







Languages
Pages
Legal


DEVELOPMENT OF SPEECH BASED PERSON AUTHENTICATION SYSTEM IN
FPGAMENTOR:- DR. G.PRADHAN
RAJESH ROSHAN(1204016)YATENDRA MEENA(1204083)
VINIT KUMAR(1204033)

CONTENT
• MOTIVATION• INRODUCTION• PROGRESS• WORKS TO BE DONE IN FUTURE• CONCLUSION• REFERENCES

MOTIVATION
• DEVELOPMENT OF LOW COMPLEXITY AND LOW COST BIOMETRIC BASED PASSWORD AUTHENTICATION SYSTEM.
• PRESENT SYSTEMS ARE TOO COSTLY AND COMPLEX.• DO NOT NEED ANY SPECIAL SETUP AT USER SIDE.

INTRODUCTION
• SPEAKER VERIFICATION IS A TASK OF VALIDATING IDENTITY CLAIM OF A PERSON FROM HIS/HER VOICE.
• VOICE PASSWORD BASED SPEAKER VERIFICATION SYSTEM • SPEAKER IS FREE TO CHOOSE HIS/HER PASSWORD • PASSWORD REMAINS SAME FOR TRAINING AND VERIFICATION

BLOCK DIAGRAM OF BIOMETRIC SYSTEMS

FEATURE EXTRACTION
THE SPEECH SIGNAL ALONG WITH SPEAKER INFORMATION CONTAINS MANY OTHER REDUNDANT INFORMATION LIKE RECORDING SENSOR, CHANNEL, ENVIRONMENT ETC.
THE SPEAKER SPECIFIC INFORMATION IN THE SPEECH SIGNAL[2] UNIQUE SPEECH PRODUCTION SYSTEM PHYSIOLOGICAL BEHAVIORAL ASPECTS
FEATURE EXTRACTION MODULE TRANSFORMS SPEECH TO A SET OF FEATURE VECTORS OF REDUCE DIMENSIONS
TO ENHANCE SPEAKER SPECIFIC INFORMATION SUPPRESS REDUNDANT INFORMATION.

SELECTION OF FEATURE
• ROBUST AGAINST NOISE AND DISTORTION• OCCUR FREQUENTLY AND NATURALLY IN SPEECH• BE EASY TO MEASURE FROM SPEECH SIGNAL• BE DIFFICULT TO IMPERSONATE/MIMIC• NOT BE AFFECTED BY THE SPEAKER’S HEALTH OR LONG TERM VARIATIONS
IN VOICE

FEATURE EXTRACTION TECHNIQUESA WIDE RANGE OF APPROACHES MAY BE USED TO PARAMETRICALLY REPRESENT THE SPEECH SIGNAL TO BE USED IN THE SPEAKER RECOGNITION ACTIVITY. LINEAR PREDICTION CODING LINEAR PREDICTIVE CEPTRAL COEFFICIENTS MEL FREQUENCY CEPTRAL COEFFICIENTS PERCEPTUAL LINEAR PREDICTION NEURAL PREDICTIVE CODINGMOST OF THE STATE-OF-THE-ART SPEAKER VERIFICATION SYSTEMS USE MEL-FREQUENCY CEPSTRAL COEFFICIENT (MFCC) APPENDED TO IT’S FIRST AND SECOND ORDER DERIVATIVE AS THE FEATURE VECTORS
EASY TO EXTRACT PROVIDES BEST PERFORMANCE COMPARED TO OTHER FEATURES MFCC MOSTLY CONTAINS INFORMATION ABOUT THE RESONANCE STRUCTURE OF THE VOCAL TRACT
SYSTEM

