







Languages
Pages
Legal


Sadayuki FuruhashiFounder & Software Architect
Treasure Data, inc.
Understanding
Presto meetup @ Tokyo #1
Presto

A little about me...> Sadayuki Furuhashi
> github/twitter: @frsyuki > Treasure Data, Inc.
> Founder & Software Architect
> Open-source hacker > MessagePack - Efficient object serializer > Fluentd - An unified data collection tool > Prestogres - PostgreSQL protocol gateway for Presto > Embulk - A bulk data loader with plugin-based architecture > ServerEngine - A Ruby framework to build multiprocess servers > LS4 - A distributed object storage with cross-region replication > kumofs - A distributed strong-consistent key-value data store

Today’s talk
1. Distributed & plug-in architecture
2. Query planning
3. Cluster configuration
4. Recent updates

1. Distributed & Plug-in architecture

ClientCoordinator Connector
Plugin
Worker
Worker
Worker
Storage / Metadata
Discovery Service

ClientCoordinator Connector
Plugin
Worker
Worker
Worker
Storage / Metadata
Discovery Service1. find servers in a cluster

ClientCoordinator Connector
Plugin
Worker
Worker
Worker
Storage / Metadata
Discovery Service
2. Client sends a query using HTTP

ClientCoordinator Connector
Plugin
Worker
Worker
Worker
Storage / Metadata
Discovery Service
3. Coordinator builds a query plan
Connector plugin provides metadata (table schema, etc.)
ClientCoordinator Connector
Plugin
Worker
Worker
Worker
Storage / Metadata
Discovery Service
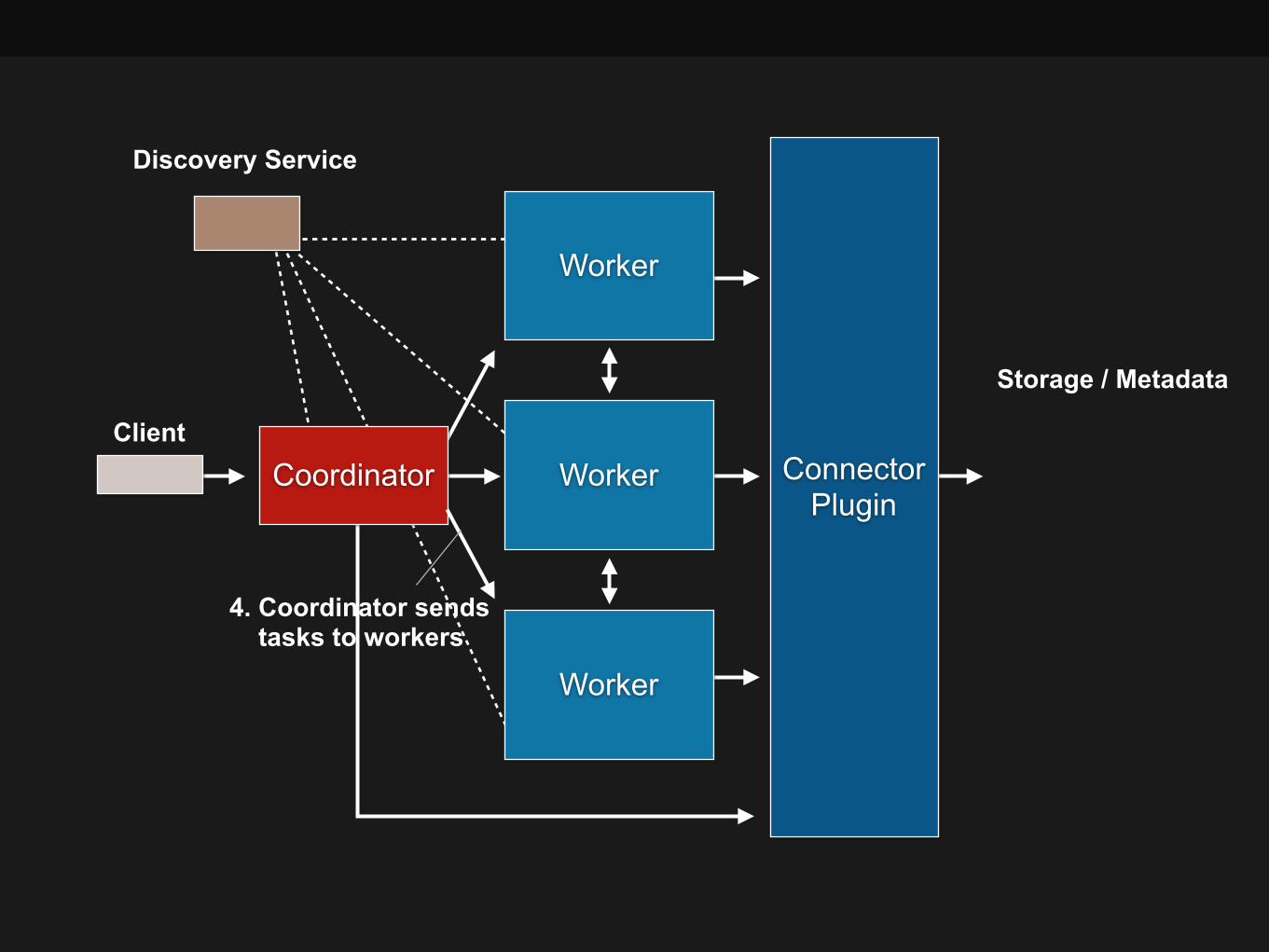
4. Coordinator sends tasks to workers

