







Languages
Pages
Legal


Helen He!NUG Meeting, 10/08/2015
Nested OpenMP

OpenMP Execution Model
• ForkandJoinModel– Masterthreadforksnewthreadsatthebeginningofparallelregions.
– Mul6plethreadsshareworkinparallel.– Threadsjoinattheendoftheparallelregions.
-2-

Hopper/Edison Compute Nodes
-3-
• Hopper:NERSCCrayXE6,6,384nodes,153,126cores.• 4NUMAdomainspernode,6coresperNUMAdomain.
• Edison:NERSCCrayXC30,5,576nodes,133,824cores.• 2NUMAdomainspernode,12coresperNUMAdomain.
2hardwarethreadspercore.• Memorybandwidthisnon-homogeneousamongNUMAdomains.

MPI Process Affinity: aprun “-S” Option • Processaffinity:orCPUpinning,bindsMPIprocesstoaCPUorarangesof
CPUsonthenode.• ImportanttospreadMPIranksevenlyontodifferentNUMAnodes.• Usethe“-S”opWonforHopper/Edison.
-4-
0200400600800
100012001400
24576*1 12288*2 8192*3 4096*6 2048*12
RunTime(sec)
MPITasks*OpenMPThreads
GTCHybridMPI/OpenMPonHopper,24,576cores
with-S-ss
no-S-ss
aprun–n4–S1–d6
aprun–n4–d6
Lower is B
etter
-S2–d3

Thread Affinity: aprun “-cc” Option
• Threadaffinity:forceseachprocessorthreadtorunonaspecificsubsetofprocessors,totakeadvantageoflocalprocessstate.
• Threadlocalityisimportantsinceitimpactsbothmemoryandintra-nodeperformance.
• OnHopper/Edison:– Thedefaultop6onis“-cccpu”(useitfornon-Intelcompilers),
bindseachPEtoaCPUwithintheassignedNUMAnode.– PayaWen6ontoIntelcompiler,whichusesanextrathread.
• Use“-ccnone”if1MPIprocesspernode• Use“-ccnuma_node”(Hopper)or“-ccdepth”(Edison)ifmul6pleMPIprocessespernode
-5-

NERSC KNC Testbed: Babbage
-6-
• NERSCIntelXeonPhiKnightsCorner(KNC)testbed
• 45computenodes,eachhas:– Hostnode:2IntelXeon
Sandybridgeprocessors,8coreseach.
– 2MICcardseachhas60na6vecoresand4hardwarethreadspercore.
– MICcardsaWachedtohostnodesviaPCI-express.
– 8GBmemoryoneachMICcard
• Recommendtouseatleast2threadspercoretohidelatencyofin-orderexecuWon.
TobestpreparecodesonBabbageforCori:• Use“na6ve”modeonKNCtomimicKNL,
whichmeansignorethehost,justruncompletelyonKNCcards.
• Encouragetoexploresinglenodeop6miza6onforthreadingscalingandvectoriza6ononKNCcardswithproblemsizesthatcanfit.
• “Symmetric”,“Offload”modesonKNCand“OpenMP4.0target”work,butarenotourpromotedusagemodelsforBabbage.

Babbage MIC Card
-7-
Babbage:NERSCIntelXeonPhitestbed,45nodes.2MICcardspernode.• 1NUMAdomainperMICcard:60physicalcores,240logicalcores.OpenMP
threadingpotenWalto240-way.• KMP_AFFINITY,KMP_PLACE_THREADS,OMP_PLACES,OMP_PROC_BINDfor
threadaffinitycontrol• I_MPI_PIN_DOMAINforMPI/OpenMPprocessandthreadaffinitycontrol.

