







Languages
Pages
Legal


1 / 19
Multiprecision Algorithms for SparseMatrix Computations
NLA group meeting27/02/2020
Mawussi ZounonNumerical Algorithms Group
Experts in numerical software andHigh Performance Computing

Questions addressed in this talk
Lower precision guarantees faster computation time.� Yes � No � Surprise me
Multiprecision iterative refinement algorithms achieve ≈ 2x speedup forsparse linear systems (Ax = b).
� Yes � No � Surprise me
Using lower precision speeds up sparse matrix-vector product,preconditioner computation/application.
� Yes � No � Surprise me
2 / 19

Use cases of mixed precision computation
3 / 19
Some applications naturally tolerate low precisionMachine Learning: deep neural networks training.Scientific applications: loose approximation, coarse iterations in multilevelalgorithms, etc.
Iterative refinement strategyResult: double precision solution for Ax = bSolve Ax0 = b by LU factorization in single precision (n3);while not converged do
r = b − Ax0 double precision (n2);Solve Ad = r single precision (n2);x0 = x0 + d double precision (n);
Three precisions version by Carson & Higham (2017).
Up to 4x speedup by Haidar et al. using Tensor cores FP16 units (2018).
The success story has been extended to QR and Cholesky.

Existing IR implementations for sparse matrices
4 / 19
Alfredo Buttari & Jack Dongarra, 2008
FGMRES-IR and CG-IR based on SuperLU and MUMPS.Performance evaluation with a single core.
“The speedup of our mixed-precision MUMPS was approaching 2”.“No benefit of using our mixed precision approach for this version of SuperLU”.
Jonathan Hogg & Jennifer Scott, 2009FGMRES-IR based on HSL_MA57 (LDLT ).Performance evaluation with a single core.Out-of-core factorization and solve for large matrices
Speedup between 1.2x and 2x for very large problems.Performance loss for small and medium size problems.

Experimental settings
5 / 19
A total of 42 sparse matrices from the Tim Davis collectionThe matrices are from different scientific applications.Number of row from 82,000 to 1,300,000.Number of nonzero elements (nnz) from 600,000 to 27,000,000.
Sparse matrix libraries usedParallel solvers: SuperLU_MT, MKL PARDISO, MUMPS, UMFPACK.Preconditioner: cuSPARSE ILU0.SpMV: MKL Sparse BLAS, cuSPARSE both with CSR format.
HardwareIntel CPU: a 20-core Intel Haswell and a 40-core intel Skylake.AMD CPU: a 64-core AMD EPYC NAPLES.GPUs: Nvidia Tesla P100 (Pascal) GPU and V100 GPU (Volta).
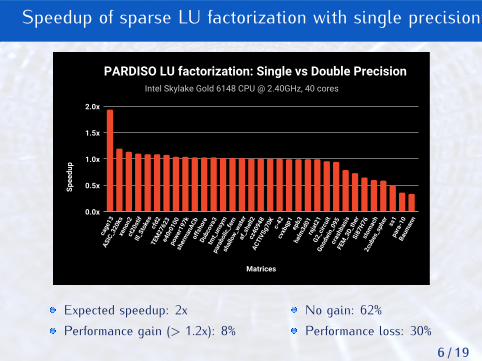
Speedup of sparse LU factorization with single precision
6 / 19
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0xca
ge13
ASIC
_320
ksxe
non2
ct20
stif
Ill_S
toke
scf
d2TE
M27
623
e40r
0100
powe
r197
ksh
erm
anAC
bof
fsho
reDu
bcov
a3tm
t_un
sym
para
bolic
_fem
shal
low_
wate
raf
_she
ll2cz
4094
8AC
TIVS
g70K c-42
cvxb
qp1
epb3
helm
3d01
raja
t21
G2_c
ircui
tGo
odwi
n_09
5cr
ashb
asis
FEM
_3D_
ther
Si87
H76
stom
ach
2cub
es_s
pher ss1
para
-10
Baum
ann
Intel Skylake Gold 6148 CPU @ 2.40GHz, 40 cores
PARDISO LU factorization: Single vs Double Precision
Expected speedup: 2xPerformance gain (> 1.2x): 8%
No gain: 62%Performance loss: 30%
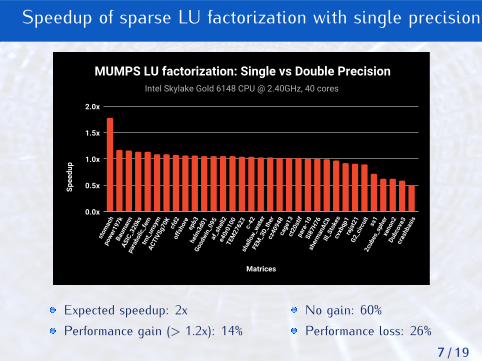
Speedup of sparse LU factorization with single precision
7 / 19
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0xst
omac
hpo
wer1
97k
Baum
ann
ASIC
_320
kspa
rabo
lic_f
emtm
t_un
sym
ACTI
VSg7
0K cfd2
offs
hore
epb3
helm
3d01
Good
win_
095
af_s
hell2
e40r
0100
TEM
2762
3c-
42sh
allo
w_wa
ter
FEM
_3D_
ther
cz40
948
cage
13ct
20st
ifpa
ra-1
0Si
87H7
6sh
erm
anAC
bIll
_Sto
kes
cvxb
qp1
raja
t21
G2_c
ircui
tss
12c
ubes
_sph
erxe
non2
Dubc
ova3
cras
hbas
is
Intel Skylake Gold 6148 CPU @ 2.40GHz, 40 cores
MUMPS LU factorization: Single vs Double Precision
Expected speedup: 2xPerformance gain (> 1.2x): 14%
No gain: 60%Performance loss: 26%

