
Variational Autoencoders - znu.ac.ircv.znu.ac.ir/afsharchim/DeepL/Variational Autoencoders.pdfIn...
16
Variational Autoencoders
Transcript of Variational Autoencoders - znu.ac.ircv.znu.ac.ir/afsharchim/DeepL/Variational Autoencoders.pdfIn...

Variational Autoencoders
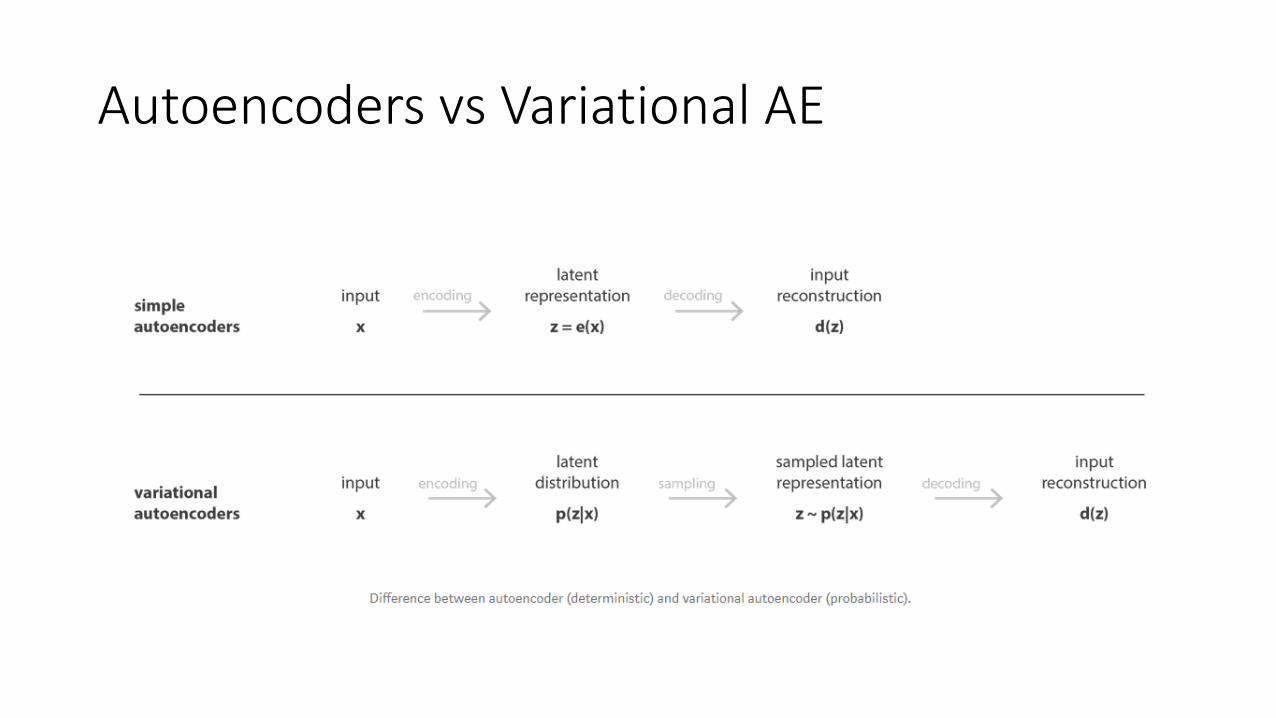