Full OpenMP 4.0 Support in Compilers
• GNUcompiler– From4.9.0forC/C++– Fromgcc/4.9.1forFortran
• Intelcompiler– Fromintel/15.0:supportsmostfeaturesinOpenMP4.0;
FromIntel/16.0:fullsupport
• Craycompiler– Fromcce/8.4.0
-8-

Thread Affinity Control in OpenMP 4.0 • OMP_PLACES:alistofplacesthatthreadscanbepinnedon
– threads:Eachplacecorrespondstoasinglehardwarethreadonthetargetmachine.
– cores:Eachplacecorrespondstoasinglecore(havingoneormorehardwarethreads)onthetargetmachine.
– sockets:Eachplacecorrespondstoasinglesocket(consis6ngofoneormorecores)onthetargetmachine.
– Alistwithexplicitplacevalues:suchas:• "{0,1,2,3},{4,5,6,7},{8,9,10,11},{12,13,14,15}”• “{0:4},{4:4},{8:4},{12:4}”
• OMP_PROC_BIND– spread:Bindthreadsasevenlydistributed(spread)aspossible– close:Bindthreadsclosetothemasterthreadwhiles6lldistribu6ng
threadsforloadbalancing,wraparoundonceeachplacereceivesonethread
– master:Bindthreadsthesameplaceasthemasterthread
-9-
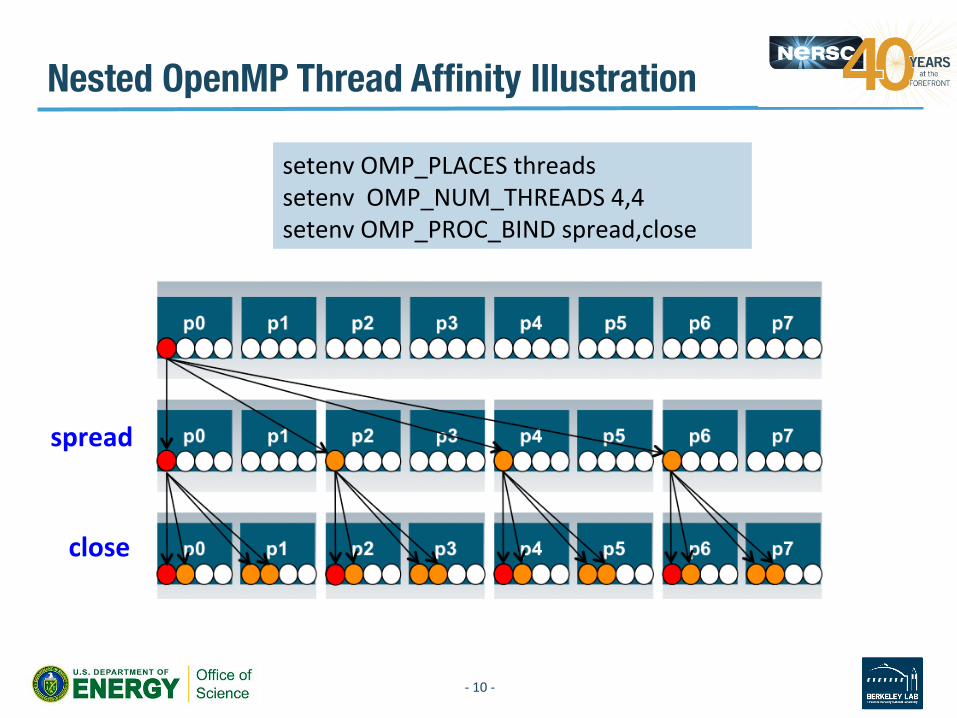
Nested OpenMP Thread Affinity Illustration
-10-
setenvOMP_PLACESthreadssetenvOMP_NUM_THREADS4,4setenvOMP_PROC_BINDspread,close
spread
close

Sample Nested OpenMP Code #include<omp.h>#include<stdio.h>voidreport_num_threads(intlevel){#pragmaompsingle{prinl("Level%d:numberofthreadsintheteam:%d\n",level,omp_get_num_threads());}}intmain(){omp_set_dynamic(0);#pragmaompparallelnum_threads(2){report_num_threads(1);#pragmaompparallelnum_threads(2){report_num_threads(2);#pragmaompparallelnum_threads(2){report_num_threads(3);}}}return(0);}
-11-
%a.outLevel1:numberofthreadsintheteam:2Level2:numberofthreadsintheteam:1Level3:numberofthreadsintheteam:1Level2:numberofthreadsintheteam:1Level3:numberofthreadsintheteam:1
%setenvOMP_NESTEDTRUE%a.outLevel1:numberofthreadsintheteam:2Level2:numberofthreadsintheteam:2Level2:numberofthreadsintheteam:2Level3:numberofthreadsintheteam:2Level3:numberofthreadsintheteam:2Level3:numberofthreadsintheteam:2Level3:numberofthreadsintheteam:2
Level0:P0Level1:P0P1Level2:P0P2;P1P3Level3:P0P4;P2P5;P1P6;P3P7