Speedup of sparse LU factorization with single precision
8 / 19
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
shal
low_
wate
rof
fsho
resh
erm
anAC
bpa
rabo
lic_f
em c-42
2cub
es_s
pher
e40r
0100
Ill_S
toke
sDu
bcov
a3cf
d2G2
_circ
uit
cvxb
qp1
TEM
2762
3he
lm3d
01af
_she
ll2ep
b3AC
TIVS
g70K
ct20
stif
cz40
948
Baum
ann
ASIC
_320
ksca
ge13
cras
hbas
isFE
M_3
D_th
erGo
odwi
n_09
5pa
ra-1
0po
wer1
97k
raja
t21
Si87
H76
ss1
stom
ach
tmt_
unsy
mxe
non2
Intel Skylake Gold 6148 CPU @ 2.40GHz, 40 cores
superLU_MT LU factorization: Single vs Double Precision
Expected speedup: 2xPerformance gain (> 1.2x): 40%
No gain: 57%Performance loss: 3%
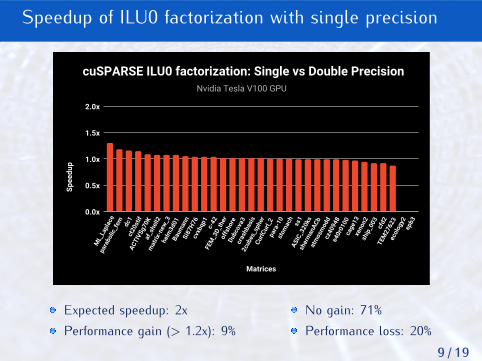
Speedup of ILU0 factorization with single precision
9 / 19
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
ML_
Lapl
ace
para
bolic
_fem dc
1ct
20st
ifAC
TIVS
g70K
af_s
hell2
mat
rix-n
ew_3
helm
3d01
Baum
ann
Si87
H76
cvxb
qp1
c-42
FEM
_3D_
ther
offs
hore
Dubc
ova3
cras
hbas
is2c
ubes
_sph
erCu
rlCur
l_2pa
ra-1
0st
omac
hss
1AS
IC_3
20ks
sher
man
ACb
atm
osm
odd
cz40
948
e40r
0100
cage
13xe
non2
ship
_003
cfd2
TEM
2762
3ec
olog
y2ep
b3
Nvidia Tesla V100 GPU
cuSPARSE ILU0 factorization: Single vs Double Precision
Expected speedup: 2xPerformance gain (> 1.2x): 9%
No gain: 71%Performance loss: 20%

