







Languages
Pages
Legal


Low Cost, High Performance, and Scalability:A New Approach to User-Level Distributed
Shared Memory
Patrick Anthony La FrattaWORTS 2005
15 December 2005
GUARANTEED!
OR YOUR MONEY BACK!!!

Programming Models: Message-Passing

Programming Models: Message-Passing

Programming Models: Shared Memory

Implementing a DSM System at the User Level

Implementing the DSM ClientInitialization, Step 1:
Get size of shared memory segment.
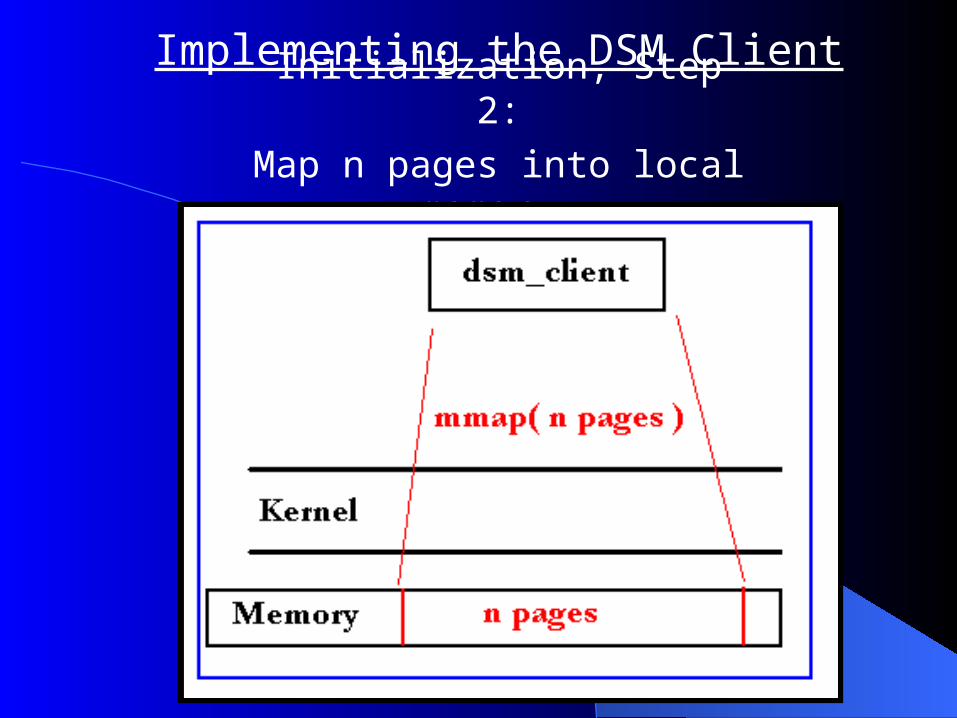
Initialization, Step 2:Map n pages into local
memory.
Implementing the DSM Client

Initialization, Step 3:Take away all access privileges from the
shared segments.
Implementing the DSM Client

Initialization, Step 4:Set up the segmentation fault
handler.
Implementing the DSM Client
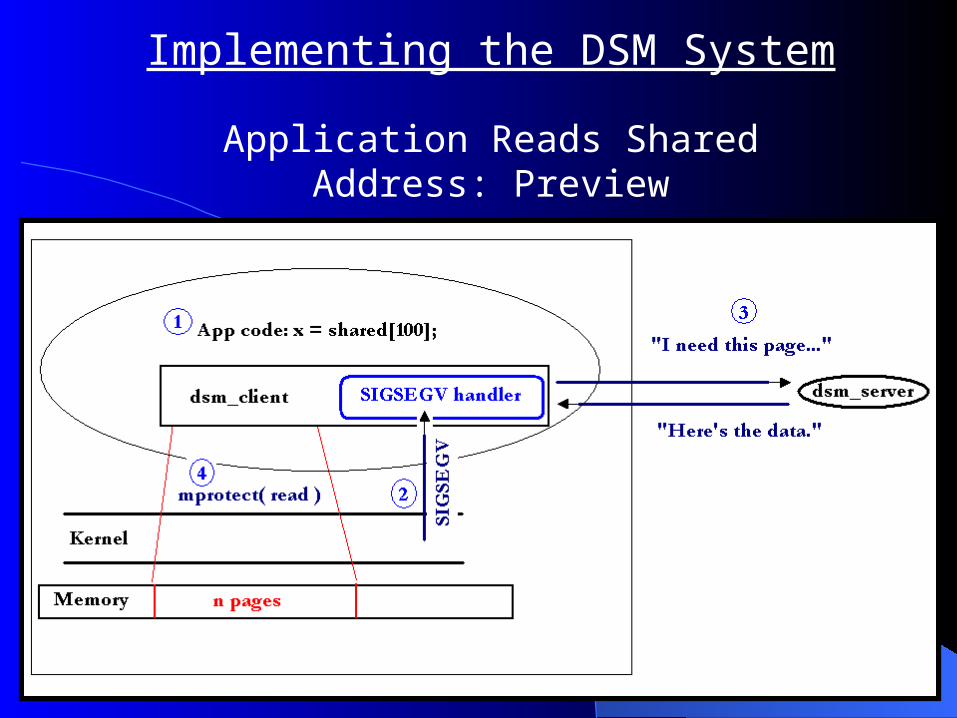
Implementing the DSM System
Application Reads Shared Address: Preview

