







Languages
Pages
Legal


Nyelvi reprezentáció tanulás
Ákos Kádár

En
• Tilburg University vegzos PhD
• Microsoft Research Montreal heti par ora
• Deep Learning integrating Vision and Language
• Juniusban kezdek Samsung AI Toronto
1/59

Termeszetes nyelvfeldolgozas
• Alexa, Siri
• Search
• Google Translate
2/59

Amirole nem lesz szo
s
3/59

Input
4/59
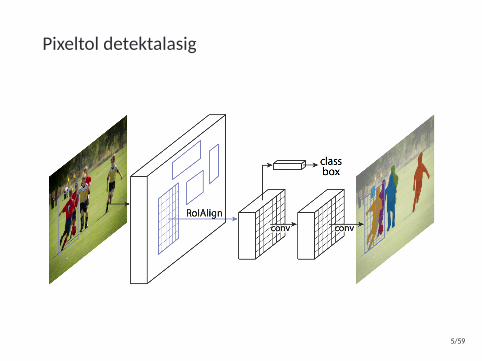
Pixeltol detektalasig
5/59

Hanghullambol hanghullam
6/59

NLP: Input
• Deep Learning♡ Raw Input
• Kep/Video: Pixel
• Hang: 16bit audio
• Szoveg: szo/karakter
7/59

Diszkretebol folytonos
8/59
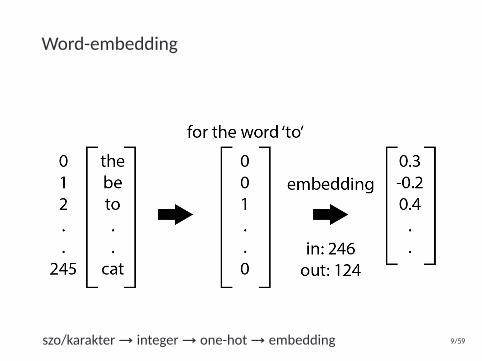
Word-embedding
szo/karakter→ integer→ one-hot→ embedding 9/59
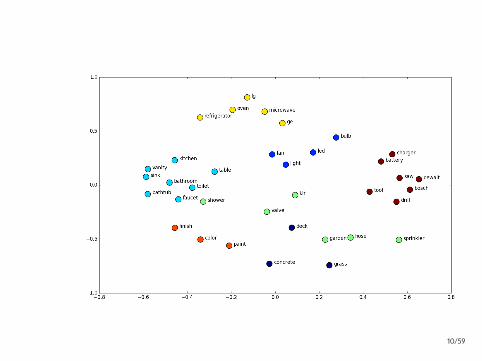
10/59

Word-embedding Literature
• GloVe: https://nlp.stanford.edu/projects/glove/
• Word2Vec: https://en.wikipedia.org/wiki/Word2vec
• fastText: https://fasttext.cc/
11/59

Recurrent Neural Network
ht = f(ht−1, xt)
12/59
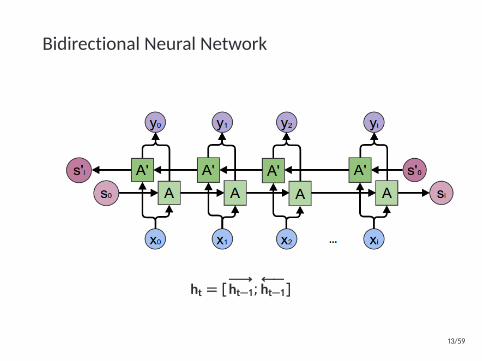
Bidirectional Neural Network
ht = [−→ht−1;
←−ht−1]
13/59

LSTM
⎡⎢⎢⎢⎣itftutot
⎤⎥⎥⎥⎦ =Wxt + Uht−1 + b (gates and candidate)
ct = ct−1 � σ(ft) + tanh(ut) � σ(it) (cell state)
ht = σ(ot) � tanh(ct) (hidden state)
14/59

