
Fault Tolerance In Mesos - Schedschd.ws/hosted_files/mesosconeu2016/d6/Fault Tolerance In...
38
Transcript of Fault Tolerance In Mesos - Schedschd.ws/hosted_files/mesosconeu2016/d6/Fault Tolerance In...

A n a n d M a z u m d a r ( a n a n d @ m e s o s p h e r e . i o )
V i n o d K o n e ( v i n o d @ m e s o s p h e r e . i o )
Fault Tolerance In

M U R P H Y ’ S L A W F O R D I S T R I B U T E D S Y S T E M S
“Anything that can go wrong will go wrong…partially”
Software
Hardware
Network
Humans!

• Availability
• Reliability
• Safety
• Maintainability
Distributed Systems Principles and Paradigms Tanenbaum et al
W H A T D O E S B E I N G FA U LT T O L E R A N T M E A N ?
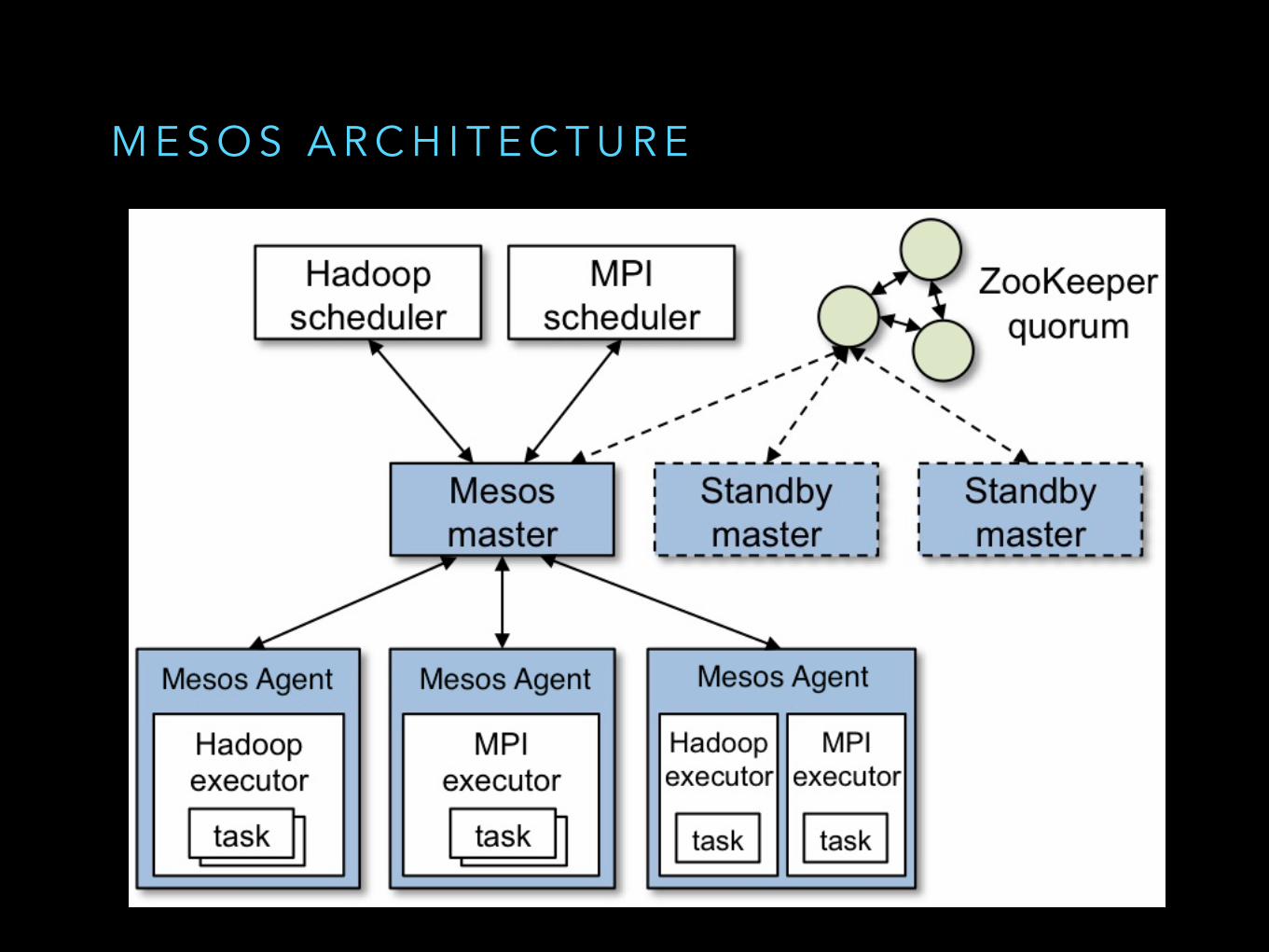
M E S O S A R C H I T E C T U R E
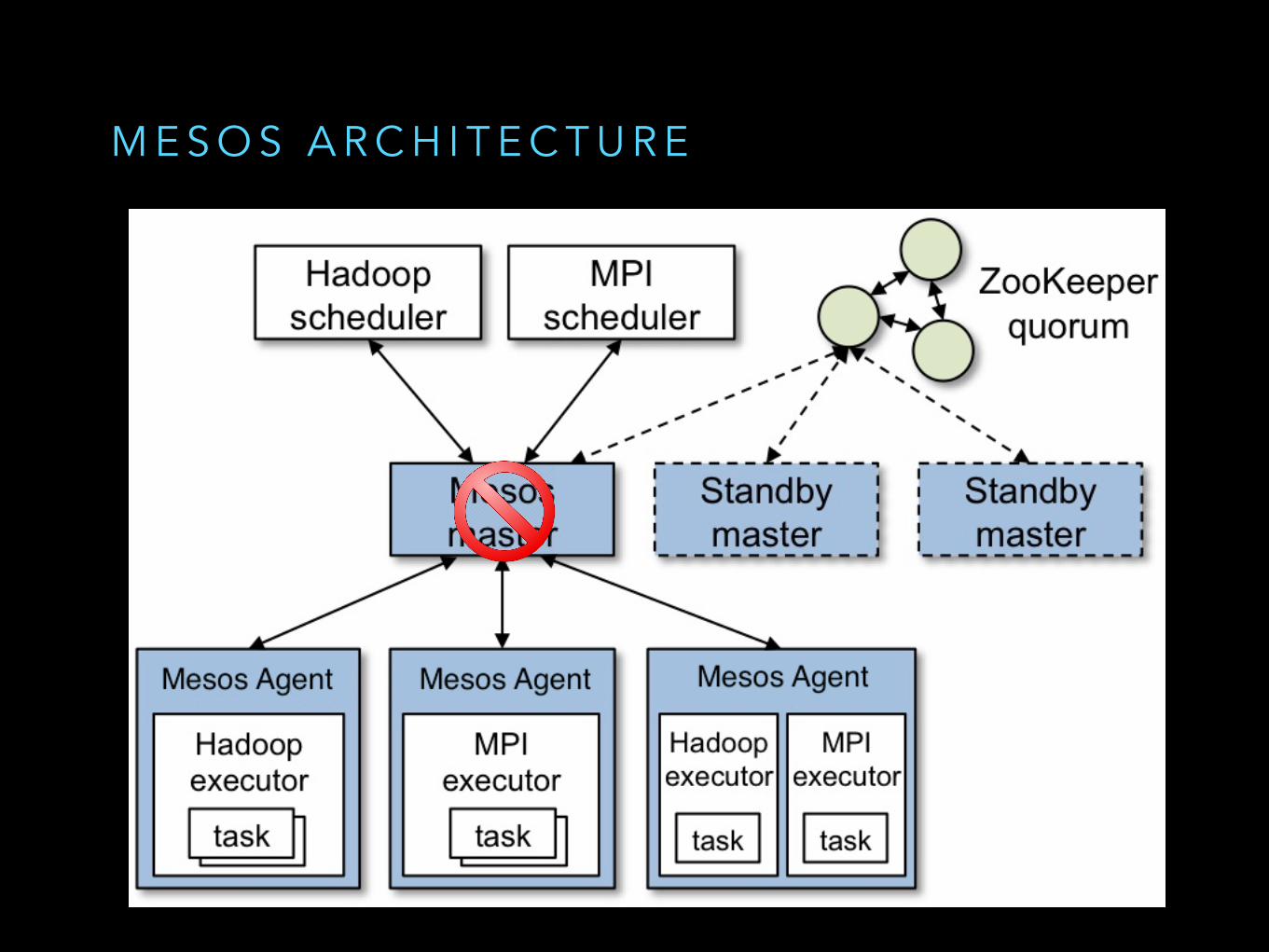
M E S O S A R C H I T E C T U R E
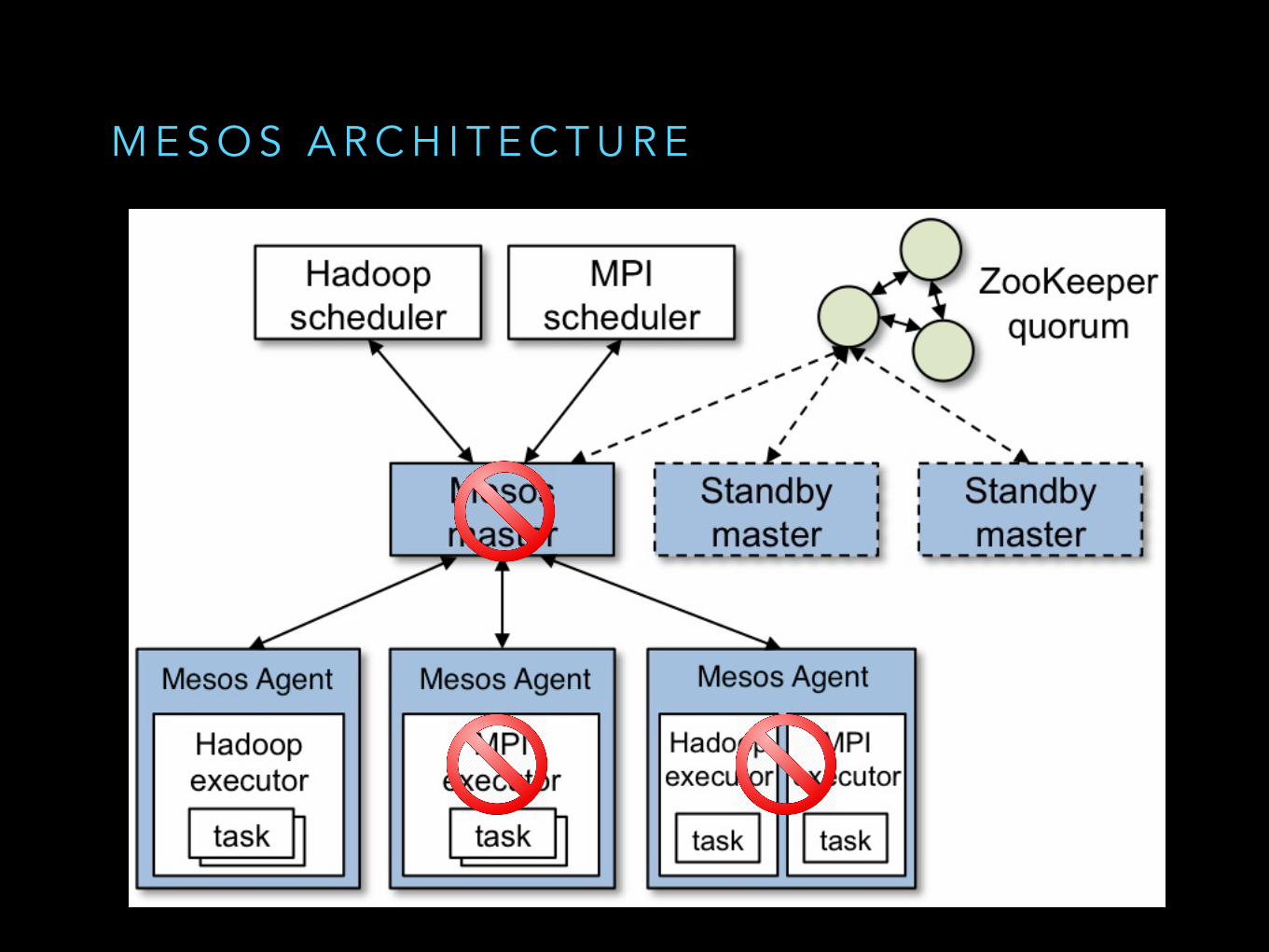
M E S O S A R C H I T E C T U R E

