







Languages
Pages
Legal


Themis An I/O-Efficient MapReduce
Alex Rasmussen, Michael Conley, Rishi Kapoor, Vinh The Lam, George Porter, Amin Vahdat*
University of California San Diego *& Google, Inc. ���
�������������������� �����
1

MapReduce is Everywhere First published in OSDI 2004 De facto standard for large-scale bulk
data processing Key benefit: simple programming model,
can handle large volume of data
2

I/O Path Efficiency I/O bound, so disks are bottleneck Existing implementations do a lot of disk I/O – Materialize map output, re-read during shuffle – Multiple sort passes if intermediate data large – Swapping in response to memory pressure
Hadoop Sort 2009: <3MBps per node (3% of single disk’s throughput!)
3

How Low Can You Go? Agarwal and Vitter: minimum of two reads and
two writes per record for out-of-core sort Systems that meet this
lower bound have the “2-IO property”
MapReduce has sort in the middle, so same principle can apply
4

Themis Goal: Build a MapReduce implementation with
the 2-IO property TritonSort (NSDI ’11): 2-IO sort – World record holder in large-scale sorting
Runs on a cluster of machines with many disks per machine and fast NICs
Performs wide range of I/O-bound MapReduce jobs at nearly TritonSort speeds
5

Outline Architecture Overview Memory Management Fault Tolerance Evaluation
6

7
Network
Phase One Map and Shuffle

Map
Network
8
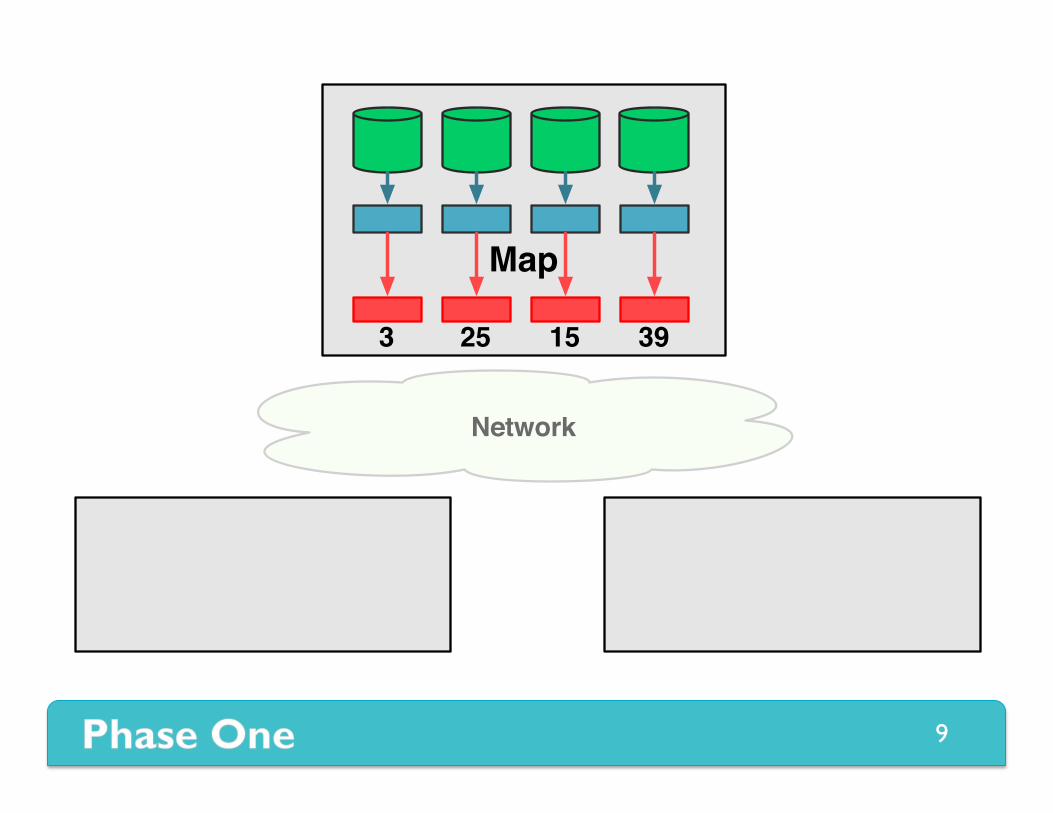
Map
3 3925 15
