







Languages
Pages
Legal


GNU R, Google Analytics und Optimierung vonGoogle Adwords
Hinnerk Gnutzmann
data2day September 30, 2015

Zur Person: Hinnerk Gnutzmann
I Grunder flexponsive UG (haftungsbeschrankt)
I E-Commerce BeratungI Fokus auf Data AnalyticsI Qualitatives User Testing
I PhD Economics, European University Institute (2013)
I Kontakt
I mailto: [email protected] web: https://www.flexponsive.net/I t: @flexponsive

Worum geht es heute?I Erfolg von Marketing
I schwer zu definierenI noch schwerer zu messen
I Vor Big Data: “Half the money I spend on advertising iswasted; the trouble is I don’t know which half.” (JohnWanamaker, 1838–1922)
I Nach Big Data: “(AdWords) brand keyword ads have nomeasurable short-term benefits” (Blake et al., 2015) - 100%wasted?
I Viele offene FragenI Incrementality Debate: Verdrangen Kampagnen organische
Besucher?I Qualitat: Sind “gekaufte” Besucher gute oder schlechte
Kunden?I Heterogenitat: Wirken Kampagnen unterschiedlich nach
Kunde?

Worum geht es heute?I Erfolg von Marketing
I schwer zu definierenI noch schwerer zu messen
I Vor Big Data: “Half the money I spend on advertising iswasted; the trouble is I don’t know which half.” (JohnWanamaker, 1838–1922)
I Nach Big Data: “(AdWords) brand keyword ads have nomeasurable short-term benefits” (Blake et al., 2015) - 100%wasted?
I Viele offene FragenI Incrementality Debate: Verdrangen Kampagnen organische
Besucher?I Qualitat: Sind “gekaufte” Besucher gute oder schlechte
Kunden?I Heterogenitat: Wirken Kampagnen unterschiedlich nach
Kunde?

Worum geht es heute?I Erfolg von Marketing
I schwer zu definierenI noch schwerer zu messen
I Vor Big Data: “Half the money I spend on advertising iswasted; the trouble is I don’t know which half.” (JohnWanamaker, 1838–1922)
I Nach Big Data: “(AdWords) brand keyword ads have nomeasurable short-term benefits” (Blake et al., 2015) - 100%wasted?
I Viele offene FragenI Incrementality Debate: Verdrangen Kampagnen organische
Besucher?I Qualitat: Sind “gekaufte” Besucher gute oder schlechte
Kunden?I Heterogenitat: Wirken Kampagnen unterschiedlich nach
Kunde?

Agenda
1. Fallbeispiel Brand Keyword: Das Geheimnnis desverschwindenden ROI fur AdWords
2. Was kann man tun?
I AttributionsmodelleI Kontrollierte ExperimenteI GNU R & Google Analytics: Ein Dream Team
3. Wie gehts?
I Google Core Reporting API & GNU RI GA Query ExplorerI Experiment in AdWords konfigurieren
4. Analyse mit GNU R
I Data wrangling, sampling, etc.I GA Metriken replizierenI Regressionsanalyse
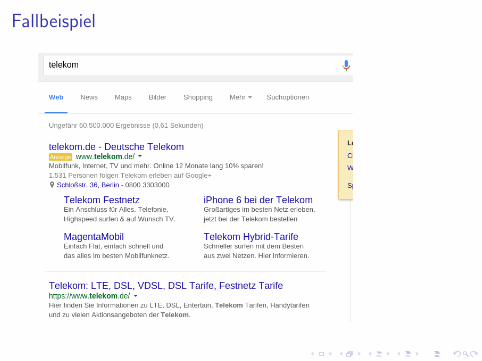
Fallbeispiel

Was ist passiert?
I Das AdWord ist hochgradig relevant fur die Suche
I Navigational Query: Der Besucher will zur TelekomI Hat sich bereits fur ein Telekom-Produkt entschieden?
I Ergebnis: Das “wohl beste” Keyword im Account
I Hervorragende CTRI Sehr gute Conversion on-siteI CPC vielleicht gar nicht mal so hoch
I Noch Fragen?
I Das organische Ergebnis ist das gleiche!I Was ware wenn. . . es nur das organische Ergebnis gabe?

