
Интеллектуальная обработка...
85
Интеллектуальная обработка информации Лекция 1(Алгоритмы) Основные положения Терновой Максим Юрьевич к.т.н., доцент кафедры информационно- телекоммуникационных сетей
Transcript of Интеллектуальная обработка...

Интеллектуальная обработка информации
Лекция 1(Алгоритмы) Основные положения
Терновой Максим Юрьевич к.т.н., доцент кафедры информационно-
телекоммуникационных сетей

Неформальное определение
Алгоритм (algorithm) — это любая корректно
определенная вычислительная процедура, на вход
(input) которой подается некоторая величина или
набор величин, и результатом выполнения которой
является выходная (output) величина или набор
значений.
Алгоритм представляет собой последовательность
вычислительных шагов, преобразующих входные
величины в выходные.

Алгоритм-инструмент решения вычислительной задачи
В постановке вычислительной задачи в
общих чертах задаются отношения между входом
и выходом.
В алгоритме описывается конкретная
вычислительная процедура, с помощью которой
удается добиться выполнения указанных
отношений.

Пример
Выполнить сортировку последовательности
чисел в неубывающем порядке.
Эта задача часто возникает на практике и служит
благодатной почвой для ознакомления на ее примере со
многими стандартными методами разработки и анализа
алгоритмов.

Постановка задачи сортировки
Вход: последовательность из n чисел
Выход: перестановка (изменение порядка)
входной последовательности таким образом, что
для ее членов выполняется соотношение

Пример
Если на вход подается последовательность <31,41,59,26,41,58>,
то вывод алгоритма сортировки должен быть таким:
<26,31,41,41,58,59>.
Подобная входная последовательность называется
экземпляром (instance) задачи сортировки.
Вообще говоря, экземпляр задачи состоит из ввода
(удовлетворяющего всем ограничениям, наложенным при
постановке задачи), необходимого для решения задачи.

Корректность алгоритма
Алгоритм корректен (correct), если для каждого
ввода результатом его работы является корректный
вывод.
Говорят, что корректный алгоритм решает данную
вычислительную задачу.

Примеры задач, решаемых при помощи алгоритмов
● Расшифровка генома человека: идентификация всех
100000 генов, входящих в состав ДНК человека, определение
последовательностей, образуемых 3 миллиардами базовых
пар, из которых состоит ДНК, сортировка этой информации в
базах данных и разработка инструментов для ее анализа.
● Маршрутизация в телекоммуникационных сетях.
● Поиск нужных страниц в Интернете.
● Электронная коммерция: криптография с открытым ключом и
электронные подписи.
● В социологических исследованиях и т.д.

Структуры данных
Структура данных (data structure) — это способ
хранения и организации данных, облегчающий
доступ к этим данным и их модификацию.
Ни одна структура данных не является
универсальной и не может подходить для всех
целей, поэтому важно знать преимущества и
ограничения, присущие некоторым из них.

Эффективность алгоритмов
Алгоритмы, разработанные для решения одной и
то же задачи, часто очень сильно различаются
по эффективности.
Эти различия могут быть намного значительнее,
чем те, что вызваны применением
неодинакового аппаратного и программного
обеспечения.

Пример(1)
Рассмотрим работу двух алгоритмов сортировки:
сортировка вставкой и сортировка слиянием.
Оценка времени работы (временной
сложности):
Сортировка вставкой:
Сортировка слиянием:
где n - количество сортируемых элементов, а
с1 и c2 — константы, не зависящие от n.
Обычно константа метода вставок меньше константы метода
слияния, т.е. с1< c2 .

Пример(2)
Для небольшого количества сортируемых элементов
сортировка включением обычно работает быстрее,
однако когда n становится достаточно большим, все
заметнее проявляется преимущество сортировки
слиянием, возникающее благодаря тому, что для
больших n незначительная величина lg(n) по сравнению с n
полностью компенсирует разницу величин постоянных
множителей.

Пример(3)
Пусть есть два компьютера — А и Б.
Компьютер А более быстрый, и на нем работает
алгоритм сортировки вставкой,
а компьютер Б более медленный, и на нем работает
алгоритм сортировки методом слияния.
Оба компьютера должны выполнить сортировку
множества, состоящего из миллиона чисел.
Предположим, что компьютер А выполняет миллиард
инструкций в секунду,
а компьютер Б — лишь десять миллионов.
Т.е. А работает в 100 раз быстрее, чем Б.

Пример(4)
Чтобы различие стало еще большим, предположим,
что код для метода вставок (компьютер А) написан
самым лучшим в мире программистом с использованием
команд процессора, и для сортировки n чисел надо
выполнить 2*n^2 команд (т.е. с1 = 2).
Сортировка методом слияния (на компьютере Б)
реализована программистом-середнячком с помощью
языка высокого уровня. При этом компилятор оказался не
слишком эффективным, и в результате получился код,
требующий выполнения 50*n*lg(n) команд (т.е. c2 =
50).
І

Пример(5)
Для сортировки миллиона чисел:
на компьютере А:
на компьютере В:

Пример(6)
Для сортировки 10 миллионов чисел:
Сортировка вставкой - 2,3 дня
Сортировка слиянием – меньше 20 минут

Упражнение
Определите максимальные значения n, для которых задача может
быть решена за время t, если предполагается, что время работы
алгоритма, необходимое для решения задачи, равно f(n) секунд.

