







Languages
Pages
Legal


Motivation
Histograms are everywhere in vision. object recognition / classification appearance-based tracking
How do we compare two histograms {pi}, {qj}?
Information theoretic measures like chi-square, Bhattacharyya coeff,KL-divergence, are very prevalent. They are based on bin-to-bincomparisons of mass.
Example, bhattacharyya coefficient

MotivationProblem: the bin-to-bin comparison measures are sensitive tothe binning of the data, and also to “shifts” of data acrossbins (say due to intensity gain/offset).Example,
0 25510
intensity
0 25510
intensity
0 25510
intensity
which of these is more similar to the black circle?
= 0 for all pairs!
problem is due to only considering intersectionof mass in each bin. Not taking into account the ground-distance between nonoverlapping bins.
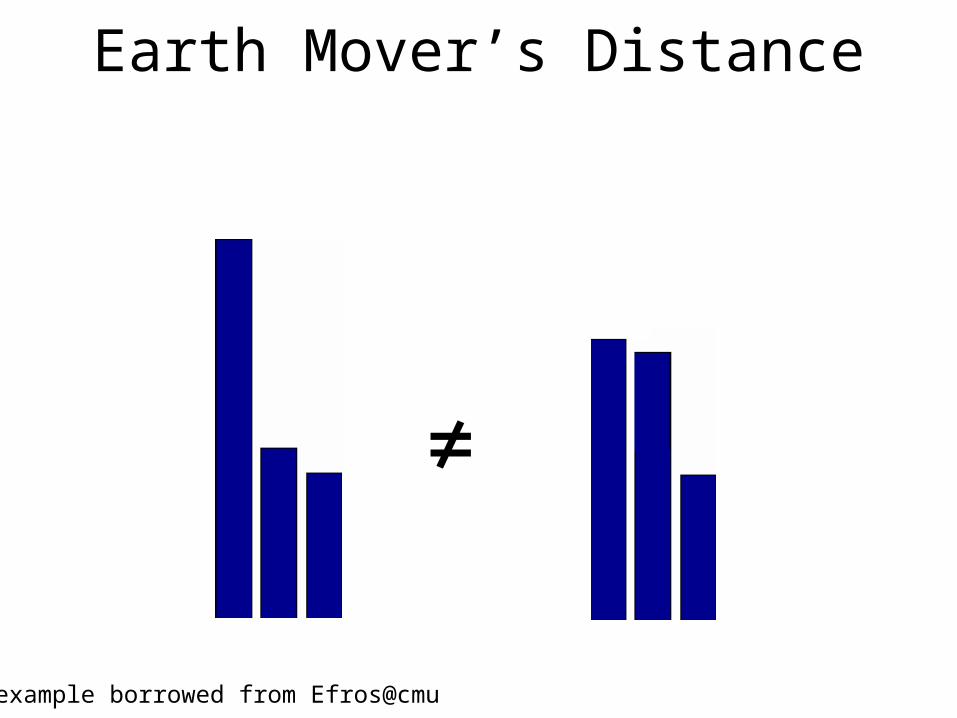
Earth Mover’s Distance
≠
example borrowed from Efros@cmu
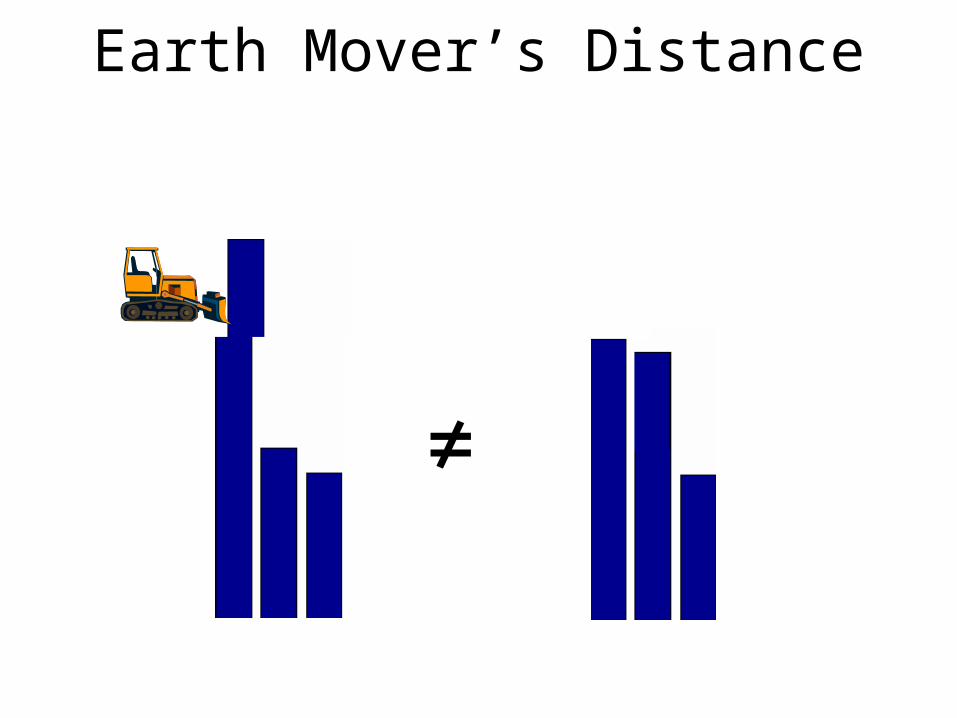
Earth Mover’s Distance
≠

