







Languages
Pages
Legal


Optimizing Search Interactions within
Professional Social Networks
(thesis proposal)
PhD Candidate: Nikita V Spirin
University of Illinois at Urbana-Champaign
Department of Computer Science
Doctoral Committee: Karrie G Karahalios, ChengXiang Zhai,
Jiawei Han, Daniel Tunkelang

Professional Social Networks (PSNs) have
become a sweat spot in the social media ecosystem
Viadeo: over 70M professionals
LinkedIn: over 380M professionals
Xing: over 20M professionals

Professional Social Networks (PSNs) have
become a sweat spot in the social media ecosystem
Viadeo: over 70M professionals
LinkedIn: over 380M professionals
Xing: over 20M professionals
Facebook: over 1.49B users (MAU)

Popular social networks generate
hundreds of terabytes of new
data per day

Keyword search for entities (e.g. people, jobs, groups)
Faceted search to filter entities based on attributes
To help users cope with the immense scale and
influx of new information, professional social
networks provide search functionality

Search within PSNs is fundamentally different
from web search and traditional IR
• The units of retrieval are structured and typed entities rather than documents.
• The entities aren't independent from each other but form the entity graph. Plus, users form the part of this graph.
• Sorting by relevance, typical for web search, is not the only way to order search results. There are many new ways of ordering, e.g. sort by price, sort by date, and etc.
• Rather than providing services to mass market, PSNs' target audience are knowledge workers.

“...it is clearly the case that the new models and
associated representation and ranking techniques
lead to only incremental (if that) improvement in
performance over previous models and techniques,
which is generally not statistically significant (e.g.
Sparck Jones, 2005); and, that such improvement,
as determined in TREC-style evaluation, rarely, if
ever, leads to improved performance by human
searchers in interactive IR systems...”
Nicholas Belkin
Keynote at ECIR 2008

How can we optimize search user
interactions within professional social
networks?

How can we optimize search user interactions
within professional social networks?
Filters
Query formulation, suggestions… Resorting
Snippets for jobs/people
Snippets for jobs/people
Snippets for jobs/people
Breadcrumbs Breadcrumbs Breadcrumbs

How can we optimize search user interactions
within professional social networks?
Filters
Query formulation, suggestions… Resorting
Snippets for jobs/people
Snippets for jobs/people
Snippets for jobs/people
Breadcrumbs Breadcrumbs Breadcrumbs

How can we optimize search user interactions
within professional social networks?
Filters
Query formulation, suggestions… Resorting
Snippets for jobs/people
Snippets for jobs/people
Snippets for jobs/people
Breadcrumbs Breadcrumbs Breadcrumbs

Thesis Statement
We must redesign all major elements of the search UI, such as input, control, and informational, to provide more effective search interactions for users of PSNs. The existing interfaces deliver suboptimal utility as they underutilize structured nature of PSN entities.
I will demonstrate that:
1. structured query language helps users search for relationships and explore the entity graph beyond the first degree;
2. relevance-aware filtering saves users’ efforts when they sort entities by an attribute value rather than by relevance;
3. structured snippets increase search utility for job search by leveraging human intelligence;
4. effectiveness of entity search could be improved with the help of delta-snippets, which show the complementary information about entities and reduce redundancy in the SUI.

Improving Input elements of the SUI
(structured query language)

• Interactive free-text queries (e.g. “Stephen Robertson“,
“SIGIR”, “Chinese Buffet”)
• Interactive structured queries (e.g. “Photos of people
who visited Beijing“)
• One-shot free-text queries (e.g. “big data”, “query log
mining“, “Shanghai”) limited to users' status updates

Interactive free-text queries (e.g. “Stephen Robertson”, “SIGIR“,
“Chinese Buffet”) => Named Entity Queries (NEQs)

• Interactive free-text queries (e.g. “Stephen Robertson“,
“SIGIR”, “Chinese Buffet”)
• Interactive structured queries (e.g. “Photos of people
who visited Beijing“)
• One-shot free-text queries (e.g. “big data”, “query log
mining“, “Shanghai”) limited to users' status updates

Interactive structured queries (e.g. “Photos of people who
visited China“) => Structured Queries (SQs)