Was ist passiert?
I Das AdWord ist hochgradig relevant fur die Suche
I Navigational Query: Der Besucher will zur TelekomI Hat sich bereits fur ein Telekom-Produkt entschieden?
I Ergebnis: Das “wohl beste” Keyword im Account
I Hervorragende CTRI Sehr gute Conversion on-siteI CPC vielleicht gar nicht mal so hoch
I Noch Fragen?
I Das organische Ergebnis ist das gleiche!I Was ware wenn. . . es nur das organische Ergebnis gabe?

Was ist passiert?
I Das AdWord ist hochgradig relevant fur die Suche
I Navigational Query: Der Besucher will zur TelekomI Hat sich bereits fur ein Telekom-Produkt entschieden?
I Ergebnis: Das “wohl beste” Keyword im Account
I Hervorragende CTRI Sehr gute Conversion on-siteI CPC vielleicht gar nicht mal so hoch
I Noch Fragen?
I Das organische Ergebnis ist das gleiche!I Was ware wenn. . . es nur das organische Ergebnis gabe?

Was sagt Google?

Die eBay Studie
I Blake et al. (2015), “Consumer Heterogeneity and PaidSearch Effectiveness: A Large Scale Field Experiment”
I Feldexperiment: Funktioniert AdWords fur eBay?I Sehr kontroverse Ergebnisse:
1. Click Substition: Wenn das Brand AdWord wegfallt, klickenfast alle Nutzer auf das organische Ergebnis
2. Informative Advertising: AdWords funktionieren, wenn Sieeinen Besucher uber ein Angebot informieren, von dem ernoch nichts wusste
I AdWords hat fast keinen Effekt auf Umsatze beiBestandskunden
I Hatten auch sonst den Weg zu eBay gefunden!

Was kann man tun? Attributionsmodelle

Was kann man tun? Kontrolliertes Experiment
I Nach Zufallsprinzip Behandlungs & Kontrollgruppeauswahlen, z.B.
I Pro Benutzer: A/B TestingI Nach geographischer Region
I Annahme: Ohne Experiment verhalten sich beide Gruppenahnlich
I Auswertung: difference in differences
I Unterschied in Kontrollgruppe: NoiseI Unterschied in Behandlungsgruppe: Effekt + Noise
I Metrik: ∆TREATED − ∆UNTREATED
I Vorteile geographisches Experiment:
I kein multi-device Tracking notwendigI einfache Integration mit externen DatenI komplizierte Customer Journeys konnen abgebildet werden
I Caveat: Geographische Gruppen mussen wirklich vergleichbarsein, mobile Benutzer

GNU R und Google Analytics: Dream Team
1. Auswahl der Behandlungs- und Kontrollgruppe
I R installieren, Sample mit GNU R erzeugenI Export: Copy&paste zu AdWords
2. Datensammlung: macht Marketing!
I Google Analytics oft schon vorhanden und konfiguriert
3. Aggregierung und Abfrage
I In der Cloud: Google Analytics mit Query ExplorerI Integration mit RGoogleAnalytics
4. Auswertung: Schatzung und Visualisierung
I Alle notwendigen Funktionen als Pakete in R vorhanden

R installieren
I Open Source fur Windows/Mac/Linux etc.
I GNU R: https://www.r-project.org/I RStudio IDE: http://www.rstudio.com
I Cheat Sheets helfen weiter!
I R Reference CardI https://www.rstudio.com/resources/cheatsheets/
I Paketmanagement uber CRAN
install.package(’RGoogleAnalytics’)
install.package(’plm’);
install.package(’ggplot2’);