Network
9
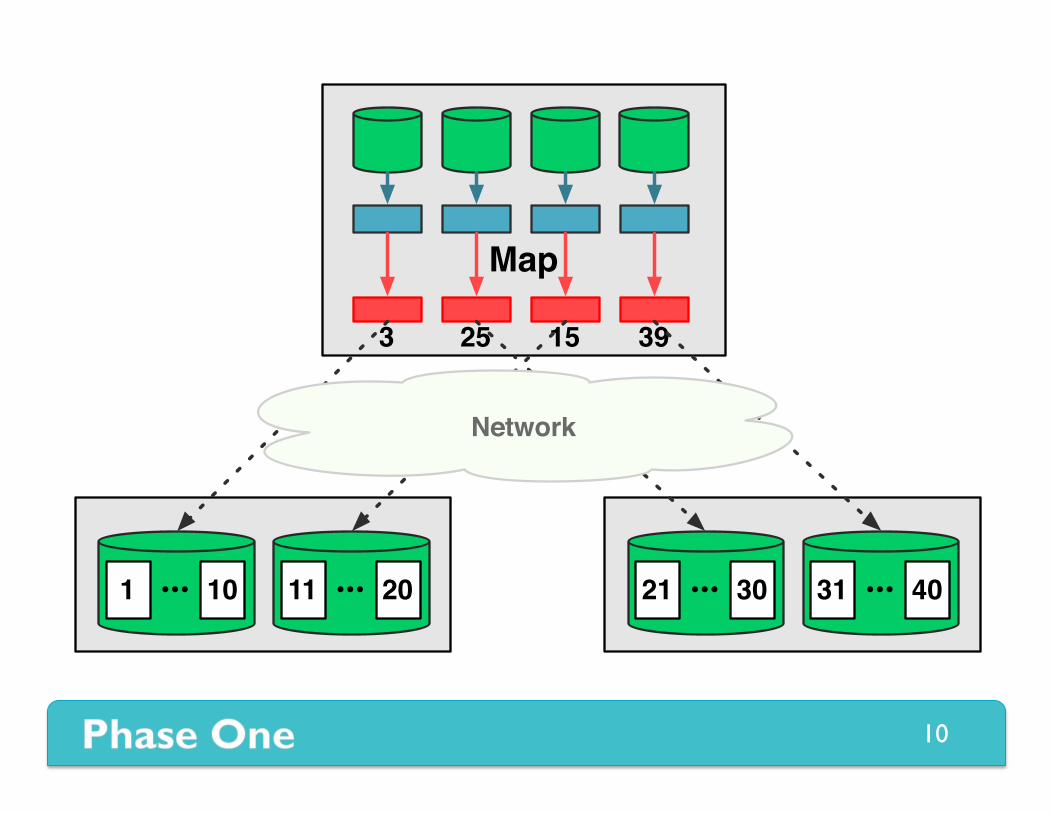
Map
3 3925 15
1 10 11 20••• ••• 21 30 31 40••• •••
Network
10
Map
3 3925 15
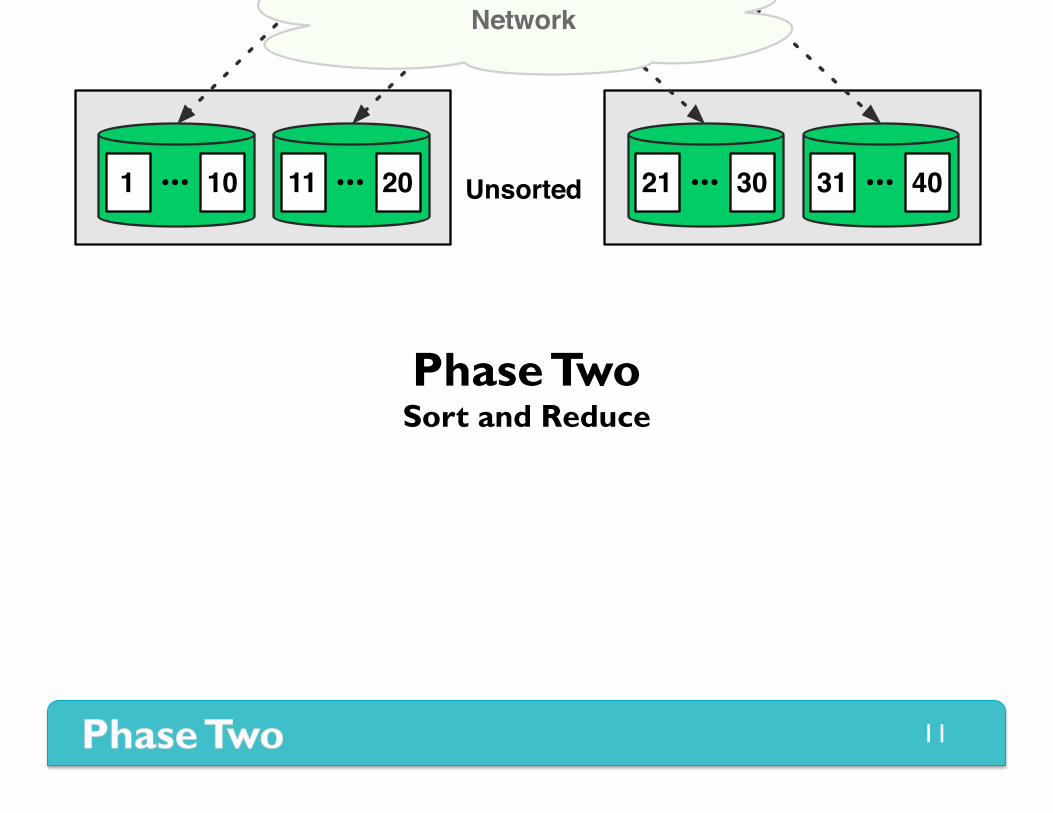
1 10 11 20••• ••• 21 30 31 40••• •••Unsorted
Network
11
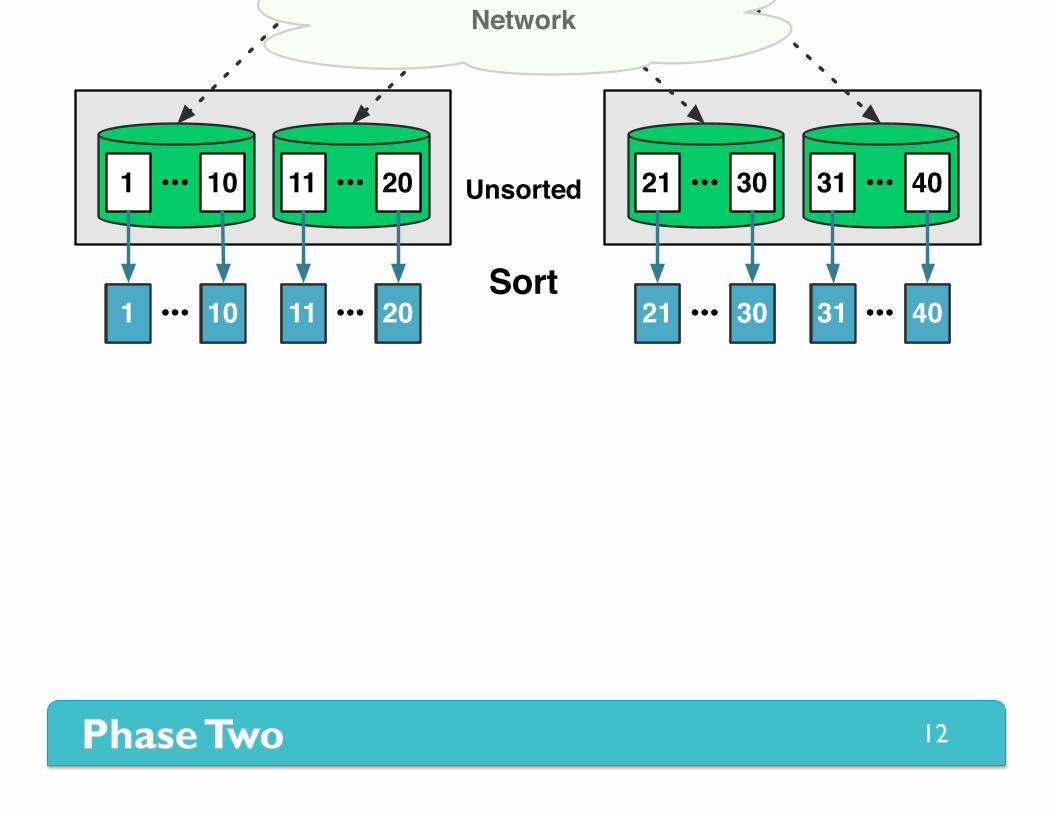
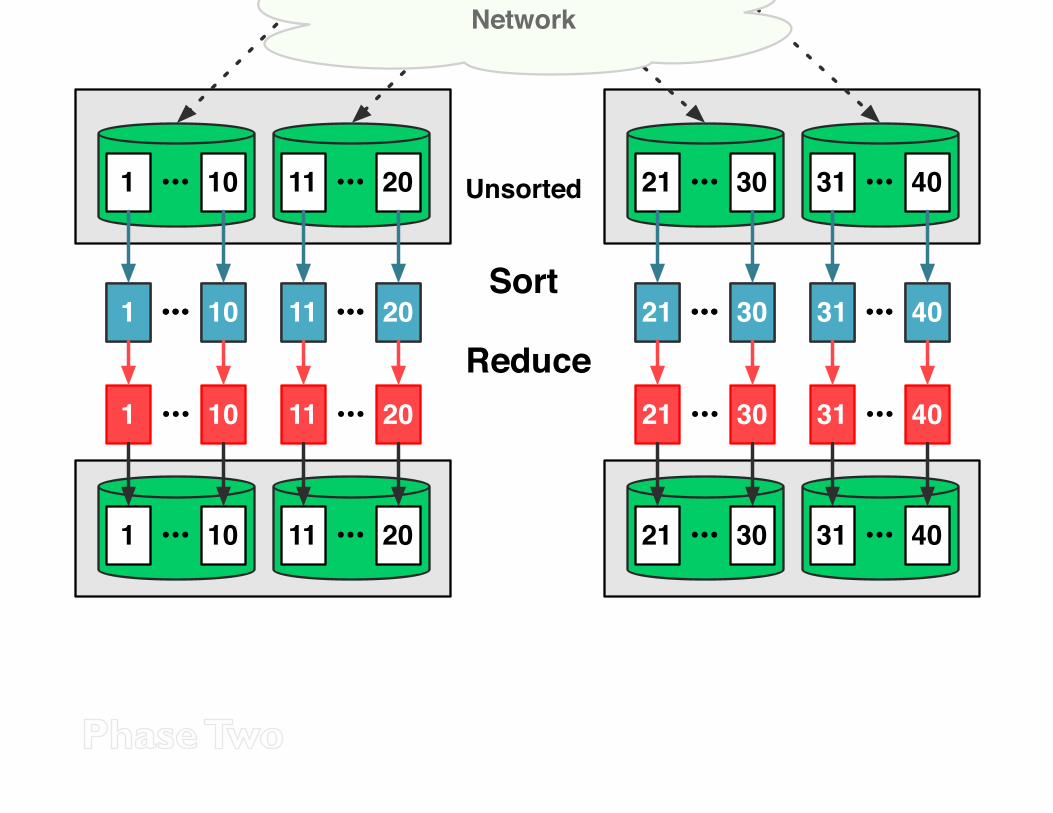
Phase Two Sort and Reduce
Map
3 3925 15
1 10 11 20••• ••• 21 30 31 40••• •••
1 10 11 20 21 30 31 40••• ••• ••• •••1 10 11 20 21 30 31 40••• ••• ••• •••
Unsorted
Network
Sort
12

