





![Link Farmer[countryside] to Customer[downtown]. Downtown Valley F F F F F F F F.](https://static.fdocuments.in/doc/165x107/56649f385503460f94c55132/link-farmercountryside-to-customerdowntown-downtown-valley-f-f-f-f-f-f.jpg)


Languages
Pages
Legal


Meta Learning (Part 2):Gradient Descent as LSTMHung-yi Lee
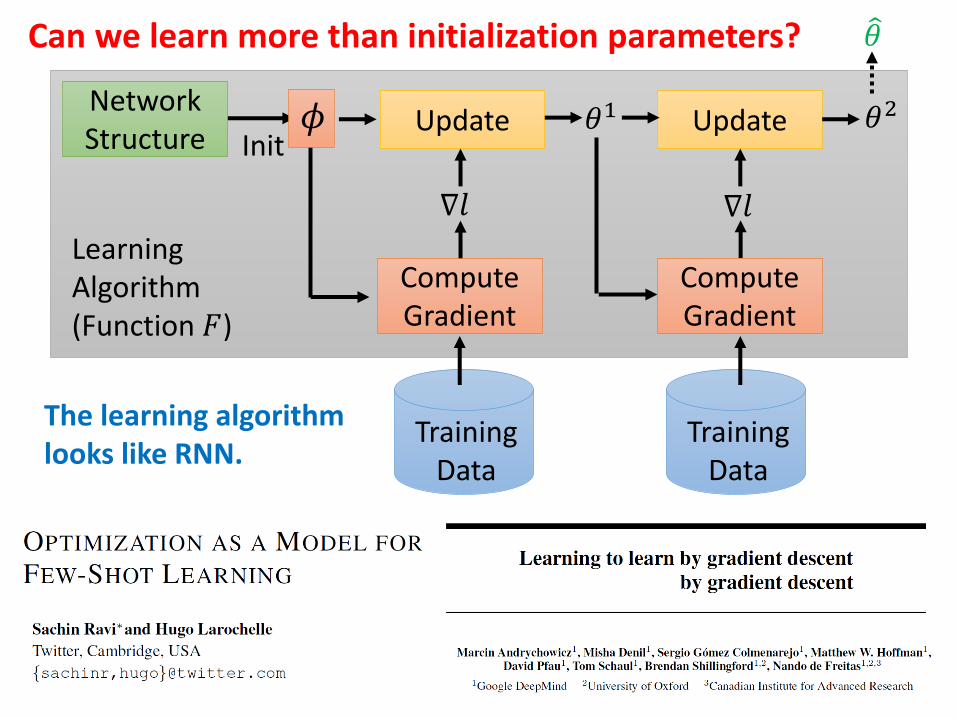
𝜃0 𝜃1
∇𝑙
Init
Compute Gradient
Update
TrainingData
𝜃2
∇𝑙
Compute Gradient
Update
TrainingData
𝜃
NetworkStructure
Learning Algorithm(Function 𝐹)
𝜙