• Interactive free-text queries (e.g. “Stephen Robertson“,
“SIGIR”, “Chinese Buffet”)
• Interactive structured queries (e.g. “Photos of people
who visited Beijing“)
• One-shot free-text queries (e.g. “big data”, “query log
mining“, “Shanghai”) limited to users' status updates

• Interactive free-text queries (e.g. “Stephen Robertson“,
“SIGIR”, “Chinese Buffet”)
• Interactive structured queries (e.g. “Photos of people
who visited Beijing“)
• One-shot free-text queries (e.g. “big data”, “query log
mining“, “Shanghai”) limited to users' status updates

We explore the way people search for
people on Facebook
• RQ1: How does search behavior differ for NEQs and SQs?
• RQ2: How does search behavior depend on the graph search
distance (friend vs. non-friend)?
• RQ3: How does search behavior depend on demographic
attributes (age, gender, number of friends, celebrity status)?
• RQ4: How structured querying capabilities are used by the
users of Graph Search?

Anonymized Named
Entity Query Log
• 3M non-novice users
• 58.5M queries
• Sept 2013 – Oct 2013
We use four interconnected data sets
provided by Facebook
Anonymized Structured
Query Log
• 3M non-novice users
• 10.9M queries
• Sept 2013 – Oct 2013
Anonymized Social Graph
• 858M vertexes
• 270B edges
• Oct 2013 snapshot
Anonymized User Profiles
• 858M vertexes
• Age, gender, # of friends
• en_US (English + USA)

Definitions: graph search distance
Named Entity Query
Use a traditional graph-theoretical
definition of the graph distance
Structured Query
1. If one entity, use a traditional
graph-theoretical definition
2. If 2+ entities, compute the
distance to each one as-is or following functional
superposition of User predicates
3. Compute a bit vector with three
components (one for each of the
three classes of the graph distance) and normalize it by the
number of non-zero components
RQ1,RQ2

NEQs and SQs complement each other enabling
more effective exploration of the network
• Users search for friends using NEQs and search for non-
friends using SQs.
• Self queries are less popular compared to an overall
query volume.
• Users search for themselves more using SQs.
RQ1,RQ2

Age Gender Number of friends
RQ3

Graph search distance vs. Age (10-year bins)
Users write NEQs for friends more often compared to NEQs
for non-friends across all age bins.
0
2
4
6
8
10
12
14
10 20 30 40 50 60 70 80
NEQ 1st/user
NEQ 2nd+/user
RQ3

Graph search distance vs. Age (10-year bins)
The graph for SQs is bi-modal. Non-friend SQs prevail for
the younger users. Friend SQs prevail for the older users.
0
0.5
1
1.5
2
2.5
3
10 20 30 40 50 60 70 80
SQ 1st/user
SQ 2nd+/user
RQ3

Graph search distance vs. Age (10-year bins)
The younger users more actively search for non-friends and
the older – for friends, relative to the average user.
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
RQ3

