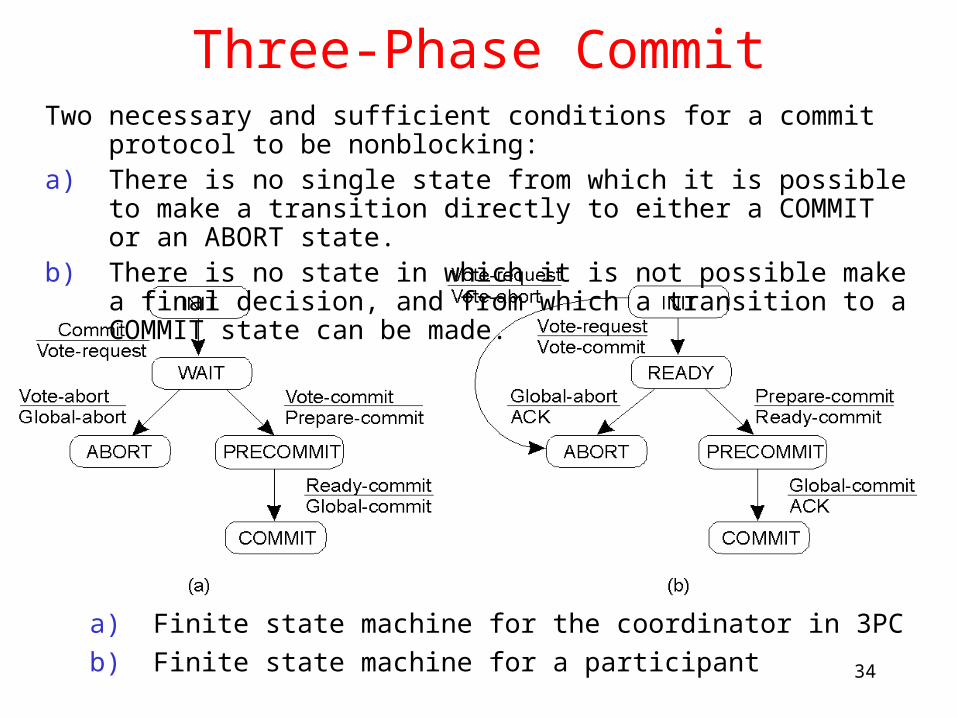
Three-Phase Commit
a) Finite state machine for the coordinator in 3PC
b) Finite state machine for a participant
Two necessary and sufficient conditions for a commit protocol to be nonblocking:
a) There is no single state from which it is possible to make a transition directly to either a COMMIT or an ABORT state.
b) There is no state in which it is not possible make a final decision, and from which a transition to a COMMIT state can be made.

35
Recovery
Two forms of error recovery:a) Backward recovery: bring the system from its present
erroneous state back into a previously correct state. It is necessary to record the system’s state from time to time (by state checkpointing and message logging). E.g., lost message retransmission.
b) Forward recovery: bring the system from its present erroneous state forward to a correct new state from which it can continue to execute. It has to know in advance which errors may occur. E.g., error correction by special encoding of messages.
Backward recovery is the most widely used error recovery technique due to its generality, but it also has the following drawbacks:
• Checkpointing is costly in terms of performance.• Not all errors are reversible.

36
Recovery Stable Storage
a) Stable Storageb) Crash after drive 1 is updatedc) Bad spot

37
Checkpointing
A recovery line.

38
Independent Checkpointing
The domino effect.

39
Message Logging
Incorrect replay of messages after recovery, leading to an orphan process.


















