







Languages
Pages
Legal


IndexFS: Scaling File System Metadata Throughput
Kai Ren Qing Zheng, Swapnil Patil, Garth Gibson
PARALLEL DATA LABORATORY Carnegie Mellon University

Why Scalable Metadata Service • Many existing cluster file systems
• Single in-memory metadata server (e.g. HDFS) • Flat object name space (e.g. Amazon S3) • Static partition namespace (e.g. Fed. HDFS/NFS)
http://www.pdl.cmu.edu/ 2
Data server
Data server
Data server
Data server Data
server Data server
Data server
Data server Data
server Data server
Data server
Data server
Metadata Server
Clients
Data path: read, write
Metadata path: stat, chmod, open

Why Scalable Metadata Service • Many existing cluster file systems
• Single in-memory metadata server (e.g. HDFS) • Flat object name space (e.g. Amazon S3) • Static partition namespace (e.g. Fed. HDFS/NFS)
• A global shared namespace is more flexible
• Our goal: • A middleware solution that provides dynamic
namespace scaling for existing file system
http://www.pdl.cmu.edu/ 3

Outline • Motivation ü IndexFS: Distributed Metadata Service
• Architecture • Namespace Distribution • Hotspot Mitigation with Storm-free Caching • Column-style Table and Bulk Insertion
• Summary
http://www.pdl.cmu.edu/ 4
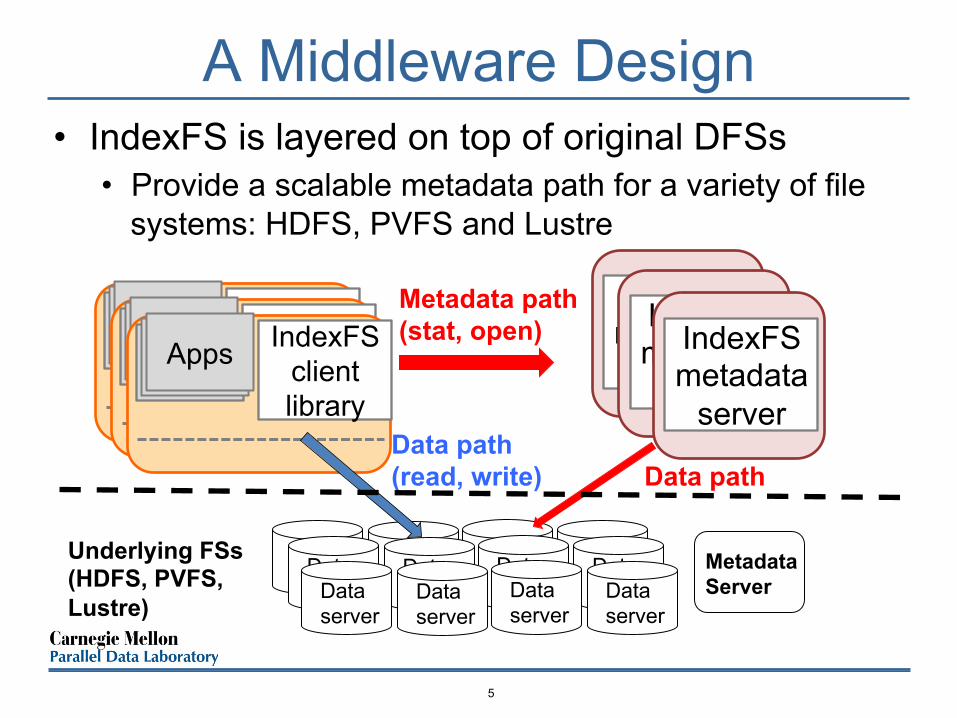
A Middleware Design
5
Underlying FSs (HDFS, PVFS, Lustre)
Data server
Data server
Data server
Data server Data
server Data server
Data server
Data server Data
server Data server
Data server
Data server
Metadata Server
IndexFS client
Apps IndexFS client
Apps IndexFS client library
Apps
Metadata path (stat, open)
Data path (read, write) Data path
• IndexFS is layered on top of original DFSs • Provide a scalable metadata path for a variety of file
systems: HDFS, PVFS and Lustre
IndexFS metadata
server
IndexFS metadata
server
IndexFS metadata
server