Klasszifikacio

Feladatok
• Sentiment (IMDB, Yelp)
• Cyberbulling (Twitter)
• Dokumentum tema (Yahoo answers)
• Kerdes tipus (Quora)
16/59

17/59
18/59

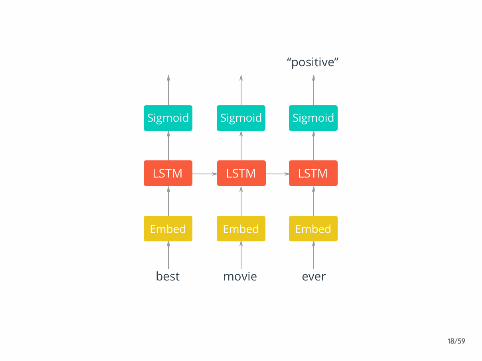
Tanulas
• Tanulo adat (y, < x1, . . . , xt >)
• Joslas: y = P(y|d, θ)
• Josolt cimke yi = arg max P(y|d, θ)
• Loss Function: J(y, y) = − log y∗
Warning: Nagyon tul magabiztos modellek (poorly calibratedprobabilities)!
19/59

Tanulas
• Tanulo adat (y, < x1, . . . , xt >)
• Joslas: y = P(y|d, θ)
• Josolt cimke yi = arg max P(y|d, θ)
• Loss Function: J(y, y) = − log y∗
Warning: Nagyon tul magabiztos modellek (poorly calibratedprobabilities)!
19/59
20/59

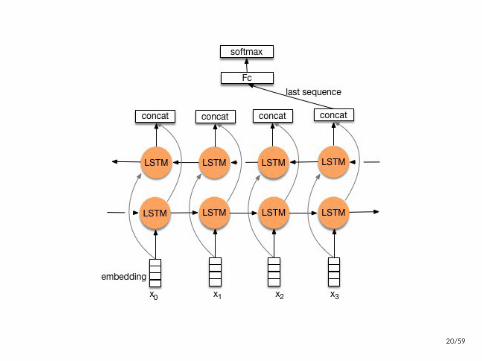
Klasszifikacio
[h1, . . . ,ht
]= BiLSTM(mondat)
h = [h1;ht]
y =Woh
P(y = i|mondat) =eyi∑j eyj
21/59

Tips and tricks: pooling
Miert pont h = [h1;ht]?
h = max([h1, . . . ,ht
]) (max pooling)
h =1
T
T∑i=1
hi (mean pooling)
22/59

Tips and Tricks: "Deep" LSTM
23/59
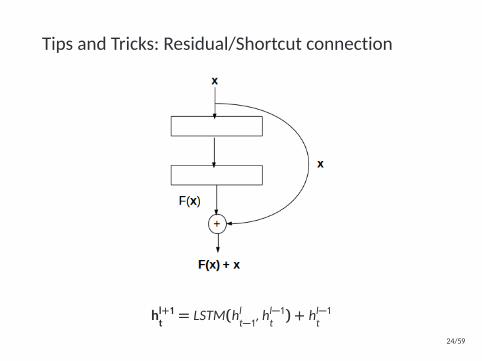
Tips and Tricks: Residual/Shortcut connection
hl+1t = LSTM(hlt−1, hl−1t ) + hl−1t
24/59

LSTM OMG
• Regularizacio: Dropout, Dropconnect, Zoneout
• Gradient clip (mindig 3.0 – 5.0), Adaptive learning rate(Adamhoz is!!!!!)
• LayerNorm, WeightDrop, WeightNorm
• On the State of the Art of Evaluation in Neural LanguageModels: https://arxiv.org/pdf/1707.05589.pdf
• Oruletes trukkok: Regularizing and Optimizing LSTM LanguageModels: https://arxiv.org/abs/1708.02182
25/59

word_dim=300, hidden_dim=512, batch_size=64, lr=0.0002
26/59

Sequence tagging

Feladatok
• Named Entity Recognition: Tulajdonnevek (ember nev, ceg nevstb.) hasznos downstream.
• Baromi sok nyelveszeti cucc ami hasznos pipeline-okban.
28/59