Can we learn more than initialization parameters?
The learning algorithm looks like RNN.
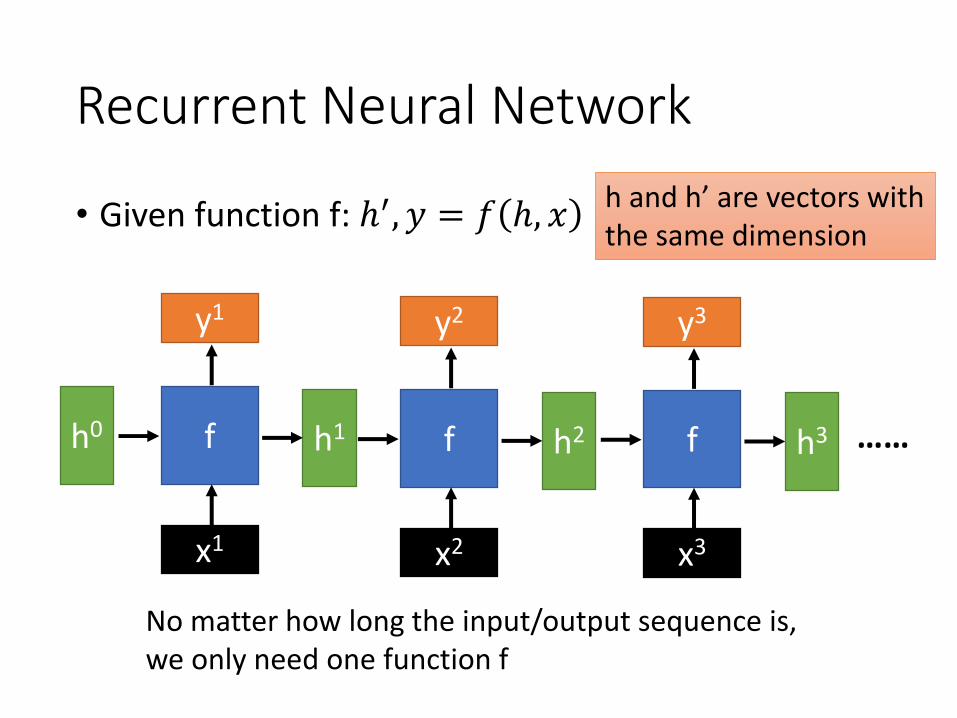
Recurrent Neural Network
• Given function f: ℎ′, 𝑦 = 𝑓 ℎ, 𝑥
fh0 h1
y1
x1
f h2
y2
x2
f h3
y3
x3
……
No matter how long the input/output sequence is, we only need one function f
h and h’ are vectors with the same dimension
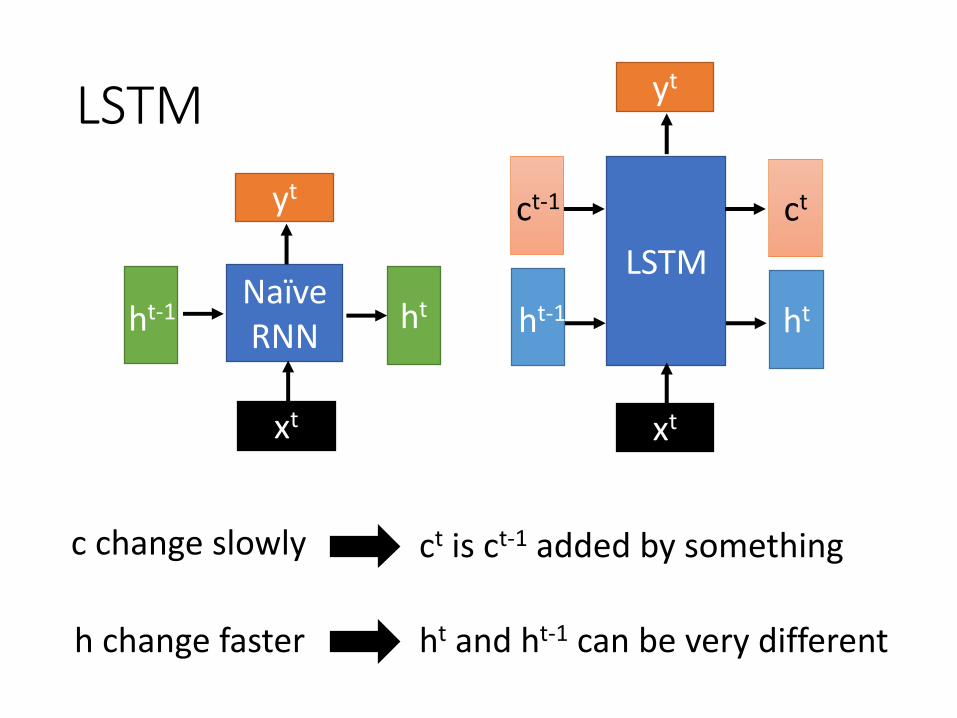
LSTM
c change slowly
h change faster
ct is ct-1 added by something
ht and ht-1 can be very different
NaïveRNN
ht
yt
xt
ht-1
LSTM
yt
ct
htht-1
ct-1
xt