How IndexFS Distribute Directories? • Randomly assign directory to servers at creation
• Hash mapping: hash(full path) à partition (server ID)
6
5book
/
home
alice bob
0
32
1
4
carol /
1
0
2
534
Server 0 Server 1
Server 2 Server 3

Each Server has a Metadata Table • Represent directory / file as a key-value pair • Key:<parent directory’s inode number, filename> • Value: attributes, file data or file pointer • Stored in a key value store : LevelDB
http://www.pdl.cmu.edu/ 7
Key Value
<0, home> 1, attributes
<1, alice> 2, attributes
<1, bob> 3, attributes
<1, carol> 4, attributes
<2, book> 5, attributes, small file data Le
xico
grap
hic
orde
r
book
/
home
alice bob
0
32
1
4
5
carol

Dynamically Split Large Directories • Use GIGA+ for incremental growth
• Binary split a partition when its size exceeds the threshold until each server holds a partition
8
Binary split a large directory Server1
/big1/.P0/ _b1 _b4 _b6 …
50% files
Server2
/big1/.P1/ _b2 _b3 _b5 …
50% files

0 20 40 60 80 100 120 140 160Time (seconds)
0
200
400
600
800
1000
1200
Aggregate throughput (K
creates/sec)
Incremental growth phase (shaded area)
128 servers
Benchmark: Splitting Directories • Workloads: clients create files in one directory • Fast split the directory to all metadata servers
9

Scalability: File Creation • Workloads: clients create files in one directory • Run on Kodiak cluster with 8-yr old hardware
10
0!100!200!300!400!500!600!700!800!900!
1000!1100!
8! 16! 32! 64! 128!
Aggr
egat
e fil
e cr
eate
thro
ughp
ut !
(K c
reat
es/s
ec)!
Cluster size (number of servers)!
Linear!
IndexFS!
Ceph(2006)!
PVFS-tmpfs!

Outline • Motivation ü IndexFS: Distributed Metadata Service
• Architecture • Namespace Distribution ü Hotspot Mitigation with Storm-free Caching • Column-style Table and Bulk Insertion
• Summary
http://www.pdl.cmu.edu/ 11

Hot Spot: Server with Root Directories • Frequent lookup in root directories
• Path traversal needs to visit each ancestor • Retrieve inode number and access permissions
12
5book
/
home
alice bob
0
32
1
4
carol /
1
0
2
534
Hot spot Server 0 Server 1
Server 2 Server 3

How To Mitigate Hot Spots? • Client caches directory information • Problem with invalidation callbacks
• Cache invalidation waits for responses of all clients – Clients may fail / may cause invalidation storm
• Idea: let the “clock” do the invalidation
• Servers remember only expiration deadline • Assume clock synchronization within data center • Directory mutations wait for expiration
– rmdir, rename, chmod can be slow
13

Timeout Based Lease • Inspiration:
• Hot spots at top of tree has few changes
• Explored two expiration time choices: • tree depth: fixed duration K / depth • rate based: L*read rate / (read rate+write rate)
• Alternative approach: • Replicate top directories over multiple servers
14
book
/
home
alice bob
0
3 2
1
4
carol

Replay Experiment
• IndexFS run on a 128-node PVFS cluster • All metadata and splitting partitions stored in PVFS
• Workload: • Replay 1 million ops/server from LinkedIn trace • One day trace:10M objects and 130M operations • Pre-create namespace in the empty file system
15
IndexFS server
LevelDB
IndexFS server
LevelDB PVFS

