







Languages
Pages
Legal


Principal Component Analysis
Principal Component Analysis in R2018 Ontario Summer School on HPC
Marcelo Ponce
May 2018
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
Principal Component AnalysisPrincipal component analysis (PCA) is a statistical procedure that uses anorthogonal transformation to convert a set of observations of possiblycorrelated variables into a set of values of linearly uncorrelated variablescalled principal components.
PCA is mostly used as a tool inexploratory data analysis and formaking predictive models.
Unsupervised.
PCA is sensitive to the relative scalingof the original variables.
SVD, dimensionality reduction, ...
Also related to clusterization algs.(k-means) ...
“PCA ≈ fitting an n-dim
ellipsoid: PC;axes”
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
It’s often used to visualize genetic distance and relatedness betweenpopulations.
PCA has successfully foundlinear combinations of thedifferent markers, thatseparate out different clusterscorresponding to differentlines of individuals’Y-chromosomal geneticdescent.
A principal components analysis scatterplot of Y-STR haplotypes calculated from
repeat-count values for 37 Y-chromosomal STR markers from 354 individuals.
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
Computing PCA in Rß pricomp
uses eigen-values/vectors andcovariance matrix
à prcomp
uses singular value decomposition(SVD)
prcomp(x, retx = TRUE, center = TRUE, scale = FALSE, tol = NULL, ...)
# USArrests data vary by orders of
magnitude, so scaling is appropriate
> prcomp(USArrests) # inappropriate
> pc1 <- prcomp(USArrests, scale = T)
> pc2 <- prcomp(~Murder + Assault +
Rape, data = USArrests, scale = TRUE)
> summary(pc1)
> summary(pc2)
> plot(pc1)
> plot(pc2)
Importance of components: Comp.1 Comp.2
Comp.3 Comp.4
Standard deviation 1.5748783 0.9948694
0.5971291 0.41644938
Proportion of Variance 0.6200604
0.2474413 0.0891408 0.04335752
Cumulative Proportion 0.6200604 0.8675017
0.9566425 1.00000000
Importance of components: PC1 PC2 PC3
PC4
Standard deviation 83.7324 14.21240
6.4894 2.48279
Proportion of Variance 0.9655 0.02782
0.0058 0.00085
Cumulative Proportion 0.9655 0.99335
0.9991 1.00000
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
Computing PCA in Rß pricomp
uses eigen-values/vectors andcovariance matrix
à prcomp
uses singular value decomposition(SVD)
prcomp(x, retx = TRUE, center = TRUE, scale = FALSE, tol = NULL, ...)
# USArrests data vary by orders of
magnitude, so scaling is appropriate
> prcomp(USArrests) # inappropriate
> pc1 <- prcomp(USArrests, scale = T)
> pc2 <- prcomp(~Murder + Assault +
Rape, data = USArrests, scale = TRUE)
> summary(pc1)
> summary(pc2)
> plot(pc1)
> plot(pc2)
Importance of components: Comp.1 Comp.2
Comp.3 Comp.4
Standard deviation 1.5748783 0.9948694
0.5971291 0.41644938
Proportion of Variance 0.6200604
0.2474413 0.0891408 0.04335752
Cumulative Proportion 0.6200604 0.8675017
0.9566425 1.00000000
Importance of components: PC1 PC2 PC3
PC4
Standard deviation 83.7324 14.21240
6.4894 2.48279
Proportion of Variance 0.9655 0.02782
0.0058 0.00085
Cumulative Proportion 0.9655 0.99335
0.9991 1.00000
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
Computing PCA in Rß pricomp
uses eigen-values/vectors andcovariance matrix
à prcomp
uses singular value decomposition(SVD)
prcomp(x, retx = TRUE, center = TRUE, scale = FALSE, tol = NULL, ...)
# USArrests data vary by orders of
magnitude, so scaling is appropriate
> prcomp(USArrests) # inappropriate
> pc1 <- prcomp(USArrests, scale = T)
> pc2 <- prcomp(~Murder + Assault +
Rape, data = USArrests, scale = TRUE)
> summary(pc1)
> summary(pc2)
> plot(pc1)
> plot(pc2)
Importance of components: Comp.1 Comp.2
Comp.3 Comp.4
Standard deviation 1.5748783 0.9948694
0.5971291 0.41644938
Proportion of Variance 0.6200604
0.2474413 0.0891408 0.04335752
Cumulative Proportion 0.6200604 0.8675017
0.9566425 1.00000000
Importance of components: PC1 PC2 PC3
PC4
Standard deviation 83.7324 14.21240
6.4894 2.48279
Proportion of Variance 0.9655 0.02782
0.0058 0.00085
Cumulative Proportion 0.9655 0.99335
0.9991 1.00000
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
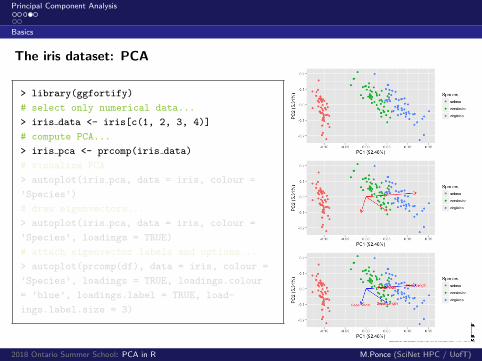
The iris dataset: PCA
> library(ggfortify)