When to Use Nested OpenMP
• SomeapplicaWonteamsareexploringwithnestedOpenMPtoallowmorefine-grainedthreadparallelism.– MPI/Hybridnotusingnodefullypacked– ToplevelOpenMPloopdoesnotuseallavailablethreads– Mul6plelevelsofOpenMPloopsarenoteasilycollapsed– Certaincomputa6onalintensivekernelscouldusemorethreads– MKLcanuseextracoreswithnestedOpenMP
-12-

Process and Thread Affinity in Nested OpenMP
• AchievingbestprocessandthreadaffinityiscrucialingernggoodperformancewithnestedOpenMP,yetitisnotstraighlorwardtodoso.
• AcombinaWonofOpenMPenvironmentvariablesandrunWmeflagsareneededfordifferentcompilersanddifferentbatchschedulersondifferentsystems.
-13-
Example:UseIntelcompilerwithTorque/MoabonEdison:setenvOMP_NESTEDtruesetenvOMP_NUM_THREADS4,3setenvOMP_PROC_BINDspread,closeaprun-n2-S1-d12–ccnuma_node./nested.intel.edison

Edison: Run Time Environment Variables • setenvOMP_NESTEDtrue
– Defaultisfalseformostcompilers• setenvOMP_MAX_ACTIVE_LEVELS2
– Thedefaultwas1forCCEpriortocce/8.4.0• setenvOMP_NUM_THREADS4,3• setenvOMP_PROC_BINDspread,close• setenvKMP_HOT_TEAMS1
– Intelonlyenv.Defaultisfalse• setenvKMP_HOT_TEAMS_MAX_LEVELS2
– Intelonlyenv.AllownestedlevelOpenMPthreadstostayaliveinsteadofbeingdestroyedandcreatedagaintoreducethreadcrea6onoverhead.
• aprun-n2-S1-d12–ccnuma_node./nested.intel.edison– Use-dfortotalnumberofthreads(productsofnum_threadsfromall
levels).–ccnuma_nodetoallowthreadsmigratewithinNUMAnodetonotaffectedbyIntel’sextramanagerthread.
-14-

Babbage: Run Time Environment Variables • SetI_MPI_PIN_DOMAIN=autotogetbasicMPIprocessaffinity• DonotsetKMP_AFFINITY,otherwiseOMP_PROC_BINDwill
beignored.• UseOMP_PLACES=threads(default)insteadofsockets• setenvOMP_NESTEDtrue• setenvOMP_NUM_THREADS4,3• setenvOMP_PROC_BINDspread,close• setenvKMP_HOT_TEAMS1• setenvKMP_HOT_TEAMS_MAX_LEVELS2• mpirun.mic-n2-hostbc1109-mic0./xthi-nested.mic|sort
-15-

XGC1: Nested OpenMP • Alwaysmakesuretousebestthreadaffinity.Avoidusingthreadsacross
NUMAdomains.• Currently:
• Isabitslowerthan(workongoing):
• Willtry:
• Usenum_threadsclauseinsourcecodestosetthreadsfornestedregions.
Formostothernon-nestedregions,useOMP_NUM_THREADSenvforsimplicityandflexibility.
-16-
exportOMP_NUM_THREADS=6,4exportOMP_PROC_BIND=spread,closeexportOMP_NESTED=TRUEexportOMP_STACKSIZE=8000000aprun-n200-N2-S1-j2-ccnuma_node./xgca
exportOMP_NUM_THREADS=24exportOMP_NESTED=TRUEexportOMP_STACKSIZE=8000000aprun-n200-d24-N2-S1-j2-ccnuma_node./xgca
exportKMP_HOT_TEAMS=1exportKMP_HOT_TEAMS_MAX_LEVELS=2
CourtesyofRobertHager,PPPLandNESAPXGC1team.