xt
zzizf zo
ht-1
ct-1
zxt
ht-1W= 𝑡𝑎𝑛ℎ
zixt
ht-1Wi= 𝜎
zfxt
ht-1Wf= 𝜎
zoxt
ht-1Wo= 𝜎
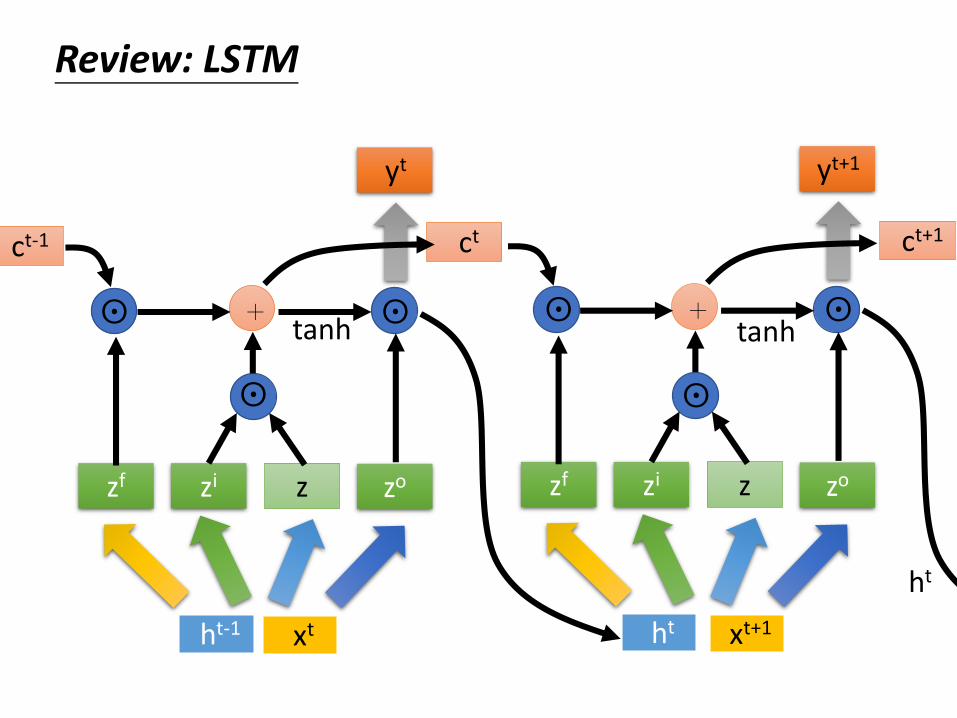
Review: LSTM
input
forget
output