Comments sparse direct solvers
The time spent in the analyze and reordering phase can be significant butit not impacted by the working precision. Dense matrices are free fromthis burden.
Are the speedups observed similar on the Intel Haswell, AMD EPYC, andP100 GPU? Yes
Is there any benefits using low precision for the solve step (y = L−1b andx = U−1y)? Let’s see
10 / 19
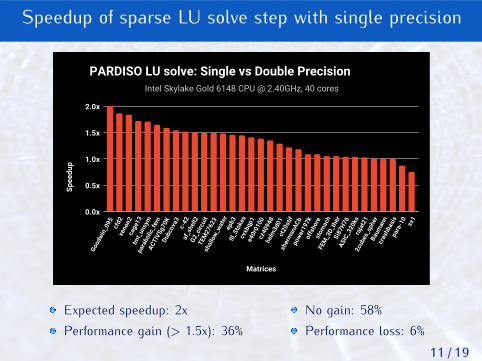
Speedup of sparse LU solve step with single precision
11 / 19
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
Good
win_
095
cfd2
xeno
n2ca
ge13
tmt_
unsy
mpa
rabo
lic_f
emAC
TIVS
g70K
Dubc
ova3
c-42
af_s
hell2
G2_c
ircui
tTE
M27
623
shal
low_
wate
rep
b3Ill
_Sto
kes
cvxb
qp1
e40r
0100
cz40
948
helm
3d01
ct20
stif
sher
man
ACb
powe
r197
kof
fsho
rest
omac
hFE
M_3
D_th
erSi
87H7
6AS
IC_3
20ks
raja
t21
2cub
es_s
pher
Baum
ann
cras
hbas
ispa
ra-1
0ss
1
Intel Skylake Gold 6148 CPU @ 2.40GHz, 40 cores
PARDISO LU solve: Single vs Double Precision
Expected speedup: 2xPerformance gain (> 1.5x): 36%
No gain: 58%Performance loss: 6%
Speedup of sparse LU solve with single precision
12 / 19
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0xcv
xbqp
1pa
ra-1
0AC
TIVS
g70K
sher
man
ACb
ss1
helm
3d01
cras
hbas
isTE
M27
623
e40r
0100
xeno
n2FE
M_3
D_th
erIll
_Sto
kes
Baum
ann
af_s
hell2
cfd2
offs
hore
shal
low_
wate
rSi
87H7
6AS
IC_3
20ks
stom
ach
para
bolic
_fem
cz40
948
Good
win_
095
ct20
stif
G2_c
ircui
ttm
t_un
sym
cage
13po
wer1
97k
c-42
2cub
es_s
pher
epb3
raja
t21
Dubc
ova3