PROGRESS
SPEECH SIGNAL
FRAMMING
WINDOWING
FFT MEL-
FREQUENCY
WRAPPING MFCC

• STEP 1:- ANALOG TO DIGITAL CONVERSION: IS TRANSFORMED TO DIGITAL FORM BY SAMPLING IT AT GIVEN FREQUENCY.
SIGNAL AQUASITION
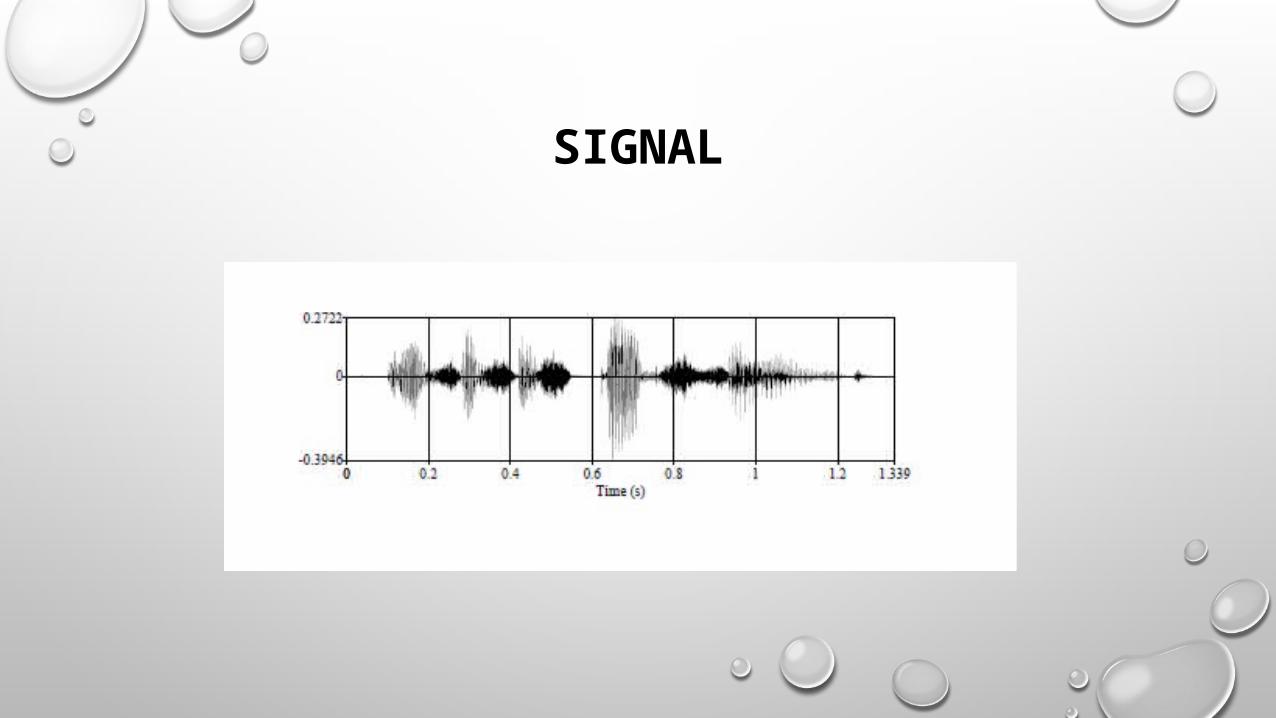