Implementing the DSM System
Shared address read, Step 1:Application reads shared address.

Implementing the DSM SystemShared address read, Step 2:
Control transferred to seg-fault handler.

Implementing the DSM System
Shared address read, Step 3:Client contacts the server to get the page’s
data.

Implementing the DSM System
Shared address read, Step 4:Client grants read access privileges to
application.
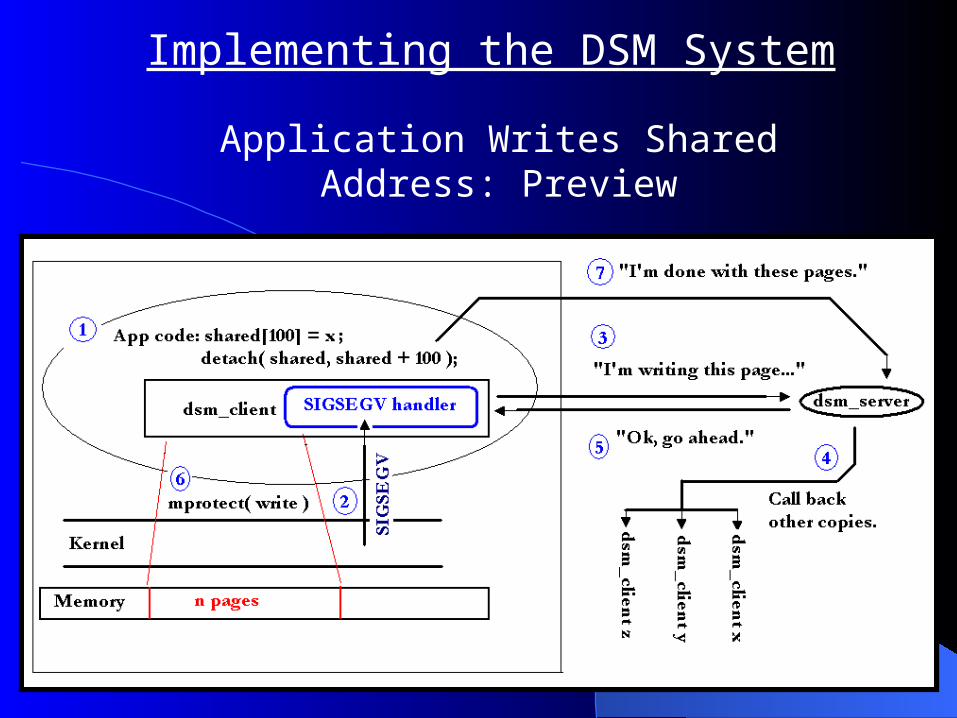
Implementing the DSM System
Application Writes Shared Address: Preview

Implementing the DSM System
Shared address write, Step 1: Application writes shared address.

Implementing the DSM SystemShared address write, Step 2: Control transferred to seg-fault
handler.

Implementing the DSM SystemShared address write, Step 3:
Client contacts server to with write notification.

Implementing the DSM SystemShared address write, Step 4:
Server calls back all other copies of pages being written.

Implementing the DSM System
Shared address write, Step 5: Server indicates to client to proceed.

Implementing the DSM SystemShared address write, Step 6:
Client grants write privileges to application.