# select only numerical data...
> iris data <- iris[c(1, 2, 3, 4)]
# compute PCA...
> iris pca <- prcomp(iris data)
# visualize PCA
> autoplot(iris pca, data = iris, colour =
’Species’)
# draw eigenvectors...
> autoplot(iris pca, data = iris, colour =
’Species’, loadings = TRUE)
# attach eigenvector labels and options...
> autoplot(prcomp(df), data = iris, colour =
’Species’, loadings = TRUE, loadings.colour
= ’blue’, loadings.label = TRUE, load-
ings.label.size = 3)
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)
Principal Component Analysis
Basics
The iris dataset: PCA
> library(ggfortify)
# select only numerical data...
> iris data <- iris[c(1, 2, 3, 4)]
# compute PCA...
> iris pca <- prcomp(iris data)
# visualize PCA
> autoplot(iris pca, data = iris, colour =
’Species’)
# draw eigenvectors...
> autoplot(iris pca, data = iris, colour =
’Species’, loadings = TRUE)
# attach eigenvector labels and options...
> autoplot(prcomp(df), data = iris, colour =
’Species’, loadings = TRUE, loadings.colour
= ’blue’, loadings.label = TRUE, load-
ings.label.size = 3)
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
The iris dataset: PCA
> library(ggfortify)
# select only numerical data...
> iris data <- iris[c(1, 2, 3, 4)]
# compute PCA...
> iris pca <- prcomp(iris data)
# visualize PCA
> autoplot(iris pca, data = iris, colour =
’Species’)
# draw eigenvectors...
> autoplot(iris pca, data = iris, colour =
’Species’, loadings = TRUE)
# attach eigenvector labels and options...
> autoplot(prcomp(df), data = iris, colour =
’Species’, loadings = TRUE, loadings.colour
= ’blue’, loadings.label = TRUE, load-
ings.label.size = 3)
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
The iris dataset: PCA
> library(ggfortify)
# select only numerical data...
> iris data <- iris[c(1, 2, 3, 4)]
# compute PCA...
> iris pca <- prcomp(iris data)
# visualize PCA
> autoplot(iris pca, data = iris, colour =
’Species’)
# draw eigenvectors...
> autoplot(iris pca, data = iris, colour =
’Species’, loadings = TRUE)
# attach eigenvector labels and options...
> autoplot(prcomp(df), data = iris, colour =
’Species’, loadings = TRUE, loadings.colour
= ’blue’, loadings.label = TRUE, load-
ings.label.size = 3)
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
The iris dataset: PCA
> library(ggfortify)
# select only numerical data...
> iris data <- iris[c(1, 2, 3, 4)]
# compute PCA...
> iris pca <- prcomp(iris data)
# visualize PCA
> autoplot(iris pca, data = iris, colour =
’Species’)
# draw eigenvectors...
> autoplot(iris pca, data = iris, colour =
’Species’, loadings = TRUE)
# attach eigenvector labels and options...
> autoplot(prcomp(df), data = iris, colour =
’Species’, loadings = TRUE, loadings.colour
= ’blue’, loadings.label = TRUE, load-
ings.label.size = 3)
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
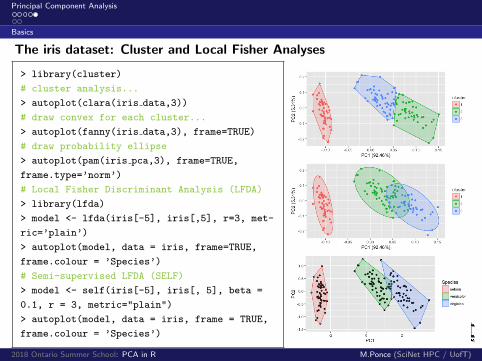
The iris dataset: Cluster and Local Fisher Analyses
> library(cluster)
# cluster analysis...
> autoplot(clara(iris data,3))
# draw convex for each cluster...
> autoplot(fanny(iris data,3), frame=TRUE)
# draw probability ellipse
> autoplot(pam(iris pca,3), frame=TRUE,
frame.type=’norm’)
# Local Fisher Discriminant Analysis (LFDA)
> library(lfda)
> model <- lfda(iris[-5], iris[,5], r=3, met-
ric=’plain’)
> autoplot(model, data = iris, frame=TRUE,
frame.colour = ’Species’)
# Semi-supervised LFDA (SELF)
> model <- self(iris[-5], iris[, 5], beta =
0.1, r = 3, metric="plain")
> autoplot(model, data = iris, frame = TRUE,
frame.colour = ’Species’)
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
The iris dataset: Cluster and Local Fisher Analyses
> library(cluster)