ht
𝑐𝑡 = 𝑧𝑓⨀𝑐𝑡−1+𝑧𝑖⨀𝑧
xt
zzizf zo
+
yt
ht-1
ct-1 ct
ℎ𝑡 = 𝑧𝑜⨀𝑡𝑎𝑛ℎ 𝑐𝑡⨀
⨀ ⨀tanh
𝑦𝑡 = 𝜎 𝑊′ℎ𝑡
Review: LSTM
xt
zzizf zo
⨀ +
yt
ht-1
ct-1 ct
xt+1
zzizf zo
+
yt+1
ht
ct+1
⨀
⨀ ⨀
⨀
⨀tanh tanh
ht
Review: LSTM

ht
𝑐𝑡 = 𝑧𝑓⨀𝑐𝑡−1+𝑧𝑖⨀𝑧
xt
zzizf zo
+
yt
ht-1
ct-1 ct
ℎ𝑡 = 𝑧𝑜⨀𝑡𝑎𝑛ℎ 𝑐𝑡⨀
⨀ ⨀tanh
𝑦𝑡 = 𝜎 𝑊′ℎ𝑡
Similar to gradient descent based algorithm
𝜃𝑡−1 𝜃𝑡
𝜃𝑡 𝜃𝑡−1
−∇𝜃𝑙
𝜃𝑡 = 𝜃𝑡−1 − 𝜂∇𝜃𝑙
−∇𝜃𝑙
all “1” all 𝜂
−∇𝜃𝑙
11⋮
𝜂𝜂⋮

𝑐𝑡 = 𝑧𝑓⨀𝑐𝑡−1+𝑧𝑖⨀𝑧
xt
zzizf
+
ht-1
ct-1 ct
⨀
⨀
Similar to gradient descent based algorithm
𝜃𝑡−1 𝜃𝑡
𝜃𝑡 𝜃𝑡−1
−∇𝜃𝑙
𝜃𝑡 = 𝜃𝑡−1 − 𝜂∇𝜃𝑙
−∇𝜃𝑙
all “1” all 𝜂
−∇𝜃𝑙
Dynamic learning rate
Something like regularization
How about machine learn to determine 𝑧𝑓 and 𝑧𝑖 from −∇𝜃𝑙and other information?Other

LSTM for Gradient Descent
“LSTM”𝜃0 𝜃1
−∇𝜃𝑙
𝜃2
−∇𝜃𝑙
𝜃3
−∇𝜃𝑙
“LSTM” “LSTM”
3 training steps Testing Data 𝑙 𝜃3
Batch from train
Batch from train
Batch from train
Learnable
Typical LSTM
𝑐𝑡 = 𝑧𝑓⨀𝑐𝑡−1+𝑧𝑖⨀𝑧𝜃𝑡 𝜃𝑡−1 −∇𝜃𝑙 Learn to minimize
Independence assumption