M E S O S A R C H I T E C T U R E

L O T S O F P O S S I B L E FA I L U R E S C E N A R I O S

T H I N G S T O K E E P I N M I N D W H E N B U I L D I N G FA U LT T O L E R A N T S Y S T E M S


T H I N K B E F O R E Y O U C O D E
• No matter what language you are using, designing is independent of the coding process
“Success really depends on the conception of problems, the design of the system, not on the details of
how it's coated.” - Lamport
• Thinking about simplicity is equally important to strive for as Computational Complexity
“You're not to come up with a simple design through any kind of coding techniques or any kind of programming language concepts. Simplicity
has to be achieved above the code level before you get to the point which you worry about how you actually implement this thing in code.”
- Lamport

P I C K Y O U R B A T T L E S
• As programmers, we love solving problems. But, why bother solving them when someone else has already done it for us
• In Distributed Systems, everything is a tradeoff:
• Impossibility results/Theorems are your best friend e.g., FLP Result, Two Generals Problem, CAP Theorem

FA I L FA S T P H I L O S O P H Y
In systems design, a fail-fast system is one which immediately reports at its interface any condition that is likely to indicate a failure. Fail-fast systems are usually designed to stop normal operation rather than attempt to continue a possibly flawed
process. - Wikipedia
• This is an anti-pattern to what we have been taught as programmers from Day 0 i.e. to handle all failures in our code
• If you want to build a layered fault tolerant system, then your building blocks must have very precise failure semantics
• A fail-fast module passes the responsibility for handling errors, but not detecting them, to the next-highest level of the system