Graph search distance vs. Gender
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
Females write more queries than males and it is consistent
across the query types (both for NEQs and SQs).
0
5
10
15
20
25
female male
NEQ1st/user
NEQ2nd+/user
NEQ/user
0
0.5
1
1.5
2
2.5
3
3.5
4
female male
SQ1st/user
SQ2nd+/user
SQ/user
RQ3
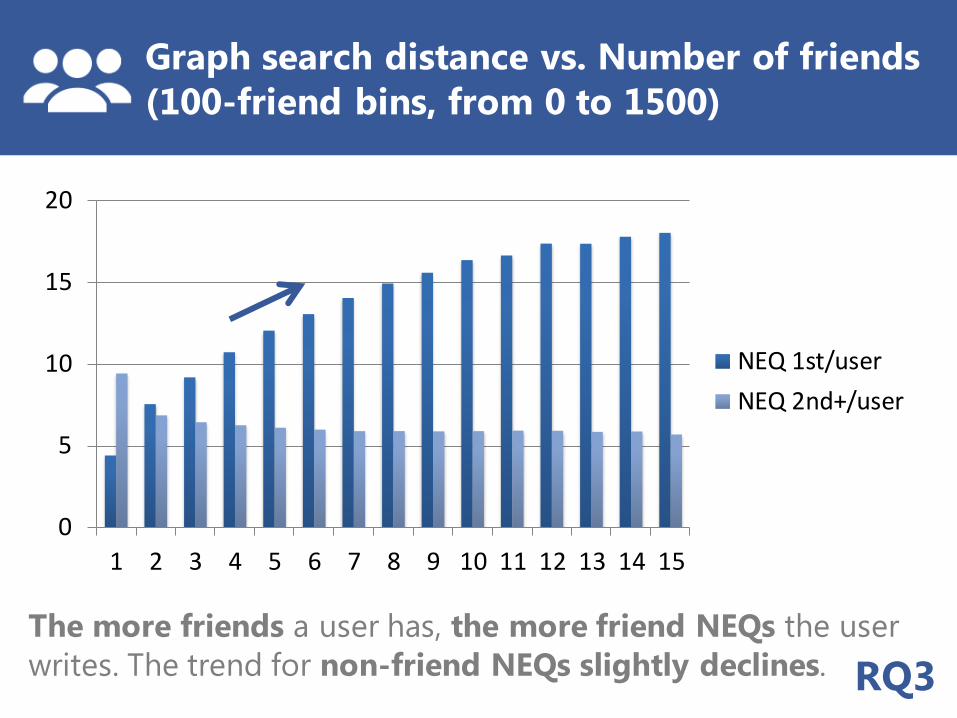
Graph search distance vs. Number of friends
(100-friend bins, from 0 to 1500)
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
The more friends a user has, the more friend NEQs the user
writes. The trend for non-friend NEQs slightly declines.
0
5
10
15
20
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
NEQ 1st/user
NEQ 2nd+/user
RQ3

0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
Users with more friends write less non-friend SQs.
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
SQ 1st/user
SQ 2nd+/user
SQ/user
RQ3
Graph search distance vs. Number of friends
(100-friend bins, from 0 to 1500)

0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
The trend for non-friend NEQs is flat, while friend NEQs
contribute to the growth of the query volume. RQ3
Graph search distance vs. Number of friends
(100-friend bins, from 0 to 1500)
0
5
10
15
20
25
30
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
NEQ 1st/user
NEQ 2nd+/user
NEQ/user

0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
SQ 1st/user
SQ 2nd+/user
SQ/user
RQ3
Graph search distance vs. Number of friends
(100-friend bins, from 0 to 1500)
The trend for friend SQs is flat, while the volume of non-
friend SQs changes with the number of friends.

Graph Search Grammar Usage
RQ4

Definitions Definitions: semantic query template
“Photos of Alice and friends of Alice and males
named Bob who live California”
RQ4

Structured query popularity vs. Length,
measured as # of functional predicates
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
RQ4
• Shorter SQs are more popular.
• Users write shorter grammar queries when they search for the
first degree connections.

Structured query popularity vs. Length,
measured as # of functional predicates
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
• Shorter SQs are more popular.
• Users write shorter grammar queries when they search for
the first degree connections.
RQ4

Distance preference for grammar predicates
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Self
Friends
Non-friends
RQ4

Distance preference for grammar predicates
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Self
Friends
Non-friends
RQ4

Distance preference for grammar predicates
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
Self
Friends
Non-friends
RQ4

Grammar usage for name disambiguation
0
0.2
0.4
0.6
0.8
1
1 2 3 4 5 6 7 8
NEQ1st/(1st + 2nd+)ratio
SQ1st/(1st + 2nd+)ratio
RQ4
Top-5 groups of
disambiguation
predicates used in SQs
1. Location
2. Affiliation (e.g. Company)
3. Interest
4. Gender
5. Relationship

Key takeaways and design implications
• Both NEQs and SQs are important to facilitate navigation
and exploration within the social network
– Users search for friends with NEQs
– Users search for non-friends and explore the graph using SQs
• Personalized search query suggestions are very promising
– Focus on SQs if have limited time or resources to achieve maximum
results since it has higher variance across demographic groups
– Don’t limit query suggestions to friends only; include some
interesting distant network vertices
– Use lift predicates while generating query suggestions
– Take into account a predicate degree preference distribution, i.e.
ranking entities for a predicate using its graph distance distribution