Сортировка вставкой

Постановка задачи сортировки(напоминание)
Вход: последовательность из n чисел
Выход: перестановка (изменение порядка)
входной последовательности таким образом, что
для ее членов выполняется соотношение

Сортировка вставкой – пояснение «на котиках», то есть на картах(1)
Алгоритм сортировки вставкой эффективно работает при
сортировке небольшого количества элементов.
Сортировка вставкой напоминает способ, к которому прибегают игроки для сортировки имеющихся на руках карт.
Пусть вначале в левой руке нет ни одной карты, и все они лежат на столе рубашкой вверх. Далее со стола берется по одной карте, каждая из которых помещается в нужное место среди карт, которые находятся в левой руке.
Чтобы определить, куда нужно поместить очередную карту, ее масть и достоинство сравнивается с мастью и достоинством карт
в руке.

Сортировка вставкой – пояснение «на котиках», то есть на картах(1)
Допустим, сравнение проводится в направлении слева направо.
В любой момент времени карты в левой руке будут рассортированы, и это будут те карты, которые первоначально лежали в стопке на столе.

Сортировка карт методом вставок

Алгоритм сортировки вставкой

Сортировка вставкой(пояснение алгоритма)
На вход подается массив А [1..n], содержащий
последовательность из n сортируемых чисел (количество
элементов массива А обозначено в этом коде как length [А].)
Входные числа сортируются без использования
дополнительной памяти: их перестановка
производится в пределах массива, и объем
используемой при этом дополнительной памяти
не превышает некоторую постоянную
величину.
По окончании работы алгоритма Insertion_Sort входной массив
содержит отсортированную последовательность.
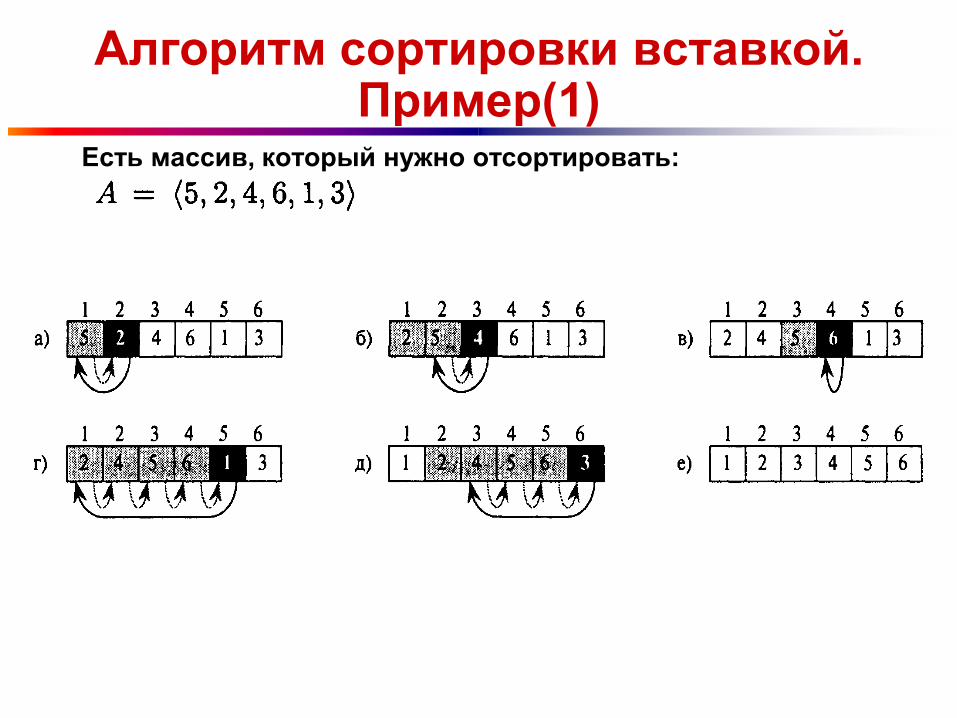
Алгоритм сортировки вставкой. Пример(1)
Есть массив, который нужно отсортировать:

Алгоритм сортировки вставкой. Пример(2)
Индекс j указывает "текущую карту", которая
помещается в руку.
В начале каждой итерации внешнего цикла for с
индексом j массив А состоит из двух частей.
Элементы A [1..j — 1] соответствуют
отсортированным картам в руке, а элемен-
ты A [j + 1..n] — стопке карт, которые пока что
остались на столе.
Заметим, что элементы A [1..j — 1] изначально тоже
находились на позициях от 1 до j — 1, но
в другом порядке, а теперь они отсортированы.

