







Languages
Pages
Legal


EDC Forum 2017
21. September 2017
Arne de Wall (52°North)Marius Appel (Institute for Geoinformatics)Thomas Paschke (Esri Deutschland)
Overview of Big (Geospatial) Data
Concepts and Technologies

+ Introduction Big (Geospatial) Data
+ Big Data Challenges & Geo-specific issues
+ Processing Concepts
+ Landscape of Big Data
+ Overview of Big Geospatial Data Technologies
+ Discussion & Program Outlook
Agenda

Arne de Wall (52°North)Marius Appel (Institue for Geoinformatics)Thomas Paschke (Esri Deutschland)
3
Introduction to Big (Geospatial) Data

Common Understanding:
+ Big Data is so "big and complex" that it requires
advanced tools and capabilities for management,
processing and analysis.
Definition Gartner:
+ „Big data are high-volume, high-velocity, and/or
high-variety information assets that require new
forms of processing to enable enhanced decision
making, insight discovery, and process optimization.“
4
IntroductionWhat is Big Data?
Source: Google Trends (https://trends.google.com)
Source: Gartner, The Importance of „Big Data“: A Definition, June 2012

Introduction3V’s of Big Data (Laney, 2001)
Volume
Scale of
Data
Velocity
Frequency
of Data
Variety
Data in Many
Forms
The challenges arise from the development
of all three characteristics
+ Terabytes to Exabytes of data to
process
+ Petabytes of data distributed
around the world
+ Management and analysis of the
entire data volume
+ Only 12% of all data is used on
average
+ Seconds to Milliseconds to respond
+ Continuous data generation at
high speed
+ Understanding and acting on data
faster
+ Structured to Unstructured data
to manage
+ Data from different sources and of
different formats
+ 80% of all Data is unstructured

6
Introduction3V‘s, 4V‘s, 5V‘s, XV‘s of Big Data
+ Uncertainty due to data inconsistency
and incompleteness, ambuguity,
latency, deception, and model
approximations.
VeracityData
in
Doubt 4V‘s3V‘s
…

+ „Revolutions in science have often been preceded
by revolutions in measurements“
+ Data, especially space-time data, impresses with
its increasing resolution.
+ Geospatial Data Analytics: Extraction of
decision-critical, space-time relations, meanings
and patterns.
+ The space-time aspect of the large data is
facing new technological challenges.
IntroductionMotivation: Big Geospatial Data
Source: IBM Institute for Business Value „Analytics: The real-world use of big data“
Where do companies get their data? Where do companies use big data?
(Sinan. Aral cited in Cukier, 2010)

IntroductionSources of Big Geospatial Data
US Commercial Jet Engines (during 1 year)
Sentinel-1/-2/-3 generate
>20TB an of data every
day
Copernicus
Internet of Things (IoT) Market
Source: https://connectedworld.sa/media/wysiwyg/IoT_predictions_2020.jpg
(Cisco: “50 billion things will be connected to the internet by 2020.”)
Internet of Things Internet of Things
“Location Infused Technologies”
EMAC model produced 2 PB of
climate data, 30-50 PB expected for
Coupled Model Intercomparison
Project 6 (CMIP6).
Climate Model Output

Arne de Wall (52°North)Marius Appel (Institue for Geoinformatics)Thomas Paschke (Esri Deutschland)
9
Big Data Challenges &
Geo-specific issues

10
Big Data ChallengesTechnical Challenges
Distributed Storage• Files gets splitted and replicated
across storage
• Abstracted administration
Move-Code-To-Data• Architectural approach which
allows for the processing of the
data where it resides
• Distributed computation close to
the data
Resilient System-design• Automated failover
• Abstracted administration of
things like fault-tolerance,
synchronization, etc.
Support for Heterogeneous Data• Storage and processing of different
file formats
• Support for structured and
unstructured data
Transparent Scalability• Add additional ressources as
required
• Abstracted administration

+ data too large for single machines → distributed environments
+ How to distribute spatio-temporal data?
> minimize network transfer when possible
> data locality for geoprocessing algorithms to reach optimal access patterns
> optimal distribution strategy depends on the problem
Geo-specific challengesData Distribution

+ Time series analysis (i) vs. spatial analysis (ii)
+ Naive approach: random distribution of files leads to data transfer overhead
+ Better: make sure that nodes have complete time series (i) or complete spatial rasters (ii)
→ Geolocation can be used to improve data locality and minimize network communication
Geo-specific challengesData Distribution