Improving Control elements of the SUI
(sorting entities by an attribute value)

Search for “data scientist” sort by “relevance”

Search for “data scientist” sort by “date desc”

Search for “product manager” sort by “relevance” Search for “product manager” sort by “relevance”
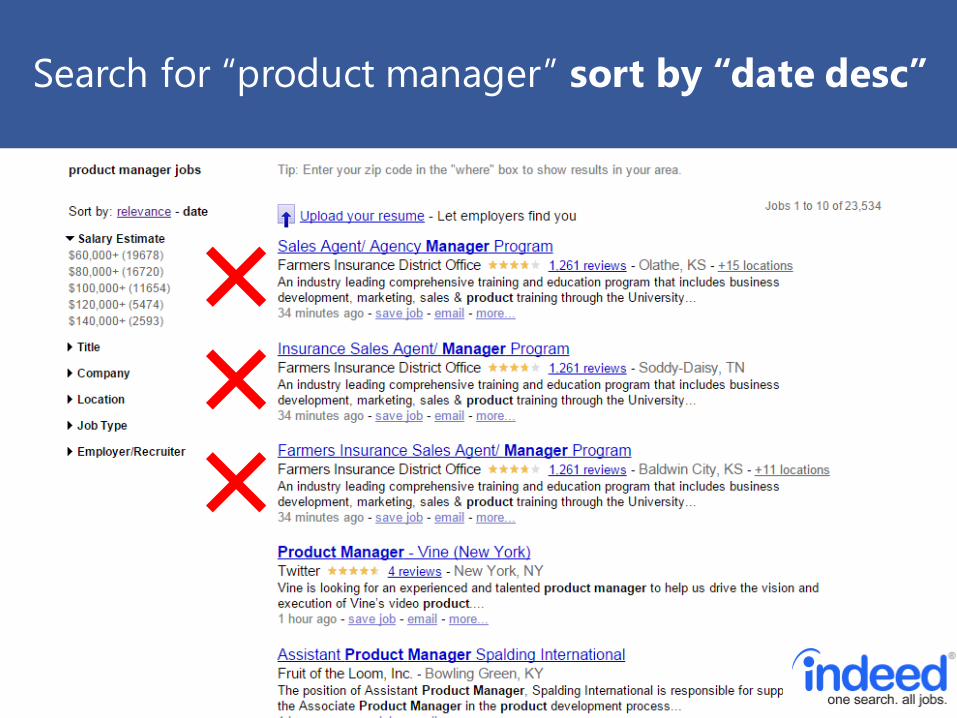
Search for “product manager” sort by “relevance” Search for “product manager” sort by “date desc”

Search for “table” sort by “relevance” Search for “table” sort by “relevance”

Search for “table” sort by “time desc” Search for “table” sort by “relevance” Search for “table” sort by “time desc”

Search for “chocolate” sort by “relevance” Search for “table” sort by “relevance” Search for “chocolate” sort by “relevance”

Search for “chocolate” sort by “price asc” Search for “table” sort by “relevance” Search for “chocolate” sort by “price desc”

Problems with the existing SUIs supporting
result re-sorting by an attribute value
• When results are sorted by relevance, the output is good
– Average Precision@10 is 0.86
– Results are personalized for the user
• When sorting by an attribute value, e.g. price low-to-high,
date recent-to-old, and so on, there are many irrelevant
results at the top of the SERP
– Average Precision@1 is 0.44
– Average Precision@5 is 0.45
– 61% of queries have the Precision@10 below 0.5
– Personalization is gone

We explore how to improve relevance of
search results sorted by an attribute value
• RQ5: Can the quality be improved by incorporating
relevance into the ranking process?
• RQ6: What is the best way to accomplish it?

