







Languages
Pages
Legal


1
SETS, HASH TABLES, AND DICTIONARIES
CS16: Introduction to Data Structures & Algorithms
Tuesday February 10, 2015

2
Outline
1. Set ADT
2. Dictionary ADT
3. Hash Tables
4. Example: JUMBLE
Tuesday February 10, 2015

3
Set
• A set is a collection of distinct elements (no repeats)
• Unlike a list or an array, a set doesn’t maintain any particular order of its elements
Tuesday February 10, 2015
{ , , }

4
Set ADT• add(obj): adds an element to the set, if it is not there already.
• remove(obj): removes an element from the set, if it is there.
• boolean contains(obj): checks whether an object is in the set
• int size(): returns the number of elements in the set
• boolean isEmpty(): checks whether the set is empty
• list enumerate(): returns a list of all the elements in some arbitrary order
Tuesday February 10, 2015

5
Simple Set Implementation
• We could use an (expandable) array• add: add to end of array O(1)• contains: step through arrayO(n)• remove: find, then compressO(n)
• Can we do any better?• hold that thought…
Tuesday February 10, 2015

6
Dictionary
• A dictionary is used to store (key, value) pairs, where the key is used to lookup its corresponding value
• Also known as a map• Applications:
• address book (name address)• …a dictionary (word definition)
Tuesday February 10, 2015

7
Dictionary ADT• add(key, val): adds a (key, value) pair to the dictionary
• V get(key): returns the value mapped to by the key
• remove(key): removes the key and its corresponding value from the dictionary
• int size(): returns the number of (key, value) pairs in the dictionary
• boolean isEmpty(): checks whether the dictionary is empty
GOAL: Implement a dictionary so that all of these methods run in O(1) time!
Tuesday February 10, 2015

8
Hash Tables• A hash table is an implementation of a dictionary• Hash tables are built using an array• h(key) is a “hash function” that takes in a key and returns
an index into the array, where the key’s corresponding value will be stored
• However, it’s possible multiple keys will “hash” to the same index. How can we store multiple values at a single index?
• Let’s make the array an array of “buckets”, where each bucket is a list of the values whose keys hash to that index• In fact, we’ll store the (key, value) pair itself in the bucket – not just
the value. Think about why this may be
• Note: it is important that h(key) runs in constant time!
Tuesday February 10, 2015

9
Hash Tables (2)
Tuesday February 10, 2015
table = array of some sizeh = some hash function
function add(key, val): index = h(key) table[index].append(key, val)
function get(key): index = h(key) for (k, v) in table[index]: if k = key: return v error(“key not found”)
O(1), as long as h() is constant
depends on the size of the bucket!
10
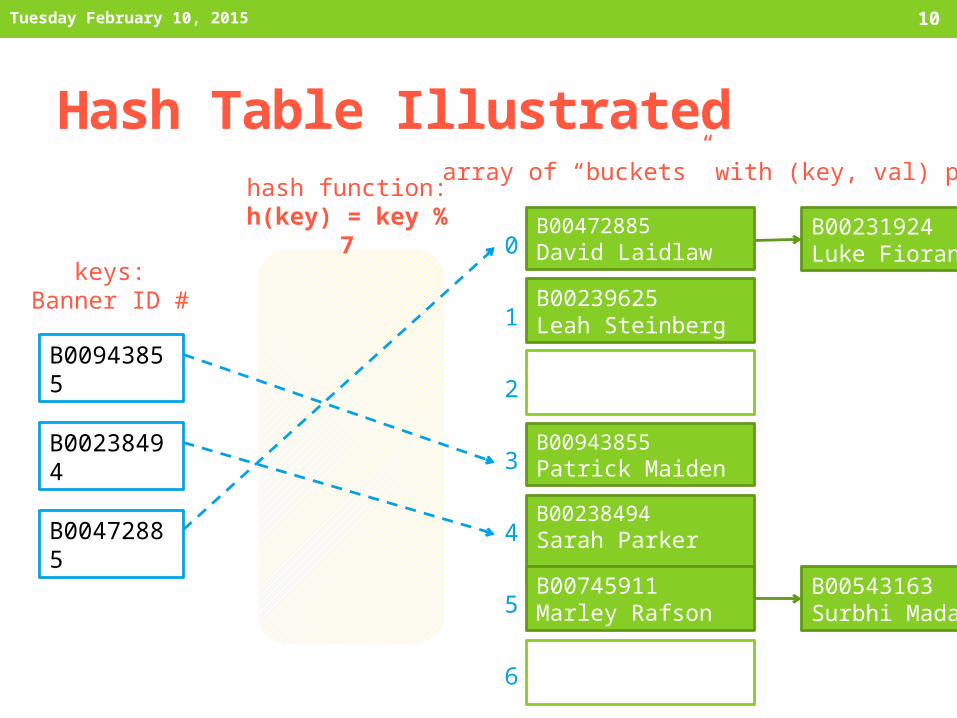
Hash Table Illustrated
Tuesday February 10, 2015
0
1
2
3
4
5
6
B00472885David Laidlaw
B00239625Leah Steinberg
B00943855Patrick Maiden
B00238494Sarah Parker
B00745911Marley Rafson
B00231924Luke Fiorante
B00543163Surbhi Madan
B00943855
B00238494
B00472885
keys:Banner ID #
hash function:h(key) = key % 7 array of “buckets” with (key, val) pairs:

11
Hash Functions
• In the example on the last slide, the hash table had size 7, and the hash function used was:h(key) = key % 7
• If we expect ~150 students to be stored in our hash table, then we’re bound to have lots of collisions.• If we’re lucky, the IDs will distribute themselves uniformly
so each bucket will contain about 150/7 students• But we’d still have to look through a list of length n/7 to
find the right one, which is O(n)• How can we do better?
Tuesday February 10, 2015

12
Hash Functions (2)• Solution: bigger table!
• We know Banner IDs have 8 digits. That means the largest possible ID is 99,999,999.
• Let’s make an array of size 100,000,000 and use the hash function: h(key) = key
• Since every ID gets its own index in the array, we’re guaranteed to have no collisions. All functions run in O(1)!
• But if we only need to keep track of 150 students, then 99.9999…% of our array goes to waste
• Besides, we might not even have enough memory for these kinds of shenanigans!
Tuesday February 10, 2015

13
Hash Functions (3)
• Solution: smaller bigger table!• Since we only expect to store ~150 students, let’s only
allocate the space we need• Make an array of size 150, and use the hash function:
h(key) = key % 150• This would be great if we were guaranteed that the IDs were
randomly distributed• But what if next year the registrar assigned new Banner IDs in
multiples of 150? Now we’re screwed!
• Since we can’t count on our keys to be random, we’ll just have to make our hash function random!
Tuesday February 10, 2015

14
Universal Hashing
• Magical universal hash function:1. Pick a prime number greater than your expected
capacity: 151• This is your array size
2. Fix 4 random numbers between 0 and 151a1, a2, a3, a4• These stay constant for the life of the hash table
3. Break keys (Banner IDs) into 4 chunksx1, x2, x3, x4• e.g. B00238918 00, 23, 89, 184. h(key) = (a1x1 + a2x2 + a3x3 + a4x4) % 151
Tuesday February 10, 2015

15
Universal Hashing (2)• The proof of why universal hashing works is tricky (and
thus optional) but awesome . It’s on the next few slides if you want to check it out.
• Whenever we have a randomized algorithm, usually there’s a worst case scenario where the algorithm runs much slower than we’d hope• You can imagine the universal hash function generating random
numbers that just happen to cause many bucket collisions
• Since that’s too depressing, instead we talk about the expected runtime of the algorithm, given any input
• For universal hashing, we can prove that the expected size of each bucket is less than 2, which means the expected runtime of get() is constant!
Tuesday February 10, 2015

16
Universal Hashing Proof: Background• Remember fractions and their inverses?
• The inverse of 3/4 is 4/3, because (3/4)*(4/3) = 1• Sometimes we write it like this: (3/4)-1 = 4/3
• Normally, integers don’t have (multiplicative) inverses, because you can’t multiply an integer i by anything to get 1. (Unless i = 1… duh.)
• But as soon as we enter modulo world, suddenly integers can have inverses too!• Take the integers mod 7:
• The inverse of 2 is 4, because 2*4 = 8 ≅ 1 mod 7• The inverse of 5 is 3, because 5*3 = 15 ≅ 1 mod 7
• But does every integer always have an inverse under any modulo?• What about the integers mod 4? Does 2 have an inverse?
• 2*0 = 0 ≅ 0 mod 4• 2*1 = 2 ≅ 2 mod 4• 2*2 = 4 ≅ 0 mod 4• 2*3 = 6 ≅ 2 mod 4
• Turns out, an integer i (mod n) only has an inverse if i and n are relatively prime, which means the only positive integer that evenly divides both of them is 1
• Then it definitely has an inverse, and that inverse is unique.• Take Abstract Algebra to find out why! Woo!!
• So if we’re talking about the integers mod n, where n is a prime number, then every integer has an inverse—because they’re all relatively prime to n!
• Oh, except for 0. Because 0 × anything is still 0.• Wow, we just talked about modular stuff AND prime numbers. Sounds likes some
serious foreshadowing!!!!!!
Tuesday February 10, 2015
Crap! No inverse!