Intel Skylake Gold 6148 CPU @ 2.40GHz, 40 cores
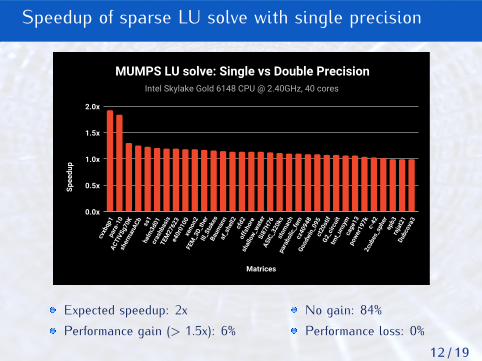
MUMPS LU solve: Single vs Double Precision
Expected speedup: 2xPerformance gain (> 1.5x): 6%
No gain: 84%Performance loss: 0%
Speedup of sparse LU solve with single precision
13 / 19
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0xaf
_she
ll2of
fsho
recf
d2pa
rabo
lic_f
eme4
0r01
00cv
xbqp
1ep
b3Ba
uman
n2c
ubes
_sph
erIll
_Sto
kes
ACTI
VSg7
0KTE
M27
623
Dubc
ova3
cz40
948
c-42
helm
3d01
ct20
stif
sher
man
ACb
G2_c
ircui
tsh
allo
w_wa
ter
ASIC
_320
ksca
ge13
cras
hbas
isFE
M_3
D_th
erGo
odwi
n_09
5pa
ra-1
0po
wer1
97k
raja
t21
Si87
H76
ss1
stom
ach
tmt_
unsy
mxe
non2
Intel Skylake Gold 6148 CPU @ 2.40GHz, 40 cores
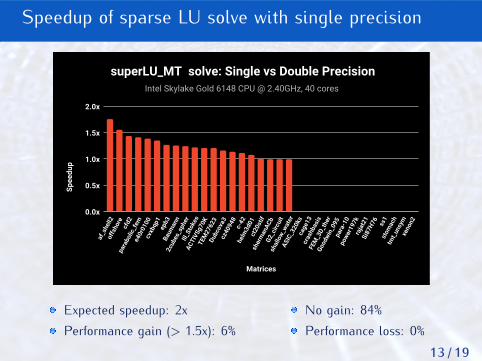
superLU_MT solve: Single vs Double Precision
Expected speedup: 2xPerformance gain (> 1.5x): 6%
No gain: 84%Performance loss: 0%
Speedup of ILU0 solve with single precision
14 / 19
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0xcz
4094
8ss
1Du
bcov
a3of
fsho
reBa
uman
npa
ra-1
0at
mos
mod
dst
omac
hcr
ashb
asis
mat
rix-n
ew_3
2cub
es_s
pher
CurlC
url_2
ML_
Lapl
ace
cage
13cf
d2cv
xbqp
1TE
M27
623
Si87
H76
c-42
sher
man
ACb
xeno
n2pa
rabo
lic_f
em dc1
helm
3d01
ship
_003
ACTI
VSg7
0Kct
20st
ifAS
IC_3
20ks
FEM
_3D_
ther
af_s
hell2
e40r
0100
ecol
ogy2
epb3
Nvidia Tesla V100 GPU
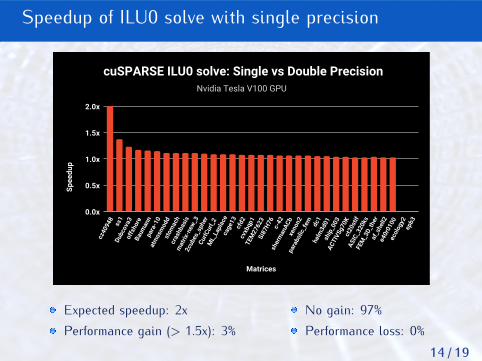
cuSPARSE ILU0 solve: Single vs Double Precision
Expected speedup: 2xPerformance gain (> 1.5x): 3%
No gain: 97%Performance loss: 0%