Autoencoders vs Variational AE
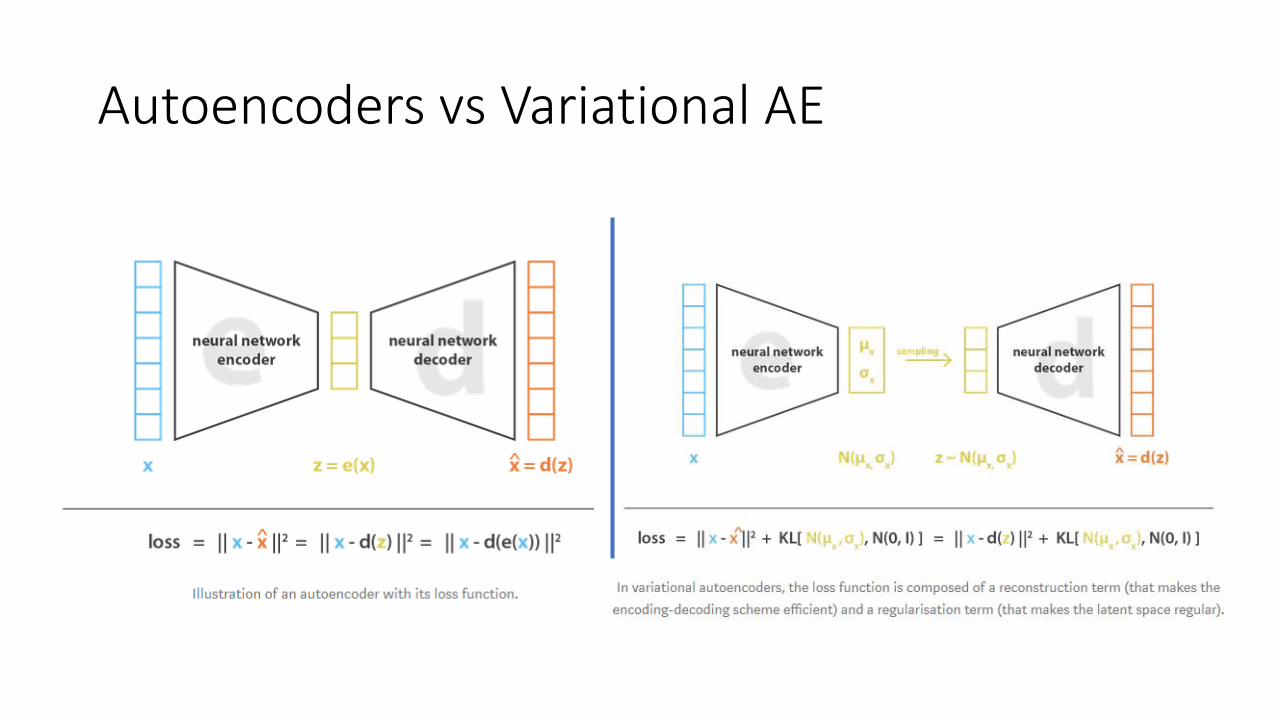
Autoencoders vs Variational AE
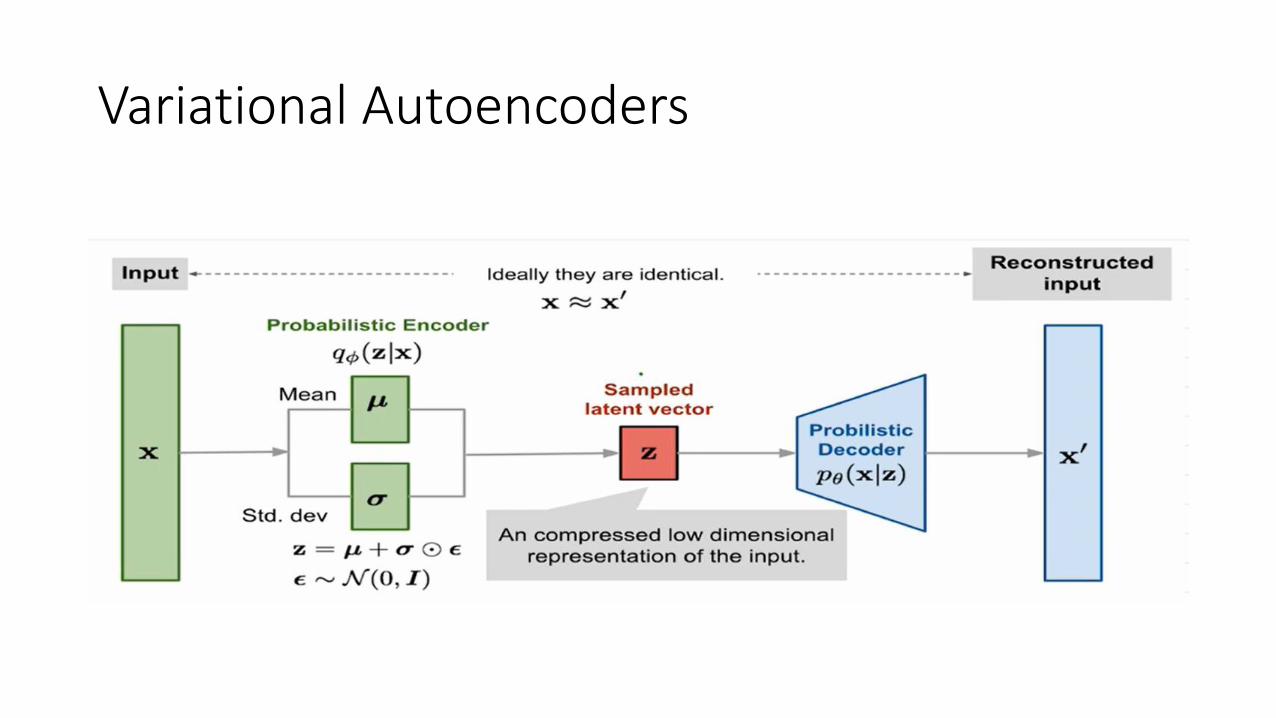