Implementing the DSM SystemShared address write, Step 7:
Later, the app detaches pages so others may use them.
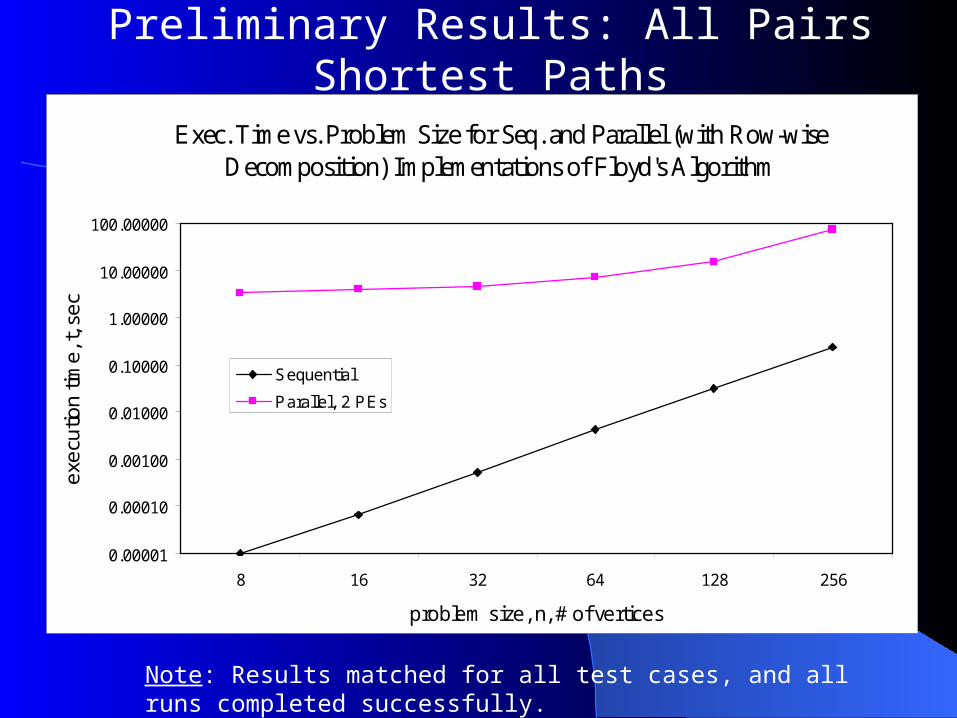
Preliminary Results: All Pairs Shortest Paths
Note: Results matched for all test cases, and all runs completed successfully.
Exec. Time vs. Problem Size for Seq. and Parallel (with Row-wise Decomposition) Implementations of Floyd's Algorithm
0.00001
0.00010
0.00100
0.01000
0.10000
1.00000
10.00000
100.00000
8 16 32 64 128 256
problem size, n, # of vertices
exe
cutio
n ti
me
, t, s
ec
Sequential
Parallel, 2 PEs

System Profiling: All Pairs Shortest Paths
0.010
0.100
1.000
10.000
100.000
1000.000
8 16 32 64 128 256 512 1024 2048
Problem Size, n, # of Vertices
Tim
e, t
, sec
Total Execution Time

0.001
0.010
0.100
1.000
10.000
100.000
1000.000
8 16 32 64 128 256 512 1024 2048
Problem Size, n, # of Vertices
Tim
e, t
, sec
T
C1DT
C2DT
BWT
System Profiling: All Pairs Shortest Paths
System Modifications and Extensions
• Better understanding of the trade-offs in the design of the interface.
• Efficient synchronization primitives through extended memory semantics with full/empty bits.
• Server-side per-page locking and client-side full- page flushing.
* Speedups > 1! *
System profiles resulted in:

Performance Results: Speedup for Various Configurations
0
1
2
3
4
5
6
7
256 512 1024 2048 4096 8192
Problem Size, n, # of Vertices
Sp
eed
up
vs.
Seq
uen
tial
Imp
lem
enta
tio
n2 P Es
4
8
16

0
1
2
3
4
5
6
7
256 512 1024 2048 4096 8192
Problem Size, n, # of Vertices
Sp
eed
up
vs.
Seq
uen
tial
Imp
lem
enta
tio
n2 P Es
4
8
16
Performance Results: Trends

Future Work
• Scalability: Enable clients to use more than one server.
• Peer-to-peer: Merge the server and client modules.
• Fault-tolerance: Checkpoint and Migration?
• Further testing: Implement and evaluate performance of other parallel applications.
Questions?
Top Related