FA I L FA S T P H I L O S O P H Y

FA U LT D E T E C T I O N
“The first step in solving any problem is recognizing there is one.”
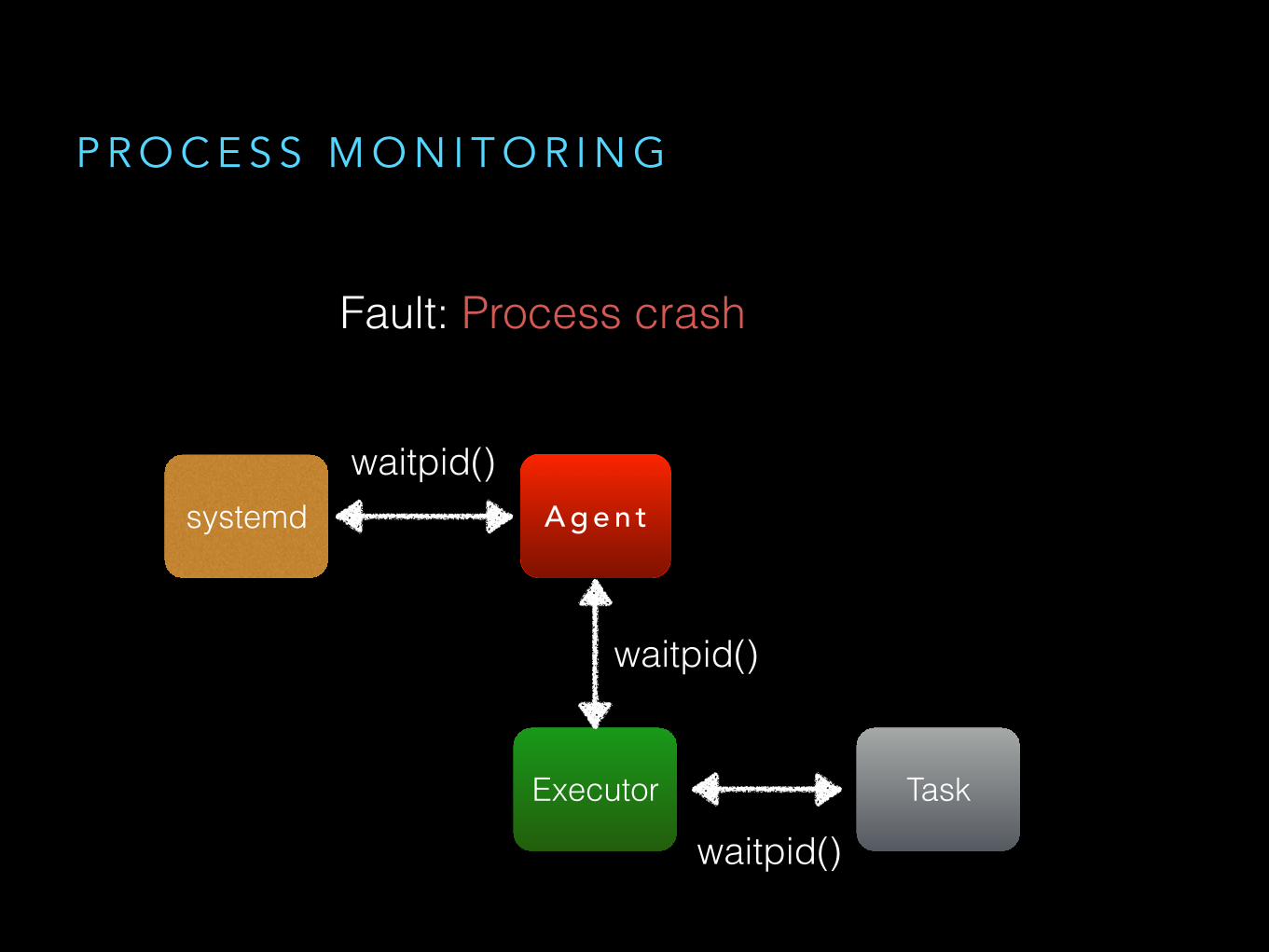
P R O C E S S M O N I T O R I N G
Fault: Process crash
A g e n t
Executor
waitpid()
systemd
Task
