
1 Algorithms for Large Data Sets Ziv Bar-Yossef Lecture 10 June 4, 2006 .
44
1 Algorithms for Large Data Sets Ziv Bar-Yossef Lecture 10 June 4, 2006 http://www.ee.technion.ac.il/cours es/049011
-
date post
21-Dec-2015 -
Category
Documents
-
view
220 -
download
0
Transcript of 1 Algorithms for Large Data Sets Ziv Bar-Yossef Lecture 10 June 4, 2006 .

1
Algorithms for Large Data Sets
Ziv Bar-YossefLecture 10
June 4, 2006
http://www.ee.technion.ac.il/courses/049011

2
Random Samplingof
Web Pages

3
Outline
Problem definition Random sampling of web pages according
to their PageRank Uniform sampling of web pages
(Henzinger et al) Uniform sampling of web pages (Bar-
Yossef et al)

4
Random Sampling of Web Pages W = a snapshot of the “indexable
web” Consider only “static” HTML web
pages
= a probability distribution over W
Goal: Design an efficient algorithm for generating samples from W distributed according to .
Our focus: = PageRank = Uniform
Indexable web

5
Random Sampling of Web Pages: Motivation Compute statistics about the web
Ex: What fraction of web pages belong to .il? Ex: What fraction of web pages are written in Chinese? Ex: What fraction of hyperlinks are advertisements?
Compare coverage of search engines Ex: Is Google larger than MSN? Ex: What is the overlap between Google and Yahoo?
Data mining of the web Ex: How frequently computer science pages cite
biology pages? Ex: How are pages distributed by topic?

6
Random Sampling of Web Pages: Challenges Naïve solution: crawl, index, sample
Crawls cannot get complete coverage Web is constantly changing Crawling is slow and expensive
Our goals: Accuracy: generate samples from a snapshot of the
entire indexable web Speed: samples should be generated quickly Low cost: sampling procedure should run on a desktop
PC

7
A Random Walk Approach
Design a random walk on W whose stationary distribution is P = Random walk’s probability transition matrix P =
Run random walk for sufficiently many steps Recall: For any initial distribution q, Mixing time: # of steps required to get close to the limit
Use reached node as a sample
Repeat for as many samples as needed

8
A Random Walk Approach:Advantages & Issues Advantages:
Accuracy: random walk can potentially visit every page on the web
Speed: no need to scan the whole web Low cost: no need for large storage or multiple
processors
Issues: How to design the random walk so it converges to ? How to analyze the mixing time of the random walk?

9
PageRank Sampling [Henzinger et al 1999]
Use the “random surfer” random walk:Start at some initial node v0
When visiting a page v Toss a coin with heads probability If coin is heads, go to a uniformly chosen page If coin is tails, go to a random out-neighbor of v
Limit distribution: PageRank Mixing time: fast (will see later)

10
PageRank Sampling:Reality Problem: how to pick a page uniformly at
random? Solutions:
Jump to a random page from the history of the walk
Creates bias towards dense web-sitesPick a random host from the hosts in the walk’s
history and jump to a random page from the pages visited on that host
Not converging to PageRank anymore Experiments indicate it is still fine

11
Uniform Sampling via PageRank Sampling [Henzinger et al 2000]
Sampling algorithm:1. Use previous random walk to generate a sample w
according to the PageRank distribution
2. Toss a coin with heads probability
3. If coin is heads, output w as a sample
4. If coin is tails, goto step 1
Analysis: Need C/|W| iterations until getting a single sample

12
Uniform Sampling via PageRank Sampling: Reality How to estimate PR(w)?
Use the random walk itself: VR(w) = visit ratio of w (# of times w was visited by
the walk divided by length of the walk) Approximation is very crude
Use the subgraph spanned by nodes visited to compute PageRank
Bias towards the neighborhood of the initial pageUse Google

13
Uniform Sampling by RW on Regular Graphs [Bar-Yossef et al 2000]
Fact: A random walk on an undirected, connected, non-bipartite, and regular graph converges to a uniform distribution.
Proof: P: random walk’s probability transition matrix
P is stochastic 1 is a right eigenvector with e.v. 1: P1 = 1
Graph is connected RW is irreducible Graph is non-bipartite RW is aperiodic Hence, RW is ergodic, and thus has a stationary
distribution : is a left eigenvector of P with e.v. 1: P =

14
Random Walks on Regular Graphs
Proof (cont.):d: graph’s degreeA: graph’s adjacency matrix
Symmetric, because graph is undirected
P = (1/d) A Hence, also P is symmetric Its left eigenvectors and right eigenvectors are the
same = (1/n) 1