Use Multiple Threads in MKL
• ByDefault,inOpenMPparallelregions,only1threadwillbeusedforMKLcalls.– MKL_DYNAMICSistruebydefault
• NestedOpenMPcanbeusedtoenablemulWplethreadsforMKLcalls.TreatMKLasanestedinnerOpenMPregion.
• Sampleserngs
-17-
exportOMP_NESTED=trueexportOMP_PLACES=coresexportOMP_PROC_BIND=closeexportOMP_NUM_THREADS=6,4exportMKL_DYNAMICS=falseexportKMP_HOT_TEAMS=1exportKMP_HOT_TEAMS_MAX_LEVELS=2

NWChem: OpenMP “Reduce” Algorithm
-18-
• PlanewaveLagrangemulWplier– Manymatrixmul6plica6onsofcomplexnumbers,C=AxB– Smallermatrixproducts:FFM,typicalsize100x10,000x100– OriginalthreadingscalingwithMKLnotsa6sfactory
• OpenMP“Reduce”or“Block”algorithm- DistributeworkonAandBalongthekdimension- Athreadputsitscontribu6oninabufferofsizemxn- BuffersreducedtoproduceC- OMPteamsofthreads
FFM
CourtesyofMathiasJacquelin,LBNL
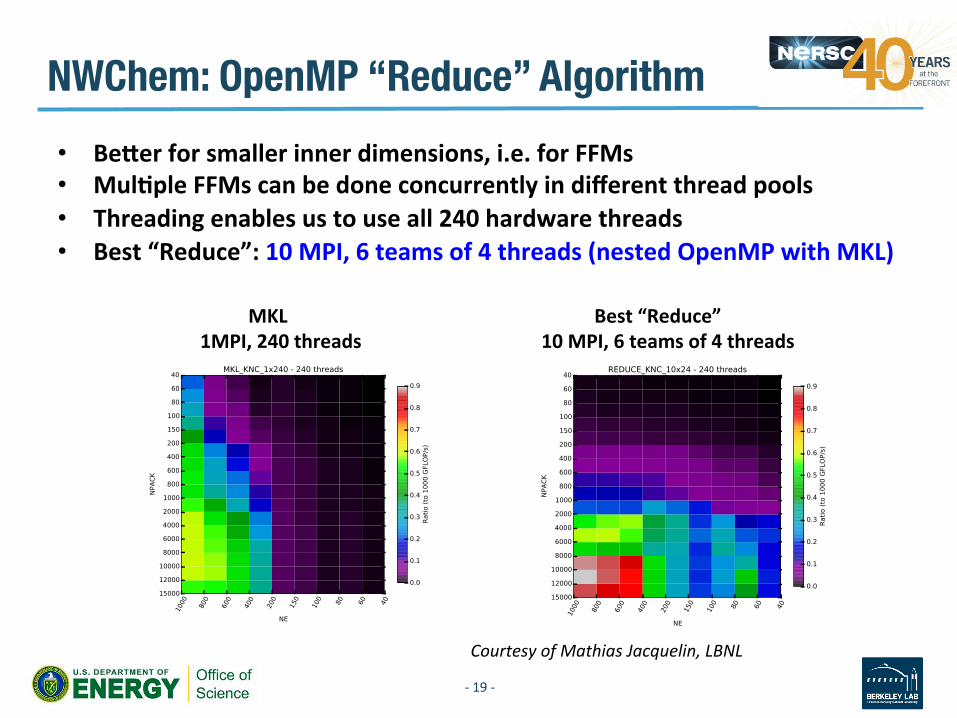
NWChem: OpenMP “Reduce” Algorithm • Bezerforsmallerinnerdimensions,i.e.forFFMs• MulWpleFFMscanbedoneconcurrentlyindifferentthreadpools• Threadingenablesustouseall240hardwarethreads• Best“Reduce”:10MPI,6teamsof4threads(nestedOpenMPwithMKL)
-19-
MKL1MPI,240threads
Best“Reduce”10MPI,6teamsof4threads
CourtesyofMathiasJacquelin,LBNL

FFT3D on KNC, Ng=643
-20-
CourtesyofJeongnimKim,Intel

Nested OpenMP on NERSC Systems
• Pleaseseedetailedexampleserngsinthe“NestedOpenMP”webpage:– RunonEdisonandBabbage– WithIntelandCraycompilers– UseTorque/MoabandSLURMbatchschedulers– hWps://www.nersc.gov/users/computa6onal-systems/edison/running-jobs/using-openmp-with-mpi/nested-openmp/
-21-

Thank you.
-22-
Top Related