Behandlungsgruppe erzeugen
download.file(’https://goo.gl/9ENFV7’,
destfile=’geoid.csv’);
regions <- read.csv(’geoid.csv’);
states<-regions[which(regions$Country.Code == ’DE’
& regions$Target.Type == ’State’
& regions$Status == ’Active’),];
set.seed(1);
states$isTreatment <- sample(c(0,1),
nrow(states), replace =T)
write.csv(states, file=’states.csv’);
# paste into AdWords
writeLines(as.vector(
states[which(states$isTreatment == ’1’),]$Canonical.Name),
file(’treatment.csv’));
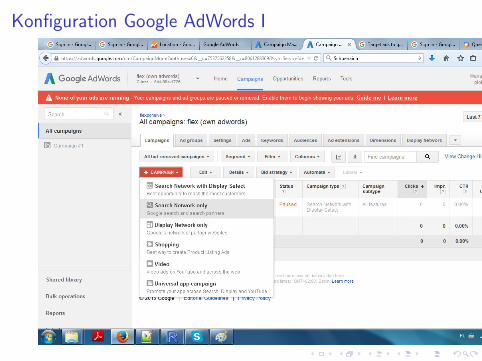
Konfiguration Google AdWords I
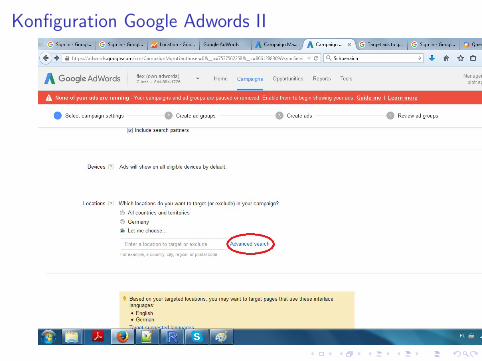
Konfiguration Google Adwords II
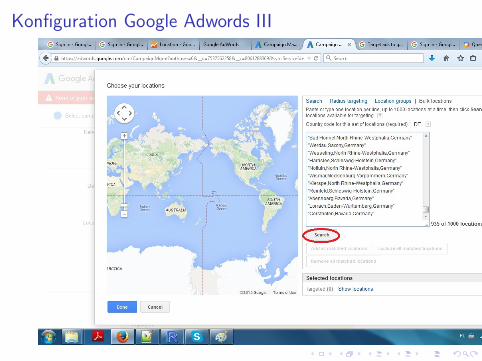
Konfiguration Google Adwords III
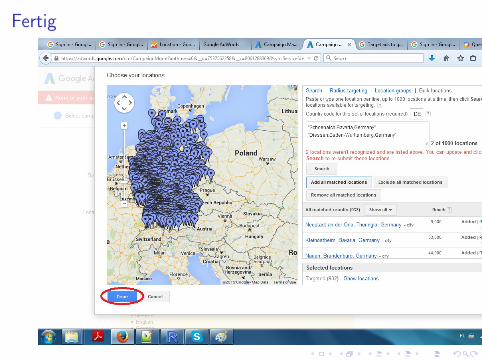
Fertig