Earth Mover’s Distance
=

The Difference?
=
(amount moved)
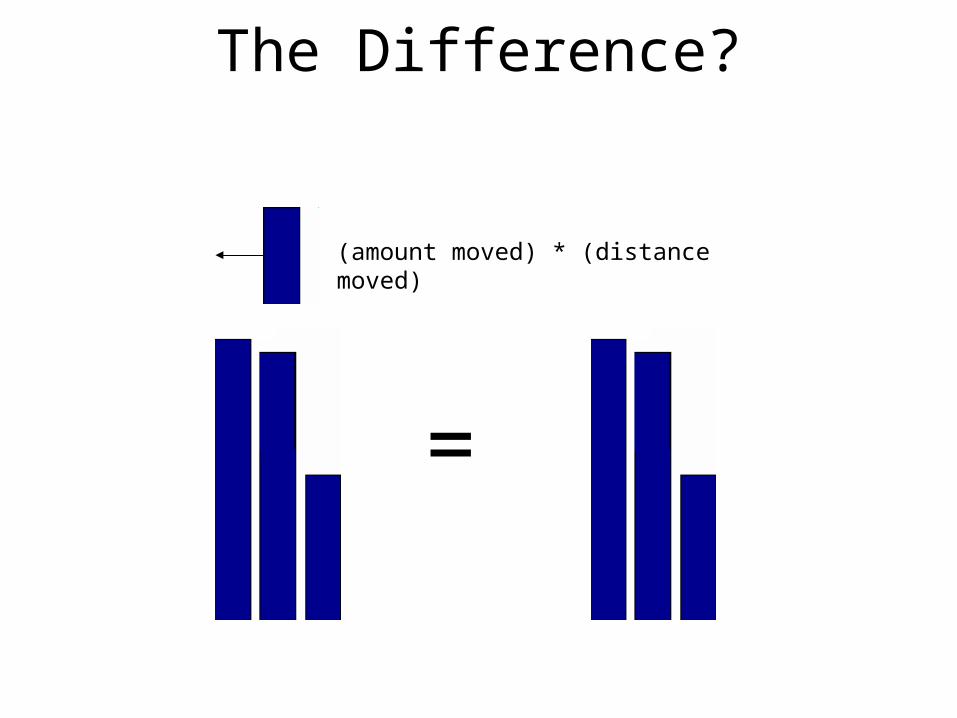
The Difference?
=
(amount moved) * (distance moved)

Thought Experiment• move the books on your bookshelf one space to the right• you are lazy, so want to minimize sum of distances moved
dist = xnew - xold
+X

Thought Experiment
strategy 1 strategy 2
dist = 4 dist = 1 + 1 + 1 + 1 = 4
More than one minimal solution. Not unique!

