







Languages
Pages
Legal


Accelerating High Performance Computing
http://www.nvidia.com/tesla
Marco Piattelli
Channel sales
South Europe

2
The ‘Super’ Computing Company SuperPhones to SuperComputers

3
c
VISUALIZATION
PARALLEL
COMPUTING PERSONAL
COMPUTING

4
CUDA GPU
Hundreds of parallel cores
CPU
Several sequential cores
CUDA GPU Accelerates Computing Choose the Right Processor for the Right Job

5
146X
Medical Imaging
U of Utah
36X
Molecular Dynamics
U of Illinois, Urbana
18X
Video Transcoding
Elemental Tech
50X
Matlab Computing
AccelerEyes
100X
Astrophysics
RIKEN
149X
Financial Simulation
Oxford
47X
Linear Algebra
Universidad Jaime
20X
3D Ultrasound
Techniscan
130X
Quantum Chemistry
U of Illinois, Urbana
30X
Gene Sequencing
U of Maryland
GPUs Accelerate Science

6
#2 : Tianhe-1A 7168 Tesla GPU’s 2.5 PFLOPS
#4 : Nebulae 4650 Tesla GPU’s 1.2 PFLOPS
We not only created the world's fastest computer, but also implemented a heterogeneous computing architecture incorporating CPU and GPU, this is a new innovation. ” Premier Wen Jiabao
Public comments acknowledging Tianhe-1A
“
#5 : Tsubame 2.0 4224 Tesla GPU’s 1.194 PFLOPS
Tesla GPUs Power 3 of Top 5 Supercomputers

7
Titan at Oak Ridge
World’s Top Open Science Computing Research Facility
2x Faster, 3x More Energy Efficient
than Current #1 (K Computer)
18,000 Tesla GPUs
20+ PetaFlops
~90% of flops from GPUs

8 Source: ORNL
S3D Model Combusion
for higher efficiency fuels & engines
LAMMPS Model biofuels. Reduce carbon
emissions & dependence on
foreign oil
CAM-SE Model global climate
change & explore mitigation strategies
Denovo Simulate radiation transport for safe,
clean, fusion energy
Titan Will Have Huge Societal Impact

9
CUDA By the Numbers:
CUDA Capable GPUs >375,000,000
Toolkit Downloads >1,000,000
Active Developers >120,000
Universities Teaching CUDA >500
New CUDA Toolkit Downloads / Hour 98
10
Workstations Servers & Blades
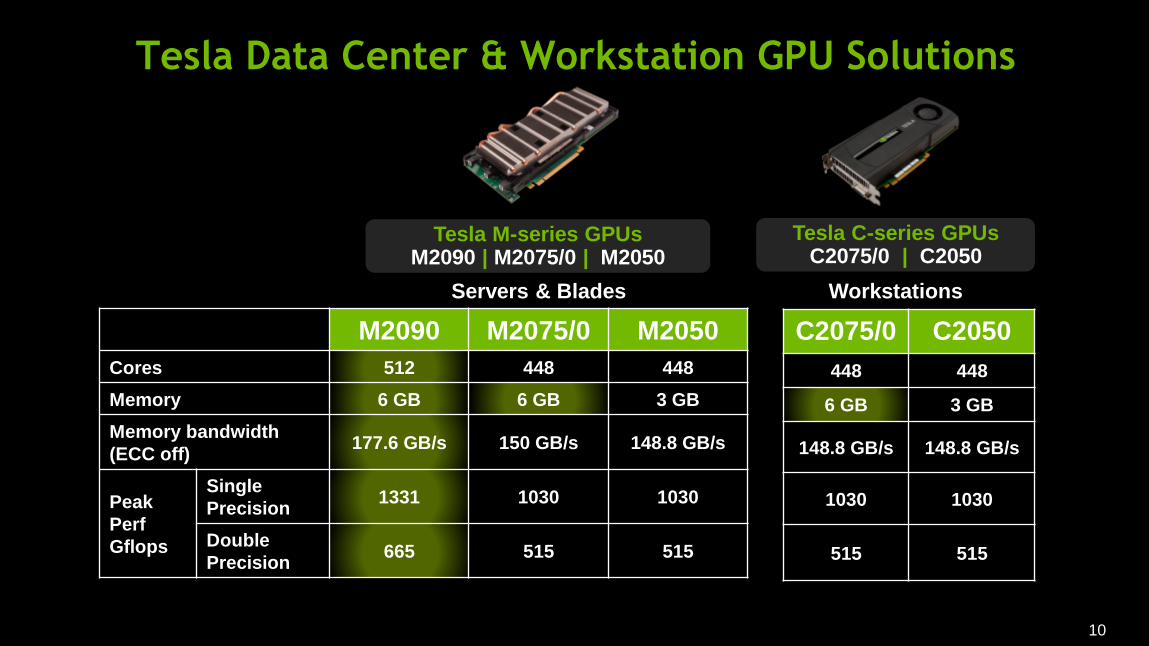
Tesla Data Center & Workstation GPU Solutions
Tesla M-series GPUs M2090 | M2075/0 | M2050
Tesla C-series GPUs C2075/0 | C2050
M2090 M2075/0 M2050
Cores 512 448 448
Memory 6 GB 6 GB 3 GB
Memory bandwidth
(ECC off) 177.6 GB/s 150 GB/s 148.8 GB/s
Peak
Perf
Gflops
Single
Precision 1331 1030 1030
Double
Precision 665 515 515
C2075/0 C2050
448 448
6 GB 3 GB
148.8 GB/s 148.8 GB/s
1030 1030
515 515