Replay Result: Throughput • Client cache mitigates hot spots
http://www.pdl.cmu.edu/ 16
10"
100"
1000"
8" 16" 32" 64" 128"
Thro
ughp
ut (K
ops
/sec
)!
Number of servers!
IndexFS+Fixed (100ms)"IndexFS+Tree (3/depth)"IndexFS+Rate (r/(r+w))"PVFS+tmpfs"IndexFS+NoCache"
4x 1.5x
10x

Replay Result: Stat Latency
http://www.pdl.cmu.edu/ 17
99.999999.99999.9999.999
7e1
1e2
3.6e2
6.4e2
1e3
3e3
5e3
1e4
3.2e4
1e5
2e5
1e6
1e7
Lookup latency (in microseconds)
0102030405060708090
Fraction of re
q. (C
DF %)
Fixed (100ms)Tree (3s/depth)Rate (r/(r+w)s)PVFS+tmpfs

99.999999.99999.9999.999
7e1
1e2
3.6e2
6.4e2
1e3
3e3
5e3
1e4
3.2e4
1e5
2e5
1e6
1e7
Update latency (in microseconds)
0102030405060708090
Fraction of re
q. (C
DF %)
Fixed (100ms)Tree (3s/depth)Rate (r/(r+w)s)PVFS+tmpfs
Replay Result: Chmod Latency
http://www.pdl.cmu.edu/ 18
• Fixed duration lease gets the lowest tail latency • Trade-off between tail latency and throughput

Experiment on HDFS & Lustre
19
• Run mdtest on IndexFS layered on top of HDFS in Kodiak and Lustre in LANL Smog
569" 619"1,053"
17.8" 19"33"
5"
21"
3"
0"
5"
50"
500"
5,000"
mknod" stat" remove"
Thro
ughp
ut (K
ops
/sec
)!
IndexFS-Lustre (Total, 32 servers)"IndexFS-Lustre (Per-server)"Lustre (Single server)"
449 " 960 " 832 "
3.5" 8 " 7 "
1"
4"1"
0 "
1 "
10 "
100 "
1,000 "
10,000 "
mknod" stat" remove"
Thro
ughp
ut (K
ops
/sec
)!
IndexFS-HDFS (Total, 128 servers)"IndexFS-HDFS (Per-server)"HDFS (Single server)"

Outline • Motivation ü IndexFS: Distributed Metadata Service
• Architecture • Namespace Distribution • Hotspot Mitigation with Storm-free Caching ü Column-style Table and Bulk Insertion
• Summary
http://www.pdl.cmu.edu/ 20

Bulk File Creations
• Some applications need faster file creations • E.g. HPC checkpoint applications
• Two main techniques:
• Column-style Metadata Schema • Bulk insertion
http://www.pdl.cmu.edu/ 21