ClientCoordinator Connector
Plugin
Worker
Worker
Worker
Storage / Metadata
Discovery Service
5. Workers read data through connector plugin

ClientCoordinator Connector
Plugin
Worker
Worker
Worker
Storage / Metadata
Discovery Service
6. Workers run tasks in memory
Coordinator ConnectorPlugin
Worker
Worker
Worker
Storage / Metadata
Discovery Service
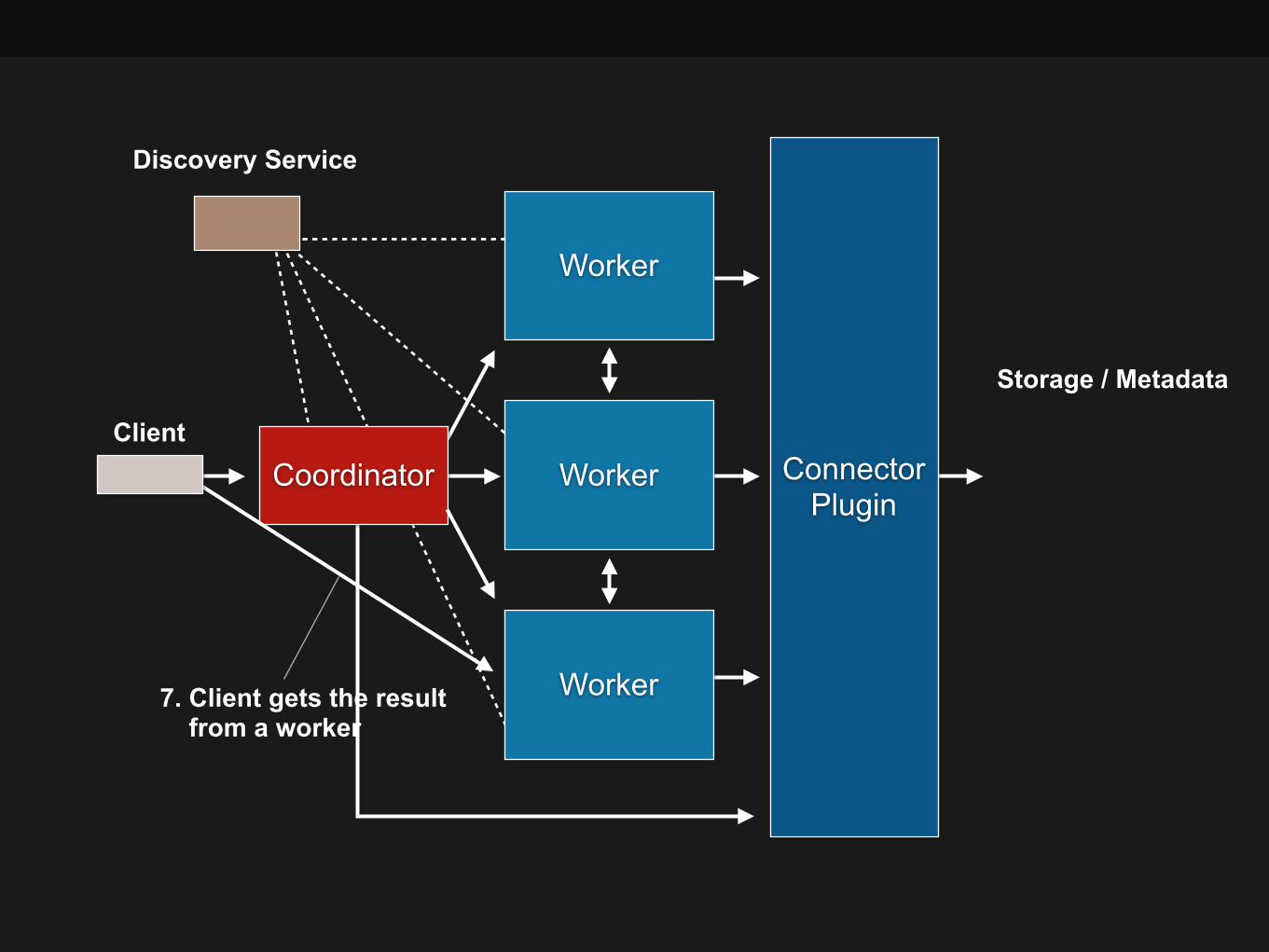
7. Client gets the result from a worker
Client