+ Multidimensional data must be mapped to one dimension (e.g. linear storage / key
value stores)
> how to maintain data locality?
> how to support efficient multidimensional range selection?
+ Naive index-order performs bad
+ Other approaches:
> Space-filling curves
> Chunking
Geo-specific challengesIndexing multidimensional data

+ Space filling curves order points from 𝑛-dimensional
space on a single sequence
+ Examples: Z-Curve, Hilbert curve (see low resolution
example right)
+ adjustable to 𝑛 dimensions
+ multidimensional ranges convert to series of one
dimensional ranges
+ used e.g. in GeoMesa and GeoWave for distributing
data by space and time
Geo-specific challengesIndexing multidimensional data
https://locationtech.github.io/geowave/previous-
versions/0.9.1/images/hilbert1.png

For large raster / array data a simple approach
to improve range selection is to
+ partition into equally sized rectangular
contiguous regions
+ use standard index-order (e.g. row major)
within chunks
Technologies that use chunking:
+ NetCDF (within files)
+ Array databases (across nodes in a cluster)
Geo-specific challengesIndexing multidimensional data

16
Geo-specific ChallengesStateful Processing
+ What does stateful processing mean?
> For some analysis in an event-based processing framework, the previous state of an object is
essential to evaluate its current status
+ Stateful processing is needed …
> to monitor the status of an object over time
> to evaluate changes in spatial conditions of an object (enter / exit)
Name: Thomas
Speed: 5 km/h
Mode: Walking
Location: X,Y
TimeStamp: 10:00
Name: Thomas
Speed: 6 km/h
Mode: Walking
Location: X,Y
TimeStamp: 10:05
Name: Thomas
Speed: 10 km/h
Mode: Running
Location: X,Y
TimeStamp: 10:12
Name: Thomas
Speed: 6 km/h
Mode: Walking
Location: X,Y
TimeStamp: 00:20
Processor / Filter:
„Enter House“
Processor / Filter:
„Time Running“

17
Geo-specific ChallengesStateful Processing
+ This can be a challenge especially in an distributed, resilient framework
DesktopWeb Device
Clients

18
Geo-specific ChallengesStateful Processing
+ This can be a challenge especially in an distributed, resilient framework
DesktopWeb Device
Clients

19
Geo-specific ChallengesSpatio-Temporal Fusion on Heterogeneos Datasets
+ How can we combine different data streams/sets for geospatial analysis?
Static Information Streaming Information ?
?(Spatial) Join
- 1000 E/s
- Every Second
- 200 E/s
- Every 5 Second

Arne de Wall (52°North)Marius Appel (Institue for Geoinformatics)Thomas Paschke (Esri Deutschland)
20
Fundamental Concepts

Volume
Scale of
Data
Velocity
Frequency
of Data
Variety
Data in Many
Forms
+ Terabytes to Exabytes of data
to process
Batch-Processing
+ Seconds to Milliseconds to
respond
Stream-Processing NoSQL
+ For high volume data volumes
(static data)
+ Processing is carried out at a
later time
+ Data is collected and processed
together
+ For high-frequency data streams
(event streams)
+ Immediate processing of incoming
data
+ Answers in (near-) real time
+ Semi-structured schema-free
databases
+ No SQL/ACID required
+ Scalable even under massive
data growth
+ Structured to Unstructured data
to manage

Big Data Fundamental ConceptsBatch- vs. Stream-Processing
Batch Processing
Stream Processing
Data Ingestion
Data Storage
Batch Processing
Data StorageBatch Processing Pipeline
Batch View
Batch View
Batch View
Dif
fere
nt
Dat
a So
urc
es
Data Ingestion
Message Buffer/Queue
Stream Processors
Data StorageStream Processing Pipeline
Updated View
Dif
fere
nt
Dat
a So
urc
es
DifferentApplications
Updated View
DifferentApplications
Data Subset
All Data

Big Data Fundamental ConceptsLambda Architecture
RECENT DATAINCREMENT
VIEWS
SPEED LAYER
Real-time Processing
BATCH LAYER
ALL DATAPRECOMPUTE
VIEWS
Batch-basedRecompute
QueryingApplications
NEWDATA
SERVING LAYER
Batch View Batch View
REAL-TIME View

+ Fundamental processing paradigm developed by Google Inc. [1]
+ Simplifies batch processing on large clusters (thousands of nodes)
> Abstracts away the parallel and distributed processing logic
+ Data processing in phases:
> Map: applies the same function to independent chunks of the data and generates intermediate
results
> Reduce: combines intermediate results to compute final results
24
Big Data Fundamental ConceptsMapReduce
[1] Dean, J., & Ghemawat, S. (2008). MapReduce: simplified data processing on large clusters. Communications of the ACM, 51(1), 107-113.