# cluster analysis...
> autoplot(clara(iris data,3))
# draw convex for each cluster...
> autoplot(fanny(iris data,3), frame=TRUE)
# draw probability ellipse
> autoplot(pam(iris pca,3), frame=TRUE,
frame.type=’norm’)
# Local Fisher Discriminant Analysis (LFDA)
> library(lfda)
> model <- lfda(iris[-5], iris[,5], r=3, met-
ric=’plain’)
> autoplot(model, data = iris, frame=TRUE,
frame.colour = ’Species’)
# Semi-supervised LFDA (SELF)
> model <- self(iris[-5], iris[, 5], beta =
0.1, r = 3, metric="plain")
> autoplot(model, data = iris, frame = TRUE,
frame.colour = ’Species’)
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
The iris dataset: Cluster and Local Fisher Analyses
> library(cluster)
# cluster analysis...
> autoplot(clara(iris data,3))
# draw convex for each cluster...
> autoplot(fanny(iris data,3), frame=TRUE)
# draw probability ellipse
> autoplot(pam(iris pca,3), frame=TRUE,
frame.type=’norm’)
# Local Fisher Discriminant Analysis (LFDA)
> library(lfda)
> model <- lfda(iris[-5], iris[,5], r=3, met-
ric=’plain’)
> autoplot(model, data = iris, frame=TRUE,
frame.colour = ’Species’)
# Semi-supervised LFDA (SELF)
> model <- self(iris[-5], iris[, 5], beta =
0.1, r = 3, metric="plain")
> autoplot(model, data = iris, frame = TRUE,
frame.colour = ’Species’)
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
Basics
The iris dataset: Cluster and Local Fisher Analyses
> library(cluster)
# cluster analysis...
> autoplot(clara(iris data,3))
# draw convex for each cluster...
> autoplot(fanny(iris data,3), frame=TRUE)
# draw probability ellipse
> autoplot(pam(iris pca,3), frame=TRUE,
frame.type=’norm’)
# Local Fisher Discriminant Analysis (LFDA)
> library(lfda)
> model <- lfda(iris[-5], iris[,5], r=3, met-
ric=’plain’)
> autoplot(model, data = iris, frame=TRUE,
frame.colour = ’Species’)
# Semi-supervised LFDA (SELF)
> model <- self(iris[-5], iris[, 5], beta =
0.1, r = 3, metric="plain")
> autoplot(model, data = iris, frame = TRUE,
frame.colour = ’Species’)
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)
Principal Component Analysis
Basics
The iris dataset: Cluster and Local Fisher Analyses
> library(cluster)
# cluster analysis...
> autoplot(clara(iris data,3))
# draw convex for each cluster...
> autoplot(fanny(iris data,3), frame=TRUE)
# draw probability ellipse
> autoplot(pam(iris pca,3), frame=TRUE,
frame.type=’norm’)
# Local Fisher Discriminant Analysis (LFDA)
> library(lfda)
> model <- lfda(iris[-5], iris[,5], r=3, met-
ric=’plain’)
> autoplot(model, data = iris, frame=TRUE,
frame.colour = ’Species’)
# Semi-supervised LFDA (SELF)
> model <- self(iris[-5], iris[, 5], beta =
0.1, r = 3, metric="plain")
> autoplot(model, data = iris, frame = TRUE,
frame.colour = ’Species’)
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
3D PCA
3D PCAAdditional Packages required:
install.packages("rgl")
install.packages("pca3d")
> library(rgl)
> library(pca3d)
# PCA analysis of ’metabo’ data
# relative abundances of metabolites
from serun samples of three groups
> data(metabo)
> dim(metabo) # 136 424
# PCA analysis, including all rows but
the ’group’ column
> pca <- prcomp(metabo[,-1],
scale=TRUE)
# 2D PCA
> pca2d(pca, group=metabo[,1])
# 3D PCA
> pca3d(pca, group=metabo[,1])
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
3D PCA
3D PCAAdditional Packages required:
install.packages("rgl")
install.packages("pca3d")
> library(rgl)
> library(pca3d)
# PCA analysis of ’metabo’ data
# relative abundances of metabolites
from serun samples of three groups
> data(metabo)
> dim(metabo) # 136 424
# PCA analysis, including all rows but
the ’group’ column
> pca <- prcomp(metabo[,-1],
scale=TRUE)
# 2D PCA
> pca2d(pca, group=metabo[,1])
# 3D PCA
> pca3d(pca, group=metabo[,1])
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)

Principal Component Analysis
3D PCA
References
PCA
http://uc-r.github.io/pca
http://genomicsclass.github.io/book/pages/pca_svd.html
https://cran.r-project.org/web/packages/ggfortify/vignettes/plot_pca.html
https://cran.r-project.org/web/packages/HSAUR/vignettes/Ch_principal_components_analysis.pdf
2018 Ontario Summer School: PCA in R M.Ponce (SciNet HPC / UofT)
Top Related