ClientCoordinator Connector
Plugin
Worker
Worker
Worker
Storage / Metadata
Discovery Service

ClientCoordinator
Worker
Worker
Worker
Discovery Service
otherconnectors
...
PostgreSQL
Hive Connector
HDFS / Metastore
JDBC Connector
Other data sources...

PostgreSQL
HDFS / Metastore
MySQL
Presto
select orderkey, orderdate, custkey, email from orders join mysql.presto_test.users on orders.custkey = users.id order by custkey, orderdate;
JOIN

PostgreSQL
HDFS / Metastore
MySQL
Presto
JOININSERT INTO
create table mysql.presto_test.recent_user_infoas select users.id, users.email, count(1) as count from orders join mysql.presto_test.users on orders.custkey = users.id group by 1, 2;

1. Distributed & Plug-in architecture> 3 type of servers
> Coordinator, Worker, Discovery server > Get data/metadata through connector plugins.
> Presto is state-less (Presto is NOT a database). > Presto can provide distributed SQL to any data stores.
• connectors are loosely-coupled (may cause some overhead here)
> Client protocol is HTTP + JSON > Language bindings: Ruby, Python, PHP, Java, R, etc.
> ODBC & JDBC support by Prestogres > https://github.com/treasure-data/prestogres

Other Presto’s features
> Comprehensive SQL features > WITH cte as (SELECT …) SELECT * FROM cte …; > implicit JOIN (join criteria at WHERE) > VIEW > INSERT INTO … VALUES (1,2,3) > Time & Date types & functions
compatible both MySQL & PostgreSQL > Culster management using SQL
> SELECT * FROM sys.node; > sys.task, sys.query