SIGNAL

FRAMING
• STEP 2:- PRE-EMPHASIS: THE AMOUNT OF ENERGY PRESENT IN THE HIGH FREQUENCY (IMPORTANT FOR SPEECH) ARE BOOSTED.
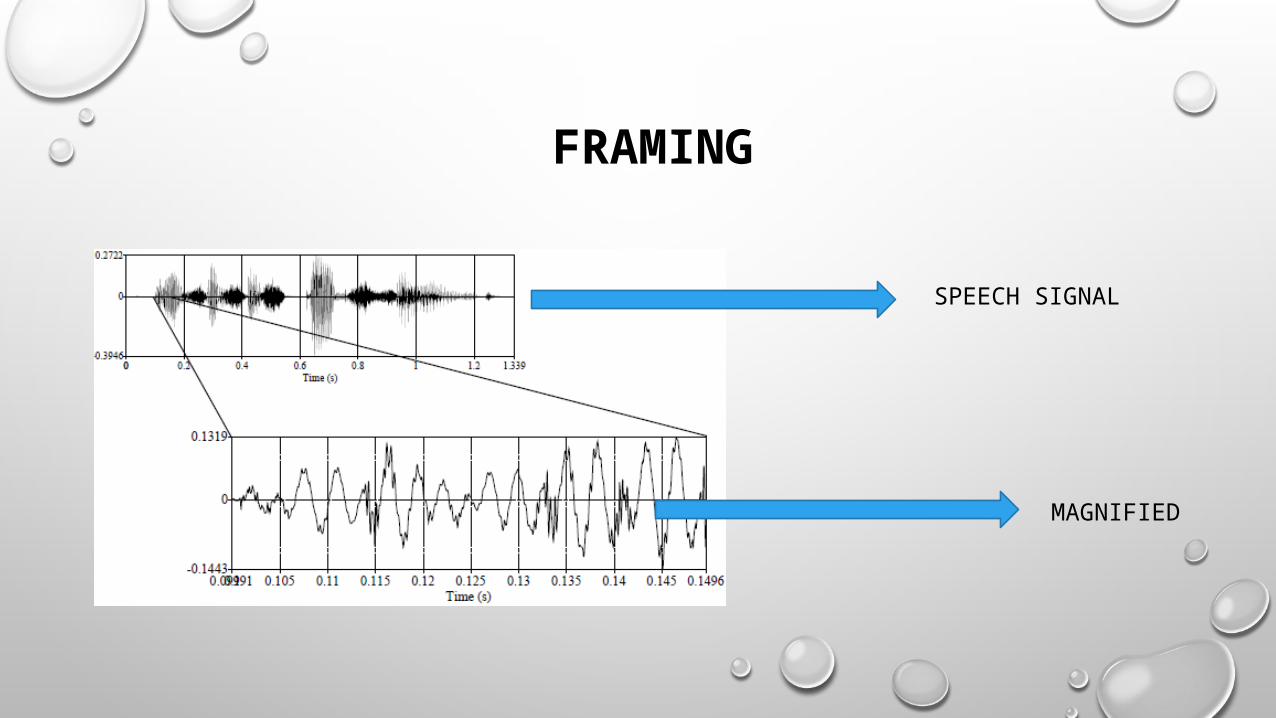
FRAMING
SPEECH SIGNAL
MAGNIFIED