Map
3 3925 15
1 10 11 20••• ••• 21 30 31 40••• •••
1 10 11 20 21 30 31 40••• ••• ••• •••1 10 11 20 21 30 31 40••• ••• ••• •••
1 10 11 20 21 30 31 40••• ••• ••• •••
Unsorted
Reduce
Network
Sort
13
Map
3 3925 15
1 10 11 20••• ••• 21 30 31 40••• •••
1 10 11 20 21 30 31 40••• ••• ••• •••1 10 11 20 21 30 31 40••• ••• ••• •••
1 10 11 20 21 30 31 40••• ••• ••• •••
Unsorted
Reduce
Network
1 10 11 20 21 30 31 40••• ••• ••• •••
Sort
14

Reader Byte Stream Converter Mapper
Sender Receiver Byte Stream Converter
Tuple Demux Chainer Coalescer Writer
Network
Implementation Details
15
Phase One

Reader Byte Stream Converter Mapper
Sender Receiver Byte Stream Converter
Tuple Demux Chainer Coalescer Writer
Network
Implementation Details
16
Phase One
Stage
Implementation Details
17
Worker 1 Worker 2
Worker 3 Worker 4

Challenges Can’t spill to disk or swap under pressure – Themis memory manager
Partitions must fit in RAM – Sampling (see paper)
How does Themis handle failure? – Job-level fault tolerance
18

Outline Architecture Overview Memory Management Fault Tolerance Evaluation
19
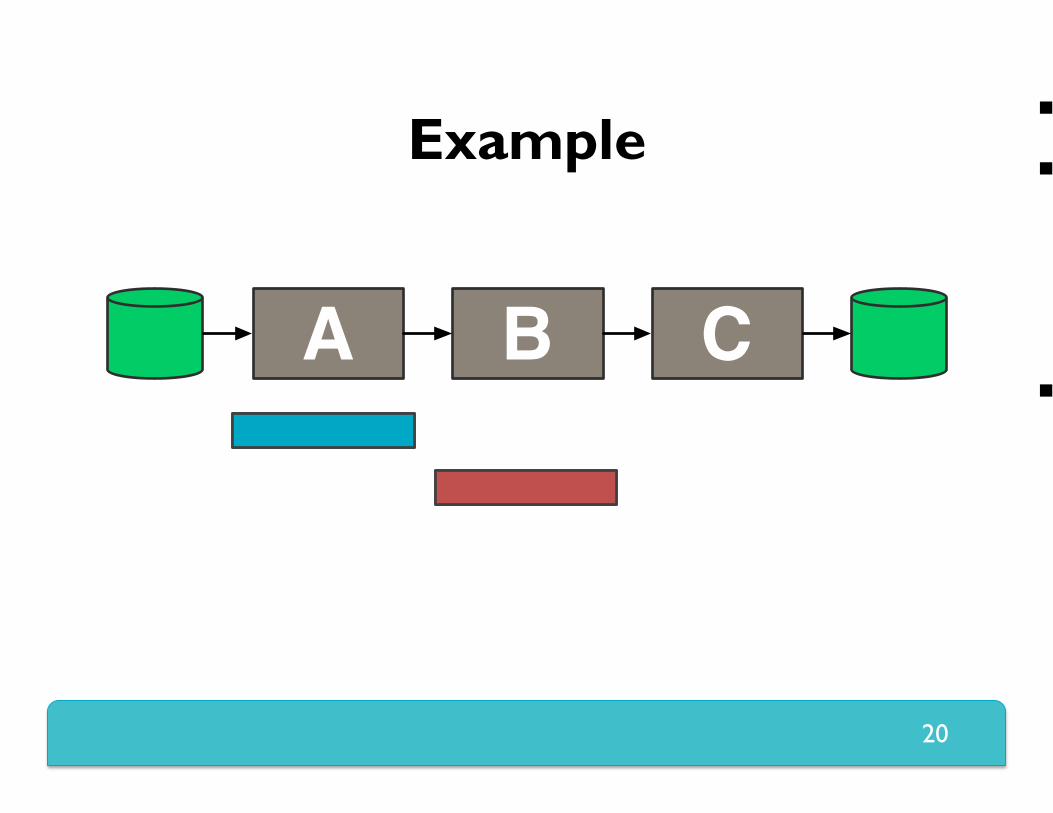
Example Why is this a problem? Example stage graph
Sample of what goes wrong
20
A B C