waitpid()
waitpid()
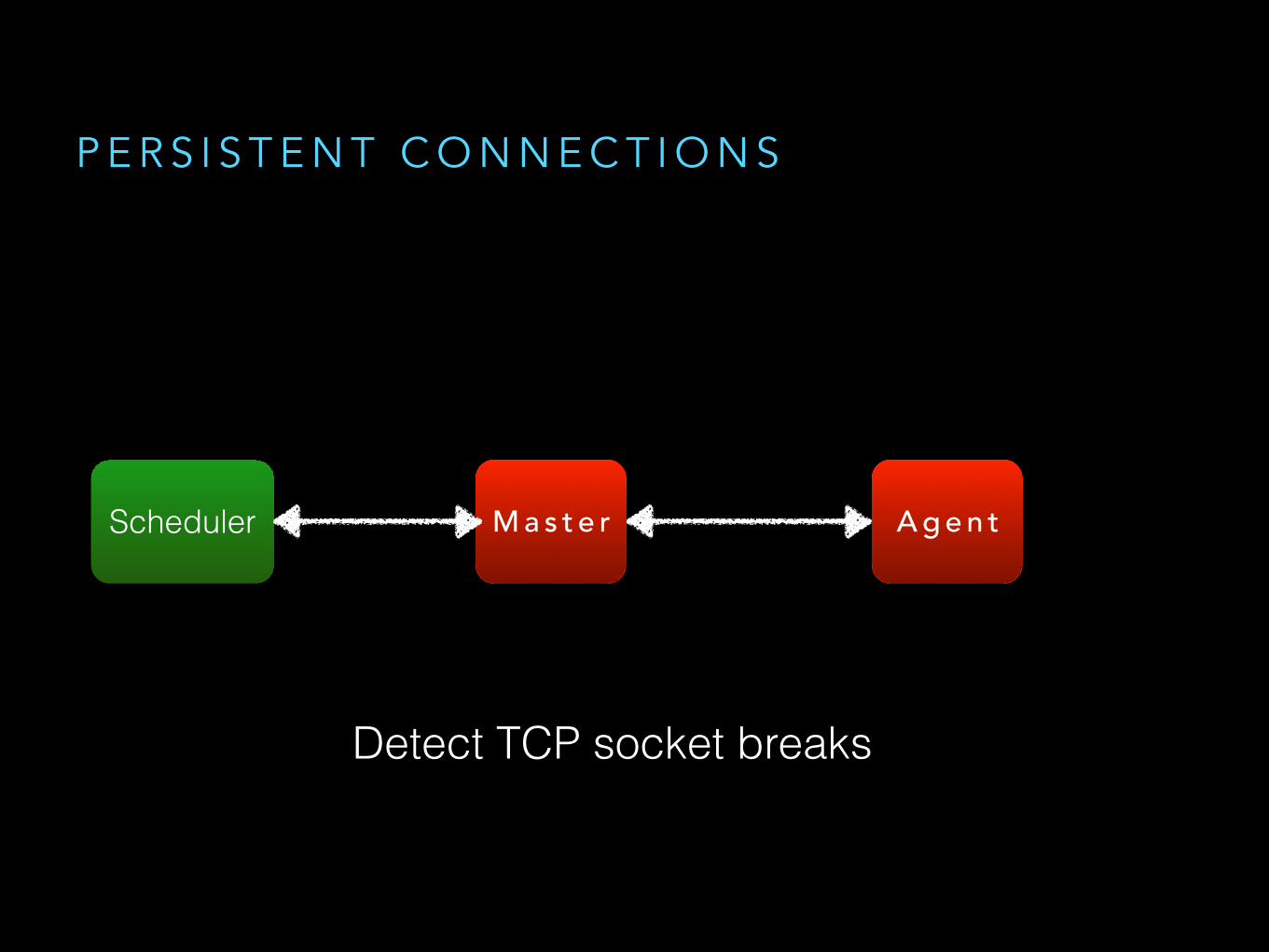
P E R S I S T E N T C O N N E C T I O N S
A g e n tM a s t e r
Detect TCP socket breaks
Scheduler
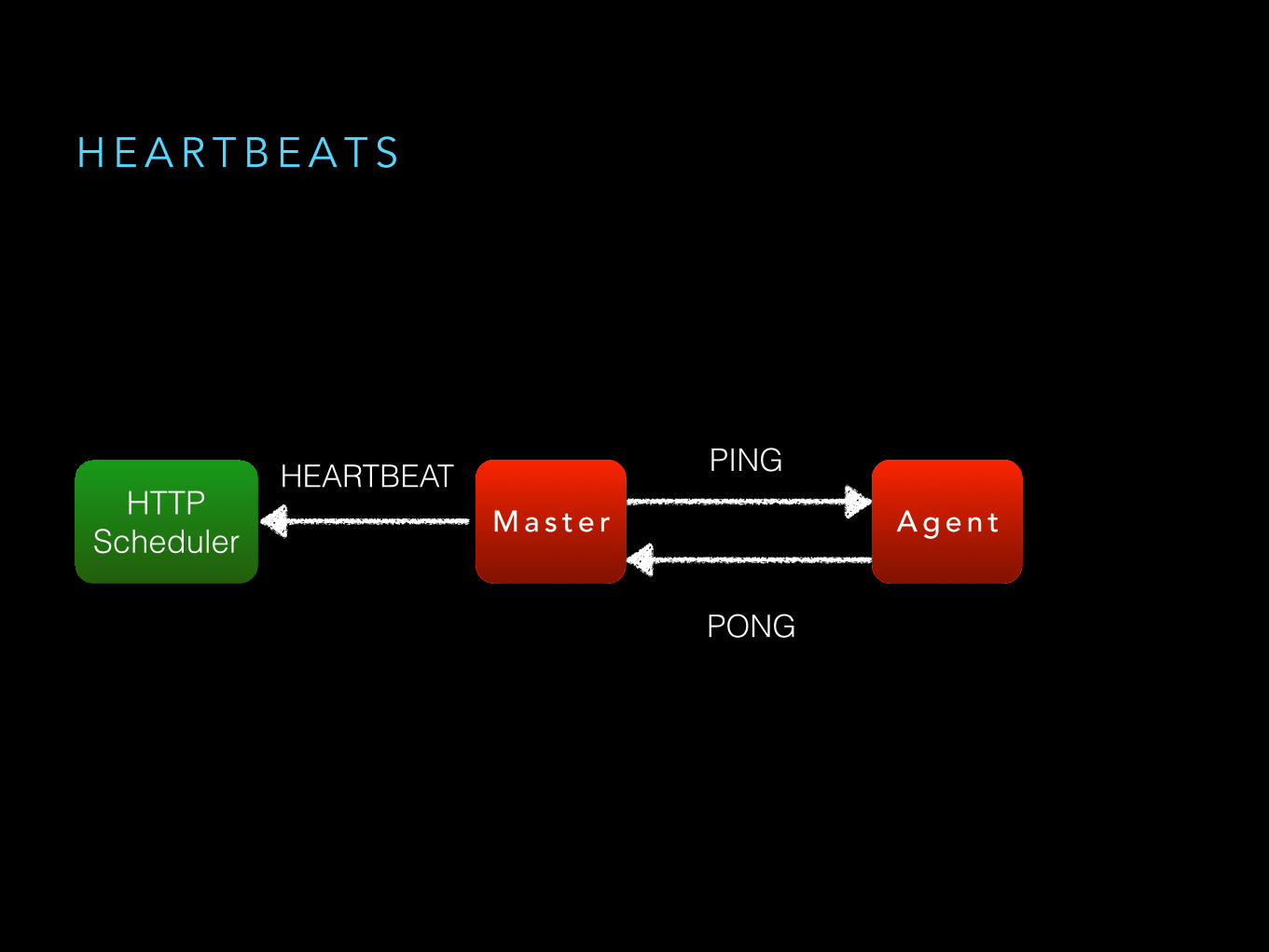
H E A R T B E A T S
A g e n tM a s t e rHTTP Scheduler
PING
PONG
HEARTBEAT