Variational Autoencoders
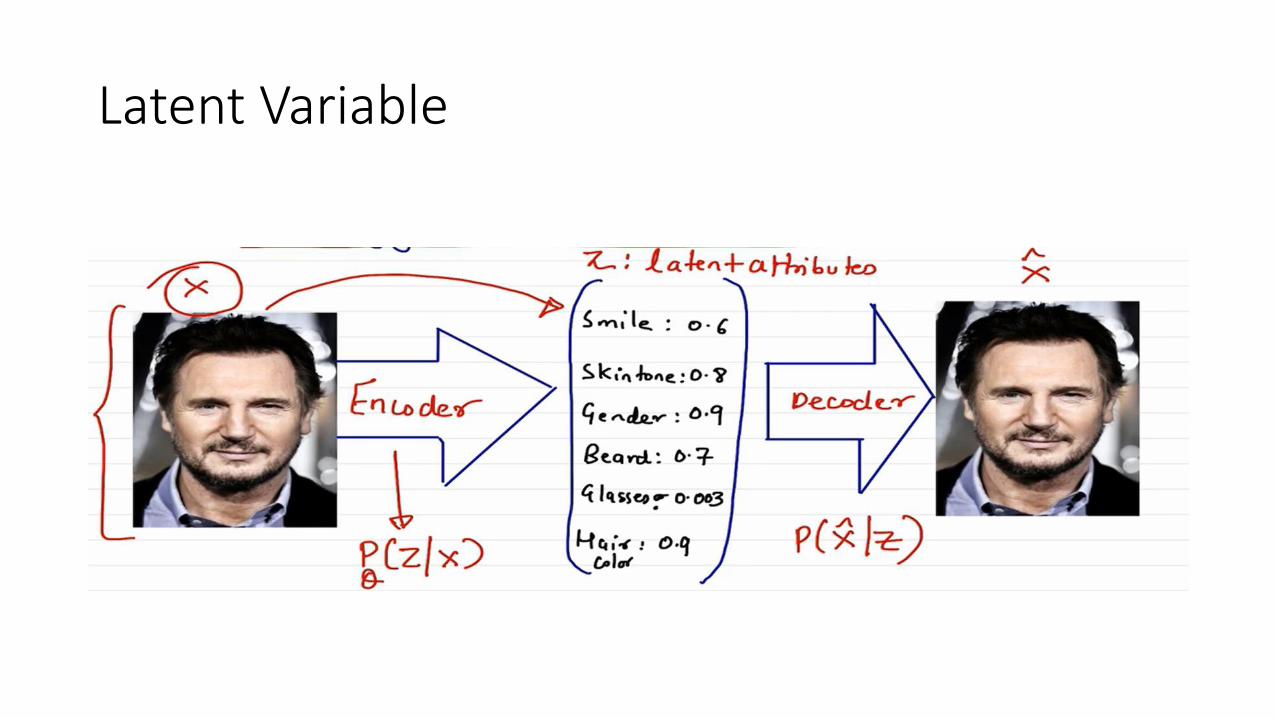
Latent Variable
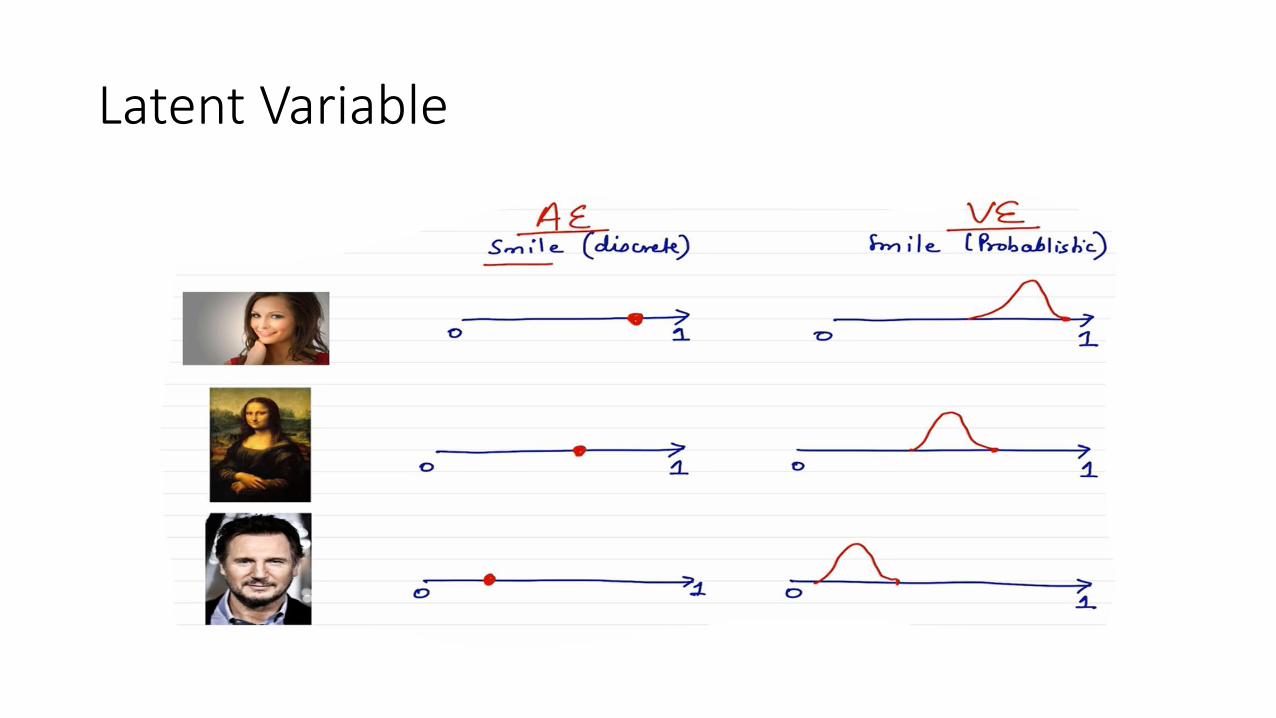
Latent Variable
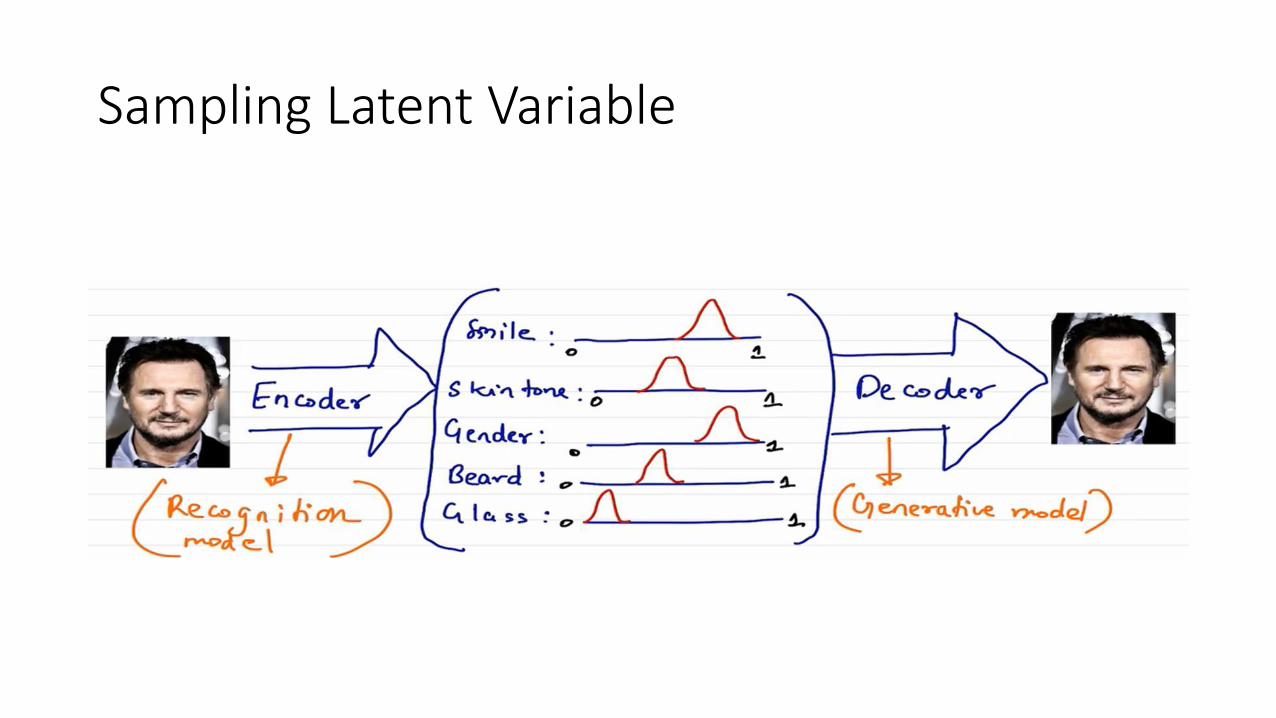