2. Query Planning

Presto’s execution model
> Presto is NOT MapReduce > Presto’s query plan is based on DAG
> more like Spark or traditional MPP databases
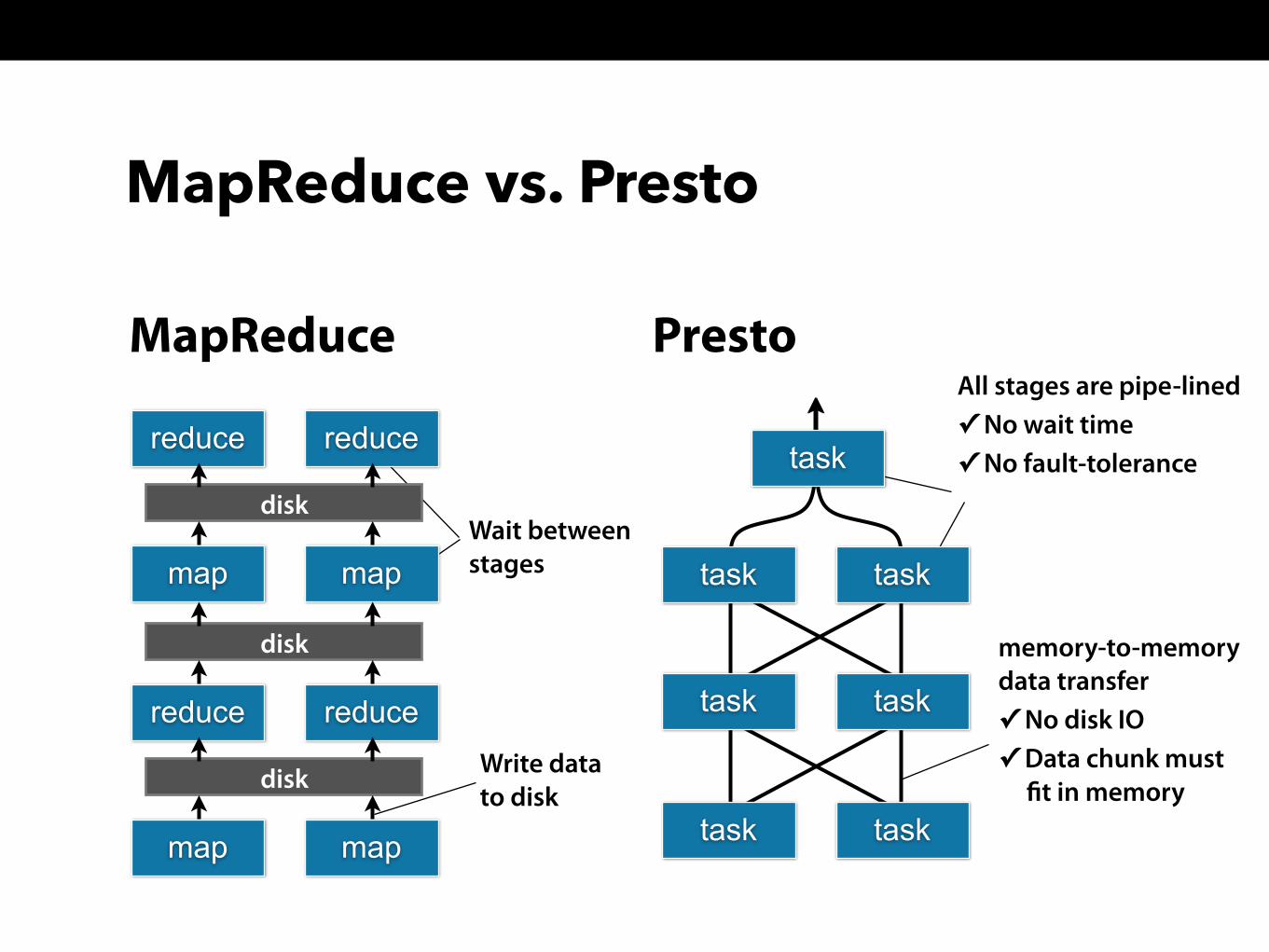
All stages are pipe-lined ✓ No wait time ✓ No fault-tolerance
MapReduce vs. Presto
MapReduce Presto
map map
reduce reduce
task task
task task
task
task
memory-to-memory data transfer ✓ No disk IO ✓ Data chunk must fit in memory