• Hard to tell the difference between
• Process/Node failures
• Network failures
• Mesos treats both the same
L I M I TA T I O N S

A VA I L A B I L I T Y

• Run masters and agents under a supervisor
• systemd, upstart, monitd etc
• Restart on failure
• Recommended for schedulers
• Leverage a meta scheduler (e.g, marathon)
A U T O R E S TA R T
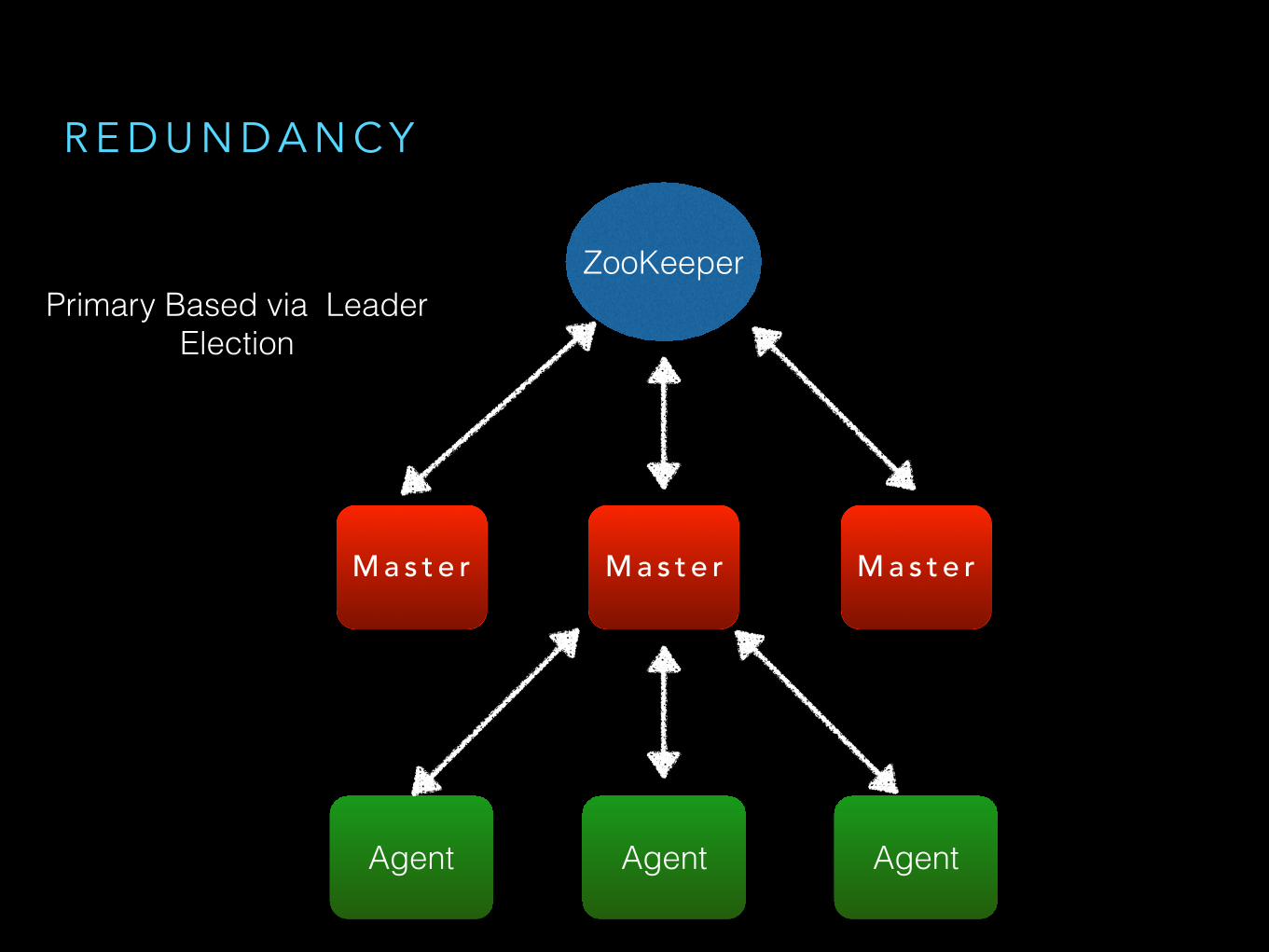
R E D U N D A N C Y
M a s t e r M a s t e r M a s t e r
ZooKeeperPrimary Based via Leader
Election
Agent Agent Agent

R E P L I C A T E D L O G
M a s t e r M a s t e r M a s t e r
Runs Paxos to ensure replicas agree on the value
Log Replica Log Replica Log Replica

• Replicated persistent state
• List of Agents
• Maintenance Schedules
• Quota
• Exposed as a library for frameworks
R E P L I C A T E D L O G

• Tasks and Executors can stay up even if agent process crashes!
• Agent checkpoints and recovery state to/from local disk
• TaskInfo, Status Updates, PID etc
A G E N T R E C O V E R Y

• ZooKeeper(s) can go down
• Master(s) can go down
• Agent(s) can go down
• Scheduler(s) can go down
H I G H LY A VA I L A B L E