The LSTM used only has one cell. Share across all parameters
“LSTM”𝜃10 𝜃1
1
−∇𝜃1𝑙
𝜃12 𝜃1
3“LSTM” “LSTM”
➢ Reasonable model size➢ In typical gradient descent, all the parameters use the
same update rule➢ Training and testing model architectures can be different.
Real Implementation
−∇𝜃1𝑙 −∇𝜃1𝑙
“LSTM”𝜃20 𝜃2
1
−∇𝜃2𝑙
𝜃22 𝜃2
3“LSTM” “LSTM”
−∇𝜃2𝑙 −∇𝜃2𝑙
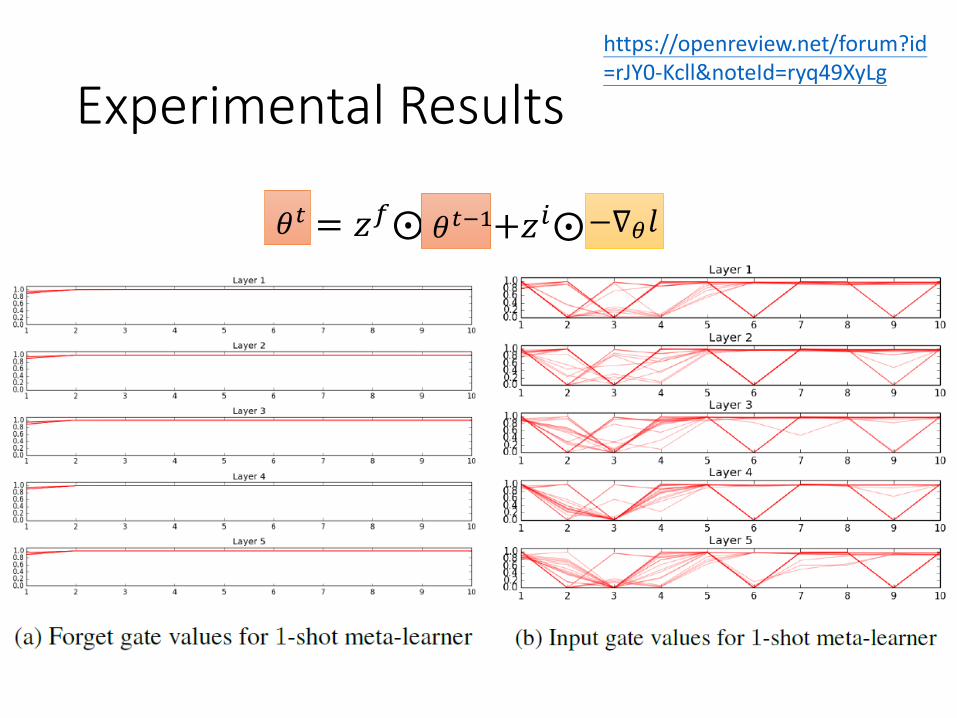
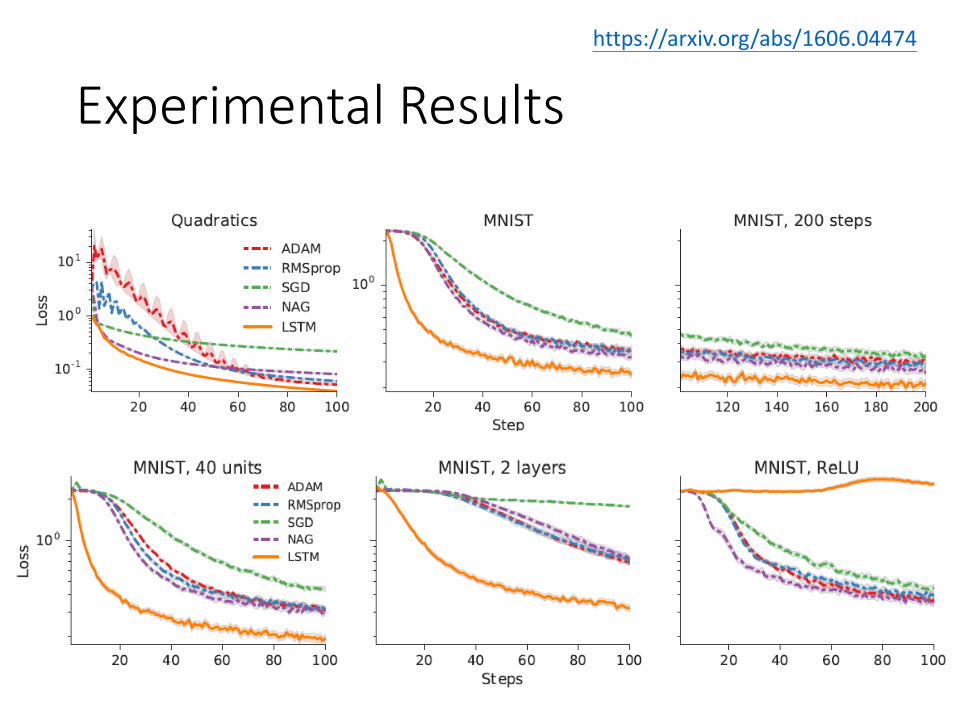
Experimental Resultshttps://openreview.net/forum?id=rJY0-Kcll¬eId=ryq49XyLg
𝑐𝑡 = 𝑧𝑓⨀𝑐𝑡−1+𝑧𝑖⨀𝑧𝜃𝑡 𝜃𝑡−1 −∇𝜃𝑙