Memory Management - Goals If we exceed physical memory, have to swap – OS approach: virtual memory, swapping – Hadoop approach: spill files
Since this incurs more I/O, unacceptable
21

Example – Runaway Stage
22
A B C
Too Much Memory!
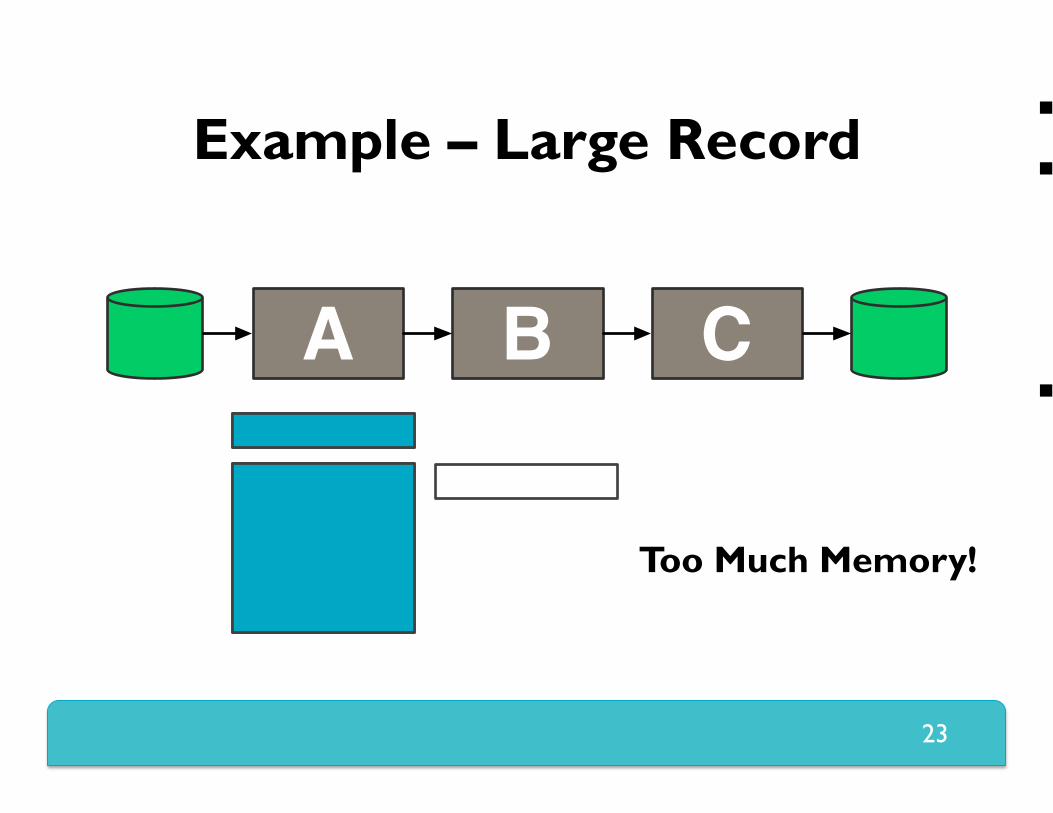
Example – Large Record Why is this a problem? Example stage graph
Sample of what goes wrong
23
A B C
Too Much Memory!

Requirements Main requirement: can’t allocate more than
the amount physical memory – Swapping or spilling breaks 2-IO
Provide flow control via back-pressure – Prevent stage from monopolizing memory – Memory allocation can block indefinitely
Support large records Should have high memory utilization
24