Инварианты цикла и корректность алгоритма

Понятие инварианта цикла
Рассмотрим понятие инварианта цикла на примере
сортировки вставкой:
Инвариант цикла:
В начале каждой итерации цикла for из строк 1-8 подмассив
A [1..j — 1] содержит те же элементы, которые были в
нем с самого начала, но расположенные в
отсортированном порядке.
Инварианты цикла позволяют понять, корректно
ли работает алгоритм.
Для этого необходимо показать, что инварианты циклов
обладают следующими тремя свойствами.

Три свойства инвариантов цикла
Инициализация. Они справедливы перед первой
инициализацией цикла.
Сохранение. Если они истинны перед очередной
итерацией цикла, то остаются истинны и после нее.
Завершение. По завершении цикла инварианты
позволяют убедиться в правильности алгоритма.

Проверка свойств инварианта цикла на сортировке вставками(1) Инициализация.
Покажем справедливость инварианта цикла перед первой
итерацией, т.е. при j = 2.
Таким образом, подмножество элементов A [1..j — 1]
состоит только из одного элемента А [1], сохраняющего
исходное значение.
Более того, в этом подмножестве элементы
рассортированы (тривиальное утверждение).
Все вышесказанное подтверждает, что инвариант цикла
соблюдается перед первой итерацией цикла.

Проверка свойств инварианта цикла на сортировке вставками(2)
Сохранение.
Покажем, что инвариант цикла сохраняется после
каждой итерации.
Можно сказать, что в теле внешнего цикла for
происходит сдвиг элементов A [j — 1], A [j — 2],
A [j - 3], ... на одну позицию вправо до тех пор,
пока не освободится подходящее место для
элемента A [j] (строки 4-7), куда он и
помещается (строка 8).
При более формальном подходе к рассмотрению второго
свойства потребовалось бы сформулировать и обосновать
инвариант для внутреннего цикла while.

Проверка свойств инварианта цикла на сортировке вставками(3)
Завершение.
При сортировке методом включений внешний цикл for
завершается, когда j превышает n, т.е. когда j = n + 1.
Подставив в формулировку инварианта цикла значение
n + 1, получим такое утверждение:
в подмножестве элементов А [1..n] находятся те
же элементы, которые были в нем до начала
работы алгоритма, но расположенные в
отсортированном порядке.
Однако подмножество A[1..n] и есть сам массив А.
Таким образом, весь массив отсортирован, что и
подтверждает корректность алгоритма.

Упражнение
Используя в качестве модели рисунок со слайда 27, проиллюстрируйте работу алгоритма INSERTIONJSORT по упорядочению массива
А = <31,41,59,26,41,58>.

Упражнение
Рассмотрим задачу поиска.
Вход: последовательность n чисел
и величина v.
Выход: индекс i, обладающий свойством v = A[i], или значение NIL, если в массиве А отсутствует значение v.
1) Составьте псевдокод линейного поиска, при работе которого выполняется сканирование последовательности в поиске значения v.
2) Докажите корректность алгоритма с помощью инварианта цикла. Для чего убедитесь, что выбранные инварианты цикла удовлетворяют трем необходимым условиям.

Анализ алгоритмов

Анализ алгоритмов. Общие положения
Анализ алгоритма заключается в том, чтобы
предсказать требуемые для его
выполнения ресурсы.
Для разных алгоритмов это может быть:
память,
пропускная способность сети,
необходимое аппаратное обеспечение,
время вычисления (чаще всего).

Технология, которая будет использоваться(1)
Для анализа алгоритмов необходимо определить
технологию, которая будет для этого использоваться.
В нее включаются модель ресурсов и величины
их измерения.
Многие алгоритмы реализуются в виде
компьютерных программ, поэтому чаще всего в
качестве технологии реализации принята модель
обобщенной однопроцессорной машины с
памятью с произвольным доступом (Random-
Access Machine — RAM).
В этой модели команды процессора выполняются
последовательно; одновременно выполняемые
операции отсутствуют.

Технология, которая будет использоваться(2)
Для анализа алгоритмов необходимо определить
технологию, которая будет для этого использоваться.
В нее включаются модель ресурсов и величины
их измерения.
Многие алгоритмы реализуются в виде
компьютерных программ, поэтому чаще всего в
качестве технологии реализации принята модель
обобщенной однопроцессорной машины с
памятью с произвольным доступом (Random-
Access Machine — RAM).
В этой модели команды процессора выполняются
последовательно; одновременно выполняемые
операции отсутствуют.

Технология, которая будет использоваться(3)
Строго говоря, в модели RAM следует точно
определить набор инструкций и время их
выполнения, однако это утомительно и мало
способствует пониманию принципов разработки и анализа
алгоритмов.
С другой стороны, нужно соблюдать осторожность,
чтобы не исказить модель RAM.
Например, что будет, если в RAM встроена команда сортировки? В
этом случае сортировку можно выполнять с помощью всего
одной команды процессора. Такая модель нереалистична,
поскольку настоящие компьютеры не имеют подобных
встроенных команд, а мы ориентируемся именно на их
устройство.

Технология, которая будет использоваться(4)
Модель содержит те команды, которые обычно можно найти в
реальных компьютерах:
арифметические (сложение, вычитание, умножение,
деление, вычисление остатка деления, приближение
действительного числа ближайшим меньшим или
ближайшим большим целым),
операции перемещения данных (загрузка, занесение в
память, копирование),
управляющие (условное и безусловное ветвление, вызов
подпрограммы и возврат из нее).
Для выполнения каждой такой инструкции требуется
определенный фиксированный промежуток
времени.