Warten
. . . auf die Ergebnisse
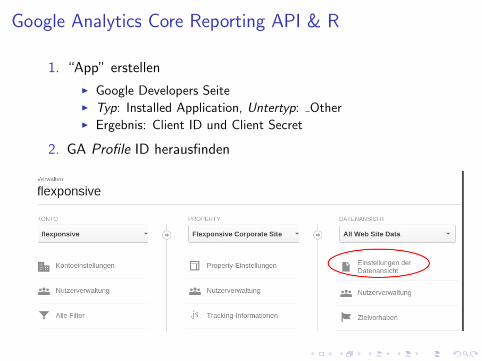
Google Analytics Core Reporting API & R
1. “App” erstellen
I Google Developers SeiteI Typ: Installed Application, Untertyp: OtherI Ergebnis: Client ID und Client Secret
2. GA Profile ID herausfinden
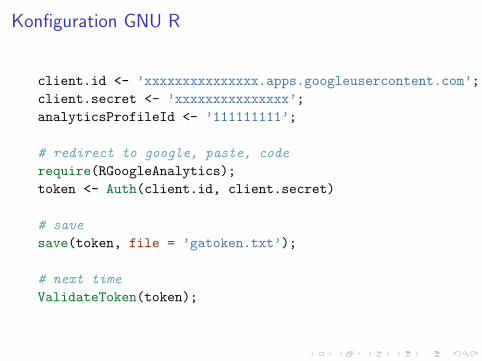
Konfiguration GNU R
client.id <- ’xxxxxxxxxxxxxxx.apps.googleusercontent.com’;
client.secret <- ’xxxxxxxxxxxxxxx’;
analyticsProfileId <- ’111111111’;
# redirect to google, paste, code
require(RGoogleAnalytics);
token <- Auth(client.id, client.secret)
# save
save(token, file = ’gatoken.txt’);
# next time
ValidateToken(token);
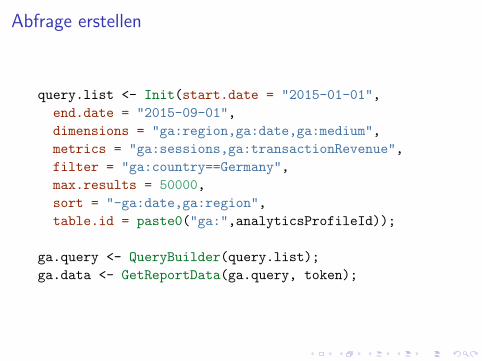
Abfrage erstellen
query.list <- Init(start.date = "2015-01-01",
end.date = "2015-09-01",
dimensions = "ga:region,ga:date,ga:medium",
metrics = "ga:sessions,ga:transactionRevenue",
filter = "ga:country==Germany",
max.results = 50000,
sort = "-ga:date,ga:region",
table.id = paste0("ga:",analyticsProfileId));
ga.query <- QueryBuilder(query.list);
ga.data <- GetReportData(ga.query, token);
Tip: Query Explorer

Tip: Sampling vermeiden
> ga.data <- GetReportData(ga.query, token)
Status of Query:
The API returned 1393 results
The query response contains sampled data. It is based on
XX.XX % of your visits. You can split the query day-wise
in order to reduce the effect of sampling.
Set split_daywise = T in the GetReportData function
Note that split_daywise = T will automatically ....
I “Sampling occurs automatically when more than 500,000sessions (25M for Premium) are collected for a report,allowing Google Analytics to generate reports more quickly forthose large data sets.”

Datenintegration
I Wide Format: fur jede Region und Zeit eine ZeileI Long Format: Region/Zeit/Dimensionen je eine Zeile (EAV)
require(reshape2);
w<- reshape(ga.data, timevar=’medium’,
idvar = c(’region’,’date’), direction=’wide’);

Datenintegration: Fast fertig
I Merge: Wer ist in welcher Gruppe?
ds <- merge(w, states[,c(’Name’,’isTreatment’)],
by.x = ’region’, by.y = ’Name’, all.x = T)
I Datenset steht bereit!
I Komfortable DSL zur DatenmanipulationI Nutzung von Paketen um Code zu minimieren