Approach Application-level memory management Three memory management schemes – Pools – Quotas – Constraints
25
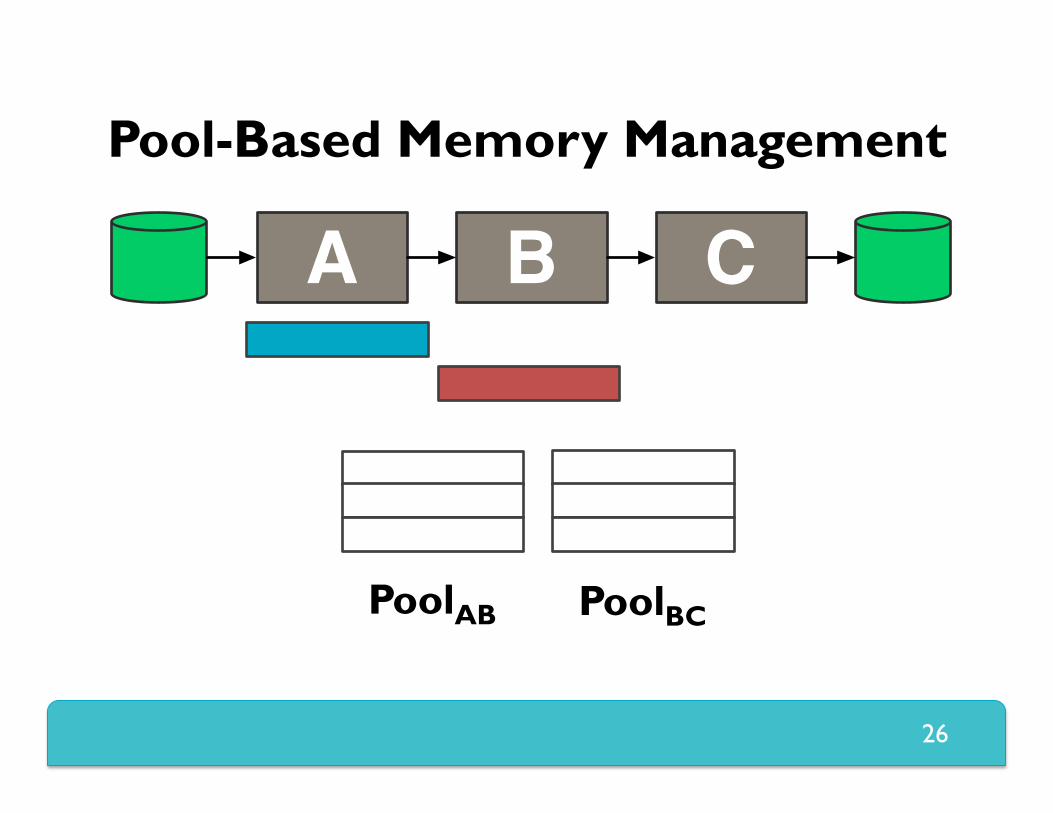
Pool-Based Memory Management
26
A B C
PoolAB PoolBC

Pool-Based Memory Management
27
A B C
PoolAB PoolBC

Pool-Based Memory Management
Prevents using more than what’s in a pool Empty pools cause back-pressure Record size limited to size of buffer Unless tuned, memory utilization might be low – Tuning is hard; must set buffer, pool sizes
Used when receiving data from network – Must be fast to keep up with 10Gbps links
28
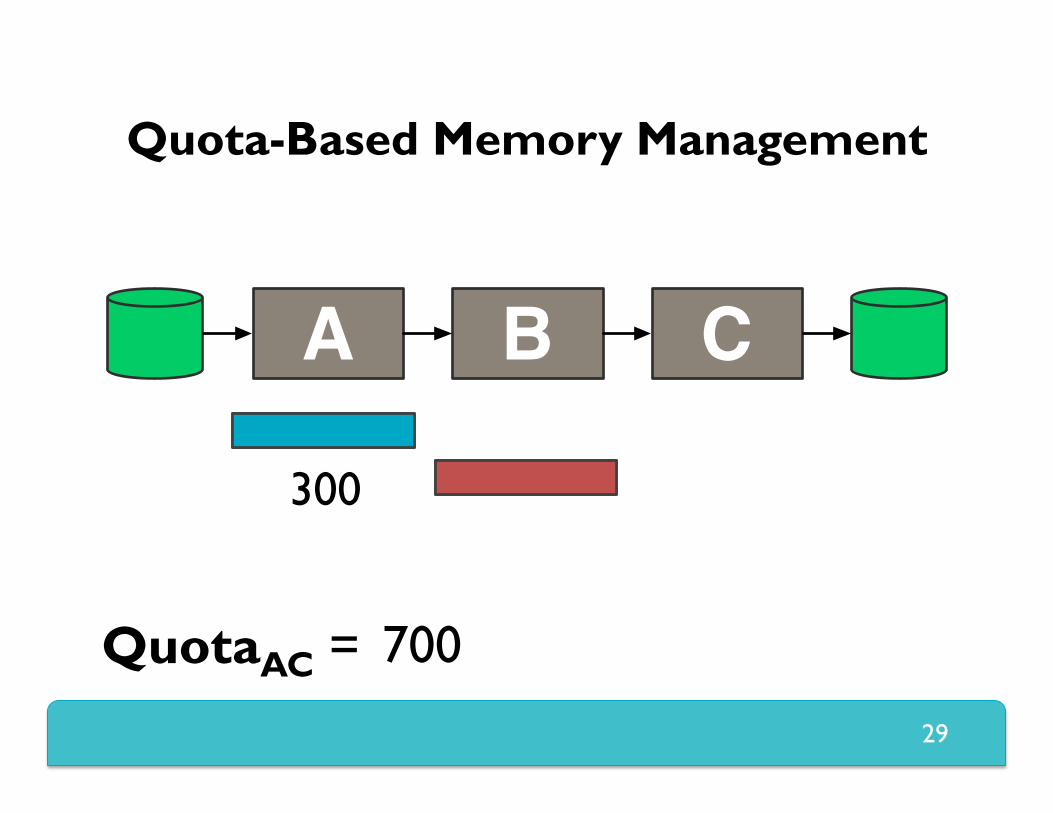
Quota-Based Memory Management
29
A B C
QuotaAC = 1000
300
700