Технология, которая будет использоваться(5)
В модели RAM есть целочисленный тип данных и тип чисел
с плавающей точкой.
Предполагается, что существует верхний предел
размера слова данных.
Например, если обрабатываются входные данные с максимальным
значением n, обычно предполагается, что целые числа
представлены с*lg(n) битами, где с — некоторая константа, не
меньшая единицы.
Требование с > 1 обусловлено тем, что в каждом слове должно
храниться одно из n значений, что позволит индексировать
входные элементы.
Кроме того, предполагается, что с — это конечная константа, поэтому
объем слова не может увеличиваться до бесконечности.

Размер входных данных(1)
Как правило временная (вычислительная)
сложность (время работы алгоритма) представляется
как функция от размера входных данных.
Размер входных данных по разному определяется для
разных задач.
Например:
задача сортировка или дискретные
преобразования Фурье, это количество
входных элементов, например, размер n
сортируемого массива;
перемножение двух целых чисел — общее
количество битов, необходимых для представления
входных данных в обычных двоичных обозначениях;

Размер входных данных(2)
если на вход алгоритма подается граф, размер
ввода состоит из двух переменных количества вершин и
ребер графа.

Время работы алгоритма
Время работы алгоритма для того или иного ввода
измеряется в количестве элементарных
операций, или "шагов", которые необходимо
выполнить.
Здесь удобно ввести понятие шага, чтобы рассуждения
были как можно более машиннонезависимыми.
На данном этапе мы будем исходить из точки зрения,
согласно которой для выполнения каждой строки
псеводкода требуется фиксированное время.
Время выполнения различных строк может отличаться, но мы
предположим, что одна и та же i-я строка выполняется за
время сi, где ci — константа.
Эта точка зрения согласуется с моделью RAM и отражает
особенности практической реализации псевдокода на
реальных компьютерах.

Анализ алгоритма сортировка вставкой

Время работы алгоритма сортировки вставкой
Время работы алгоритма определяется суммой
произведений значений, стоящих в столбцах время и
количество раз:

Анализ алгоритма сортировка вставкой. Наилучший случай
Время работы алгоритма может зависеть от степени
упорядоченности сортируемых величин,
которой они обладали до ввода.
Например, на входе все элементы массива отсортированы.
Тогда для каждого j = 2,3,..., n получается, что А [j] <= key в
строке 5, еще когда i равно своему начальному значению
j - 1. Таким образом, при j = 2,3,..., n tj = 1, и
\
Это время работы можно записать как a*n + b, где а и b —
константы, зависящие от величин ci т.е. это время
является линейной функцией от n.

Анализ алгоритма сортировка вставкой. Наихудший случай
Например, на входе все элементы массива отсортированы
в обратном порядке.
Каждый элемент A [j] необходимо сравнивать со всеми
элементами уже отсортированного подмножества
A[1..j-1], так что для j = 2,3,..., n значения tj = j. С учетом того,
что
и

Время работы алгоритма сортировки вставками в наихудшем случае
Время работы можно записать как a*n^2 + b*n + c, где
константы a, b и с зависят от ci. Таким образом, это
квадратичная функция от n.

Наихудшее время работы
Обычно рассматривают время работы в наихудшем случае.
Причины:
• Время работы алгоритма в наихудшем случае — это
верхний предел этой величины для любых входных
данных. Мы точно знаем, что для выполнения алгоритма не
потребуется большее количество времени. Не нужно будет
делать каких-то сложных предположений о времени работы и
надеяться, что на самом деле эта величина не будет
превышена.
• В некоторых алгоритмах наихудший случай встречается
достаточно часто. Например, если в базе данных происходит
поиск информации, то наихудшему случаю соответствует
ситуация, когда нужная информация в базе данных
отсутствует. В некоторых поисковых приложениях поиск
отсутствующей информации может происходить довольно
часто.

Наихудшее время работы
• Характер поведения "усредненного" времени работы
часто ничем не лучше поведения времени работы для
наихудшего случая.
Предположим, что последовательность, к которой применяется
сортировка методом вставок, сформирована случайным
образом. Сколько времени понадобится, чтобы определить, в
какое место подмассива A[1..j — 1] следует поместить элемент
A [j]? В среднем половина элементов подмассива A [1..j — 1]
меньше, чем A [j], а половина — больше его. Таким образом, в
среднем нужно проверить половину элементов подмассива A
[1..j — 1], поэтому tj приблизительно равно j/2. B результате
получается, что среднее время работы алгоритма является
квадратичной функцией от количества входных элементов, т.е.
характер этой зависимости такой же, как и для времени работы
в наихудшем случае.

Скорость роста
Скорость роста (rate of growth), или
порядок роста (order of growth), времени
работы нас интересует на самом деле.
Таким образом, во внимание будет приниматься
только главный член формулы (т.е. в
нашем случае a*n^2), поскольку
при больших n членами меньшего порядка можно
пренебречь.