Parameter update depends on not only current gradient, but previous gradients.
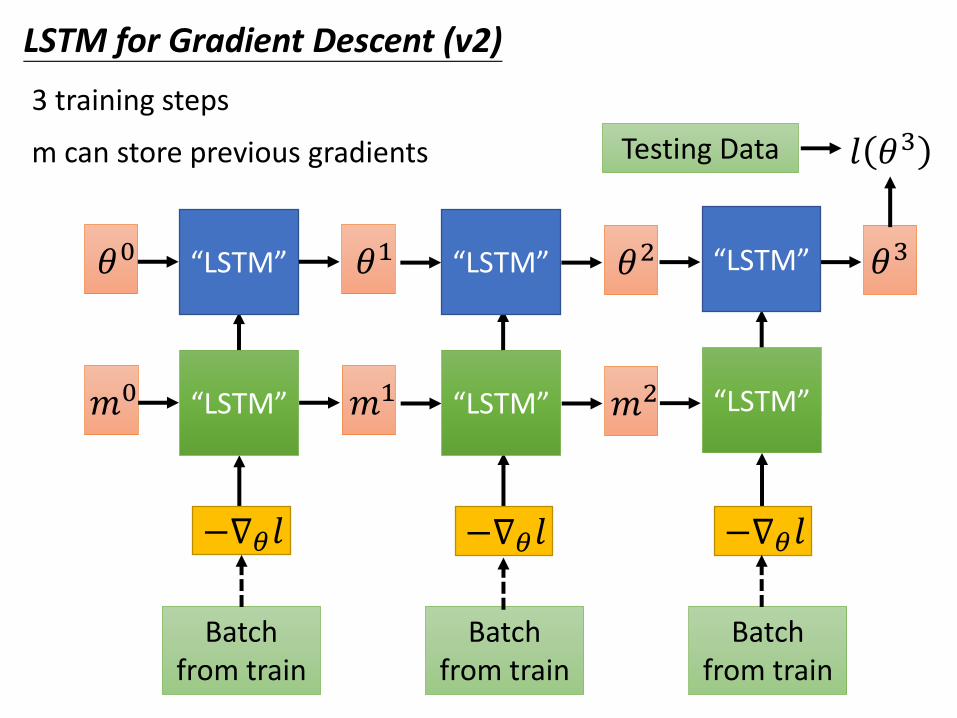
LSTM for Gradient Descent (v2)
“LSTM”𝜃0 𝜃1
−∇𝜃𝑙
𝜃2
−∇𝜃𝑙
𝜃3
−∇𝜃𝑙
“LSTM” “LSTM”
3 training steps
Testing Data 𝑙 𝜃3
Batch from train
Batch from train
Batch from train
“LSTM”𝑚0 𝑚1 𝑚2“LSTM” “LSTM”
m can store previous gradients

Meta Learning (Part 3)Hung-yi Lee

Even more crazy idea …
• Input:
• Training data and their labels
• Testing data
• Output:
• Predicted label of testing data
Training Data & Labels
cat
cat dog
Testing Data
Learning + Prediction
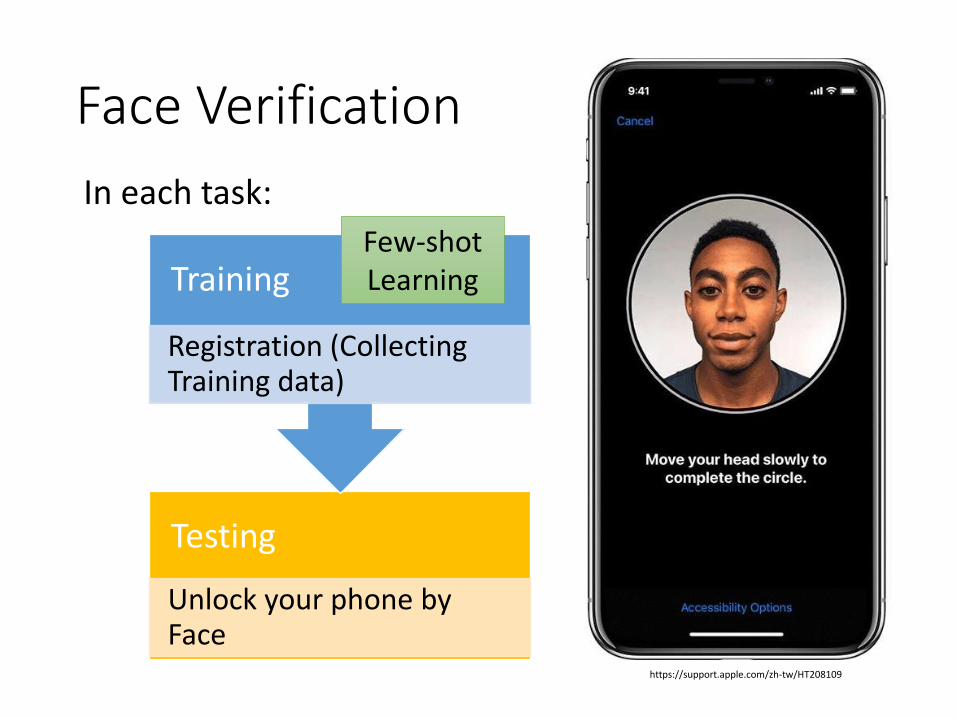
Face Verification
https://support.apple.com/zh-tw/HT208109
Testing
Unlock your phone by Face
Training
Registration (Collecting Training data)
In each task:
Few-shot Learning