task
disk
map map
reduce reduce
disk
disk
Write datato disk
Wait betweenstages
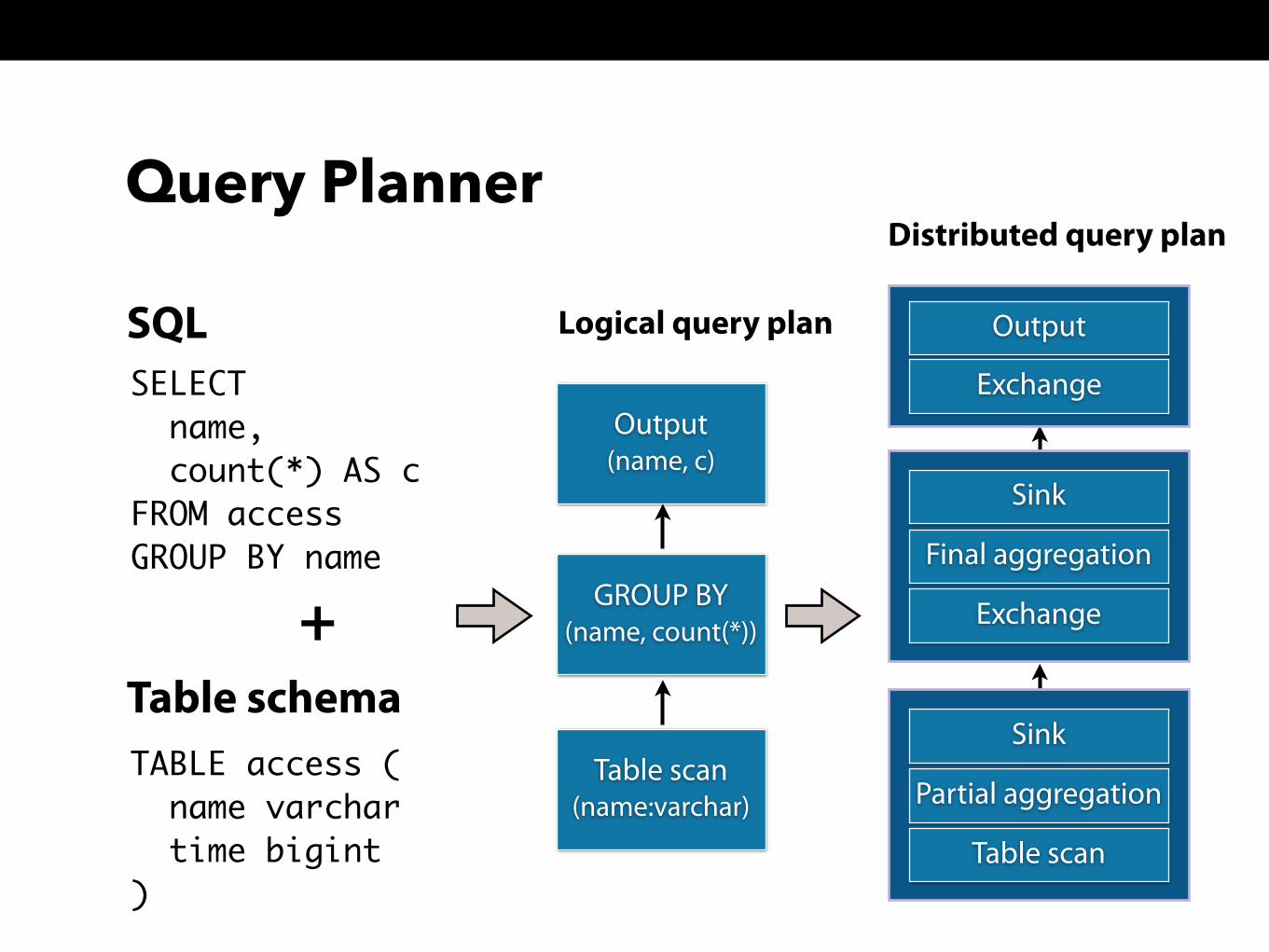
Query Planner
SELECT name, count(*) AS c FROM access GROUP BY name
SQL
TABLE access ( name varchar time bigint)
Table schemaTable scan
(name:varchar)
GROUP BY (name, count(*))
Output (name, c)
+
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Output
Exchange
Logical query plan
Distributed query plan