MAP
+ takes key value pairs as input
+ the map function is applied in parallel to
individual pairs
+ outputs a list of new key value pairs for each
input pair
25
Big Data Fundamental ConceptsMapReduce
REDUCE
+ takes output pairs from map results grouped
by their key
+ outputs a list of values
Output
(Values)Input Data
(Key value
pairs)
Intermediate
Results
MAP
MAP
MAP
MAP
REDUCE
REDUCE
Key value
pair lists

+ Introduced by Google Inc. (2006) [1]
+ Used by Google Search, Maps, Earth, and many others
+ Data is organized in tables
26
Big Data Fundamental ConceptsBigTable
[1] Chang, F., Dean, J., Ghemawat, S., Hsieh, W. C., Wallach, D. A., Burrows, M., ... & Gruber, R. E. (2008). Bigtable: A distributed storage
system for structured data. ACM Transactions on Computer Systems (TOCS), 26(2), 4.
Traditional relational RDBMS BigTable
ACID Relaxed ACID for scalability and efficiency
Fixed schemaUnlimited columns, different number of
columns for different rows variety
No data distribution Row distribution by lexicographic key order

Arne de Wall (52°North)Marius Appel (Institue for Geoinformatics)Thomas Paschke (Esri Deutschland)
27
Big Data Landscape


Paper:The Google File
System
Paper:MapReduce:
Simplified Data Processing on Large
Clusters
Initial developments on
Yahoo! is working on
Hadoop
Apache Hadoop goes productive
Batch
Paper:Bigtable: A Distributed
Storage System for Structured Data
29
Big Data Landscape13 Years of Big Data Technologies
2003 2004 2005 20092007 20082006 2010 2011 2012 2013 2014 2015 2016