Quota-Based Memory Management
Provides back-pressure by limiting memory between source and sink stage
Supports large records (up to size of quota) High memory utilization if quotas set well Size of the data between source and sink
cannot change – otherwise leaks Used in the rest of phase one (map + shuffle)
30

Constraint-Based Memory Management
Single global memory quota Requests that would exceed quota are
enqueued and scheduled Dequeue based on policy – Current: stage distance to network/disk write – Rationale: process record completely before
admitting new records
31

Constraint-Based Memory Management
Globally limits memory usage Applies back-pressure dynamically Supports record sizes up to size of memory Extremely high utilization Higher overhead (2-3x over quotas) Can deadlock for complicated graphs, patterns Used in phase two (sort + reduce)
32

Outline Architecture Overview Memory Management Fault Tolerance Evaluation
33

Fault Tolerance Cluster MTTF determined by size, node MTTF – Node MTTF ~ 4 months (Google, OSDI ’10)
34
Google 10,000+ Nodes
2 minute MTTF Failures common
Job must survive fault
Average Hadoop Cluster 30-200 Nodes
80 hour MTTF Failures uncommon OK to just re-run
MTTF Small MTTF Large

Why are Smaller Clusters OK? Hardware trends let you do more with less – Increased hard drive density (32TB in 2U) – Faster bus speeds – 10Gbps Ethernet at end host – Larger core counts
Can store, process petabytes But is it really OK to just restart on failure?
35

Analytical Modeling Modeling goal: when is performance gain
nullified by restart cost? Example: 2x improvement – 30 minute jobs: ~4300 nodes – 2.5 hr jobs: ~800 nodes
Can sort 100TB on 52 machines in ~2.5 hours – Petabyte scale easily possible in these regions
See paper for additional discussion
36

Outline Architecture Overview Memory Management Fault Tolerance Evaluation
37

Workload Sort: uniform and highly-skewed CloudBurst: short-read gene alignment
(ported from Hadoop implementation) PageRank: synthetic graphs, Wikipedia Word count n-Gram count (5-grams) Session extraction from synthetic logs
38

Performance
39

Performance
40

Performance
41

Performance vs. Hadoop
42
Application Hadoop Runtime
(Sec)
Themis Runtime
(Sec)
Improvement
Sort-500G 28881 1789 16.14x CloudBurst 2878 944 3.05x

Summary Themis – MapReduce with 2-IO property Avoids swapping and spilling by carefully
managing memory Potential place for job-level fault tolerance Executes wide variety of workloads at
extremely high speed
43

Themis - Questions?
44
Zoom!
http://themis.sysnet.ucsd.edu/!
Top Related