Relevance = 0
Relevance = 3
Relevance = 1
Relevance = 2
Relevance = 1
Relevance = 3
0
3
1
2
1
3 So
rted
by a
n a
ttri
bu
te
Problem Formalization

• Natural enumeration order for subsequences
• Prefix-additivity of search quality metrics
• Optimality of subproblems => can use dynamic programming
1, 2
3, 4, 5
12, 13, 14,
15, 23, 24, 25, 34, 35
123, 124,
125, 134, 135, 234, 235, 345
1234
1235
2345
12345
Key insights underlying the solution

Evaluation trace for a toy example problem
{(0, 0); (1, 3); (2, 1); (3, 2); (4, 1); (5, 3)}
Dependencies between problems
in the memoization matrix and
proper evaluation order
Reconstruction of the optimal
path using the intermediate
values in the memoization matrix

• Predict relevance labels with Gradient Boosted Regression
Trees (5-fold cross validation partitioning)
• Extend MQ2007 and MSLR-WEB10K data sets by assigning a
random timestamp to each document to model the sorting
by the attribute value
• Apply filtering as the final step in the query processing
pipelines for the following baselines:
– B1: sort by the attribute value and do nothing else (weak)
– B2: predict relevance labels, take all above the threshold, re-sort by
the attribute value (somewhat strong)
– B3: sort by relevance, take top-k results, re-sort by the attribute value
(strong)
• Average the results from 1000 simulation runs
Experiments with the real L2R data sets (MSR
LETOR collections MQ2007 and MSLR-WEB10K)

Our approach outperforms all baselines (including
top-k re-ranking) and leads to ~2-4% lift in NDCG M
Q2
00
7
MSLR
-WEB
10
K

The behavior of the algorithm for different
input sizes and relevance label distributions

Key takeaways and design implications
• The quality of search results sorted by an attribute value could
be improved using relevance-aware filtering. The proposed
algorithm consistently outperforms all known baselines and
increases search quality by 2-4%
• Assuming that users scan the results sequentially, the proposed
algorithm is theoretically optimal as it directly optimizes a
search quality metric within a dynamic programming framework
• Higher gains are characteristic for the relevance label
distributions, where relevant results are more probable, and for
medium length result sets (20-100 tuples)

Improving Informational elements of SUI
(snippets for job search)

Examples of existing job search user interfaces
and problems with them
Title + Snippet
redundancy
Title + Snippet
redundancy
Marginally relevant information
about a job – hi, Chris!

Numbers aren’t useful
Examples of existing job search user interfaces
and problems with them

Jobs are not directly
related to “data science”.
No reason to click
without knowing why
they are shown. Snippets aren’t very informative
to help in making a
click decision.
Examples of existing job search user interfaces
and problems with them

Hard to differentiate
similar job titles +
no textual snippets
(only company,
location, date posted)
Examples of existing job search user interfaces
and problems with them

Hard to differentiate
similar job titles +
no textual snippets
(only company,
location, date posted)
Examples of existing job search user interfaces
and problems with them

What differentiates
these two jobs?
Examples of existing job search user interfaces
and problems with them

The problem is that search snippets are either
absent or generated with very naive heuristics
• Titles on the SERP are not discriminative and minimally help users in making click decisions. Users play the “lottery” by trying to find a relevant link among 10 similarly looking links.
• A title and a snippet are redundant, which requires users to spend more time on the SERP without extra gains.
• Often the content of a snippet doesn’t provide useful information about a job posting hidden behind the link. For example, snippets contain irrelevant numbers, names, and etc.
• For jobs, which are not directly related to the query, snippets with the title only doesn’t help in making click decisions. For example, software engineer in a data-driven company might do data science, but the common belief is not => users will ignore such a job posting.

The proposal is to standardize job postings using
information extraction prior to snippets generation
Generate snippets for job search Optimize detailed page views

We explore the feasibility to generate
structured snippets and their effectiveness
• RQ7: Do structured snippets improve search user
experience for job search? How do users behave when
structured snippets are used?
• RQ8: How to generate structured snippets for job
search? Is it possible to generate them in an
unsupervised way?