Скорость роста
Постоянные множители при главном
члене также будут игнорироваться, так как
для оценки вычислительной эффективности
алгоритма с входными данными большого
объема они менее важны, чем порядок роста.
Таким образом, время работы алгоритма,
работающего по методу вставок, в
наихудшем случае равно
(произносится "тета от n в квадрате").

Сравнение эффективности алгоритмов
Один алгоритм считается эффективнее другого,
если время его работы в наихудшем случае
имеет более низкий порядок роста.
Из-за наличия постоянных множителей и второстепенных
членов эта оценка может быть ошибочной, если
входные данные невелики.
Однако если объем входных данных значительный, то,
например, алгоритм в наихудшем случае работает
быстрее, чем алгоритм

Упражнение
Выразите функцию
в -обозначениях.

Разработка алгоритмов

Метод декомпозиции

Общие замечания
Многие полезные алгоритмы имеют рекурсивную
структуру: для решения данной задачи они рекурсивно
вызывают сами себя один или несколько раз, чтобы
решить вспомогательную задачу, имеющую
непосредственное отношение к поставленной задаче.
Такие алгоритмы зачастую разрабатываются с помощью метода
декомпозиции, или разбиения: сложная задача разбивается на
несколько более простых, которые подобны исходной задаче,
но имеют меньший объем; далее эти вспомогательные задачи
решаются рекурсивным методом, после чего полученные
решения комбинируются с целью получить решение исходной
задачи.
Метод декомпозиций основан на принципе «разделяй и
властвуй».

Метод декомпозиции
Включает в себя 3 этапа на каждом уроне
рекурсии:
Разделение задачи на несколько подзадач.
Покорение — рекурсивное решение этих подзадач. Когда
объем подзадачи достаточно мал, выделенные
подзадачи решаются непосредственно.
Комбинирование решения исходной задачи из решений
вспомогательных задач.
Пример, сортировка слиянием.

Сортировка слиянием «на пальцах»
Разделение: сортируемая последовательность, состоящая
из n элементов, разбивается на две меньшие
последовательности, каждая из которых содержит n/2
элементов.
Покорение: сортировка обеих вспомогательных
последовательностей методом слияния.
Комбинирование: слияние двух отсортированных
последовательностей для получения окончательного
результата.
Рекурсия достигает своего нижнего предела, когда
длина сортируемой последовательности
становится равной 1.
В этом случае вся работа уже сделана, поскольку любую
такую последовательность можно считать упорядоченной.

Сортировка слиянием. Merge
Основная операция — это объединение двух
отсортированных последовательностей в ходе
комбинирования (последний этап).
Это делается с помощью вспомогательной процедуры
Merge(A,p, q,r), где А — массив, а р, q и r — индексы,
нумерующие элементы массива, такие, что р < q < г.
Предполагается, что элементы подмассивов A [p..q] и A[q+1..r]
упорядочены.
Она сливает эти два подмассива в один отсортированный,
элементы которого заменяют текущие элементы подмассива А
[р..г].
Для выполнения процедуры MERGE требуется время , где n =
г - р+1 — количество подлежащих слиянию элементов.

Merge
Маленькая хитрость –введение сигнальной карты,
которая будет в конце и говорить о том, что все
элементы массива уже «слиты».