+ Open Source Platform to store and process Big Data that is
heavily supported by Yahoo
+ Hadoop MapReduce
⇒ Computing Engine (Batch-Processing) based on MapReduce
+ Hadoop Yet Another Resource Negotiator (YARN):
⇒ Cluster Management and Resource Scheduler
+ Hadoop Distributed File System (HDFS):
⇒ Distributed file system consisting of replicated chunks of data
30
Big Data LandscapeHadoop Ecosystem
Name
Node
Backup
Node
Data Node 1 Data Node 2 Data Node 3 Data Node 4
-> {1,3,4}
-> {1,2,4}
-> {1,2,3}
-> {2,3,4}
file.txt (409mb)
$ hadoop fs –put file.txt
128mb 128mb 128mb 25mb
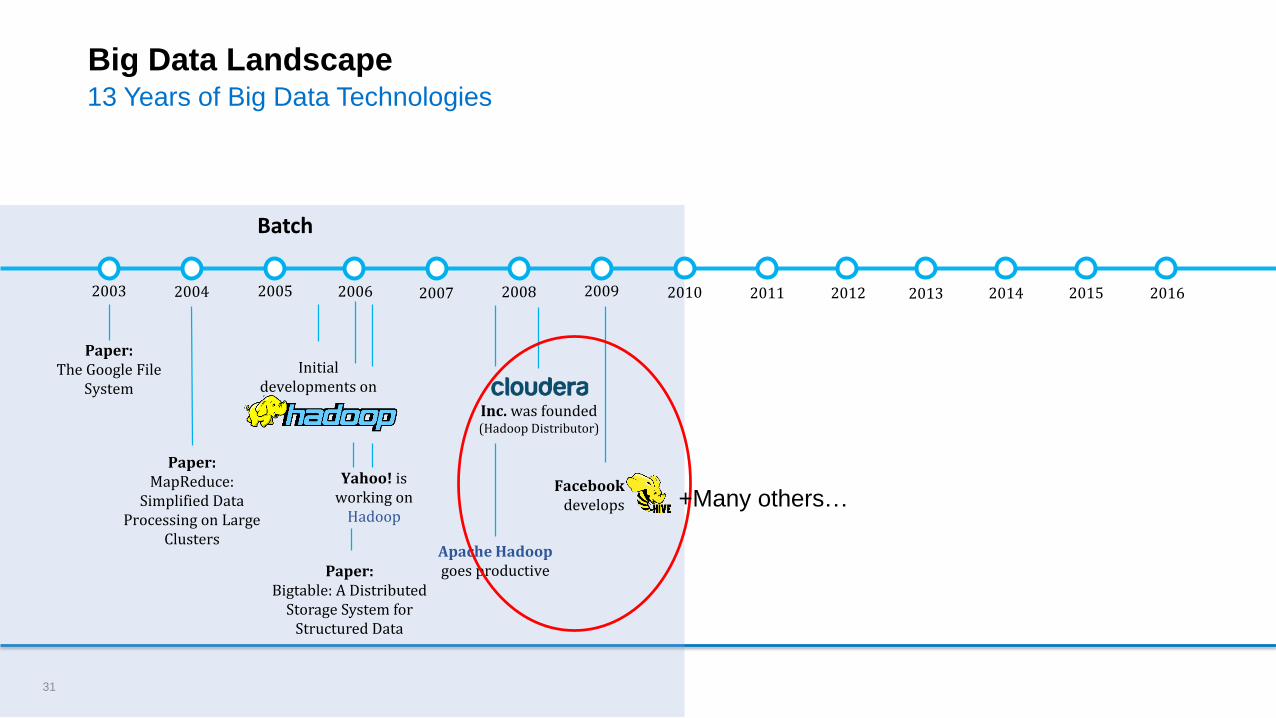
Paper:The Google File
System
Paper:MapReduce:
Simplified Data Processing on Large
Clusters
Initial developments on
Yahoo! is working on
Hadoop
Facebookdevelops
Apache Hadoop goes productive
Batch
Inc. was founded (Hadoop Distributor)
Paper:Bigtable: A Distributed
Storage System for Structured Data
31
Big Data Landscape13 Years of Big Data Technologies
2003 2004 2005 20092007 20082006 2010 2011 2012 2013 2014 2015 2016
+Many others…

32
Big Data LandscapeHadoop Ecosystem
(+150 Technologies listed on https://hadoopecosystemtable.github.io/)

+ We do not talk about the ONE
technology.
+ Hadoop Infrastructures consists of
several technologies for different
purposes.
33
Big Data LandscapeHadoop Ecosystem