11
Getting Started with GPUs
TRY
Try CUDA 4.0 on your Notebook or
Desktop with CUDA Enabled GPU
DEVELOP
Optimize HPC Apps on Compute
Workstation with Tesla GPUs
DEPLOY
Run apps in production with GPU
Compute Cluster

12
Rich Toolchain & Ecosystem for Fast Ramp-up on GPUs
Debuggers & Profilers
cuda-gdb NV Visual Profiler
Parallel Nsight Visual Studio
Allinea TotalView
MATLAB Mathematica NI LabView
pyCUDA
Numerical Packages
C C++
Fortran OpenCL
DirectCompute Java
Python
GPU Compilers
PGI Accelerator CAPS HMPP
mCUDA OpenMP
Parallelizing Compilers
BLAS FFT
LAPACK NPP
Sparse Imaging
RNG
Libraries
OEM Solution Providers GPGPU Consultants & Training
ANEO GPU Tech

13
Programming GPUs

14
Enabling Developer Ecosystem
Tools & Libraries
TotalView Debugger
Thrust C++ Template Lib
R-Stream
Reservoir Labs
NVIDIA NPP Perf
Primitives
Bright Cluster Manager
CAPS HMPP
PBSWorks
PGI CUDA Fortran
GPU Packages For R Stats
Pkg
IMSL
TauCUDA Perf Tools
pyCUDA
Platform LSF Cluster
Manager
MAGMA
MOAB
Adaptive Computing
Torque
Adaptive Computing
EMPhotonics CULAPACK
NVIDIA Video
Libraries CUDA C/C++
Parallel Nsight Vis Studio IDE
Allinea DDT Debugger
ParaTools VampirTrace
PGI Accelerators
Acceleware EM Library
Open CV CUDA Beta
CUDA X86
GPU.Net
C++-AMP
Available NVIDIA
15
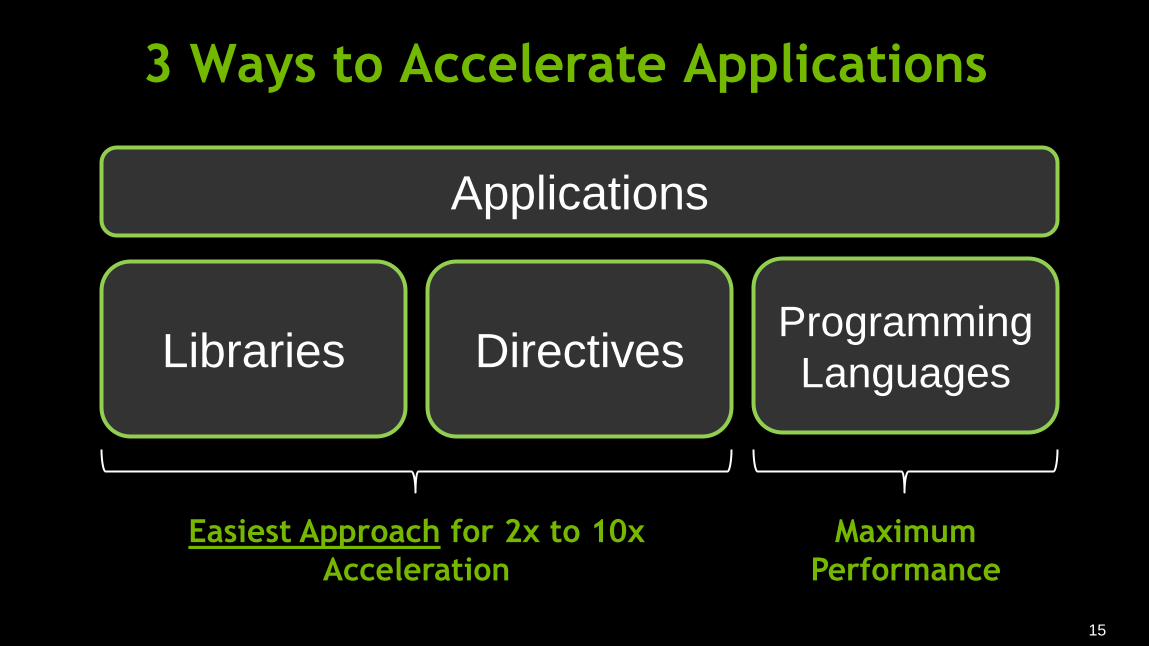
3 Ways to Accelerate Applications
Libraries Directives Programming
Languages
Applications
Easiest Approach for 2x to 10x
Acceleration
Maximum
Performance