Training Tasks
Testing Tasks
Train Test
Train Test
Yes
Train Test No
Meta Learning
Train Test No
YesorNo
Network
Network
Network
Yes
No
?
Same approach for Speaker Verification

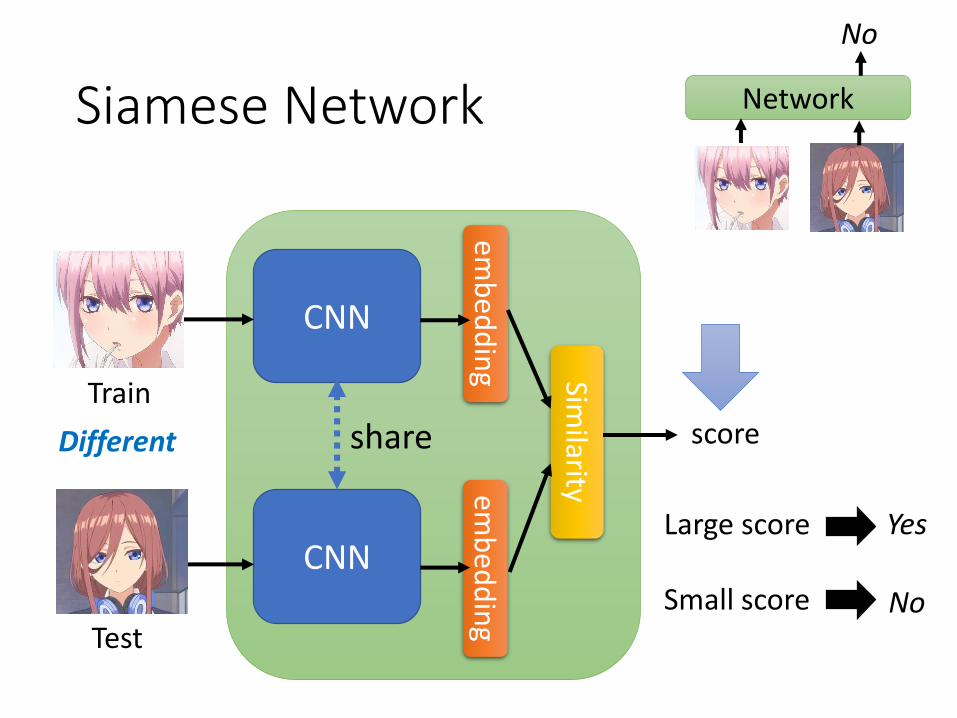
Siamese Network Network
No
CNN
Similarity
CNN
shareem
be
dd
ing
emb
ed
din
g
Train
Test
score
Large score
Small score
Yes
No
Same
Siamese Network Network
No
CNN
Similarity
CNN
shareem
be
dd
ing
emb
ed
din
g
Train
Test
score
Large score
Small score
Yes
No
Different
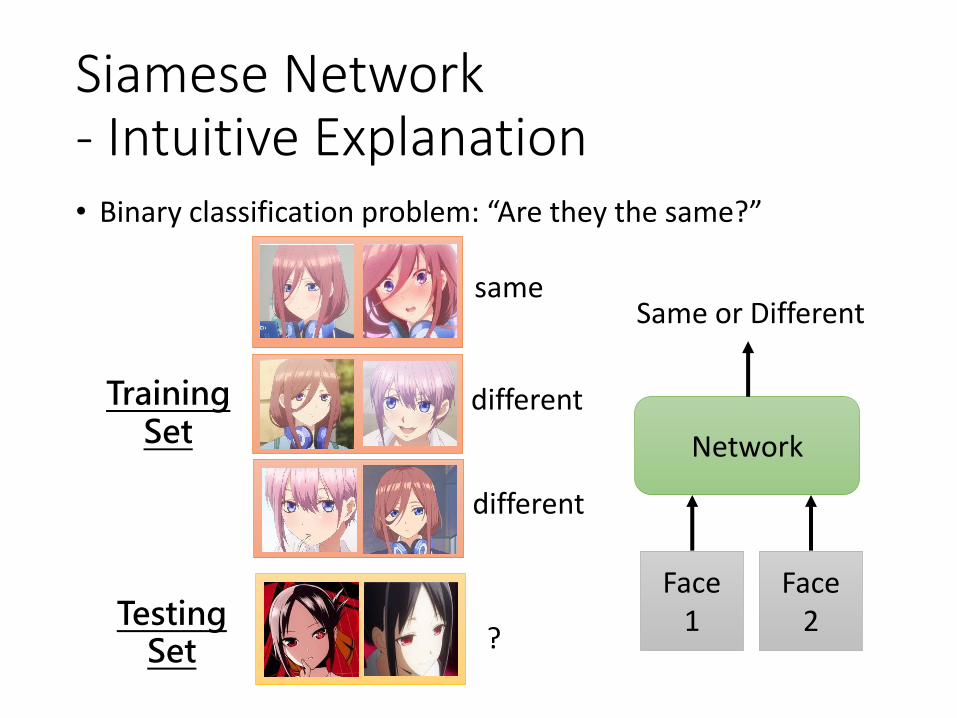
Siamese Network- Intuitive Explanation • Binary classification problem: “Are they the same?”
Training Set
Testing Set ?
same
different
different
Network
Same or Different
Face1
Face2
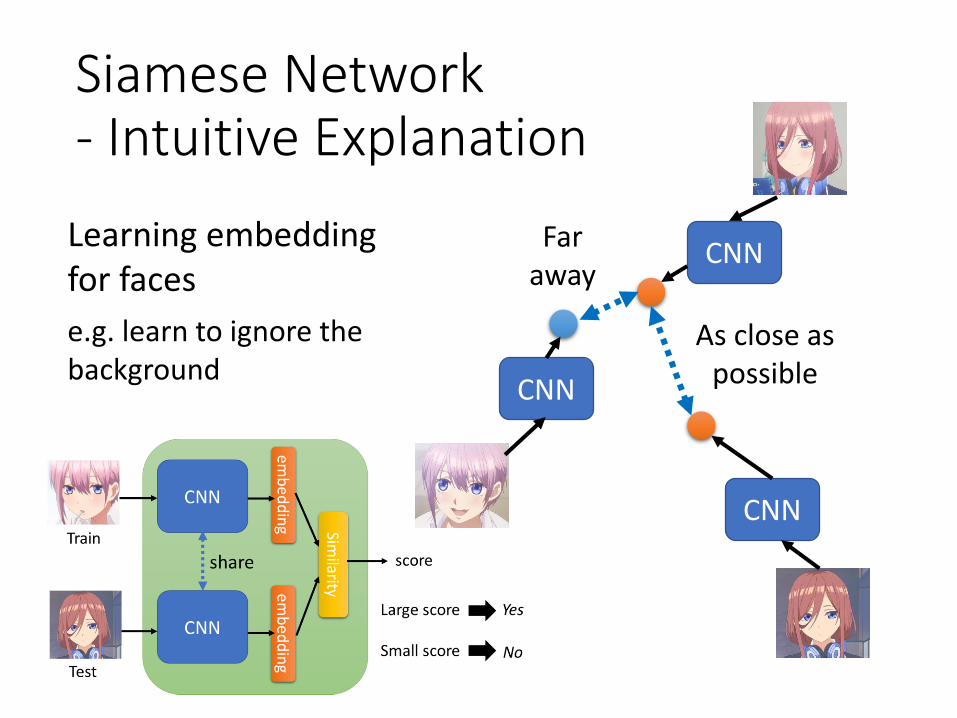
Siamese Network- Intuitive Explanation
Learning embedding for faces
e.g. learn to ignore the background
CNN
CNN
CNNFar
away
As close as possible