Thought Experiment
strategy 1 strategy 2
dist = 4 dist = 1 + 1 + 1 + 1 = 4
now minimize sum of squared distances
dist = 4^2 = 16 dist = 1^2+1^2+1^2+1^2 = 4

How Do We Know?How do we know those are the minimal solutions?Is that all of them? Let’s go back to abs distance |new-old|
A B C D E
0 1 2 3 4
1 0 1 2 3
2 1 0 1 2
3 2 1 0 1
4 3 2 1 0
A B C D E
A
B
C
D
E
Form a table of distances |new-old|
new
old

How Do We Know?How do we know those are the minimal solutions?Is that all of them? Let’s go back to abs distance |new-old|
A B C D E
x 1 2 3 4
x 0 1 2 3
x 1 0 1 2
x 2 1 0 1
x x x x x
A B C D E
A
B
C
D
E
Form a table of distances |new-old| X off ones that are not admissable new
old

How Do We Know?How do we know those are the minimal solutions?Is that all of them? Let’s go back to abs distance |new-old|
A B C D E
x 1 2 3 4
x 0 1 2 3
x 1 0 1 2
x 2 1 0 1
x x x x x
A B C D E
A
B
C
D
E
Consider all permutations where there is asingle 1 in each admissable row and column. new
old

How Do We Know?How do we know those are the minimal solutions?Is that all of them? Let’s go back to abs distance |new-old|
A B C D E
x 1 2 3 4
x 0 1 2 3
x 1 0 1 2
x 2 1 0 1
x x x x x
A B C D E
A
B
C
D
E
Consider all permutations where there is asingle 1 in each admissable row and column.
new
old
sum = 1+3+0+1 = 5

How Do We Know?How do we know those are the minimal solutions?Is that all of them? Let’s go back to abs distance |new-old| |
A B C D E
x 1 2 3 4
x 0 1 2 3
x 1 0 1 2
x 2 1 0 1
x x x x x
A B C D E
A
B
C
D
E
Consider all permutations where there is asingle 1 in each admissable row and column.
new
old
sum = 2+2+2+2 = 8

How Do We Know?How do we know those are the minimal solutions?Let’s go back to using absolute distance |new-old|
A B C D E
x 1 2 3 4
x 0 1 2 3
x 1 0 1 2
x 2 1 0 1
x x x x x
A B C D E
A
B
C
D
E
Consider all permutations where there is asingle 1 in each admissable row and column.Try to find the minimum one!
new
old
sum = 4+2+0+2 = 8There are 4*3*2*1=24 permutations in this example. We can try them all.

It turns out that lot’s of solutions are minimal, when we use absolute distance.
8 min solutions!

How Do We Know?The two we had before are there. But there are others!!
4 1 2 3 1 2 3 4 3 1 2 4

Recall: Thought Experiment
strategy 1 strategy 2
dist = 4 dist = 1 + 1 + 1 + 1 = 4
now minimize sum of squared distances
dist = 4^2 = 16 dist = 1^2+1^2+1^2+1^2 = 4
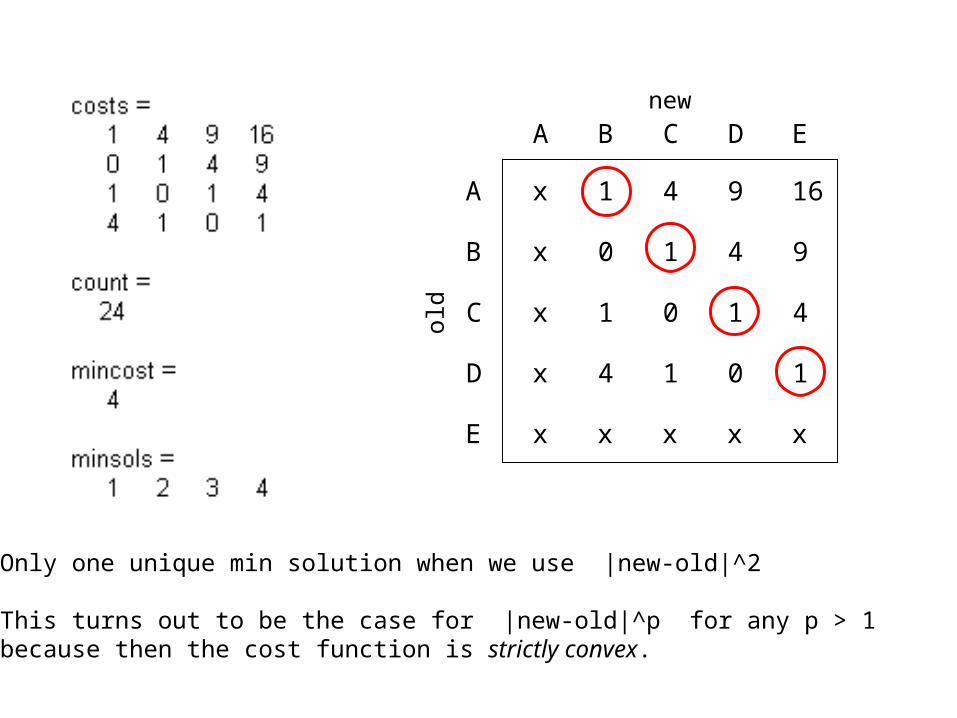
Only one unique min solution when we use |new-old|^2
This turns out to be the case for |new-old|^p for any p > 1because then the cost function is strictly convex.
x 1 4 9 16
x 0 1 4 9
x 1 0 1 4
x 4 1 0 1
x x x x x
A B C D E
A
B
C
D
E
new
old