Процедура слияния
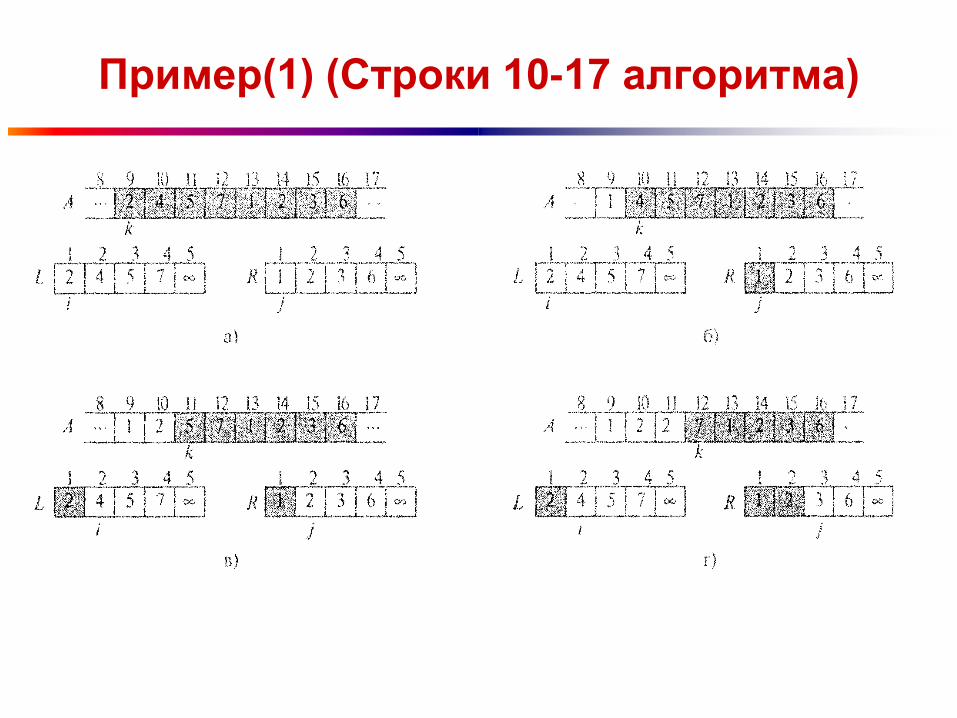
Пример(1) (Строки 10-17 алгоритма)
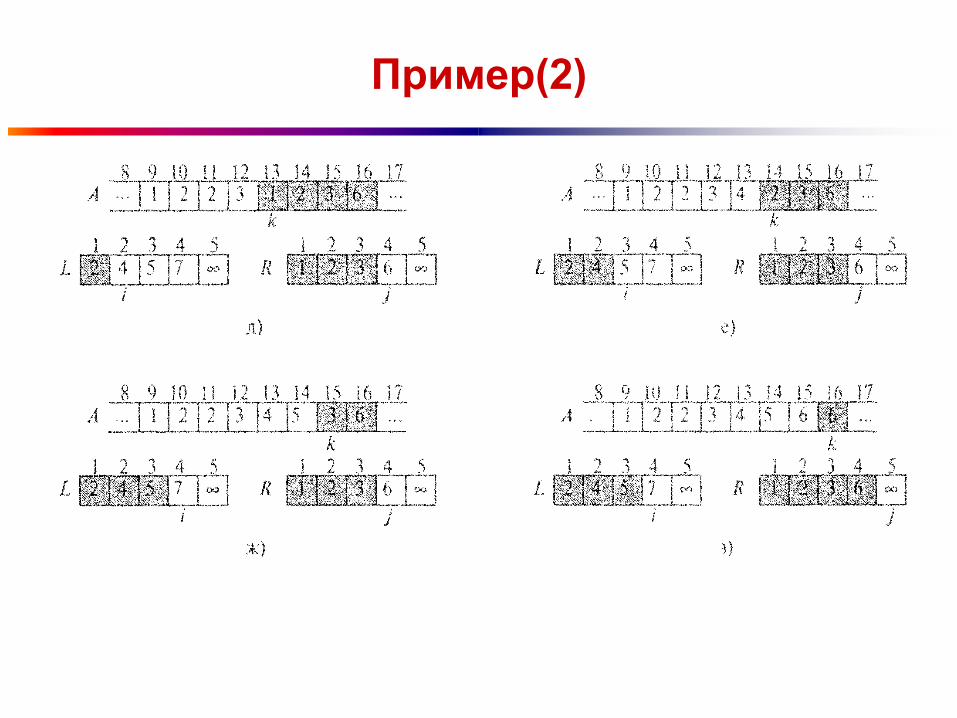
Пример(2)
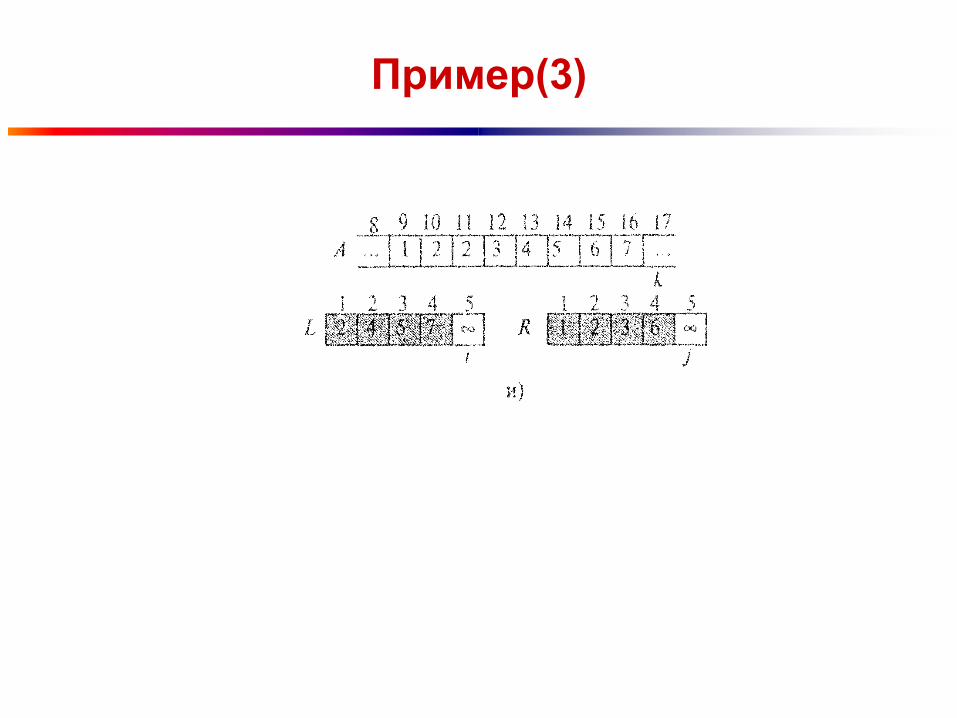
Пример(3)

Процедура Merge(инвариант цикла)
Перед каждой итерацией цикла for в строках 12-17, подмас-
сив А [р..k-1] содержит k - р наименьших элементов массивов
L [1..n1 + 1] и R [1..n2 + 1] в отсортированном порядке.
Кроме того, элементы L[i] и R[i] являются наименьшими
элементами массивов L и R, которые еще не скопированы в
массив А.
Необходимо показать:
-инвариант цикла соблюдается перед первой итерацией
рассматриваемого цикла for,
-каждая итерация цикла не нарушает его,
-что с его помощью удается продемонстрировать
корректность алгоритма, когда цикл заканчивает свою работу.