Jobs are quite regular and one word per section is
enough to prepare the learning set for ML model
RQ7

RQ7
Jobs are quite regular and one word per section is
enough to prepare the learning set for ML model

RQ7
Jobs are quite regular and one word per section is
enough to prepare the learning set for ML model

Unsupervised approach to perform structured
summarization and IE from job postings
• Crawl a lot of job postings from the web (1M+ jobs)
• Leveraging data redundancy and inherent structure, align job postings and generate a training set in unsupervised way (10M+ sentences in the A/B study)
• Train a machine learning model to predict section for a
new sentence from a new job posting – Linear SVM with the feature hashing (Joachims et. al 2006)
– Bag of words, binary features, 1,2,3-grams, capitalization, etc.
– Stacking of several models trained with different features RQ7

Unsupervised VS. Supervised (English)
Unsupervised approach scores equally good compared to the
supervised model trained on a corpus of 1000 labeled job
postings. At the same time, our unsupervised approach is easily
deployable for many languages and has higher coverage.
RQ7

Extraction quality across job titles (English)
Extraction quality is consistently high across randomly
selected sample of job titles. It implies generalizability of the
model to the entire job search domain. RQ7

Tuning for a special language (Russian) leads
to boost in information extraction quality
• Active learning pipeline to bootstrap more accurate section detection rules, which minimizes human
intervention and efforts and increases model precision
• Hybrid algorithm based on rules and machine learning as a back-off [2 stage processing]:
– Do high accuracy classification using manually defined rules
– Classify with the machine learning model other sentences
0
50
100
1 4 7 10 13 16 19 22 25 28 31 34 37 40 43 46 49 52
Pag
es
cove
red
%
Number of rules
RQ7

Before (#1 job search engine in Russia)
Hard to differentiate
similar job titles +
no textual snippets
(only company,
location, date posted)
RQ8

After (tested in production A/B tests with #1 job search
engine in Russia): DEFAULT vs. RESP+REQ+COND
RQ8

The ratio of SERP clicks per query is less
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1 2 3 4 5 6 7 8 9 10 11
Less
is
bett
er
Days since the beginning of the experiment
Series1
Series2
RQ8

The ratio of job actions over job views is more
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1 2 3 4 5 6 7 8 9 10 11 12
Mo
re is
bett
er
Days since the beginning of the experiment
Series1
Series2
RQ8

The ratio of job applications over job views is more
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
Mo
re is
bett
er
Days since the beginning of the experiment
Series1
Series2
RQ8

Other relevant metrics from the A/B test
• Extraction quality: 97% precision at 100% coverage
• Decreased number of queries per session by 8%
• Decreased number of detailed page views by 1.4X
• Increased number of applications overall by 1.6%
• Increased application rate conditioned on click by 13%
• Decreased number of short clicks by 5.5%
• Decreased number of wasted views by 1.25X
• Decreased click entropy 1.98X
RQ8

[job]snipper system architecture
BI
Lo
gic
Co
nta
iner
Redis Cache
Model Builder
Memory
Model Rules Config
Redis Cache
Memory
Model Rules Config
AP
I En
d-p
oin
t (N
gin
x P
roxy
)
Crawler Rules Config

Key takeaways and design implications
• The proposed approach leverages the power of big data for
unsupervised model training and doesn’t require data
labeling compared to existing approaches to IE
• Already for one rule IE accuracy is high and it can be further
optimized by increasing the # of IE rules and data set size
• Structured snippets improve search user experience:
– Minimize irrelevant clicks
– Standardize representation
– Eliminate title-snippet redundancy

Improving Informational elements of SUI
(snippets for people/entity search)

Examples of existing user interfaces for entity
search within PSNs and problems with them

Examples of existing user interfaces for entity
search within PSNs and problems with them

Examples of existing user interfaces for entity
search within PSNs and problems with them

Examples of existing user interfaces for entity
search within PSNs and problems with them

Examples of existing user interfaces for entity
search within PSNs and problems with them

Examples of existing user interfaces for entity
search within PSNs and problems with them