FRAMMING
ONE FRAME OF SPEECH SIGNAL
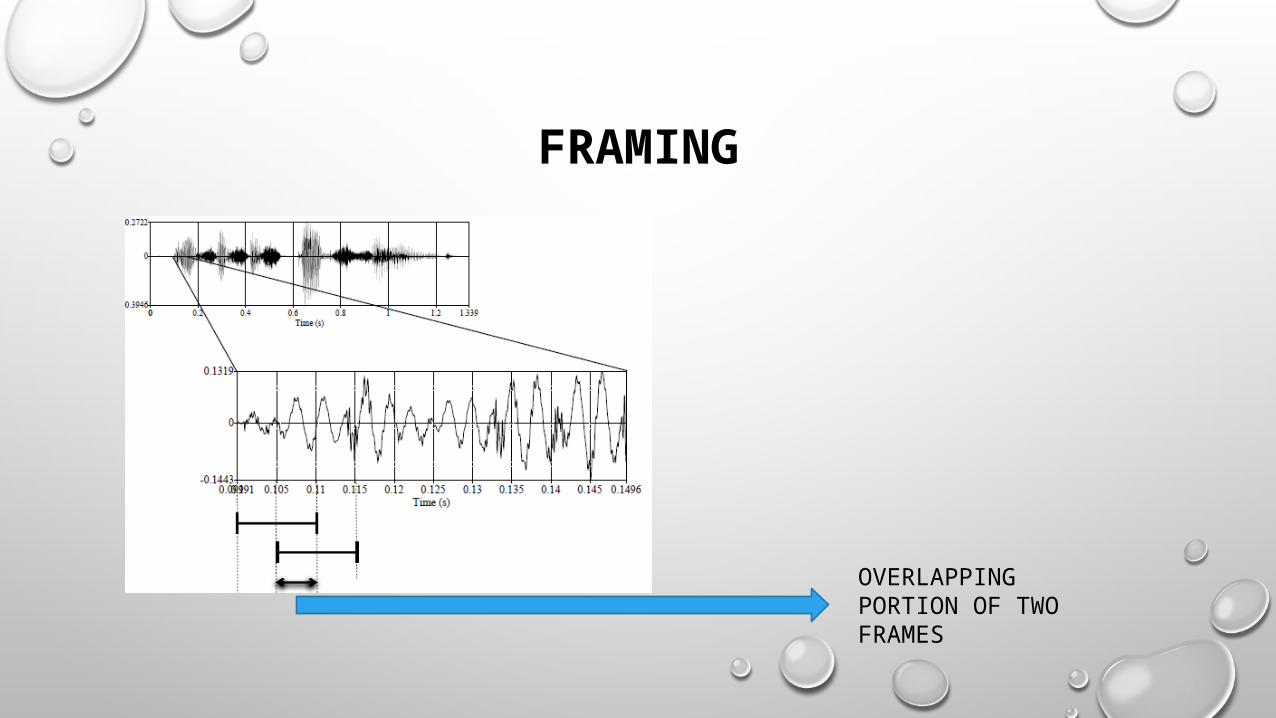
FRAMING
OVERLAPPING PORTION OF TWO FRAMES
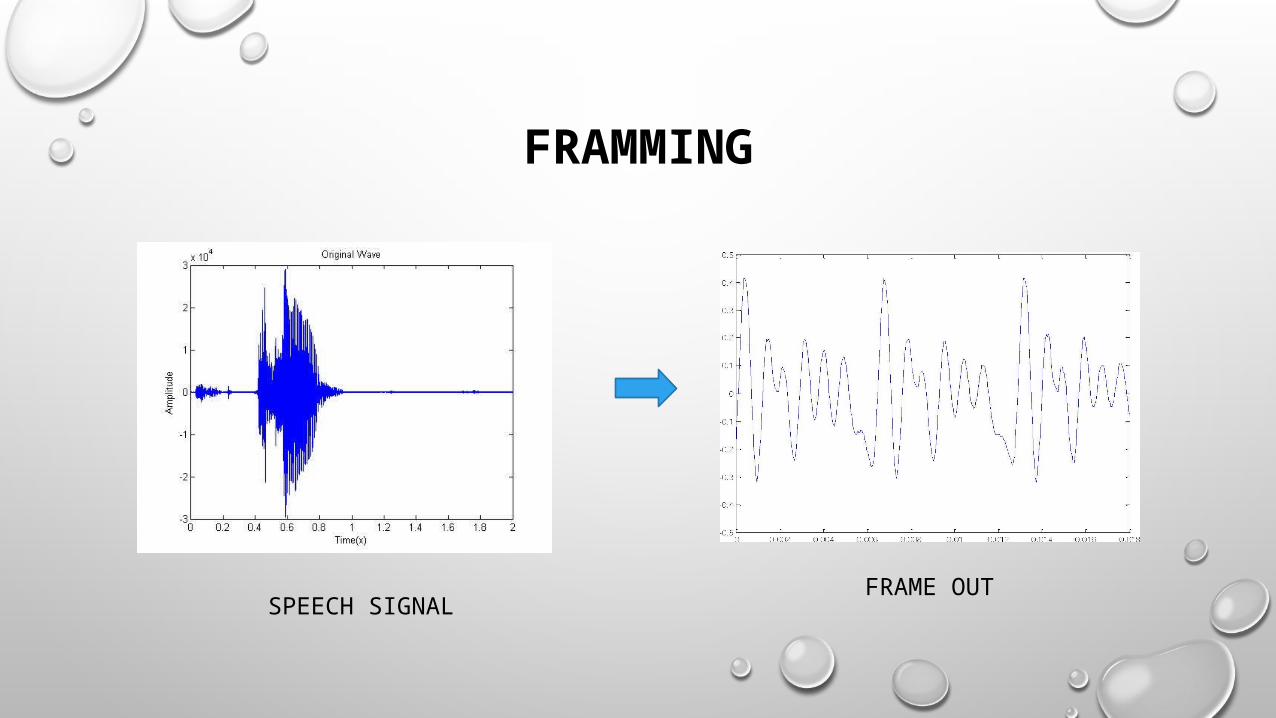
FRAMMING
SPEECH SIGNAL FRAME OUT