17
Universal Hashing Proof• Now for the actual proof:• Let n be the prime size of our array• Choose any 2 distinct Banner IDs, broken into their 4 chunks:(x1, x2, x3, x4) and (y1, y2, y3, y4)• Because the IDs are distinct, we know that they must differ by at
least 1 chunk. Without loss of generality, we can assume that they differ by the last one. That is,x4 ≠ y4
• Fix 4 random numbers for our hash function, h:a1, a2, a3, a4• The probability that these 2 IDs will hash to the same bucket is
the probability that:h(x1, x2, x3, x4) = h(y1, y2, y3, y4)
Tuesday February 10, 2015

18
Universal Hashing Proof (2)Tuesday February 10, 2015
This is just some number, csubtract
stuff from both sides
multiply both sides by (x4 – y4)-1
Now let’s simplify that last expression:

19
• …Therefore, the probability that 2 distinct IDs will collide is the probability that a4 ≅ c(x4 – y4)-1 mod n
• Because x4 ≠ y4, we know that(x4 – y4) ≠ 0 • And since we chose n to be prime, (x4 – y4) is guaranteed to have a
unique inverse mod n.• Therefore, there is only one possible value that c(x4 – y4)-1 could take,
and only one value of a4 that would satisfy this congruence.
• Since a4 is randomly selected from n possible values, the probability that a4 was chosen “right” is 1/n.
• Therefore, the probability that a particular ID, x, will collide with another given ID is 1/n = 1/151. This means the expected number of collisions between x and all other IDs is 149/151 ≈ 1.
• So the expected size of x’s bucket is ≈ 2
Universal Hashing Proof (3)Tuesday February 10, 2015
OMG WE DID IT.

20
Back to Sets
• We can also use hashing to implement a set!• There are no key-value pairs, just elements.
• Also called a Hash Set
Tuesday February 10, 2015
function add(obj): index = h(obj) table[index].append(obj)
function contains(obj): index = h(obj) for elt in table[index]: if elt == obj: return true return false

21
HashMap vs HashSet
Tuesday February 10, 2015
Hash Map Hash Set
• Maps keys to values• There is no ordering
• No keys, just values. • That is, it is like a
HashMap where the key and value are the same.
• There is no ordering

22
Example: JUMBLE• Leah is making a Jumble for the
Daily Herald. There should only be one solution for a set of jumbled letters. How can she find all 5-letter words for which there is no other valid permutation?
• Input: list of all 5-letter words in English (each word represented as an array of 5 characters)
• Output: all words for which no other permutation is a word
Tuesday February 10, 2015

23
Example: JUMBLE Plan• Naive solution: for every valid word, find ALL of its permutations, and
check if each permutation is an English word. Keep track of a list for each word and return which words have only a single valid permutation.
• The problem with this: generating every permutation for every word is very expensive! • For a 5-letter word, there are as many as 5! permutations we would
have to check.
• The better solution: sort the letters of each valid word alphabetically. Use the sorted letter combination as the keys in the hashmap. Therefore, every two words that are permutations of each other will have the same key, so they'll be mapped to the same "value", a list of permutations of the same letter combination. We use only the valid English word to generate this, so we're never touching the tons and tons of non-valid letter combinations.
Tuesday February 10, 2015

24
Example: JUMBLE Solutionfunction jumble(words): // Input: list of words // Output: list of all words for which no other // permutation is a word output = [] permutations = dictionary() for each word in words: sortedKey = sort the letters of “word” alphabetically permlist = permutations.get(sortedKey) or [] // [] if empty permlist.append(word) permutations.add(sortedKey, permlist) for each word in words: sortedKey = sort the letters of word alphabetically if permutations.get(sortedKey).length == 1: output.append(word) return output
Tuesday February 10, 2015

25
Readings
• Dasgupta section 1.5 covers universal hashing, pages 43-47.
• Dasgupta “Randomized algorithms: a virtual chapter” on page 39 motivates algorithms like hashing.
Tuesday February 10, 2015
Top Related