Metadata Table Storage • Per-server metadata table stored in LevelDB
• LevelDB packs them as files in the underlying FSs
http://www.pdl.cmu.edu/ 22
Key Value
<0, home> 1, attributes
<1, alice> 2, attributes
<1, bob> 3, attributes
<1, carol> 4, attributes
<2, book> 5, attributes, small file data Le
xico
grap
hic
orde
r
Underlying FSs
IndexFS metadata
server
LevelDB
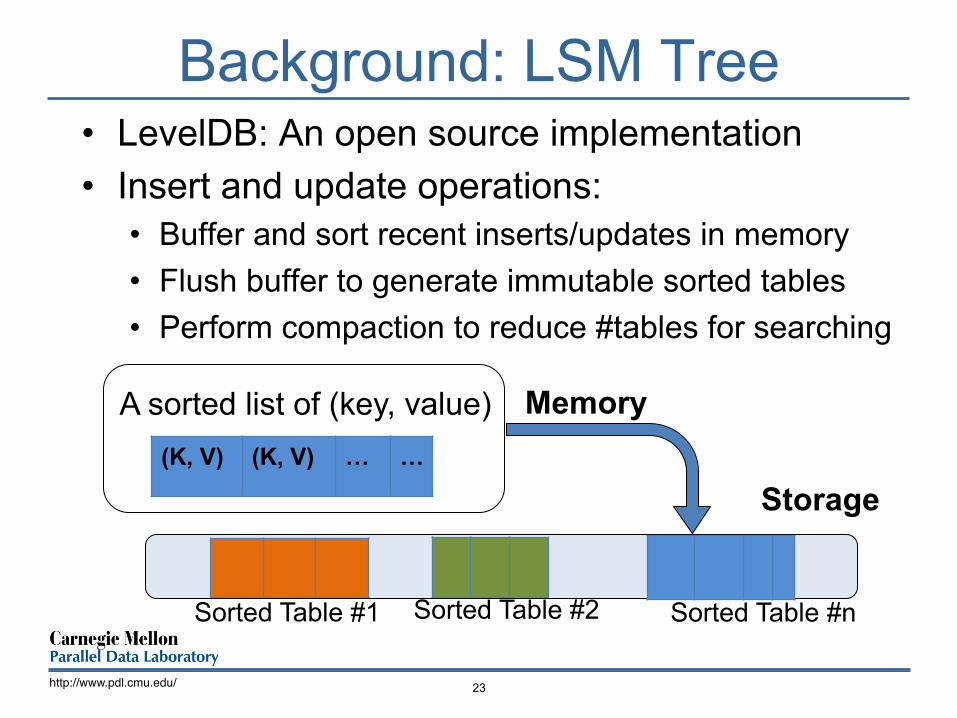
Background: LSM Tree • LevelDB: An open source implementation • Insert and update operations:
• Buffer and sort recent inserts/updates in memory • Flush buffer to generate immutable sorted tables • Perform compaction to reduce #tables for searching
http://www.pdl.cmu.edu/ 23
(K, V) (K, V) … …
A sorted list of (key, value) Memory
Sorted Table #1 Sorted Table #2
Storage
Sorted Table #n

Potential for Even Faster Insertion • Slow insertion for storing all metadata and data file
• 75% of insertion disk traffic caused by compaction • Compaction of larger values wastes more bandwidth
http://www.pdl.cmu.edu/ 24
0%
25%
50%
75%
100%
300B 4KB 64KB
Frac
tion
of D
isk
Traf
fic
Value Size
Compaction LogCommit

Column-style Metadata Schema • Column-styple approach:
• Metadata/small files appended to non-LevelDB log files • LevelDB stores only pointers to metadata • Don’t compact the metadata
– Delay space reclamation for deleted/over-written values since metadata are small
http://www.pdl.cmu.edu/ 25
Log file #1 Log file #2 Log file #n
(<0, home>, ptr) (<1, alice>, ptr) … … LevelDB
… No compaction

Speed up Ingestion Rate
http://www.pdl.cmu.edu/ 26
• Insert 30M entries sequentially or randomly • Limit memory to 350 MB, using single SATA disk
• About 2 to 15 times faster insertion
52"
16"
1.3"
28"
6"0.37"
0"
10"
20"
30"
40"
50"
60"
300B" 4KB" 64KB"
Thro
ughp
ut (K
ops
/sec
)!
Value Size!
Sequential Insertion!
ColumnStyle"
LevelDB"
52"
16"
1.3"10"
1" 0.35"0"
10"
20"
30"
40"
50"
60"
300B" 4KB" 64KB"
Thro
ughp
ut (K
ops
/sec
)!
Value Size!
Random Insertion!ColumnStyle"
LevelDB"