WINDOWING
• STEP 3:(FRAMING)THE SIGNAL IS DIVIDED INTO FRAMES OF GIVEN SIZE.

WINDOWING
• THE NEXT STEP IS TO WINDOW INDIVIDUAL FRAME TO MINIMIZE THE SIGNAL DISCONTINUITIES AT THE BEGINNING AND END OF EACH FRAME.
• THE CONCEPT APPLIED HERE IS TO MINIMIZE THE SPECTRAL DISTORTION BY USING THE WINDOW TO TAPER THE SIGNAL TO ZERO AT THE BEGINNING AND END OF EACH FRAME.
• WE HAVE USED HAMMING WINDOW

WINDOWING
SPEECH SIGNAL HAMMING WINDOW WINDOWED SIGNAL
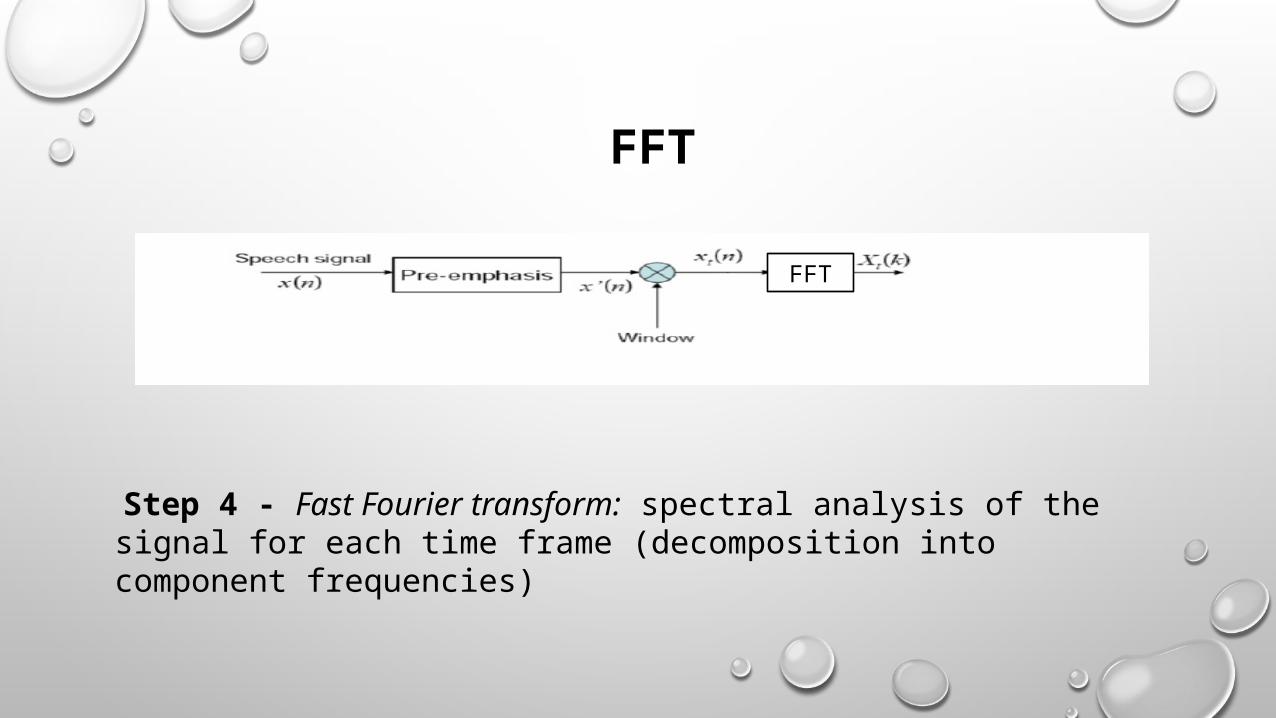
FFT
FFT
Step 4 - Fast Fourier transform: spectral analysis of the signal for each time frame (decomposition into component frequencies)