15
Web as a Regular Graph
Problems Web is not connected Web is directed Web is non-regular
Solutions Focus on indexable web, which is connected Ignore directions of links Add a weighted self loop to each node
weight(w) = degmax – deg(w)
All pages then have degree degmax
Overestimate on degmax doesn’t hurt

16
Mixing Time Analysis
Theorem
Mixing time of a random walk is log(|W|) / (1 - 2) 1 - 2: spectral gap of P
Experiment (over a large web crawl): 1 – 2 ~ 1/100,000 log(|W|) ~ 34
Hence: mixing time ~ 3.4 million steps Self loop steps are free About 1 in 30,000 steps is not a self loop step (degmax
~ 300,000, degavg ~ 10) Actual mixing time: ~ 115 steps!

17
Random Walks on Regular Graphs: Reality How to get incoming links?
Search engines Potential bias towards search engine index Do not provide full list of in-links? Costly communication
Random walk’s history Important for avoiding dead ends Requires storage
How to estimate deg(w)? Solution: run random walk on the sub-graph of W
spanned by the available links Sub-graph may no longer have the good mixing time
properties

18
Top 20 Internet Domains (Summer 2003)
10.36%
5.57%4.15%3.01%
0.61%
9.19%
51.15%
0%
10%
20%
30%
40%
50%
60%
.com
.org
.net
.edu .d
e .uk
.au .u
s.e
s .jp .ca .nl .it .ch .p
l .il .nz
.gov
.info .m
x

19
68%
54%50% 50%
48%
38%
0%
10%
20%
30%
40%
50%
60%
70%
80%
Google AltaVista Fast Lycos HotBot Go
Search Engine Coverage(Summer 2000)

20
Random Samplingfrom
a Search Engine’s Index

21
Search Engine Samplers
IndexPublicInterface
PublicInterface
Search Engine
Sampler
Web
D
Queries
Top k results
Random document x D
Indexed Documents

22
Motivation Useful tool for search engine evaluation:
Freshness Fraction of up-to-date pages in the index
Topical bias Identification of overrepresented/underrepresented topics
Spam Fraction of spam pages in the index
Security Fraction of pages in index infected by viruses/worms/trojans
Relative Size Number of documents indexed compared with other search
engines