Other Ways to Look at It
The way we’ve set it up so far, this problem is equivalent tothe linear assignment problem. We can therefore solve itusing the Hungarian algorithm.
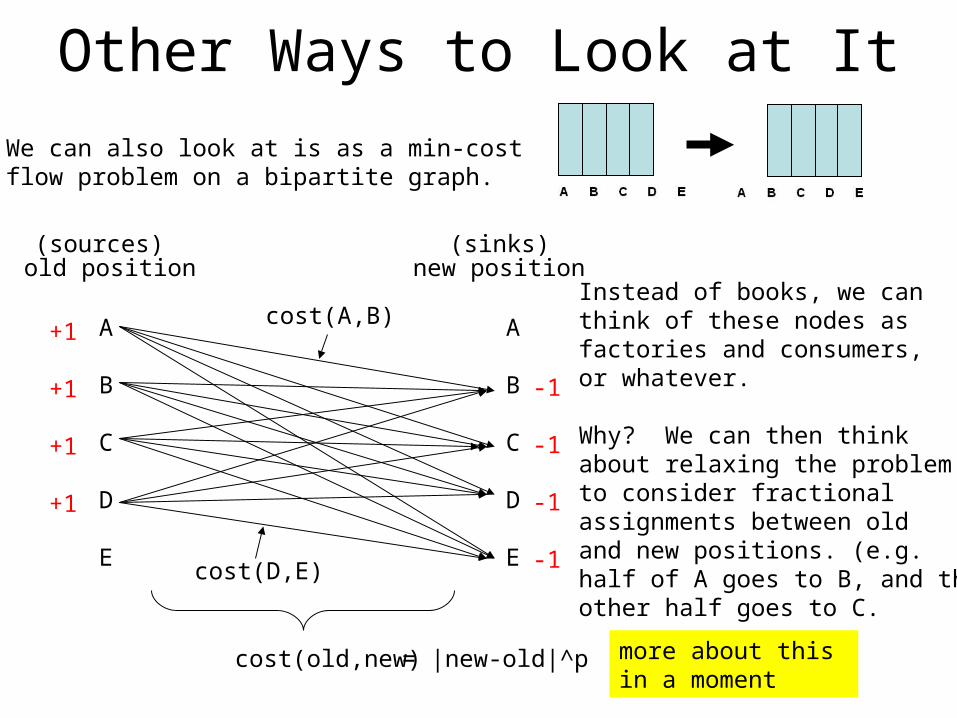
Other Ways to Look at It
We can also look at is as a min-costflow problem on a bipartite graph.
A
B
C
D
E
A
B
C
D
E
old position new position
cost(old,new)
cost(A,B)
cost(D,E)
= |new-old|^p
Instead of books, we canthink of these nodes asfactories and consumers,or whatever.
Why? We can then think about relaxing the problemto consider fractional assignments between oldand new positions. (e.g.half of A goes to B, and theother half goes to C.
more about this in a moment
+1
+1
+1
+1
(sources) (sinks)
-1
-1
-1
-1