Named Entity Recognition
29/59
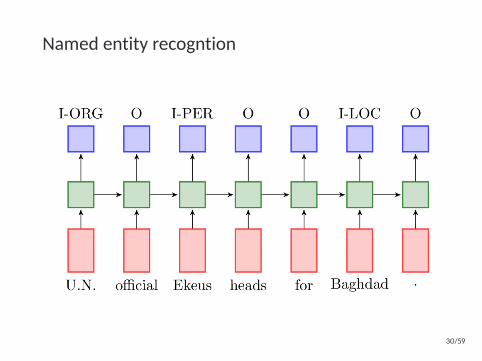
Named entity recogntion
30/59

Tanulas
• Tanulo adat (< y1, . . . , yn >,< x1, . . . , xt >)
• Joslas: yt = P(yt|(xt, x<t, y<t), θ)
• Josolt cimke arg maxy∈Y P(y|X, θ)
31/59

Hidden Markov Model
P(tt|t1, . . . , tt−1) = P(tt|tt−1) (transition prob)
P(ot|t1, . . . , tt, o1, . . . , ot−1) = P(ot|tt) (emission prob)
P(ot, . . . , o1, tt+1, . . . , t1) =i+1∏i=1
q(ti|ti−1)n∏i=1
e(oi|ti)
(bi-gram tagger)
Az argmax-ot megtalalja egy dinamikus program: Viterbi 32/59

Linear Chain Conditional Random Field
p(y|x) =1
Z(X)
T∏texp
{ K∑k=1
θkfk(tt, tt−1, xt)
}(log-linear model)
Z(X) =∑y
T∏texp
{ K∑k=1
θkfk(tt, tt−1, xt)
}(partition function)
p(y|x) =1
Z(X)
T∏tt(tt, tt−1, xt) (factor-graph reprezentacio)
Ne aggodjatok a VITERBI megtalalja :D.
33/59

Linear Chain Conditional Random Field
p(y|x) =1
Z(X)
T∏texp
{ K∑k=1
θkfk(tt, tt−1, xt)
}(log-linear model)
Z(X) =∑y
T∏texp
{ K∑k=1
θkfk(tt, tt−1, xt)
}(partition function)
p(y|x) =1
Z(X)
T∏tt(tt, tt−1, xt) (factor-graph reprezentacio)
Ne aggodjatok a VITERBI megtalalja :D.
33/59
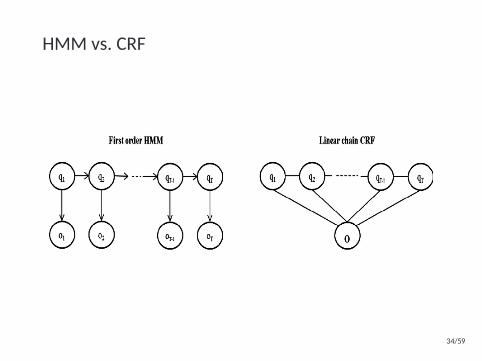
HMM vs. CRF
34/59

BiLSTM tagger
35/59

BiLSTM tagger
[h1, . . . ,ht
]= BiLSTM(mondat)
y1, . . . , yt =Wo
[h1, . . . ,ht
]P(y1 = i|mondat) =
ey1i∑
j ey1j
36/59