+ Preconfigured Hadoop environments
packaged with multiple components that
work well together.
+ Tested, performance patches, predictable
upgrade path..
+ And most importantly .. Support!
34
Big Data LandscapeHadoop Distributors
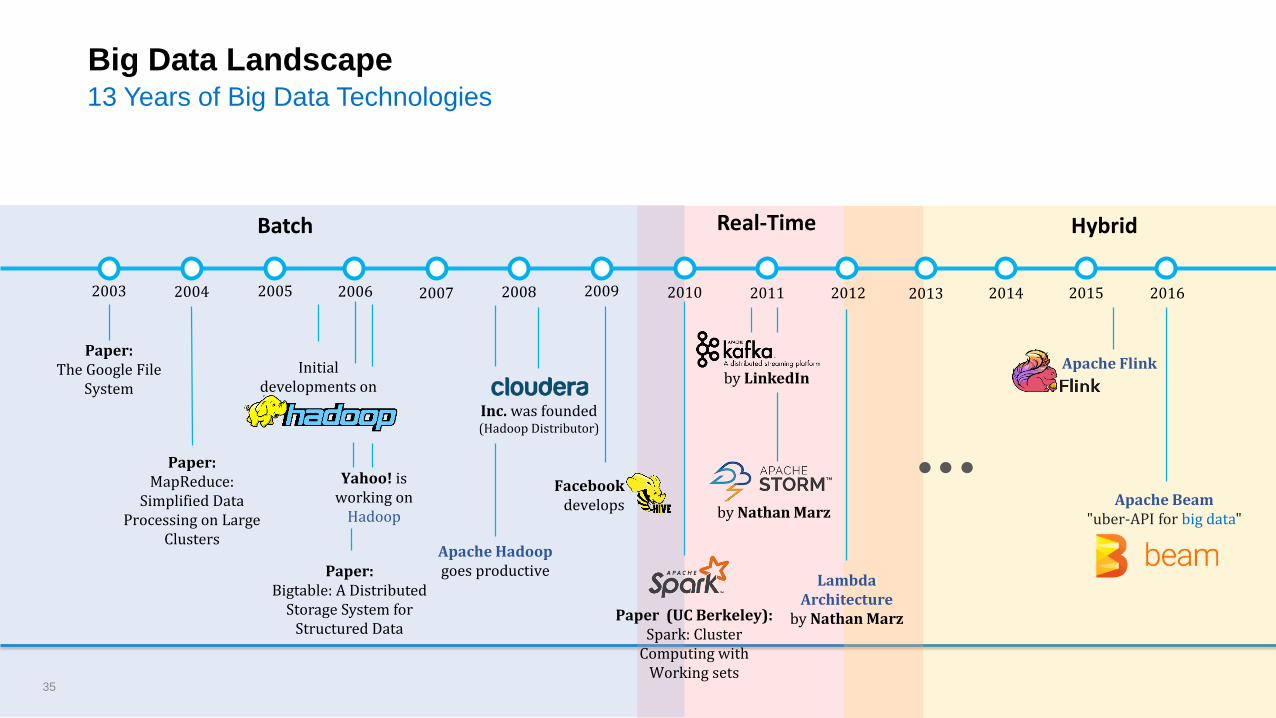
Real-Time
by Nathan Marz
by LinkedIn
Hybrid
Apache Beam"uber-API for big data"
Lambda Architecture
by Nathan Marz
Apache FlinkPaper:
The Google File System
Paper:MapReduce:
Simplified Data Processing on Large
Clusters
Initial developments on
Yahoo! is working on
Hadoop
Facebookdevelops
Apache Hadoop goes productive
Batch
Paper (UC Berkeley):Spark: Cluster
Computing with Working sets
Inc. was founded (Hadoop Distributor)
Paper:Bigtable: A Distributed
Storage System for Structured Data
35
Big Data Landscape13 Years of Big Data Technologies
2003 2004 2005 20092007 20082006 2010 2011 2012 2013 2014 2015 2016

36
Big Data Technologies
Source: https://acadgild.com
Logistic regression in Hadoop and SparkSource: https://spark.apache.org/
Batch & Stream Processing – Apache Spark

37
Big Data Technologies
+ In memory processing
+ Scatter/gather paradigm
+ Data Model = Resilient Distributed Dataset (RDD)
> “ […] the basic abstraction in Spark. Represents an immutable,
partitioned collection of elements that can be operated on in parallel.” (http://spark.apache.org)
> motivated by two types of applications that other computing frameworks
handle inefficiently: iterative algorithms and interactive data mining tools
> Can be persisted
+ Mllib
> Spark's scalable
machine learning library.
Batch & Stream Processing – Apache Spark
Input
Query 1
Query 2
Query 3
Result 1
Result 1
Result 1
RDD

38
Big Data Technologies
+ Spark SQL
> Module that enables structured queries that can be expressed in SQL on structured and
semi-structured data primary and feature-rich interface to Spark’s
+ GraphX
> Spark's API for graphs and graph-parallel computation.
+ Programming model = transform & action
> transformation is a lazy operation on a RDD that returns another RDD
> action is an operation that triggers execution of RDD transformations and returns a value
Batch & Stream Processing – Apache Spark
RDD
Transformation
Action Result

39
Big Data Technologies
+ Distributed computation
> Spark Client
> Spark Context (Driver)
> Creates Job Hands off to
Spark cluster manager
> Cluster manager distributes the job into tasks that are
processed on distributed Spark worker nodes
> Spark Worker Node
> Multiple Executers that receive and run tasks
(transformation or action methods)
+ Storage agnostic
Spark
Spark Spark
Spark
Spark
Driver / CMWorker
Worker
Worker
Worker
Worker
Task
Result
JobRAM
RAM
RAM
RAMRAM
Batch & Stream Processing – Apache Spark

Topic(s)
Producer(s)
40
Big Data Landscape
©2015 O‘Reilly Media, Inc.
Messages (Events)
Consumer(s)
Stream Processing – Apache Kafka
Connector(s)
App
Stream
Prozessor(s)