Examples of existing user interfaces for entity
search within PSNs and problems with them
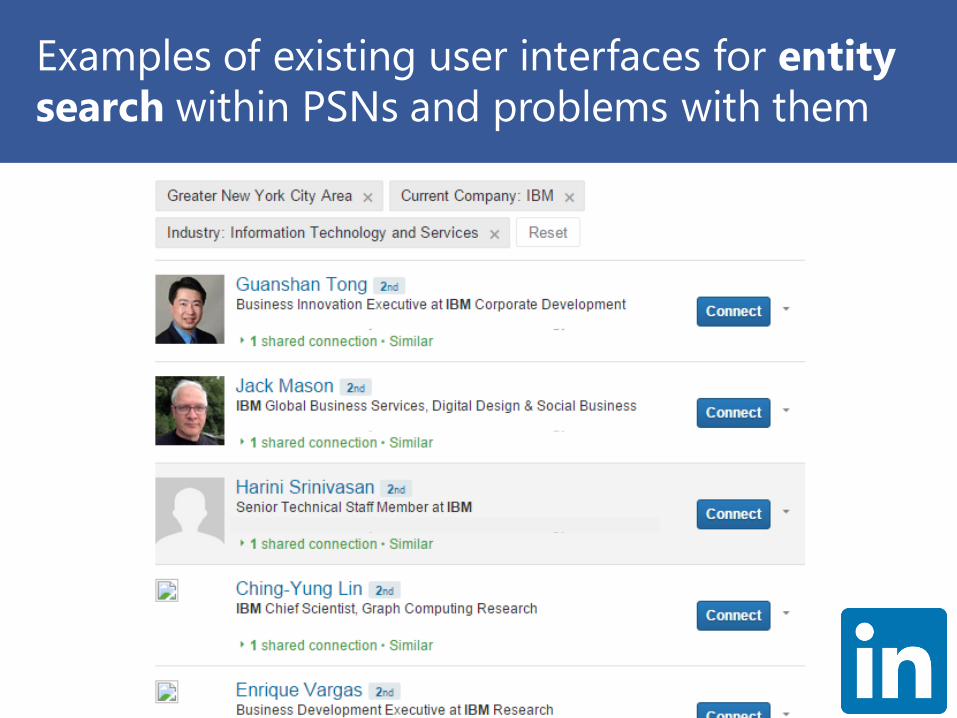
Examples of existing user interfaces for entity
search within PSNs and problems with them

The longer the query in the exact match
scenario, the more redundant and less
informative a query-biased snippet gets
Query-snippet duality

• RQ9: How do users react to delta-snippets? Do they
understand that results match the filters specified in a query?
• RQ10: Can delta-snippets make users more productive
compared to the existing query-biased entity snippets?
The proposal is to use delta-snippets showing information complementary to the query in the exact match scenario

Design space for “persuasive” SUI: structured query
language with the bolded entities

Design space for “persuasive” SUI: breadcrumbs
Hearst et al. CHI ‘2003

Design space for “persuasive” SUI: advanced operators

• Structured query language with the bolded entities
• Breadcrumbs
• Explicitly mention that only exact match entities are shown

• Structured query language with the bolded entities
• Breadcrumbs
• Explicitly mention that only exact match entities are shown
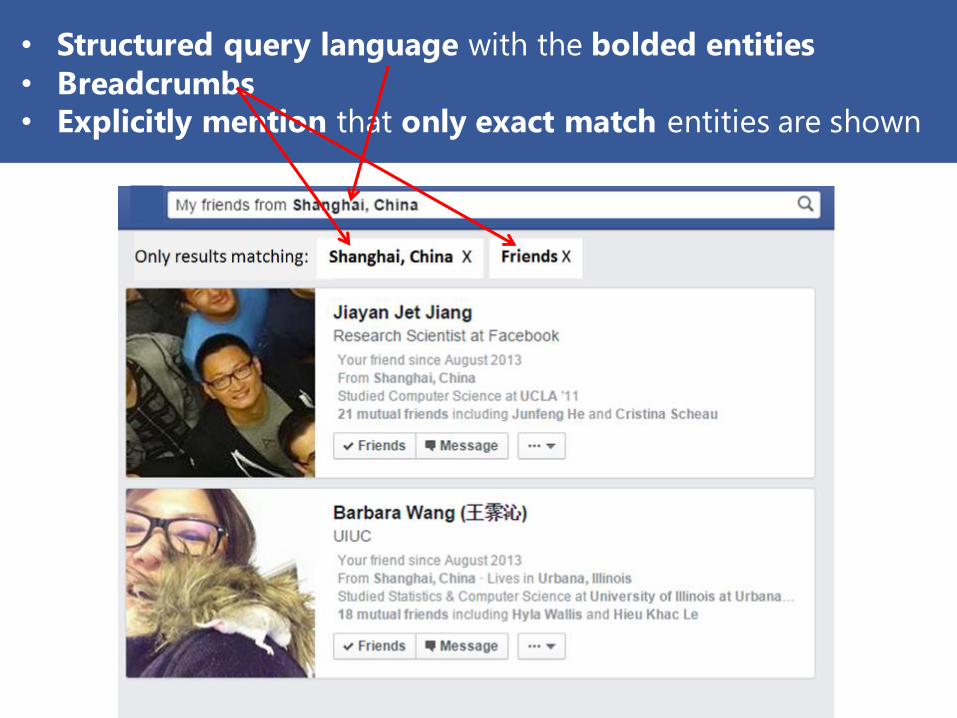
• Structured query language with the bolded entities
• Breadcrumbs
• Explicitly mention that only exact match entities are shown