Comments on triangular solve
Lower precision does not improve triangular solve efficiency.Main issues: limited parallelism, synchronization points and latency.
Sparse direct solvers often store factors (L, U) in opaque formats.It is difficult/impossible to perform the solve step in a different precision.Multiprecision precision
Any hope to speedup a sparse matrix-vector product (SpMV) using lowerprecision? Let’s see
15 / 19
Speedup of SpMV with single precision
16 / 19
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
ecol
ogy2
tmt_
unsy
mpa
ra-1
0ca
ge13
ship
_003
offs
hore
CurlC
url_2
PR02
Rat
mos
mod
daf
_she
ll2M
L_La
plac
eSi
87H7
6xe
non2
Dubc
ova3
para
bolic
_fem
stom
ach
Good
win_
095
FEM
_3D_
ther
mpo
wer1
97k
shal
low_
wate
r1ra
jat2
1cr
ashb
asis
ACTI
VSg7
0K dc1
cfd2
G2_c
ircui
tss
1th
erm
omec
h_T
mat
rix-n
ew_3
helm
3d01
ASIC
_320
ksIll
_Sto
kes
e40r
0100
Intel Haswell E5-2650 v3 @ 2.30GHz.MKL SpMV: Single vs Double Precision
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
epb3
cvxbqp1
atmosmodd
G2_circuit
PR02R
Si87H7
6parabolic_fem
CurlC
url_2
cage13
ship_003 ss1
thermom
ech_T
af_shell2
Baum
ann
powe
r197k
e40r0100 dc1
ecology2
ML_Laplace
para-10
Dubcova3
helm3d01
tmt_unsym
matrix-new
_3shermanAC
bxenon2
FEM_3D_therm
2cubes_spher
cfd2
TEM27623
Ill_Stokes
cz40948
ASIC_320ks
Intel Skylake Gold 6148 CPU @ 2.40GHz, 40 cores
MKL SpMV: Single vs Double Precision
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
cage
13st
omac
hcr
ashb
asis
ML_
Lapl
ace
atm
osm
odd
para
bolic
_fem
PR02
Rof
fsho
rera
jat2
1e4
0r01
00tm
t_un
sym
af_s
hell2
CurlC
url_2
ecol
ogy2
xeno
n2Go
odwi
n_09
5dc
1ss
1Si
87H7
6ep
b3FE
M_3
D_th
ersh
erm
anAC
bpo
wer1
97k
ASIC
_320
kssh
ip_0
03pa
ra-1
0Du
bcov
a3ct
20st
if2c
ubes
_sph
erBa
uman
nc-
42G2
_circ
uit
cfd2
Nvidia Tesla V100 GPU
cuSPARSE SpMV: Single vs Double Precision
Matrices
spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
cz40
948
TEM
2762
3ca
ge13
e40r
0100
stom
ach
helm
3d01
epb3
af_s
hell2
Ill_S
toke
sat
mos
mod
dBa
uman
nAC
TIVS
g70K
CurlC
url_2
ML_
Lapl
ace
offs
hore
xeno
n2cr
ashb
asis
para
bolic
_fem
Si87
H76
FEM
_3D_
ther
tmt_
unsy
mec
olog
y2Go
odwi
n_09
5PR
02R
raja
t21
c-42 ss
1sh
ip_0
03Du
bcov
a32c
ubes
_sph
erct
20st
ifAS
IC_3
20ks
powe
r197
k
Nvidia Tesla P100 GPU
cuSPARSE SpMV: Single vs Double Precision
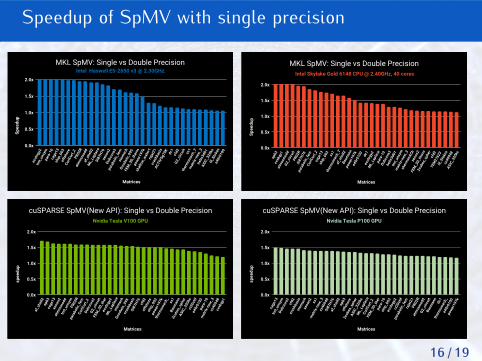
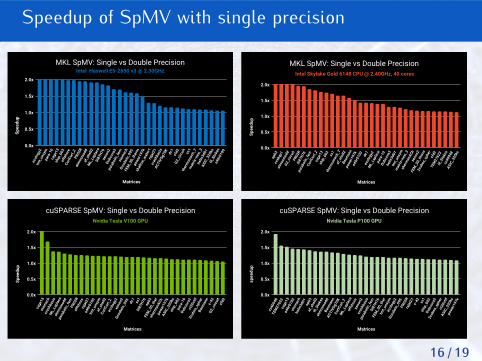
Speedup of SpMV with single precision
16 / 19
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
ecol
ogy2
tmt_
unsy
mpa
ra-1
0ca
ge13
ship
_003
offs
hore
CurlC
url_2
PR02
Rat
mos
mod
daf
_she
ll2M
L_La
plac
eSi
87H7
6xe
non2
Dubc
ova3
para
bolic
_fem
stom
ach
Good
win_
095
FEM
_3D_
ther
mpo
wer1
97k
shal
low_
wate
r1ra
jat2
1cr
ashb
asis
ACTI
VSg7
0K dc1
cfd2
G2_c
ircui
tss
1th
erm
omec
h_T
mat
rix-n
ew_3
helm
3d01
ASIC
_320
ksIll
_Sto
kes
e40r
0100
Intel Haswell E5-2650 v3 @ 2.30GHz.MKL SpMV: Single vs Double Precision
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
epb3
cvxbqp1
atmosmodd
G2_circuit
PR02R
Si87H7
6parabolic_fem
CurlC
url_2
cage13
ship_003 ss1
thermom
ech_T
af_shell2
Baum
ann
powe
r197k
e40r0100 dc1
ecology2
ML_Laplace
para-10
Dubcova3
helm3d01
tmt_unsym
matrix-new
_3shermanAC
bxenon2
FEM_3D_therm