41
Big Data Landscape
©2015 O‘Reilly Media, Inc.
Why distribution?
Topic(s)
Stream Processing – Apache Kafka

42
Big Data Landscape
©2015 O‘Reilly Media, Inc.
Topic Partitioning
0
0
0
1
1
1
2
2 3
Stream Processing – Apache Kafka
> ordered, immutable sequence of records
that is continually appended to
> replicated across a configurable number
of servers for fault tolerance
> all published records are retained (consumed or not)
using a configurable retention period

43
Big Data Landscape
©2015 O‘Reilly Media, Inc.
0
0
0
1
1
1
2
2 3
Stream Processing – Apache Kafka
Topic Partitioning
> position (offset) of consumer is retained
> Configurable consistency semantics
while producer is writing to the topic
wait for replication or not
3 4 5

44
Big Data LandscapeStream Processing – Apache Kafka
+ Originally developed by LinkedIn
+ Widely deployed
> LinkedIn, Ebay, Netflix, PayPal, Uber etc.
+ JVM-based (written in Scala)
+ Kafka is good for, building …
> … real-time streaming data pipelines, that reliably
get data between systems or applications
> … real-time streaming applications,
that transform or react to the streams of data
Source: Confluent Inc.

45
Big Data Landscape
+ Wide-Column stores Bigtable Concept
+ Data Model: “A Bigtable is a sparse, distributed,
persistent multidimensional sorted map.“(Chang et. al. (2006), “Bigtable: A Distributed Storage System for Structured Data”, Google Inc.)
> Map = collection of keys and values
key value data store
> Sorted = key/value pairs are kept in strict alphabetical order (of the key)
> Multidimensional = map is indexed by a row key, column key, and a timestamp
> Sparse = each row can have any number of columns (in each column family) with
varying names and formats
NoSQL – Big Data Storages

46
Big Data Landscape
+ HBase
> “Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.”
(Source: https://hbase.apache.org/)
> Providing bigtable like capabilities for Hadoop (HDFS)
+ Cassandra
> Initially developed at Facebook
> Own data store concept (inspired by Amazon’s Dynamo) with Bigtable data model
+ Accumulo
> Initially developed by the NSA
> Bigtable design build on top of HDFS and Zookeeper
NoSQL – Big Data Storages

47
Big Data Landscape
+ Scaling
> auto-sharding
NoSQL – Big Data Storages
Source: https://blog.cloudera.com

+ Represent data as multidimensional arrays:
48
Big Data LandscapeNoSQL Storage – Array Databases
+ Implicit Index for dimensions: e.g., time, space, spectral
+ High-level data access
+ Compared to files, array DBs require additional ingestion
+ Mostly for raster data, more difficult to represent irregular data

+ Individual DB nodes store and process parts
of the data
+ Queries can run in parallel over the nodes
+ Chunk-based distribution balances memory
comsumption and computational load
49
Big Data LandscapeNoSQL Storage – Array Databases

+ Distributed, highly scalable, near real-time and open source full-text search and
analytics engine
+ Why Elasticsearch?
> Geo features it offers
> e.g. Geohash Indexing &
Aggregation
50
Big Data LandscapeNoSQL Storage – elasticsearch

+ BKD trees for storing numeric and geo data
51
Big Data Landscape
Source: https://commons.wikimedia.org
NoSQL Storage – elasticsearch

+ Cluster consists of several nodes
+ Data is organized in indices (collection of documents) and shards (pieces of an index)
> Allows to horizontally split/scale your content volume
> Allows to distribute and parallelize operations across
shards (potentially on multiple nodes) thus increasing
performance/throughput
+ Data can be replicated
+ Automatically managed how indices and queries
are distributed across the cluster
+ Scales horizontally to handle
large numbers of events per second
52
Big Data Landscape
T2.2
node 1
node 2
node 3node 4
node 5
T1
T2.1
T2.1
r = 1
T1
T2.3
T2.2
T2.3
NoSQL Storage – elasticsearch

Arne de Wall (52°North)Marius Appel (Institue for Geoinformatics)Thomas Paschke (Esri Deutschland)
53
Big Geospatial Data @ Scale

54
Big Geospatial Data @ ScaleEsri ArcGIS Enterprise
ArcGIS
Enterprise
GeoEvent
Server
spatiotemporal
big data store
Big DataIoT
GeoAnalytics
Server

55
Big Geospatial Data @ ScaleEsri ArcGIS R&D Project Trinity
Sensors
DesktopWeb Device
ArcGIS Enterprise with real-time & big data
spatiotemporal
archive
real-time
batch
sources
hubs
project Trinity
+ Managed Cloud Solution
+ Using Microservices with DC/OS
framework
+ Scalable for stream and batch
analysis in new dimensions