Процедура Merge(инвариант цикла). Инициализация
Инициализация. Перед первой итерацией цикла к = р, поэтому
подмассив А [р..k -1] пуст.
Он содержит k - р = 0 наименьших элементов массивов L и R.
Поскольку r = j = 1, элементы L[i] и R [j] — наименьшие элементы
массивов L и R, не скопированные обратно в массив А.

Процедура Merge(инвариант цикла). Сохранение
Сохранение. Предположим, что L [i] <=R [j]. Тогда L[i] —
наименьший элемент, не скопированный в массив А.
Поскольку в подмассиве А [р..k-1] содержится k-р наименьших
элементов, после выполнения строки 14, в которой значение
элемента L [i] присваивается элементу А [k], в подмассиве А
[р..k] будет содержаться k - р + 1 наименьший элемент.
В результате увеличения параметра к цикла for и значения
переменной i (строка 15), инвариант цикла восстанавливается
перед следующей итерацией. Если же выполняется
неравенство L[i] > R[j], то в строках 16 и 17 выполняются
соответствующие действия, в ходе которых также сохраняется
инвариант цикла.

Процедура Merge(инвариант цикла). Завершение
Завершение. Алгоритм завершается, когда k = r + 1.
В соответствии с инвариантом цикла, подмассив
А[р..k - 1] (т.е. подмассив А [р..r]) содержит
k - р = r - р + 1 наименьших элементов массивов L
[1..n1 + 1] и R [1..n2 + 1] в отсортированном порядке.
Суммарное количество элементов в массивах L и R
равно n1 + n2 + 2 = r - р + 3. Все они, кроме двух
самых больших, скопированы обратно в массив А, а
два оставшихся элемента являются сигнальными.

Время работы Merge
Время работы процедуры Merge равно ,
где n = r- р+1.
Поскольку каждая из строк 1-3 и 8-11
выполняется в течение фиксированного
времени;
длительность циклов for в строках 4-7 равна
а в цикле for в строках 12-17 выполняется n
итераций, на каждую из которых
затрачивается фиксированное время.

Сортировка слиянием

Сортировка слиянием. Пример

Анализ алгоритмов, основанных на принципе «разделяй и властвуй»

Рекуррентное уравнение(1)
Если алгоритм рекурсивно обращается к
самому себе, время его работы часто
описывается с помощью рекуррентного
уравнения, или рекуррентного соотношения, в
котором полное время, требуемое для решения
всей задачи с объемом ввода n, выражается
через время решения вспомогательных
подзадач.
Затем данное рекуррентное уравнение решается с помощью
определенных математических методов, и устанавливаются
границы производительности алгоритма.

Рекуррентное уравнение(2)
Обозначим через T(n) время решения задачи,
размер которой равен n.
Если размер задачи достаточно мал
n<= с, где с — некоторая заранее известная константа,
то задача решается непосредственно в течение
определенного фиксированного времени, которое
мы обозначим через
Предположим, что наша задача делится на а
подзадач, объем каждой из которых равен
1/b от объема исходной задачи.

Рекуррентное уравнение(3)
Если разбиение задачи на вспомогательные
подзадачи происходит в течение времени
D(n), а объединение решений подзадач в
решение исходной задачи — в течение
времени С(n), то получим такое
рекуррентное соотношение:

Анализ алгоритма сортировки слиянием(1)
Сортировка одного элемента методом слияния
длится в течение фиксированного времени.
Если n > 1, время работы распределяется
таким образом.
Разбиение. В ходе разбиения определяется,
где находится средина подмассива.
Эта операция длится фиксированное время,
поэтому

Анализ алгоритма сортировки слиянием(2)
Покорение. Рекурсивно решаются две
подзадачи, объем каждой из которых
составляет n/2. Время решения этих
подзадач равно 2Т(n/2).
Комбинирование. Выше показано, что
процедура MERGE в n-элементном
подмассиве выполняется в течение времени
, поэтому .