2cubes_spher
cfd2
TEM27623
Ill_Stokes
cz40948
ASIC_320ks
Intel Skylake Gold 6148 CPU @ 2.40GHz, 40 cores
MKL SpMV: Single vs Double Precision
Matrices
Spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
cage
13st
omac
hcr
ashb
asis
ML_
Lapl
ace
atm
osm
odd
para
bolic
_fem
PR02
Rof
fsho
rera
jat2
1e4
0r01
00tm
t_un
sym
af_s
hell2
CurlC
url_2
ecol
ogy2
xeno
n2Go
odwi
n_09
5dc
1ss
1Si
87H7
6ep
b3FE
M_3
D_th
ersh
erm
anAC
bpo
wer1
97k
ASIC
_320
kssh
ip_0
03pa
ra-1
0Du
bcov
a3ct
20st
if2c
ubes
_sph
erBa
uman
nc-
42G2
_circ
uit
cfd2
Nvidia Tesla V100 GPU
cuSPARSE SpMV: Single vs Double Precision
Matrices
spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
cz40
948
TEM
2762
3ca
ge13
e40r
0100
stom
ach
helm
3d01
epb3
af_s
hell2
Ill_S
toke
sat
mos
mod
dBa
uman
nAC
TIVS
g70K
CurlC
url_2
ML_
Lapl
ace
offs
hore
xeno
n2cr
ashb
asis
para
bolic
_fem
Si87
H76
FEM
_3D_
ther
tmt_
unsy
mec
olog
y2Go
odwi
n_09
5PR
02R
raja
t21
c-42 ss
1sh
ip_0
03Du
bcov
a32c
ubes
_sph
erct
20st
ifAS
IC_3
20ks
powe
r197
k
Nvidia Tesla P100 GPU
cuSPARSE SpMV: Single vs Double Precision
Matrices
spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
af_s
hell2
epb3
cage
13xe
non2
atm
osm
odd
tmt_
unsy
mPR
02R
para
bolic
_fem
CurlC
url_2
Dubc
ova3
G2_c
ircui
tFE
M_3
D_th
erec
olog
y2M
L_La
plac
est
omac
hGo
odwi
n_09
5cr
ashb
asis
Si87
H76
cfd2
offs
hore
ship
_003
powe
r197
kth
erm
omec
h_ ss1
Baum
ann
2cub
es_s
pher
ASIC
_320
ksct
20st
ife4
0r01
00pa
ra-1
0m
atrix
-new
_3cz
4094
8cv
xbqp
1Nvidia Tesla V100 GPU
cuSPARSE SpMV(New API): Single vs Double Precision
Matrices
spee
dup
0.0x
0.5x
1.0x
1.5x
2.0x
cage
13tm
t_un
sym
Dubc
ova3
cfd2
cras
hbas
isst
omac
hxe
non2 ss
1m
atrix
-new
_3cz
4094
8Si
87H7
6af
_she
ll2ep
b3of
fsho
re2c
ubes
_sph
erAS
IC_3
20ks
ML_
Lapl
ace
CurlC
url_2
FEM
_3D_
ther
para
-10
ship
_003
ecol
ogy2
ct20
stif
para
bolic
_fem
raja
t21
PR02
Rat
mos
mod
dG2
_circ
uit
Baum
ann
dc1
ther
mom
ech_
e40r
0100
powe
r197
k
Nvidia Tesla P100 GPU
cuSPARSE SpMV(New API): Single vs Double Precision

Comments on SpMV kernels
Average speedup of 1.5x for SpMV.
To reduce precision conversion overhead, conversion kernels should behighly optimized and/or fused with memory bound kernels.
As memory footprint is critical in iterative solvers, data conversion on thefly should be preferred. Mixed precision SpMV kernels for example.
Ongoing work for matrix-free SpMV.
17 / 19

Final takeaway
Multiprecision IR is less attractive for sparse direct solvers evaluated.Efficient and parallel algorithms should be investigated for the analyzestep.
No gain in applying a preconditioner (triangular solve) in lower precision.
Looking for efficient mixed precision algorithms to exploit the 1.5x speedupof SpMV. (I need your creativity)
Specialized mixed precision units (Tensor cores & Google TPU) arelimited to dense matrix operations.
Kernels should be optimized and parallelized to get close to the maximumbandwidth or to the peak performance before stepping into themultiprecision jungle.
18 / 19

Contacts
Thank you for your mixed attention.
Mawussi [email protected]://mawussi.github.io
19 / 19
This work is part funded by Innovate UK.Academic partners: J. Dongarra, N. Higham & F. Tissuer.NAG partners: Craig Lucas & Mike Dewar.
Top Related