56
Big Geospatial Data @ ScaleOpen Source Technologies
GIS Tools for Hadoop
GeoJinni(formerly SpatialHadoop)

+ GeoJinni (formerly SpatialHadoop):
> Spatial Constructs at the core of Hadoop
> Adds different spatial cosntructs to the core of Hadoop
> spatial operations (Spatial Join, Range Query, …)
> index types (Grid, R-Tree, R+-Tree…)
> MapReduce components for the implementation of new spatial operations.
+ GIS Tools for Hadoop
> Spatial Framework for Hadoop: Adds geometric User Defined Functions
(UDFs) for Hive based on the OGC ST_Geometry geometry type.
> Esri Geometry API for Java: UDFs are based on the Esri Geometry API
for Java. Can also be applied for MapReduce algorithms.
> Geoprocessing Tools for Hadoop: Serves as the connector between Esri
ArcMap and the Hadoop Plattform.
57
Big Geospatial Data @ ScaleSpatial Analytics on Hadoop

+ GeoTrellis
> Distributed computations of spatial and spatio-temporal data sets based
on Apache Spark.
> mainly raster (can perform MapAlgebra on distributed tile sets)
> some vector (e.g. vector tiles), a little bit pointcloud
> Support for Python with GeoPySpark.
+ GeoSpark / Magellan / Spatial Spark
> Open source libraries for Geospatial Analytics on top of Spark.
> Provide analytical capabilities especially for vector information.
> All libraries are using different concepts for enhancing Spark
> GeoSpark introduces the Spatial Resilient Distributed Dataset (SRDD)
> Magellan relies on and extends SparkSQL, …
58
Big Geospatial Data @ ScaleSpatial Analytics on Apache Spark
GeoPySpark

+ Distributed spatio-temporal databases with
highly parallelized indexing strategy
> GeoMesa -> Z-Curves
(spatial & spatio-temporal binned by week)
> GeoWave -> Hilbert Curves
(in N-dimensions with tiered indexing and binning)
+ Adds spatial querying and data manipulation to
Accumulo as PostGIS does to Postgres
+ Offers a GeoServer plugin to expose GeoMesa-
managed data via WFS/WMS
59
Big Geospatial Data @ ScaleGeospatial Big Data Storages
Index Type
Backends
Supported
Servers
Supported
Supported
Processing
Frameworks
[1] http://www.geomesa.org/documentation/_images/Zcurve-LoRes.png
[2] https://upload.wikimedia.org/wikipedia/commons/0/0d/Hilbert_Curve.gif
[1] [2]

Arne de Wall (52°North)Marius Appel (Institue for Geoinformatics)Thomas Paschke (Esri Deutschland)
60
Discussion & Program Outlook

+ Big Data is already mainstream – Big Geospatial Data is still in its infancy
> Many existing Big Data technologies are not primarily developed for geo-applications
> Big Data concepts require spatio-temporal adjustments that are not trivial
+ „Best practices“ for geospatial big data are still lacking
> No obvious usage of technologies for specific geo-questions
> Many isolated solutions and most of them are hardly accessible to end users
+ Geo-related questions require a GIS – even in the context of Big Data
61
DiscussionOpen Questions

+ ArcGIS Real-Time & Big Data Solutions
13:30 – 14:00
+ Scalable Earth observation analytics with SciDB
14:30 – 15:00
+ Processing and Analysis of Earth Observation data
17:30 – 18:00
+ R / Python and Big Data, openEO
14:00 – 14:30
62
Program OutlookTechnologies

+ Big Spatial Data in Agriculture
16:00 – 16:30
+ A Query Language for Handling Big Observation Data Sets in the Sensor Web
16:30 – 17:00
+ ArcGIS Big Data Analytics use-cases
17:00 – 17:30
63
Program OutlookApplication Areas

+ Introduction Big (Geospatial) Data
+ Geo-specific Challenges of Big Data
+ Landscape of Big Data
+ Processing Concepts of Big Data
+ Technologies for Big Data
+ Overview of Big Geospatial Data Technologies
64
SummaryIntroduction to Big Data
Volume
Scale of
Data
Velocity
Frequency
of Data
Variety
Data in Many
Forms
Top Related