BiLSTM + CRF
• P ∈ Rt×k: t szo, k tag, Pi,j j-edik tag erteke a i-edik szora.
• A ∈ Rk+2×k+2: Ai,j transition-score a i-edik tagbol a j-edikbe.
score(x, y) =∑i=0
Ayi,yi+1 +∑i=1
Pi,yi
P(y|x) =escore(x,y)∑y∈Y escore(x,y)
logP(y|x) = score(x, y) − log
⎛⎝∑y∈Y
escore(x,y)
⎞⎠y∗ = arg maxy∈Yscore(x, y)
37/59
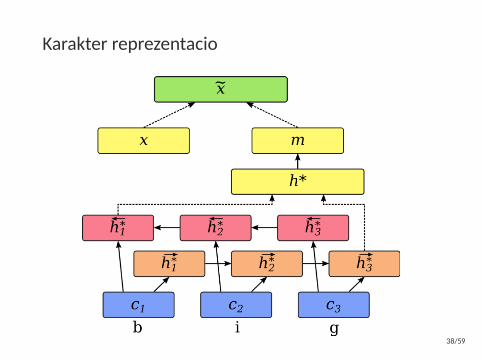
Karakter reprezentacio
38/59
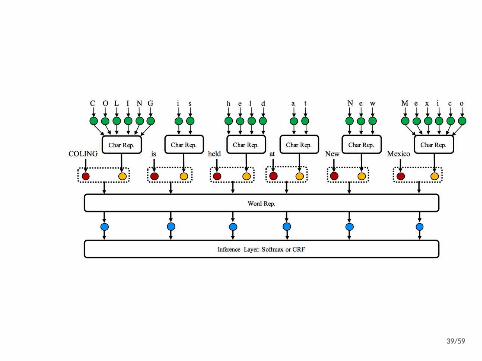
39/59

Neural Tagging
• Bidirectional LSTM-CRF Models for Sequence Tagging:https://arxiv.org/abs/1508.01991
• Neural Architectures for Named Entity Recognitionhttps://arxiv.org/pdf/1603.01360.pdf
• Design Challenges and Misconceptions in Neural SequenceLabeling: https://arxiv.org/abs/1806.04470
40/59

Mondat Generalas

Mondat Generalas
• Tanulo adat (< y1, . . . , ym >, X)
• Loss: L(θ, Xi) = −∑
m logp(ym|y∗<j, Xi, θ)
42/59

Feladatok
• Gepi forditas
• Képleírás (image-captioning)
• Dialogus rendszerek
43/59
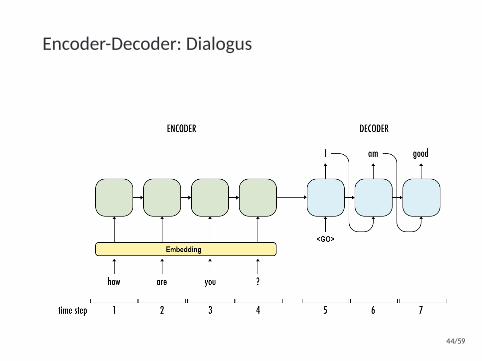
Encoder-Decoder: Dialogus
44/59
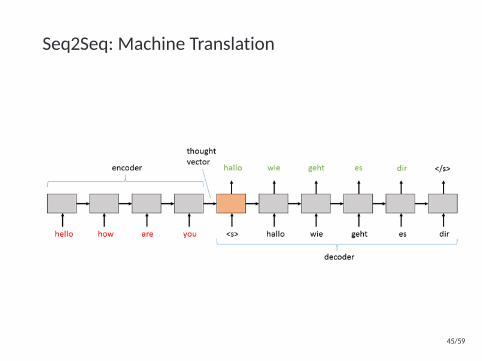
Seq2Seq: Machine Translation
45/59