Monge-Kantorovich Transportation Problem

Mallow’s (Wasserstein) Distance
X and Y be d-dimensional random variables. Prob distribution of X is P, and distribution of Y is Q. Also, consider some unknown distribution F overthe two of them taken jointly (X,Y) [dxd dimensional]
Mallow’s distance:
In words: Trying to find a minimum expected value of the distance between X and YExpected value is taken over some unknown joint distribution F!F is constrained such that marginal wrt X is P, and marginal wrt Y is Q

Understanding Mallow’s Distance
0 1 2 3 4
1 0 1 2 3
2 1 0 1 2
3 2 1 0 1
4 3 2 1 0
y1 y2 y3 y4 y5
x1
x2
x3
x4
x5
new
old
0
0 .25 .25 .25 .25
.25
.25
.25
.25
P(xi)
Q(yj)
for discrete variables:
*f11 *f12 *f13 *f14 *f15
*f21 *f22 *f23 *f24 *f25
*f31 *f32 *f33 *f34 *f35
*f41 *f42 *f43 *f44 *f45
*f51 *f52 *f53 *f54 *f55
Looking for set of values fij thatminimize sum
Subject to constraints:
F has to be a prob distribution!
F has to have appropriate marginals
costs dij

Mallow’s Versus EMD
Mallow’sEMD
For distributions they are the same.Also same when total masses are same

Mallow’s vs EMDmain difference: EMD allows partial matches in the case of unequal masses.
As the paper points out, you have to be careful when allowing partial matches to make sure what you are doing is sensible.
Mallows = 1/2 EMD = 0 note: using L1 norm

Linear Programming
Mallow’s/EMD for general d-dimensional data is solved vialinear programming, for example by the simplex algorithm.
This makes it OK for low values of d (up to dozens), but makesit unsuitable for very large d.
As a result, EMD is typically applied after clustering the data(say using k-means) into a smaller set of clusters. The coarse descriptors based on clusters are often called signatures.

Transportation Problem
Mallow’s is a special case of linearprogramming : transportation problem
p1
p2
pm
-q1
-q2
-qn
formulated as a min-flow problem in a graph

Assignment Problem
p1
p2
pm
-q1
-q2
-qn
formulated as a min-flow problem in a graph
+1
+1
+1
-1
-1
-1all x_ij are 0 or 1, and only one 1 ineach row or column
some discrete cases (like our book example) simplify further : assignment problem

Linear Programming
Mallow’s/EMD for general d-dimensional data is solved vialinear programming, for example by the simplex algorithm.
This makes it OK for low values of d (up to dozens), but makesit unsuitable for very large d.
As a result, EMD is typically applied after clustering the data(say using k-means) into a smaller set of clusters. The coarse descriptors based on clusters are often called signatures.
However, If we use marginal distributions, so that we have 1D histograms,something wonderful happens!!!

One-Dimensional Dataone dimensional data (like we’ve been using for illustration duringthis whole talk) is an important special case.
Mallow’s/EMD distance computation greatly simplifies!
First of all, for 1D, we can represent densities by their cumulativedistribution functions
0
1 F(x)
0 255intensity (for example)
t
(x) x

One-Dimensional Dataone dimensional data (like we’ve been using for illustration duringthis whole talk) is an important special case.
Mallow’s/EMD distance computation greatly simplifies!
First of all, for 1D, we can represent densities by their cumulativedistribution functions
and the min distance can be computed as
| F(x) – G(x) | dx
(x) x

One-Dimensional Data
0
1 F(x)
0 255intensity (for example)
G(x)
t
just area between the two cumulative distribution function curves
| F(x) – G(x) | dx
x0
1F-1(t)
0 255intensity (for example)
G-1(t)
t
x

Proof?It is easy to find papers that state the previous 1D simplified solution, but quite hard to find one with a proof! One is
First, recall the quantile transform: given a cdf F(x), we can generate samples from it by uniformly sampling t ~ U(0,1) and then outputting F-1(t)
0
1 F(x)
0 255intensity (for example)
tt0
x0
ti ~ U(0,1) => xi ~ F
but you still have to work at it. I did, one week, and here is what I came up with:

Proof?
This allows us to understand that

But so what? Why does this minimize the Mallow’s distance?

consider an (abstract) example. Consider two density functions
consider L2 cost function
consider some (unknown) joint density
Expected cost is sum ofthe 4x4 array of products.To compute Mallow’s distance,we want to choose pij tominimize this expected cost

P.Major says: at minimum solution, for any pab and pcd on opposite sides ofthe diagonal, one or both of them should be zero. If not, we can construct alower cost solution.
Example:
Let min(p31,p14) = a > 0.
now: subtract a from p31,p14 and add a to p11,p34Note that the marginals have not changed!
-a
-a
+a
+a
our new cost differs from old on by –a(9+4) + a(0+1) = -12aso is a lower cost solution.

Connection (and a missing piece of the proof in P.Major’s paper)
The above procedure serves to concentrate all the mass of the joint distribution along the diagonal, and apparently also yields the mincost solution..
However, concentration of mass along the diagonal is also a property of joint distributions of correlated random variables.
Therefore... generating maximally correlated random variables via the quantile transformation should serve to generate a joint distribution clustered as tightly as possible around the diagonal of the cost matrix, and therefore, should yield the minimum expected cost.
QED!!!!
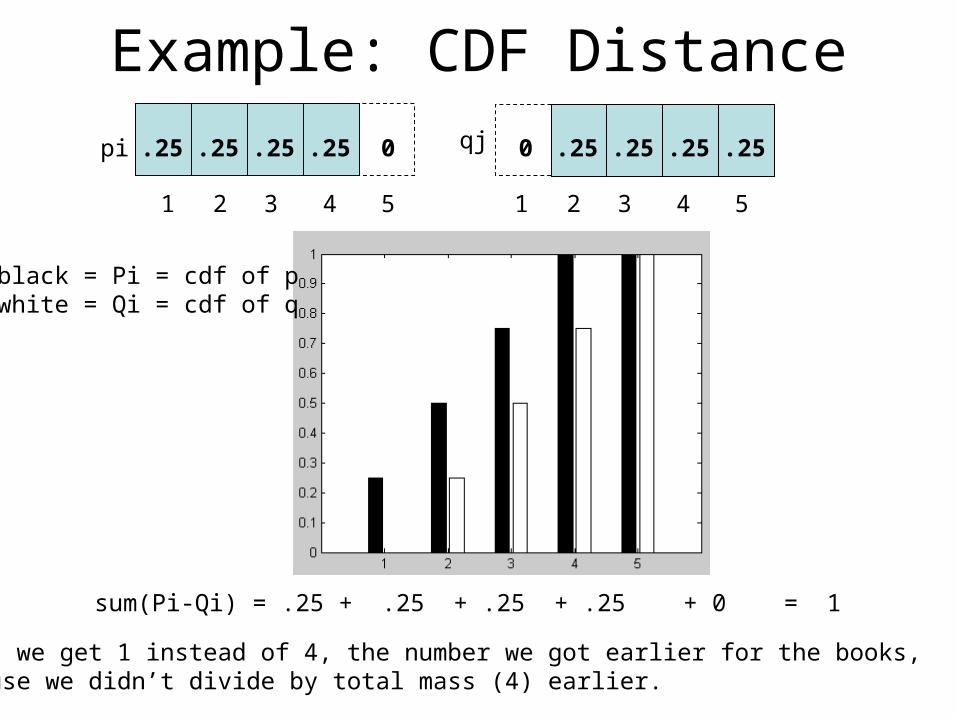
Example: CDF Distance
.25 .25 .25 .25.25 .25 .25 .25 00
1 2 3 4 5
pi
1 2 3 4 5
qj
black = Pi = cdf of pwhite = Qi = cdf of q
sum(Pi-Qi) = .25 + .25 + .25 + .25 + 0 = 1
Note: we get 1 instead of 4, the number we got earlier for the books,because we didn’t divide by total mass (4) earlier.

Example Applicationconvert 3D color data into three 1D marginals compute CDF of marginal color data in a circular region compute CDF of marginal color data in a ring around that circlecompare two CDFs using Mallow’s distanceselect peaks in the distance function as interest regions
repeat, at a range of scales...
Top Related