FFT

N.I.T. PATNA ECE, DEPTT.
MFCCFFT
FFT

.
MFCC
DCT
FFT
DISCRETE FOURIER TRANSFORM
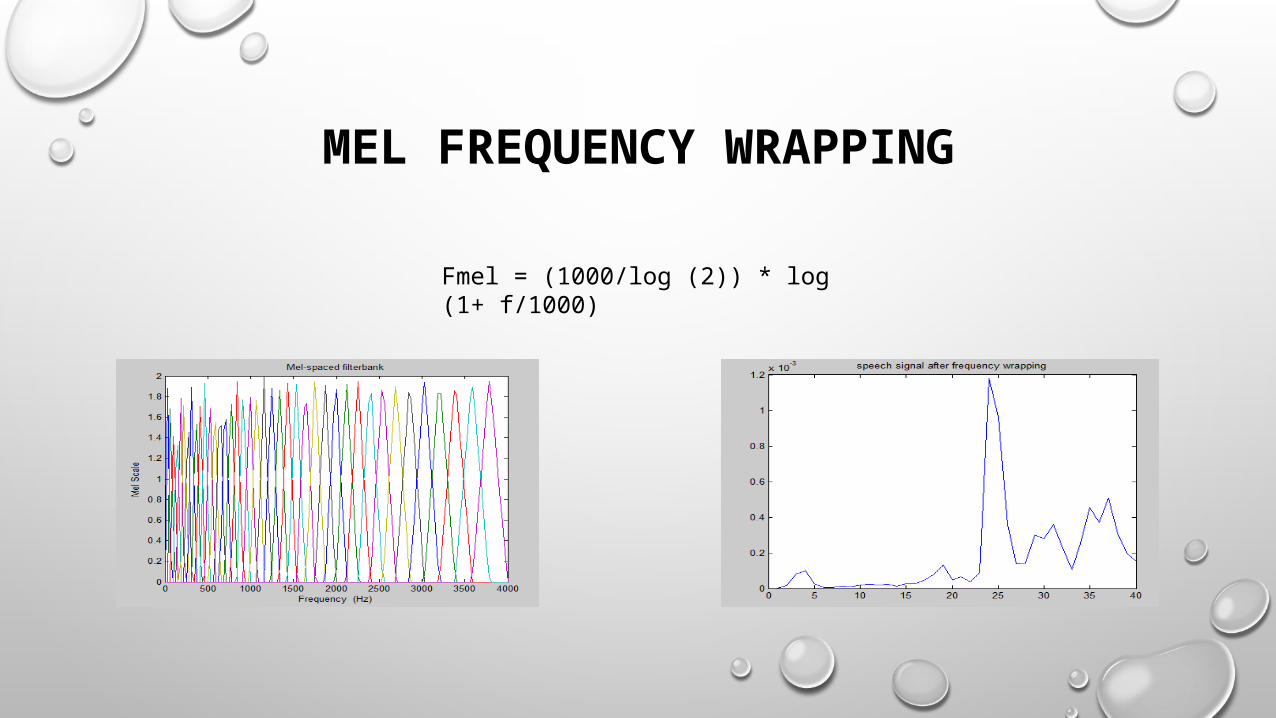
MEL FREQUENCY WRAPPING
Fmel = (1000/log (2)) * log (1+ f/1000)

MFCCCEPES = DCT( log (abs( FFT(Ywindowed)))
MFC COFFICIENTS IN TIME DOMAIN ORIGINAL SPEECH SIGNAL

MFCC
FFT
DCT

MFCC

WORK TO BE DONE NEXT
• SPEAKER MODELING USING GMM.• TESTING AND VERIFICATION.• FPGA IMPLEMENTATION.

CONCLUSION
• WE HAVE SUCCESSFULLY IMPLEMENTED FEATURE EXTRACTION AND DATABASE CREATION AND ARE WORKING ON MODELLING OF THE FEATURES EXTRACTED USING GMM TECHNIQUE.
• PARALLELY WE ARE EXPLORING FPGA BOARDES IN WHICH WE CAN IMPLEMENT ONCE THE ALOGRITM IS EFFECTIVELY OPTIMISED IN MATLAB.

REFERENCES
• CAMPBELL, J.P., JR.; "SPEAKER RECOGNITION: A TUTORIAL" PROCEEDINGS OF THE IEEE VOLUME 85,ISSUE 9, SEPT. 1997 PAGE(S):1437 - 1462.
• SEDDIK, H.; RAHMOUNI, A.; SAMADHI, M.; "TEXT INDEPENDENT SPEAKER RECOGNITION USING THEMEL FREQUENCY CEPSTRAL COEFFICIENTS" FIRST INTERNATIONAL SYMPOSIUM ON CONTROL, COMMUNICATIONS AND SIGNAL PROCESSING, PROCEEDINGS OF IEEE 2004PAGE(S):631 - 634.
• CHILDERS, D.G.; SKINNER, D.P.; KEMERAIT, R.C.; "THE CEPSTRUM: A GUIDE TO PROCESSING"PROCEEDINGS OF THE IEEE VOLUME 65, ISSUE 10, OCT. 1977 PAGE(S):1428 - 1443.
• ROUCOS, S. BEROUTI, M. BOLT, BERANEK AND NEWMAN, INC., CAMBRIDGE, MA; "THEAPPLICATION OF PROBABILITY DENSITY ESTIMATION TO TEXT-INDEPENDENT SPEAKER IDENTIFICATION" IEEEINTERNATIONAL CONFERENCE ON ACOUSTICS, SPEECH, AND SIGNAL PROCESSING, ICASSP '82. VOLUME:7, ON PAGE(S): 1649- 1652. PUBLICATION DATE: MAY 1982.

THANK YOU
Top Related