• Structured query language with the bolded entities
• Breadcrumbs
• Explicitly mention that only exact match entities are shown

• Structured query language with the bolded entities
• Breadcrumbs
• Explicitly mention that only exact match entities are shown
Location
Occupation
Skills
Education

Query-biased snippets Delta-snippets (our proposal)
Method: laboratory A/B user study

• Participants:
– 24-36 members from UIUC community
– Must be 25-34 years old (core users of PSNs)
– Must use at least one social network more than once per week
– reward for participation in the study
• Experimental procedure:
– [10 min] Briefing section describing the SUIs and procedures
– [10 min] Pre-study survey – what search engines do you use, how often,
for what purpose, how familiar are you with social search, and more
– [10 min] Initialization task - read all topics and for each say what do
you expect to see on the SERP? why?
– [50 min] Working on tasks – seven tasks per experimental condition,
order randomized using Latin square design (5 easy + 2 hard tasks)
– [10 min] Post-study survey – which version did you like? why?
Method: laboratory A/B user study

• Tasks (parallel within-subject design to increase reliability):
– [2 min] Find a person who lives in New York
– [2 min] Find 3 people who work at Deloitte
– [2 min] Find a person working as a project manager
– [2 min] Find operations manager who works at Uber
– [2 min] Find iOS engineers who work at Uber
– [8 min] You are an HR and your task is to hire 10 Android engineers for
a secret project in San Diego. Only engineers from Google or Twitter
are allowed. Any candidate that meets these constraints is a great fit.
– [8 min] Your friend Alice/Bob is looking for a date and you want to help
her/him. Find 5 potential candidates. Alice/Bob lives in Boston and
cannot travel. S/he likes karaoke and coffee. S/he told you that in the
past s/he did not like dating with the Designers and Doctors.
• Setup: we use Latin square design to randomize conditions
Method: laboratory A/B user study

• System instrumentation:
– Search logs (queries, clicks, scrolls, page views)
– Eye-tracker [optionally]
• Measurements/Metrics:
– Task completion time
– Task completion success (Precision/Recall for hard tasks)
– Dwell time before the first click
– Query length
– Query count
– Usage of entity-focused query suggestions
– Usage of breadcrumbs
– Qualitative and quantitative analysis of survey responses
Method: laboratory A/B user study

Hypotheses and expected outcomes
• It is possible to communicate to the users that the
matching is exact with the proper SUI design elements
• As users gain experience with the SUI using delta-snippets
for exact match scenarios, they become more comfortable
relying on delta-snippets and write longer queries
• Delta-snippets help reduce query-snippet redundancy and
lead to faster task completion times

Key contributions behind the thesis
A large scale analysis of Facebook Graph Search query logs (CIKM
2014 + invited for keynote at SIGIR 2015 workshop on “Graph
Search and Beyond”)
An algorithm for relevance-aware search results filtering (SIGIR
2015 + work-in-progress on the journal paper at JASIST)
An algorithm for snippets generation for job search (WWW 2013 +
work-in-progress on the journal paper at JASIST/IPM/IRJournal)
• [new project] A user study analyzing the effectiveness of delta-
snippets for entity search (planning to submit for SIGIR 2016)

Thank you!

Interested to collaborate? Let us do it!
I also would love to discuss community
projects around data science.
Skype: @spirinus
Twitter: @spirinus
Gmail: [same_as_above]@gmail.com
Top Related