R E L I A B I L I T Y

• Exactly-one semantics is hard and impossible without coordination!
• You need to build up your own application logic to get around communication failures
R E L I A B L E C O M M U N I C A T I O N
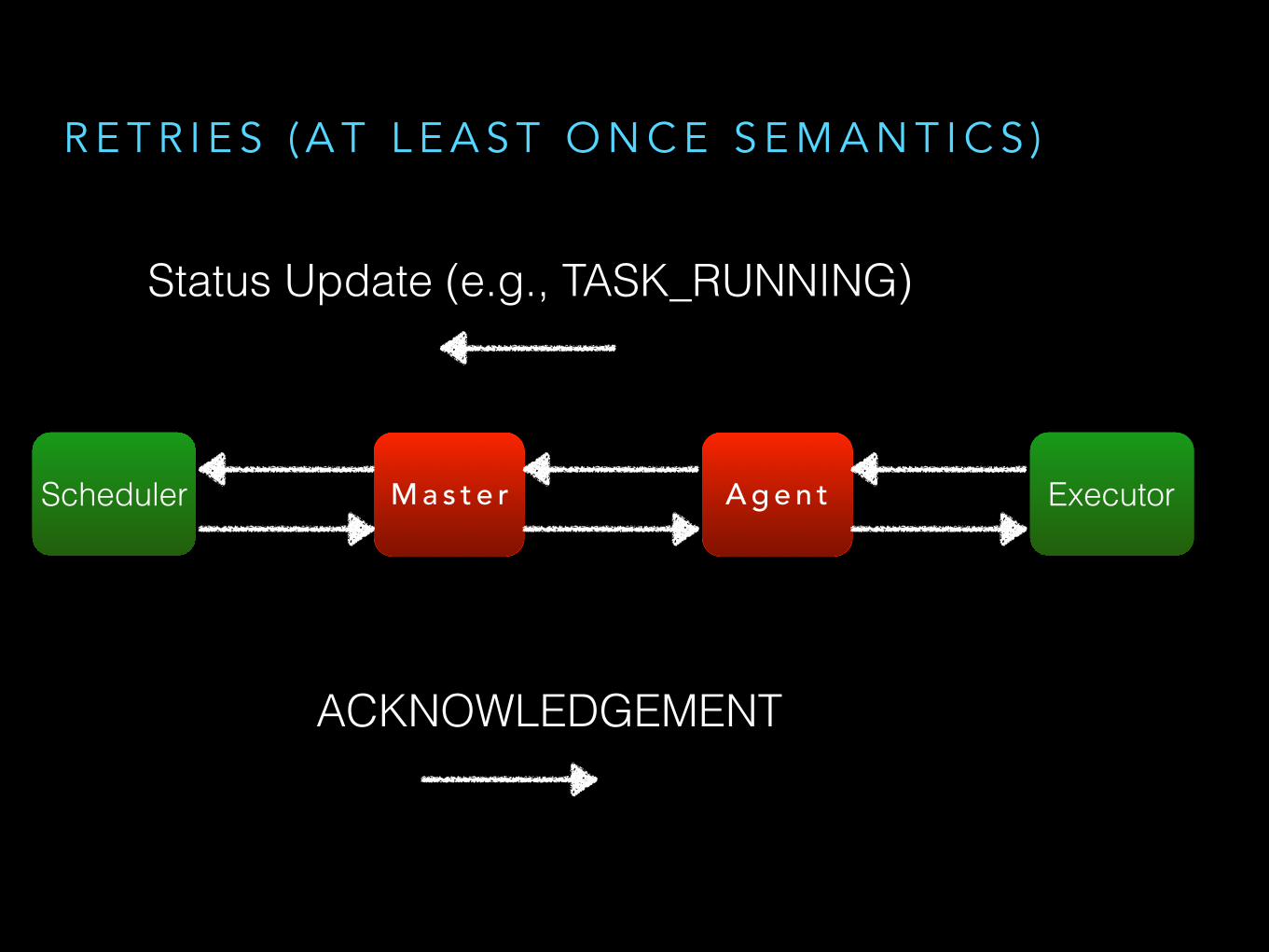
R E T R I E S ( A T L E A S T O N C E S E M A N T I C S )
M a s t e r A g e n tScheduler Executor
Status Update (e.g., TASK_RUNNING)
ACKNOWLEDGEMENT
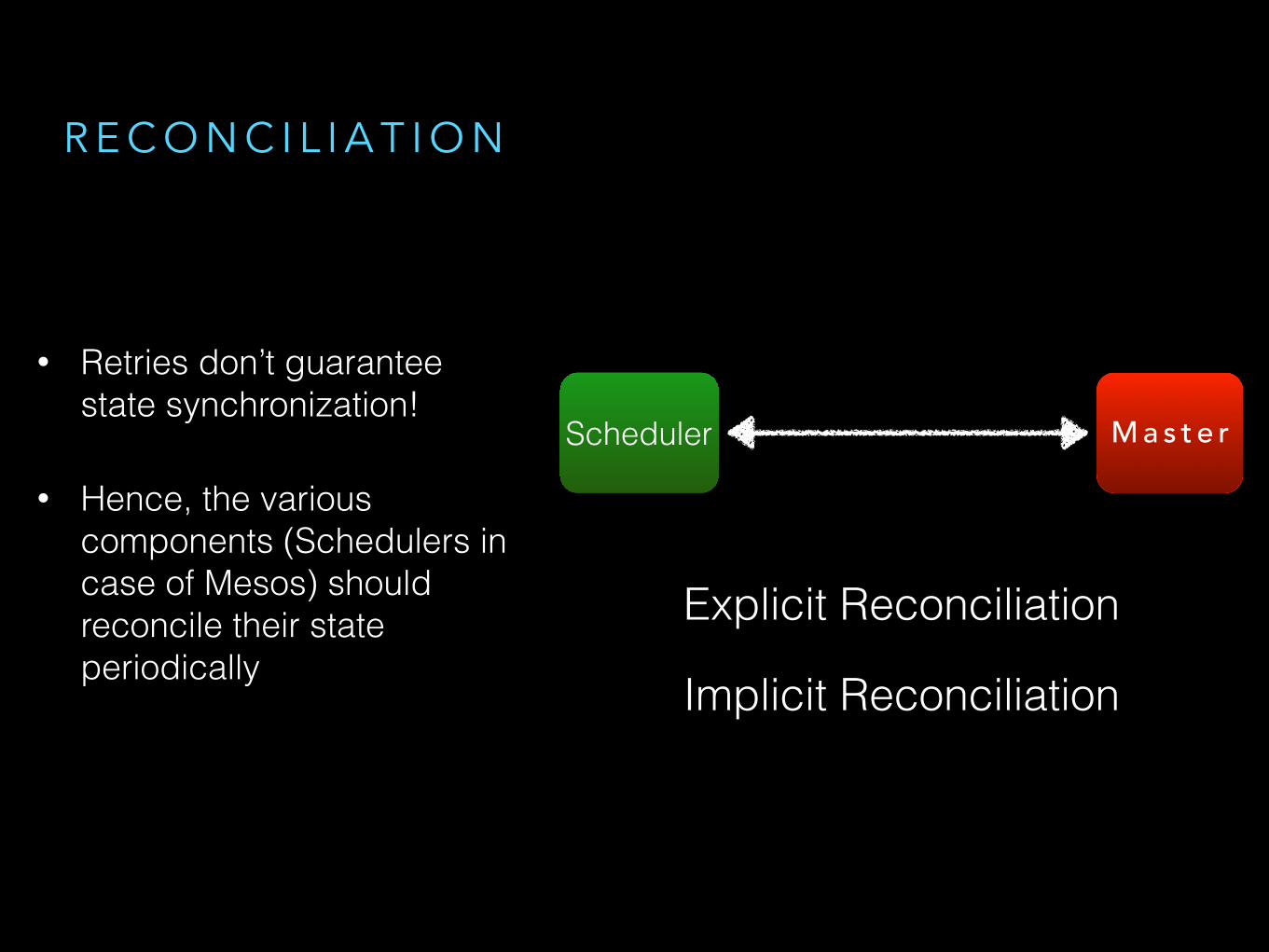
R E C O N C I L I A T I O N
M a s t e rScheduler
Explicit Reconciliation
Implicit Reconciliation
• Retries don’t guarantee state synchronization!
• Hence, the various components (Schedulers in case of Mesos) should reconcile their state periodically