Анализ алгоритма сортировки слиянием(3)
Сложив функции D(n) и С(n), получим сумму величин0
и которая является линейной функцией от
n, т.е.
Этап «покорения» занимает 2T(n/2).
В итоге время работы алгоритма сортировки
слиянием в наихудшем случае:

Решение рекуррентного уравнения
Перепишем уравнение в виде:
где константа с обозначает время, которое
требуется для решения задачи размер которой
равен 1, а также удельное (приходящееся на один
элемент) время, требуемое для разделения и
сочетания.
Для удобства предположим, что n равно степени
двойки.
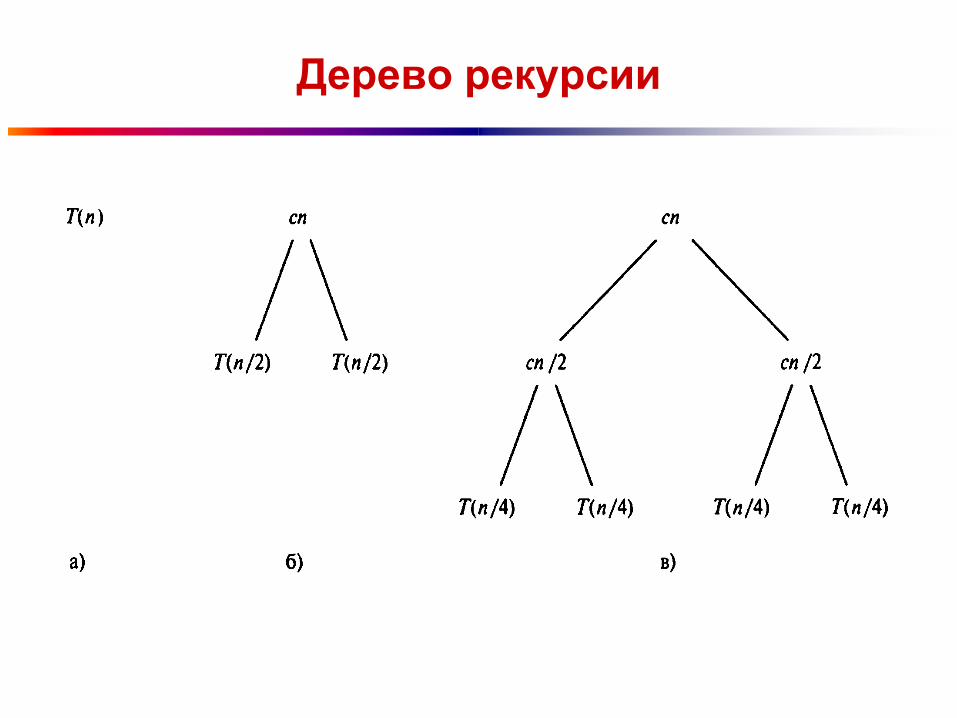
Дерево рекурсии
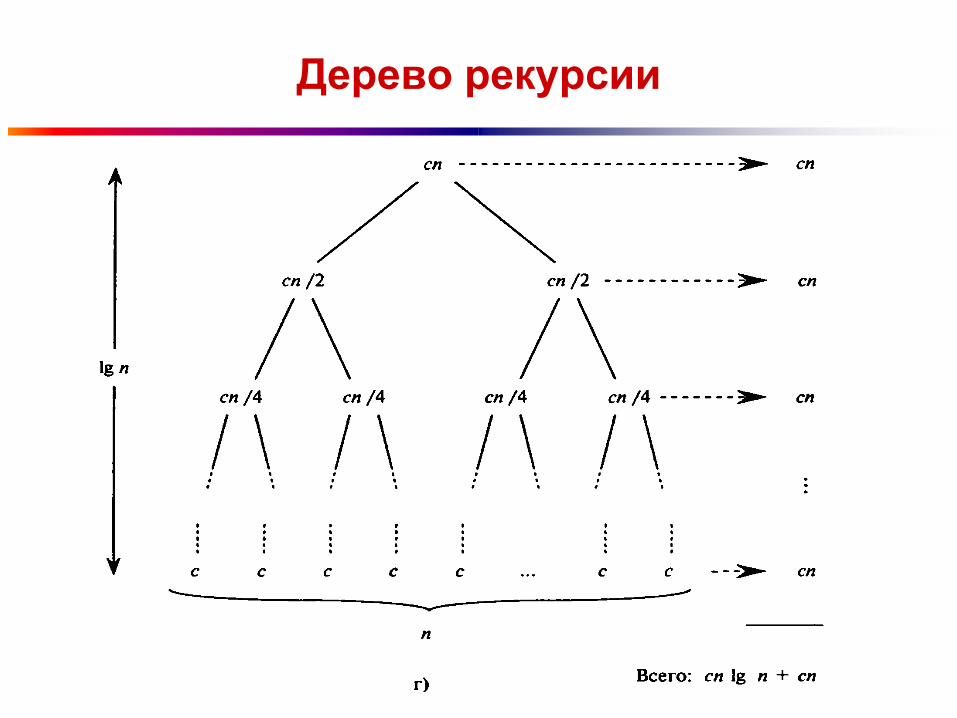
Дерево рекурсии

Ответ
Дерево состоит из lg(n) + 1 уровней (т.е. его
высота равна lg(n), а каждый уровень дает
вклад в полное время работы, равный с*n.
Таким образом, полное время работы
алгоритма равно сn*lg(n) + сn, что
соответствует

Спасибо за внимание!


