23
Size Wars
August 2005
: We index 20 billion documents.
So, who’s right?
September 2005
: We index 8 billion documents, but our index is 3 times larger than our competition’s.
24
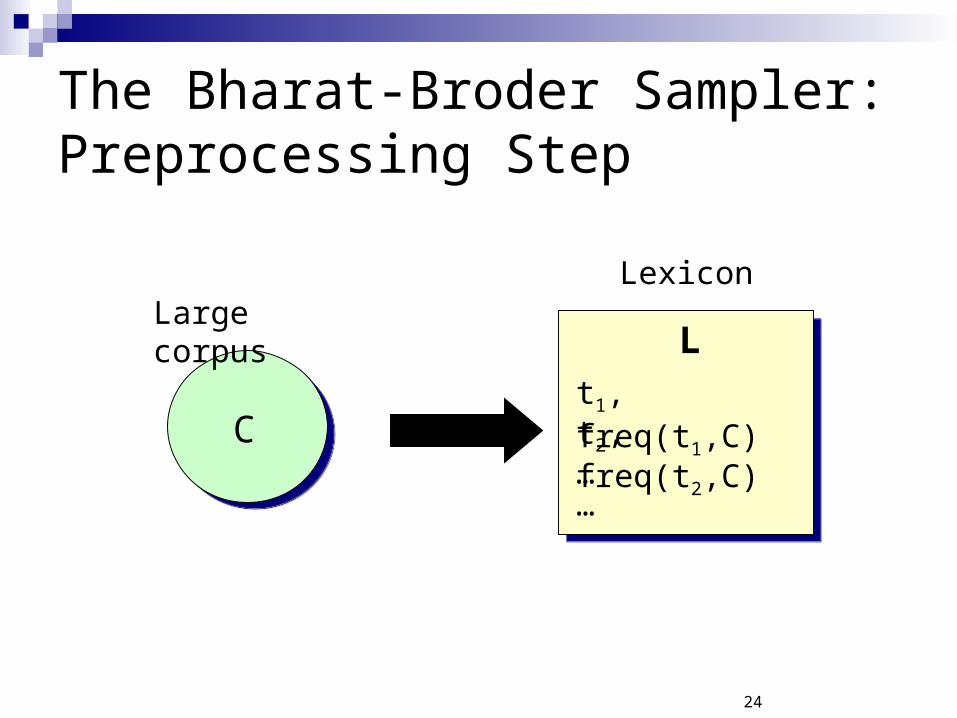
The Bharat-Broder Sampler: Preprocessing Step
C
Large corpusL
t1, freq(t1,C)t2, freq(t2,C)……
Lexicon
25
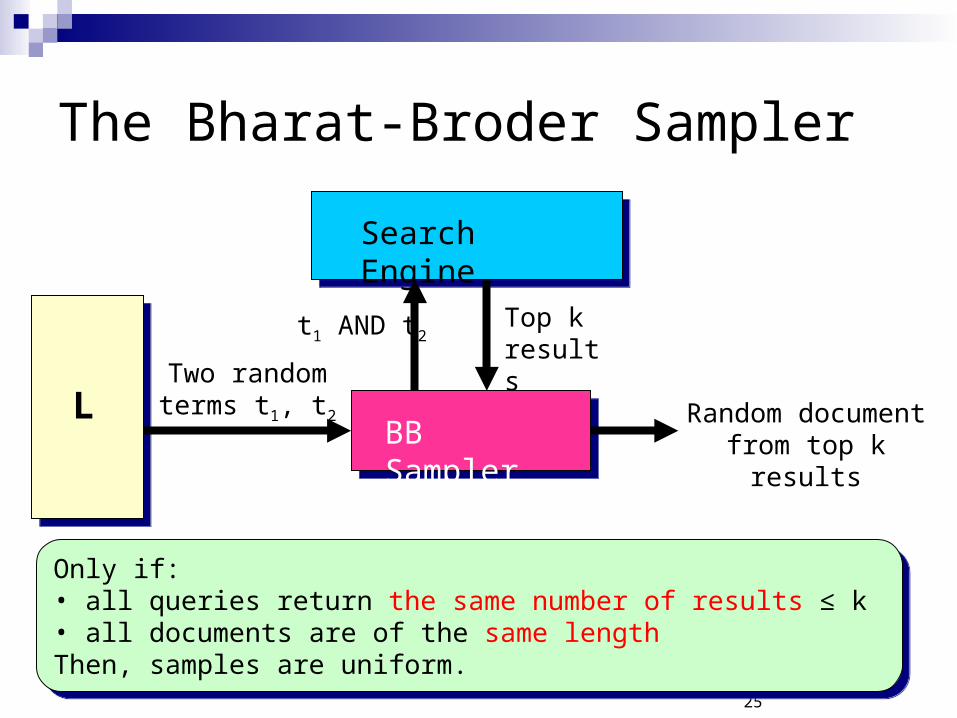
The Bharat-Broder Sampler
Search Engine
BB Sampler
t1 AND t2Top k results
Random document from top k results
LTwo random terms t1, t2
Only if:• all queries return the same number of results ≤ k • all documents are of the same lengthThen, samples are uniform.
Only if:• all queries return the same number of results ≤ k • all documents are of the same lengthThen, samples are uniform.

26
The Bharat-Broder Sampler:Drawbacks Documents have varying lengths
Bias towards long documents
Some queries have more than k matchesBias towards documents with high static rank

27
Search Engines as Hypergraphs
results(q) = { documents returned on query q } queries(x) = { queries that return x as a result } P = query pool = a set of queries Query pool hypergraph:
Vertices: Indexed documents Hyperedges: { result(q) | q P }
www.cnn.com
www.foxnews.com
news.google.com
news.bbc.co.ukwww.google.com
maps.google.com
www.bbc.co.uk
www.mapquest.com
maps.yahoot.com
“news”
“bbc”
“google”
“maps”
en.wikipedia.org/wiki/BBC