Sampling Latent Variable
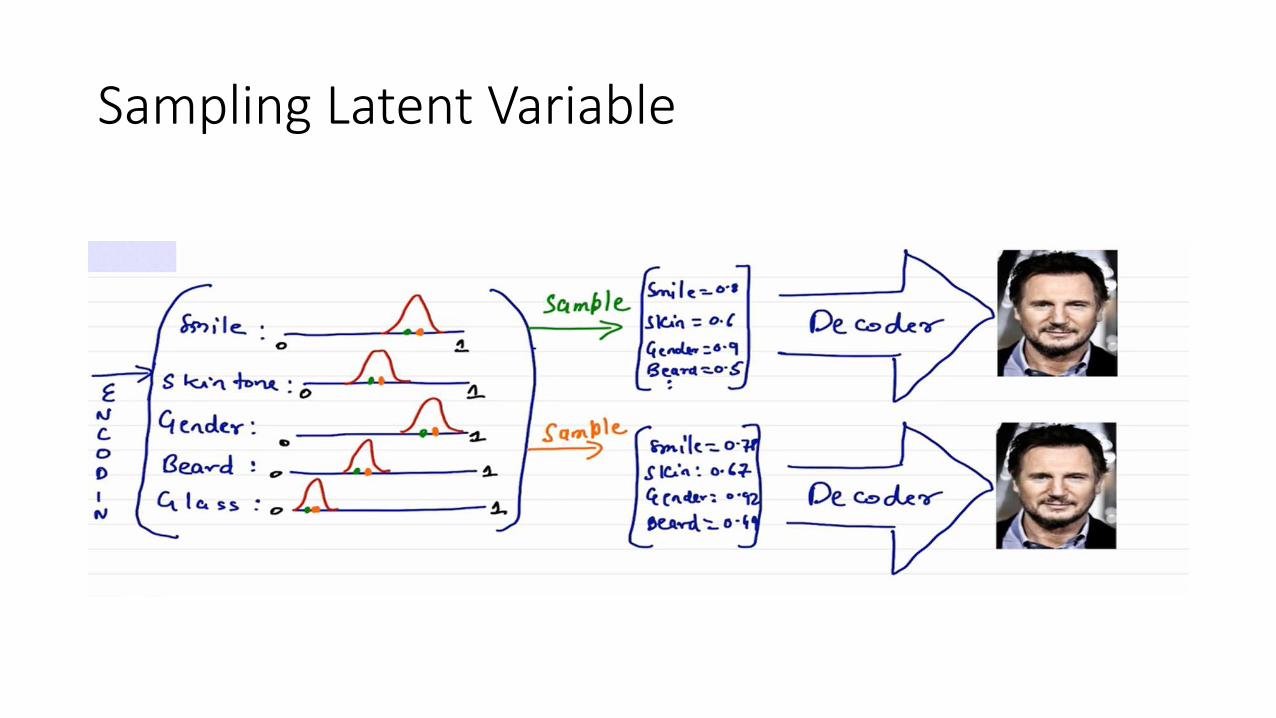
Sampling Latent Variable
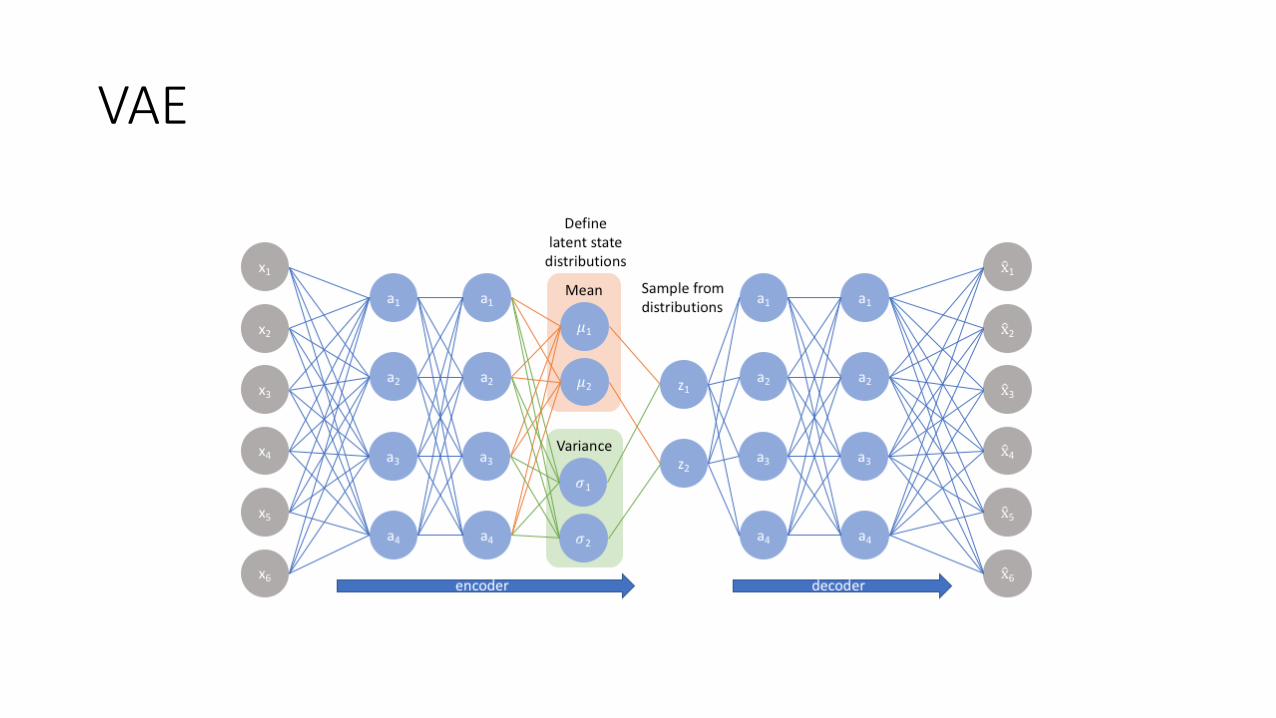
VAE

KL-Divergence
ENTROPY- If we use log2 for our calculation we can
interpret entropy as "the minimum number of bits it would take us to encode our information".