S A F E T Y
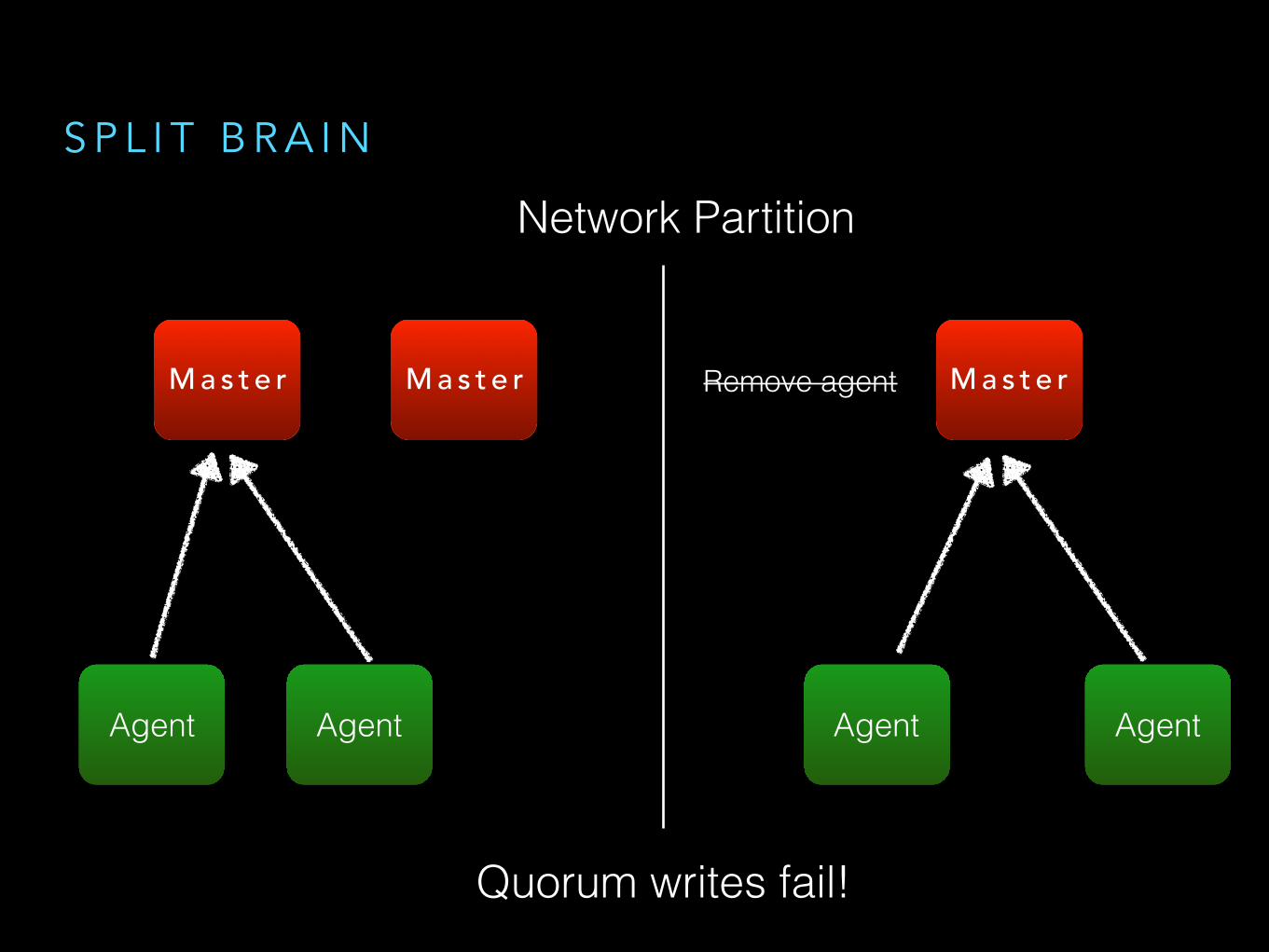
S P L I T B R A I N
M a s t e r M a s t e r M a s t e r
Agent Agent Agent Agent
Network Partition
Quorum writes fail!
Remove agent

• Agent configuration changes disallowed
• IP, hostname, attributes, resources
• Might be smarter in the future
• e.g., resources “increase” is allowed
A G E N T S TA T E C H A N G E S

M A I N TA I N A B I L I T Y

• Easy to add/remove agents
• Zero downtime upgrades
• Maintenance primitives
U P D A T E S A N D U P G R A D E S

• Building fault tolerant distributed systems is hard
• Partial failures!
• Design for failures
• Understand the trade offs
TA K E A W A Y S

THANK YOU

R E F E R E N C E S
• https://www.infoq.com/news/2014/10/ser-lamport-interview
• https://channel9.msdn.com/Events/Build/2014/3-642


