28
Query Cardinalities and Document Degrees
Query cardinality: card(q) = |results(q)| Document degree: deg(x) = |queries(x)| Examples:
card(“news”) = 4, card(“bbc”) = 3 deg(www.cnn.com) = 1, deg(news.bbc.co.uk) = 2
www.cnn.com
www.foxnews.com
news.google.com
news.bbc.co.ukwww.google.com
maps.google.com
www.bbc.co.uk
www.mapquest.com
maps.yahoot.com
“news”
“bbc”
“google”
“maps”
en.wikipedia.org/wiki/BBC
29
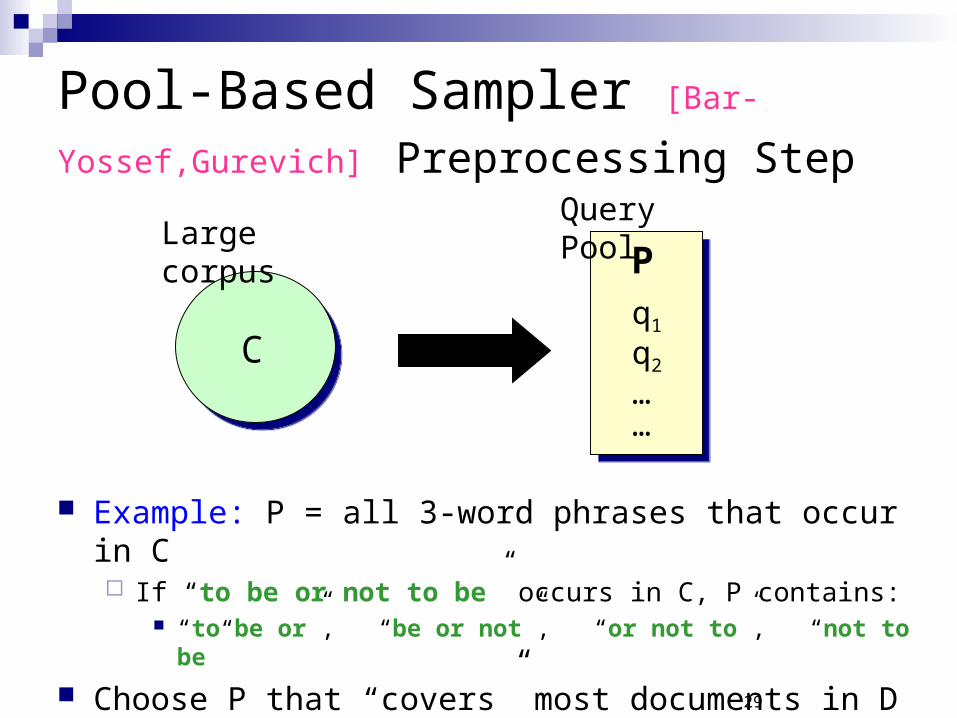
Pool-Based Sampler [Bar-Yossef,Gurevich] Preprocessing Step
C
Large corpusPq1
……
Query Pool
Example: P = all 3-word phrases that occur in C If “to be or not to be” occurs in C, P contains:
“to be or”, “be or not”, “or not to”, “not to be”
Choose P that “covers” most documents in D
q2

30
Monte Carlo Simulation
Don’t know how to generate uniform samples from D directly
How to use biased samples to generate uniform samples?
Samples with weights that represent their bias can be used to simulate uniform samples
Monte Carlo Simulation Methods
Rejection Sampling
Rejection Sampling
Importance Sampling
Importance Sampling
Metropolis-Hastings
Metropolis-Hastings
Maximum-Degree
Maximum-Degree

31
Document Degree Distribution
Can generate biased samples from the “document degree distribution”
Advantage: Can compute weights representing the bias of p:

32
Unnormalized forms of distributions p: a distribution on a domain D Unnormalized form of p:
: (unknown) normalization constant
Examples: p = uniform: p = degree distribution:

33
Monte Carlo Simulation : Target distribution
In our case: =uniform on D p: Trial distribution
In our case: p = document degree distribution
Bias weight of p(x) relative to (x): In our case:
Monte Carlo Simulator
Monte Carlo Simulator
Samples from p
Sample from
x
Sampler
(x1,w(x)), (x2,w(x)),… p-Samplerp-Sampler

34
C: envelope constant C ≥ w(x) for all x
The algorithm: accept := false while (not accept)
generate a sample x from p toss a coin whose heads probability is if coin comes up heads,
accept := true
return x
In our case: C = 1 and acceptance prob = 1/deg(x)
Rejection Sampling [von Neumann]

35
Pool-Based Sampler
Degree distribution sampler
Degree distribution sampler
Search EngineSearch Engine
Rejection Sampling
Rejection Sampling
q1,q2,…results(q1), results(q2),…
x
Pool-Based Sampler
(x(x11,1/deg(x,1/deg(x11)),)),
(x(x22,1/deg(x,1/deg(x22)),…)),…
Uniform sample
Documents sampled from degree distribution with corresponding weights
Degree distribution: p(x) = deg(x) / x’deg(x’)

36
Sampling documents by degree
Select a random q P Select a random x results(q) Documents with high degree are more likely to be sampled If we sample q uniformly “oversample” documents that
belong to narrow queries We need to sample q proportionally to its cardinality
www.cnn.com
www.foxnews.com
news.google.com
news.bbc.co.ukwww.google.com
maps.google.com
www.bbc.co.uk
www.mapquest.com
maps.yahoot.com
“news”
“bbc”
“google”
“maps”
en.wikipedia.org/wiki/BBC