Encoder-Decoder
[henc1 , . . . ,henct
]= BiLSTM(mondat)
henc = λ([henc1 , . . . ,henct
])
hdec1 = LSTM(henc, START,0)
y1 = arg max softmax(hdec1 )
hdec2 = LSTM(hdec1 , xt, y∗1 )
y2 = arg max softmax(hdec2 )
46/59
47/59
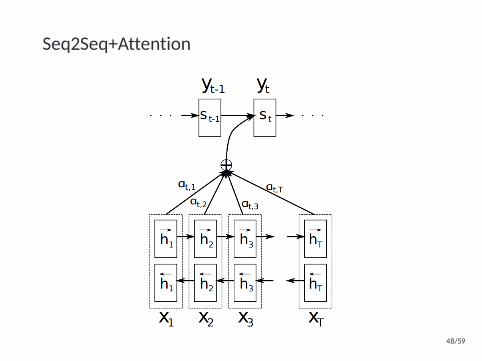
Seq2Seq+Attention
48/59

Attention mechanizmus
eji = vaTtanh(Wahdecj + Uahi)
αji =exp(eji)∑Ni exp(eli)
cj =N∑i
αjihi
49/59
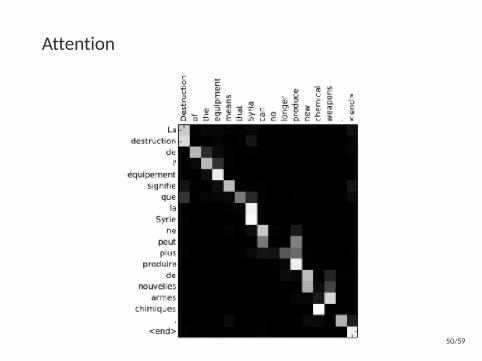
Attention
50/59

Google NMT
51/59

Zero-shot
Adat: A→ B, B→ C
Teszt: A→ C
52/59
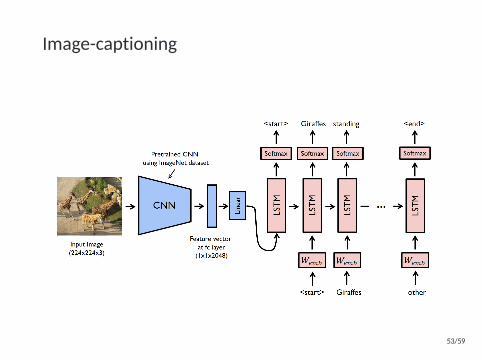
Image-captioning
53/59

54/59

Seq2seq
• Neural Machine Translation and Sequence-to-sequence ModelsTutorial: https://arxiv.org/pdf/1703.01619.pdf
• Show and Tell: A Neural Image Caption Generatorhttps://arxiv.org/abs/1411.4555
55/59

Exposure bias
• L(θ, Xi) = −∑
t logp(yt|y∗1 , . . . , y∗t−1, X)
• yt+1 = argmax P(y|y1, . . . , yt, X)
• Teszt es tanulas kozotti kulonbseg.
• Loss es evaluation metric kozotti kulonbseg.
56/59

Mondat-szintu tanulas RL-el
∇L(θ) = −Ey∼pθ
[R(y)∇ logpθ(y)
](Expectation)
∇θL(θ) ≈ −R(y)∇θ logpθ(y) (Monte-Carlo sample)
• R(y): evaluation metric (BLEU, METEOR, ROUGE)
• Evaluation metric = Objective function
• Mondat-szintu objetive
57/59

Sequence level loss for RNNs
• Sequence level training with recurrent neural networks:https://arxiv.org/pdf/1511.06732.pdf
• Classical Structured Prediction Losses for Sequence to SequenceLearning: http://aclweb.org/anthology/N18-1033
• SEARNN : Training RNNs with Global-Local losses:https://arxiv.org/pdf/1706.04499.pdf
58/59

Vegre vege
• Deep Learning: LSTM/CNN/Transformer general featureextractor
• Raktunk a tetejere egy loss fuggvenyt
• Hasznaltuk az LSTM reprezentaciot/valiszinusegeit egy keresoalgoritmusban
• Parsing with Dynamic programming:https://www.youtube.com/watch?v=gRtEW6Q5XJE
59/59
Top Related