To learn more …
• What kind of distance should we use?
• SphereFace: Deep Hypersphere Embedding for Face Recognition
• Additive Margin Softmax for Face Verification
• ArcFace: Additive Angular Margin Loss for Deep Face Recognition
• Triplet loss
• Deep Metric Learning using Triplet Network
• FaceNet: A Unified Embedding for Face Recognition and Clustering

N-way Few/One-shot Learning
• Example: 5-ways 1-shot
Training Data (Each image represents a class)
Testing Data
Network (Learning + Prediction)
一花 二乃 三玖 四葉 五月
三玖

Testing Data
Prototypical Network
https://arxiv.org/abs/1703.05175
CNN CNN CNN CNN CNN
CNN
= similarity
𝑠1 𝑠2 𝑠3 𝑠4 𝑠5
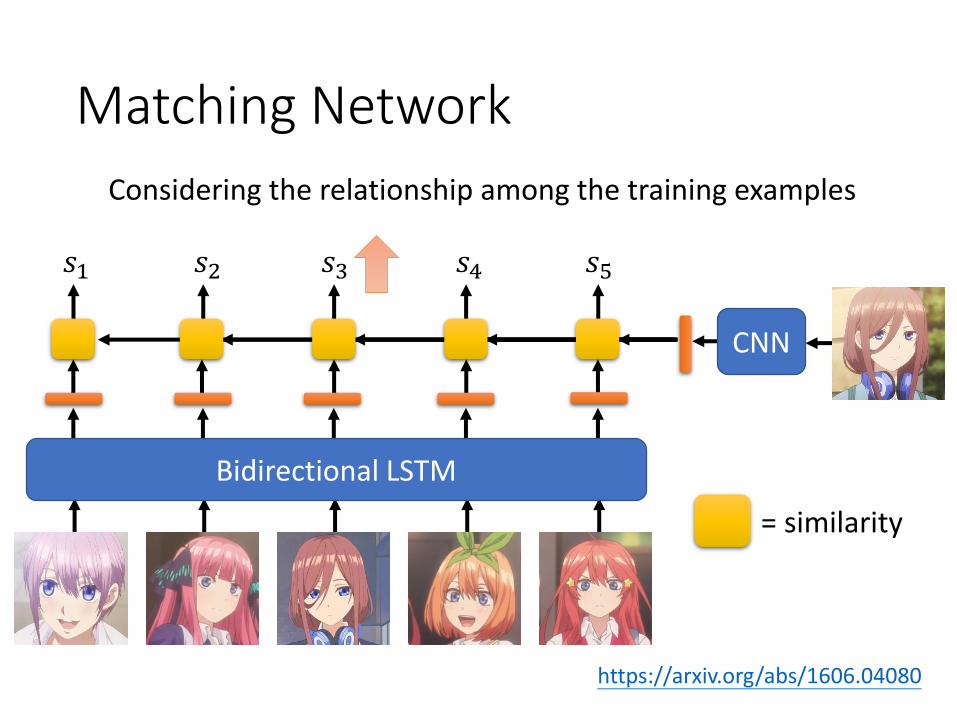
Matching Network
https://arxiv.org/abs/1606.04080
Bidirectional LSTM
CNN
= similarity
𝑠1 𝑠2 𝑠3 𝑠4 𝑠5
Considering the relationship among the training examples

Few-shot learning for imaginary data
https://arxiv.org/abs/1801.05401
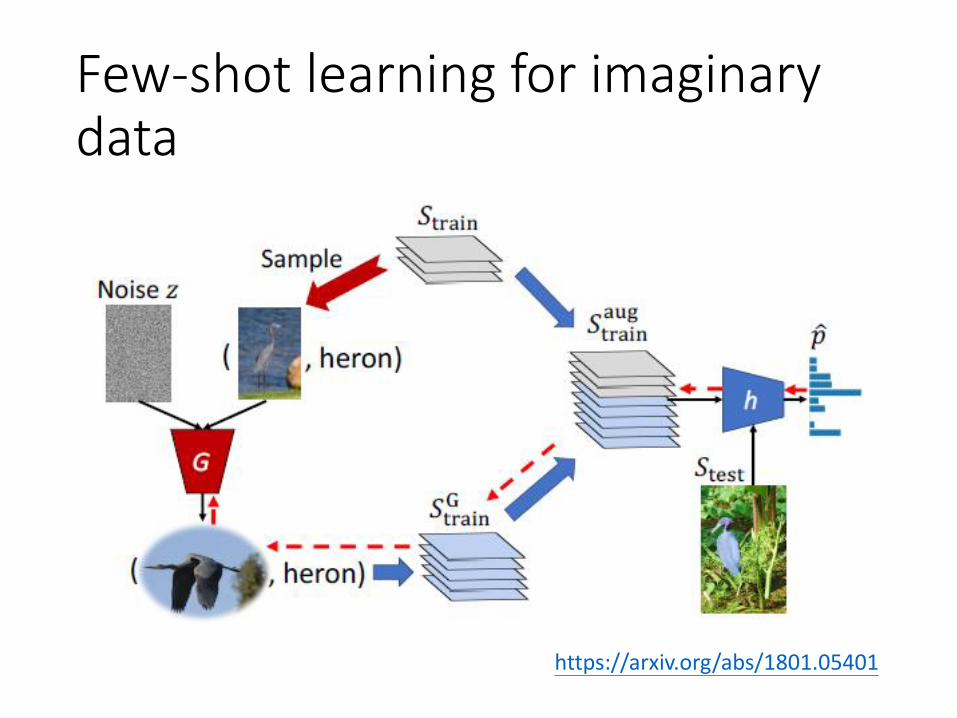
Few-shot learning for imaginary data
https://arxiv.org/abs/1801.05401
Top Related