37
Query Cardinality Distribution
Unrealistic assumptions: Can sample queries from the cardinality distribution
In practice, don’t know a priori card(q) for all q P q P, card(q) ≤ k
In practice, some queries overflow (vol(q) > k)
results(q) = results returned on query q card(q) = |results(q)| Cardinality distribution:

38
Degree Distribution Sampler
Search EngineSearch Engine
results(q)
xCardinality Distribution Sampler
Cardinality Distribution Sampler
Sample x uniformly from results(q)
Sample x uniformly from results(q)
q
Analysis:
Degree Distribution Sampler
Query sampled from cardinality
distribution
Document sampled from
degree distribution

39
Sampling queries by cardinality
Sampling queries from pool uniformly:Easy
Sampling queries from pool by cardinality: Hard Requires knowing cardinalities of all queries in the
search engine
Use Monte Carlo methods to simulate biased sampling via uniform sampling: Target distribution: the cardinality distribution Trial distribution: uniform distribution on P

40
Sampling queries by cardinality
Bias weight of cardinality distribution relative to the uniform distribution:
Can be computed using a single search engine query
Use rejection sampling: Envelope constant for rejection sampling:
Queries are sampled uniformly from P Each query q is accepted with probability

41
Degree Distribution Sampler
Degree Distribution Sampler
Complete Pool-Based Sampler
Search EngineSearch Engine
Rejection Sampling
Rejection Sampling
x(x,1/deg(x)),…
Uniform document
sample
Documents sampled from degree distribution with corresponding weights
Uniform Query Sampler
Uniform Query Sampler
Rejection Sampling
Rejection Sampling
(q,card(q)),…
Uniform query
sampleQuery
sampled from cardinality distribution
(q,results(q)),…

42
Dealing with Overflowing Queries
Problem: Some queries may overflow (card(q) > k) Bias towards highly ranked documents
Solutions: Select a pool P in which overflowing queries are rare
(e.g., phrase queries) Skip overflowing queries Adapt rejection sampling to deal with approximate weights
Theorem:
Samples of PB sampler are at most -away from uniform. ( = overflow probability of P)
43
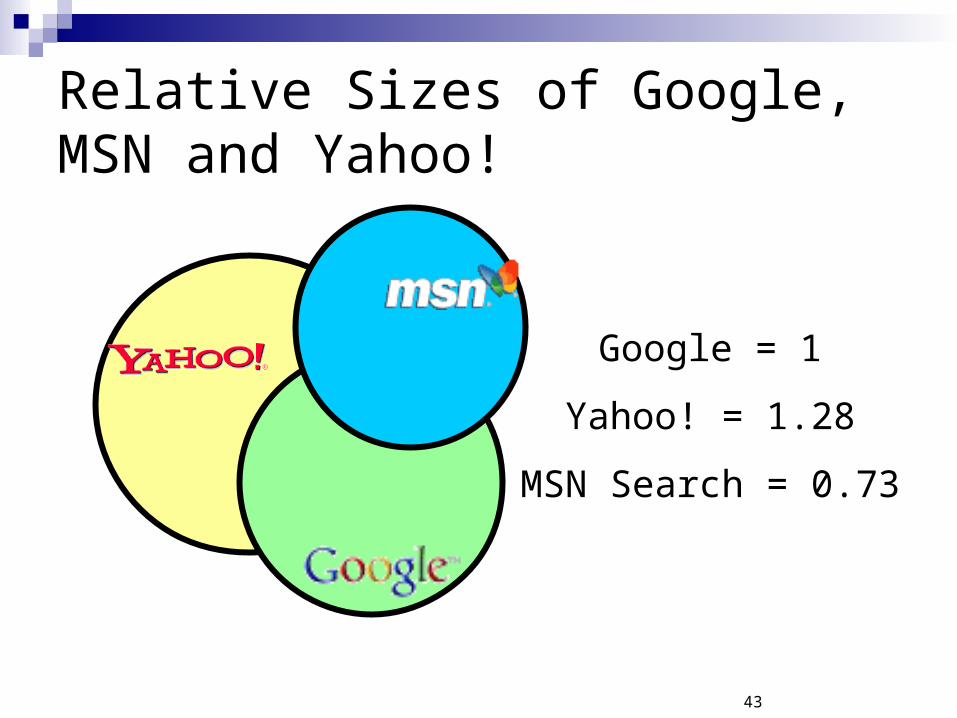
Relative Sizes of Google, MSN and Yahoo!
Google = 1
Yahoo! = 1.28
MSN Search = 0.73

44
End of Lecture 10


