16
NVIDIA cuBLAS NVIDIA cuRAND NVIDIA cuSPARSE NVIDIA NPP
Vector Signal Image Processing
GPU Accelerated Linear Algebra
Matrix Algebra on GPU and Multicore NVIDIA cuFFT
C++ STL Features for CUDA
Sparse Linear Algebra
Building-block Algorithms for CUDA IMSL Library
GPU Accelerated Libraries “Drop-in” Acceleration for Your Applications
17
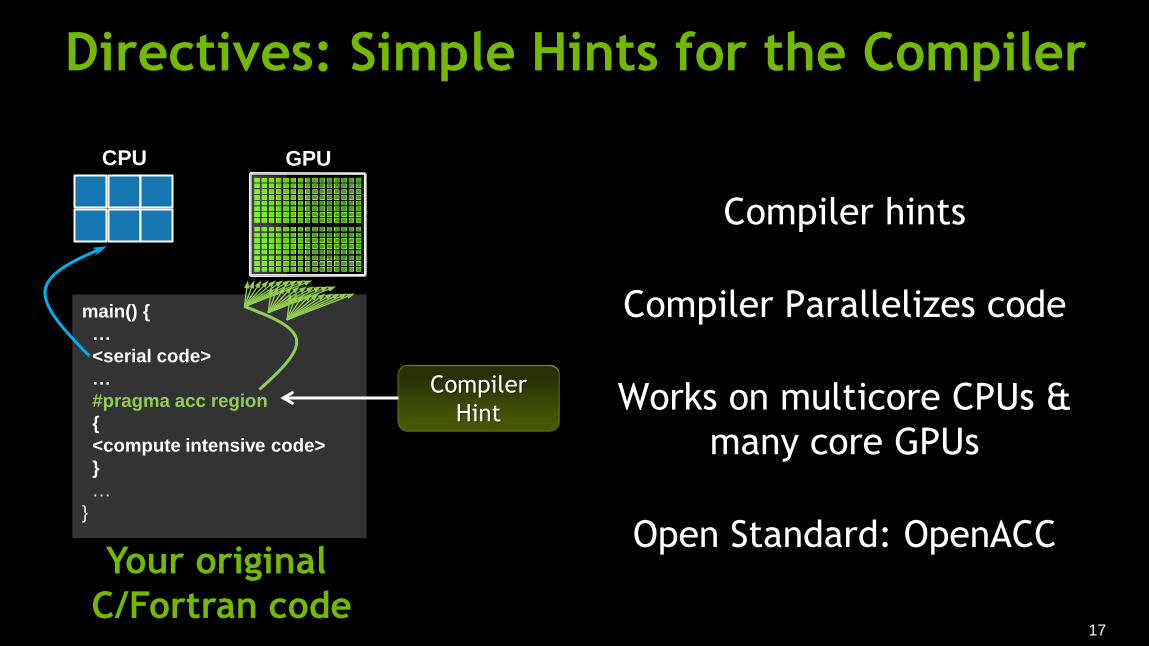
Directives: Simple Hints for the Compiler
main() {
…
<serial code>
…
#pragma acc region
{
<compute intensive code>
}
…
}
CPU GPU
Your original
C/Fortran code
Compiler hints
Compiler Parallelizes code
Works on multicore CPUs &
many core GPUs
Open Standard: OpenACC
Compiler
Hint

18
OpenACC: Open Parallel Programming Standard
Buddy Bland Titan Project Director
Oak Ridge National Lab
Dr. Kerry Black Associate Professor,
University of Melbourne
Easy Open Safe

19
Directives or CUDA C/C++/Fortran
Develop your own
parallel algorithms
Automatically parallelize
your loops
CUDA
C/C++/Fortran

20
Opening the CUDA Platform
CUDA Compiler Source for
Researchers & Tools Vendors
Enables
New Language Support
New Processor Support
CUDA Compiler LLVM
C C++ Fortran
New Language Support
PGI NVIDIA
x86 CPUs
NVIDIA GPUs
New Processor Support

21
Opening the CUDA Platform
Liszt

22
Moving Forward: Standards & Compilers
MPI

23
PGI CUDA x86 CUDA Now Available for CPUs and GPUs
Single CUDA
C / C++
Codebase
NVIDIA C / C++ Compiler
PGI CUDA X86 Compiler
C / C++ Support
GPU
CPU

24
CUDA GPU Roadmap
16
2
4
6
8
10
12
14
DP G
FLO
PS p
er
Watt
2007 2010 2012 2014
Tesla Fermi
Kepler
Maxwell

25
CUDA for ARM Development Kit
Research development board
Quad-core ARM based NVIDIA Tegra 3 processor
NVIDIA CUDA GPU
Gigabit Ethernet
CUDA software development kit
Available: 1H 2012
SECO Hardware Development Kit
CUDA GPU Tegra ARM CPU
http://www.secoqseven.com/en/item/secocq7-mxm/

26
CUDA Everywhere:
Supercomputers to Superphones

27
Thank You, Questions ?
Top Related