Auswertung
I Kunstliche Daten zur Illustration: 90 Tage
I 50. Tag: Experiment startet in 8 Bundeslandern - AdWords ausI 50. Tag: Ebenfalls Saisonende, Suchvolumen fallt uberall 50%
I Szenario: 100% der Besucher klicken organisch, wenn dasAdWord wegfallt
I Beispiellander - Randomisierung hat entschieden:
I Bayern: Im Experiment, ab 50. Tag keine AdWordsI Bremen: Nimmt nicht teil, AdWords laufen weiter
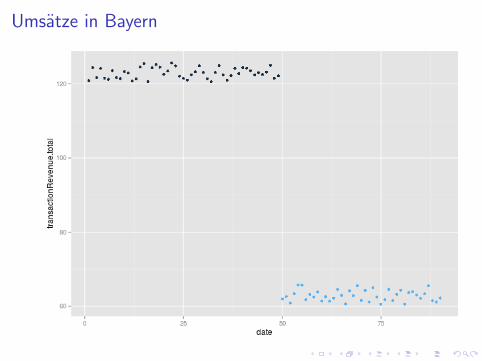
Umsatze in Bayern
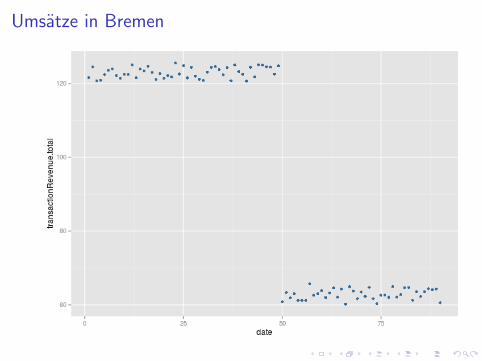
Umsatze in Bremen
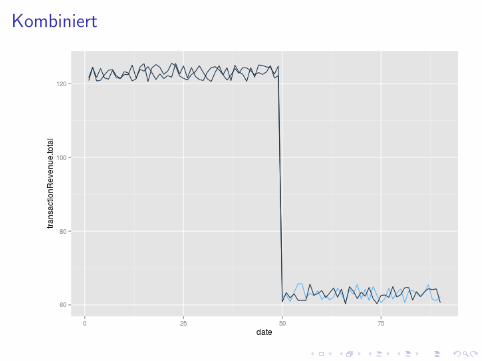
Kombiniert
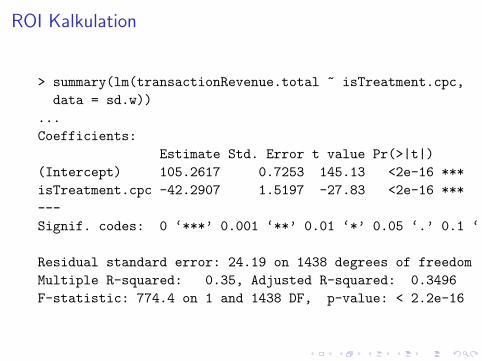
ROI Kalkulation
> summary(lm(transactionRevenue.total ~ isTreatment.cpc,
data = sd.w))
...
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 105.2617 0.7253 145.13 <2e-16 ***
isTreatment.cpc -42.2907 1.5197 -27.83 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 24.19 on 1438 degrees of freedom
Multiple R-squared: 0.35, Adjusted R-squared: 0.3496
F-statistic: 774.4 on 1 and 1438 DF, p-value: < 2.2e-16

Differences in Differences
> require(plm)
> summary(plm(transactionRevenue.total ~ isTreatment.cpc,
data=sd.w, index=c("region", "date"), model="between"))
Coefficients :
Estimate Std. Error t-value Pr(>|t|)
(Intercept) 95.657436 0.052508 1821.7609 <2e-16 ***
isTreatment.cpc -0.125488 0.163005 -0.7698 0.4542
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Total Sum of Squares: 0.32187
Residual Sum of Squares: 0.3088
R-Squared : 0.040613
Adj. R-Squared : 0.035536
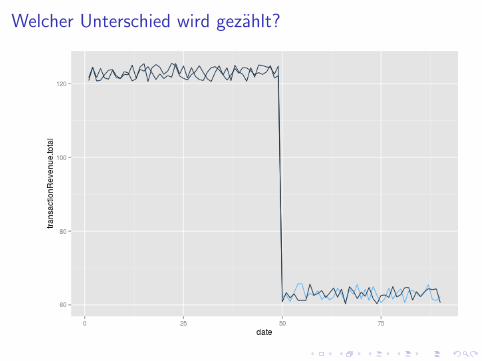
Welcher Unterschied wird gezahlt?

Diskussion
I Grundproblem: The Missing Counterfactual
I wir wissen nicht, was sonst passiert sein konnteI Hilfe: Experiment
I Herausfoderung: Big Data without Big Code
I Google Analytics & GNU RI Sehr reiche Toolbox
I Ergebnis: Differences in Differences kann funktionieren
I Annahmen beachtenI Viel mit den Daten arbeiten
Top Related