Comparable Read Throughput • Read after rand./seq. insertion of 4KB entries
• Random Read: read randomly over all entries • Range Read: read randomly in 1% adjacent range
• No compaction, so no clustering for range read • Only use compaction for workload-specific prefetch
http://www.pdl.cmu.edu/ 27
0"
100"
200"
300"
400"
Seq Write, Rand Read"
Rand Write, Rand Read"
Ope
ratio
ns/s
ec!
Random Reads!
ColumnStyle"LevelDB"
0
30
60
90
120
150
180
Seq Write, Range Read
Rand Write, Range Read
Ope
ratio
ns/s
ec (K
)
Range Reads
ColumnStyle LevelDB

Bulk insertion • Extend client cache to support write-back
• No RPC overheads per metadata operation • Avoids constant synchronization at servers • Better utilization of the underlying bandwidth
• Assumptions • Clients have access to backend storage nodes • Only possible for clients to insert new subtrees
– No namespace conflicts • Asynchronous error reporting is acceptable
http://www.pdl.cmu.edu/ 28

Bulk Insertion Implementation
FS Metadata Indexing Module
Application IndexFS Server
FS Metadata Backend Client
FS Metadata Indexing Module
FS Metadata Backend Client
cache cache
normal getattr/mknod
Shared Cluster File System
SSTables SSTables log
localized getattr/mknod
bulk insert
server metadata storage
29 http://www.pdl.cmu.edu/

Bulk Insertion: Factor Analysis
0.64 0.50 6.71
25.92
42.66
72.74
0.94 3.13 3.14
3.50 8.27 8.27
0 10 20 30 40 50 60 70 80
PVFS+tmpfs
Index
FS+Sync
+Async
+Bulk
+ColumnS
tyle
+Large
rBuff
er
Per-N
ode
Thro
ughp
ut (K
op/
s)�
File Create Random Getattr
http://www.pdl.cmu.edu/ 30
• Evaluation bulk insertion on top of PVFS • Perform random insertion and stat in one directory
3.8x 1.6x
1.7x
Flush size: 16KB->64KB

Summary • IndexFS: a middleware approach to reuse
scalable data path to scale metadata path
• Scale out: partition tree on directory basis • Use GIGA+ for incremental partition of large dirs. • Use consistent caching without per-client state
• Scale up: optimize log-structured merge tree • Column-style schema reduces compaction overhead • Bulk insertion for creating files in new sub-tree
http://www.pdl.cmu.edu/ 31

Reference • [Ren14] IndexFS: Scaling File System Metadata Performance with Stateless Caching and
Bulk Insertion. Kai Ren, Qing Zheng, Swapnil Patil and Garth Gibson. SC 2014 • [Ren13] TableFS: Enhancing metadata efficiency in local file systems. Kai Ren and Garth
Gibson. USENIX ATC 2013 • [Welch13] Optimizing a hybrid ssd/hdd hpc storage system based on file size distributions.
Brent Welch and Geoffrey Noer. 29th IEEE Conference on Massive Data Storage, 2013. • [Meister12] A Study on Data Deduplication in HPC Storage Systems. Dirk Meister, Jurgen
Kaiser, Andre Brinkmann, Toni Cortes, Michael Kuhn, Julian Kunkel. Supercomputing 2012 • [Patil11] Scale and Concurrency in GIGA+: File System Directories with Millions of Files.
Swapnil Patil and Garth Gibson. FAST 2011 • [Dean11] LevelDB: A fast, lightweight key-value database library. Jeff Dean and Sanjay
Ghemawat. http://leveldb.googlecode.com. • [Meyer11] A Study of Practical De-duplication. Dutch T. Meyer, and William J. Bolosky.
FAST 2011 • [Ganger97] Embedded Inodes and Explicit Grouping: Exploiting Disk Bandwidth for Small
Files. Gregory Ganger and Frans Kaashoek. Usenix ATC 1997. • [O’Neil96] The log-structured merge-tree (LSM-tree). Patrick ONeil and et al. Acta
Informatica, 1996 • [Rosenblum91] The design and implementation of a log-structured file system. Mendel
Rosenblum and John Ousterhout. SOSP 1991.
http://www.pdl.cmu.edu/ 32
Top Related