Essentially, what we're looking at with the KL divergence is the
expectation of the log difference between the probability of
data in the original distribution with the approximating
distribution. Again, if we think in terms of log2 we can interpret
this as "how many bits of information we expect to lose"

Deriving Loss Function

Deriving Loss Function

Loss Function
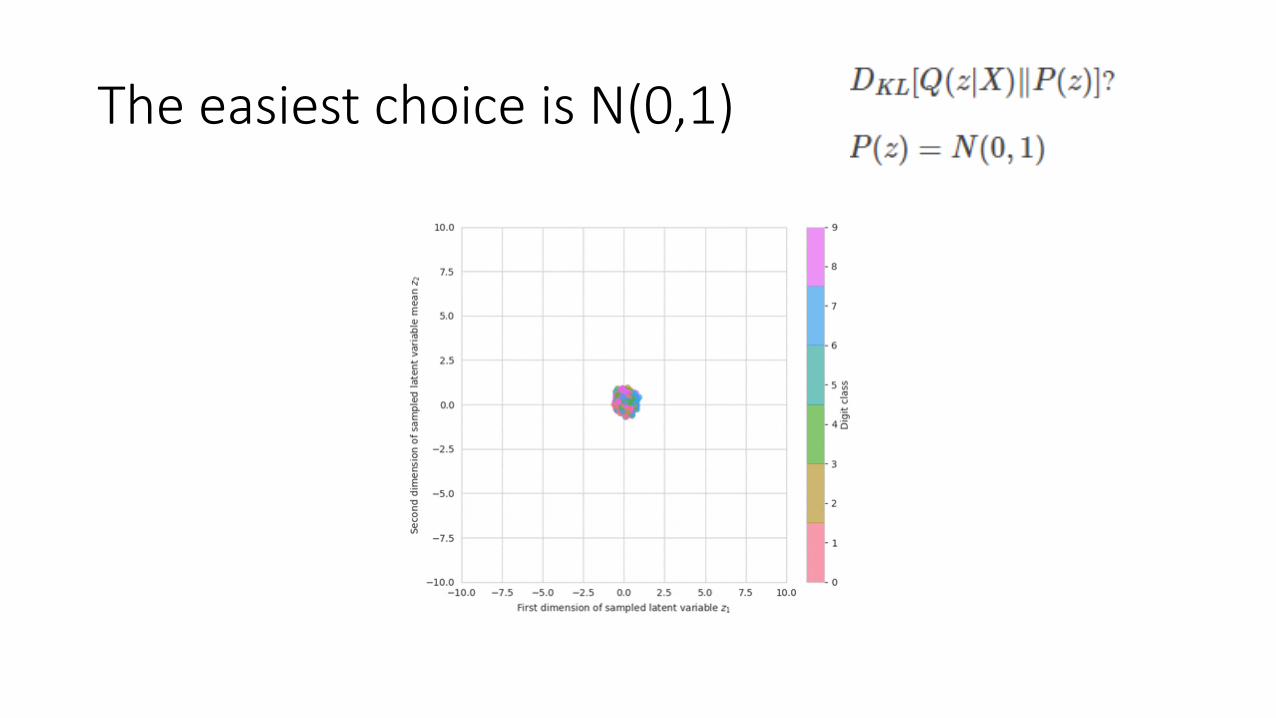
The easiest choice is N(0,1)

Keras-VAE

Keras-VAE


