Query Planner - Stages
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Output
Exchange
inter-worker data transfer
pipelined aggregation
inter-worker data transfer
Stage-0
Stage-1
Stage-2

Sink
Partial aggregation
Table scan
Sink
Partial aggregation
Table scan
Execution Planner
+ Node list✓ 2 workers
Sink
Final aggregation
Exchange
Output
Exchange
Sink
Final aggregation
Exchange
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Output
Exchange
Worker 1 Worker 2
node-scheduler.min-candidates=2query.initial-hash-partitions=2node-scheduler.multiple-tasks-per-node-enabled

Execution Planner - Tasks
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Task1 task / worker / stage
Output
Exchange
Worker 1 Worker 2
if node-scheduler.multiple-tasks-per-node-enabled=false

Execution Planner - Split
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Sink
Final aggregation
Exchange
Sink
Partial aggregation
Table scan
Output
Exchange
Split
many splits / task = many threads / worker (table scan)
1 split / task = 1 thread / worker
Worker 1 Worker 2
1 split / worker = 1 thread / worker

2. Query Planning
> SQL is converted into stages, tasks and splits > All tasks run in parallel
> No wait time between stages (pipelined) > If one task fails, all tasks fail at once (query fails)
> Memory-to-memory data transfer > No disk IO > If hash-partitioned aggregated data doesn’t fit in memory,
query fails • Note: Query dies but worker doesn’t die.
Memory consumption is fully managed.

3. Cluster Configuration

coordinator=true node-scheduler.include-coordinator=true discovery-server.enabled=true
Single-server
client
> Most simple
Coordinator +
Discovery Server+
Worker
✓ Task scheduling ✓ Failure detection ✓ Table scan ✓ Aggregation

coordinator=false discovery.uri=http://the-coordinator.net:8080
coordinator=true node-scheduler.include-coordinator=false discovery-server.enabled=true
Multi-worker cluster
client
Worker
Worker
> More performance
Coordinator +
Discovery Server
✓ Table scan ✓ Aggregation
✓ Task scheduling ✓ Failure detection

coordinator=false discovery.uri=http://the-discovery.net:8080
coordinator=true node-scheduler.include-coordinator=false discovery-server.enabled=false discovery.uri=http://the-discovery.net:8080
Multi-worker cluster with separated Discovery Server
client
Worker
Worker
Discovery Server
https://repo1.maven.org/maven2/io/airlift/discovery/discovery-server/1.20/discovery-server-1.20.tar.gz
> More reliable
✓ Failure detection
✓ Task scheduling
✓ Table scan ✓ Aggregation
Coordinator

coordinator=false discovery.uri=http://the-discovery.net:8080
coordinator=true node-scheduler.include-coordinator=false discovery-server.enabled=false discovery.uri=http://the-discovery.net:8080
Multi-coordinator cluster
client
Worker
Worker
Discovery Server
Coordinator
Coordinator
HA by failover(or load-balance)
> Most reliable
✓ Table scan ✓ Aggregation

4. Recent Updates

Recent updates
> Presto 0.75 (2014-08-21) > max_by(col, compare_col) aggregation function
> Presto 0.76 (2014-09-18) > MySQL, PostgreSQL and Kafka connectors
> Presto 0.77 (2014-10-01) > Distributed JOIN
• enabled if distributed-joins-enabled=true

Recent updates> Presto 0.78 (2014-10-08)
> ARRAY, MAP and JSON types • json_extract(json, json_path) • json_array_get(json, index) • array || array • contains(array, search_key)
> Presto 0.80 (2014-11-03) > Optimized ORCFile reader
• enabled if hive.optimized-reader.enabled=true > Metadata-only queries
• count(), count(distinct), min(), max(), etc. > numeric_histogram(buckets, col) aggregation function

Recent updates
> Presto 0.86 (2014-12-01) > ntile(n) window function
> Presto 0.87 (2014-12-03) > JDK >= 8
> Presto 0.88 (2014-12-11) > Any aggregation functions can be a window function
> Presto 0.90 (soon) > ConnectorPageSink SPI > year_of_week() function

Check: www.treasuredata.com
Cloud service for the entire data pipeline, including Presto. We’re hiring!


Top Related